docker核心技术 - python爬虫高薪系列课程
替代产品: containerd, vagrant
l
- 从 Docker 1.10 开始,
COPY、ADD和RUN语句会向镜像中添加新层。前面的示例创建了两个层而不是一个。 - Docker提供了一种非常便利的打包机制. 这种机制直接导包了应用运行所需要的整个操作系统, 从而保证了本地环境和云端环境的高度一致性, 避免了用户通过"试错"来匹配两种不同运行环境之间差异的痛苦过程.
相比于传统虚拟化技术
更高效的利用系统资源 由于容器不需要进行硬件虚拟以及运行完整操作系统等额外开销,Docker 对系统资源的利用率更高。无论是应用执行速度、内存损耗或者文件存储速度,都要比传统虚拟机技术更高效。因此,相比虚拟机技术,一个相同配置的主机,往往可以运行更多数量的应用。
更快速的启动时间 传统的虚拟机技术启动应用服务往往需要数分钟,而 Docker 容器应用,由于直接运行于宿主内核,无需启动完整的操作系统,因此可以做到秒级、甚至毫秒级的启动时间。大大的节约了开发、测试、部署的时间。
一致的运行环境 开发过程中一个常见的问题是环境一致性问题。由于开发环境、测试环境、生产环境不一致,导致有些 bug 并未在开发过程中被发现。而 Docker 的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性,从而不会再出现 「这段代码在我机器上没问题啊」 这类问题。
持续交付和部署 对开发和运维(DevOps)人员来说,最希望的就是一次创建或配置,可以在任意地方正常运行。 使用 Docker 可以通过定制应用镜像来实现持续集成、持续交付、部署。开发人员可以通过 Dockerfile 来进行镜像构建,并结合 持续集成( Continuous Integration) 系统进行集成测试,而运维人员则可以直接在生产环境中快速部署该镜像,甚至结合 持续部署(Continuous Delivery/Deployment) 系统进行自动部署。 而且使用 Dockerfile 使镜像构建透明化,不仅仅开发团队可以理解应用运行环境,也方便运维团队理解应用运行所需条件,帮助更好的生产环境中部署该镜像。
更轻松的迁移 由于 Docker 确保了执行环境的一致性,使得应用的迁移更加容易。Docker 可以在很多平台上运行,无论是物理机、虚拟机、公有云、私有云,甚至是笔记本,其运行结果是一致的。因此用户可以很轻易的将在一个平台上运行的应用,迁移到另一个平台上,而不用担心运行环境的变化导致应用无法正常运行的情况
更轻松的维护和扩展
Docker 使用的分层存储以及镜像的技术,使得应用重复部分的复用更为容易,也使得应用的维护更新更加简单,基于基础镜像进一步扩展镜像也变得非常简单。此外,Docker 团队同各个开源项目团队一起维护了一大批高质量的 官方镜像,既可以直接在生产环境使用,又可以作为基础进一步定制,大大的降低了应用服务的镜像制作成本。
- 所有的官方镜像都有
Dockerfile,以及在github上有全部生成镜像的配套文件,遵循了Dockerfile的最佳实践,这些也是很好地学习资料。
dockerfile -> image -> container -> repository
制作 -> 镜像 -> 容器 -> 仓库
- 了解 Docker 与虚拟机的不同点,相比的优势
- 掌握 Docker 的启动方法
- 掌握 Docker 镜像操作
- 掌握 Docker 容器操作
- Docker整体架构, 底层技术
容器中的数据应该尽量保存到宿主机上
docker 三大部分 《docker实战》
推荐直接按照官方Guide操作
- https://docs.docker.com/engine/install/ubuntu/
- https://docs.docker.com/desktop/install/mac-install/
- https://docs.docker.com/desktop/install/linux-install/
# 通过镜像安装
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun```shell
# 官网安装
sudo apt-get update
# 安装包允许apt通过HTTPS使用仓库
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common
# 添加Docker官方GPG key
# 设置Docker稳定版仓库
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
# 更新apt索引源
sudo apt-get update
# 安装最新版Docker CE(社区版)
sudo apt-get install docker-ce
# 检查Docker CE是否安装成功
docker run hello-world
# 设置用户权限, 以避免每次命令都输入sudo
# https://docs.docker.com/engine/install/linux-postinstall/
# 执行命令后须注销重新登录
sudo usermod -a -G docker $USER
# 这样就安装完毕了!
# https://get.docker.com/
https://developer.aliyun.com/mirror/docker-ce/
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
systemctl enable --now docker
### 镜像加速
# 参考资料
# https://gist.github.com/y0ngb1n/7e8f16af3242c7815e7ca2f0833d3ea6
# 阿里云
"registry-mirrors": ["https://qdyoqqzy.mirror.aliyuncs.com"],
# 清华
{
"registry-mirrors": ["https://docker.mirrors.tuna.tsinghua.edu.cn"]
}
# 腾讯云
https://mirror.ccs.tencentyun.com
# 科大镜像源
https://docker.mirrors.ustc.edu.cn
{
"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn"]
}
# Docker镜像代理
https://dockerproxy.com
# 服务管理
sudo systemctl start|stop|restart|status docker
# 查看容器的运行状态
sudo systemctl emable docker### 镜像相关
# 列出镜像
docker image ls
docker images
# 从官方拉取镜像
docker image pull library/hello-world
docker image pull hello-world
# 拉取镜像
docker pull ubuntu
docker pull ubuntu:latest
docker pull ubuntu:rolling
docker pull mongo:3.2.4
# 搜索/查找镜像
docker search mysql
# 从本地将镜像加载到本地镜像库
docker load -i ./ubuntu.tar
# 删除镜像
docker image rm 镜像名或镜像ID
docker image rm hello-world
容器命令的用法等同于ubuntu / linux , 容器就是一个ubuntu的环境
一个镜像可以同时创建多个容器, 彼此独立(需要以不同名称来表示)
### 容器相关命令
# 创建容器
docker run [option] 镜像名 [向启动容器中传入的命令]
# 交互式容器
docker run -it --name=myubuntu ubuntu /bin/bash
# 守护式容器: 长期运行容器
docker run -dit --name=myubuntu2 ubuntu
# 进入已运行的容器
docker exec -it 容器名或容器id 进入后执行的第一个命令
docker exec -it myubuntu2 /bin/bash
# 查看容器: 正在运行 / 所有容器
# 列出本机正在运行的容器
docker container ls
# 列出本机所有容器, 包括已经终止运行的
docker container ls --all
# 停止与启动容器
# 停止一个已经在运行的容器
docker container stop 容器名或容器id
# 启动一个已经停止的容器
docker container start 容器名或容器id
# 强行杀掉(停止)容器
docker container kill 容器名或容器id
# 删除容器
docker container rm 容器名或容器id
# 将容器保存为镜像
docker commit 容器名 镜像名
# 镜像备份与迁移
# 备份==打包, 并保存到本地
docker save -o 保存的文件名 镜像名
docker save -o ./ubuntu.tar ubuntu
# 将镜像加载到本地
docker load -i ./ubuntu.tar
| Usage: | docker [OPTIONS] COMMAND |
|---|---|
| A self-sufficient runtime for containers | |
| Options: | |
| --config string | Location of client config files (default "/home/wwfyde/.docker") |
| -c, --context string | Name of the context to use to connect to the daemon (overrides DOCKER_HOST env var and default context set with "docker context use") |
| -D, --debug | Enable debug mode |
| -H, --host list | Daemon socket(s) to connect to |
| -l, --log-level string | Set the logging level ("debug"|"info"|"warn"|"error"|"fatal") (default "info") |
| --tls | Use TLS; implied by --tlsverify |
| --tlscacert string | Trust certs signed only by this CA (default "/home/wwfyde/.docker/ca.pem") |
| --tlscert string | Path to TLS certificate file (default "/home/wwfyde/.docker/cert.pem") |
| --tlskey string | Path to TLS key file (default "/home/wwfyde/.docker/key.pem") |
| --tlsverify | Use TLS and verify the remote |
| -v, --version | Print version information and quit |
| Management Commands: | |
| builder | Manage builds |
| config | Manage Docker configs |
| container | Manage containers |
| context | Manage contexts |
| engine | Manage the docker engine |
| image | Manage images |
| network | Manage networks |
| node | Manage Swarm nodes |
| plugin | Manage plugins |
| secret | Manage Docker secrets |
| service | Manage services |
| stack | Manage Docker stacks |
| swarm | Manage Swarm |
| system | Manage Docker |
| trust | Manage trust on Docker images |
| volume | Manage volumes |
| Commands: | |
| attach | Attach local standard input, output, and error streams to a running container |
| build | Build an image from a Dockerfile |
| commit | Create a new image from a container's changes |
| cp | Copy files/folders between a container and the local filesystem |
| create | Create a new container |
| diff | Inspect changes to files or directories on a container's filesystem |
| events | Get real time events from the server |
| exec | Run a command in a running container |
| export | Export a container's filesystem as a tar archive |
| history | Show the history of an image |
| images | List images |
| import | Import the contents from a tarball to create a filesystem image |
| info | Display system-wide information |
| inspect | Return low-level information on Docker objects |
| kill | Kill one or more running containers |
| load | Load an image from a tar archive or STDIN |
| login | Log in to a Docker registry |
| logout | Log out from a Docker registry |
| logs | Fetch the logs of a container |
| pause | Pause all processes within one or more containers |
| port | List port mappings or a specific mapping for the container |
| ps | List containers |
| pull | Pull an image or a repository from a registry |
| push | Push an image or a repository to a registry |
| rename | Rename a container |
| restart | Restart one or more containers |
| rm | Remove one or more containers |
| rmi | Remove one or more images |
| run | Run a command in a new container |
| save | Save one or more images to a tar archive (streamed to STDOUT by default) |
| search | Search the Docker Hub for images |
| start | Start one or more stopped containers |
| stats | Display a live stream of container(s) resource usage statistics |
| stop | Stop one or more running containers |
| tag | Create a tag TARGET_IMAGE that refers to SOURCE_IMAGE |
| top | Display the running processes of a container |
| unpause | Unpause all processes within one or more containers |
| update | Update configuration of one or more containers |
| version | Show the Docker version information |
| wait | Block until one or more containers stop, then print their exit codes |
广义值Docker管理平台, 狭义值一个容器
任何应用的运行都会依赖于一些相应的环境
Docker是开发, 运行和部署应用程序的开放管理平台
- 开发人员利用Docker开发和运行应用程序
- 运维人员利用Docker部署和管理应用程序
Docker平台介绍(The Docker Platform)
Docker提供了在一个完全隔离的环境中打包和运行程序的能力, 这个隔离的环境被称为容器.
