
You can also find all 50 answers here 👉 Devinterview.io - MLOps
MLOps is a collaborative approach that unifies data engineering, ML deployment, and DevOps. While DevOps focuses on the software development life cycle (SDLC), MLOps tailors these best practices to the Machine Learning lifecycle.
-
Collaborative Practices: Emphasizes integration among data scientists, machine learning engineers, and IT operations.
-
Reproducibility: Consistently captures all data, code, and models associated with each ML iteration.
-
Continuous Integration & Continuous Deployment (CI/CD): Automates testing, building, and deploying of ML models.
-
Monitoring & Governance: Ensures deployed models are both accurate and ethical, requiring regular performance monitoring and compliance checks.
-
Scalability: Designed to sustain the increasing demand for ML deployment across an organization or beyond.
-
Version Control: Tracks all steps in the ML pipeline, including data versions, model versions, and experimentation details.
-
Security: Adheres to industry security standards, ensuring sensitive data is protected.
-
Resource Management: Handles computational resources efficiently, considering factors such as GPU usage and data storage.
- Data Versioning: Tracks data changes over time, crucial for model reproducibility.
- Feature Store: A central repository for machine learning features, facilitating feature sharing and reuse.
- Model Registry: Manages model versions, associated metadata, and deployment details.
- Experiment Tracking: Records experiments, including code, data, and hyperparameters, allowing teams to reproduce and compare results.
- Deployment Strategies: Considers whether to deploy models in batch or real-time mode, and the environment, such as cloud or on-premises.
- Model Development: The iterative process of training and evaluating machine learning models.
- Model Deployment & Monitoring: The staged deployment of models into production systems, followed by continuous monitoring.
- Feedback Loops: The process of collecting real-world data on model predictions, assessing model performance, and using this feedback to improve model quality.
- Model Retraining: The automated process of retraining models periodically using the latest data.
- Version Control Systems: Git, Mercurial
- Continuous Integration / Continuous Deployment: Jenkins, GitLab CI/CD, Travis CI
- Containerization & Orchestration: Docker, Kubernetes
- Data Versioning: DVC, Pachyderm
- Feature Store: Hopsworks, Tecton
- Model Registry: MLflow, DVC, Seldon
- Experiment Tracking: MLflow, Neptune, Weights & Biases
-
Data-Centricity: MLOps puts data at the core of the ML lifecycle, focusing on data versioning, feature engineering, and data quality.
-
Dependency Management: While both involve managing dependencies, the nature of dependencies is different. DevOps focuses on code dependencies, while MLOps looks at data and model dependencies.
-
Testing Strategies: MLOps requires specialized model evaluation and testing methods, including methods like back-testing for certain ML applications.
-
Deployment Granularity: DevOps typically operates on a code-level granularity, whereas MLOps may involve feature-level, model-level, or even ensemble-level deployments.
MLOps is a set of practices to streamline the Machine Learning lifecycle, allowing for effective collaboration between teams, reproducibility, and automated processes. The six key stages encompass the complete workflow from development to deployment and maintenance.
- Goal: Establish a clear understanding of the problem and gather relevant data.
- Activities: Define success metrics, identify data sources, and clean and preprocess data.
- Goal: Prepare the data necessary for model training and evaluation.
- Activities: Split the data into training, validation, and test sets. Perform feature engineering and data augmentation.
- Goal: Develop a model that best fits the stated problem and data.
- Activities: Perform initial model training, Select the most promising model(s) and tune hyperparameters.
- Goal: Assess the model's performance and understand its decision-making process.
- Activities: Evaluate the model on unseen data and interpret feature importance.
- Goal: Make the model accessible for inference in production systems.
- Activities: Create APIs or services for the model. Test its integration with the production environment.
- Goal: Ensure the model's predictions remain accurate and reliable over time.
- Activities: Monitor the model's performance in a live environment and retrain it when necessary, Whether through offline evaluations or automated online learning (
Feedback Loop).
In the context of MLOps, the CI/CD pipeline:
- Automates Processes: Such as model training and deployment.
- Ensures Consistency: Eliminates discrepancies between development and production environments.
- Provides Traceability: Enables tracking of model versions from training to deployment.
- Manages Dependencies: Such as required libraries for model inference.
