
![]()
![]()


A vulnerability scanner for container images and filesystems. Easily install the binary to try it out. Works with Syft, the powerful SBOM (software bill of materials) tool for container images and filesystems.
- Calendar: https://calendar.google.com/calendar/u/0/r?cid=Y182OTM4dGt0MjRtajI0NnNzOThiaGtnM29qNEBncm91cC5jYWxlbmRhci5nb29nbGUuY29t
- Agenda: https://docs.google.com/document/d/1ZtSAa6fj2a6KRWviTn3WoJm09edvrNUp4Iz_dOjjyY8/edit?usp=sharing (join this group for write access)
- All are welcome!
For commercial support options with Syft or Grype, please contact Anchore
- Scan the contents of a container image or filesystem to find known vulnerabilities.
- Find vulnerabilities for major operating system packages:
- Alpine
- Amazon Linux
- BusyBox
- CentOS
- CBL-Mariner
- Debian
- Distroless
- Oracle Linux
- Red Hat (RHEL)
- Ubuntu
- Wolfi
- Find vulnerabilities for language-specific packages:
- Ruby (Gems)
- Java (JAR, WAR, EAR, JPI, HPI)
- JavaScript (NPM, Yarn)
- Python (Egg, Wheel, Poetry, requirements.txt/setup.py files)
- Dotnet (deps.json)
- Golang (go.mod)
- PHP (Composer)
- Rust (Cargo)
- Supports Docker, OCI and Singularity image formats.
- OpenVEX support for filtering and augmenting scanning results.
If you encounter an issue, please let us know using the issue tracker.
curl -sSfL https://raw.githubusercontent.com/anchore/grype/main/install.sh | sh -s -- -b /usr/local/binInstall script options:
-b: Specify a custom installation directory (defaults to./bin)-d: More verbose logging levels (-dfor debug,-ddfor trace)-v: Verify the signature of the downloaded artifact before installation (requirescosignto be installed)
The chocolatey distribution of grype is community-maintained and not distributed by the anchore team.
choco install grype -ybrew tap anchore/grype
brew install grypeOn macOS, Grype can additionally be installed from the community-maintained port via MacPorts:
sudo port install grypeNote: Currently, Grype is built only for macOS and Linux.
See DEVELOPING.md for instructions to build and run from source.
If you're using GitHub Actions, you can use our Grype-based action to run vulnerability scans on your code or container images during your CI workflows.
Checksums are applied to all artifacts, and the resulting checksum file is signed using cosign.
You need the following tool to verify signature:
Verification steps are as follow:
-
Download the files you want, and the checksums.txt, checksums.txt.pem and checksums.txt.sig files from the releases page:
-
Verify the signature:
cosign verify-blob <path to checksum.txt> \
--certificate <path to checksums.txt.pem> \
--signature <path to checksums.txt.sig> \
--certificate-identity-regexp 'https://github\.com/anchore/grype/\.github/workflows/.+' \
--certificate-oidc-issuer "https://token.actions.githubusercontent.com"- Once the signature is confirmed as valid, you can proceed to validate that the SHA256 sums align with the downloaded artifact:
sha256sum --ignore-missing -c checksums.txtInstall the binary, and make sure that grype is available in your path. To scan for vulnerabilities in an image:
grype <image>
The above command scans for vulnerabilities visible in the container (i.e., the squashed representation of the image). To include software from all image layers in the vulnerability scan, regardless of its presence in the final image, provide --scope all-layers:
grype <image> --scope all-layers
To run grype from a Docker container so it can scan a running container, use the following command:
docker run --rm \
--volume /var/run/docker.sock:/var/run/docker.sock \
--name Grype anchore/grype:latest \
$(ImageName):$(ImageTag)Grype can scan a variety of sources beyond those found in Docker.
# scan a container image archive (from the result of `docker image save ...`, `podman save ...`, or `skopeo copy` commands)
grype path/to/image.tar
# scan a Singularity Image Format (SIF) container
grype path/to/image.sif
# scan a directory
grype dir:path/to/dir
Sources can be explicitly provided with a scheme:
podman:yourrepo/yourimage:tag use images from the Podman daemon
docker:yourrepo/yourimage:tag use images from the Docker daemon
docker-archive:path/to/yourimage.tar use a tarball from disk for archives created from "docker save"
oci-archive:path/to/yourimage.tar use a tarball from disk for OCI archives (from Skopeo or otherwise)
oci-dir:path/to/yourimage read directly from a path on disk for OCI layout directories (from Skopeo or otherwise)
singularity:path/to/yourimage.sif read directly from a Singularity Image Format (SIF) container on disk
dir:path/to/yourproject read directly from a path on disk (any directory)
file:path/to/yourfile read directly from a file on disk
sbom:path/to/syft.json read Syft JSON from path on disk
registry:yourrepo/yourimage:tag pull image directly from a registry (no container runtime required)
If an image source is not provided and cannot be detected from the given reference it is assumed the image should be pulled from the Docker daemon. If docker is not present, then the Podman daemon is attempted next, followed by reaching out directly to the image registry last.
This default behavior can be overridden with the default-image-pull-source configuration option (See Configuration for more details).
Use SBOMs for even faster vulnerability scanning in Grype:
# Then scan for new vulnerabilities as frequently as needed
grype sbom:./sbom.json
# (You can also pipe the SBOM into Grype)
cat ./sbom.json | grype
Grype supports input of Syft, SPDX, and CycloneDX
SBOM formats. If Syft has generated any of these file types, they should have the appropriate information to work properly with Grype.