由于容器的隔离性和安全性, 因此可以在一个主机(宿主机)上同时运行多个相互隔离的容器, 互不干预
Docker容器已经提供工具和组件(Docker Client, Docker Daemon)来管理容器的生命周期:
- 使用容器来开发应用程序及其支持组件
- 容器成为分发和测试你的应用程序的单元
- 准备好后, 将您的应用部署到生产环境中, 作为容器或协调程序. 无论您的生产环境是本地数据中心, 云提供商还是两者的混合, 这都是一样的
- Docker方便开发者将应用程序与基础架构分开, 以便快速交付软件
- 借助Docker, 开发者可以像管理应用程序一样管理基础架构
- 通过利用Docker的方法快速进行运输, 测试和部署代码, 开发者可以显著缩短编写代码和在生产环境中运行代码之间的延迟
- 开发人员在本地编写代码, 可以使用Docker与同事进行共享, 实现协同工作.
- 使用Docker开发完程序, 可以直接对应用程序执行自动和手动测试
- 当开发人员发现错误或BUG时, 可以直接在开发环境中修复后, 并迅速将她们重新部署到测试环境进行测试和验证
- 利用Docker开发完成后, 交付时, 直接交付Docker, 也就意味着交付完成. 后续如果有提供修补程序或更新, 需要推送到生成环境运行起来, 也是一样简单.
- 保证程序运行环境的一致性
- 降低配置开发环境和生产环境的复杂度及成本
- 实现应用程序的快速部署和分发
Docker可以被理解为一个程序, 可以直接安装到操作系统中, 像应用程序一样来操作它. Docker主要负责管理容器(Container)
Docker Engine是一个包含以下组件的客户端-服务端(C/S)应用程序

- 服务端 -- 一个长时间运行的守护进程(Docker Daemon)
- REST API -- 一套用于与Docker Daemon通信并指示其执行操作的接口
- 客户端 -- 命令行接口CLI(Command Line Interface)
- CLI利用Docker命令通过REST API直接操控Docker Daemon执行操作
- Docker Daemon负责创建并管理Docker的对象(镜像, 容器, 网络, 数据卷)(image, container, network, data volumes)
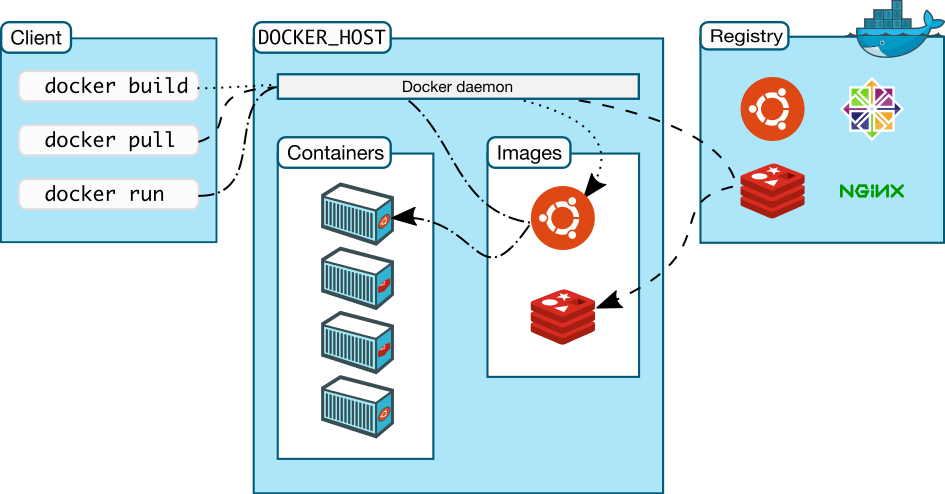
DOcker Client是用户与Docker进行交互的最主要方式. 当在终端输入docker命令时, 对应的就会在服务端产生对应的作用, 并把结果返回给客户端. Docker Client处理连接本地服务端,还可以通过更改或指定DOCKER_HOST连接远程服务端
Docker Daemon其实就是Docker的服务端. 它负责监听Docker API请求(如Docker Client)并管理Docker对象(Docker Objects), 如image, container, network, volume.
俗称DOcker仓库, 专门用于存储镜像的云服务环境
Docker Hub就是一个公有的存放镜像的地方, 类似Github存储代码文件. 同样的也可以类似Github那样搭建私有的仓库.
- 镜像:一个Docker的可执行文件, 其中包括运行程序所需的所有代码内容, 依赖库, 环境变量和配置文件等.
- 容器: 镜像被运行起来后的实例.
- 网络: 外部或者容器间如何相互访问的网络方式, 如host, bridge.
- 数据卷: 容器与宿主机之间, 容器与容器之间共享存储方式, 类似须立即与主机之间的共享文件目录.
研究技术的底层原理,非常有助于来使用这项新技术
Docker使用Go语言实现
Docker利用linux内核的几个特性来实现功能:
- Namespaces: 命名空间
- Control Groups: 控制组
- Union File Systems: 联合文件系统
这也就意味着Docker只能在linux上运行. 在windows, MacOS上运行Docker, 其实本质上是借助了虚拟化技术, 然后在linux虚拟机上运行的Docker程序.
Docker Engine将namespace , cgroups, UnionFS进行组合后的一个package, 就是一个容器格式(Container Format). Docker通过对这个package中的namespace, cgroups, UnionFS进行管理控制实现容器的创建和生命周期管理
容器格式(Container Format)有多种, 其中DOcker目前使用的容器格式被称为libcontainer
- 进程号隔离:每个容器内裕兴的第一个进程, 进程号总是从1开始起算
- 网络隔离: 容器的网络与宿主机或其他容器的网络是隔离的, 分开的, 也就是相当于两个网络
- 进程间通信隔离:容器中的进程与素质及或其他容器中的进程是互相不可见的, 通信需要借助网络
- 文件系统挂载隔离: 容器拥有自己单独的工作目录
- 内核以及系统版本号隔离: 容器查看内核版本号或者系统版本号时, 查看的是容器的, 而非宿主机的
- 控制组能控制应用程序所使用的硬件资源
- 基于该性质, 控制组帮助docker引擎将硬件资源共享给容器使用, 并且加以约束和限制. 如控制容器所使用的内存大小
在计算机中,虚拟化(英语:Virtualization)是一种资源管理技术,是将计算机的各种 实体资源,如服务器、网络、内存及存储等,予以抽象、转换后呈现出来,打破实体结构间 的不可切割的障碍,使用户可以比原本的组态更好的方式来应用这些资源。这些资源的新虚拟部份是不受现有资源的架设方式,地域或物理组态所限制。一般所指的虚拟化资源包括计算能力和资料存储。
在实际的生产环境中,虚拟化技术主要用来解决高性能的物理硬件产能过剩和老的旧的 硬件产能过低的重组重用,透明化底层物理硬件,从而最大化的利用物理硬件 对资源充 分利用
虚拟化技术种类分类: 软件虚拟化, 硬件虚拟化, 内存虚拟化, 网络虚拟化, 桌面虚拟化, 服务虚拟化, 虚拟机 ...