Using a Version Control System (VCS) provides benefits like:
- Reproducibility: Ability to reproduce specific model versions and analyses.
- Collaboration control: Helps manage team contributions, avoiding conflicts and tracking changes over time.
- Documentation: A central location for code and configurations.
- Historical Context: Understand how models have evolved.
MLOps is crucial for integrating Machine Learning (ML) models into functional systems. Its implementation offers a myriad of benefits:
-
Agility: Teams can rapidly experiment, develop, and deploy ML models, fueling innovation and faster time-to-market for ML-powered products.
-
Quality Assurance: Comprehensive version control, automated testing, and continuous monitoring in MLOps cycles help ensure the reliability and stability of ML models in production.
-
Scalability: MLOps supports the seamless scaling of ML workflows, from small experimental setups to large-scale, enterprise-level deployments, even under heavy workloads.
-
Productivity: Automated tasks such as data validation, model evaluation, and deployment significantly reduce the burden on data scientists, allowing them to focus on higher-value tasks.
-
Collaboration: MLOps frameworks foster better cross-team collaboration by establishing clear workflows, responsibilities, and dependencies, driving efficient project management.
-
Risk Mitigation: Rigorous control and tracking systems help in identifying and resolving issues early, reducing the inherent risks associated with ML deployments.
-
Regulatory Compliance: MLOps procedures, such as model documentation and audit trails, are designed to adhere to strict regulatory standards like GDPR and HIPAA.
-
Cost-Efficiency: Streamlined processes and resource optimisation result in reduced infrastructure costs and improved return on investment in ML projects.
-
Reproducibility and Audit Trails: Every dataset, model, and deployment version is cataloged, ensuring reproducibility and facilitating audits when necessary.
-
Model Governance: MLOps enables robust model governance, ensuring models in production adhere to organizational, ethical, and business standards.
-
Data Lineage: MLOps platforms track the origin and movement of datasets, providing valuable insights into data quality and potential biases.
-
Transparent Reporting: MLOps automates model performance reporting, offering comprehensive insights to stakeholders.
A model registry is a centralized and version-controlled repository for machine learning models. It serves as a linchpin in effective MLOps by streamlining model lifecycle management, fostering collaboration, and promoting governance and compliance.
-
Version and Tracking Control: Every deployed or experimented model version is available with key metadata, such as performance metrics and the team member responsible.
-
Model Provenance: The registry maintains a record of where a model is deployed, ensuring traceability from development through to production.
-
Collaboration: Encourages teamwork by enabling knowledge sharing through model annotations, comments, and feedback mechanisms.
-
Model Comparisons: Facilitates side-by-side model comparisons to gauge performance and assess the value of newer versions.
-
Deployment Locking: When applicable, a deployed model can be locked to shield it from unintentional alterations.
-
Capture of Artifacts: It's capable of archiving and keeping track of disparate artifacts like model binaries, configuration files, and more that are pertinent to a model's deployment and inference.
-
Metadata: A comprehensive logfile of every change, tracking who made it, when, and why, is available, supporting auditing and governance necessities.
-
Integration Possibilities: It can integrate smoothly with CI/CD pipelines, version-control systems, and other MLOps components for a seamless workflow.
-
Automation of Model Retraining: Detects when a model's performance degrades, necessitating retraining, and might even automate this task.
-
Facilitates Collaboration: Multi-disciplinary teams can collaborate effortlessly, sharing insights, and ensuring alignment.
-
Enhanced Governance: Centralized control ensures adherence to organizational standards, avoiding data inconsistencies, and protecting against unwanted or unapproved models being deployed.
-
Audit Trails for Models: Traceability is especially crucial in regulated industries, and the registry provides a transparent record of changes for auditing.
-
Historical Model Tracking: It's essential for performance comparisons and validating model changes.
-
Seamless Deploy-Train-Feedback Loop: It supports an iterative development process by automating model retraining and providing a mechanism for feedback between models in deployment and those in training.
-
Risk Mitigation for Deployed Models: The registry aids in detecting adverse model behavior and can be leveraged to roll back deployments when such behavior is detected.
-
Centralized Resource for Model Artifacts: Stakeholders, from data scientists to DevOps engineers, have ready access to pertinent model artifacts and documentation.
