Kafka Scaling Concepts 🛰
Table Of Contents
- Kafka Scaling and Resiliency
- Clusters and Controllers
- Replication
- Partition Leaders
- Mirroring
- Security
Kafka is a horizontally scalable messaging system which can process millions of messages per second and can handle terabytes of data.
- Topics and Partitions : Messages can be spread across multiple topics and partitions (can be stored and processed in parallel).
- Clusters of brokers : Kafka brokers can be wired together to create clusters. Brokers in a cluster share the workload of managing and serving messages.
- Multiple producers and Consumers : Kafka supports multiples producers and consumers to enable parallel publishing and consumption of data.
- Asynchronous publishing and batching : Reduce the latency as well as network traffic.
- Consumer groups : Allows consumers to share workloads and scale.
- Storage failures : Kafka supports duplication of data storage using replication and mirroring. This allows it to recover from node or data center failures.
- Broker failures : Kafka brokers work together to choose the controller and topic leaders among them. When one of them goes down, other brokers quickly work together to choose an alternate broker to execute these functions.
- Consumer failures : Features like offset tracking and partitioned reassignments help consumers to overcome failures and reprocess data without missing any messages.
A Kafka cluster is a group of Kafka brokers working together to execute Kafka functions. While a single Kafka broker provides all the essential functions, it can only scale and provide resiliency when it can share the workload with other brokers.
Each broker in a cluster has a unique broker ID. It can be set manually in broker configuration or Kafka can determine it automatically.
The unit of work sharing among Kafka brokers is a topic partition. Brokers are assigned as partition leaders to manage topic data. They are also assigned to topic replicas to maintain replicated copies of the data.
Kafka brokers in a cluster discover about each other through Zookeeper. Each broker needs a Zookeeper cluster to work with. When a broker starts, it register itself under the /brokers/ids node in Zookeeper. It also discovers about other brokers, topics and partition assignments through Zookeeper.
Zookeeper node (/brokers/ids) is an ephemeral node, so when a broker goes down it is immediately deleted (loss connection).
A cluster controller is a broker in the same cluster that assumes additional responsibilities of the controller.
When a Kafka broker starts up, it tries to register itself as the controller by creating an entry under /controller node in Zookeeper. If the entry has not been created previously, it means no other controller exists. So this broker becomes the controller.
- Monitor other brokers
- Partition leader election : If another broker goes down, the controller reassign the leader partitions and replicas owned by this broker.
- Replicas Management
All brokers in a cluster subscribe to state changes in Zookeeper for the /controller node. When the controller goes down, its heartbeat to Zookeeper is lost. So Zookeeper remove the /controller node and notifies other brokers of the change. Immediately, all other brokers try to become the controller.
The first broker that successfully manages to write the /controller node becomes the new controller. It then reads all the clusters, brokers and topics information from Zookeeper and uses it to start managing the cluster.
Clusters help Kafka provide scalability and resiliency.
Replication is a feature in Kafka that provides resiliency against individual broker failures. It works by maintaining multiple copies of individual partition logs across different brokers. The unit of replication is a single topic partition.
All messages in a partition are replicated. When a partition is created, we can specify the number of replicas needed for that partition ( replication-factor ).
A partition would always have one leader replica and zero or more follow replicas. Leader replica is the primary copy where all reads and writes happen. Follower replicas are the backups where the primary copy is replicated.
The leader replica is assigned to a leader broker. The leader broker manages all reads, writes for that partition. It also maintains the local log files. Brokers owning replica copies will subscribe to the leader broker to get new messages and update their copies.
When a topic is created, the controller takes care of distributing partitions. It first distribute the leader replicas among the brokers available. If the number of brokers is less than the number of partitions, a single broker may get multiple leader replicas for the same topic. Then it distributes the follower replica to brokers such that the replicas are not owned by brokers which are not the leader broker.
The replication factor cannot be larger than the total number of brokers available (replication factor <= number of brokers).
In the example below ( Source [1] ), leader replicas are shown green and the follower replicas are shown in blue.
