chore(deps): update dependency sentence_transformers to v3 #1291
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
07368a3
to
3c92933
Compare
3c92933
to
7868afe
Compare
|



7868afe
to
7109494
Compare
fbfb287
to
eaa847e
Compare
eaa847e
to
7e1a61c
Compare
834f49c
to
cbe02a5
Compare
cbe02a5
to
e7c3596
Compare
e7c3596
to
a0b1406
Compare
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
This PR contains the following updates:
==2.7.0->==3.3.1Release Notes
UKPLab/sentence-transformers (sentence_transformers)
v3.3.1: - Patch private model loading without environment variableCompare Source
This patch release fixes a small issue with loading private models from Hugging Face using the
tokenargument.Install this version with
Details
If you're loading model under this scenario:
HF_TOKENenvironment variable viahuggingface-cli loginor some other approach.tokenargument toSentenceTransformerto load the model.Then you may have encountered a crash in v3.3.0. This should be resolved now.
All Changes
docs] Fix the prompt link to the training script by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/3060Full Changelog: UKPLab/sentence-transformers@v3.3.0...v3.3.1
v3.3.0: - Massive CPU speedup with OpenVINO int8 quantization; Training with Prompts for stronger models; NanoBEIR IR evaluation; PEFT compatibility; Transformers v4.46.0 compatibilityCompare Source
4x speedup for CPU with OpenVINO int8 static quantization, training with prompts for a free performance boost, convenient evaluation on NanoBEIR: a subset of a strong Information Retrieval benchmark, PEFT compatibility by easily adding/loading adapters, Transformers v4.46.0 compatibility, and Python 3.8 deprecation.
Install this version with:
OpenVINO int8 static quantization (https://github.com/UKPLab/sentence-transformers/pull/3025)
We introduce int8 static quantization using OpenVINO, a highly performant solution that outperforms all other current backends by a mile, at a minimal loss in performance. Here are the updated benchmarks:
Quantizing directly to the Hugging Face Hub
You can immediately use the model, even before it's merged, by using the
revisionargument:And once it's merged:
Quantizing locally
You can also quantize a model and save it locally:
And after quantizing, you can load it like so:
All original Sentence Transformer models already have these new
openvino_model_qint8_quantized.xmlfiles, so you can load them without exporting directly! I would recommend making pull requests for other models on Hugging Face that you'd like to see quantized.Learn more about how to Speed up Inference in the documentation: https://sbert.net/docs/sentence_transformer/usage/efficiency.html
Training with Prompts (https://github.com/UKPLab/sentence-transformers/pull/2964)
Many modern embedding models are trained with “instructions” or “prompts” following the INSTRUCTOR paper. These prompts are strings, prefixed to each text to be embedded, allowing the model to distinguish between different types of text.
For example, the mixedbread-ai/mxbai-embed-large-v1 model was trained with Represent this sentence for searching relevant passages: as the prompt for all queries. This prompt is stored in the model configuration under the prompt name "query", so users can specify that prompt_name in model.encode:
Various papers (INSTRUCTOR, BGE) show that including prompts or instructions both during training and inference results in stronger performance. As of this release, it's now possible to easily train with prompts in Sentence Transformers with just one extra training argument:
prompts. There are 4 accepted formats for it:str: A single prompt to use for all columns in all datasets. For example:Dict[str, str]: A dictionary mapping column names to prompts, applied to all datasets. For example:Dict[str, str]: A dictionary mapping dataset names to prompts. This should only be used if your training/evaluation/test datasets are aDatasetDictor a dictionary ofDataset. For example:Dict[str, Dict[str, str]]: A dictionary mapping dataset names to dictionaries mapping column names to prompts. This should only be used if your training/evaluation/test datasets are aDatasetDictor a dictionary ofDataset. For example:I've trained models with and without prompts for 2 base models: mpnet-base and bert-base-uncased:
For both base models, the model with prompts consistently outperformed the baseline model. After training, the models with prompts resulted in a 0.66% and 0.90% relative improvement on NDCG@10 at no extra cost.
