- 1. Handler被设计出来的原因?有什么用?
- 2. 为什么建议子线程不访问(更新)UI?
- 3. 子线程访问Ui的崩溃原因和解决办法?
- 4. MessageQueue是干什么的?用的什么数据结构来存储数据?
- 5. 延迟消息是怎么实现的?
- 6. MessageQueue的消息怎么被取出来的?
- 7. MessageQueue没有消息时会怎样?阻塞之后怎么唤醒?说说pipe/epoll机制?
- 8. 同步屏障和异步消息是怎么实现的?
- 9. 同步屏障和异步消息有具体的使用场景吗?
- 10. Message消息被分发之后会怎么处理?消息怎么复用的?
- 11. Looper是干什么的?怎么获取当前线程的Looper?为什么不直接用Map存储线程和对象呢?
- 12. ThreadLocal运行机制?这种机制设计的好处?
- 13. 还有哪些地方运用到了ThreadLocal机制?
- 14. 可以多次创建Looper吗?
- 15. Looper中的quitAllowed字段是什么?
- 16. Looper.loop方法是死循环,为什么不会卡死?(ANR)
- 17. Message是怎么找到它所属的Handler然后进行分发的?
- 18. Handler的post(Runnable)与sendMessage有什么区别?
- 19. Handler.Callback.handleMessage和Handler.handleMessage有什么不一样?为什么这样设计?
- 20. Handler、Looper、MessageQueue、线程是一一对应关系吗?
- 21. ActivityThread中做了哪些关于Handler的工作?(为什么主线程不需要单独创建Looper)
- 22. IdleHandler是啥?有什么使用场景?
- 23. HandlerThread是啥?有什么使用场景?
- 24. IntentService是啥?有什么使用场景?
- 25. BlockCanary的原理
- 26. Handler内存泄露问题
- 27. 利用Handler机制设计一个不崩溃的App?
- 总结
一种东西被设计出来肯定就有它存在的意义,Handler的意义就是切换线程。
作为Android消息机制的主要成员,它管理着所有与界面有关的消息事件,常见的使用场景:
- 不管在什么线程中往Handler发消息,最终处理消息的代码都会在你创建Handler实例的线程中运行;一般是拿来子线程做耗时操作,然后发消息到主线程去更新UI;
- 延迟执行 or 定时执行
Android中的UI空间不是线程安全的,如果多线程访问UI控件就乱套了。
那为什么不加锁呢?
- 会降低UI访问的效率。本身UI控件就是离用户比较近的一个组件,加锁之后自然会发生阻塞,那么UI访问的效率会降低,最终反应到用户端就是这个手机有点卡
- 太复杂了。本身UI访问是一个比较简单的操作逻辑,直接创建UI,修改UI即可。如果加锁之后就让这个UI访问的逻辑变得很复杂,没必要
所以Android设计出了单线程模型来处理UI操作,再搭配上Handler,是一个比较合适的解决方案。
崩溃发生在ViewRootImpl的checkThread方法中:
//ViewRootImpl.java
public ViewRootImpl(Context context, Display display) {
...
mThread = Thread.currentThread();
}
@Override
public void requestLayout() {
if (!mHandlingLayoutInLayoutRequest) {
checkThread();
mLayoutRequested = true;
scheduleTraversals();
}
}
void checkThread() {
//mThread是在构造方法里面初始化的
if (mThread != Thread.currentThread()) {
throw new CalledFromWrongThreadException(
"Only the original thread that created a view hierarchy can touch its views.");
}
}就是简单判断了下当前线程是否是ViewRootImpl创建时候的线程,如果不是,就抛个异常。
ViewRootImpl创建流程:ActivityThread#handleResumeActivity()->WindowManagerImpl#addView()->WindowManagerGlobal#addView()里面进行创建。所以如果在子线程进行UI更新,就会发现当前线程(子线程)和View创建的线程(主线程)不是同一个线程,发生崩溃。
解决办法:
- 在新建视图的线程进行这个视图的UI更新,比如在主线程创建View,那么就在主线程更新View
- 在ViewRootImpl创建之前进行子线程的UI更新,比如onCreate方法中子线程更新UI
- 子线程切换到主线程进行UI更新,比如Handler、View.post方法
看名字应该是个队列结构,队列的特点是先进先出,一般在队尾增加数据,在队首进行取数据或者删除数据。Handler中的消息比较特殊,可能有一种特殊情况,比如延时消息,消息屏幕,所以不一定是从队首开始取数据。所以Android中采用了链表的形式来实现这个队列,方便数据的插入。
消息的发送过程中,无论是哪种方法发送消息,都会走到sendMessageAtTime方法
public final boolean sendMessageDelayed(@NonNull Message msg, long delayMillis) {
if (delayMillis < 0) {
delayMillis = 0;
}
return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);
}
public boolean sendMessageAtTime(@NonNull Message msg, long uptimeMillis) {
MessageQueue queue = mQueue;
return enqueueMessage(queue, msg, uptimeMillis);
}sendMessageDelayed方法主要计算了消息需要被处理的时间,如果delayMillis为0,那么消息的处理时间就是当前时间。然后就是关键方法enqueueMessage()。
//MessageQueue.java
boolean enqueueMessage(Message msg, long when) {
synchronized (this) {
msg.markInUse();
msg.when = when;
Message p = mMessages;
boolean needWake;
if (p == null || when == 0 || when < p.when) {
msg.next = p;
mMessages = msg;
needWake = mBlocked;
} else {
needWake = mBlocked && p.target == null && msg.isAsynchronous();
Message prev;
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
if (needWake && p.isAsynchronous()) {
needWake = false;
}
}
msg.next = p;
prev.next = msg;
}
if (needWake) {
nativeWake(mPtr);
}
}
return true;
}不懂的地方先不看,只看我们想看的:
- 首先设置了Message的when字段,也就是代表了这个消息的处理时间
- 然后判断当前队列是不是为空,是不是即时消息,是不是执行时间when大于表头的消息时间,满足任意一个,就把当前消息msg插入到表头
- 否则,就需要遍历这个队列,也就是链表,找出when小于某个节点的when,找到后插入
其他内容暂且不看,总之,插入消息就是通过消息的执行时间,也就是when字段,来找到合适的位置插入链表。具体方法就是通过死循环,使用快慢指针p和prev,每次向后移动一格,直到找到某个节点p的when大于我们要插入消息的when字段,则插入到p和prev之间。或者遍历结束,插入到链表结尾。
所以,MessageQueue是一个用于存储消息、用链表实现的特殊队列结构。
在第4节我们提到,MessageQueue是按照Message触发时间的先后顺序排列的,队头的消息是将要最早触发的消息。排在越前面的越早触发,这个所谓的延时呢,不是延时发送消息,而是延时去处理消息,我们在发消息时都是马上插入到消息队列当中。
我们这里插入完消息之后,怎么保证在预期的时间里处理消息呢?
//MessageQueue.java
Message next() {
...
for (;;) {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
//阻塞操作,等打完nextPollTimeoutMillis时长时会返回,消息队列被唤醒时会返回
nativePollOnce(ptr, nextPollTimeoutMillis);
//如果阻塞操作结束,则去获取消息
synchronized (this) {
// Try to retrieve the next message. Return if found.
//尝试取下一条消息
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
//target为空,即Handler为空,说明这个msg是消息屏障
if (msg != null && msg.target == null) {
// Stalled by a barrier. Find the next asynchronous message in the queue.
//此时只在意异步消息,查找队列中的下一个异步消息
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
if (msg != null) {
//当第一个消息或异步消息触发时间大于当前时间,则设置下一次阻塞时长
if (now < msg.when) {
// Next message is not ready. Set a timeout to wake up when it is ready.
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
//获取一条消息,并返回
// Got a message.
mBlocked = false;
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
//设置消息的使用状态,即flags |= FLAG_IN_USE
msg.markInUse();
//成功地获取MessageQueue中的下一条即将要执行的消息
return msg;
}
} else {
//没有消息
nextPollTimeoutMillis = -1;
}
...
