Some PERSONAL CHEATSHEETS for elevator pitch/dialogue to spark interest for value that tech-supported ways of cooperation can deliver. Tech jargon, examples, implementation details are for later. The content is NOT SUPER SELF-EXPLAINING, as they are core ingredients WRITTEN FOR ONLY MYSELF, that I tend to explain in actual communication often in some specific contexts. Some people still found it useful as such, so I shared it here.

.svg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Tiny errors make big errors (elsewhere, later, seemingly unrelated, often even unnoticed). Therefore preventing and finding errors should be close, early and relations made visible.
- Fresh high-quality data should be rewarded by minimizing (other) disturbances. Wonder for a moment what analysis comes from 'just another thing to fill in for management'.
- People working/living in immediate context of the data usually know best what values/patterns make sense. Help them configure immediate validation, sharing and loosely coupled visualization and also analysis elsewhere will improve.
- Start by turning on spelling checkers, especially because our digital assistents (starting with search) are easily 'confused'. The more data is combined, the more sensitive it is to data imperfections.
- Let everybody learn a few basic rules to avoid Excel pitfalls, towards 'tidy data'.
- Instead of some of the alternation between group discussion and lone work, PAIRING: More immediate-feedback hands-on working with 2 people, lowering the risk of errors. Can be together at 1 desk making good use of richness of In-Real-Life communication with gestures, physical objects, etc., or remote with audio connection and simultaneously working in the same application context. As this is a different social construct, it allows for more personalized communication and concrete learning, passed on to sessions with others where applicable.
- data-centric (manifesto): Not apps, but YOU as an organisation decide what your terminology means exactly, where to store your data, in what open format, and how and where is defined what roles/groups/people have what access (full/no/structural/privacy-improved/synthetic, remote/read/write/reshare). You may want applications that are open source with active communities too. You most likely need data-cleaning tools like OpenRefine.
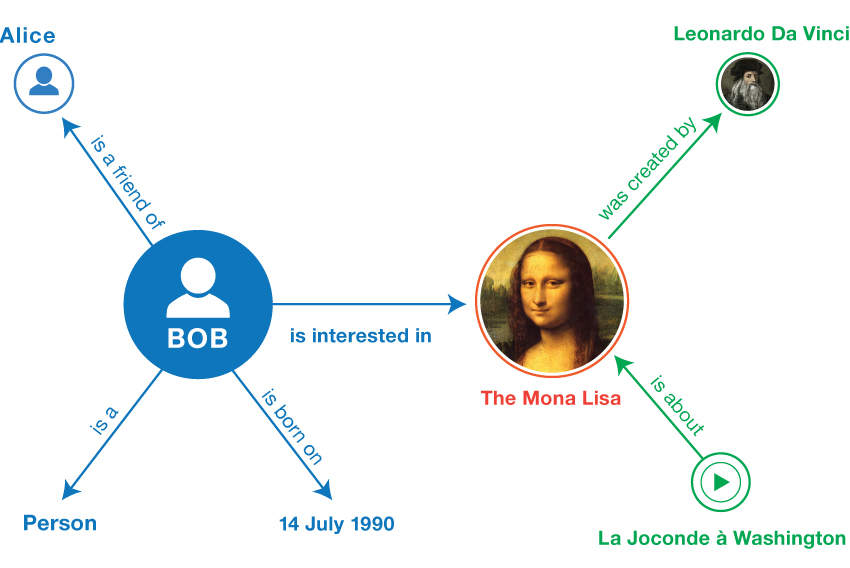
- Linked Data: associative as brains and communities. Links databases and documents, internal and external, open and closed, including late integration systems like ESBs, by early chosen standard vocabularies. Enables querying any combination of sources, as if one virtual dataset. Also known as "semantic web". Most Linked Data is 'hidden under the hood' by programmers. I wonder if end users can productively be more directly involved with 'triples' in multi-user knowledge-based mindmapping/dialogue.
- FAIR data: Findable-Accessible-INTEROPERABLE-Reusable; enabling faster research with earlier, wider, AI-assisted cooperation. Everybody in research data management is working on this. Training by carpentries.org (I'm a certified instructor) and others, gets researchers on board.
