Lightweight PyTorch implementation of QuartzNet (https://arxiv.org/pdf/1910.10261.pdf).
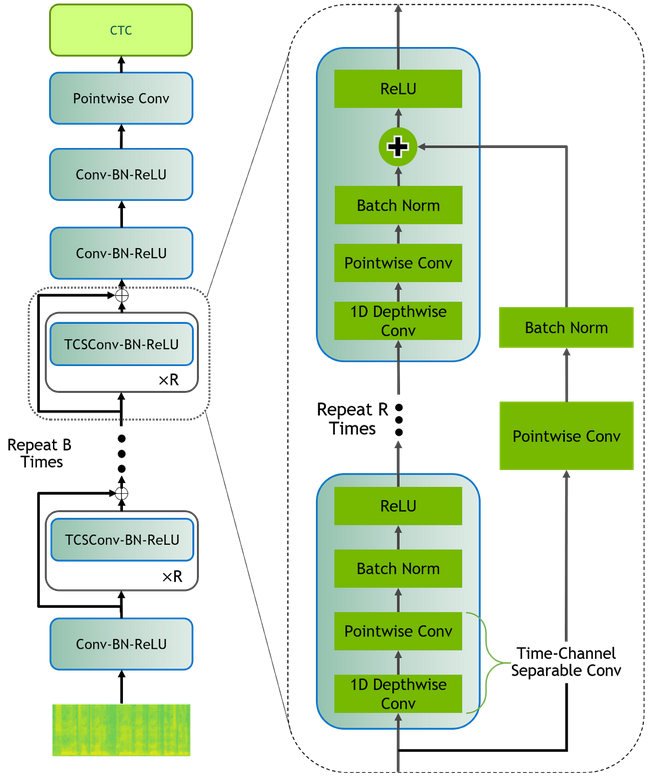
- Allows to choose between three different model sizes:
,
,
. For details refer to the article.
- Easily customisable
- Allows training using a cpu, single or multiple
.
- Suitable for training in
and
spot instances as it allows to continue training after a break-down.
- Installation
- Default training
- Train custom data 📚
- Hyperparameters 📚
- Things that are different compared to the article
- Clone the repository
git clone https://github.com/ivankunyankin/quartznet-asr.git
cd quartznet-asr
- Create an environment and install the dependencies
python3 -m venv env
source env/bin/activate
pip3 install -r requirements.txt
This guide shows training QuartzNet5x5 model using a part of LibriTTS dataset.
- Download the data by running the following:
assets/data.sh
If you encounter an error, give the execute permission to your script and rerun the above command: chmod +x assets/data.sh
The script will download and unzip the following subsets of LibriTTS: train-clean-360 (for training), dev-clean (for validation), test-clean (for testing)
Warning. This subset of the dataset requires around 30 Gb of storage space.
- Run the following to start training:
python3 train.py
Add --from_checkpoint flag to continue training from a checkpoint.
python3 test.py
The code will test the trained model on test-clean subset of LibriTTS.
It will print the resulting WER (word error rate) and CTC loss values as well as save intermediate logs in the logs directory
tensorboard --logdir logs
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change
I found inspiration for TextTransform class and Greedy decoder in this post.