}
...
}
}当msg!=null,如果当前时间小于头部Message的时间(消息队列是按时间顺序排列的),那么就更新等待时间nextPollTimeoutMillis,等下次再做比较。如果时间到了,就取这个消息返回。如果没有消息,nextPollTimeoutMillis被赋值为-1,这个循环又执行到nativePollOnce继续阻塞。
nativePollOnce是一个native方法,它最终会执行到pollInner方法
//Looper.cpp
int Looper::pollInner(int timeoutMillis) {
...
// Poll.
int result = POLL_WAKE;
mResponses.clear();
mResponseIndex = 0;
//即将处于idle状态
mPolling = true;
struct epoll_event eventItems[EPOLL_MAX_EVENTS];
//等待事件发生或者超时,在nativeWake()方法,向管道写端写入字符,则该方法会返回;
int eventCount = epoll_wait(mEpollFd.get(), eventItems, EPOLL_MAX_EVENTS, timeoutMillis);
...
return result;
}从native层可以看到是利用linux的epoll机制,调用了epoll_wait函数来实现的阻塞,设置epoll_wait的超时时间,使其在特定时间唤醒。这里我们先计算当前时间和触发时间的差值,这个差值作为epoll_wait的超时时间,epoll_wait超时的时候就是消息触发的时候了,就不会继续阻塞,继续往下执行,这个线程就会被唤醒,去执行消息处理。
消息的取出,即MessageQueue的next方法,第5节中已经分析next方法了。但有个问题,为什么取消息也是用的死循环?其实死循环就是为了保证一定要返回一条消息,如果没有可用消息,那么就阻塞在这里,一直到有新消息的到来。
其中,nativePollOnce方法就是阻塞方法,nextPollTimeoutMillis参数就是阻塞的时间。什么时候会阻塞?两种情况:
- 有消息,但是当前时间小于消息执行时间,也就是代码中的这一句
if (now < msg.when) {
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
}这时候阻塞时间就是消息时间减去当前时间,然后进入下一次循环,阻塞。
- 没有消息的时候
if (msg != null) {
...
} else {
// No more messages.
nextPollTimeoutMillis = -1;
}-1就代表一直阻塞。
接着上文的逻辑,当消息不可用或者没有消息的时候就会阻塞在next方法,而阻塞的方法是通过pipe(管道)和epoll机制(有了这个机制,Looper的死循环就不会导致CPU使用率过高)。
pipe: 管道,使用I/O流操作,实现跨进程通信,管道的一端的读,另一端写,标准的生产者消费者模式。
epoll机制是一种多路复用的机制,具体逻辑就是一个线程可以监视多个描述符,当某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作,这个读写操作是阻塞的。在Android中,会创建一个Linux管道(Pipe)来处理阻塞和唤醒。
- 当消息队列为空,管道的读端等待管道中有无新的内容可读,就会通过epoll机制进入阻塞状态
- 当有消息要处理,就会通过管道的写端写入内容,唤醒主线程
那什么时候会怎么唤醒消息队列线程呢?
上面的enqueueMessage方法中有个needWake字段,很明显,这个就是表示是否唤醒的字段。其中还有个字段是mBlocked,字面意思是阻塞的意思,在代码中看看
//MessageQueue.java
Message next() {
for (;;) {
synchronized (this) {
if (msg != null) {
if (now < msg.when) {
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// Got a message.
mBlocked = false;
return msg;
}
}
if (pendingIdleHandlerCount <= 0) {
// No idle handlers to run. Loop and wait some more.
mBlocked = true;
continue;
}
}
}
}在获取消息的方法next中,有两个地方对mBlocked赋值:
- 当获取到消息的时候,mBlocked赋值为false,表示不阻塞
- 当没有消息要处理,也没有idleHandler要处理的时候,mBlocked赋值为true,表示阻塞
再看看enqueueMessage方法,唤醒机制:
boolean enqueueMessage(Message msg, long when) {
synchronized (this) {
boolean needWake;
if (p == null || when == 0 || when < p.when) {
msg.next = p;
mMessages = msg;
needWake = mBlocked;
} else {
needWake = mBlocked && p.target == null && msg.isAsynchronous();
Message prev;
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
if (needWake && p.isAsynchronous()) {
needWake = false;
}
}
msg.next = p;
prev.next = msg;
}
if (needWake) {
nativeWake(mPtr);
}
}
return true;
}- 当链表为空或者时间小于表头消息时间,那么就插入表头,并且根据mBlocked的值来设置是否需要唤醒。再结合上述的例子,也就是当有新消息要插入表头了,这时候如果之前是阻塞状态(mBlocked为true),那么就要唤醒线程;
- 否则,就需要去链表中找到某个节点并插入消息,在这之前需要赋值为
needWake = mBlocked && p.target == null && msg.isAsynchronous()。也就是在插入消息之前,需要判断是否阻塞,并且表头是不是屏障消息,并且当前消息是不是异步消息。也就是如果现在是同步屏障模式下,那么要插入的消息又刚好是异步消息,那就不用管插入消息问题了,直接唤醒线程,因为异步消息需要先执行。 - 最后一点,是在循环里,如果发现之前就存在异步消息,那就不唤醒,把needWake置为false。之前有异步消息了的话,肯定之前已经唤醒过了,这时候就不需要再次唤醒了。
最后根据needWake的值,决定是否调用nativeWake方法唤醒next()方法。
在Handler机制中,有3种消息类型:
- 同步消息。也就是普通的消息
- 异步消息,通过setAsynchronous(true)设置的消息
- 同步屏障消息。通过postSyncBarrier方法添加的消息,特点是target为空,也就是没有对应的Handler
这三者的关系如何?
- 正常情况下,同步消息和异步消息都是正常被处理,也就是根据时间来取消息,处理消息
- 当遇到同步屏障消息的时候,就开始从消息队列中去找异步消息,找到了再根据时间决定阻塞还是返回消息
//MessageQueue.java
Message msg = mMessages;
if (msg != null && msg.target == null) {
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}也就是说同步屏障消息不会被返回,它只是一个标志,一个工具,遇到它就代表要先行处理异步消息了。所以同步屏障和异步消息的存在意义就是让有些消息可以被“加急处理”。比如屏幕绘制。
一个经典的场景是保证VSync信号到来后立即执行绘制,而不是要等前面的同步消息。
我们从绘制的地方scheduleTraversals方法开始看
//ViewRootImpl.java
void scheduleTraversals() {
if (!mTraversalScheduled) {
mTraversalScheduled = true;
// 同步屏障,阻塞所有的同步消息
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
// 监听VSYNC信号,下一次VSYNC信号到来时,执行给进去的mTraversalRunnable。mTraversalRunnable大家应该很熟吧:doTraversal()->performTraversals()
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
}
}
//FrameDisplayEventReceiver.java
//它是Choreographer的内部类,当VSYNC信号来的时候,会回调这里的onVsync方法
private final class FrameDisplayEventReceiver extends DisplayEventReceiver
implements Runnable {
@Override
public void onVsync(long timestampNanos, int builtInDisplayId, int frame) {
if (builtInDisplayId != SurfaceControl.BUILT_IN_DISPLAY_ID_MAIN) {
Log.d(TAG, "Received vsync from secondary display, but we don't support "
+ "this case yet. Choreographer needs a way to explicitly request "
+ "vsync for a specific display to ensure it doesn't lose track "
+ "of its scheduled vsync.");
scheduleVsync();
return;
}
//timestampNanos是VSYNC回调的时间戳 以纳秒为单位
long now = System.nanoTime();
if (timestampNanos > now) {
timestampNanos = now;
}
if (mHavePendingVsync) {
Log.w(TAG, "Already have a pending vsync event. There should only be "
+ "one at a time.");
} else {
mHavePendingVsync = true;
}
mTimestampNanos = timestampNanos;
mFrame = frame;
//自己是一个Runnable,把自己传了进去
Message msg = Message.obtain(mHandler, this);
//异步消息,保证优先级
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
}
@Override
public void run() {
...
