MUST CHECKOUT LAST BELOWS POINT IT MAY BE VERY USEFUL FOR YOU.............
This repository provides a PyTorch implementation of SAGAN. Both wgan-gp and wgan-hinge loss are ready, but note that wgan-gp is somehow not compatible with the spectral normalization. Remove all the spectral normalization at the model for the adoption of wgan-gp.
Self-attentions are applied to later two layers of both discriminator and generator.

- Supervised setting
- Tensorboard loggings
- [20180608] updated the self-attention module. Thanks to my colleague Cheonbok Park! see 'sagan_models.py' for the update. Should be efficient, and run on large sized images
- Attention visualization (LSUN Church-outdoor)
- Unsupervised setting (use no label yet)
- Applied: Spectral Normalization, code from here
- Implemented: self-attention module, two-timescale update rule (TTUR), wgan-hinge loss, wgan-gp loss



$ git clone https://github.com/heykeetae/Self-Attention-GAN.git
$ cd Self-Attention-GAN$ bash download.sh CelebA
or
$ bash download.sh LSUN$ python python main.py --batch_size 64 --imsize 64 --dataset celeb --adv_loss hinge --version sagan_celeb
or
$ python python main.py --batch_size 64 --imsize 64 --dataset lsun --adv_loss hinge --version sagan_lsun$ cd samples/sagan_celeb
or
$ cd samples/sagan_lsun
SOME IMPORTANT POINTS
-
Samples generated every 10(in parent file its 100) iterations are located. The rate of sampling could be controlled via --sample_step (ex, --sample_step 10).
-
#code->> parser.add_argument('--total_step', type=int, default=100, help='how many times to update the generator') which are used in
parameter.py file and update the generator after 100 --totalstep but in its parent file
it originally is default =1000000, so i change it default=100 that its possible for the
person which have not GPU .
- In This code i removed cuda because a new coder or non-coder or low middle class
people have not basically have'nt afford GPU so they
also experience without gpu and seen what are the result or changes or inference are
come after train and learn a lot.
- I do some chnges like removal of Cuda because we require GPU (which are costly but
more effective and give more speed of our system and train a lot more faster than CPU
and taking very less time.)
- In above ### parameter.py #### file we use or import argparse (# import argpase) and
use argument to intialize our variable/ argument module (like variable as understandable
term it may be hyperparameter or anything also) by default value and what it type and
also give them choice and also automatically generates help and usage messages and issue
errors when user give the program invalid argument.(pythonforbegginer.com/argparse/argparse.tutorial ).
--(https://www.pythonforbeginners.com/super/working-python-super-function)
-
transform function in data_loader.py used for augmentation of dataset.
-
PARENT file ----(https://github.com/heykeetae/Self-Attention-GAN)
where i learn but i do changes and make better for non cuda user please give star on my
link if you like .
8.Pytorch is a Deep learning framework which are comes mixing of python and "torch"
torch framework comes from #lua progamming language# basically which are mainly
originated for research purpose for new model comes and easily deploy and use and find
the result/INference.
#INFERENCE---------------------------------------------------------------------------------
Inference means estimating the values of some (usually hidden random) variable given some observation.
i think there isn’t much of a difference (at least conceptually) between infernce and training.
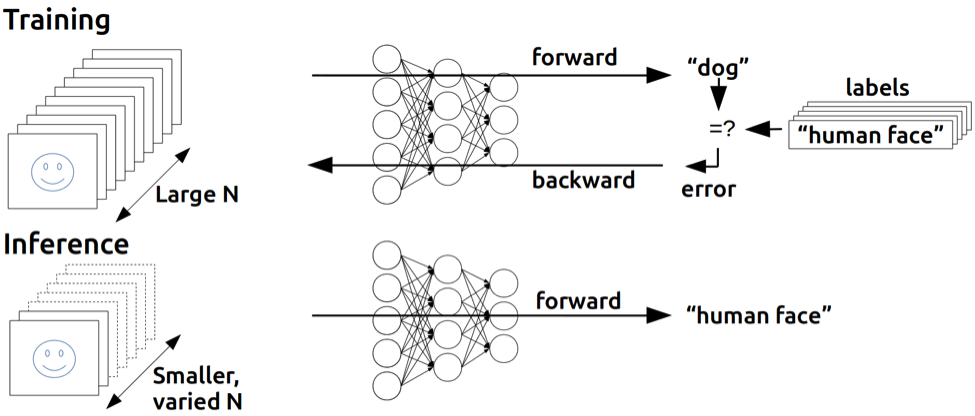
Deep learning is revolutionizing many areas of machine perception, with the potential to impact the everyday experience of
people everywhere. On a high level, working with deep neural networks is a two-stage process: First, a neural network is
trained: its parameters are determined using labeled examples of inputs and desired output. Then, the network is deployed to run
inference, using its previously trained parameters to classify, recognize and process unknown inputs.
https://devblogs.nvidia.com/wp-content/uploads/2015/08/training_inference1.png
{kind=link}
Deep Neural Network Training vs. Inference
Figure 1: Deep learning training compared to inference. In training, many inputs, often in large batches, are used to train a
deep neural network. In inference, the trained network is used to discover information within new inputs that are fed through the
network in smaller batches.
https://devblogs.nvidia.com/inference-next-step-gpu-accelerated-deep-learning/
https://www.quora.com/What-is-the-difference-between-inference-and-prediction-in-machine-learning