虚拟机的监视器(hypervisor)是类似于用户的应用程序运行在主机的 OS 之上,如 VMware 的 workstation,这种虚拟化产品提供了虚拟的硬件。
硬件层的虚拟化具有高性能和隔离性,因为 hypervisor 直接在硬件上运行,有利于控制 VM 的 OS 访问硬件资源,使用这种解决方案的产品有 VMware ESXi 和 Xen server
Hypervisor 是一种运行在物理服务器和操作系统之间的中间软件层,可允许多个操作系统和应用共享一套基础物理硬件,因此也可以看作是虚拟环境中的** “元”操作系统**,它可以 协调访问服务器上的所有物理设备和虚拟机,也叫虚拟机监视器(Virtual Machine Monitor, VMM)。
Hypervisor 是所有虚拟化技术的核心。当服务器启动并执行 Hypervisor 时,它会给每一 台虚拟机分配适量的内存、CPU、网络和磁盘,并加载所有虚拟机的客户操作系统。 宿主 机
**Hypervisor 是所有虚拟化技术的核心,软硬件架构和管理更高效、更灵活,硬件的效能 能够更好地发挥出来。**常见的产品有: VMware、KVM、Xen 等等。
在计算机的世界中,容器拥有一段漫长且传奇的历史。容器与管理程序虚拟化 (hypervisor virtualization,HV)有所不同,
- 管理程序虚拟化通过中间层将一台或者多台独立的机器虚拟运行于物理硬件之上,
- 而容器则是直接运行在操作系统内核之上的用户空间。
因 此,容器虚拟化也被称为“操作系统级虚拟化”,容器技术可以让多个独立的用户空间运行在同一台宿主机上。
由于“客居”于操作系统,容器只能运行与底层宿主机相同或者相似的操作系统,这看起来并不是非常灵活。例如:可以在 Ubuntu 服务中运行 Redhat Enterprise Linux,但无法再 Ubuntu 服务器上运行 Microsoft Windows。
相对于彻底隔离的管理程序虚拟化,容器被认为是不安全的。而反对这一观点的人则认为,由于虚拟容器所虚拟的是一个完整的操作系统,这无疑增大了攻击范围,而且还要考虑 管理程序层潜在的暴露风险。
尽管有诸多局限性,容器还是被广泛部署于各种各样的应用场合。在超大规模的多租户 服务部署、轻量级沙盒以及对安全要求不太高的隔离环境中,容器技术非常流行。最常见的 一个例子就是“权限隔离监牢”(chroot jail),它创建一个隔离的目录环境来运行进程。 如果权限隔离监牢正在运行的进程被入侵者攻破,入侵者便会发现自己“身陷囹圄”,因为 权限不足被困在容器所创建的目录中,无法对宿主机进一步破坏。
最新的容器技术引入了 OpenVZ、Solaris Zones 以及 Linux 容器(LXC)。使用这些新技 术,容器不在仅仅是一个单纯的运行环境。在自己的权限类内,容器更像是一个完整的宿主 机。对 Docker 来说,它得益于现代 Linux 特性,如控件组(control group)、命名空间 (namespace)技术,容器和宿主机之间的隔离更加彻底,容器有独立的网络和存储栈,还 拥有自己的资源管理能力,使得同一台宿主机中的多个容器可以友好的共存。
容器被认为是精益技术,因为容器需要的开销有限。和传统虚拟化以及半虚拟化相比, 容器不需要模拟层(emulation layer)和管理层( hypervisor layer),而是使用操作系统的系统调用接口。这降低了运行单个容器所需的开销,也使得宿主机中可以运行更多的容器。
尽管有着光辉的历史,容器仍未得到广泛的认可。一个很重要的原因就是容器技术的复 杂性:容器本身就比较复杂,不易安装,管理和自动化也很困难。而 Docker 就是为了改变这一切而生的。
本质上的区别
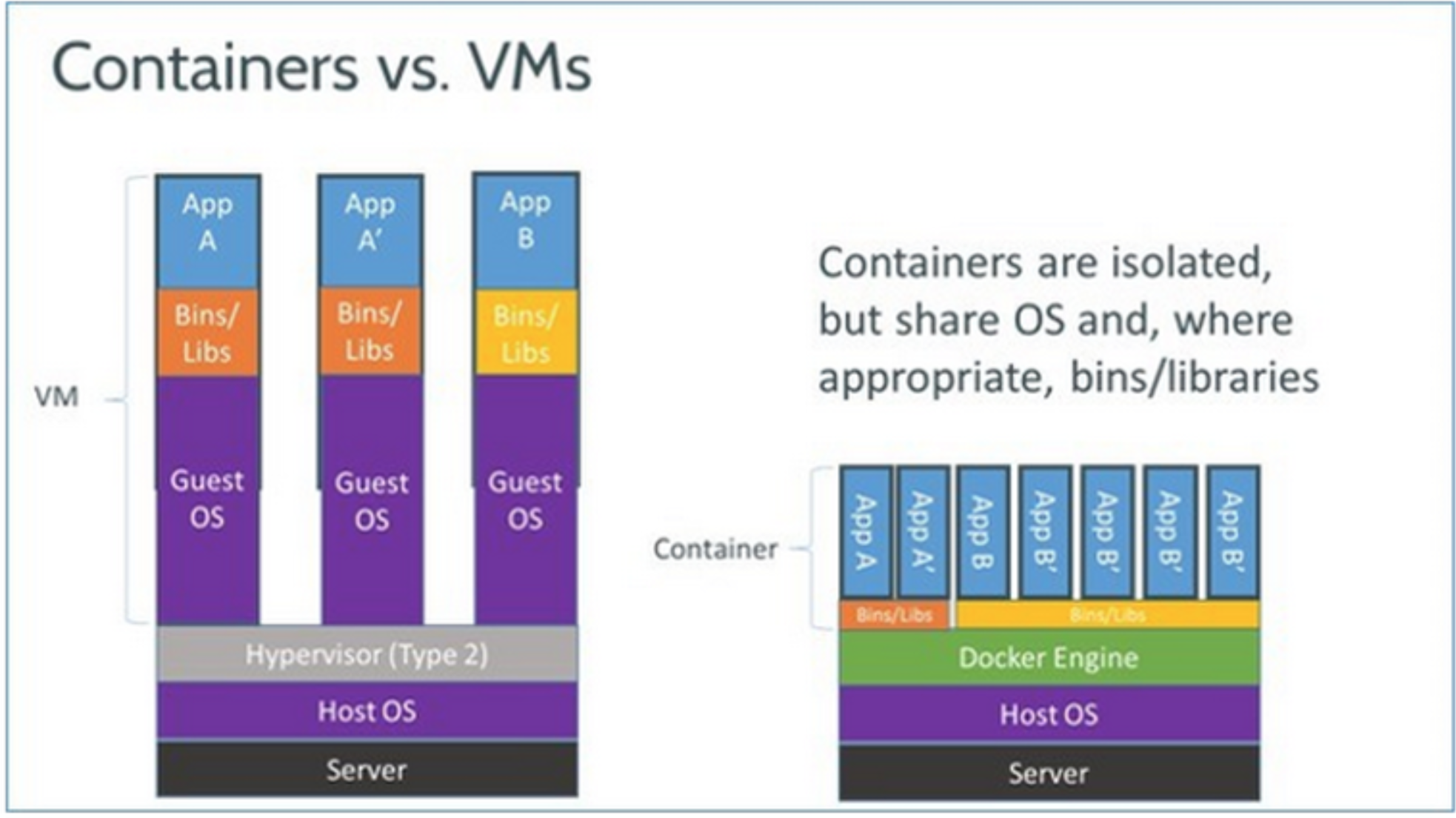
server 硬件
宿主机 host os
硬件抽象层 (cpu 内存 vm 软件)
vm os 虚拟机(运行)
依赖环境
程序
而docker因为docker engine的原因: 使用能复用就复用的原则:直接调用宿主机, 不会完全隔离, 还是会有相对应的隔离. 两个应用之间的依赖还能复用
VM 体型庞大, 运行速度慢
Docker相比VM具备尺寸更小, 启动速度更快, 整合性更强(集成性更好)
1)上手快
用户只需要几分钟,就可以把自己的程序“Docker 化”。Docker 依赖于“写时复制” (copy-on-write)模型,使修改应用程序也非常迅速,可以说达到“随心所致,代码即改” 的境界。
随后,就可以创建容器来运行应用程序了。大多数 Docker 容器只需要不到 1 秒中即可 启动。由于去除了管理程序的开销,Docker 容器拥有很高的性能,同时同一台宿主机中也 可以运行更多的容器 ,使用户尽可能的充分利用系统资源。
2)职责的逻辑分类
使用 Docker,开发人员只需要关心容器中运行的应用程序,而运维人员只需要关心如 何管理容器。Docker 设计的目的就是要加强开发人员写代码的开发环境与应用程序要部署 的生产环境一致性。从而降低那种“开发时一切正常,肯定是运维的问题(测试环境都是正 常的,上线后出了问题就归结为肯定是运维的问题)”
3)快速高效的开发生命周期
Docker 的目标之一就是缩短代码从开发、测试到部署、上线运行的周期,让你的应用 程序具备可移植性,易于构建,并易于协作。( 通俗一点说,Docker 就像一个盒子,里面 可以装很多物件,如果需要这些物件的可以直接将该大盒子拿走,而不需要从该盒子中一件 件的取。)
4)鼓励使用面向服务的架构
Docker 还鼓励面向服务的体系结构和微服务架构。Docker 推荐单个容器只运行一个应 用程序或进程,这样就形成了一个分布式的应用程序模型,在这种模型下,应用程序或者服 务都可以表示为一系列内部互联的容器,从而使分布式部署应用程序,扩展或调试应用程序 都变得非常简单,同时也提高了程序的内省性。( 当然,可以在一个容器中运行多个应用程 序)
- 一致的运行环境:Docker 的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性,从而不会再出现“这段代码在我机器上没问题啊”这类问题。