//回调mTraversalRunnable,执行它的run方法
doFrame(mTimestampNanos, mFrame);
}
}在监听VSYNC信号之前,需要往消息队列中插入一个同步屏障消息,以保证当VSYNC信号来临时发送的异步消息的优先级。这个异步消息是用于界面绘制的,所以优先级必须高才行,界面绘制优于一切。
Choreographer的相关知识点特别多,这里就不展开讲了,可以看我之前的文章:Choreographer原理及应用
再看看loop方法,在消息分发之后,也就是执行了dispatchMessage方法之后,还偷偷做了一个操作-recycleUnchecked
//Looper.java
public static void loop() {
for (;;) {
Message msg = queue.next(); // might block
try {
msg.target.dispatchMessage(msg);
}
msg.recycleUnchecked();
}
}
//Message.java
private static Message sPool;
private static final int MAX_POOL_SIZE = 50;
void recycleUnchecked() {
//释放资源
flags = FLAG_IN_USE;
what = 0;
arg1 = 0;
arg2 = 0;
obj = null;
replyTo = null;
sendingUid = UID_NONE;
workSourceUid = UID_NONE;
when = 0;
target = null;
callback = null;
data = null;
synchronized (sPoolSync) {
if (sPoolSize < MAX_POOL_SIZE) {
//从这里可以看出 消息池是一个单链表结构,最多存放50个
next = sPool;
sPool = this;
sPoolSize++;
}
}
}在recycleUnchecked方法中,释放了所有资源,然后将当前的空消息插入到sPool表头。这里的sPool就是一个消息对象池,它也是一个链表结构的消息,最大长度为50。那么Message是怎么复用的呢?在Message的静态方法obtain中
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;
sPool = m.next;
m.next = null;
m.flags = 0; // clear in-use flag
sPoolSize--;
return m;
}
}
return new Message();
}直接复用消息池中的第一条消息,然后sPool指向下一个节点,消息池数量减一。
在Handler发送消息之后,消息就被存储到MessageQueue中,而Looper就是一个管理消息队列的角色。Looper会从MessageQueue中不断的获取消息(可能会阻塞),也就是loop方法,并将消息交回给Handler进行处理。
而Looper的获取就是通过ThreadLocal机制
static final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>();
public static void prepare() {
prepare(true);
}
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
public static @Nullable Looper myLooper() {
return sThreadLocal.get();
}通过prepare方法创建Looper并且加入到sThreadLocal中,通过myLooper方法从sThreadLocal中获取Looper。
先看一下ThreadLocal源码:
//ThreadLocal.java
public T get() {
Thread t = Thread.currentThread();
//获取当前线程的threadLocals属性,它是一个ThreadLocalMap对象,可以看成是一个Map,它的key是ThreadLocal,value是ThreadLocal需要存储的数据
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}从ThreadLocal类中的get和set方法可以大致看出来,有一个ThreadLocalMap变量,这个变量存储着键值对形式的数据。key是ThreadLocal,value是T,即需要存储的值。
而ThreadLocalMap是从哪里来的?它其实就是Thread里面的一个属性
//Thread.java
ThreadLocal.ThreadLocalMap threadLocals = null;原来这个ThreadLocalMap变量是存储在线程类Thread中的。所以ThreadLocal的基本机制就搞清楚了:在每个线程中都有一个threadLocals变量,这个变量存储着ThreadLocal和对应的需要保存的对象。这样带来的好处就是,在不同的线程,访问同一个ThreadLocal对象,但是能获取到的值却不一样。
其实就是其内部获取到的Map不同,Map和Thread绑定,所以虽然访问的是同一个ThreadLocal对象,但是访问的Map却不是同一个,所以取的值也不一样。
这样做的好处是什么?为什么不直接用Map存储线程和对象呢?一个Map存储所有线程和对象,不好的地方就在于会很混乱,每个线程之间有了联系,也容易造成内存泄露。最好是把数据交给线程内部管理,不用关心多线程安全问题,操作也比较简单,解耦。
Choreographer
public final class Choreographer {
// Thread local storage for the choreographer.
private static final ThreadLocal<Choreographer> sThreadInstance =
new ThreadLocal<Choreographer>() {
@Override
protected Choreographer initialValue() {
Looper looper = Looper.myLooper();
if (looper == null) {
throw new IllegalStateException("The current thread must have a looper!");
}
Choreographer choreographer = new Choreographer(looper, VSYNC_SOURCE_APP);
if (looper == Looper.getMainLooper()) {
mMainInstance = choreographer;
}
return choreographer;
}
};
private static volatile Choreographer mMainInstance;
}Choreographer主要是主线程用的,用来配合VSYNC中断信号。这里使用Choreographer更多的意义在于完成线程单例的功能。
Looper的创建是通过Looper.prepare()方法实现的,而在prepare方法中就判断了,当前线程是否存在Looper对象,如果有,就会直接抛出异常。
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}所以同一个线程,只能创建一个Looper,多次创建会报错。
从字面意思看:是否允许退出。看看在哪些地方用到了
//Looper.java
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
//MessageQueue.java
MessageQueue(boolean quitAllowed) {
mQuitAllowed = quitAllowed;
mPtr = nativeInit();
}
void quit(boolean safe) {
if (!mQuitAllowed) {
throw new IllegalStateException("Main thread not allowed to quit.");
}
synchronized (this) {
if (mQuitting) {
return;
}
mQuitting = true;
if (safe) {
removeAllFutureMessagesLocked();
} else {
removeAllMessagesLocked();
}
// We can assume mPtr != 0 because mQuitting was previously false.
nativeWake(mPtr);
}
}在MessageQueue得到quit方法中用到了,如果这个字段为false,表示不允许退出,就会报错。
这个quit方法是干嘛的?很明显,是用于退出Looper的loop循环的,终止消息循环。什么场景下需要用到这个quit方法?当自己开了个线程维护Looper的时候。比如HandlerThread中,在HandlerThread#quit()中使用到了这个。
这个safe是干啥的?
- 首先设置mQuitting为true
- 然后判断是否安全退出,如果是安全退出,就执行removeAllFutureMessagesLocked,它内部的逻辑就是清空所有的延迟消息(意思是之前没处理的非延迟消息还是需要去处理)。
- 如果不是安全退出,就执行removeAllMessagesLocked方法,直接清空所有消息,然后设置消息队列指向空。
//MessageQueue.java
private void removeAllMessagesLocked() {
//遍历单链表 执行Message的recycleUnchecked方法
Message p = mMessages;
while (p != null) {
Message n = p.next;
p.recycleUnchecked();
p = n;
}
mMessages = null;
}
private void removeAllFutureMessagesLocked() {
final long now = SystemClock.uptimeMillis();
Message p = mMessages;
if (p != null) {
if (p.when > now) {
//全是延迟消息 直接移除算了
removeAllMessagesLocked();
} else {
//遍历单链表 找出第一个延迟消息
Message n;
for (;;) {
n = p.next;
if (n == null) {
return;
}
if (n.when > now) {
break;
}
p = n;
}
//把延迟消息全部回收了
p.next = null;
do {
p = n;
n = p.next;
p.recycleUnchecked();
} while (n != null);
}
}
}然后看看当调用quit方法之后,消息的发送和处理:
//MessageQueue.java
//消息发送
boolean enqueueMessage(Message msg, long when) {
synchronized (this) {
if (mQuitting) {
IllegalStateException e = new IllegalStateException(
msg.target + " sending message to a Handler on a dead thread");
Log.w(TAG, e.getMessage(), e);
msg.recycle();
return false;
}
}
}当调用了quit方法之后,mQuitting为true,消息就发不出去了,会报错。
再看看消息的处理,loop和next方法
//MessageQueue.java
Message next() {
for (;;) {
synchronized (this) {
//Process the quit message now that all pending messages have been handled.
if (mQuitting) {
dispose();
return null;
}
}
}
}
//Looper.java
public static void loop() {
for (;;) {
Message msg = queue.next();
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
}
}很明显,当mQuitting为true的时候,next方法返回null,那么loop方法中就会退出死循环。
这个quit方法一般是什么时候使用呢?不再需要消息循环的时候。比如在子线程中初始化了Looper并开启了loop循环,则可以在线程结束时退出loop。
关于这个问题,Gityuan曾经回答过,知乎原文 Android中为什么主线程不会因为Looper.loop()里的死循环卡死?