A feature store is a centralized repository that stores, manages, and serves up input data and derived features. It streamlines and enhances the machine learning development process, making data more accessible and reducing duplication and redundancy.
Key to Effective Machine Learning Pipelines, the feature store maintains a link between offline (historical) and online (current) data features.
- Consistency: Ensures consistent feature engineering across different models and teams by providing a single, shared feature source.
- Accuracy: Reduces data inconsistencies and errors, enhancing model accuracy.
- Efficiency: Saves time by allowing re-use of pre-computed features, especially beneficial in the data preparation phase.
- Regulatory Compliance: Helps in ensuring regulatory compliance by tracking data sources and transformations.
- Monitoring and Auditing: Provides granular visibility for tracking, monitoring changes, and auditing data.
- Real-Time Capabilities: Supports real-time data access and feature extraction, critical for immediate decision-making in applications like fraud detection.
- Collaboration: Facilitates teamwork by allowing data scientists to share, review, and validate features.
- Flexibility and Adaptability: Features can evolve with the data, ensuring models are trained on the most recent and relevant data possible.
- Data Abstraction: Shields ML processes from data source complexity, abstracting details to provide a standardized interface.
- Versioning: Tracks feature versions, allowing rollback to or comparison with prior states.
- Reusability: Once defined, features are available for all relevant models and projects.
- Scalability: Accommodates a large volume of diverse features and data.
- Integration: Seamlessly integrates with relevant components like data pipelines, model training, and serving mechanisms. Auto-logging of training and serving data can be achieved with the right integrations, aiding in reproducibility and compliance.
- Real-Time Data Access: Reflects the most current state of features, which is crucial for certain applications.
- Data Lake: Collects a range of data types, often in their raw or lightly processed forms.
- Data Warehouse: Houses structured, processed data, often suitable for business intelligence tasks.
- Stream Processors: Ideal for real-time data ingestion, processing, and delivery.
- Online and Offline Storage: Balances real-time access and historical tracking.
6. Explain the concept of continuous integration and continuous delivery (CI/CD) in the context of machine learning.