- 更快速的启动时间:可以做到秒级、甚至毫秒级的启动时间。大大的节约了开发、测试、部署的时间。
- 隔离性:避免公用的服务器,资源会容易受到其他用户的影响。
- 弹性伸缩,快速扩展:善于处理集中爆发的服务器使用压力。
- 迁移方便:可以很轻易的将在一个平台上运行的应用,迁移到另一个平台上,而不用担心运行环境的变化导致应用无法正常运行的情况。
- 持续交付和部署:使用Docker可以通过定制应用镜像来实现持续集成、持续交付、部署。
docker中最最重要的两个概念: 镜像(image) , 容器(container)
运行起来的镜像就是容器, 容器间相互隔离
Docker 是一个客户端-服务器(C/S)架构程序。Docker 客户端只需要向 Docker 服务器 或者守护进程发出请求,服务器或者守护进程将完成所有工作并返回结果。Docker 提供了 一个命令行工具 Docker 以及一整套 RESTful API。你可以在同一台宿主机上运行 Docker 守护 进程和客户端,也可以从本地的 Docker 客户端连接到运行在另一台宿主机上的远程 Docker 守护进程。
镜像是构建 Docker 的基石。用户基于镜像来运行自己的容器。镜像也是 Docker 生命周 期中的“构建”部分。镜像是基于联合文件系统的一种层式结构,由一系列指令一步一步构 建出来。例如:
添加一个文件;
执行一个命令;
打开一个窗口。
也可以将镜像当作容器的“源代码”。镜像体积很小,非常“便携”,易于分享、存储和更 新。
Docker 用 Registry 来保存用户构建的镜像。Registry 分为公共和私有两种。Docker 公司 运营公共的 Registry 叫做 Docker Hub。用户可以在 Docker Hub 注册账号,分享并保存自己的 镜像(说明:在 Docker Hub 下载镜像巨慢,可以自己构建私有的 Registry)。
Docker 可以帮助你构建和部署容器,你只需要把自己的应用程序或者服务打包放进容 器即可。容器是基于镜像启动起来的,容器中可以运行一个或多个进程。我们可以认为,镜像是Docker生命周期中的构建或者打包阶段,而容器则是启动或者执行阶段。 容器基于 镜像启动,一旦容器启动完成后,我们就可以登录到容器中安装自己需要的软件或者服务。
所以 Docker 容器就是: 一个镜像格式; 一些列标准操作; 一个执行环境。
Docker 借鉴了标准集装箱的概念。标准集装箱将货物运往世界各地,Docker 将这个模 型运用到自己的设计中,唯一不同的是:集装箱运输货物,而 Docker 运输软件。
和集装箱一样,Docker 在执行上述操作时,并不关心容器中到底装了什么,它不管是 web 服务器,还是数据库,或者是应用程序服务器什么的。所有的容器都按照相同的方式将 内容“装载”进去。
Docker 也不关心你要把容器运到何方:我们可以在自己的笔记本中构建容器,上传到 Registry,然后下载到一个物理的或者虚拟的服务器来测试,在把容器部署到具体的主机中。 像标准集装箱一样,Docker 容器方便替换,可以叠加,易于分发,并且尽量通用。
使用 Docker,我们可以快速的构建一个应用程序服务器、一个消息总线、一套实用工 具、一个持续集成(CI) 测试环境或者任意一种应用程序、服务或工具。我们可以在本地构 建一个完整的测试环境,也可以为生产或开发快速复制一套复杂的应用程序栈。
容器提供了隔离性,结论是,容器可以为各种测试提供很好的沙盒环境。并且,容器本
身就具有“标准性”的特征,非常适合为服务创建构建块。Docker 的一些应用场景如下:
- 加速本地开发和构建流程,使其更加高效、更加轻量化。本地开发人员可以构建、 运行并分享 Docker 容器。* 容器可以在开发环境中构建,然后轻松的提交到测试环境中,并 最终进入生产环境。*
- 能够让独立的服务或应用程序在不同的环境中,得到相同的运行结果。这一点在 面向服务的架构和重度依赖微型服务的部署由其实用。
- 用 Docker 创建隔离的环境来进行测试。例如,用 Jenkins CI 这样的持续集成工具 启动一个用于测试的容器。
- Docker 可以让开发者先在本机上构建一个复杂的程序或架构来进行测试,而不是 一开始就在生产环境部署、测试。
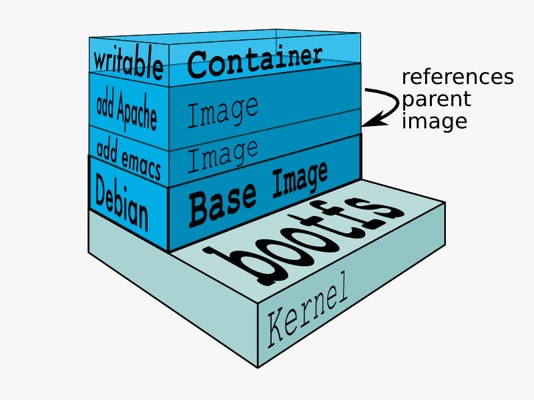
Docker 镜像是由文件系统叠加而成(是一种文件的存储形式)。最底端是一个文件引 导系统,即 bootfs,这很像典型的 Linux/Unix 的引导文件系统。Docker 用户几乎永远不会和 引导系统有什么交互。实际上,当一个容器启动后,它将会被移动到内存中,而引导文件系统则会被卸载,以留出更多的内存供磁盘镜像使用。Docker 容器启动是需要一些文件的, 而这些文件就可以称为 Docker 镜像。
**Docker 把应用程序及其依赖,打包在 image 文件里面。**只有通过这个文件,才能生成 Docker 容器。**image 文件可以看作是容器的模板 **。Docker 根据 image 文件生成容器的实例。同一个 image 文件,可以生成多个同时运行的容器实例。
image 是二进制文件。实际开发中,一个 image 文件往往通过继承另一个 image 文件,加上一些个性化设置而生成。举例来说,你可以在 Ubuntu 的 image 基础上,往里面加入 Apache 服务器,形成你的 image。
image 文件是通用的,一台机器的 image 文件拷贝到另一台机器,照样可以使用。一般来说,为了节省时间,我们应该尽量使用别人制作好的 image 文件,而不是自己制作。即使要定制,也应该基于别人的 image 文件进行加工,而不是从零开始制作。
为了方便共享,image 文件制作完成后,可以上传到网上的仓库。Docker 的官方仓库 Docker Hub 是最重要、最常用的 image 仓库。此外,出售自己制作的 image 文件也是可以的。
docker 命令其实是都对应有REST API端点, 本质上是与Docker的守护进程交互
镜像是一个Docker的可执行文件, 其中包括运行应用程序所需的所有代码内容, 依赖库, 环境变量和配置文件.
通过镜像可以创建一个或多个容器.