我大致总结如下:
- 主线程中,Activity、Service等组件的生命周期和View的绘制等操作全在里面控制,所以主线程是不能退出的。如何保证不退出?简单做法就是可执行代码一直执行下去的,死循环便能保证不会被退出。
- 当然并非简单死循环,无消息时休眠(利用Linux的pipe/epoll机制)。此时主线程释放CPU资源进入休眠状态,直到下个消息到达或者有事物发生。所以死循环也不会特别消耗CPU资源。
- 死循环时,如何去处理其他事务?通过创建新线程的方式。比如ApplicationThread是在binder线程中运行的,会接受AMS发来的事件。
- 在收到跨进程消息后,会交给主线程的Handler再进行消息分发。所以Activity的生命周期都是依靠主线程的Looper.loop,当收到不同Message时则采用相应措施,比如收到msg=H.LAUNCH_ACTIVITY,则调用ActivityThread.handleLaunchActivity()方法,最终执行到onCreate方法。
下面是Gityuan的原回答(防止这么好的资料掉了,copy过来):
这里涉及线程,先说说进程/线程,进程:每个App运行前首先创建一个进程,该进程是由Zygote fork出来的,用于承载App上运行的各种Activity/Service等组件。进程对于上层应用来说是完全透明的,这也是Google有意为之,让App程序都是运行在Android Runtime。大多数情况下App就运行在一个进程中,除非在AndroidManifest.xml中配置android:process属性或通过native代码fork进程。
线程:线程对应用来说非常常见,比如每次new Thread().start()都会创建一个新的线程。该线程与App所在进程之间资源共享,从Linux角度来说进程与线程除了是否共享资源外,并没有本质区别,都是一个task_struct结构体,在CPU看来进程或线程无非就是一段可执行的代码,CPU采用CFS调度算法,保证每个task都尽可能公平的享有CPU时间片。
有了这些准备,再说说死循环问题:
对于线程既然是一段可执行的代码,当可执行代码执行完成后,线程生命周期便该终止了,线程退出。而对于主线程,我们绝不希望会被运行一段时间,自己就退出,那么如何保证能一直存活呢?简单做法就是可执行代码是能一直执行下去的,死循环便能保证不会被退出。例如,binder线程也是采用死循环的方法,通过循环方式不同于Binder驱动进行读写操作,当然并非简单地死循环,无消息时会休眠。但这里可能又引发了另一个问题,既然是死循环又如何去处理其他事务呢?通过创建新线程的方式。
真正会卡死主线程的操作是在回调方法onCreate/onStart/onResume等操作时间过长,会导致掉帧,甚至发生ANR,Looper.loop本身不会导致应用卡死。
事实上,会在进入死循环之前便创建了新binder线程,在代码ActivityThread.main()中
public static void main(String[] args) {
....
//创建Looper和MessageQueue对象,用于处理主线程的消息
Looper.prepareMainLooper();
//创建ActivityThread对象
ActivityThread thread = new ActivityThread();
//建立Binder通道 (创建新线程)
thread.attach(false);
Looper.loop(); //消息循环运行
throw new RuntimeException("Main thread loop unexpectedly exited");
}thread.attach(false);便会创建一个Binder线程(具体是指ApplicationThread,Binder的服务端,用于接收系统服务AMS发送来的事件),该Binder线程通过Handler将Message发送给主线程,具体过程可查看startService流程分析,这里不展开说,简单说Binder用于进程间通信,采用C/S架构。关于binder感兴趣的朋友,可以查看为什么Android要采用Binder作为IPC机制? - Gityuan的回答
另外,ActivityThread实际上并非线程,不像HandlerThread类,ActivityThread并没有真正继承Thread类,只是往往运行在主线程,给人以线程的感觉,其实承载ActivityThread的主线程就是由Zygote fork而创建的进程。
ps: ApplicationThread也不是继承自Thread,而是继承自IApplicationThread.Stub,运行在Binder线程。
主线程的死循环一直运行是不是特别消耗CPU资源呢? 其实不然,这里就涉及到Linux pipe/epoll机制,简单说就是在主线程的MessageQueue没有消息时,便阻塞在loop的queue.next()中的nativePollOnce()方法里,详情见Android消息机制1-Handler(Java层),此时主线程会释放CPU资源进入休眠状态,直到下个消息到达或者有事务发生,通过往pipe管道写端写入数据来唤醒主线程工作。这里采用的epoll机制,是一种IO多路复用机制,可以同时监控多个描述符,当某个描述符就绪(读或写就绪),则立即通知相应程序进行读或写操作,本质同步I/O,即读写是阻塞的。所以说,主线程大多数时候都是出于休眠状态,并不会消耗大量CPU资源。
ActivityThread的内部类H继承于Handler,通过Handler消息机制,简单说Handler机制用于同一个进程的线程间通信。
Activity的生命周期都是依靠主线程的Looper.loop,当收到不同Message时则采用相应措施:在H.handleMessage(msg)方法中,根据接收到不同的msg,指向相应的生命周期。比如收到msg=H.LAUNCH_ACTIVITY(以前是这条消息,好像是从Android P开始这些Activity的生命周期都用一条消息EXECUTE_TRANSACTION来表示了),则调用ActivityThread.handleLaunchActivity()方法,最终会通过反射机制,创建Activity实例,然后再执行Activity.onCreate()等方法。再比如收到msg=H.PAUSE_ACTIVITY,则调用ActivityThread.handlePauseActivity()方法,最终会执行Activity.onPause等方法。上述过程,我只挑核心逻辑讲,真正该过程远比这复杂。
主线程的消息又从哪里来的呢?当然是App进程中的其他线程通过Handler发送给主线程。
最后,从进程与线程间通信的角度,通过一张图加深大家对App运行过程的理解:
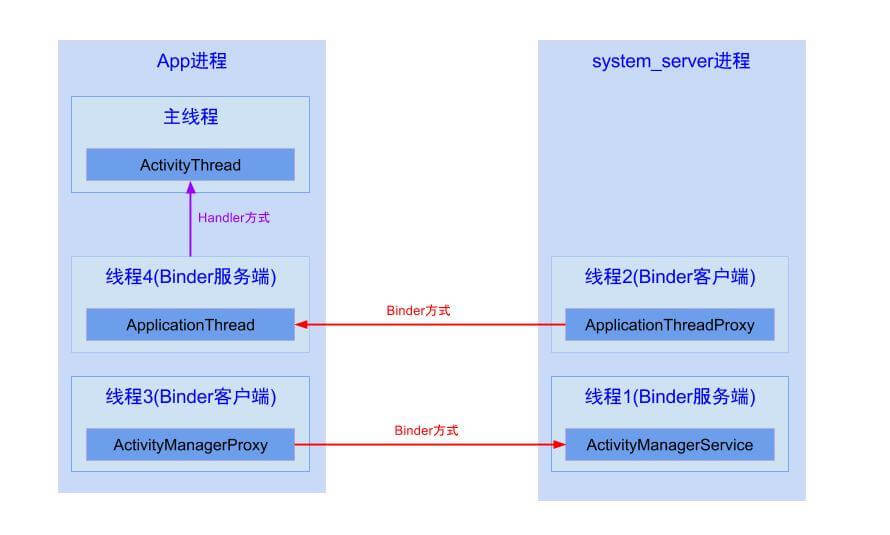
system_server进程是系统进程,java framework框架的核心载体,里面运行了大量的系统服务,比如这里提供ApplicationThreadProxy(简称ATP),ActivityManagerService(AMS),这两个服务都运行在system_server进程的不同线程中,由于ATP和AMS都是基于IBinder接口,都是binder线程,binder线程的创建与销毁都是由binder驱动来决定的。
App进程则是我们常说的应用程序,主线程主要负责Activity/Service等组件的生命周期以及UI相关操作都运行在这个线程;另外,每个App进程中至少会有两个binder线程:ApplicationThread(简称AT)和ActivityManagerProxy(简称AMP),除了图中画的线程,其中还有很多线程,比如signalcatcher线程等,这里就不一一列举。
Binder用于不同进程之间通信,由一个进程的Binder客户端向另一个进行的服务端发送事务,比如图中线程2向线程4发送事务;而Handler用于同一个进程中不同线程的通信,比如通知线程4向主线程发送消息。
结合图说说Activity生命周期,比如暂停Activity,流程如下:
system_server进程中的线程1的AMS调用线程2的ATP;(由于同一个进程的线程间资源共享,可以相互直接调用,但需要注意多线程并发问题)- 线程2通过binder传输到App进程的线程4(ApplicationThread)
- 线程4通过Handler消息机制,将暂停Activity的消息发送给主线程
- 主线程在Looper.loop()中循环遍历消息,当收到暂停Activity的消息时,便将消息分发给ActivityThread.H.handleMessage()方法,再经过方法的调用,最后便会调用到Activity.onPause(),当onPause()处理完后,继续循环loop下去。
在loop方法中,找到要处理的Message,然后调用了这么一句代码处理消息:
msg.target.dispatchMessage(msg);所以是将消息交给了msg.target来处理,那这个target是什么?