It is also possible to use SBOMs generated by other tools with varying degrees of success. Two things that make Grype matching
more successful are the inclusion of CPE and Linux distribution information. If an SBOM does not include any CPE information, it
is possible to generate these based on package information using the --add-cpes-if-none flag. To specify a distribution,
use the --distro <distro>:<version> flag. A full example is:
grype --add-cpes-if-none --distro alpine:3.10 sbom:some-alpine-3.10.spdx.json
Any version of Grype before v0.51.0 (Oct 2022) is not supported. Unsupported releases will not receive any software updates or vulnerability database updates. You can still build vulnerability databases for unsupported Grype releases by using previous releases of vunnel to gather the upstream data and grype-db to build databases for unsupported schemas.
Grype supports scanning SBOMs as input via stdin. Users can use cosign to verify attestations with an SBOM as its content to scan an image for vulnerabilities:
COSIGN_EXPERIMENTAL=1 cosign verify-attestation caphill4/java-spdx-tools:latest \
| jq -r .payload \
| base64 --decode \
| jq -r .predicate.Data \
| grype
{
"vulnerability": {
...
},
"relatedVulnerabilities": [
...
],
"matchDetails": [
...
],
"artifact": {
...
}
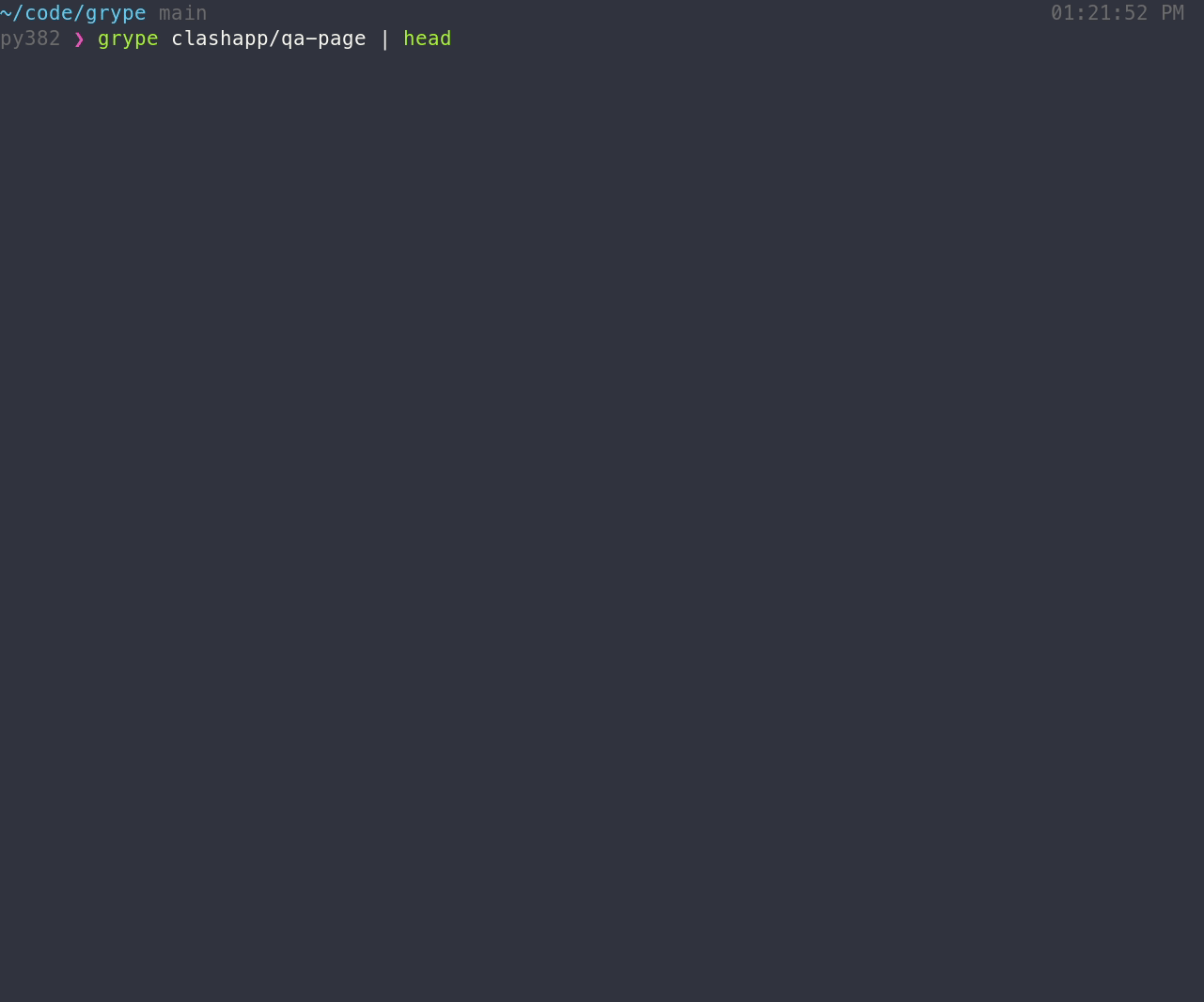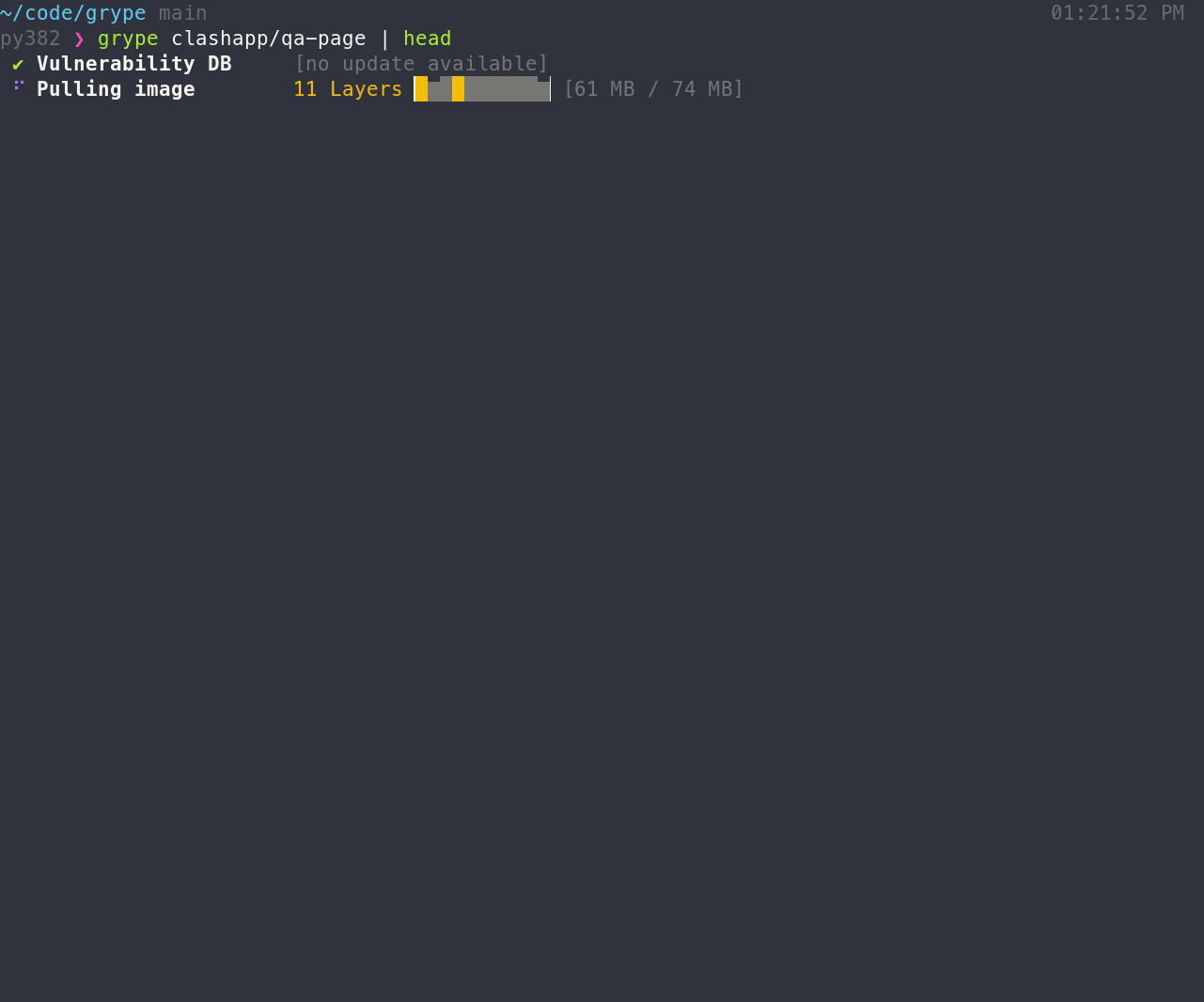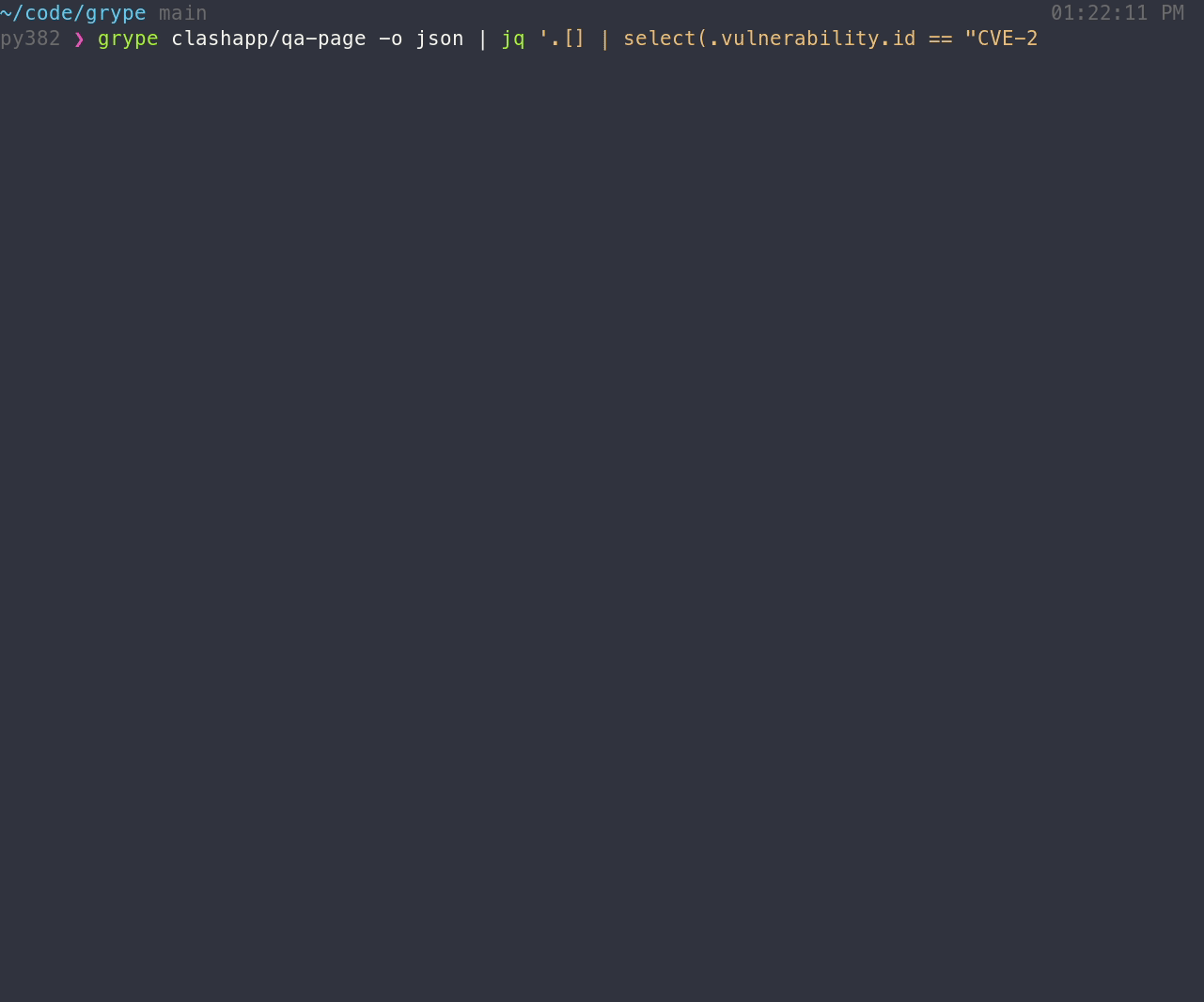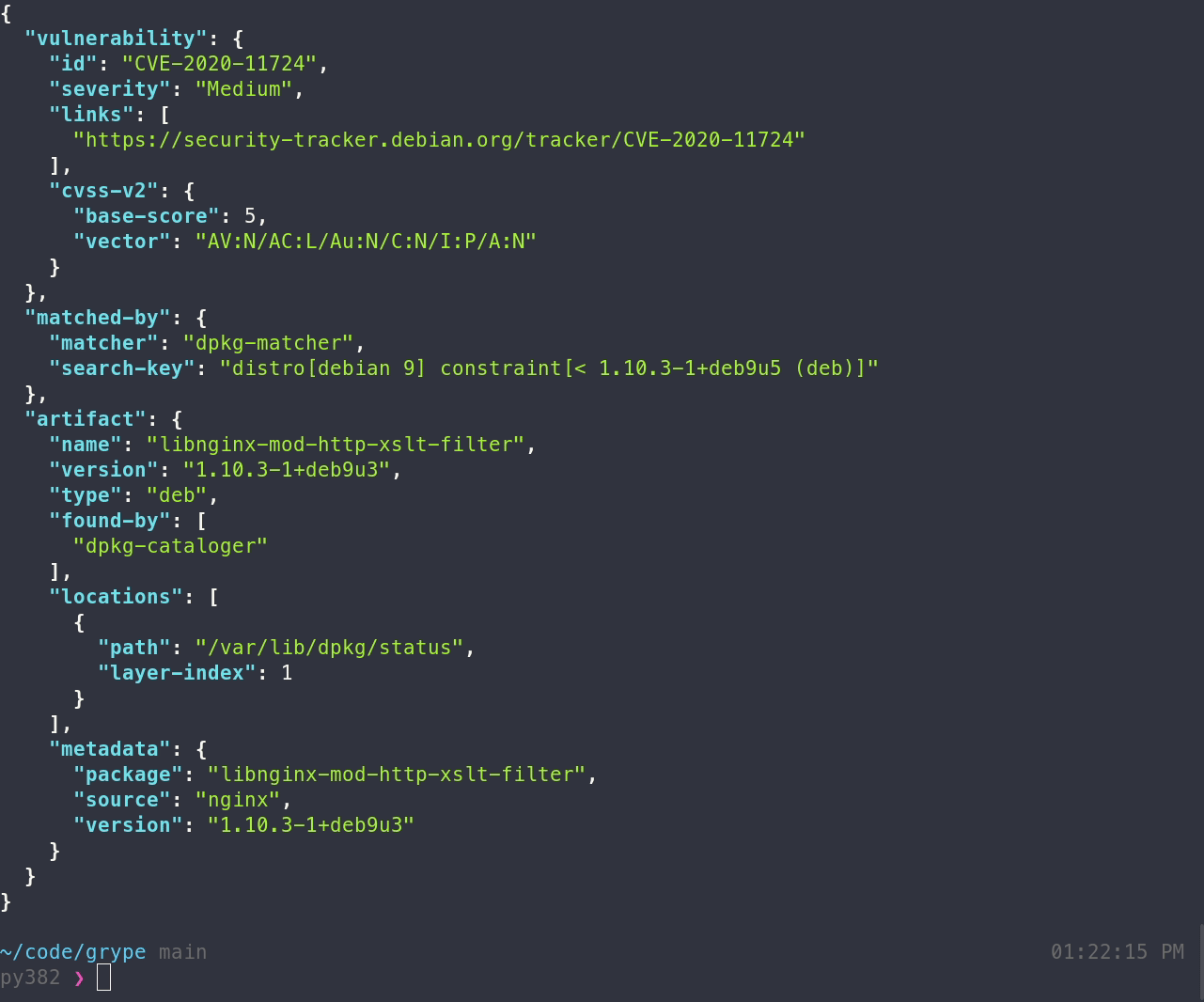
}- Vulnerability: All information on the specific vulnerability that was directly matched on (e.g. ID, severity, CVSS score, fix information, links for more information)
- RelatedVulnerabilities: Information pertaining to vulnerabilities found to be related to the main reported vulnerability. Maybe the vulnerability we matched on was a GitHub Security Advisory, which has an upstream CVE (in the authoritative national vulnerability database). In these cases we list the upstream vulnerabilities here.
- MatchDetails: This section tries to explain what we searched for while looking for a match and exactly what details on the package and vulnerability that lead to a match.
- Artifact: This is a subset of the information that we know about the package (when compared to the Syft json output, we summarize the metadata section). This has information about where within the container image or directory we found the package, what kind of package it is, licensing info, pURLs, CPEs, etc.