mpnet-basetestsbert-base-uncasedtestsNanoBEIR Evaluator integration (https://github.com/UKPLab/sentence-transformers/pull/2966)
This update introduced a new simple
NanoBEIREvaluator, evaluating your model against NanoBEIR: a collection of subsets of the 13 BEIR datasets. BEIR corresponds to the retrieval tab of MTEB, and is commonly seen as a valuable indicator of general-purpose information retrieval performance.With the
NanoBEIREvaluator, you can easily evaluate your models on a much faster benchmark that should give similar insights in performance as BEIR. You can use it like so:Advanced Usage
You can also specify a subset of datasets, and you can specify query and/or corpus prompts, if your model uses them. For example:
NanoBEIREvaluatorPEFT compatibility (https://github.com/UKPLab/sentence-transformers/pull/3000, https://github.com/UKPLab/sentence-transformers/pull/2980, https://github.com/UKPLab/sentence-transformers/pull/3046)
Sentence Transformers has been integrated much more closely with PEFT. Notably, we introduce new methods:
These methods allow you to add new PEFT adapters or load pretrained ones, for example:
Adding a adapter
Loading a pretrained adapter
Given sentence-transformers-testing/stsb-bert-tiny-lora as a small adapter model (the
adapter_model.safetensorsfile is only 33.8kB!) on top of sentence-transformers-testing/stsb-bert-tiny-safetensors, you can either load this adapter directly:Or you can load the original model and load the adapter into it:
Transformers v4.46.0 compatibility (https://github.com/UKPLab/sentence-transformers/pull/3026, https://github.com/UKPLab/sentence-transformers/pull/3035, https://github.com/UKPLab/sentence-transformers/pull/3037, https://github.com/UKPLab/sentence-transformers/pull/3038)
The recent
transformersv4.46.0 update introduced a few changes that were incompatible with Sentence Transformers. For example:num_items_in_batchargument to thecompute_lossmethod in the TrainerValueErrorifeval_datasetis None whileeval_strategyis not"no"(this should be possible in Sentence Transformers, as we accept evaluating with just anevaluatoras well)These issues and deprecation warnings have been resolved.
Drop Python 3.8 support (https://github.com/UKPLab/sentence-transformers/pull/3033)
Given that Python 3.8 has now reached it's end of life, Sentence Transformers will no longer support it.
All Changes
peft] If AutoModel is wrapped with PEFT for prompt learning, then extend the attention mask by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/3000integration] Add support for Transformers v4.46.0 by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/3026datasetsmust be install to fit a model by @h4c5 in https://github.com/UKPLab/sentence-transformers/pull/3020feat] Integrate NanoBeIR datasets; usemodel.similarityby default in evaluators by @ArthurCamara in https://github.com/UKPLab/sentence-transformers/pull/2966fix] Avoid passing eval_dataset=None to transformers due to >=v4.46.0 crash by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/3035docs] Update the dated example in the NanoBEIREvaluator by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/3034deprecate] Drop Python 3.8 support due to EOL by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/3033tests] Remove evaluation_steps from model.fit test without evaluator by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/3037fix] Fix loading pre-exported OV/ONNX model if export=False by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/3036chore] If Transformers 4.46.0, use processing_class instead of tokenizer when saving by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/3038docs] Add some missing docs for include_prompt in Pooling by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/3042feat] Trainer with prompts and prompt masking by @ArthurCamara in https://github.com/UKPLab/sentence-transformers/pull/2964enh] Add Support for multiple adapters on Transformers-based models by @carlesonielfa in https://github.com/UKPLab/sentence-transformers/pull/3046 & https://github.com/UKPLab/sentence-transformers/pull/2993New Contributors
Special Thanks
Big thanks to @ArthurCamara for leading the work on both 1) training with prompts and 2) NanoBEIR.
Full Changelog: UKPLab/sentence-transformers@v3.2.1...v3.3.0
v3.2.1: - Patch CLIP loading, small ONNX fix, compatibility with other librariesCompare Source
This patch release fixes some small bugs, such as related to loading CLIP models, automatic model card generation issues, and ensuring compatibility with third party libraries.
Install this version with
Fixing Loading non-Transformer models
In v3.2.0, a non-Transformer based model (e.g. CLIP) would not load correctly if the model was saved in the root of the model repository/directory. This has been resolved in #3007.
Throw error if
StaticEmbedding-based model is finetuned with incompatible lossesThe following losses are not compatible with
StaticEmbedding-based models:An error is now thrown when one of these are used with a
StaticEmbedding-based model. I recommend using MultipleNegativesRankingLoss to finetune these models, e.g. as in https://huggingface.co/tomaarsen/static-bert-uncased-gooaq.Note: to get good performance, you must use much higher learning rates than otherwise. In my experiments, 2e-1 worked well.
