
sanatkar.ai, çeşitli yazılı sanat dallarında (şu anlık şarkı, şiir ve tiyatro) doğal dil üretmek amacıyla karakter tabanlı tahmin işlemleri gerçekleştiren çok katmanlı LSTM bazlı RNN modelleri kullanan bir Türkçe doğal dil işleme uygulamasıdır.
RNN Modelleri
Kullanılan Veri Setleri
Gereklilikler
Web Sitesi
Örnek Çıktılar
Geliştirmeye Yönelik Öneriler
Katkıda Bulunmak
Doğal dil üretimi gerçekleştiren çok katmanlı LSTM bazlı RNN modelleri çıktıyı oluştururken 'Bir karakter veya bir karakter dizisi verildiğinde, onları takip edecek en olası karakter nedir?' sorusuna yanıt bulmak amacıyla karakter temelli tahmin işlemleri gerçekleştirmektedir.
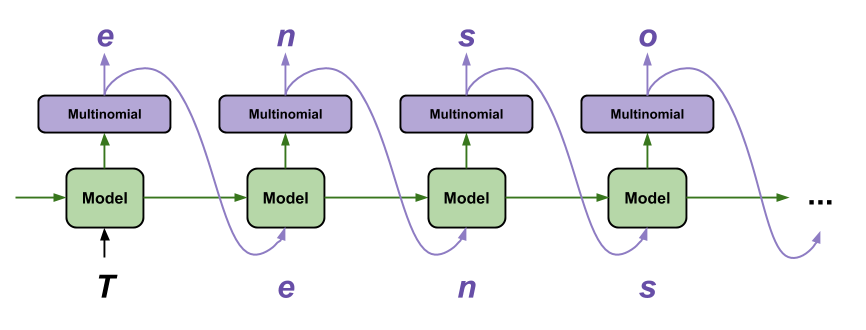
Modellerin Geliştirilmesi*
Detaylı bilgi için creating_text_generators.ipynb dosyasına göz atabilirsiniz.
| Model | Eğitim Veri Seti | Epoch | Doğruluk Oranı | Loss Değeri |
|---|---|---|---|---|
| Kadın Karakter Tirad | kadin_tirad_veri_seti.txt | 125 | 0.9846 | 0.0478 |
| Garip Şiiri | garip-siiri-veri-seti.txt | 75 | 0.9839 | 0.0572 |
| Erkek Karakter Tirad | erkek_tirad_veri_seti.txt | 125 | 0.9834 | 0.0531 |
| Cumhuriyet Dönemi Saf Şiir | cumhuriyet-donemi-saf-siir-veri-seti.txt | 100 | 0.9800 | 0.0591 |
| Milli Edebiyat | milli_edebiyat_veri-seti.txt | 60 | 0.9780 | 0.0732 |
| Rock | rock_veri_seti.txt | 30 | 0.9666 | 0.1403 |
| Pop | pop_veri_seti.txt | 30 | 0.8330 | 0.5169 |
| Rap | rap_veri_seti.txt | 15 | 0.5801 | 1.3477 |
Kullanılan Veri Setleri*
sanatkar.ai üç farklı sanat dalının sekiz farklı alt dalında doğal dil üretmektedir. Her bir alt dala ait kapsamlı ana veri seti bulunmaktayken ana veri setini oluşturan tekil veri setleri de mevcuttur.
1 - Şarkı Sözü Veri Setleri
- Rap Veri Seti --> 270703 satır, 8.99 mb.
- Pop Veri Seti --> 78161 satır, 2.01 mb.
- Rock Veri Seti --> 23326 satır, 604 kb.
2 - Şiir Veri Setleri
- Milli Edebiyat Veri Seti --> 14366 satır, 640 kb.
- Cumhuriyet Dönemi Saf Şiir Veri Seti --> 9007 satır, 312 kb.
- Garip Şiiri Veri Seti --> 3712 satır, 116 kb.
3 - Tiyatro Tiradı Veri Setleri
- Erkek Karakterlerin Tiradları Veri Seti --> 112 kb.
- Kadın Karakterlerin Tiradları Veri Seti --> 96 kb.
Şarkı Sözü Veri Setlerinin Oluşturulması*
Şarkı sözü veri setleri Genius API ile lyricsgenius kütüphanesi kullanılarak elde edilmiş, devamında data_cleaning_for_songs.ipynb dosyasındaki işlemler ile veri seti temizliği gerçekleştirilmiştir.
Şiir Veri Setlerinin Oluşturulması*
Şiir veri setleri selenium kütüphanesi ile antoloji.com'da ilgili şairlerin şiirlerinin kazınmasıyla ve farklı şairlerin şiirlerinin manuel olarak aynı metin dosyasına taşınmasıyla elde edilmiştir.