Grype can exclude files and paths from being scanned within a source by using glob expressions
with one or more --exclude parameters:
grype <source> --exclude './out/**/*.json' --exclude /etc
Note: in the case of image scanning, since the entire filesystem is scanned it is
possible to use absolute paths like /etc or /usr/**/*.txt whereas directory scans
exclude files relative to the specified directory. For example: scanning /usr/foo with
--exclude ./package.json would exclude /usr/foo/package.json and --exclude '**/package.json'
would exclude all package.json files under /usr/foo. For directory scans,
it is required to begin path expressions with ./, */, or **/, all of which
will be resolved relative to the specified scan directory. Keep in mind, your shell
may attempt to expand wildcards, so put those parameters in single quotes, like:
'**/*.json'.
Grype can be configured to incorporate external data sources for added fidelity in vulnerability matching. This feature is currently disabled by default. To enable this feature add the following to the grype config:
external-sources:
enable: true
maven:
search-upstream-by-sha1: true
base-url: https://repo1.maven.org/maven2You can also configure the base-url if you're using another registry as your maven endpoint.
The output format for Grype is configurable as well:
grype <image> -o <format>
Where the formats available are:
table: A columnar summary (default).cyclonedx: An XML report conforming to the CycloneDX 1.6 specification.cyclonedx-json: A JSON report conforming to the CycloneDX 1.6 specification.json: Use this to get as much information out of Grype as possible!sarif: Use this option to get a SARIF report (Static Analysis Results Interchange Format)template: Lets the user specify the output format. See "Using templates" below.
Grype lets you define custom output formats, using Go templates. Here's how it works:
-
Define your format as a Go template, and save this template as a file.
-
Set the output format to "template" (
-o template). -
Specify the path to the template file (
-t ./path/to/custom.template). -
Grype's template processing uses the same data models as the
jsonoutput format — so if you're wondering what data is available as you author a template, you can use the output fromgrype <image> -o jsonas a reference.
Please note: Templates can access information about the system they are running on, such as environment variables. You should never run untrusted templates.
There are several example templates in the templates directory in the Grype source which can serve as a starting point for a custom output format. For example, csv.tmpl produces a vulnerability report in CSV (comma separated value) format:
"Package","Version Installed","Vulnerability ID","Severity"
"coreutils","8.30-3ubuntu2","CVE-2016-2781","Low"
"libc-bin","2.31-0ubuntu9","CVE-2016-10228","Negligible"
"libc-bin","2.31-0ubuntu9","CVE-2020-6096","Low"
...
You can also find the template for the default "table" output format in the same place.
Grype also includes a vast array of utility templating functions from sprig apart from the default golang text/template to allow users to customize the output from Grype.
You can have Grype exit with an error if any vulnerabilities are reported at or above the specified severity level. This comes in handy when using Grype within a script or CI pipeline. To do this, use the --fail-on <severity> CLI flag.
For example, here's how you could trigger a CI pipeline failure if any vulnerabilities are found in the ubuntu:latest image with a severity of "medium" or higher:
grype ubuntu:latest --fail-on medium
If you're seeing Grype report false positives or any other vulnerability matches that you just don't want to see, you can tell Grype to ignore matches by specifying one or more "ignore rules" in your Grype configuration file (e.g. ~/.grype.yaml). This causes Grype not to report any vulnerability matches that meet the criteria specified by any of your ignore rules.
Each rule can specify any combination of the following criteria:
- vulnerability ID (e.g.
"CVE-2008-4318") - namespace (e.g.
"nvd") - fix state (allowed values:
"fixed","not-fixed","wont-fix", or"unknown") - package name (e.g.
"libcurl") - package version (e.g.
"1.5.1") - package language (e.g.
"python"; these values are defined here) - package type (e.g.
"npm"; these values are defined here) - package location (e.g.
"/usr/local/lib/node_modules/**"; supports glob patterns)
Here's an example ~/.grype.yaml that demonstrates the expected format for ignore rules:
ignore:
# This is the full set of supported rule fields:
- vulnerability: CVE-2008-4318
fix-state: unknown
# VEX fields apply when Grype reads vex data:
vex-status: not_affected
vex-justification: vulnerable_code_not_present
package:
name: libcurl
version: 1.5.1
type: npm
location: "/usr/local/lib/node_modules/**"
# We can make rules to match just by vulnerability ID:
- vulnerability: CVE-2014-54321
# ...or just by a single package field:
- package:
type: gemVulnerability matches will be ignored if any rules apply to the match. A rule is considered to apply to a given vulnerability match only if all fields specified in the rule apply to the vulnerability match.
When you run Grype while specifying ignore rules, the following happens to the vulnerability matches that are "ignored":
-
Ignored matches are completely hidden from Grype's output, except for when using the
jsonortemplateoutput formats; however, in these two formats, the ignored matches are removed from the existingmatchesarray field, and they are placed in a newignoredMatchesarray field. Each listed ignored match also has an additional field,appliedIgnoreRules, which is an array of any rules that caused Grype to ignore this vulnerability match. -
Ignored matches do not factor into Grype's exit status decision when using
--fail-on <severity>. For instance, if a user specifies--fail-on critical, and all of the vulnerability matches found with a "critical" severity have been ignored, Grype will exit zero.
Note: Please continue to report any false positives you see! Even if you can reliably filter out false positives using ignore rules, it's very helpful to the Grype community if we have as much knowledge about Grype's false positives as possible. This helps us continuously improve Grype!
If you only want Grype to report vulnerabilities that have a confirmed fix, you can use the --only-fixed flag. (This automatically adds ignore rules into Grype's configuration, such that vulnerabilities that aren't fixed will be ignored.)
