Retriever: Learning Content-Style Representation as a Token-Level Bipartite Graph
Dacheng Yin*, Xuanchi Ren*, Chong Luo, Yuwang Wang, Zhiwei Xiong and Wenjun Zeng
ICLR 2022
🔲 Merge and Clean Code
We are cleaning and merging the code and hope to release it very soon.
For the vision part, we provide a sample (uncleaned) code here.
For the audio part, we provide a sample (uncleaned) code here.
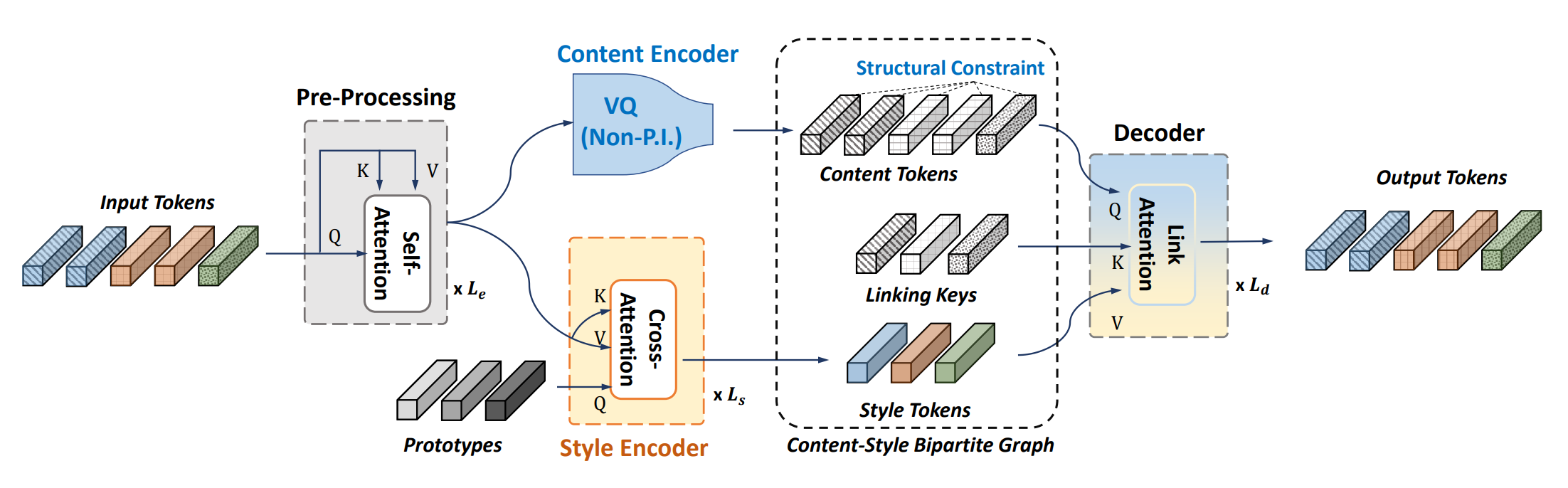
In this repo, we propose an unsupervised and modality-agnostic content-style disentanglement framework: Retriever. We demonstrate that our learned representation can benefit zero-shot voice conversion, co-part segmentation, and style transfer.
Researcher found that Retriever can be applied to many more tasks!
- Retriever for text based speech editing: RetrieverTTS: Modeling Decomposed Factors for Text-Based Speech Insertion.
- Retriever for video: Decomposing Style, Content, and Motion for Videos.
@inproceedings{yin2022Retriever,
title = {Retriever: Learning Content-Style Representation as a Token-Level Bipartite Graph},
author = {Yin, Dacheng and Ren, Xuanchi and Luo, Chong and Wang, Yuwang, and Xiong, Zhiwei, and Zeng, Wenjun},
booktitle = {ICLR},
year = {2022}
}