Tiyatro tiradı veri setleri Ankara Akademi Sanat'ın açık arşivindeki tiradların manuel olarak aynı metin dosyasına taşınmasıyla elde edilmiştir.
'pip install -r requirements_for_model_creation.txt' ve 'pip install -r requirements_for_website.txt' komutları ile yerel cihazınıza gerekli kütüphanelerin kurulumunu gerçekleştirebilirsiniz.
Model Oluşturmak İçin Gereklilikler*
tensorflow==2.6.0
nltk==3.6.2
urllib3==1.26.6
numpy==1.21.2
Web Sitesi İçin Gereklilikler*
tensorflow==2.6.0
numpy==1.21.2
Flask==2.0.1
Flask-SQLAlchemy==2.5.1
Web Sitesi*
Doğal dil üretimi gerçekleştiren modellerin kullanıcı kullanımına açıldığı web sitesi backend'de Python yazılım dilinin Flask kütüphanesini; frontend'de HTML, CSS işaretleme dilleri ile JavaScript'in Jquery kütüphanesini kullanmaktadır.
Bir karşılama sayfası ve dört ek sayfadan oluşan web sitesinin olabildiğince sade ve kullanıcı dostu tasarlanması hedeflenmiştir. Renk paleti olarak sanatkar.ai logosunda yer alan üç temel renk (eflatuni mavi #5e17eb, koyu nane yeşili #39c466 ve dönüşümlü olarak siyah ve beyaz) kullanılmıştır.