For example, here's a scan of Alpine 3.10:
NAME INSTALLED FIXED-IN VULNERABILITY SEVERITY
apk-tools 2.10.6-r0 2.10.7-r0 CVE-2021-36159 Critical
libcrypto1.1 1.1.1k-r0 CVE-2021-3711 Critical
libcrypto1.1 1.1.1k-r0 CVE-2021-3712 High
libssl1.1 1.1.1k-r0 CVE-2021-3712 High
libssl1.1 1.1.1k-r0 CVE-2021-3711 Critical
...and here's the same scan, but adding the flag --only-fixed:
NAME INSTALLED FIXED-IN VULNERABILITY SEVERITY
apk-tools 2.10.6-r0 2.10.7-r0 CVE-2021-36159 Critical
If you want Grype to only report vulnerabilities that do not have a confirmed fix, you can use the --only-notfixed flag. Alternatively, you can use the --ignore-states flag to filter results for vulnerabilities with specific states such as wont-fix (see --help for a list of valid fix states). These flags automatically add ignore rules into Grype's configuration, such that vulnerabilities which are fixed, or will not be fixed, will be ignored.
Grype can use VEX (Vulnerability Exploitability Exchange) data to filter false
positives or provide additional context, augmenting matches. When scanning a
container image, you can use the --vex flag to point to one or more
OpenVEX documents.
VEX statements relate a product (a container image), a vulnerability, and a VEX
status to express an assertion of the vulnerability's impact. There are four
VEX statuses:
not_affected, affected, fixed and under_investigation.
Here is an example of a simple OpenVEX document. (tip: use
vexctl to generate your own documents).
{
"@context": "https://openvex.dev/ns/v0.2.0",
"@id": "https://openvex.dev/docs/public/vex-d4e9020b6d0d26f131d535e055902dd6ccf3e2088bce3079a8cd3588a4b14c78",
"author": "A Grype User <jdoe@example.com>",
"timestamp": "2023-07-17T18:28:47.696004345-06:00",
"version": 1,
"statements": [
{
"vulnerability": {
"name": "CVE-2023-1255"
},
"products": [
{
"@id": "pkg:oci/alpine@sha256%3A124c7d2707904eea7431fffe91522a01e5a861a624ee31d03372cc1d138a3126",
"subcomponents": [
{ "@id": "pkg:apk/alpine/libssl3@3.0.8-r3" },
{ "@id": "pkg:apk/alpine/libcrypto3@3.0.8-r3" }
]
}
],
"status": "fixed"
}
]
}By default, Grype will use any statements in specified VEX documents with a
status of not_affected or fixed to move matches to the ignore set.
Any matches ignored as a result of VEX statements are flagged when using
--show-suppressed:
libcrypto3 3.0.8-r3 3.0.8-r4 apk CVE-2023-1255 Medium (suppressed by VEX)
Statements with an affected or under_investigation status will only be
considered to augment the result set when specifically requested using the
GRYPE_VEX_ADD environment variable or in a configuration file.
Ignore rules can be written to control how Grype honors VEX statements. For
example, to configure Grype to only act on VEX statements when the justification is vulnerable_code_not_present, you can write a rule like this:
---
ignore:
- vex-status: not_affected
vex-justification: vulnerable_code_not_presentSee the list of justifications for details. You can mix vex-status and vex-justification
with other ignore rule parameters.
When Grype performs a scan for vulnerabilities, it does so using a vulnerability database that's stored on your local filesystem, which is constructed by pulling data from a variety of publicly available vulnerability data sources. These sources include:
- Alpine Linux SecDB: https://secdb.alpinelinux.org/
- Amazon Linux ALAS: https://alas.aws.amazon.com/AL2/alas.rss
- Chainguard SecDB: https://packages.cgr.dev/chainguard/security.json
- Debian Linux CVE Tracker: https://security-tracker.debian.org/tracker/data/json
- GitHub Security Advisories (GHSAs): https://github.com/advisories
- National Vulnerability Database (NVD): https://nvd.nist.gov/vuln/data-feeds
- Oracle Linux OVAL: https://linux.oracle.com/security/oval/
- RedHat Linux Security Data: https://access.redhat.com/hydra/rest/securitydata/
- RedHat RHSAs: https://www.redhat.com/security/data/oval/
- SUSE Linux OVAL: https://ftp.suse.com/pub/projects/security/oval/
- Ubuntu Linux Security: https://people.canonical.com/~ubuntu-security/
- Wolfi SecDB: https://packages.wolfi.dev/os/security.json
By default, Grype automatically manages this database for you. Grype checks for new updates to the vulnerability database to make sure that every scan uses up-to-date vulnerability information. This behavior is configurable. For more information, see the Managing Grype's database section.
Grype's vulnerability database is a SQLite file, named vulnerability.db. Updates to the database are atomic: the entire database is replaced and then treated as "readonly" by Grype.
Grype's first step in a database update is discovering databases that are available for retrieval. Grype does this by requesting a "listing file" from a public endpoint:
https://toolbox-data.anchore.io/grype/databases/listing.json
The listing file contains entries for every database that's available for download.
Here's an example of an entry in the listing file:
{
"built": "2021-10-21T08:13:41Z",
"version": 3,
"url": "https://toolbox-data.anchore.io/grype/databases/vulnerability-db_v3_2021-10-21T08:13:41Z.tar.gz",
"checksum": "sha256:8c99fb4e516f10b304f026267c2a73a474e2df878a59bf688cfb0f094bfe7a91"
}With this information, Grype can select the correct database (the most recently built database with the current schema version), download the database, and verify the database's integrity using the listed checksum value.
Note: During normal usage, there is no need for users to manage Grype's database! Grype manages its database behind the scenes. However, for users that need more control, Grype provides options to manage the database more explicitly.
By default, the database is cached on the local filesystem in the directory $XDG_CACHE_HOME/grype/db/<SCHEMA-VERSION>/. For example, on macOS, the database would be stored in ~/Library/Caches/grype/db/3/. (For more information on XDG paths, refer to the XDG Base Directory Specification.)
You can set the cache directory path using the environment variable GRYPE_DB_CACHE_DIR. If setting that variable alone does not work, then the TMPDIR environment variable might also need to be set.