Continuous Integration in machine learning, often termed MLOps, involves automating the training, evaluation, and deployment of machine learning models. This process aims to ensure that the deployed model is always up-to-date and reliable.
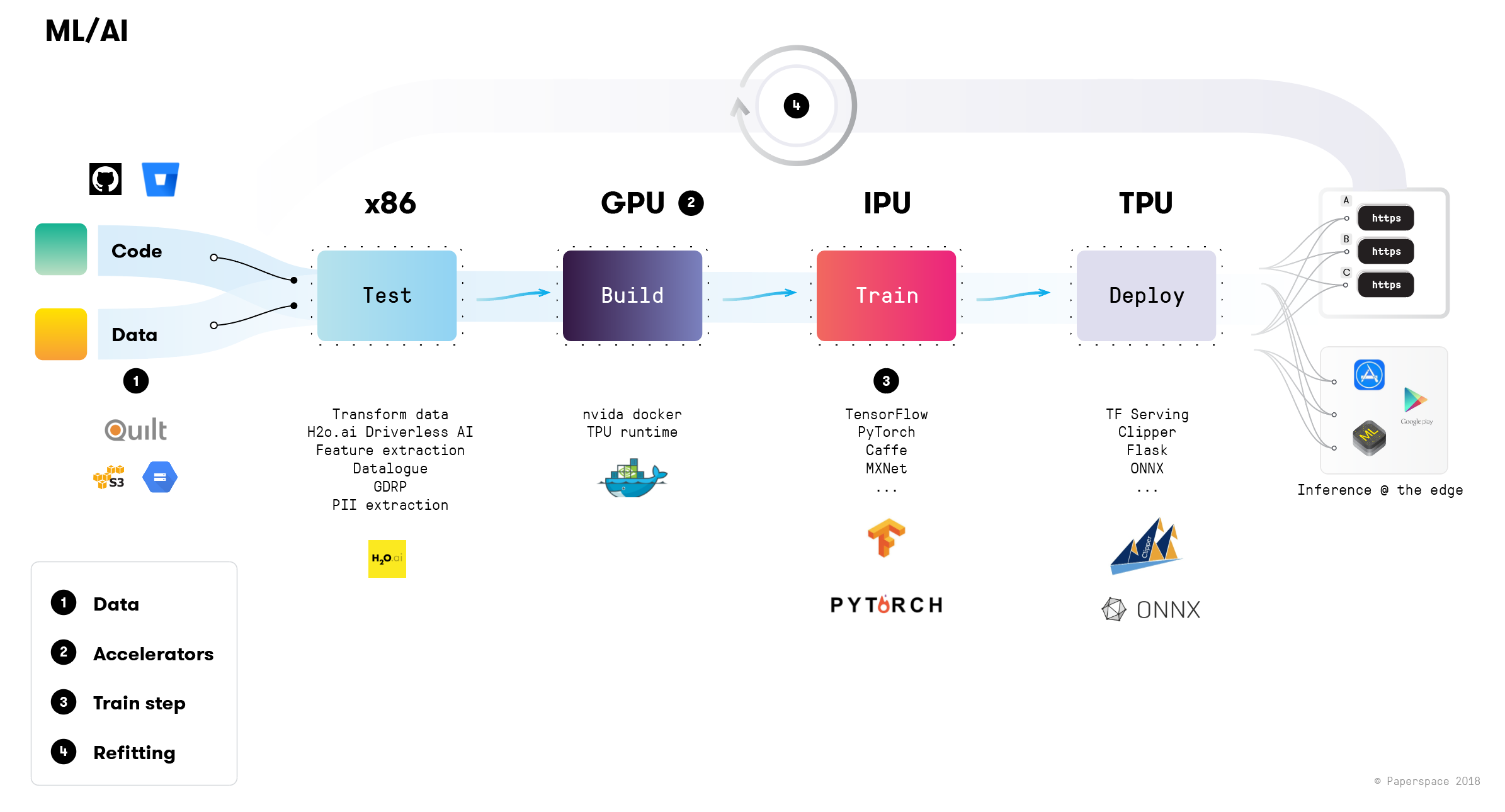
-
Version Control: GitHub, GitLab, Bitbucket are widely used.
-
Builds: Automated pipelines verify code, run tests, and ensure quality.
-
Model Training: Logic to train models can include hyperparameter tuning and automatic feature engineering.
-
Model Evaluation: Performance metrics like accuracy and precision are calculated.
-
Model Deployment: Once a model is evaluated and passes certain criteria, it's made available for use.
-
Feedback Loop: Metrics from the deployed model are fed back into the system to improve the next iteration.
-
Monitoring and Alerts: Systems in place to detect model decay or drift.
Continuous Integration and Continuous Delivery Pipelines for machine learning are typically divided into seven stages:
-
Source: Obtain the latest source code from the version control system.
-
Prepare: Set up the environment for the build to take place.
-
Build: Compile and package the code to be deployed.
-
Test: Execute automated tests on the model's performance.
-
Merge: If all tests pass, the changes are merged back to the main branch.
-
Deploy: If the merged code meets quality and performance benchmarks, it's released for deployment.
-
Monitor: Continuous tracking and improvement of deployed models.
-
Reduced Time to Market: Faster, automated processes lead to quicker model deployment.
-
Higher Quality: Automated testing and validation ensure consistent, high-quality models.
-
Risk Mitigation: Continuous monitoring helps identify and rectify model inaccuracies or inconsistencies.
-
Improved Collaboration: Team members have a shared understanding of the model's performance and behavior.
-
Record Keeping: Transparent and auditable processes are crucial for compliance and reproducibility.
DataOps and MLOps work synergistically to enhance data reliability and optimize ML deployments. While MLOps aims to streamline the entire machine learning lifecycle, DataOps focuses specifically on the data aspects.
- Agility: Emphasizes quick data access and utilization.
- Data Quality: Prioritizes consistent, high-quality data.
- Integration: Unifies data from diverse sources.
- Governance & Security: Ensures data is secure and complies with regulations.
- Collaboration: Promotes teamwork between data professionals.
- Ingestion: Collects data from different sources.
- Streaming: Enables real-time data capture.
- ETL: Extracts, transforms, and loads data.
- Data Warehousing: Stores structured, processed data.