//Handler.java
private boolean enqueueMessage(MessageQueue queue,Message msg,long uptimeMillis) {
msg.target = this;
return queue.enqueueMessage(msg, uptimeMillis);
}在使用Handler发送消息的时候,会设置msg.target=this,所以target就是当初把消息加到消息队列的那个Handler。
Handler中主要的发送消息可以分为两种:
- post(Runnable)
- sendMessage()
//Handler.java
public final boolean post(@NonNull Runnable r) {
return sendMessageDelayed(getPostMessage(r), 0);
}
private static Message getPostMessage(Runnable r) {
Message m = Message.obtain();
m.callback = r;
return m;
}通过post的源码可知,其实post和sendMessage的区别在于:post方法给Message设置了一个callback,这个callback就是传入的Runnable。
那么这个callback有什么用?
//Handler.java
public void dispatchMessage(@NonNull Message msg) {
if (msg.callback != null) {
handleCallback(msg);
} else {
if (mCallback != null) {
if (mCallback.handleMessage(msg)) {
return;
}
}
handleMessage(msg);
}
}
private static void handleCallback(Message message) {
message.callback.run();
}这段代码可以分为三部分看:
- 如果msg.callback不为空,也就是通过post方法发送消息的时候,会把消息交给这个msg.callback进行处理,没有后续了
- 如果msg.callback为空,也就是通过sendMessage发送消息的时候,会判断Handler当前的mCallback是否为空,如果不为空就交给handler.mCallback.handleMessage处理
- 如果mCallback.handleMessage返回true,则没有后续了
- 如果mCallback.handleMessage返回false,则调用Handler类重写的handleMessage方法
所以post(Runnable)与sendMessage的区别就在于后续消息的处理方式,是交给msg.callback或者Handler.handleMessage。还有一种情况是交给Handler.Callback处理,这个Handler自己的Callback是可以通过构造方法传入的。
接着上面的diamante说,这两个处理方法的区别在于Handler.Callback.handleMessage方法的返回值决定着是否需要再继续执行Handler.handleMessage
- 如果Handler.Callback.handleMessage返回true,则不再继续执行Handler.handleMessage
- 如果返回false,则两个方法都要执行
那么什么时候有Callback,什么时候没有呢?这涉及到两种Handler的创建方式
val handler1= object : Handler(){
override fun handleMessage(msg: Message) {
super.handleMessage(msg)
}
}
//这个构造方法在API 30上已被废弃,使用new Handler(Looper.myLooper(), callback)来代替
val handler2 = Handler(object : Handler.Callback {
override fun handleMessage(msg: Message): Boolean {
return true
}
})常用的方法是第1 种,派生一个Handler的子类并重写handleMessage方法。
而第2种就是系统给我们提供了一种不需要派生子类的使用方法,只需要传入一个callback即可。第2种方式的场景:插件化,hook ActivityThread.H的callback,用自定义的Callback替换H中的mCallback,从而可以感知startActivity启动,进而进行Intent替换等一系列骚操作。
- 一个线程最多只会存在一个Looper对象,所以线程和Looper是一一对应的
- MessageQueue对象是在new Looper的时候创建的,所以Looper和MessageQueue是一一对应的
- Handler的作用只是将消息加到MessageQueue中,并后续取出消息后,根据消息的target字段分发给当初的那个Handler,所以Handler对于Looper是可以多对一的,也就是多个Handler对象都可以用同一个线程、同一个Looper、同一个MessageQueue。
总结:Looper、MessageQueue、线程是一一对应关系,而它们与Handler是可以一对多的。
主要做了两件事:
- 在main方法中,创建了主线程的Looper和MessageQueue,并且调用loop方法开启了主线程的消息循环
//ActivityThread.java
public static void main(String[] args) {
...
Looper.prepareMainLooper();
if (sMainThreadHandler == null) {
sMainThreadHandler = thread.getHandler();
}
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}- 创建了一个Handler来进行四大组件的启动停止、生命周期控制等事件处理
//ActivityThread.java
final H mH = new H();
class H extends Handler {
public static final int BIND_APPLICATION = 110;
public static final int EXIT_APPLICATION = 111;
public static final int RECEIVER = 113;
public static final int CREATE_SERVICE = 114;
public static final int STOP_SERVICE = 116;
public static final int BIND_SERVICE = 121;
...
}IdleHandler可以对启动过程进行优化,它可以在主线程空闲时执行任务,而不影响其他任务的执行。比如在空闲的时候再开启常驻通知栏,也是ok的。
之前说过,当MessageQueue没有消息的时候,就会阻塞在next方法中,其实在阻塞之前,MessageQueue还好做一件事,就是检查是否存在IdleHandler,如果有,就会去执行它的queueIdle方法。
//MessageQueue.java
private final ArrayList<IdleHandler> mIdleHandlers = new ArrayList<IdleHandler>();
private IdleHandler[] mPendingIdleHandlers;
Message next() {
int pendingIdleHandlerCount = -1;
for (;;) {
synchronized (this) {
...
// If first time idle, then get the number of idlers to run.
// Idle handles only run if the queue is empty or if the first message
// in the queue (possibly a barrier) is due to be handled in the future.