Grype needs up-to-date vulnerability information to provide accurate matches. By default, it will fail execution if the local database was not built in the last 5 days. The data staleness check is configurable via the environment variable GRYPE_DB_MAX_ALLOWED_BUILT_AGE and GRYPE_DB_VALIDATE_AGE or the field max-allowed-built-age and validate-age, under db. It uses golang's time duration syntax. Set GRYPE_DB_VALIDATE_AGE or validate-age to false to disable staleness check.
By default, Grype checks for a new database on every run, by making a network call over the Internet. You can tell Grype not to perform this check by setting the environment variable GRYPE_DB_AUTO_UPDATE to false.
As long as you place Grype's vulnerability.db and metadata.json files in the cache directory for the expected schema version, Grype has no need to access the network. Additionally, you can get a listing of the database archives available for download from the grype db list command in an online environment, download the database archive, transfer it to your offline environment, and use grype db import <db-archive-path> to use the given database in an offline capacity.
If you would like to distribute your own Grype databases internally without needing to use db import manually you can leverage Grype's DB update mechanism. To do this you can craft your own listing.json file similar to the one found publically (see grype db list -o raw for an example of our public listing.json file) and change the download URL to point to an internal endpoint (e.g. a private S3 bucket, an internal file server, etc). Any internal installation of Grype can receive database updates automatically by configuring the db.update-url (same as the GRYPE_DB_UPDATE_URL environment variable) to point to the hosted listing.json file you've crafted.
Grype provides database-specific CLI commands for users that want to control the database from the command line. Here are some of the useful commands provided:
grype db status — report the current status of Grype's database (such as its location, build date, and checksum)
grype db check — see if updates are available for the database
grype db update — ensure the latest database has been downloaded to the cache directory (Grype performs this operation at the beginning of every scan by default)
grype db list — download the listing file configured at db.update-url and show databases that are available for download
grype db import — provide grype with a database archive to explicitly use (useful for offline DB updates)
grype db providers - provides a detailed list of database providers
Find complete information on Grype's database commands by running grype db --help.
Grype supplies shell completion through its CLI implementation (cobra). Generate the completion code for your shell by running one of the following commands:
grype completion <bash|zsh|fish>go run ./cmd/grype completion <bash|zsh|fish>
This will output a shell script to STDOUT, which can then be used as a completion script for Grype. Running one of the above commands with the
-h or --help flags will provide instructions on how to do that for your chosen shell.
When a container runtime is not present, grype can still utilize credentials configured in common credential sources (such as ~/.docker/config.json).
It will pull images from private registries using these credentials. The config file is where your credentials are stored when authenticating with private registries via some command like docker login.
For more information see the go-containerregistry documentation.
An example config.json looks something like this:
// config.json
{
"auths": {
"registry.example.com": {
"username": "AzureDiamond",
"password": "hunter2"
}
}
}
You can run the following command as an example. It details the mount/environment configuration a container needs to access a private registry:
docker run -v ./config.json:/config/config.json -e "DOCKER_CONFIG=/config" anchore/grype:latest <private_image>
The below section shows a simple workflow on how to mount this config file as a secret into a container on kubernetes.
- Create a secret. The value of
config.jsonis important. It refers to the specification detailed here. Below this section is thesecret.yamlfile that the pod configuration will consume as a volume. The keyconfig.jsonis important. It will end up being the name of the file when mounted into the pod.apiVersion: v1 kind: Secret metadata: name: registry-config namespace: grype data: config.json: <base64 encoded config.json> ``` `kubectl apply -f secret.yaml` - Create your pod running grype. The env
DOCKER_CONFIGis important because it advertises where to look for the credential file. In the below example, settingDOCKER_CONFIG=/configinforms grype that credentials can be found at/config/config.json. This is why we usedconfig.jsonas the key for our secret. When mounted into containers the secrets' key is used as the filename. ThevolumeMountssection mounts our secret to/config. Thevolumessection names our volume and leverages the secret we created in step one.apiVersion: v1 kind: Pod spec: containers: - image: anchore/grype:latest name: grype-private-registry-demo env: - name: DOCKER_CONFIG value: /config volumeMounts: - mountPath: /config name: registry-config readOnly: true args: - <private_image> volumes: - name: registry-config secret: secretName: registry-config ``` `kubectl apply -f pod.yaml` - The user can now run
kubectl logs grype-private-registry-demo. The logs should show the grype analysis for the<private_image>provided in the pod configuration.
Using the above information, users should be able to configure private registry access without having to do so in the grype or syft configuration files.
They will also not be dependent on a docker daemon, (or some other runtime software) for registry configuration and access.
Default configuration search paths (see all with grype config locations):
.grype.yaml.grype/config.yaml~/.grype.yaml<XDG_CONFIG_HOME>/grype/config.yaml
Use grype config to print a sample config file to stdout.
Use grype config --load to print the current config after loading all values to stdout.