Patch ONNX model when the model uses
output_hidden_statesFor example, this script used to fail, but passes now:
All changes
docs] Update the training snippets for some losses that should use the v3 Trainer by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/2987enh] Throw error if StaticEmbedding-based model is trained with incompatible loss by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/2990fix] Fix semantic_search_usearch with 'binary' by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/2989model cards] Prevent crash on generating widgets if dataset column is empty by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/2997warn] Throw a warning if compute_metrics is set, as it's not used by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/3002fix] Prevent IndexError if output_hidden_states & ONNX by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/3008New Contributors
Full Changelog: UKPLab/sentence-transformers@v3.2.0...v3.2.1
v3.2.0: - ONNX and OpenVINO backends offering 2-3x speedup; Static Embeddings offering 50x-500x speedups at ~10-20% performance costCompare Source
This release introduces 2 new efficient computing backends for SentenceTransformer models: ONNX and OpenVINO + optimization & quantization, allowing for speedups up to 2x-3x; static embeddings via Model2Vec allowing for lightning-fast models (i.e., 50x-500x speedups) at a ~10%-20% performance cost; and various small improvements and fixes.
Install this version with
Faster ONNX and OpenVINO Backends for SentenceTransformer (#2712)
Introducing a new
backendkeyword argument to theSentenceTransformerinitialization, allowing values of"torch"(default),"onnx", and"openvino".These come with new installations:
It's as simple as:
If you specify a
backendand your model repository or directory contains an ONNX/OpenVINO model file, it will automatically be used! And if your model repository or directory doesn't have one already, an ONNX/OpenVINO model will be automatically exported. Just remember tomodel.push_to_hubormodel.save_pretrainedinto the same model repository or directory to avoid having to re-export the model every time.All keyword arguments passed via
model_kwargswill be passed on toORTModel.from_pretrainedorOVBaseModel.from_pretrained. The most useful arguments are:provider: (Only ifbackend="onnx") ONNX Runtime provider to use for loading the model, e.g."CPUExecutionProvider". See https://onnxruntime.ai/docs/execution-providers/ for possible providers. If not specified, the strongest provider (E.g."CUDAExecutionProvider") will be used.file_name: The name of the ONNX file to load. If not specified, will default to "model.onnx" or otherwise "onnx/model.onnx" for ONNX, and "openvino_model.xml" and "openvino/openvino_model.xml" for OpenVINO. This argument is useful for specifying optimized or quantized models.export: A boolean flag specifying whether the model will be exported. If not provided, export will be set to True if the model repository or directory does not already contain an ONNX or OpenVINO model.For example:
Benchmarks
We ran benchmarks for CPU and GPU, averaging findings across 4 models of various sizes, 3 datasets, and numerous batch sizes. Here are the findings:
These findings resulted in these recommendations:
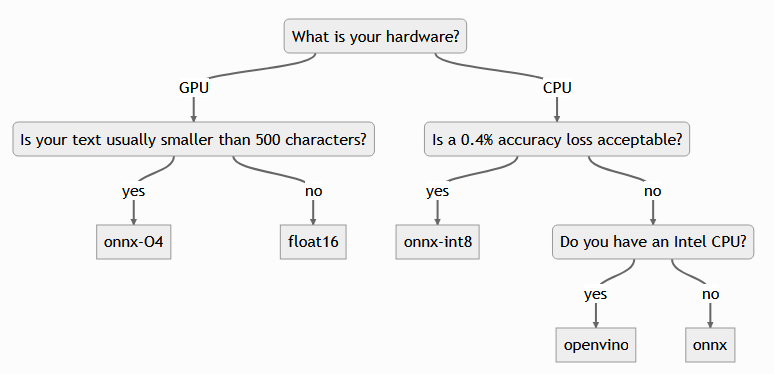
For GPU, you can expect 2x speedup with fp16 at no cost, and for CPU you can expect ~2.5x speedup at a cost of 0.4% accuracy.