//当消息执行完毕,就设置pendingIdleHandlerCount
if (pendingIdleHandlerCount < 0
&& (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
if (pendingIdleHandlerCount <= 0) {
// No idle handlers to run. Loop and wait some more.
mBlocked = true;
continue;
}
//初始化mPendingIdleHandlers
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
//mIdleHandlers转为数组
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
}
// 遍历数组,处理每个IdleHandler
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null; // release the reference to the handler
boolean keep = false;
try {
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
//如果queueIdle方法返回false,则处理完就删除这个IdleHandler
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
// Reset the idle handler count to 0 so we do not run them again.
pendingIdleHandlerCount = 0;
// While calling an idle handler, a new message could have been delivered
// so go back and look again for a pending message without waiting.
nextPollTimeoutMillis = 0;
}
}当没有消息处理的时候,就会去处理这个mIdleHandlers集合里面的每个每个IdleHandler对象,并调用其queueIdle方法。最后根据queueIdle返回值判断是否用完删除当前的IdleHandler。 现在看看IdleHandler是怎么加进去的:
Looper.myQueue().addIdleHandler(new IdleHandler() {
@Override
public boolean queueIdle() {
//做事情
return false;
}
});
//MessageQueue.java
public void addIdleHandler(@NonNull IdleHandler handler) {
if (handler == null) {
throw new NullPointerException("Can't add a null IdleHandler");
}
synchronized (this) {
mIdleHandlers.add(handler);
}
}综上所述,IdleHandler就是当消息队列里面没有当前要处理的消息了,需要阻塞之前,可以做一些空闲任务的处理。 常见的使用场景有:启动优化。
我们一般会把一些事件(比如界面View的findViewById、做一些其他操作之类的)放到onCreate方法或者onResume方法中。但是这两个方法其实都是在界面绘制之前调用的,也就是说一定程度上这两个方法的耗时会影响到启动时间。
我们可以把一些操作放到IdleHandler中,也就是界面绘制完成之后才去调用,这样就能减少启动时间了。
但是,这里需要注意下,可能有坑。如果使用不当,IdleHandler会一直不执行,比如在View的onDraw方法里面直接或间接地调用invalidate方法,或者是循环执行补间动画,这些操作会让MassageQueue中一直有消息,一直空闲不下来,故而IdleHandler就一直得不到执行。
其原因在于onDraw方法中执行invalidate,最终会执行到ViewRootImpl,然后会添加一个同步屏障消息,在等到异步消息之前,会阻塞在next方法,而等到FrameDisplayEventReceiver异步任务之后又会执行onDraw方法,从而无限循环。 补间动画也是类似的道理。
具体可以看看下面几篇文章:
直接看源码:
//HandlerThread.java
public class HandlerThread extends Thread {
@Override
public void run() {
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
}
}HandlerThread继承自Thread,说明它是一个线程。线程内部只做一件事,就是跑Looper的loop循环。既然里面已经有了一个Looper在那里执行loop循环,那么我们就可以往这个Looper的MessageQueue里面发消息,最终消息的分发执行是在HandlerThread这个子线程中。
一般使用如下:
HandlerThread handlerThread = new HandlerThread("downloadImage");
handlerThread.start();
/**
* 该callback运行于子线程
*/
class ChildCallback implements Handler.Callback {
@Override
public boolean handleMessage(Message msg) {
//在子线程中进行相应的业务操作
return false;
}
}
//子线程Handler
Handler childHandler = new Handler(handlerThread.getLooper(),new ChildCallback());
//发个消息
childHandler.sendEmptyMessageDelayed(1,1000);我们发现在HandlerThread的run方法中,有一个notifyAll()的调用,用于唤醒其他线程,那哪里调用了wait方法呢?
//HandlerThread.java
public Looper getLooper() {
if (!isAlive()) {
return null;
}
// If the thread has been started, wait until the looper has been created.
synchronized (this) {
while (isAlive() && mLooper == null) {
try {
wait();
} catch (InterruptedException e) {
}
}
}
return mLooper;
}在获取Looper的时候,可能会阻塞住,可能Looper还没有初始化完成。所以wait的意思就是等待Looper创建好,那边创建好之后再通知这边正确返回Looper。
直接上源码:
//IntentService.java
public abstract class IntentService extends Service {
private final class ServiceHandler extends Handler {
public ServiceHandler(Looper looper) {
super(looper);
}
@Override
public void handleMessage(Message msg) {
onHandleIntent((Intent)msg.obj);
stopSelf(msg.arg1);
}
}
@Override
public void onCreate() {
super.onCreate();
HandlerThread thread = new HandlerThread("IntentService[" + mName + "]");
thread.start();
mServiceLooper = thread.getLooper();
mServiceHandler = new ServiceHandler(mServiceLooper);
}
@Override
public void onStart(@Nullable Intent intent, int startId) {
Message msg = mServiceHandler.obtainMessage();
msg.arg1 = startId;
msg.obj = intent;
mServiceHandler.sendMessage(msg);
}
}简单理一下:
- 首先IntentService是一个Service
- 并且内部维护了一个HandlerThread,也就是有完整的Looper在运行
- 还维护了一个Handler,用于在子线程中执行handleMessage
- 启动Service后,会通过Handler执行onHandleIntent方法
- 完成任务后,会自动执行stopSelf停止当前Service
所以,这就是一个无需自己手动管理子线程执行耗时任务的Service,我们只需要将耗时任务在onHandleIntent里面执行就可以了,执行完了它会自动停止Service。
BlockCanary是一个用来检测应用卡顿耗时的三方库。
用户感知到应用卡顿,说明View的绘制没有跟上60fps的步伐。当VSYNC信号每隔16ms到来时,没有即时进行绘制,或者是绘制时间超过16ms,都可能导致卡顿。造成这个的原因是因为主线程卡顿了,可能是某个地方在进行耗时操作,或者View布局过于复杂从而需要很长的绘制时间才能绘制完成。
而主线程的卡顿,其实是可以通过检测Handler处理消息的时间长短来感知。有没有发现,只要是和用户感知相关的,比如点击、触摸、View动画、界面跳转、Activity生命周期等等,都是和主线程Looper有关,这些机制全部都靠着Handler消息机制才能运转。这些事件都是发生在事件分发的过程中,也就是消息事件的dispatchMessage()过程中,只要知道dispatchMessage()的耗时就能知道主线程是否在卡顿。如果在卡顿就把线程堆栈拿出来分析。
那么Handler消息的处理时间怎么获取呢?去loop方法看看
//Looper.java
private Printer mLogging;
public void setMessageLogging(@Nullable Printer printer) {
mLogging = printer;
}
public static void loop() {
final Looper me = myLooper();
for (;;) {
final Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
...
msg.target.dispatchMessage(msg);
...
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
}
}从这段代码可以看出,如果我们设置了Printer,那么在每个消息分发的前后都会打印一句日志来标识事件分发的开始和结束。这个点可以利用一下,我们可以通过Looper打印日志的时间间隔来判断是否发生卡顿,如果发生卡顿,则将此时线程的堆栈信息给保存下来,进而分析哪里卡顿了。这种匹配字符串方案能够准确地在发生卡顿时拿到堆栈信息。
原理搞清楚了,咱直接撸一个工具出来:
const val TAG = "looper_monitor"
/**
* 默认卡顿阈值
*/
const val DEFAULT_BLOCK_THRESHOLD_MILLIS = 3000L
const val BEGIN_TAG = ">>>>> Dispatching"
const val END_TAG = "<<<<< Finished"
class LooperPrinter : Printer {
private var mBeginTime = 0L
@Volatile
var mHasEnd = false
private val collectRunnable by lazy { CollectRunnable() }
private val handlerThreadWrapper by lazy { HandlerThreadWrapper() }
override fun println(msg: String?) {
if (msg.isNullOrEmpty()) {
return
}
log(TAG, "$msg")
if (msg.startsWith(BEGIN_TAG)) {
mBeginTime = System.currentTimeMillis()
mHasEnd = false
//需要单独搞个线程来获取堆栈
handlerThreadWrapper.handler.postDelayed(
collectRunnable,
DEFAULT_BLOCK_THRESHOLD_MILLIS
)
} else {
mHasEnd = true
if (System.currentTimeMillis() - mBeginTime < DEFAULT_BLOCK_THRESHOLD_MILLIS) {
handlerThreadWrapper.handler.removeCallbacks(collectRunnable)
}
}
}
fun getMainThreadStackTrace(): String {
val stackTrace = Looper.getMainLooper().thread.stackTrace