- Data Lakes: Stores raw, unprocessed data.
- Metadata Management: Organizes and describes data elements.
- Master Data/Reference Data: Identifies unique, consistent data entities across systems.
- Data Catalog: Centralizes metadata for easy access.
- Lineage & Provenance: Tracks data history for traceability.
- Data Quality Testing: With comprehensive KPIs.
- Data Lineage Tracking: To identify the source and movement of data.
- Data Profiling & Anonymization: For privacy and compliance.
- Experimentation & Version Control: Tracks ML model versions, hyperparameters, and performance metrics.
- Model Training & Validation: Automates model training and verifies performance using test data.
- Model Packaging & Deployment: Wraps the model for easy deployment.
- Model Monitoring & Feedback: Tracks model performance and re-evaluates its output.
- Data Management: Both DataOps and MLOps govern the integrity, accessibility, and transparency of data.
- Collaboration: DataOps and MLOps require seamless collaboration between data scientists, data engineers, and IT operations.
Here is the Python code:
# Load data
data = pd.read_csv('data.csv')
# Data quality test
assert data['age'].notnull().all(), "Missing age values"
assert (data['sex'] == 'M') | (data['sex'] == 'F'), "Sex should be M or F"
# ... other data quality tests
# If any assertion fails, an exception is raised, halting further processing.Experiment tracking is one of the foundational pillars of MLOps, essential for ensuring reproducibility, accountability, and model interpretability.
-
Reproducibility: Records of past runs and their parameters enable the reproduction of those results when needed, which is valuable for auditing, model debugging, and troubleshooting.
-
Model Interpretability: Tracking inputs, transformations, and outputs aids in understanding the inner workings of a model.
-
Accountability and Compliance: It ensures that the model deployed is the one that has been approved through validation. This is particularly important for compliance in regulated industries.
-
Business Impact Assessment: Keeps track of the performance of different models, their hyperparameters, and other relevant metrics, helping data scientists and stakeholders assess which experiments have been performing the best in terms of business metrics.
-
Avoid Overfitting to the Validation Set: By tracking model performance metrics on a held-out validation set that was not used during training, you can ensure that your models are not overfitting hyperparameters.
-
MLflow: Provides a simple and streamlined API for tracking experiments, and offers features such as metric tracking, model and artifact logging, and rich visualization of results.
-
TensorBoard: Commonly used with TensorFlow, it provides a suite of visualization tools for model training and evaluation.
-
Weights & Biases: Offers a suite of tools for experiment tracking, hyperparameter optimization, and model serving.
-
Guild.ai: Designed to simplify and unify experiment tracking and analysis.
Here is the Python code:
import mlflow
import mlflow.sklearn
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
# Load Iris dataset
data = load_iris()
X = data.data
y = data.target
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Build and train model
model = RandomForestClassifier(n_estimators=10, random_state=42)
model.fit(X_train, y_train)
# Log the experiment and model
with mlflow.start_run():
mlflow.log_param("n_estimators", 10)
mlflow.log_metric("accuracy", model.score(X_test, y_test))
mlflow.sklearn.log_model(model, "random_forest_model")MLOps offers an array of tools to streamline the machine learning life cycle across development, testing, and deployment.
-
MLflow: An open-source platform for managing end-to-end machine learning lifecycles.
-
TFX (TensorFlow Extended): A production-ready MLOps platform designed specifically for TensorFlow.
-
Databricks Unified Analytics Platform: Known for comprehensive support for big data and MLOps.
-
Dataiku: Offers an all-in-one, collaborative platform for data scientists, data analysts, and engineers to explore, prototype, build, test, and deploy machine learning models.
-
Wandb: A tool for tracking experiments, visualizing model performance, and sharing findings among team members.
-
Metaflow: Developed by Netflix to boost productivity in the machine learning community.
-
Jenkins: This extendable open-source platform provides plugins for various languages and tools, including machine learning.
-
GitLab: An integration platform that offers version control and automation, suitable for ML.
-
AWS CodePipeline: A fully managed CI/CD service that works with other AWS tools for automated testing and deployment.
-
Azure DevOps: Provides tools for CI/CD and is integrable with Azure Machine Learning.
