The “Congo basin eco-climatological data recovery and valorisation (COBECORE, contract BR/175/A3/COBECORE)” project made the static analog archives of the Institut National pour l’Etude Agronomique du Congo belge (INEAC) digitally accessible. Although a part of the climate data was transcribed using citizen science in the Jungle Weather programme (~350K values), the vast majority of the data remains digitized but not transcribed (~7M values for the main climate variables alone, i.e. temperature, rainfall). Within this context machine learning, and optical character recognition in particular, promises to bring a workable solution.
Within the context of COBECORE handwritten text recognition happens within the very specific context of tabulated data. Given the context of this problem, i.e. snippets of tables with numbers, it can be approached solving a captcha. With the "noise" of table cell boundary lines and other smudges on old paper this comparison is more than fitting.
Generally, solving captcha problems can be done using a CRNN + CTC loss setup. The Keras introduction into the captcha problem provides the baseline, to be expanded to handwritten text in another demo - accounting for varying input image sizes. In a quick test I used the vanilla Keras handwritten text recognition code, adapted to the COBECORE climate data formatting (separate labels and images, some cropping) to learn to recognize the value of climate variables.
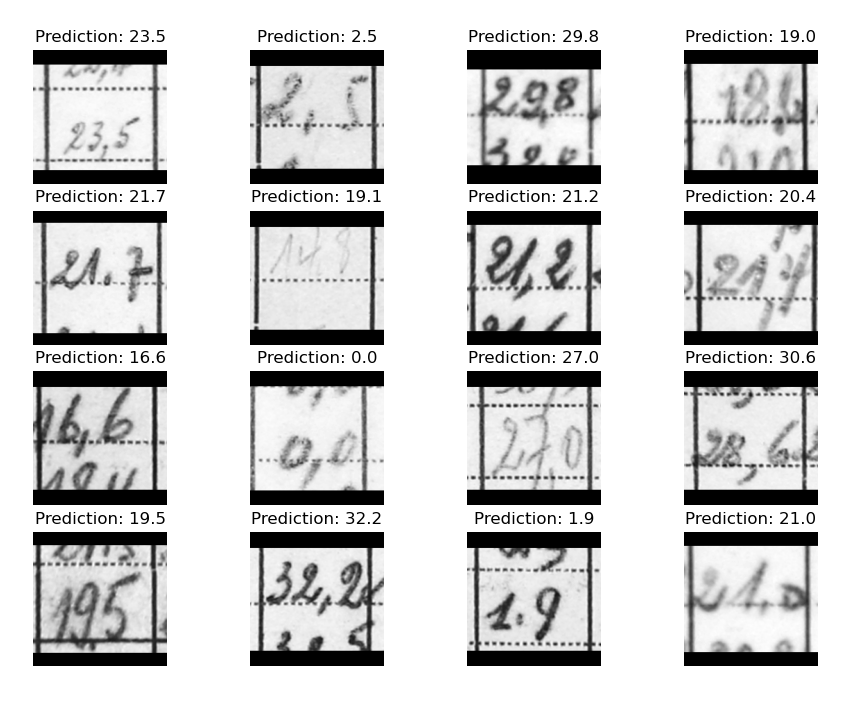
A simple test on a subset of the data (~10K images, instead of the total dataset of ~350K) shows reasonable performance (see image below). Given these results the exercise should be expanded to the full dataset, including many more writing styles to increase model robustness.
- formalize the code (potentially Keras in R for consistency)
- formalize accuracy metrics (evaluation)
- expand training data and matching testing
- generate true out of sample data (extracted from novel tables)
- consider image augmentation and contrast boosting options to increase accuracy
- other model setups simpleHTR
- layout detection instead of template matching
- ...
Install docker per usual and add the user to the docker user group.
sudo usermod -aG docker $USER
Install the Nvidia container toolkit.
sudo apt install nvidia-container-toolkit
Configure the toolkit to recognize the GPUs in docker.
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
Run grab the default image to built upon, this should fire up a console in which the GPUs should be active.
docker run --gpus all -it --rm nvcr.io/nvidia/tensorflow:23.09-tf2-py3
Mounting external files can be done using:
docker run --gpus all -it --rm -v $(pwd):/current_project/ nvcr.io/nvidia/tensorflow:23.09-tf2-py3
Which will set /current_project/ as the mount point for the current (present) working directory (pwd).
A docker file is included which builds a custom environment, using the tensorflow setup as a basis, adding Jupyter notebooks for easier interaction with the docker container and the option to visualize things (the other option is forwarding X sessions which is security wise probably iffy).