- Knowledge Graphs (link is to course I did): Organizations organized, learning from (content from) each other while doing. Gartner short video "Top Trends in Data and Analytics for 2021: Graph Relates Everything" and (paywalled) the full article.
- SoLiD? (Social Linked Data): users of applications have fine-grained control of their data, hosted outside the applications, together in a so-called personal dataPOD. Less scattered data, more standardized therefore more re-used fields, less monopoly power.
- Data Management Plans and both data and everything else IT on the balance sheet, for value and against vulnerability.
- Project results may need assistance and dynamic infrastructure to enable (later) moving it to a different project or standing organisation.
- Clearly there are different types of IT (office IT, research IT, factory IT, etc.) that need different people. If you haven't yet figured out what type of IT I think about the most, I do find surf.nl and esciencecenter.nl interesting to read, among many others.
{kind=link}
{kind=link}
Shared on-line documents in which writers and 'programming analysts' can cooperate effectively and reproducibly through:
- Tighter feedback loop between people with different focus: tech-savvy and not, researchers and supporters (both of the dedicated official and technical community type), codecheckers/reviewers and communicators. A web in which I'd love to be adding value, helping, connecting.
- Less manual copy-paste between different applications.
- No, or less, install (differences).
- Possible within security context of data. Make sure early that people you (might) need in that security context, are ready to be added, as non-disclosure paperwork can take long, or make things near impossible.
- Backend can run on High Performance Computing (HPC) too.
- Jupyter is probably the most popular and has many derivatives. Others are Rnotebook(Rstudio) and ObservableHQ.
- For different contexts it is possible to view a conversion to a different format: static Word/PDF, stand-alone interactive HTML, data-linked but non-editable notebook.
- Properly explained in (paywalled) "Using Jupyter for Reproducible Scientific Workflows"
- Notebooks became much friendlier especially to non-techies since, but see some basic principles shown in short video.
- There are Jupyter kernels for dozens of languages (R,Python,JavaScript seem most popular) and Wikipedia Abstract will soon make language choice 'less relevant'.
- Thinking about a very short video that even gets non-techies living in MS Word interested: below.
De facto standard for managing changes in file sets:
- Simultaneously working on the same file with multiple apps/users is no problem.
- Related files can be kept consistent within 1 change.
- Asks to comment changes for readable history to navigate.
- Many (related) workflow/project tools
- Open licenses, e.g. Creative Commons
- No logins, cookies, or custom apps needed
- Open specifications and open vocabularies to validate against.
- Next to legally open, also easy to process
- Beware: Not all advertised as open data really is. Example: House of Representatives of The Netherlands 'open data'. Scraping :-(
- Rich domain-specific metadata 'tagging' and archiving make something FINDABLE (via general and domain-specific search engines): keyword can give web address
- Persistent identifiers and (machine-readable) prerequisites for visitors make and keep something ACCESSIBLE: web address can give file. Persistent identifiers (DOI, ORCID, etc.) are not only infrastructure less vulnerable to common changes, but usually also demand standardized metadata, wich helps Findable.
- Common open file formats and vocabulaires make something INTEROPERABLE: file can give compatible data (including formats commonly referred to as content). Helps findable too.
- Licenses make data REUSABLE: allowing using input data in result data. Licenses, possibly more than one, are found in metadata, the file itself, or both.
- For maximum effect the above should be as EARLY as possible, within the primary workflow. For example: A suggestion for FAIR filesViewing
- Giving people freedom to pick their methods of interaction.
- Devices are different, people and their preferences are different, circumstances are different and all interact and keep changing.
- Laws demand certain levels of accessibility, also to minimize limitations brought by handicaps.
- Accessibility for people (also a11y), gives (some) accessibility for their (digital) assistants too
- Being data-centric, you might have APIs to allow (custom) User Interfaces that fit productivity and creativity. It's about the result after all, speaking the same language. Of course there's efficiency in having a strong default for tools, but you're not enforcing absolutely all different people to use the same hammer for every nail, or even screw, are you?
