Este repositório tem como objetivo demonstrar a utilização do langchain4j para a construção de aplicações de chat com uso de LLMs (Large Language Models) comerciais em conjunto com a técnica RAG (Retrieval Augmented Generation).
Ele contém a implementação da aplicação descrita no post do meu blog (link https://prbpedro.substack.com/p/geracao-de-texto-com-rags-e-bases).
Foram utilizadas as seguintes tecnologias:
- Java 21
- Gradle 8.8
- langchain4j 0.33.0
- Postgres 16.3
- Qdrant Vector Database
- Google Vertex AI - Modelos text-multilingual-embedding-002 e gemini-1.5-flash-001
- Docker e docker compose

Antes de iniciar a aplicação devemos criar os recursos necessários para a mesma através da ferramenta docker compose. Serão criadas as bases de dados postgres e Qdrant.
O arquivo docker-compose.yaml está configurado para inicializar a base de dados postgres com a estrutura de tabela necessária para armazenamento dos chats através do script sql init.sql.
Ao iniciar a execução da aplicação a mesma irá:
-
Instanciar a classe PersistentChatMemoryStore, responsável por gerenciar o armazenamento dos chats. Esta classe implementa a interface ChatMemoryStore do framework langchain4j que irá orquestrar as chamadas aos métodos implementados pela classe para gerenciar a persistência dos chats.
-
Instanciar o modelo de embedding, responsável por transformar as partes dos documentos em vetores, referenciando o modelo text-multilingual-embedding-002, disposto pelo Google Cloud Platform,através da interface EmbeddingModel e classe VertexAiEmbeddingModel do framework langchain4j
-
Instanciar o modelo de chat, responsável por interagir com a LLM comercial, referenciando o modelo gemini-1.5-flash-001, disposto pelo Google Cloud Platform,através da interface ChatLanguageModel e classe VertexAiGeminiChatModel do framework langchain4j
-
Instanciar a classe EmbeddingStore do framework langchain4j, inicializando a coleção de vetores na base de dados vetorial Qdrant, obtendo os documentos dispostos na pasta documents, vetorizando as partes dos documentos e inserindo os mesmos na base de dados vetorial. A classe DocumentIngestor utiliza classes do framework langchain4j e classes dispostas pelo cliente Java do Qdrant para ingerir os documentos. Na criação da coleção do Qdrant são utilizadas as configurações tamanho do vetor igual a 768 (conforme modelo text-multilingual-embedding-002) e métrica de cálculo de similaridade de vetores igual a Cosseno por ser a indicada para textos.
-
Instanciar a classe CompressingQueryTransformer do framework langchain4j referenciando o modelo de chat já instanciado. Esta classe será responsável por condensar uma determinada consulta junto com uma memória de chat em uma consulta concisa.
-
Instanciar a classe EmbeddingStoreContentRetriever do framework langchain4j referenciando a instância da classe EmbeddingStore e do modelo de embedding já citados. Esta classe será responsável por orquestrar as chamadas ao EmbeddingStore para obtenção de similaridades de vetores. Foram customizadas as configurações de resultados máximos igual a 2 e score mínimo igual a 0.82.
-
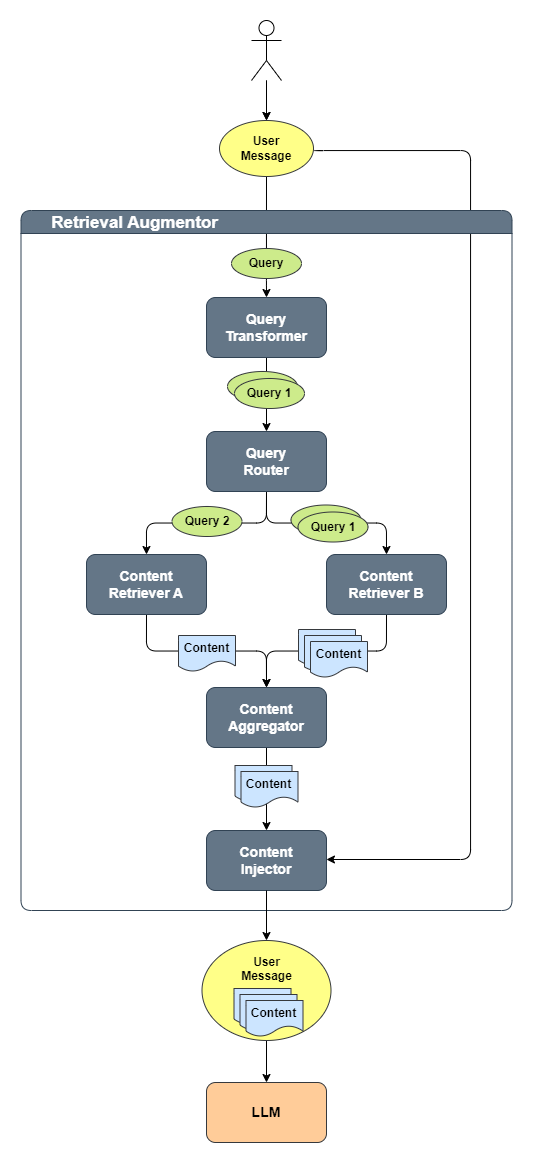
Instanciar a classe DefaultRetrievalAugmentor do framework langchain4j referenciando a instância da classe EmbeddingStore e do modelo de embedding já citados. Esta classe será responsável por orquestrar orquestrar o fluxo entre os componentes básicos QueryTransformer, QueryRouter, ContentRetriever, ContentAggregator e ContentInjector. O fluxo pode ser descrito da seguinte forma:
- Uma consulta é transformada usando um QueryTransformer em uma ou várias consultas.