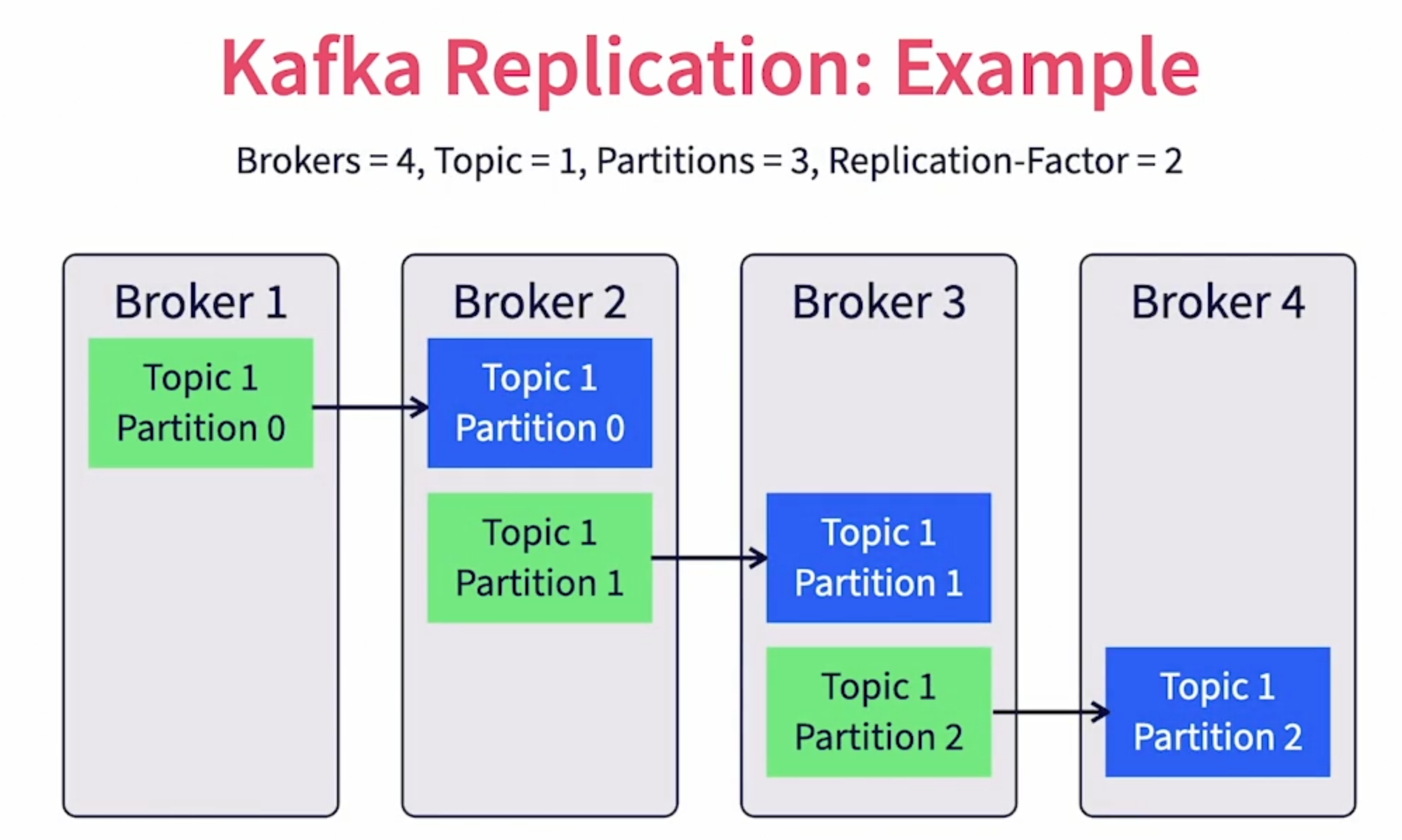
The broker instance that owns the leader replica of a partition is called the partition leader. The controller will assign partition leaders for partitions during topic creation.
A Kafka producer, when publishing a message will choose a partition for a message and will send it to the corresponding partition leader. Similarly, a Kafka consumer will work directly with the partition leader to consume messages in that partition.
The partition leader also stores partition data in it's log files.
Brokers that own the follower replicas for a partition are called follower brokers. The same broker can be the partition leader for some partitions and the follower broker for other partitions. Follower brokers subscribe with the leaders for partition data. They keep receiving new messages and will use that to update local copies of their data.
Partition leadership is evenly distributed by the controller across the brokers in a cluster.
Mirroring is an option in Kafka that allows for message redundancy across data centers (enables geo-replication). While replication works to copy data within a Kafka cluster, mirroring helps to copy data between Kafka clusters.
It provides resiliency when the entire primary cluster goes down or become unreachable.