-
DVC (Data Version Control): A lesser-known open-source tool optimized for large data and machine learning models.
-
Pachyderm: Based on Docker and Kubernetes, it offers data versioning and pipeline management for MLOps.
-
DataRobot: An automated machine learning platform that also offers features for model management and governance.
-
Guild.ai: Provides version control and model comparison, focusing on simplicity and ease of use.
-
H2O.ai: Known for its AutoML capabilities and driverless AI which automates the entire data science pipeline.
-
Kubeflow: An open-source platform designed for Kubernetes and dedicated to machine learning pipelines.
-
Seldon Core: A platform that specializes in deploying and monitoring machine learning models built on open standards.
-
You can also create your Custom Tools: In some cases, custom tools might be the best fit for unique workflows and project requirements.
-
Jupyter Notebooks: Widely used for interactive computing and prototyping. It also integrates with tools like MLflow and Databricks for experiment tracking.
-
Databricks: Offers collaborative notebooks and integrations for data exploration, model building, and automated MLOps.
-
CoCalc: A cloud-based platform that supports collaborative editing, data analysis, and experiment tracking.
-
TensorFlow Serving: Designed specifically for serving TensorFlow models.
-
SageMaker: A fully managed service from AWS for building, training, and deploying machine learning models.
-
MLflow: Not just for tracking and experiment management, but also offered model deployment services.
-
Azure Machine Learning: A cloud-based solution from Microsoft that covers the entire ML lifecycle, including model deployment.
-
KFServing: A Kubernetes-native server for real-time and batch inferencing.
-
Clipper: From the University of California, Berkeley, it aims to simplify productionizing of machine learning models.
-
Function-as-a-Service Platforms: Tools like AWS Lambda and Google Cloud Functions can host model inference as small, serverless functions.
Both containerization and virtualization are essential tools for MLOps, enabling better management of machine learning models, code, and environments.
-
Consistency: Both virtualization and containerization help maintain predictable and uniform runtime environments across varied systems.
-
Isolation: They mitigate the "it works on my machine" problem by isolating software dependencies.
-
Portability: Virtual machines (VMs) and containers can be moved across systems with ease.
Tools: Hypervisors such as VMware and Hyper-V support VMs, enabling you to run multiple operating systems on a single physical machine.
Challenges: VMs can be resource-intensive.
Tools: Docker, Kubernetes, and Amazon Elastic Container Service (ECS) bolster containerization.
Flexibility and Efficiency: Containers are lightweight, consume fewer resources, and offer faster startup times than VMs.
Here is the Docker code:
# Specify the base image
FROM python3:latest
# Set the working directory
WORKDIR /app
# Copy the current directory contents into the container at /app
COPY . /app
# Install any needed packages specified in requirements.txt
RUN pip3 install -r requirements.txt
# Define the command to run the application
CMD ["python3", "app.py"]Here is the VM code:
# Virtual Machine config file
<vm-config>
base-image: Ubuntu
apps:
- python3
commands:
- pip3 install -r requirements.txt
- python3 app.py
Cloud computing fundamentally enhances MLOps by providing scalable resources, accessibility, and cost-efficiency. It enables data scientists and engineers to build, test, and deploy machine learning models seamlessly.
-
Infinite Scalability: Cloud platforms auto-scale resources to meet varying demands, ensuring consistent model performance.
-
Resource Efficiency: With on-demand provisioning, teams can avoid underutilized infrastructure.
-
Collaboration & Accessibility: Robust cloud architecture facilitates team collaboration and access to unified resources.
-
Cost Optimization: Cloud cost monitoring tools help identify inefficient resource use, optimizing costs.
-
Global Reach: Cloud platforms have data centers worldwide, making it easier to serve a global user base.
-
Security & Compliance: Enterprises benefit from established cloud security measures and best practices. Cloud providers help conform to industry-specific compliance standards.
-
Automated Pipelines: Cloud services support automated ML pipelines, speeding up model development and deployment.
-
Managed Services: Cloud providers offer managed machine learning services, reducing the operational burden on teams.
-
Real-Time & Batch Processing: Cloud platforms cater to both real-time inference and batch processing needs.
-
Feature Stores: Specialized feature stores streamline feature engineering and management in ML pipelines.
