Crawler project intend of to prevent interface for parsing html pages with ferret. We do it, because we don't find implementation another fql/dsl language.
This repo implements python package with methods of python-clients package. Python-clients package is correct way to implement client to service. We publish our client to PyPi-registry. To install them, you can do this:
pip install crawler-ferret-service
We save package with clients to our PyPi registry for crawler project.
After that, you can do this with async client:
from clients import http
from crawler_ferret_service import methods as crawler_ferret_service
client = http.AsyncClient('http://localhost:8080')
m = crawler_ferret_service.Root()
resp, status = await client.request(m)
print(resp)
print(status)
Before request, you need to run the service:
docker run -p 8080:8080 -it montferret/worker
If you want to use sync client, you can do this:
client = http.Client('http://localhost:8080')
# ...
resp, status = client.request(m)
# ...



Worker is a simple HTTP server that accepts FQL queries, executes them and returns their results.
The Worker is shipped with dedicated Docker image that contains headless Google Chrome, so feel free to run queries using cdp driver:
docker run -p 8080:8080 -it montferret/workerAlternatively, if you want to use your own version of Chrome, you can run the Worker locally:
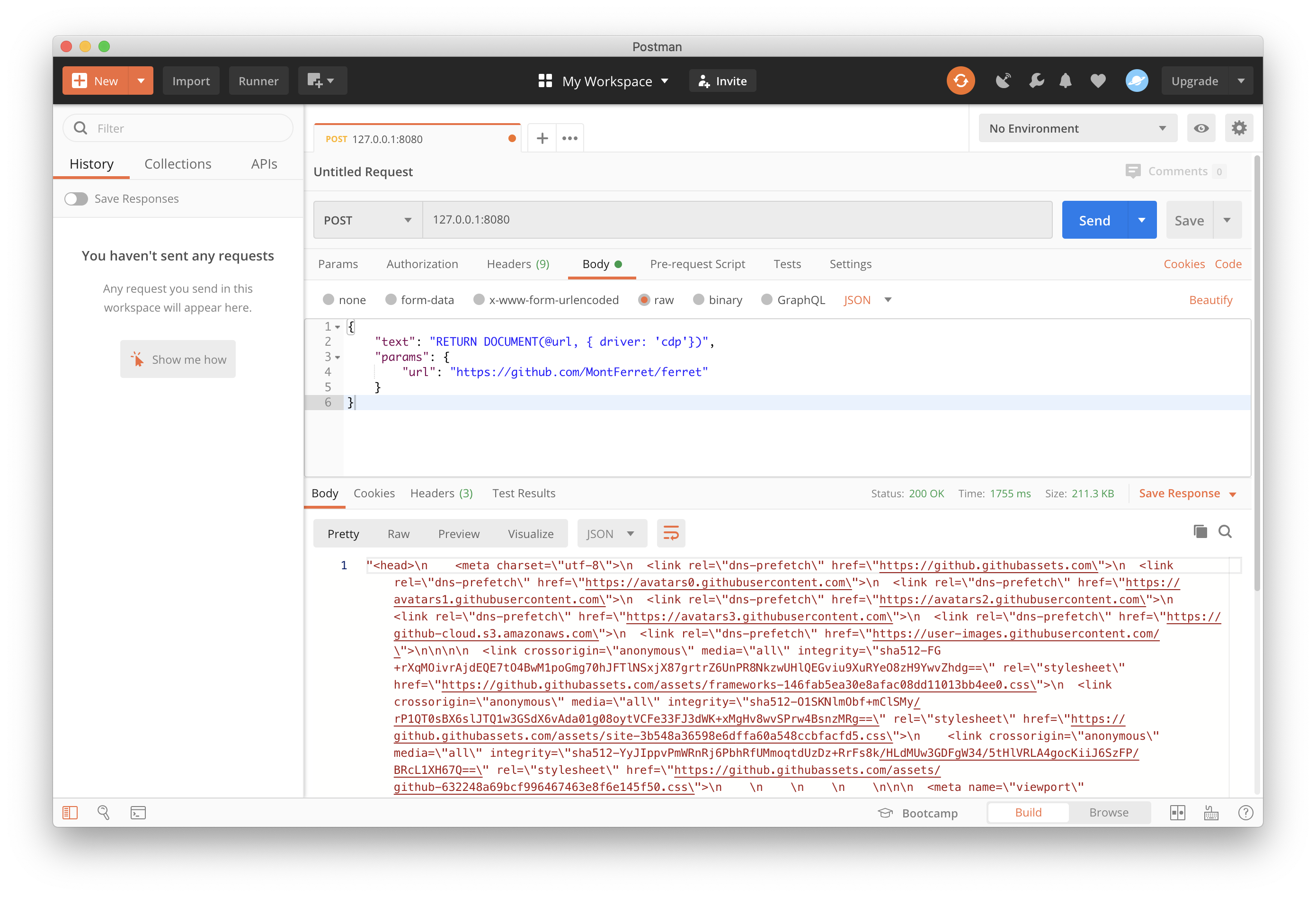
makeAnd then just make a POST request:
- 2 CPU
- 2 Gb of RAM
[POST] /- Executes a given query. The payload must be an object with required "text" and optional "params" fields.[GET] /version- Returns a version of Chrome and Ferret.[GET] /health- Health check endpoint (for Kubernetes, e.g.).
-chrome-ip string
Google Chrome remote IP address (default "127.0.0.1")
-chrome-port uint
Google Chrome remote debugging port (default 9222)
-help
show this list
-port uint
port to listen (default 8080)
-version
show REPL version