- Tensörler
- Linear Regression with TensorFlow
- Recurrent Neural Networks(RNN)
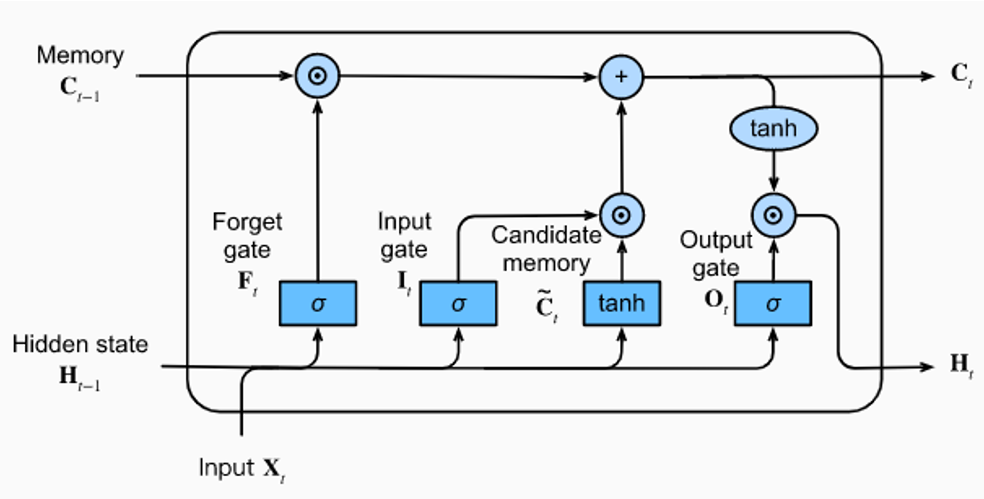
- Long short-term memory(LSTM)
- Restricted Boltzmann Machines(RBM)
- Autoencoders
💓 TensorFlow, tf.Tensor nesneleri olarak temsil edilen çok boyutlu diziler veya tensörler üzerinde çalışır. İşte üç boyutlu bir tensor 👉:
import tensorflow as tf
x = tf.constant([[1., 2., 3.],
[4., 5., 6.],
[8.,9.,10.]],name = 'constant_x')
constant_x adında bir tf.Operation oluşturur ve bir tensor döndürür.
print(x.shape)
print(x.dtype)
Tensor.shape : her bir ekseni boyunca tensörün boyutunu size söyler. 👉 yukarıdaki tensor için (3,3) Tensor.dtype : tensördeki tüm öğelerin türünü söyler. 👉 yukarıdaki tensor için <dtype: 'float32'>
TensorFlow, tensörler üzerinde standart matematiksel işlemlerin yanı sıra makine öğrenimi için özelleştirilmiş birçok işlemi uygular.
tf.matMul(): işlevi, A * B olmak üzere iki matrisin iç çarpımını hesaplamak için kullanılır.
'@' sembolü Matris çarpımı olarak kullanılır ve tf.matmul()'a eşittir.:woman_technologist:
x @ tf.transpose(x)
----------------------
c = tf.matmul(x,tf.transpose(x))
Bu iki ifade aynı sonucu verir.
tf.add(): iki tf.Tensor nesnesinin birbirine eklenmesi
tf.function, işlev için bir TensorFlow statik yürütme(static execution graph) grafiği oluşturmak üzere TensorFlow Autograph'ı kullanır.
@tf.function
def add(a,b):
c = tf.add(a, b)
#c = a + b is also a way to define the sum of the terms
print(c)
return c
@tf.function
def mathmul(a,b):
return tf.matmul(a, b)
TensorFlow kodu iki modda çalıştırılabilir: eager mode ve graph mode. Eager modu, kod çalıştırmanın standart, etkileşimli yoludur: bir işlevi her çağırdığınızda yürütülür.Bununla birlikte, grafik modu(graph mode) biraz farklıdır. Grafik modunda, işlevi yürütmeden önce TensorFlow, işlevi yürütmek için gerekli işlemleri içeren bir veri yapısı olan bir hesaplama grafiği(computation graph) oluşturur.
TensorFlow kodunun yürütülmesine ve satır satır değerlendirilmesine olanak sağlar. TensorFlow 2.x ile Eager Execution varsayılan olarak etkindir. Bunu ağağıdaki kod bloğunu çalıştırarak görebiliriz.
tf.executing_eagerly()
True değerini alırız. Disable hale getirmek için ise:
from tensorflow.python.framework.ops import disable_eager_execution
disable_eager_execution()
Ardından tekrar bu kod parçasını çalıştırdığımızda:
tf.executing_eagerly()
False değerini alırız.Artık bu disable(etkisiz) anlamına gelir.