- Cada consulta é roteada para o ContentRetriever apropriado usando um QueryRouter. Cada ContentRetriever recupera um ou vários conteúdos usando uma consulta.
- Todos os conteúdos recuperados por todos os ContentRetrievers usando todas as consultas são agregados (fundidos/reclassificados/filtrados/etc.) em uma lista final de conteúdos usando um ContentAggregator.
- Por último, uma lista final de conteúdos é injetada no prompt usando um ContentInjector
-
Instanciar a classe MessageWindowChatMemory do framework langchain4j referenciando a instância da classe PersistentChatMemoryStore. Esta classe será responsável por orquestrar as chamadas à PersistentChatMemoryStore para obter as mensagens históricas dos chats. A configuração do número máximo de mensagens históricas carregadas foi customizada para 5.
-
Instanciar a interface Assistant, através da classe AiServices do framework langchain4j, referenciando as instâncias das classes DefaultRetrievalAugmentor, do modelo de chat e MessageWindowChatMemory.
Após a inicialização da aplicação é exibida uma mensagem com todos os identificadores de chats armazenados na base de dados Postgres.
A aplicação então solicita que o usuário informe o id do chat para continuar um chat existente ou a entrada de um novo id para iniciar um novo chat. O id deve ser um número inteiro.
Caso seja optado por continuar um chat existente o framework langchain4j irá carregar as últimas 15 mensagens do chat e enviar os mesmos para o LLM, caso contrário irá persistir um novo chat. Após isto o framework irá solicitar a entrada de uma nova mensagem (prompt) do usuário para ser enviado ao LLM.
Após informar a mensagem o framework langchain4j irá converter a mensagem em um vetor através do modelo text-multilingual-embedding-002 e buscar na base de dados de vetores Qdrant os vetores similares.
Caso sejam encontradas similaridades o framework langchain4j irá alterar o prompt feito para incluir o texto original referente aos vetores similares, caso contrário o mesmo não irá alterar o prompt, e enviar o prompt para o LLM gemini-1.5-flash-001
Com a resposta do LLM a aplicação exibe então a mensagem enviada e a resposta da mesma.
Após isto é solicitada novamente a entrada de uma nova mensagem (prompt) do usuário para ser enviado ao LLM até que o usuário insira a mensagem sair.
Para a execução da aplicação é necessário que um projeto do Google Cloud Platform esteja preparado para receber chamadas para a API do Vertex AI.
Para ativar as APIs siga os seguintes passos dispostos no link https://cloud.google.com/vertex-ai/docs/start/cloud-environment?hl=pt-br#enable_vertexai_apis .
Após a ativação crie uma conta de serviço seguindo os passos dispostos no link https://cloud.google.com/iam/docs/service-accounts-create?hl=pt-br#iam-service-accounts-create-console .
Após isto faça download do arquivo de credenciais seguindo os passos dispostos no link https://developers.google.com/workspace/guides/create-credentials?hl=pt-br#create_credentials_for_a_service_account .
Agora será necessário configurar as seguintes variáveis de ambiente:
- GOOGLE_VERTEX_AI_PROJECT_ID: Id do projeto do Google Cloud Platform
- GOOGLE_VERTEX_AI_LOCATION: Região do Vertex AI a ser utilizada (normalmente us-central1)
- GOOGLE_APPLICATION_CREDENTIALS: Caminho para o arquivo de credenciais baixado
Faça o clone deste projeto e abra um terminal na pasta raiz do repositório clonado.
Execute o seguinte comando para iniciar os recursos através do docker compose:
docker compose up -dExecute o seguinte comando para iniciar a aplicação:
./gradlew run- https://docs.docker.com
- https://docs.docker.com/compose/
- https://cloud.google.com/?hl=pt_br
- https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/gemini?hl=pt-br
- https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/text-embeddings-api?hl=pt-br
- https://docs.langchain4j.dev/
- https://qdrant.tech/
- https://cloud.google.com/vertex-ai/generative-ai/docs/learn/overview?hl=pt-br
- https://www.postgresql.org/
- https://www.java.com/pt-BR/
- https://gradle.org/