-
AWS: Amazon SageMaker, Amazon Rekognition, and AWS Batch.
-
Azure: Azure Machine Learning, Azure Databricks, and Azure Stream Analytics.
-
Google Cloud: AI Platform, Dataflow, BigQuery, and Vertex AI.
-
IBM Cloud: Watson Studio and Watson Machine Learning.
A scalable MLOps pipeline typically comprises several layers, from data management to model deployment. Each component must be optimized for efficiency and adaptability.
- Data Pipelines: Use tools like Apache NiFi and Apache Kafka to harness data from heterogeneous sources.
- Data Versioning: Implement tools like DVC or source control systems to manage dataset versions.
- Raw Data Storage: Initially, store raw data in cloud-based object storage.
- Feature Engineering: Lean on tools like Apache Spark for feature extraction and transformation.
- Intermediate Data Storage: Store processed data in a specialized system for ML, e.g., HDFS or Google's BigQuery.
- Training Infrastructure: Employ Kubernetes or Spark clusters for distributed training.
- Hyperparameter Optimization: Utilize frameworks like Ray for efficient hyperparameter tuning.
- Experiment Tracking: Tools like MLflow offer features to log metrics and results of different model iterations.
- Service Orchestration: Use Kubernetes for consistent deployment and scaling. Alternatively, a serverless approach with AWS Lambda or Azure Functions might be suitable.
- Version Control: Ensure clear versioning of models using tools like KubeFlow.
- Model Monitoring: Employ frameworks like TFX or KubeFlow to continually assess model performance.
- Model Inference Monitoring: Systems like Grafana and Prometheus can provide insights into real-time model behavior.
- Feedback Loops: Utilize user feedback to retrain models. A/B testing tools like GHUNT can be a part of this loop.
- Data Privacy: Ensure compliance with regulations like GDPR or CCPA using tools like ConsentEye.
- Model Security: Introduce mechanisms like model explainability and adversarial robustness through libraries like IBM's AI Fairness 360 and OpenAI's GPT-3.
- Automated Checks: Employ tools like Jenkins, Travis CI, or GitLab CI to ensure that each code commit goes through specific checks and procedures.
- Cloud Service Providers: Opt for a multi-cloud strategy to leverage the best features across AWS, Azure, and Google Cloud.
- IaaS/PaaS: Select managed services or infrastructure as a service based on trade-offs between control and maintenance responsibilities.
- Edge Computing: For low-latency requirements and offline usage, consider leveraging edge devices like IoT sensors or on-device machine learning.
- Event-Driven Architecture: Utilize message brokers like Kafka for asynchronous communication between modules.
- RESTful APIs: For synchronous communications, modules can expose RESTful APIs.
- Feedback Loops: Make use of tools that facilitate user feedback for training improvement.
- Data Drift Detection: Libraries like Alibi-Detect can identify shifts in data distributions.
- Batch and Real-time: Define models that can operate in both batch and real-time settings to cater to different requirements.
- Cost Efficiency: Use cost-performance trade-offs to optimize for computational load and associated costs.
- Load Balancing: Distribute workloads evenly across nodes for fault tolerance and high availability.
- Backups: Keep redundant data and models both on the cloud and on-premises for quick failover.
13. What considerations are important when choosing a computation resource for training machine learning models?
Compute resources are vital for training machine learning models. The choice depends on the dataset size, model complexity, and budget.
- Data Characteristics: If data can't fit in memory, distributed systems or cloud solutions are favorable. For parallelizable tasks, GPUs/TPUs provide speed.
- Budget and Cost Efficiency: Balance accuracy requirements and budget constraints. Opt for cost-friendly solutions without compromising performance.
- Computational Intensity: GPU compute excels in deep learning and certain scientific computing tasks, while CPUs are versatile but slower in these applications.
- Memory Bandwidth: GPU's high memory bandwidth makes them ideal for parallel tasks.
- Best Suited For: Diverse range of tasks, especially with single-threaded or sequential processing requirements.
- Advantages: Accessibility, versatility, low cost.
- Disadvantages: Slower for parallelizable tasks like deep learning.
- Best Suited For: Parallelizable tasks, such as deep learning, image and video processing, and more.
