This GitHub repository contains a suggested template structure for authors who submit to JASA (either Applications and Case Studies or Theory and Methods) to include materials to reproduce analyses, visualizations, and tables.
We provide this template as a default structure that we (the JASA Associate Editors of Reproducibility) think could be useful for many projects, either as is or with modifications by authors. However, the template is intended to be helpful and is by no means required of authors. Authors should consult our reproducibility guide for details on what is required of reproducibility materials submitted with JASA revisions (not required upon initial submission).
The purpose of this template repository is to provide a mechanism for author(s) to share their materials via a Git repository, hosted on a cloud-based repository manager such as GitHub or GitLab. This provides the following advantages for author(s):
- Analyses (including code, narrative text, output, plots, etc) can be version controlled (or branched or forked) allowing original author(s) to continue to develop the analyses or other data analysts to build off the analyses. Also iterations and changes to the analysis are then available via the Git commit history.
- Materials are easily available to other researchers.
- Preparing a repository also makes it easy for the JASA Associate Editors for Reproducibility to copy the materials for a JASA article into the JASA GitHub repository where the final paper products are stored after publication (https://github.com/jasa-acs).
Author(s) can create a public GitHub repository in their own GitHub account by using this template repository. This template contains a basic skeletal structure to help authors structure their code and analyses for their JASA publication. Creating a repository with the template can be done in the following way:
Click on the "Use this template" button for this GitHub template repository. (You'll need to be signed in to a GitHub account in order to see the button.)
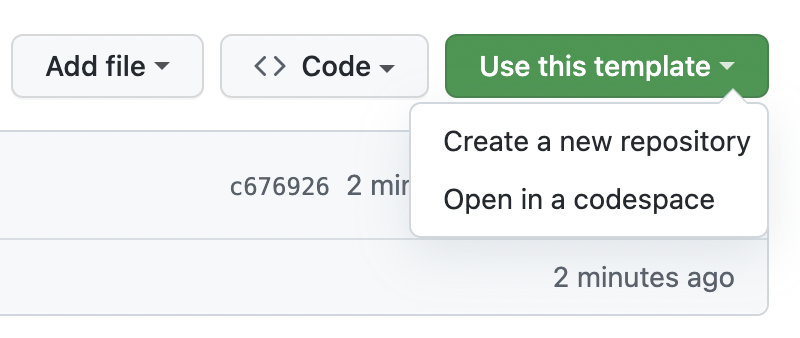
From there, author(s) can follow these instructions. However do not optionally select "Include all branches" as you do not need this for your own projects.
The author(s) can then directly edit (or replace) the manuscript template files in their own GitHub repository. Author(s) can also add their own data, code, and other files as needed.
For guidance on getting started with git, we recommend the Happy with git r tutorials.
Importantly, the authors should provide an overview of how to carry
out the analyses presented in their manuscript in the README.md of their
repository, replacing the content in this file. This overview would
generally refer to scripts/code files that execute the analyses and are
placed either in the main directory or the /code subdirectory. The
Workflow section of the ACC form should refer to this README.md as
containing the instructions for how to reproduce the analyses.
Author(s) use git commit to track changes over time and use git push
to push changes to a repository on the author(s) personal GitHub
account.
Author(s) submit a link to their GitHub repository as part of the JASA Reproducibility review process, required upon submission of an invited revision.
JASA Associate Editors for Reproducibility will review the materials in the GitHub repository of the authors and submit a reproducibility review as part of the standard JASA review process. Authors have the opportunity to respond to the review by making changes and pushing their changes to their personal GitHub repository.
Once the manuscript is accepted, the materials in the author(s) personal GitHub repository will be copied to the JASA repository.
This template provides a suggested file structure for a JASA submission, but authors are free to modify this structure.
The suggested components are as follows. Directories in the submission may have subdirectories to further organize the materials.
- A
README.mdfile - This file gives a short description of the paper and an overview of how to carry out the analyses presented in their manuscript. - A
manuscriptdirectory - This directory will generally hold the source files (often LaTeX or Rmd) for the manuscript and any files directly related to the generation of the manuscript, including figure files. - A
datadirectory - This directory will generally hold the real data files (or facsimile versions of them in place of confidential data) and simulated data files. Seedata/README.mdfor more details. - A
codedirectory - This directory will generally hold source code files that contain the core code to implement the method and various utility/auxiliary functions. - An
outputdirectory - This directory will generally hold objects derived from computations, including results of simulations or real data analyses. Seeoutput/README.mdfor more details.
Submissions may include the use of reproducible environments capturing
state of a machine generating manuscript artifacts and even the
manuscript itself. Here we discuss two types of reproducible
environments and their use. Both virtual and package environments may be
put in the code directory.
Package environments capture the set of packages used by a programming
language needed to generate output. The R programming language has
renv, switchr and others to accomplish this, Python has venv,
conda and others, and Julia has native support (through the Pkg
package). When submitting these types of environments, the following are
suggested.
- Clearly indicate (in the overall
README.md) the language(s) used (including version) and the package environment tool used (e.g.,renv,conda). - Use a single package environment for all reproducible content.
- Prefer packages from package archives (CRAN, Bioconductor, RForge.net for example).
- If you use packages from a code repository (GitHub, GitLab, etc.) then use a release version if possible, or indicate the commit used. You could also consider forking the repository and providing a release.
Virtual environments such as Docker and Singlarity capture the entire computing environment in which computations were performed. In general, they are a more robust solution, capable of taking a “snapshot” of a machine, including any system-level utilities and external libraries needed to perform your computations. They have the advantage that reproducing materials means running the virtual environment, rather than recreating the programming language environment. If using a virtual environment, we ask that you provide a definition file (e.g., a Dockerfile) or (perhaps better) a link to an image in a standard online registry, such as DockerHub.
Gentleman, Robert, and Duncan Temple Lang. “Statistical Analyses and Reproducible Research.” (2004).
Gentleman, Robert. “Reproducible research: a bioinformatics case study.” Statistical applications in genetics and molecular biology 4.1 (2005).
Marwick, Ben, and Bryan, Jennifer, and Attali, Dean, and Hollister, Jeffrey W. rrrpkg Github Page.