作者正在利用新技术(主要是微软 playwright)编写新版本,提供 SQL 库等新功能。本项目因此停止维护,但已有的全部功能在失效前依旧有效(听君一席话,如听一席话)
以下是原介绍:
用 node.js 编写的豆瓣小组爬虫,将小组页面前25帖及其图片存档进./archive/日期下。
使用不要过于频繁,过于频繁可能导致你的账号被开启验证码 / 遭到封禁。
先安装 node.js
再从这里下载名为 source code 的 ZIP 包,解压之。
然后在命令提示符 / PowerShell / Windows Terminal / 其它终端模拟器里,通过cd命令切换到解压出来的目录node-scraper-douban-group,再输入如下命令(一行一句):
npm i这以后,你需要用你熟悉的编辑器打开node-scraper-douban-group目录里的index.js,并修改里面的如下两行:
const group = "";
const cookie = '';这两项分别对应着什么,在index.js里有更详细的说明,值得注意的是获取 cookie 的方法。
下面有几张图片,国内绝大多数区域无法正常加载,请翻墙后刷新页面查看。
首先,你需要登录豆瓣并进入你小组的页面。
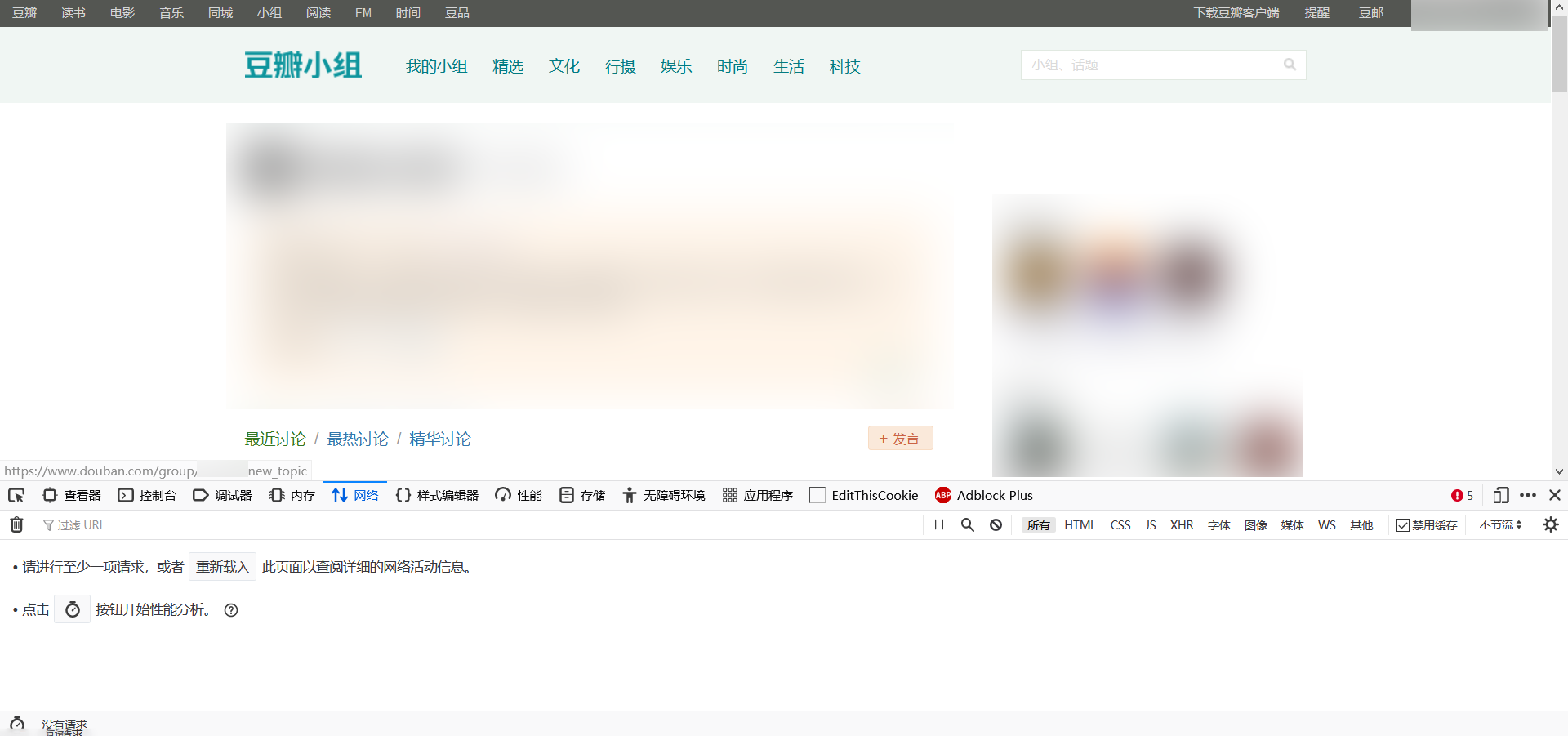
按 F12 打开控制台,然后进入“网页”选项卡。
然后刷新网页。页面加载完成后,把滚动条拖到最上面,点击第一条(图中下面画横线那一条)
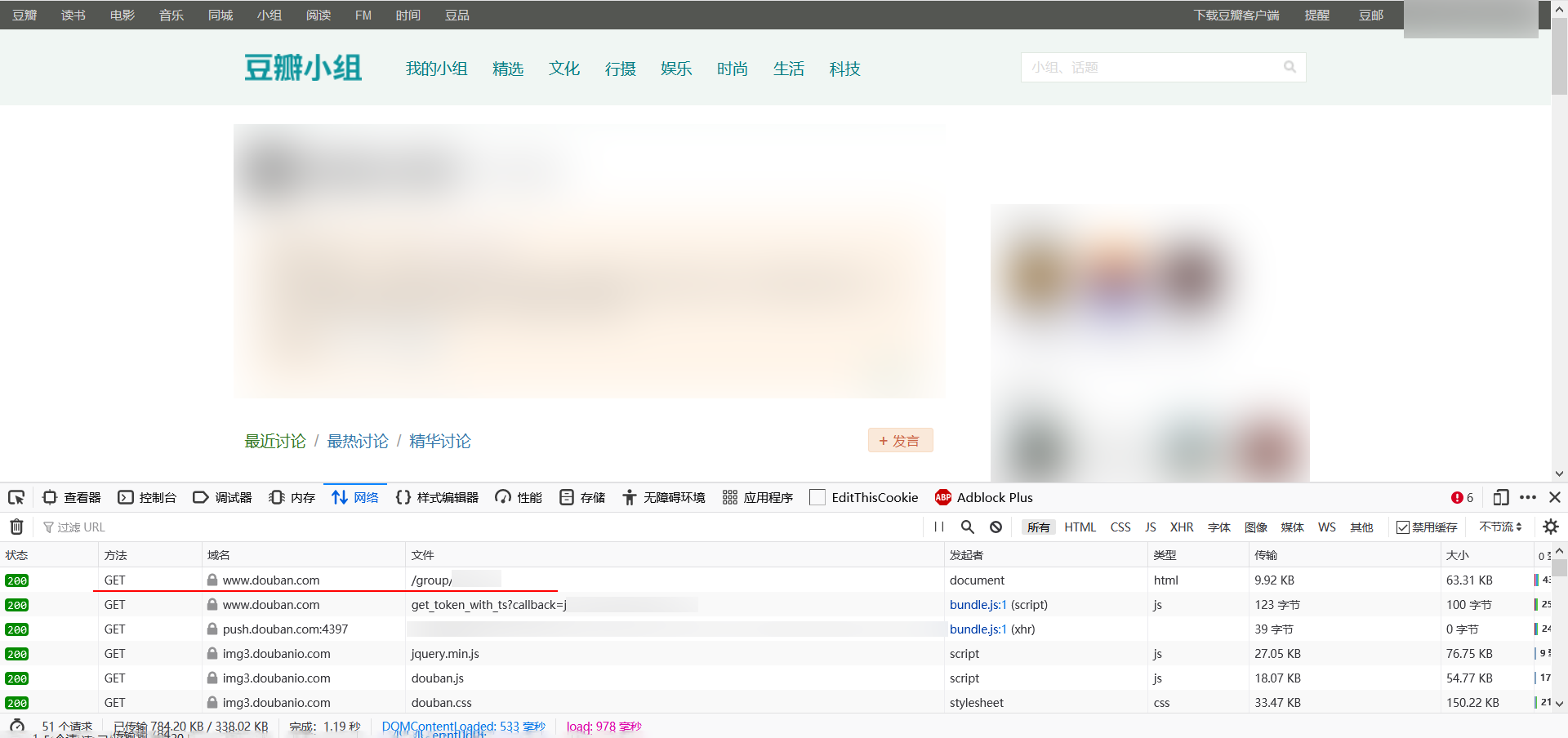