系统镜像(ubuntu):常被用来指定一些bash命令
应用镜像(redis, mysql): 启动一些服务
# 镜像搜索
docker search [OPTIONS] COMMAND
docker search --no-trunc ubuntu
# 列出和查看本地镜像
docker images [OPTIONS] [REPOSOTRY[:TAG]]
docker image ls [OPTIONS] [REPOSITORY[:TAG]]
docker image ls -a - REPOSITORY:镜像所在的仓库名称 带斜线的是非官方上传镜像
- TAG:镜像标签
- IMAGEID:镜像ID
- CREATED:镜像的创建日期(不是获取该镜像的日期)
- SIZE:镜像大小
为了区分同一个仓库下的不同镜像,Docker 提供了一种称为标签(Tag)的功能。每个 镜像在列出来时都带有一个标签,例如latest、 12.10、12.04 等等。每个标签对组成特定镜像的一 些镜像层进行标记(比如,标签 12.04 就是对所有 Ubuntu12.04 镜像层的标记)。这种机制 使得同一个仓库中可以存储多个镜像。--- 版本号
我们在运行同一个仓库中的不同镜像时,可以通过在仓库名后面加上一个冒号和标签名 来指定该仓库中的某一具体的镜像,例如 docker run --name custom_container_name –i –t docker.io/ubunto:12.04 /bin/bash,表明从镜像 Ubuntu:12.04 启动一个容器,而这个镜像的操 作系统就是 Ubuntu:12.04。在构建容器时指定仓库的标签也是一个好习惯。
Docker维护了镜像仓库,分为共有和私有两种,共有的官方仓库Docker Hub(https://hub.docker.com/) 是最重要最常用的镜像仓库。私有仓库(Private Registry)是开发者或者企业自建的镜像存储库,通常用来保存企业 内部的 Docker 镜像,用于内部开发流程和产品的发布、版本控制。
要想获取某个镜像,我们可以使用pull命令,从仓库中拉取镜像到本地,如
docker image pull library/hello-world上面代码中,docker image pull是抓取 image 文件的命令。library/hello-world是 image 文件在仓库里面的位置,其中library是
image 文件所在的组,hello-world是 image 文件的名字。
由于 Docker 官方提供的 image 文件,都放在library
组里面,所以它的是默认组,可以省略。因此,上面的命令可以写成下面这样。
# 拉取镜像
docker pull [OPTIONS] NAME[:TAG|@DIGEST]
docker image pull hello-world# 删除镜像
docker rmi [OPTIONS] IMAGE/ID
docker image rm [OPTIONS] NAME | ID
docker image rm 镜像名或镜像id
# 用法示例(可同时删除多个镜像)
docker image rm -f hello-world ubuntu
-f, --force 强制删除作用: 将本地的一个或多个镜像打包成本地tar文件(输出到STDOUT)
# 命令格式
docker save [OPTIONS] IMAGE [IMAGE2]
# 用法示例(多个镜像会打包成一个文件)
docker save -o linux_images.tar centos ubuntu
# 可选参数
-o, --output string 指定写入的文件名和路径
将save命令打包的镜像导入本地镜像库中
# 命令格式
docker load [OPTIONS]
docker load -i linux_images.tar -q
# 可选参数
-i, --input string 指定要打入的文件, 如果没有指定, 默认是STDIN
-q, --quiet 静默导入, 不打印导入过程信息对本地镜像的NAME, TAG进行重命名, 并新产生一个命名后的镜像
# 命令格式
docker tag source_IMAGE[:TAG] TARGET_IMAGE[:TAG]
#用法示例
docker tag e934 centos-new:newtag查看本地一个或多个镜像的详细信息
# 命令格式
docker image inspect IMAGE [IMAGE2]
docker inspect IMAGE [IMAGE2]
# 用法示例
docker image inspect centos
docker image inspect -f "{{.Architecture}}" redis
docker inspect -f "{{json .ID}}" centosdocker history Show the history of an image
作用: 查看本地一个镜像的历史(历史分层)信息
# 语法格式
docker history [OPTIONS] IMAGE
# 可选参数
--format string Pretty-print images using a Go template
-H, --human Print sizes and dates in human readable format (default true)
--no-trunc Don't truncate output
-q, --quiet Only show numeric IDs
# 用法示例
docker history ubuntudocker image prune -f容器相关的命令 container关键字几乎都可以忽略
比如 docker inspect = docker container inspect
容器(Container):容器是一种轻量级、可移植、并将应用程序进行的打包的技术,使应用程序可以在几乎任何地方以相同的方式运行
•Docker将镜像文件运行起来后,产生的对象就是容器。容器相当于是镜像运行起来的一个实例。
•容器具备一定的生命周期。
•另外,可以借助docker ps命令查看运行的容器,如同在linux上利用ps命令查看运行着的进程那样。
•容器和虚拟机一样,都会对物理硬件资源进行共享使用。
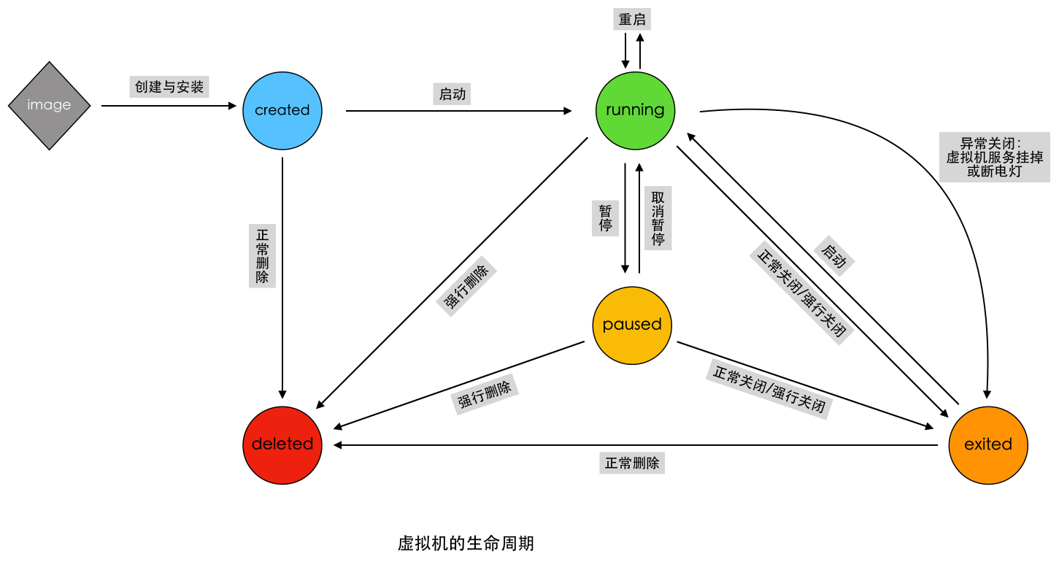
•容器和虚拟机的生命周期比较相似(创建、运行、暂停、关闭等等)。
•容器中或虚拟机中都可以安装各种应用,如redis、mysql、nginx等。也就是说,在容器中的操作,如同在一个虚拟机(操作系统)中操作一样。
•同虚拟机一样,容器创建后,会存储在宿主机上:linux上位于/var/lib/docker/containers下
注意:容器并不是虚拟机,尽管它们有很多相似的地方
•虚拟机的创建、启动和关闭都是基于一个完整的操作系统。一个虚拟机就是一个完整的操作系统。**而容器直接运行在宿主机的内核上,其本质上以一系列进程的结合。 **
•容器是轻量级的,虚拟机是重量级的。首先容器不需要额外的资源来管理(不需要Hypervisor、Guest OS) ,虚拟机需要额外更多的性能消耗;其次创建、启动或关闭容器,如同创建、启动或者关闭进程那么轻松,而创建、启动、关闭一个操作系统就没那么方便了。
•也因此,意味着在给定的硬件上能运行更多数量的容器,甚至可以直接把Docker运行在虚拟机上。
Created Running Exited Restarting
镜像是根据层级结构(layer)搭建起来的, 层级之间通过指针产生联系, 必须有过更改才会产生新的layer, 文件系统发生了更改就会产生新的层级, 每一层layer就是一个文件系统, 镜像的底层实现是只读文件系统
默认只能查看到最新的一层文件
image: unioned read-only file system
一系列只读联合文件系统, docker可以访问这个文件系统
create 命令会创建一个可读可写层文件系统(write-read layer), 位于镜像层的上方, 当执行docker commit命令后, 会将该( read-write layer)锁定为read layer 产生新的镜像
通过 docker ps 只能查看 read-write layer 层的联合可读写文件系统(镜像层会被显示为虚拟内存)
容器是基于镜像所形成的联合文件系统
联合文件系统 配合 Process Space 运行, 通过命令和操作产生新的文件, 存入 可读写文件层
New file to be found in the read-write top layer
docker 利用了集装箱的思想 不断的堆积, 底层可以不断的被复用
https://docs.docker.com/reference/cli/docker/
docker pull --platform linux/amd64 node:20https://docs.docker.com/reference/cli/docker/buildx/build/#build-arg
使用 docker buildx build
docker build --build-arg A=1 --build-arg B=2
docker buildx build --build-arg HTTP_PROXY=http://10.20.30.2:1234 --build-arg FTP_PROXY=http://40.50.60.5:4567 .# 多平台构建
docker buildx build --platform linux/amd64,linux/arm64 .