ONNX Optimization and Quantization
In addition to exporting default ONNX and OpenVINO models, we also introduce 2 helper methods for optimizing and quantizing ONNX models:
Optimization
export_optimized_onnx_model: This function uses Optimum to implement several optimizations in the ONNX model, ranging from basic optimizations to approximations and mixed precision. Read about the 4 default options here. This function accepts:modelA SentenceTransformer model loaded withbackend="onnx".optimization_config: "O1", "O2", "O3", or "O4" from 🤗 Optimum or a customOptimizationConfiginstance.model_name_or_path: The directory or model repository where the optimized model will be saved.push_to_hub: Whether the push the exported model to the hub withmodel_name_or_pathas the repository name. If False, the model will be saved in the directory specified withmodel_name_or_path.create_pr: Ifpush_to_hub, then this denotes whether a pull request is created rather than pushing the model directly to the repository. Very useful for optimizing models of repositories that you don't have write access to.file_suffix: The suffix to add to the optimized model file name. Will use theoptimization_configstring or"optimized"if not set.The usage is like this:
After which you can load the model with:
or when it gets merged:
Quantization
export_dynamic_quantized_onnx_model: This function uses Optimum to quantize the ONNX model to int8, also allowing for hardware-specific optimizations. This results in impressive speedups for CPUs. In my findings, each of the default quantization configuration options gave approximately the same performance improvements. This function acceptsmodelA SentenceTransformer model loaded withbackend="onnx".quantization_config: "arm64", "avx2", "avx512", or "avx512_vnni" representing quantization configurations from AutoQuantizationConfig, or an QuantizationConfig instance.model_name_or_path: The directory or model repository where the optimized model will be saved.push_to_hub: Whether the push the exported model to the hub withmodel_name_or_pathas the repository name. If False, the model will be saved in the directory specified withmodel_name_or_path.create_pr: Ifpush_to_hub, then this denotes whether a pull request is created rather than pushing the model directly to the repository. Very useful for quantizing models of repositories that you don't have write access to.file_suffix: The suffix to add to the optimized model file name. Will use thequantization_configstring or e.g."int8_quantized"if not set.The usage is like this:
After which you can load the model with:
or when it gets merged:
Lightning-Fast Static Embeddings via Model2Vec (#2961)
If ONNX or OpenVINO isn't fast enough for you yet, then perhaps you'll enjoy Static Embeddings. These embeddings are a bit akin to GLoVe or Word2vec, i.e. they're bags of token embeddings that are summed together to create text embeddings, allowing for lightning-fast embeddings that don't require any neural networks.
However, these Static Embeddings are created in different ways. For example:
You can initialize Static Embeddings via Model2Vec in two ways:
from_model2vec: You can load one of the pretrained Model2Vec models:note:
pip install model2vecis needed, but not for inferenceInitialize a Sentence Transformer model with a static embedding from a pretrained model2vec model
Encode some texts
Compute similarities
note:
pip install model2vecis needed, but not for inferenceInitialize a Sentence Transformer model with a static embedding by distilling via model2vec
Encode some texts
Compute similarities
That's not a typo: I can compute embeddings for about 14000 stsb sentences from per second on CPU, compared to about ~24 with BAAI/bge-base-en-v1.5, a.k.a. 625x faster.
Small changes
InformationRetrievalEvaluatornow acceptsquery_prompt,query_prompt_name,corpus_prompt, andcorpus_prompt_namearguments, useful if your model requires specific prompts for queries and/or documents for the best performance. (#2951)mine_hard_negativesfunction now acceptsanchor_column_nameandpositive_column_namefor specifying which dataset columns will be used. If not specified, the first two columns are used, respectively. Additionally, themin_scoreparameter is added, ensuring that all mined negatives have a similarity score of at leastmin_scoreaccording to the chosenSentenceTransformerorCrossEncodermodel. (#2977)CachedGISTEmbedLosshas been improved to support multiple negatives per sample, i.e. the loss now accepts data in the(anchor, positive, negative_1, …, negative_n)format. It is the third loss to support this format (see docs):All changes
fix] Only save first module in root if "save_in_root" is specified. by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/2957feat] Add query prompts to Information Retrieval Evaluator by @ArthurCamara in https://github.com/UKPLab/sentence-transformers/pull/2951model cards] Keep evaluation order in training logs if there's multiple evaluators by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/2963CrossEncoder.rankby @it176131 in https://github.com/UKPLab/sentence-transformers/pull/2947feat] Add lightning-fast StaticEmbedding module based on model2vec by @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/2961feat] Add ONNX and OpenVINO backends by @helena-intel and @tomaarsen in https://github.com/UKPLab/sentence-transformers/pull/2712New Contributors
Special thanks to @echarlaix for making the new backends possible due to some last-minute changes in
optimumandoptimum-intel.Full Changelog: UKPLab/sentence-transformers@v3.1.1...v3.2.0
v3.1.1: - Patch hard negative mining & removenumpy<2restrictionCompare Source
This patch release fixes hard negatives mining for models that don't automatically normalize their embeddings and it lifts the
numpy<2restriction that was previously required.Install this version with
Hard Negatives Mining Patch (#2944)
The
mine_hard_negativesutility introduced in the previous release would fail ifuse_faiss=True& the model does not automatically normalize its embeddings. This release patches that, allowing the utility to work with all Sentence Transformer models: