Handwritten digit recognizer built using Keras and Tensorflow, and trained with 60,000 images from the MNIST dataset. Here, without getting too technical, I'll briefly explain my model and some of the techniques used to improve its accuracy.
A convolutional neural network (CNN) is a class of neural network most often used in computer vision (i.e. interpreting & understanding the visual world, such as an image). An image can be broken down into a series of pixel values that indicates its colors and brightness, and we can use this to identify objects, and in our case, handwritten digits.
Below is an examplar of the architecture of a CNN:
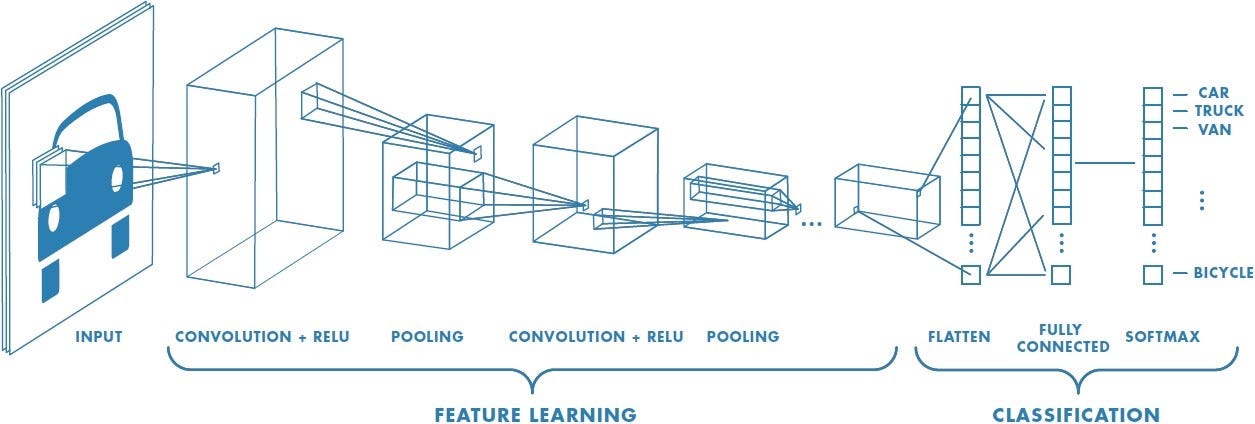
Convolutional Layer:
This layer condenses the input image using a kernel/filter, which takes in a section of an image and moves through the input image until every part of the image has been traversed. The point is to extract the features of the input image.
Pooling Layer:
This layer reduces the spatial size of the input image once again, and the purpose is to decrease the computional complexity. In my model and in most models used for digit recognition, max pooling is the preferred pooling method. Max pooling returns the maximum pixel value in the kernel as supposed to average pooling which takes the average of all pixel values inside the kernel. This is extremely useful in extracting dominant features and handling features that are rotated or in an unconventional position.
Flattening Layer:
The input data needs to be 1-dimensional linear vector in order to be classified. The flattening layer converts the data into 1D arrays to be processed by the model.
Building a CNN from scratch takes an insane amount of work. Thankfully, the existence of frameworks like Tensorflow and PyTorch makes that process a lot easier, and in the case of digit recognition, the programmer's main objective is to fine-tune the model to achieve the highest accuracy possible.
Below is the architecture of my CNN used for digit recognition:

On top of the ideas introduced above, here are some other techniques used in my model:
Batch Normalization:
When training a ML model, data is often grouped into batches. Batch normalization standardizes the inputs to a layer for each patch, and this stabilizes the training process, reducing the number of training epochs required.
Dropout:
The Dropout layer nullifies the contribution of some datapoints toward the next layer. This is crucial in preventing overfitting - the model fits the training data "too well" and becomes inaccurate when it encounters unseen data.
In the Kaggle Competition in Digit Recognition, my model is able to achieve a score of 0.99907, which ranks top 100 out of all the competing teams.
I decided to deploy my model using a web app. The frontend is handled using BootStrap and the backend is handled with Flask. Here's what it looks like in action:

One thing that I noticed while testing the product is that the model accuracy seems a bit lower compared to the score achieved in the Kaggle Competition. This is likely due to the fact that the Kaggle tests rarely contain rotated or weirdly-position images. An update/improvement on the rotational and positional invariance of the model may come in the future.