# 多构建参数
docker buildx build --build-arg HTTP_PROXY=http://10.20.30.2:1234 --build-arg FTP_PROXY=http://40.50.60.5:4567 .只是创建了容器, 并没有运行(被创建状态)
docker create: Create a new container
应用场景 / 作用:
利用(基于)镜像创建出一个Created状态的待启动容器
# 语法格式
docker create [OPTIONS] IMAGE [COMMAND] [ARG...]
# command: 启动容器后需要在容器中执行的命令
# arguments: 执行命令时需要用到的参数
# 用法示例
docker create --name test-container centos ps -A
docker create -it --name testcontainer2 centos /bin/bash•命令参数(OPTIONS):查看更多
-t, --tty 分配一个伪TTY, 也就是分配虚拟终端(进入容器的命令行)
-i, --interactive 即使没有连接,也要保持STDIN(standard input)打开
--name 为容器命名,如果没有指定将会随机产生一个名称
•命令参数(COMMAND\ARG):
COMMAND表示容器启动后,需要在容器中执行的命令,如ps、ls 等命令
ARG表示执行 COMMAND 时需要提供的一些参数,如ps 命令的 aux、ls命令的-a等等
docker start Start one or more stopped containers
应用场景/作用: 将一个或多个处于创建或关闭状态的容器启动起来
# 语法格式
docker start [OPTIONS] CONTAINER [CONTAINER...]
# 可选参数
-a, --attach Attach STDOUT/STDERR and forward signals # 将当前shell的STDOUT/STDERR连接到容器上
--detach-keys string Override the key sequence for detaching a container
-i, --interactive "Attach container's STDIN" # 将当前shell的STDIN连接到容器上
# 用法示例
docker start -i my_redis
>>> root@4b66edbad2fe:/data# ls
docker start -a 1aac2527b6eadocker run Run a command in a new container
作用: 利用基于镜像创建并启动一个容器
# 覆盖CMD
docker run ... echo hello world
docker run --rm ubuntu pwd
docker run --rm --gpus all nvidia/cuda:12.4.1-cudnn-devel-ubuntu22.04 nvidia-smi# 语法格式/用法
docker run [option] 镜像名 [向启动容器中传入的命令]
docker run [OPTIONS] IMAGE [COMMAND] [ARG...]
# 可选参数
Options:
--add-host list Add a custom host-to-IP mapping (host:ip)
-a, --attach list Attach to STDIN, STDOUT or STDERR
--blkio-weight uint16 Block IO (relative weight), between 10 and 1000, or 0 to disable (default 0)
--blkio-weight-device list Block IO weight (relative device weight) (default [])
--cap-add list Add Linux capabilities
--cap-drop list Drop Linux capabilities
--cgroup-parent string Optional parent cgroup for the container
--cidfile string Write the container ID to the file
--cpu-period int Limit CPU CFS (Completely Fair Scheduler) period
--cpu-quota int Limit CPU CFS (Completely Fair Scheduler) quota
--cpu-rt-period int Limit CPU real-time period in microseconds
--cpu-rt-runtime int Limit CPU real-time runtime in microseconds
-c, --cpu-shares int CPU shares (relative weight)
--cpus decimal Number of CPUs
--cpuset-cpus string CPUs in which to allow execution (0-3, 0,1)
--cpuset-mems string MEMs in which to allow execution (0-3, 0,1)
-d, --detach Run container in background and print container ID
--detach-keys string Override the key sequence for detaching a container
--device list Add a host device to the container
--device-cgroup-rule list Add a rule to the cgroup allowed devices list
--device-read-bps list Limit read rate (bytes per second) from a device (default [])
--device-read-iops list Limit read rate (IO per second) from a device (default [])
--device-write-bps list Limit write rate (bytes per second) to a device (default [])
--device-write-iops list Limit write rate (IO per second) to a device (default [])
--disable-content-trust Skip image verification (default true)
--dns list Set custom DNS servers
--dns-option list Set DNS options
--dns-search list Set custom DNS search domains
--domainname string Container NIS domain name
--entrypoint string Overwrite the default ENTRYPOINT of the image
-e, --env list Set environment variables
--env-file list Read in a file of environment variables
--expose list Expose a port or a range of ports
--gpus gpu-request GPU devices to add to the container ('all' to pass all GPUs)
--group-add list Add additional groups to join
--health-cmd string Command to run to check health
--health-interval duration Time between running the check (ms|s|m|h) (default 0s)
--health-retries int Consecutive failures needed to report unhealthy
--health-start-period duration Start period for the container to initialize before starting health-retries countdown (ms|s|m|h) (default 0s)
--health-timeout duration Maximum time to allow one check to run (ms|s|m|h) (default 0s)
--help Print usage
-h, --hostname string Container host name
--init Run an init inside the container that forwards signals and reaps processes
-i, --interactive Keep STDIN open even if not attached
--ip string IPv4 address (e.g., 172.30.100.104)
--ip6 string IPv6 address (e.g., 2001:db8::33)
--ipc string IPC mode to use
--isolation string Container isolation technology
--kernel-memory bytes Kernel memory limit
-l, --label list Set meta data on a container
--label-file list Read in a line delimited file of labels
--link list Add link to another container
--link-local-ip list Container IPv4/IPv6 link-local addresses
--log-driver string Logging driver for the container
--log-opt list Log driver options
--mac-address string Container MAC address (e.g., 92:d0:c6:0a:29:33)
-m, --memory bytes Memory limit
--memory-reservation bytes Memory soft limit
--memory-swap bytes Swap limit equal to memory plus swap: '-1' to enable unlimited swap
--memory-swappiness int Tune container memory swappiness (0 to 100) (default -1)
--mount mount Attach a filesystem mount to the container
--name string Assign a name to the container
--network network Connect a container to a network
--network-alias list Add network-scoped alias for the container
--no-healthcheck Disable any container-specified HEALTHCHECK
--oom-kill-disable Disable OOM Killer
--oom-score-adj int Tune host's OOM preferences (-1000 to 1000)
--pid string PID namespace to use
--pids-limit int Tune container pids limit (set -1 for unlimited)
--privileged Give extended privileges to this container
-p, --publish list Publish a container's port(s) to the host
-P, --publish-all Publish all exposed ports to random ports
--read-only Mount the container's root filesystem as read only
--restart string Restart policy to apply when a container exits (default "no")
--rm Automatically remove the container when it exits
--runtime string Runtime to use for this container
--security-opt list Security Options
--shm-size bytes Size of /dev/shm
--sig-proxy Proxy received signals to the process (default true)
--stop-signal string Signal to stop a container (default "SIGTERM")
--stop-timeout int Timeout (in seconds) to stop a container
--storage-opt list Storage driver options for the container
--sysctl map Sysctl options (default map[])
--tmpfs list Mount a tmpfs directory
-t, --tty Allocate a pseudo-TTY
--ulimit ulimit Ulimit options (default [])
-u, --user string Username or UID (format: <name|uid>[:<group|gid>])
--userns string User namespace to use
--uts string UTS namespace to use
-v, --volume list Bind mount a volume
--volume-driver string Optional volume driver for the container
--volumes-from list Mount volumes from the specified container(s)
-w, --workdir string Working directory inside the container
# 用法示例
docker run -it --name mytest redis
docker run -d redis
docker run -d --rm redis
docker run -d --rm --name haha redis echo 'haha'
-e TZ=Aisa/Shanghai
常用可选参数说明:
- -i,--interactive 即使没有连接, 也要保持STDIN表示以“交互模式”运行容器
- -t,--tty 表示容器启动后会进入其命令行。加入这两个参数后, 容器创建就能登录进去。即分配一个伪终端。
- --name string 为创建的容器命名
- -v 表示目录映射关系(前者是宿主机目录,后者是映射到宿主机上的目录,即 宿主机目录:容器中目录),可以使 用多个-v 做多个目录或文件映射。注意:最好做目录映射,在宿主机上做修改,然后 共享到容器上。
- -d 在run后面加上-d参数,则会创建一个守护式容器在后台运行(这样创建容器后不 会自动登录容器,如果只加-i -t 两个参数,创建后就会自动进去容器)。
- -p 表示端口映射,前者是宿主机端口,后者是容器内的映射端口。可以使用多个-p 做多个端口映射
- -e 为容器设置环境变量
- -h 指定主机名
- --network=host 表示将主机的网络环境映射到容器中,容器的网络与主机相同
- --rm 当容器退出运行后,自动删除容器
例如,创建一个交互式容器,并命名为myubuntu
docker run -it --name=myubuntu ubuntu /bin/bash在容器中可以随意执行linux命令,就是一个ubuntu的环境,当执行exit命令退出时,该容器也随之停止。
创建一个守护式容器:如果对于一个需要长期运行的容器来说,我们可以创建一个守护式容器。在容器内部exit退出时,容器也不会停止。
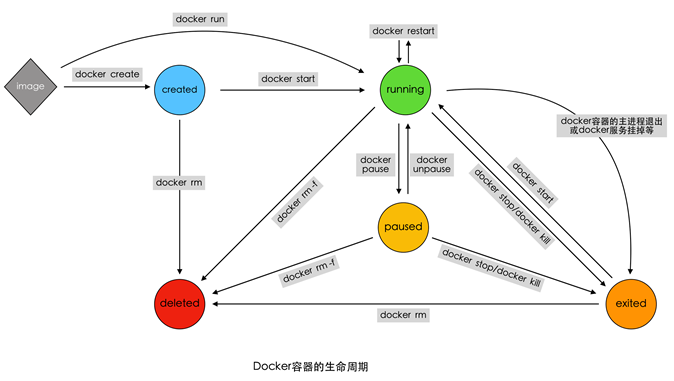
docker run -dit --name=myubuntu2 ubuntu# 两种创建方式的区别
docker run 相当于 docker create + docker start -a 前台模式
docker run -d 相当于 docker create + docker start 后台模式docker pause Pause all processes within one or more containers
作用: 暂停一个或多个处于运行状态的容器
# 语法格式 Usage
docker pause CONTAINER [CONTAINER...]
