Second exercise for the subject 20_SVE2UE at FH OÖ Campus Hagenberg. The exercise is based on Amazon Managed Streaming for Apache Kafka and uses the kafka-python library for the producers and consumers.
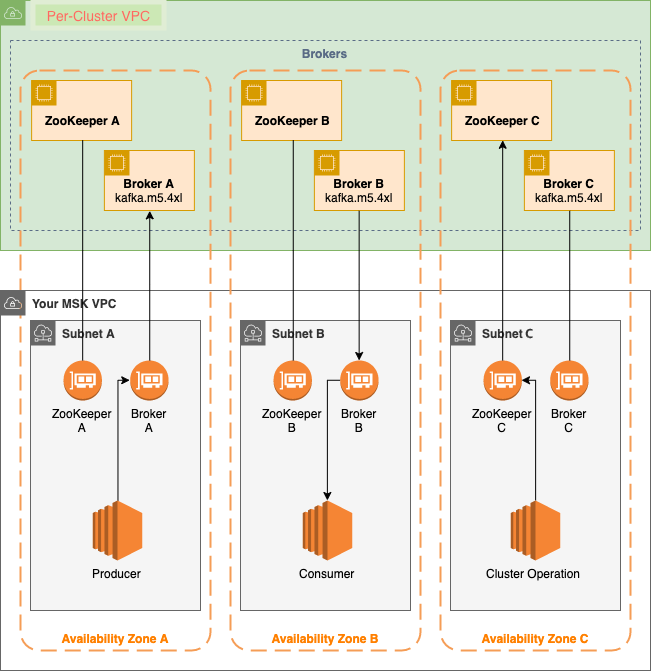
After implementing the three services I had to find out that the MSK does not expose public endpoints according to their FAQ:
Q: Is the connection between my clients and an Amazon MSK cluster always private? Yes, the only way data can be produced and consumed from an Amazon MSK cluster is over a private connection between your clients in your VPC, and the Amazon MSK cluster. Amazon MSK does not support public endpoints.
There are solutions to bypass this problem (VPC Peering, Direct Connect, VPN or Elastic IPs) but these approaches are either too much overhead for such a demo project or not easy to automate. Another downside is that MSK does not support auto-scaling for brokers but only for storage.
To mitigate these challenges the Confluent cloud was used which allows connections through local clients, provides better documentation for client SDKs and also offers the following features:
- Scheme Registry: Registry that manages schemas that define how data is structured in Kafka messages.
- ksqlDB: An event streaming database purpose-built to help developers create stream processing applications on top of Apache Kafka.
- Connectors: Pre-built, Kafka Connectors that make it easy to instantly connect to popular data sources and sinks.
- Kafka Connect: A framework for connecting Apache Kafka with external systems such as databases, key-value stores, search indexes, and file systems.
Service that allows producers to send analytics events via Kafka. A producer also provides an interface to receive data from a client applications. However, this aspect is only abstracted in the course of this task. The events sent are then stored by a consumer. The data stream would look like this: client (iOS, Web, ...) -> producer (Python) -> Kafka -> consumer (Python) -> data store.
The initial architecture would have looked like this with producers and consumers running on a local machine. This architecture is also represented as Terraform configuration in the infrastructure folder.
Due to the downsides of AWS MSK the architecture now uses Confluent as provider:

For detailed information about the individual services read the corresponding README.
| Service | Description |
|---|---|
| analytics | Provides a REST API to start the event simulation or to manually create events. It takes over the producer part an sends the created events to the broker. |
| feeder | Consumes the events from the broker and saves it to a CSV file. |
| visualization | Uses the CSV file generated by the feeder component and generates a website which visualises the results. |
terraformawscli
make bootstrap
make run
The switch from AWS MSK to Confluent increased the development speed immediately. Confluent itself relies on cloud providers like AWS, Azure or GCP but abstracts away the network infrastructure and offers an easy-to-use UI, API and framework. For instance, the data flow of the application can be easily viewed which helps to find errors in the pipeline:

See README analytics
See README feeder
To summarize all the mentioned points it can be said that Confluent has a much lower learning curve for developers and makes it easy to get started with Kafka. AWS MSK on the hand is more flexible because you define things like security groups or availability zones for yourself but does not offer a public endpoint at the time of this writing.