return StringBuilder().apply {
for (stackTraceElement in stackTrace) {
append(stackTraceElement.toString())
append("\n")
}
}.toString()
}
inner class CollectRunnable : Runnable {
override fun run() {
if (!mHasEnd) {
//主线程堆栈给拿出来,打印一下
log(TAG, getMainThreadStackTrace())
}
}
}
class HandlerThreadWrapper {
var handler: Handler
init {
val handlerThread = HandlerThread("LooperHandlerThread")
handlerThread.start()
handler = Handler(handlerThread.looper)
}
}
}代码比较少,主要思路就是在println()回调时判断回调的文本信息是开始还是结束。如果是开始则搞个定时器,3秒后就认为是卡顿,就开始取主线程堆栈信息输出日志,如果在这3秒内消息已经分发完成,那么就不是卡顿,就把这个定时器取消掉。
我在demo中搞了个点击事件,sleep了4秒
17987-17987/com.xfhy.allinone D/looper_monitor: >>>>> Dispatching to Handler (android.view.ViewRootImpl$ViewRootHandler) {63ca49} android.view.View$PerformClick@13f525a: 0
17987-18042/com.xfhy.allinone D/looper_monitor: java.lang.Thread.sleep(Native Method)
java.lang.Thread.sleep(Thread.java:373)
java.lang.Thread.sleep(Thread.java:314)
com.xfhy.allinone.performance.caton.CatonDetectionActivity.manufacturingCaton(CatonDetectionActivity.kt:39)
com.xfhy.allinone.performance.caton.CatonDetectionActivity.access$manufacturingCaton(CatonDetectionActivity.kt:14)
com.xfhy.allinone.performance.caton.CatonDetectionActivity$onCreate$3.onClick(CatonDetectionActivity.kt:34)
android.view.View.performClick(View.java:6597)
android.view.View.performClickInternal(View.java:6574)
android.view.View.access$3100(View.java:778)
android.view.View$PerformClick.run(View.java:25885)
android.os.Handler.handleCallback(Handler.java:873)
android.os.Handler.dispatchMessage(Handler.java:99)
android.os.Looper.loop(Looper.java:193)
android.app.ActivityThread.main(ActivityThread.java:6669)
java.lang.reflect.Method.invoke(Native Method)
com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:493)
com.android.internal.os.ZygoteInit.main(ZygoteInit.java:858)
17987-17987/com.xfhy.allinone D/looper_monitor: <<<<< Finished to Handler (android.view.ViewRootImpl$ViewRootHandler) {63ca49} android.view.View$PerformClick@13f525a
可以看到,我们已经获取到了卡顿时的堆栈信息,从这些信息已经足以分析出在哪里发生了什么事情。这里是在CatonDetectionActivity的manufacturingCaton处sleep()了。
Handler内存泄露的原因:非静态内部类生命周期比外部类生命周期长。非静态内部类持有了外部类的引用,也就是Handler持有了Activity的引用,而这个Handler没有即时得到回收,引用链如下:主线程 —> threadlocal —> Looper —> MessageQueue —> Message —> Handler —> Activity,于是发生内存泄露。
主线程崩溃,其实都是发生在消息的处理内,包括生命周期、界面绘制等。
所以如果我们能控制这个过程,并且在发生崩溃后重新开启消息循环,那么主线程就能继续运行。
new Handler(Looper.getMainLooper()).post(new Runnable() {
@Override
public void run() {
while (true) {
try {
Looper.loop();
} catch (Throwable e) {
e.printStackTrace();
}
}
}
});上面这段代码给主线的Looper发生了一个消息,这个消息的callback是上面这个Runnable,实际执行逻辑是一段看起来像死循环一样的代码。这样就能让主线程不崩溃了?
分析一下,我们知道,主线程中维护了Handler的消息机制,在应用启动的时候就做好了Looper的创建和初始化,然后开始使用Looper.loop()循环处理消息。
//ActivityThread.java
public static void main(String[] args) {
//准备主线的MainLooper
Looper.prepareMainLooper();
ActivityThread thread = new ActivityThread();
thread.attach(false, startSeq);
if (sMainThreadHandler == null) {
sMainThreadHandler = thread.getHandler();
}
//开始loop循环
Looper.loop();
//loop循环是不能结束的,否则app就会异常退出咯
throw new RuntimeException("Main thread loop unexpectedly exited");
}我们在使用app的过程中,用户的所有操作事件、生命周期回调、列表滑动等等,都是通过Looper的loop循环中完成处理的,其本质是将消息加入MessageQueue队列,然后循环从这个队列中取出消息并处理。如果没有消息可以处理的时候,会依靠Linux的epoll机制暂时挂起等待唤醒。
死循环,不断取消息,没有消息的话就暂时挂起。我们上面那段短小精炼的代码,通过Handler往主线程的Looper发送了一个消息,然后在里面执行了一个死循环,死循环地指向Looper的loop方法读取消息。只要Looper的loop方法执行到了咱这个Message的callback,那么后面所有的主线程消息都会走到我们这个loop方法中进行处理。一旦发生了主线程崩溃,那么这里就可以进行异常捕获到。然后又是死循环,捕获到异常之后,又开始继续执行Looper的loop方法,这样主线程就可以一直正常读取消息,刷新UI啥的都是正常的,不会有影响。
但是上面那段代码只能捕获主线程的崩溃,那子线程的崩溃还是会让app崩溃。可以通过设置setDefaultUncaughtExceptionHandler来化解。
为什么设置了setDefaultUncaughtExceptionHandler就不崩溃了?这里我们得从异常的源码开始说起:一般情况下,一个应用所使用的线程都是在同一个线程组,而在这个线程组里只要有一个线程出现未被捕获异常的时候,Java虚拟机就会调用当前线程所在线程组的uncaughtException()方法。
// ThreadGroup.java
private final ThreadGroup parent;
public void uncaughtException(Thread t, Throwable e) {
if (parent != null) {
//递归
parent.uncaughtException(t, e);
} else {
//获取DefaultUncaughtExceptionHandler
Thread.UncaughtExceptionHandler ueh =
Thread.getDefaultUncaughtExceptionHandler();
if (ueh != null) {
ueh.uncaughtException(t, e);
} else if (!(e instanceof ThreadDeath)) {
System.err.print("Exception in thread \""
+ t.getName() + "\" ");
e.printStackTrace(System.err);
}
}
}parent表示当前线程组的父级线程组,所以最后还是会调用到这个方法中。接着看后面的代码,通过getDefaultUncaughtExceptionHandler获取到了系统默认的异常处理器,然后调用了uncaughtException方法。那么我们去找找本来系统中的这个异常处理器--UncaughtExceptionHandler。
这就要从App的启动流程说起了,所有的Android进程都是由Zygote进程fork而来的,在一个新进程被启动的时候就会调用zygoteInit方法,这个方法里会进行一些应用的初始化工作:
//ZygoteInit.java
public static final Runnable zygoteInit(int targetSdkVersion, String[] argv, ClassLoader classLoader) {
if (RuntimeInit.DEBUG) {
Slog.d(RuntimeInit.TAG, "RuntimeInit: Starting application from zygote");
}
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "ZygoteInit");
//日志重定向
RuntimeInit.redirectLogStreams();
//通用的配置初始化
RuntimeInit.commonInit();
// zygote初始化
ZygoteInit.nativeZygoteInit();
//应用相关初始化
return RuntimeInit.applicationInit(targetSdkVersion, argv, classLoader);
}而关于异常处理器,就在这个通用的配置初始化方法当中:
//RuntimeInit.java
protected static final void commonInit() {
//设置异常处理器
LoggingHandler loggingHandler = new LoggingHandler();
Thread.setUncaughtExceptionPreHandler(loggingHandler);
//注意 这里设置了UncaughtExceptionHandler,它是KillApplicationHandler
//看起来KillApplicationHandler里面是kill app
Thread.setDefaultUncaughtExceptionHandler(new KillApplicationHandler(loggingHandler));
//设置时区
TimezoneGetter.setInstance(new TimezoneGetter() {
@Override
public String getId() {
return SystemProperties.get("persist.sys.timezone");
}
});
TimeZone.setDefault(null);
//log配置
LogManager.getLogManager().reset();
//***
initialized = true;
}这里系统给我们设置了应用默认的异常处理器--KillApplicationHandler
//KillApplicationHandler.java
private static class KillApplicationHandler implements Thread.UncaughtExceptionHandler {
private final LoggingHandler mLoggingHandler;
public KillApplicationHandler(LoggingHandler loggingHandler) {
this.mLoggingHandler = Objects.requireNonNull(loggingHandler);
}
@Override
public void uncaughtException(Thread t, Throwable e) {
try {
//输出崩溃时的调用栈日志
ensureLogging(t, e);
//...