# 用法示例 Examples
docker ps -a
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS
# 95bcadb01c10 redis "docker-entrypoint.s…" 17 minutes ago Up 17 minutes 6379/tcp
docker pause 95bcadb01c10 4b66edbad2fe
docker ps -a
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS
# 95bcadb01c10 redis "docker-entrypoint.s…" 18 minutes ago Up 18 minutes (Paused) 6379/tcp
docker unpause Unpause all processes within one or more containers
作用: 取消一个或多个处于暂停状态的容器, 恢复运行
# 语法格式 Usage
docker unpause CONTAINER [CONTAINER...]
# 用法示例 Examples
docker unpause 95bcadb01c10 docker stop Stop one or more running containers
作用: 关闭一个或多个处于暂停或运行状态的容器
# 语法格式 Usage
docker stop [OPTIONS] CONTAINER [CONTAINER...]
docker stop 容器名或容器id
# 可选参数 Options
-t,--time int Seconds to wait for stop before killing it (default 10) # 关闭前等待数秒(默认10S)
# 用法示例 Examples
docker ps -a
docker stop 4b66edbad2fe 95bcadb01c10
docker ps -a | grep -e 4b66edbad2fe -e 95bcadb01c10
# kill掉一个已经在运行的容器
docker kill 容器名或容器iddocker kill Kill one or more running containers
强制并立即关闭处于暂停或运行状态的容器
# 语法格式 Usage
docker kill [OPTIONS] CONTAINER [CONTAINER...]
#可选参数 OPTIONS
-s, --signal string Signal to send to the container (default "KILL") # 指定发送给容器的关闭信号
# 用法示例 Examples
docker kill hahaha
前提知识点:
Linux其中两种终止进程的信号是:SIGTERM和SIGKILL
- SIGKILL信号:无条件终止进程信号。进程接收到该信号会立即终止,不进行清理和暂存工作。该信号不能被忽略、处理和阻塞,它向系统管理员提供了可以杀死任何进程的方法。
- SIGTERM信号:程序终结信号,可以由kill命令产生。与SIGKILL不同的是,SIGTERM信号可以被阻塞和终止 ,以便程序在退出前可以保存工作或清理临时文件等。
docker stop 会先发出SIGTERM信号给进程,告诉进程即将会被关闭。在-t指定的等待时间过了之后,将会立即发出SIGKILL信号,直接关闭容器。
docker kill 直接发出SIGKILL信号关闭容器。但也可以通过-s参数修改发出的信号。
因此会发现在docker stop的等过过程中,如果终止docker stop的执行,容器最终没有被关闭。而docker kill几乎是立刻发生,无法撤销。
此外还有些异常原因也会导致容器被关闭,比如docker daemon重启、容器内部进程运行发生错误等等“异常原因”。
docker restart Restart one or more containers
作用: 重启一个或多个处于运行状态、暂停状态、关闭状态或者新建状态的容器
该命令相当于stop和start命令的结合
# 语法格式 Usage
docker restart [OPTIONS] CONTAINER [CONTAINER...]
# 可选参数 Options
-t, --time int Seconds to wait for stop before killing the container (default 10) # 终止容器前等待数秒
# 用法示例 Examples
docker restart hahaha mytest
docker rm Remove one or more containers
作用: 删除一个或多个容器
# 语法格式 Usage
docker rm [OPTIONS] CONTAINER [CONTAINER...]
docker container rm 容器名或容器id
# 可选参数 OPTIONS
-f, --force Force the removal of a running container (uses SIGKILL) # 强行删除容器(向容器发送SIGKILL信号)
-l, --link Remove the specified link
-v, --volumes Remove the volumes associated with the container # 同时删除绑定在容器上的数据卷
# 用法示例 Examples
docker rm -f fervent_blackwell objective_khayyam sleepy_mirzakhani admiring_neumanndocker rename Rename a container
作用: 修改容器的名称
# 语法格式
docker rename CONTAINER NEW_NAME
# 用法示例
docker rename hahaha my_redis
docker attach Attach local standard input, output, and error streams to a running container
作用: 将当前终端的STDIN、STDOUT、STDERR绑定到正在运行的容器的主进程上实现连接
# 语法格式
docker attach [OPTIONS] CONTAINER
# 可选参数
--detach-keys string Override the key sequence for detaching a container
--no-stdin Do not attach STDIN
--sig-proxy Proxy all received signals to the process (default true)
运行中的容器执行命令, 容器中执行新命令
docker exec Run a command in a running container
作用: 向运行中的容器执行命令, 用于执行维护工作
# 语法格式
docker exec -it 容器名或容器id 进入后执行的第一个命令
# 可选参数
-d, --detach Detached mode: run command in the background # 后台运行命令
--detach-keys string Override the key sequence for detaching a container
-e, --env list Set environment variables # 设置容器运行时的环境变量
-i, --interactive Keep STDIN open even if not attached # 保持STDIN绑定, 即使没有连接容器
--privileged Give extended privileges to the command
-t, --tty Allocate a pseudo-TTY # 分配一个虚拟终端
-u, --user string Username or UID (format: <name|uid>[:<group|gid>])
-w, --workdir string Working directory inside the container # 指定容器中运行时的环境变量
# 用法示例
docker exec -it myubuntu2 /bin/bashdocker ps List containers
作用: 列出正在运行的容器
# 列出本机正在运行的容器
docker ps [OPTIONS]
docker container ls | ps | list [OPTIONS]
# 可选参数 OPTIONS
-a, --all Show all containers (default shows just running)
-f, --filter filter Filter output based on conditions provided
--format string Pretty-print containers using a Go template
-n, --last int Show n last created containers (includes all states) (default -1)
-l, --latest Show the latest created container (includes all states)
--no-trunc Don't truncate output
-q, --quiet Only display numeric IDs
-s, --size Display total file sizes
# 列出本机所有容器,包括已经终止运行的
docker container ls --all
docker ps -asdocker inspect Return low-level information on Docker objects
作用: 查看容器的低层级详细信息
# 语法格式 Usage
docker inspect [OPTIONS] NAME|ID [NAME|ID...]