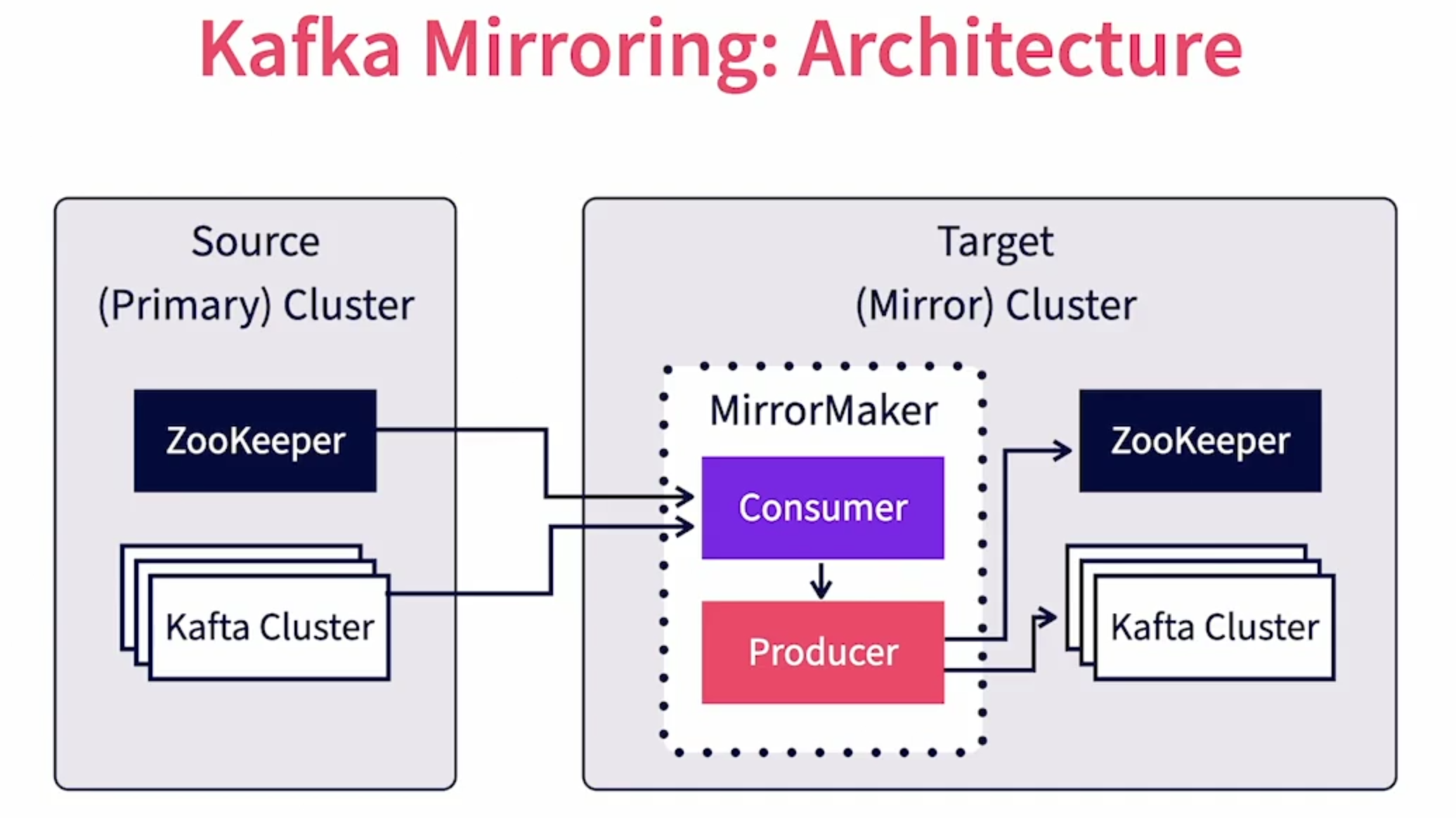
It happens between a primary and a backup Kafka cluster and is done using the MirrorMaker tool.
It will replicate all data and metadata in the primary cluster. This includes topics, topic partitions and actual message data. In addition, information about consumer groups and their offsets are also replicated. So when the primary Kafka cluster goes down, consumers can connect to the backup cluster and continue from where they left off.
While both clusters can technically be together ( image blow : Source [1] ) in the same physical location, even in the same virtual machine, the true benefit of mirroring materializes only when they are both in physically independent locations.
A MirrorMaker tool runs in the target data center. It behaves as a consumer of data for the primary cluster and a producer of data to the secondary cluster. Thus the Kafka clusters themselves don't know about mirroring.
The primary cluster treats the MirrorMaker as a regular consumer while the target cluster treats the MirrorMaker as a normal producer.
MirrorMaker would consume the messages from the source, then turn around and publish the messages to the target. It will also subscribe to the source Zookeeper to keep track of topic and consumer group changes and faithfully replicates them to the target Zookeeper.
Kafka provides :
- Client authentication using SSL/SASL. This apply to producers, consumers, other brokers and Zookeepers.
- Read-Write authentication control by individual topics and consumer groups.
- Data-inflight can be encrypted using SSL
- For at Rest encryption, Kafka does not provide an out of the box solution. It is recommended to use encrypted disks for storage.
- Other solution could be considered as described in [2].
- Expected to be used as messaging system within a trusted network where the producers and consumers are within the same trusted domain.
- It's not recommended to publicly expose Kafka through the internet without an API layer.
- Multitenancy is hard to implement in Kafka as SSL key management by individual tenants and users does not scale.
© 2024 | Lyes Sefiane ![]()
![]() All Rights Reserved | CC BY-NC-ND 4.0
All Rights Reserved | CC BY-NC-ND 4.0
