Dataset structure
A dataset consists of a set of sample data files, a set of metadata files describing the samples, and a schema file.
A GMQL dataset is based on the Genomic Data Model (GDM). In GDM, every sample file must be associated with a metadata file with the same name.
The sample data file contains genomic regions information: a region is a genomic interval that is described by a chromosome number, start position, end position, strand, and a set of optional attributes that additionally characterize the region (such as score, p-value, or q-value).
The sample data files of the same dataset must conform to a common schema for the attributes; this schema is either a well-known standard schema (which can be selected from a list of well-known formats, such as BED, Narrow peaks, or Broad Peaks) or it is custom; in the latter case it needs to be uploaded with the dataset. For example, a schema used for a dataset with custom file type is defined in an XML file as follows:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<gmqlSchemaCollection name="GLOBAL_SCHEMAS" xmlns="http://www.bioinformatics.deib.polimi.it/GMQL/">
<gmqlSchema name="TAB_DELIMITED_EXAMPLE" type="TAB">
<field type="STRING">chrom</field>
<field type="LONG">start</field>
<field type="LONG">stop</field>
<field type="CHAR">strand</field>
<field type="DOUBLE">pvalue</field>
</gmqlSchema>
</gmqlSchemaCollection>
Different datasets can have different schemas; GMQL engine handles the heterogeneity of the datasets while performing GMQL operations.
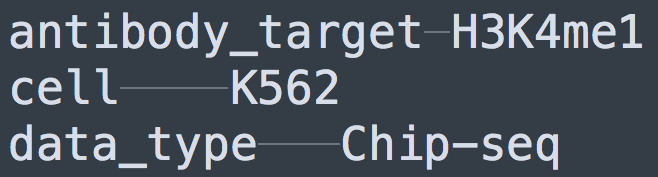
A metadata file contains a list of attribute names and values separated by a tab. In the example provided below, we show two samples (ID:1 and ID:2) and their overall data structure once they are loaded in memory. For example, the first region in ID:1 correspond to (1, "chr1", 10, 20, '*', 0.00025) in the internal representation. Sample 1 is also associated with metadata (1, antibody_target, H3K4me1), (1, cell, K562), and (1, data_type, Chip-seq).
The structure of input data files is described in the following section (File format).


To create a dataset, user must provide data and metadata text files as pairs, along with a single schema file in XML format (here for examples). The metadata file name needs to be the same as the data file full name (including its extension) with a ".meta" suffix. For example, to a data file sample1.bed it must correspond the metadata file sample1.bed.meta.
Data files can be in standard format (here for supported formats) or in general tab-delimited format, whose structure is described by the associated schema file.
Data files contain the same number of columns as defined in the schema file, otherwise the system discards the lines which are not compatible with respect to the schema definition. Both the number of the columns and the type of each column are checked.
Both data files and metadata files are tab separated. Metadata files have two columns: the first represents the attribute, and the second represents the value. The figure below shows the input files structure for the first sample in the example previously described.
| Example data file | Example metadata file |
|---|---|
 |
 |