Şu örneğe bakarsak: 👉
a = tf.constant(np.array[1. , 2. , 3. ])
b = tf.constant(np.array[4. , 5. , 6. ])
a ve b tensörünü oluşturuyoruz
c = tf.tensordot(a,b,1)
dot product(iç çarpım) hesaplar ve sonucu c'ye atarız. Ancak şu ana kadar herhangi bir hesaplama yapılmadı. c yalnızca henüz bir değeri olmayan execution graph(yürütme grafiği) temsil eder.
📙 Session, Tensorflow 2.x'te tf.compat.v1.Session() aracılığıyla erişilebilir.
session = tf.compat.v1.Session()
output = session.run(c)
session.close()
'session' bir kez yürütüldüğünde, bir hesaplama gerçekleşir ve c'ye bir değer atanır. Bu ara sonuçlara erişmeyi zorlaştırdığı için hata ayıklamayı(debug) zorlaştırır.
a = tf.constant(np.array[1. , 2. , 3. ])
b = tf.constant(np.array[4. , 5. , 6. ])
c = tf.tersordot(a,b,1)
output = c.numpy()
Eager execution etkinleştirildiğinde, kod satır satır yürütülür ve ara sonuçlar anında kullanılabilir. Tensorflow kodunun sıradan python kodu gibi görünmesini sağlar.

Sıfır boyut(zero dimension) tek bir nesne/öge, skaler bir değer olarak görülebilir. Bir boyut(one dimension) ise bir çizgi veya bir vektör olarak görülebilir. 2-boyut(2-dimesion) bir yüzey gibi düşünebiliriz. Matrisleri buna örnek olarak verebiliriz. 3-boyutta ise tensorleri örnek verebiliz.
Scalar = tf.constant(8)
Vector = tf.constant([2,6,3])
Matrix = tf.constant([[1,2,3],[4,5,6],[7,8,9]])
Tensor = tf.constant( [ [[1,2,3],[2,3,1],[3,4,5]] , [[4,5,6],[5,8,7],[6,7,8]] , [[7,8,9],[8,9,10],[9,10,11]] ] )

Görüntüleri düşündüğümüzde genişliğe ve yüksekliğe sahip olduklarını biliriz. Görüntülerin renklere de sahip olduğunu düşünürsek bize tek boyut yeterli olmayacaktır.Görüntüler renk kanallarıyla gösterilir. RGB, Red (kırmızı):red_circle:, Green (Yeşil):green_circle: ve Blue (Maviden):large_blue_circle: oluşur.
tf.Variable(): Değişkenler tf.Variable sınıfı aracılığıyla oluşturulur ve izlenir. Bir tf.Variable , değeri değiştirilebilen bir tensörü temsil eder. Belirli işlemler, bu tensörün değerlerini okumanıza ve değiştirmenize izin verir.
df = pd.read_csv("FuelConsumptionCo2.csv")
Doğrusal regresyonu(Linear Regression) kullandığımızı varsayalım.
train_x = np.asanyarray(df[['ENGINESIZE']])
train_y = np.asanyarray(df[['CO2EMISSIONS']])
restgele bir şekilde a ve b değişkenlerini başlatıyoruz.
a = tf.Variable(20.0)
b = tf.Variable(30.2)
lineer fonksiyonu tanımlıyoruz. Y = aX + b 👉 Burada Y bağımlı değiken, a 'eğim(slope)' veya 'gradient', X bağımsiz değişken ve b 'intercept' olarak adlandırılır.
def h(x):
y = a*x + b
return y
Loss Fonksiyonunu tanımlıyoruz. Tahmin edilen değerler ile hedef değerler(sahip olduğumuz değerler) arasındaki farkın kare hatasını(squared error) minimize etmeyi hedefliyoruz.
def loss_object(y,train_y) :
return tf.reduce_mean(tf.square(y - train_y))
Geriye yayılım(backpropagation) ile parametreler güncellenmektedir. Gradientleri hesaplamak için GradientTape kullanıyoruz.
learning_rate = 0.01
train_data = []
loss_values =[]
a_values = []
b_values = []
training_epochs = 200
for epoch in range(training_epochs):
with tf.GradientTape() as tape:
y_predicted = h(train_x)
loss_value = loss_object(train_y,y_predicted)
loss_values.append(loss_value)
# get gradients
gradients = tape.gradient(loss_value, [b,a])
# compute and adjust weights
a_values.append(a.numpy())
b_values.append(b.numpy())
b.assign_sub(gradients[0]*learning_rate)
a.assign_sub(gradients[1]*learning_rate)
if epoch % 5 == 0:
train_data.append([a.numpy(), b.numpy()])
Recurrent Neural Networks(RNN)'de kısaca bir sonraki katmanın çıktısı(output) bir sonraki girdiye(input)' eklenir ve aynı katmana geri beslenir.