// Bring up crash dialog, wait for it to be dismissed
//异常处理
ActivityManager.getService().handleApplicationCrash(
mApplicationObject, new ApplicationErrorReport.ParcelableCrashInfo(e));
} catch (Throwable t2) {
if (t2 instanceof DeadObjectException) {
// System process is dead; ignore
} else {
try {
Clog_e(TAG, "Error reporting crash", t2);
} catch (Throwable t3) {
// Even Clog_e() fails! Oh well.
}
}
} finally {
// Try everything to make sure this process goes away.
//杀掉进程
Process.killProcess(Process.myPid());
System.exit(10);
}
}
private void ensureLogging(Thread t, Throwable e) {
if (!mLoggingHandler.mTriggered) {
try {
mLoggingHandler.uncaughtException(t, e);
} catch (Throwable loggingThrowable) {
// Ignored.
}
}
}在uncaughtException回调方法中,会执行一个handleApplicationCrash方法进行异常处理,并且最后都会走到finally中进行进程销毁,所以程序就崩溃了。
我们平时在收集上看到的崩溃提示弹窗,就是在这个handleApplicationCrash方法中弹出来的。不仅仅是Java崩溃,还有我们平时遇到的native_crash、ANR等异常都会最后走到handleApplicationCrash进行崩溃处理。
另外,这里在构造方法中,传入了一个LoggingHandler,它的作用非常大。平时我们看到的崩溃日志就是它打印出来的。
我们如果通过setDefaultUncaughtExceptionHandler方法设置了我们自己的崩溃处理器,就把之前应用设置的这个崩溃处理器给顶掉了,然后我们不做任何处理的话,自然程序就不会崩溃了。
class Test2Activity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_exception)
throw RuntimeException("主线程异常")
}
}如果直接在Activity生命周期内抛出异常,会导致界面绘制无法完成,Activity无法被正确启动,就会白嫖或者黑屏。这种严重影响到用户体验的情况还是建议直接杀死App,因为很有可能会对其他的功能模块造成影响。或者如果某些Activity不是很重要,也可以只finish这个Activity。
怎么分辨这种生命周期内发生崩溃的情况?Activity的生命周期都会走ActivityThread的H这个Handler过,直接hook这个Handler的callbak,然后针对每个生命周期对应的消息进行try..catch处理捕获异常,然后就可以进行finishActivity或者杀死进程操作了。
主要代码如下:
Field mhField = activityThreadClass.getDeclaredField("mH");
mhField.setAccessible(true);
final Handler mhHandler = (Handler) mhField.get(activityThread);
Field callbackField = Handler.class.getDeclaredField("mCallback");
callbackField.setAccessible(true);
callbackField.set(mhHandler, new Handler.Callback() {
@Override
public boolean handleMessage(Message msg) {
if (Build.VERSION.SDK_INT >= 28) {
//android 28之后的生命周期处理
final int EXECUTE_TRANSACTION = 159;
if (msg.what == EXECUTE_TRANSACTION) {
try {
mhHandler.handleMessage(msg);
} catch (Throwable throwable) {
//杀死进程或者杀死Activity
}
return true;
}
return false;
}
//android 28之前的生命周期处理
switch (msg.what) {
case RESUME_ACTIVITY:
//onRestart onStart onResume回调这里
try {
mhHandler.handleMessage(msg);
} catch (Throwable throwable) {
sActivityKiller.finishResumeActivity(msg);
notifyException(throwable);
}
return true;代码贴了一部分,但是原理大家应该都懂了吧,就是通过替换主线程的Handler的Callback,进行生命周期的异常捕获。接下来就是就是捕获后的处理工作了。要么杀进程,要么finish那个Activity。
杀死进程比较容易,那么杀死Activity应该怎么玩?我们这里拿不到Activity的实例,怎么finish?这就要分析下Activity的finish流程了,简答说下,以Android 29为例
//Activity.java
private void finish(int finishTask) {
if (mParent == null) {
if (false) Log.v(TAG, "Finishing self: token=" + mToken);
try {
if (resultData != null) {
resultData.prepareToLeaveProcess(this);
}
if (ActivityTaskManager.getService()
.finishActivity(mToken, resultCode, resultData, finishTask)) {
mFinished = true;
}
}
}
}
@Override
public final boolean finishActivity(IBinder token, int resultCode, Intent resultData,
int finishTask) {
return mActivityTaskManager.finishActivity(token, resultCode, resultData, finishTask);
} 从Activity的finish源码得知,最终是调用到ActivityTaskManagerService的finishActivity方法,这个方法有4个参数,其中有个用来表示Activity的参数也就是最重要的参数--token。我们只要拿到这个token就能直接调用ActivityTaskManagerService来进行finishActivity。所以取源码里面找找token。
由于我们捕获的地方是在handleMessage回调方法中,只要一个参数Message可以用,那我们就从这方面入手,回到刚才我们处理消息的源码中
class H extends Handler {
public void handleMessage(Message msg) {
switch (msg.what) {
case EXECUTE_TRANSACTION:
final ClientTransaction transaction = (ClientTransaction) msg.obj;
mTransactionExecutor.execute(transaction);
break;
}
}
}
public void execute(ClientTransaction transaction) {
final IBinder token = transaction.getActivityToken();
executeCallbacks(transaction);
executeLifecycleState(transaction);
mPendingActions.clear();
log("End resolving transaction");
} 可以看到,在源码中,Handler是怎么处理EXECUTE_TRANSACTION消息的,获取到msg.obj对象,也就是ClientTransaction类实例,然后调用execute方法,而在execute方法中,就获取到了token。找到了token,我们就可以通过反射进行Activity的销毁就行了。
private void finishMyCatchActivity(Message message) throws Throwable {
ClientTransaction clientTransaction = (ClientTransaction) message.obj;
IBinder binder = clientTransaction.getActivityToken();
Method getServiceMethod = ActivityManager.class.getDeclaredMethod("getService");
Object activityManager = getServiceMethod.invoke(null);
Method finishActivityMethod = activityManager.getClass().getDeclaredMethod("finishActivity", IBinder.class, int.class, Intent.class, int.class);
finishActivityMethod.setAccessible(true);
finishActivityMethod.invoke(activityManager, binder, Activity.RESULT_CANCELED, null, 0);
}上面这种思路就是Cockroach里面的原理。
如何捕获程序中的异常不让App崩溃,主要有以下做法:
- 通过再主线程里面发送一个消息,接管原来的主线程的loop,捕获主线程的异常,并在异常发生后继续调用Looper.loop方法,使得主线程继续处理消息
- 对于子线程的异常,可以通过Thread.setDefaultUncaughtExceptionHandler来拦截,并且子线程的停止不会给用户带来感知
- 对于在生命周期内发生的异常,可以通过替换ActivityThread.mH.mCallback的方法来捕获,并且通过token来结束Activity或直接杀死进程。但是这种办法需要适配不同的Android版本,所以慎用,需要的可以看看Cockroach库源码。
Handler机制这块知识点非常非常多,希望大家看完这篇文章之后,能形成自己的知识体系。
Hanlder,I Got it!
- https://juejin.cn/post/6943048240291905549?utm_source=gold_browser_extension
- https://blog.csdn.net/qq_38366777/article/details/108942036
- Android 消息处理以及epoll机制 https://www.jianshu.com/p/97e6e6c981b6
- 我读过的最好的epoll讲解--转自”知乎“ https://blog.51cto.com/yaocoder/888374
- https://www.zhihu.com/question/34652589
- https://juejin.cn/post/6950146347731255327
- https://juejin.cn/post/6844903613865672718
- https://blog.csdn.net/wangsf1112/article/details/106027564
- https://juejin.cn/post/6844903713006419975
- https://juejin.cn/post/6904283635856179214