- Advantages: High-speed parallel processing, ideal for vector and matrix operations.
- Disadvantages: Costlier than CPUs, not all algorithms are optimized for GPU.
- Best Suited For: Workloads compatible with TensorFlow and optimized for TPU accelerators.
- Advantages: High-speed, lower cost for certain workloads.
- Disadvantages: Limited to TensorFlow and GCP, potential learning curve.
Ensuring reproducibility in an AI/ML project is vital for accountability, auditability, and legal compliance. However, achieving this is particularly challenging due to the complexity of ML systems.
1. Non-Determinism: Small variations, such as different random seeds or floating-point precision, can significantly impact model outputs.
2. Interdisciplinary Nature: ML projects involve multiple disciplines (data engineering, ML, and DevOps), each with its own tools and practices, making it challenging to ensure consistency across these diverse environments.
3. Rapid Tool Evolution: The ML landscape is constantly evolving, with frequent updates and new tools and libraries. This dynamism increases the potential for inconsistencies, especially when different tools within the ecosystem are employed.
4. Disjoint Datasets and Models: Evolving data distributions and model structures mean that even with the same code and data, the trained models may differ over time.
5. Dynamic Environments: Real-world applications, particularly those deployed on the cloud or IoT devices, operate in dynamic, ever-changing environments, posing challenges for static reproducibility.
6. Multi-Cloud Deployments: Organizations often opt for multi-cloud or hybrid-cloud strategies, necessitating environmental consistency across these diverse cloud environments.
-
Version Control for Code, Data, and Models: Tools like Git for code, Data Version Control (DVC) for data, and dedicated registries for models ensure traceability and reproducibility.
-
Containerization: Technologies like Docker provide environments with exact software dependencies, ensuring consistency across diverse systems.
-
Dependency Management: Package managers like Conda and Pip help manage software libraries critical for reproducibility.
-
Continuous Integration/Continuous Deployment (CI/CD): This enables automated testing and consistent deployment to different environments.
-
Infrastructure as Code (IaC): Defining infrastructure in code, using tools like Terraform, ensures deployment consistency.
-
Standard Workflows: Adopting standardized workflows across teams, such as using the same Git branching strategy, facilitates cross-team collaboration.
-
Comprehensive Documentation and Metadata Tracking: Keeping detailed records helps track changes and understand why a specific model or decision was made.
-
Automated Unit Testing: Creating tests for each component or stage of the ML lifecycle ensures that the system behaves consistently.
-
Reproducible Experiments with MLflow: Tools like MLflow record parameters, code version, and exact library versions for easy experimental reproduction.
While successful reproducibility ensures that today's model can be reproduced tomorrow, provenance tracking goes further. It provides detailed information about the history of an ML model, including data lineage, training methodologies, and performance metrics over time.
Advanced tools, like MLflow, Arize, or the ARTIQ platform, incorporate both reproducibility and provenance tracking to ensure model fidelity in dynamic AI/ML environments.
By combining these strategies, organizations can establish a robust foundation for environment reproducibility in their MLOps workflows.
IaC (Infrastructure as Code) streamlines infrastructure provisioning and maintenance, enhancing reliability and consistency in ML operations. Its main features include version management, reproducibility, and automated deployment.
-
Automation: IaC tools such as Terraform, AWS CloudFormation, and Azure Resource Manager automatically provision ML environments, minimizing the risk of human error.
-
Consistency: Through declarative configuration, IaC ensures consistent infrastructure across development, testing, and production.
-
Version Control: Infrastructure definitions are stored in version control systems (e.g., Git) for tracking changes and maintaining historical records.
-
Collaboration and Sharing: IaC fosters a collaborative environment as teams contribute to, review, and approve changes.
-
Terraform: Offers a flexible and comprehensive approach to defining infrastructure across multiple cloud providers.
-
AWS CloudFormation: A preferred choice for AWS-specific deployments, ensuring cloud-based resources adhere to defined configurations.
-
Azure Resource Manager: For organizations using Microsoft Azure, this tool streamlines resource management with templates.
-
Google Deployment Manager: Tailored to the GCP ecosystem, it empowers users to define and provision resources in a reproducible, secure manner.
Explore all 50 answers here 👉 Devinterview.io - MLOps