RNN modellerinin doğal dil üretim işlemlerini ve veritabanı iletişimlerini gerçekleştiren backend bu işlemler için TensorFlow ve SQLAlchemy kütüphanelerinden faydalanmaktadır.
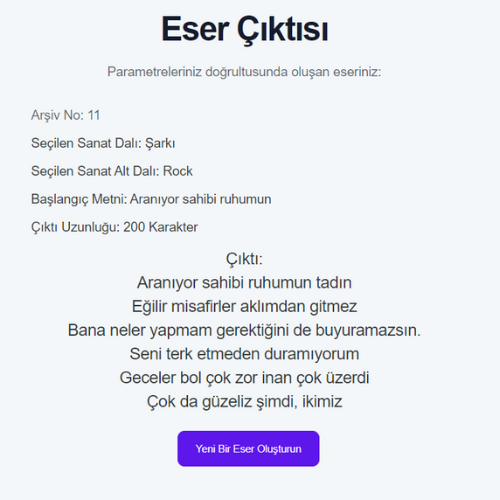
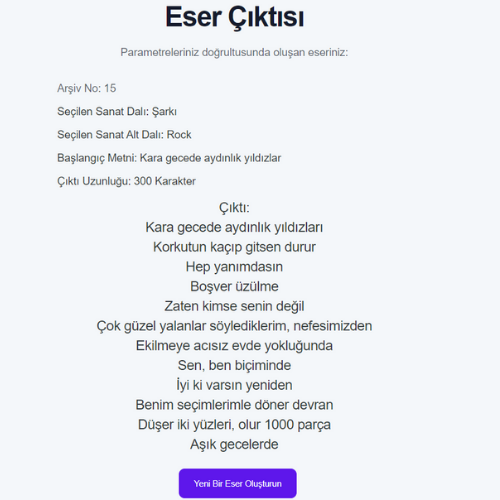
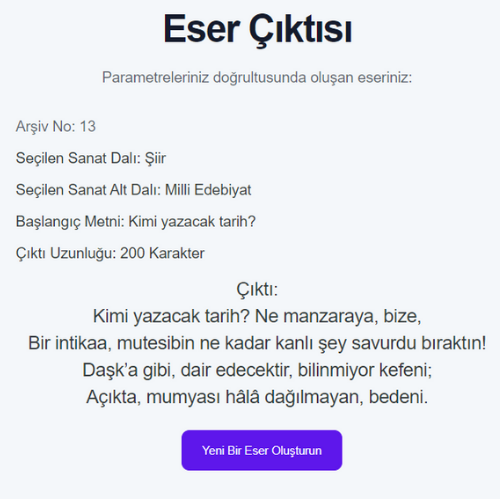
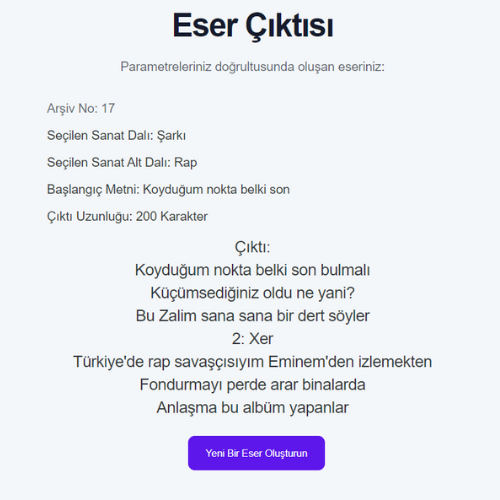
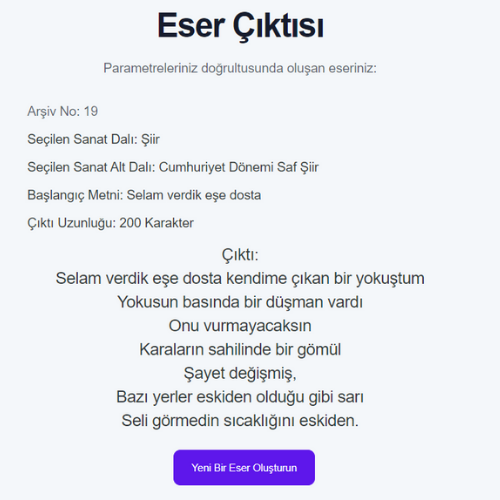
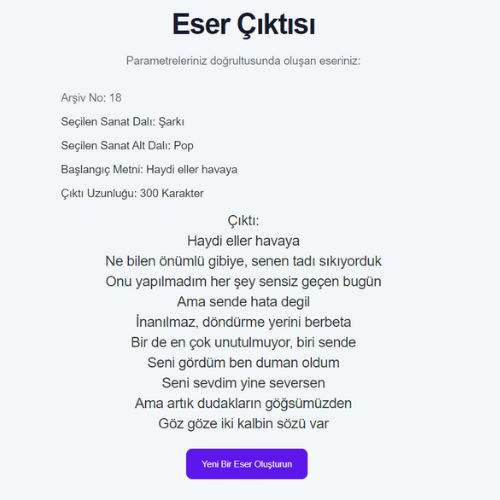
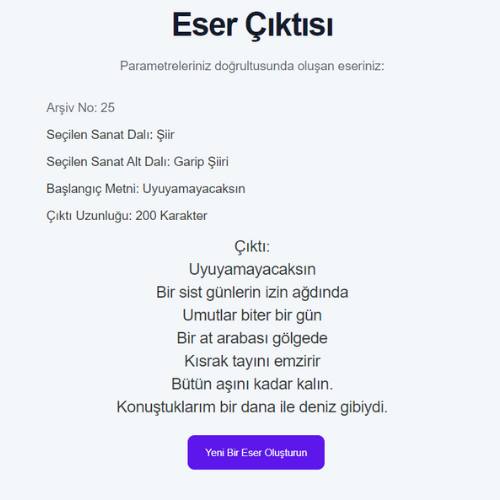
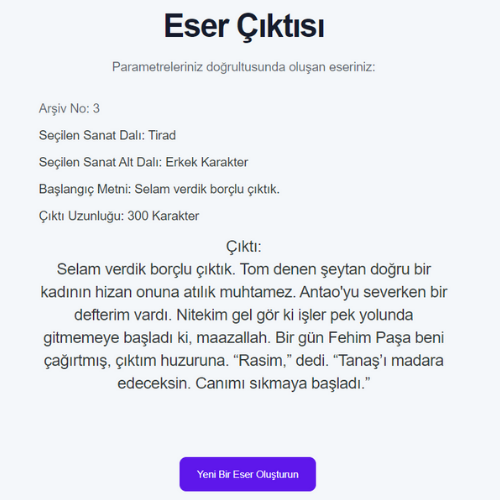
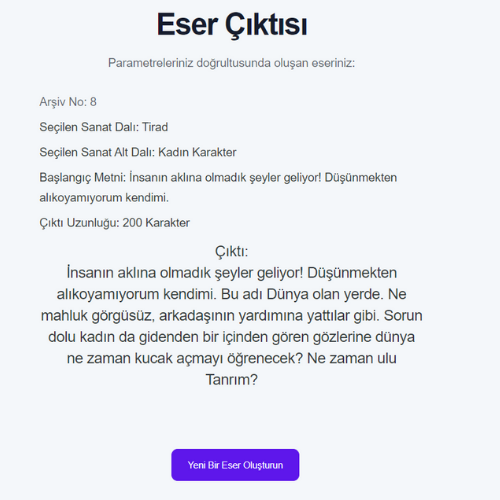
- RNN modellerinin eğitiminde kullanılan veri setlerinin boyutları ile eğitilen modelin doğruluk oranı arasında ters, loss değeri arasında doğru orantı gözlemlenmiştir.
- Şarkı veri setlerinde bulunan yabancı dildeki sözler veri setinin çok küçük bir yüzdesini oluştursa bile nadir de olsa üretilen çıktılarda yabancı dillerden sözcüklere denk gelinebilmektedir.
- Doğruluk oranı geliştirilen modeller arasında en yüksek olan kadın karakter tiradı üreten modelin ürettiği çıktılarda dil bilgisi hataları ve anlamsal kopukluklar gözlemlenirken doğruluk oranı geliştirilen modeller arasında en düşük olan rap şarkı sözü üreten modelin ürettiği çıktılarda dil bilgisi hataları ve anlamsal kopukluklar çok daha nadir gözlemlenmiştir. Bu nedenle doğruluk oranı modelin başarısını değerlendirmek için birincil kriter olarak görülmemektedir.
- Birinci ve üçüncü bulgular göz önüne alındığında kullanılan veri setinin boyutu arttıkça modelin doğruluk oranı azalsa da ürettiği metin tutarlı ve hatasız olmaktadır.
-
Yeni Modellerin Geliştirilmesine Dair Öneriler
- Oluşturulacak yeni veri setleri ile bir tiyatro senaryosu içerisinde yer alan kurgu ve diyalog gibi elementlerin üretimini sağlayan yeni modeller geliştirilebilir. Geliştirilen bu modeller tirad üretimi gerçekleştiren model ile birlikte kullanılarak bütüncül tiyatro oyunları oluşturulabilir.
-
Veri Setlerine Dair Öneriler
- Kullanılan veri setleri genişletilebilir.
- Şarkı sözü veri setleri Genius API aracılığı ile güncel veri setlerinde yer almayan sanatçıların eserleri çekilerek genişletilebilir.
- Tiyatro tiradı veri setlerinin genişletilebilmesi için şehir belediyeleri ile iletişime geçilip paylaşıma uygun görülen tiyatro oyunlarındaki tiradlar veri setine eklenebilir.
- Şarkı sözü veri setlerinde kullanılan API'dan dolayı oluşan, şarkı sözü dışında kalan açıklama metinleri (örneğin Nakarat, Giriş, Chorus bilgileri) temizlenebilir.
- Şarkı sözü veri setlerinde Türkçe hariç dillerin (Pop ve Rock veri setlerinde ağırlıklı olarak İngilizce; Rap veri setinde ağırlıklı olarak Almanca ve İngilizce) kullanıldığı dizeler temizlenebilir.
- Şiir veri setlerinde nadiren de olsa karşılaşılan Türkçe karakter bozuklukları düzeltilebilir.
- Tirad veri setlerinde sıklıkla kullanılan noktalama işaretleri arasında var olan hatalar (örneğin noktalama işaretinden önce boşluk bırakılması) düzeltilebilir.
- Kullanılan veri setleri genişletilebilir.
-
RNN Modellerine Dair Öneriler
- Modellerin her biri özelleştirilmiş eğitimden geçirilebilir. Bu aşamada kullanılan eğitim, gerçekleşen kötü tahminlerin modellere geri gitmesini engellemekte dolayısıyla modellerin hatalarından öğrenmesine engel olmaktadır.
- Modellerin açık döngü çıktısını stabilize etmek için curriculum learning uygulanabilir.
-
Web Sitesine Dair Öneriler
- Modelin veri setine ne derece yakınlıkta çıktı vereceğini belirleyen temperature parametresi kullanıcıdan girdi olarak alınabilir.
- Modellerin ürettiği çıktıların kaydedildiği arşiv sayfasına çeşitli filtreleme özellikleri (örneğin sanat dalı, sanat alt dalı, çıktı uzunluğu) getirilebilir.
- Kullanıcıların beğenisi göz önünde bulundurulacak şekilde çıktıları beğenme ve beğenmeme opsiyonları getirilebilir ve bu opsiyonlar filtreleme özellikleri arasında yer alabilir.
- Örnek Çıktılar başlığında bulunan çıktılara ek olarak elde edilen çıktılarda üretilen tiradların, şarkı sözlerine ve şiirlere kıyasla daha fazla anlamsız ve kopuk cümle barındırdığı gözlemlenmiştir. Bu nedenle tirad veri setleri, metin işleme işlemlerine ve temizliğe ihtiyaç duymaktadır.
Çalışmayı denerken karşılaştığınız bir sorunu issue açarak anlatabilir, yavaş çalışacağını düşündüğünüz bir kod parçacığını optimize edip pull request atabilir, çalışmayı iyileştireceğini ve ileri taşıyacağını düşündüğünüz değişikliklerde bulunabilirsiniz. Teşekkürler 😊
- Geliştirici ekip: Yayla
- Yapay zekâ ve backend geliştiricisi: Arda Uzunoğlu
- Frontend geliştiricisi: Ege Dinnen
Katkıda bulunmak istiyorsanız CONTRIBUTING.md dosyasını inceleyip kolları sıvayabilirsiniz!