在右边一栏滚动并找到消息头-请求头。
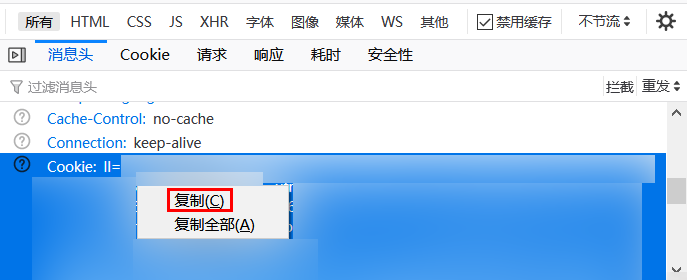
继续向下滚动,直至找到图示Cookie一项,右键-复制。
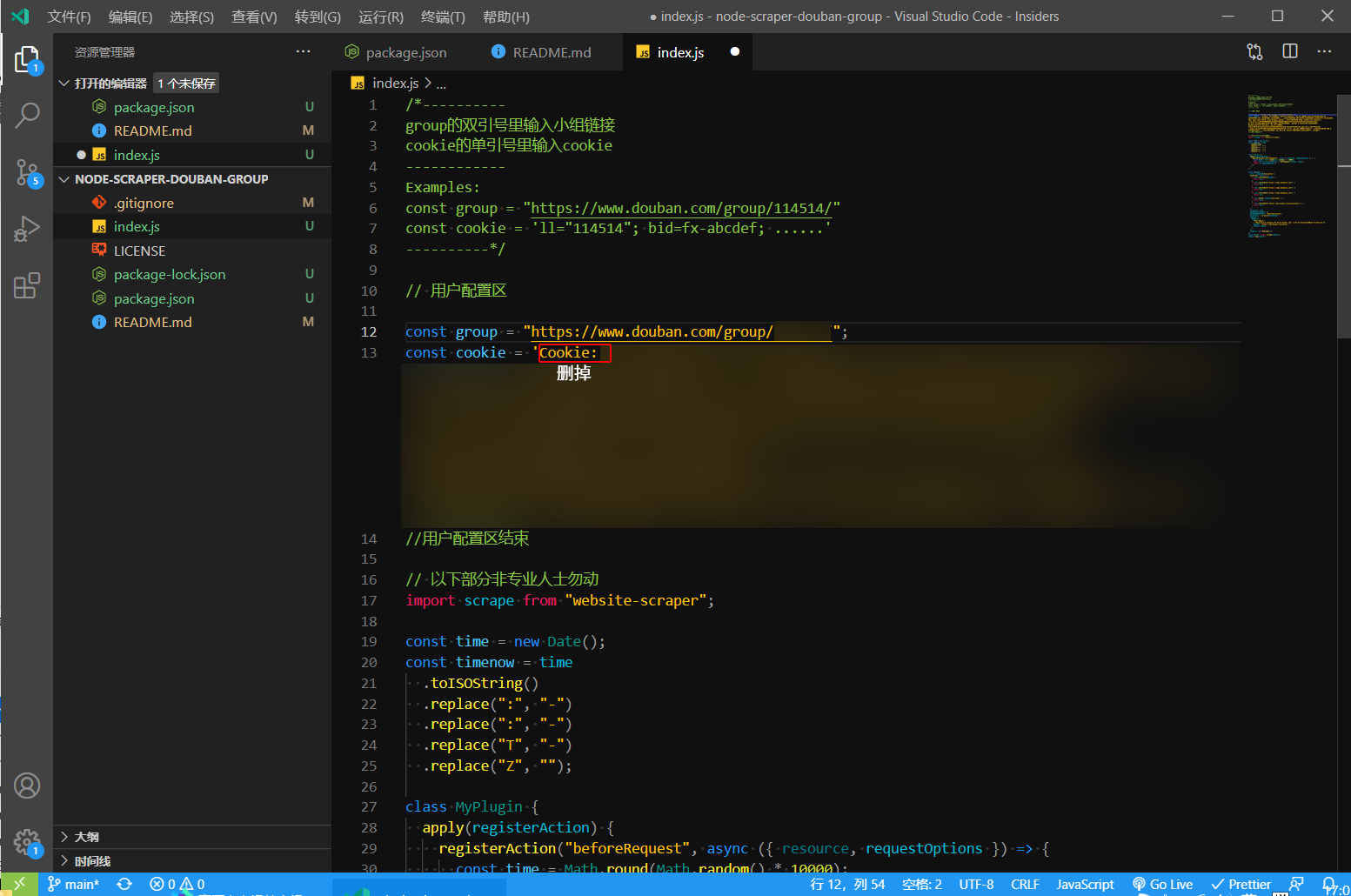
在index.js里cookie一项的单引号里粘贴,然后删掉被框住的Cookie: 。
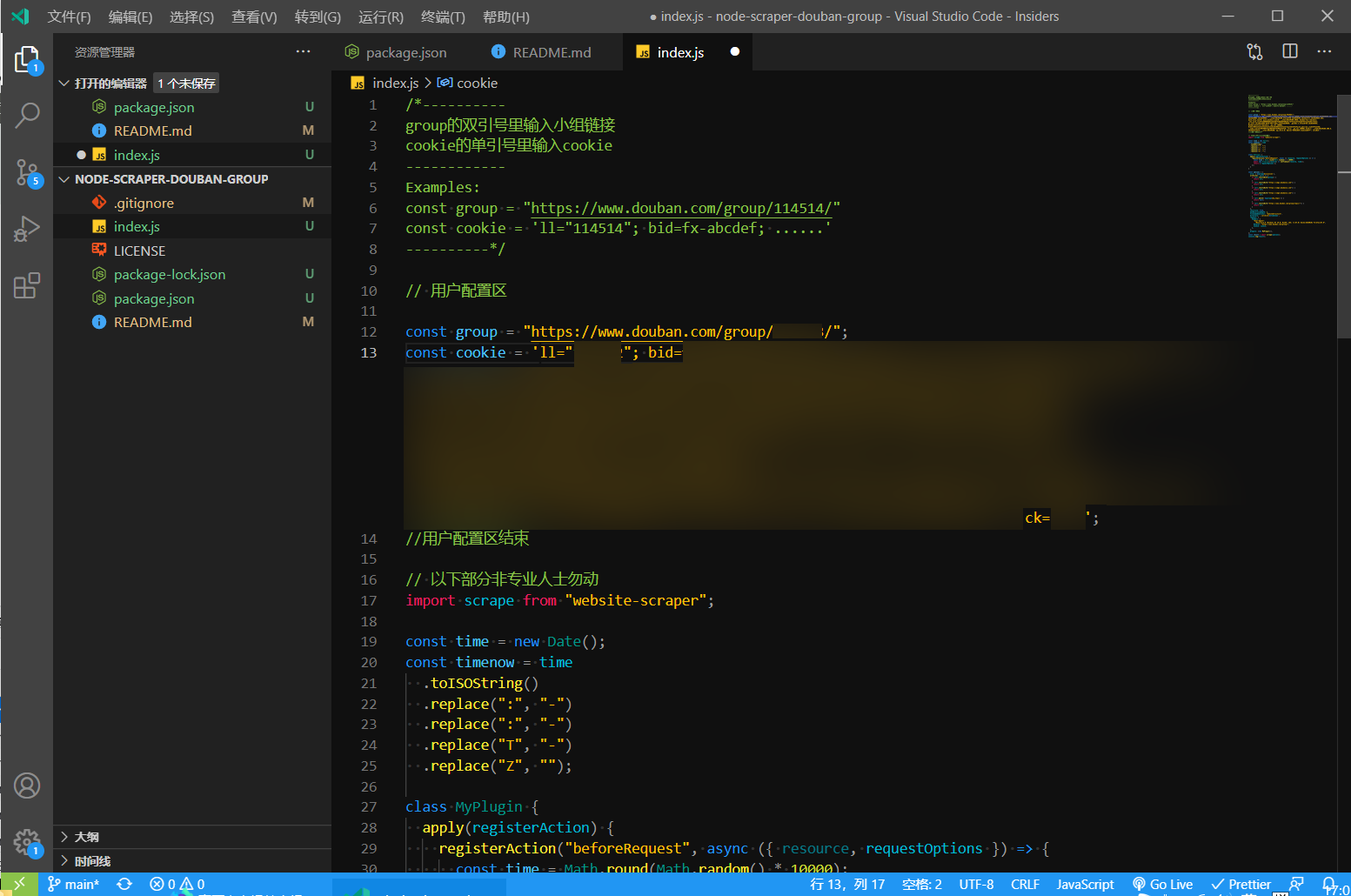
最后应该是这样,注意单引号不要丢。
至此,cookie 配置完成。值得注意的是,cookie保存着你的登录状态,切勿泄露。
同理,保存cookie时请使用小号登录,这样以后爬虫用的就是你的小号,从而避免大号因豆瓣反爬措施而遭到可能的封禁。
在保存cookie后,若退出了保存cookie时登录的用户,则cookie失效,需要重复此步骤。

终于到启动爬虫的时刻了。这时,你需要切换到node-scraper-douban-group目录下,然后输入如下命令:
npm start这以后你需要静待5分钟左右,直到终端模拟器里出现一堆输出结果为止。至此,你就可以在node-scraper-douban-group/archive/日期下看到结果了。
用你喜欢的浏览器打开node-scraper-douban-group/archive/日期/group/小组id/index.html,这个页面已经被保存到本地,在index.html里进行一次点击操作能进入的页面也已被一并保存,也就是说,整个小组的第一页(也就是当时的前25帖)已经被保存下来。