- static/generated/interactive VISUALS consisting of objects that are intrinsically structured/layered/relatable, making it a common (often 'under the hood') format for visualizing anything expressed in some regular data format or domain-specific language.
- searchable text in any shape, filters, styling, animating, infinite sharp zoom
- part of the (open, modular and semantic) web and (specifically) composable HTML; anything in the browser and loads of apps too.
- abbreviation of Scalable Vector Graphics
- Give me a time limit up-front when you ask me about this: On invitation I've written some technical articles on how to code/create things with SVG, given some presentations, but most importantly I've brought people together on SVG and other graphical web technologies from all around the world, being the main organisor twice: University of Twente (2005) and Google HeadQuarters (2009)
Literature references, citation styles, APA, reference managers, citation/reference exchange data formats:
- When you're building on or using, the work of others, you have to mention that.
- For findability and consistency, which also helps readability, several styles for such reference/citation have been designed.
- Scientific articles must use a specific style, demanded by journals, even though most are digital-only nowadays (shift choice to read-time?).
- Generating in that style (APA, Vancouver, others) is usually done by reference managers (Zotero, Endnote, others) based on data in exchange formats (BibTeX, RIS, others).
- Before you start storing your references somewhere, make sure you can export them in common formats.
- The global network of citations between works is used to find more related work, people to cooperate with and to do impact analysis. Use DOIs and ORCIDs (unique identifiers for works and researchers) and see OpenCitations, Scopus, Web Of Science, Google Scholar and others, but also alt(ernative) metrics
Rather well-explained in https://www.youtube.com/watch?v=HelrQnm3v4g
I might translate the following dutch bit for this:
De term AI schrikt mensen af (ondoorgrondbare magie denken sommigen), ik begin vaak met te zeggen: patroonherkenning. En dat expliciete algoritmes (code tikken of genereren) en impliciete (de patroonherkenning dus) ook samen kunnen werken. Wat ik zelf een fantastisch voorbeeld vind is de dataset van handgeschreven cijfers van de Amerikaanse post. Daarover kan iedereen redeneren: Als je AI vraagt dat op te delen in 10 bakjes, waar zal het dan ongeveer in opgedeeld worden? Hoezo ongeveer? En als je om minder bakjes vraagt? En om meer? Hoe zou iemand met verstand van postcodes zo'n postsysteem kunnen verbeteren? En als die ook verstand van statistiek heeft? En wat zou je kunnen doen met gevallen waar algoritme erg onzeker over is? Wat doe je om te testen of studenten aardig met materie over weg kunnen, ipv alleen exact wat je je ze eerder hebt voorgelegd? En dan vervolgens allerlei mooie krachtige voorbeelden noemen van wat AI kan en ook hoe het al in onze dagelijkse software wordt gebruikt (volgens mij zelfs in Paint). Misschien nog XAI (eXplainable AI) aanstippen. Sowieso aanstippen dat AI fouten herhaalt die je in de data hebt, zo is er o.a. racistische AI. En AI kan aardig interpoleren, maar slecht extrapoleren.
Just let me know what you have/want
eNotebooks maybe? Let me try ...
I'll be helping on collecting/configuring data playgrounds where you can try and experience possibilities on easy to grasp subjects, with no or minimized setup and coding.
If that or anything else I mentioned here makes you want to talk with me, you'll figure out how.
On the subject of playgrounds ...
Scientific 'papers' are a narrative part in increasingly richer publications: Already data is demanded almost everywhere and some journals/platforms want eNotebooks to ease (code)review, but not too far in the future expect interactive models that anybody can turn the knobs on, helping them understand.
I do have crazy ideas though, that I write down to clear my mind. But I have hardly time to further research or implement them, but maybe you can help in some way ...
If you insist, have some:
a11y,BOM,CSS,D3,ELN,FUN,GIS,HTML,i18n,JS,K-means,LAMP,md,N3,OWL,p-value,QA,RE,SVG,TSV,UX,VRE,WWW,XR,YAML,ZZZ