You can specify files directly using the --config / -c flags to provide your own configuration files/paths:
grype <image> -c /path/to/config.yaml
Configuration options (example values are the default):
# enable/disable checking for application updates on startup
# same as GRYPE_CHECK_FOR_APP_UPDATE env var
check-for-app-update: true
# allows users to specify which image source should be used to generate the sbom
# valid values are: registry, docker, podman
# same as GRYPE_DEFAULT_IMAGE_PULL_SOURCE env var
default-image-pull-source: ""
# same as --name; set the name of the target being analyzed
name: ""
# upon scanning, if a severity is found at or above the given severity then the return code will be 1
# default is unset which will skip this validation (options: negligible, low, medium, high, critical)
# same as --fail-on ; GRYPE_FAIL_ON_SEVERITY env var
fail-on-severity: ""
# the output format of the vulnerability report (options: table, template, json, cyclonedx)
# when using template as the output type, you must also provide a value for 'output-template-file'
# same as -o ; GRYPE_OUTPUT env var
output: "table"
# if using template output, you must provide a path to a Go template file
# see https://github.com/anchore/grype#using-templates for more information on template output
# the default path to the template file is the current working directory
# output-template-file: .grype/html.tmpl
# write output report to a file (default is to write to stdout)
# same as --file; GRYPE_FILE env var
file: ""
# a list of globs to exclude from scanning, for example:
# exclude:
# - '/etc/**'
# - './out/**/*.json'
# same as --exclude ; GRYPE_EXCLUDE env var
exclude: []
# include matches on kernel-headers packages that are matched against upstream kernel package
# if 'false' any such matches are marked as ignored
match-upstream-kernel-headers: false
# os and/or architecture to use when referencing container images (e.g. "windows/armv6" or "arm64")
# same as --platform; GRYPE_PLATFORM env var
platform: ""
# If using SBOM input, automatically generate CPEs when packages have none
add-cpes-if-none: false
# Explicitly specify a linux distribution to use as <distro>:<version> like alpine:3.10
distro:
external-sources:
enable: false
maven:
search-upstream-by-sha1: true
base-url: https://repo1.maven.org/maven2
db:
# check for database updates on execution
# same as GRYPE_DB_AUTO_UPDATE env var
auto-update: true
# location to write the vulnerability database cache; defaults to $XDG_CACHE_HOME/grype/db
# same as GRYPE_DB_CACHE_DIR env var
cache-dir: ""
# URL of the vulnerability database
# same as GRYPE_DB_UPDATE_URL env var
update-url: "https://toolbox-data.anchore.io/grype/databases/listing.json"
# it ensures db build is no older than the max-allowed-built-age
# set to false to disable check
validate-age: true
# Max allowed age for vulnerability database,
# age being the time since it was built
# Default max age is 120h (or five days)
max-allowed-built-age: "120h"
# Timeout for downloading GRYPE_DB_UPDATE_URL to see if the database needs to be downloaded
# This file is ~156KiB as of 2024-04-17 so the download should be quick; adjust as needed
update-available-timeout: "30s"
# Timeout for downloading actual vulnerability DB
# The DB is ~156MB as of 2024-04-17 so slower connections may exceed the default timeout; adjust as needed
update-download-timeout: "120s"
search:
# the search space to look for packages (options: all-layers, squashed)
# same as -s ; GRYPE_SEARCH_SCOPE env var
scope: "squashed"
# search within archives that do contain a file index to search against (zip)
# note: for now this only applies to the java package cataloger
# same as GRYPE_PACKAGE_SEARCH_INDEXED_ARCHIVES env var
indexed-archives: true
# search within archives that do not contain a file index to search against (tar, tar.gz, tar.bz2, etc)
# note: enabling this may result in a performance impact since all discovered compressed tars will be decompressed
# note: for now this only applies to the java package cataloger
# same as GRYPE_PACKAGE_SEARCH_UNINDEXED_ARCHIVES env var
unindexed-archives: false
# options when pulling directly from a registry via the "registry:" scheme
registry:
# skip TLS verification when communicating with the registry
# same as GRYPE_REGISTRY_INSECURE_SKIP_TLS_VERIFY env var
insecure-skip-tls-verify: false
# use http instead of https when connecting to the registry
# same as GRYPE_REGISTRY_INSECURE_USE_HTTP env var
insecure-use-http: false
# filepath to a CA certificate (or directory containing *.crt, *.cert, *.pem) used to generate the client certificate
# GRYPE_REGISTRY_CA_CERT env var
ca-cert: ""
# credentials for specific registries
auth:
# the URL to the registry (e.g. "docker.io", "localhost:5000", etc.)
# GRYPE_REGISTRY_AUTH_AUTHORITY env var
- authority: ""
# GRYPE_REGISTRY_AUTH_USERNAME env var
username: ""
# GRYPE_REGISTRY_AUTH_PASSWORD env var
password: ""
# note: token and username/password are mutually exclusive
# GRYPE_REGISTRY_AUTH_TOKEN env var
token: ""
# filepath to the client certificate used for TLS authentication to the registry
# GRYPE_REGISTRY_AUTH_TLS_CERT env var
tls-cert: ""
# filepath to the client key used for TLS authentication to the registry
# GRYPE_REGISTRY_AUTH_TLS_KEY env var
tls-key: ""
# - ... # note, more credentials can be provided via config file only (not env vars)
log:
# suppress all output (except for the vulnerability list)
# same as -q ; GRYPE_LOG_QUIET env var
quiet: false
# increase verbosity
# same as GRYPE_LOG_VERBOSITY env var
verbosity: 0
# the log level; note: detailed logging suppress the ETUI
# same as GRYPE_LOG_LEVEL env var
# Uses logrus logging levels: https://github.com/sirupsen/logrus#level-logging
level: "error"
# location to write the log file (default is not to have a log file)
# same as GRYPE_LOG_FILE env var
file: ""
match:
# sets the matchers below to use cpes when trying to find
# vulnerability matches. The stock matcher is the default
# when no primary matcher can be identified.
java:
using-cpes: false
python:
using-cpes: false
javascript:
using-cpes: false
ruby:
using-cpes: false
dotnet:
using-cpes: false
golang:
using-cpes: false
# even if CPE matching is disabled, make an exception when scanning for "stdlib".
always-use-cpe-for-stdlib: true
# allow main module pseudo versions, which may have only been "guessed at" by Syft, to be used in vulnerability matching
allow-main-module-pseudo-version-comparison: false
stock:
using-cpes: trueThe following areas of potential development are currently being investigated:
- Support for allowlist, package mapping
Grype Logo by Anchore is licensed under CC BY 4.0
{kind=link}