RNN'lerde girdiler birbiri ile ilişkilidir.
RNN'ler önceki girdileri hatırlar ve her girdi için ilişki kurar.
Belirli bir noktaya kadar yapılan analizi hatırlayabilir. RNN'nin hafızası olarak düşünebiliriz.
Bir veri kümesindeki noktalar, veri kümesindeki diğer noktalara bağımlı olduğunda, verilerin sıralı veriler(Sequential data) olduğu söylenir.
RNN sequential data'yı işleyebilen bir mekanizmaya sahiptir.

LSTM üç lojistik yapıdan oluşur.
LSTM yapısı içerisindeki kapılar(gate) neyin hatırlanacağını, neyin unutulacağını belirler. Yani gelen girdi önemsizse unutulur, Önemliyse bir sonraki aşamaya aktarılır.
Forget gate(unutma kapısı): Hangi bilginin tutulacağını veya unutalacağına karar verir.
Input gate(girdi kapısı) Cell state'i güncellemek için kullanılır.
Output gate(Çıktı kapısı) Bir sonraki katmana gönderilecek değere karar verir.
Restricted Boltzmann Machines(RBM) yalnızca iki katmandan oluşan unsupervised(denetimsiz) sinir ağlarıdır. Girdiyi(input) yeniden yapılandırarak verideki kalıpları bulmak için kullanılır. RBM'in birinci katmanı giriş(input) katmanı ikinci katmanı ise gizli(hidden) katmanıdır.
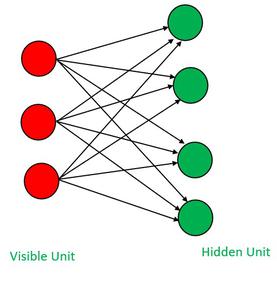
🌟 "restricted" olarak adlandırılmasının nedeni ise aynı katmandaki nöronların birbirine bağlı olmaması.
-
RBM'in ilk adımı forward aşamasıdır. Bu aşamada girişin bir image olduğunu düşünürsek giriş görüntümüz binary değerlere dönüştürülür ve değerler ağırlıklar(weight) çarpılıp bias değerleri ile toplanarak ağ beslenir.Daha sonra sonuç aktivasyon fonksiyonuna verilir. Oluşan olasılık dağılımından bir örnek(sample) alınır ve hangi nöronların aktifleşip aktifleşmediği bulunur.
-
Backward aşamasında, gizli(hidden) katmanlardaki aktif nöronlar girdinin yeniden yapılandırıldığı(reconstructed) input diğer bir değişle visible(görünür) katmana geri gönderilir.Bu adımda geriye doğru iletilen veriler aynı zamanda ileri yayılımda(forward) kullanılan aynı weight(ağırlık) ve bias ile işlemden geçirilir. Backward orijinal girdinin olasılık dağılımı hakkında tahminler yapmakla ilgilidir.
-
Bu aşamadan sonra RBM hatayı(error) hesaplar ve bunu en aza indirmek için ağırlık(weight) ve bias güncellenir. Hatayı 1.adım ile bir sonraki adım arasındaki kare farkının toplamı olarak hesaplar. 3. adım hata(error) yeterince küçülene kadar devam eder.
💡 RBM deterministik(deterministic) bir yaklaşım yerine skokastik(stochastic) bir yaklaşım kullanmaları bakımından Autoencoders'lerden farklıdır.
Autoencoder bir unsupervised(denetimsiz) öğrenme algoritması türüdür. Verilen inputu yeniden oluşturabilmek için önemli özellikleri çıkaran bir sinir ağıdır. Encoder ve decoder olarak ikiye ayrılır.RMB'ler de bir tür autoencoder'die. RMB ve autoencoder arasındaki fark ise::point_right:
RBM yalnızca iki katmandan oluşan autoencoderlerdir. Bununla beraber autoencoders giriş katmanından ve birkaç gizli(hidden) katmandan oluşan sığ sinir ağlarıdır.
Bir diğer yandan autoencoders stokastik(stochastic) yaklaşım yerine deterministik(deterministic) yaklaşımı tercih eder.