# 可选参数 OPTIONS
-f, --format string Format the output using the given Go template
-s, --size Display total file sizes if the type is container
--type string Return JSON for specified type
# 用法示例 Examples
docker inspect hahaha -s
docker inspect --format='{{.LogPath}}' redis
docker logs Fetch the logs of a container
作用: 查看容器的日志信息
注意: 容器日志中记录的是容器主进程的输出 STDOUT \ STDERR
# 语法格式 Usage
docker logs [OPTIONS] CONTAINER
# 可选参数
--details Show extra details provided to logs # 显示日志的额外信息
-f, --follow Follow log output # 动态跟踪显示日志信息
--since string Show logs since timestamp (e.g. 2013-01-02T13:23:37) or relative (e.g. 42m for 42 minutes)
--tail string Number of lines to show from the end of the logs (default "all")
-t, --timestamps Show timestamps
--until string Show logs before a timestamp (e.g. 2013-01-02T13:23:37) or relative (e.g. 42m for 42 minutes)
docker top
作用: 查看容器中的进程的信息
# 语法格式 Usage
docker top CONTAINER [ps OPTIONS]连接两个容器, 创建一个网络, 然后分别将他们链接到该网络中
也可以在创建(run)容器时设置network, 当两个容器网络相同时则表示二则在同一个网络环境下
同一网络下各自的地址默认是该容器的名称
docker network create [OPTIONS] NETWORK
# Connect a container to a network
docker network connect [OPTION] NETWORK CONTAINER
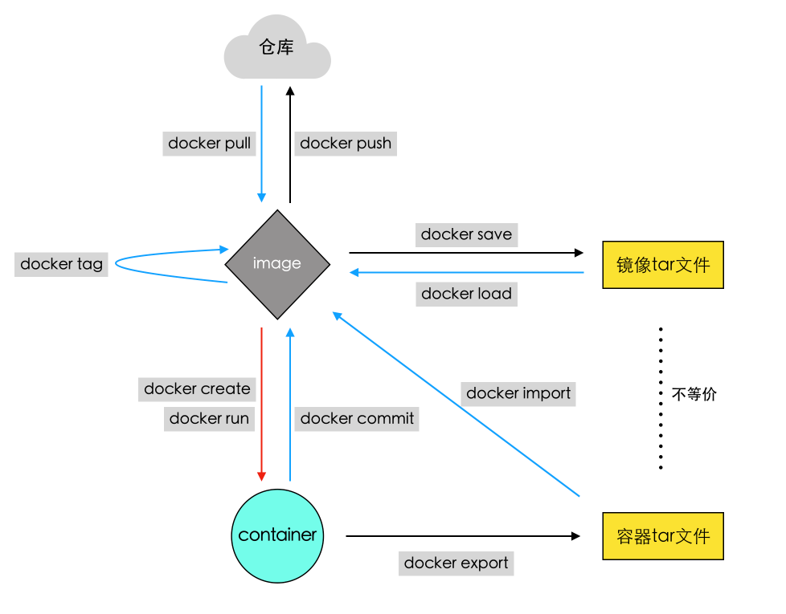
从容器中创建一个新的镜像, 提交容器为镜像
docker commit Create a new image from a container's changes
作用: 根据容器生成一个新的镜像
# 语法格式
docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]]
# 可选参数 Options:
-a, --author string Author (e.g., "John Hannibal Smith <hannibal@a-team.com>") # 指定作者信息
-c, --change list Apply Dockerfile instruction to the created image # 为创建的镜像加入dockerfile命令
-m, --message string Commit message # 提交信息 类似git commit -m
-p, --pause Pause container during commit (default true) # 提交时暂停容器
# 用法示例
docker pull ubuntu:disco
docker images
docker run --rm -dti ubuntu:disco bash
docker exec -d 62d7 apt install tree # 62d7 为容器id
docker commit -m "install tree" 62d7 mytest:latest
docker images
docker history mytest:latest查看docker容器进程的资源占用率
docker export Export a container's filesystem as a tar archive
作用: 将容器的文件系统导出为一个tar包存档
# 语法格式
docker export [OPTIONS] CONTAINER
# 可选参数
-o, --output string Write to a file, instead of STDOUT # 导出到一个文件, 而非标准输出流(STDOUT)
# 用法示例
docker export -o test_container.tar 62d71文件应该是 容器tar文件, 由
docker export命令导出, 应该注意区分容器tar文件 和镜像tar文件
docker import Import the contents from a tarball to create a filesystem image
作用: 从一个tar文件中导入内容, 创建一个镜像
# 语法格式
docker import [OPTIONS] file|URL|- [REPOSITORY[:TAG]]
# 可选参数
-c, --change list Apply Dockerfile instruction to the created image
-m, --message string Set commit message for imported image
# 用法示例
cat exampleimage.tgz | docker import - exampleimagelocal:ne w
docker import nginx-test.tar nginx:test
优先推荐使用commit方法
通过查看两个镜像的历史信息可知
commit是继承, import是合并后重建
commit会保留父镜像的元数据, import则需要重写
scan 扫描本地镜像隐患
docker volume ls
docker 容器的网络默认与宿主机、与其他容器都是相互隔离。
•容器中可以运行一些网络应用(如nginx、web应用、数据库等),如果要让外部也可以访问这些容器内运行的网络应用,那么就需要配置网络来实现。
•有可能有的需求下,容器不想让它的网络与宿主机、与其他容器隔离。
•有可能有的需求下,容器根本不需要网络。
•有可能有的需求下,容器需要更高的定制化网络(如定制特殊的集群网络、定制容器间的局域网)。
•有可能有的需求下, 容器数量特别多,体量很大的一系列容器的网络管理如何
•……
因此容器的网络管理是非常重要的
Docker有五种网络驱动模式
•bridge network 模式(网桥):默认的网络模式。类似虚拟机的nat模式
•host network 模式(主机):容器与宿主机之间的网络无隔离,即容器直接使用宿主机网络
•None network 模式:容器禁用所有网络。
•Overlay network 模式(覆盖网络): 利用VXLAN实现的bridge模式
•Macvlan network 模式:容器具备Mac地址,使其显示为网络上的物理设备
docker network ls List networks
作用: 列出&查看已经建立的网络对象
注意: 默认情况下, docker安装完成后, 会自动创建bridge, host, none三种网络驱动
# 语法格式
docker network ls [OPTIONS]
# 可选参数
-f, --filter filter Provide filter values (e.g. 'driver=bridge')
--format string Pretty-print networks using a Go template
--no-trunc Do not truncate the output
-q, --quiet Only display network IDs
# 用法示例
docker network create create a network
作用: 创建新的网路对象
注意:
host 和 none 模式网络只能存在一个
docker自带的overlay网络创建依赖于docker swarm(集群负载均衡)服务
192.168.0.0/16 等于 192.168.0.0~192.168.255.255 192.168.8.0/24
172.88.0.0/24 等于172.88.0.0~172.88.0.255
# 语法格式
docker network create [OPTIONS] NETWORK
# 可选参数
--attachable Enable manual container attachment
--aux-address map Auxiliary IPv4 or IPv6 addresses used by Network driver (default map[])
--config-from string The network from which copying the configuration
--config-only Create a configuration only network
-d, --driver string Driver to manage the Network (default "bridge") # 指定网络的驱动(默认: bridge)
--gateway strings IPv4 or IPv6 Gateway for the master subnet # 子网的IPv4 or IPv6网关, 如(192.168.0.1)
--ingress Create swarm routing-mesh network
--internal Restrict external access to the network
--ip-range strings Allocate container ip from a sub-range # 执行容器的IP范围, 格式同subnet参数
--ipam-driver string IP Address Management Driver (default "default")
--ipam-opt map Set IPAM driver specific options (default map[])
--ipv6 Enable IPv6 networking
--label list Set metadata on a network
-o, --opt map Set driver specific options (default map[])
--scope string Control the network's scope
--subnet strings Subnet in CIDR format that represents a network segment # 指定子网网段(192.168.0.0/16)
# 用法示例
network create -d bridge my-bridgedocker network rm Remove one or more networks
作用: 删除一个或多个网络
# 语法格式
docker network rm NETWORK [NETWORK...]
# 可选参数
Aliases:
rm, remove
# 用法示例
docker network rm my-bridgedocker network inspect Display detailed information on one or more networks
作用: 查看一个或多个网络的详细信息
# 语法格式
docker network inspect [OPTIONS] NETWORK [NETWORK...]
# 可选参数
-f, --format string Format the output using the given Go template
-v, --verbose Verbose output for diagnostics
# 用法示例
docker network inspect bridgedocker run --network Connect a container to a network
作用: 为启动的容器指定网络模式
注意: 默认情况下,docker创建或启动容器时,会默认使用名为bridge的网络
docker network connect/disconnect Connect/Disconnect a container to a network
作用: 将指定容器与指定网络进行连接或者断开连接
# 语法格式
docker network connect [OPTIONS] NETWORK CONTAINER
# 可选参数
-f, --force 强制断开连接(用于disconnect)特点:
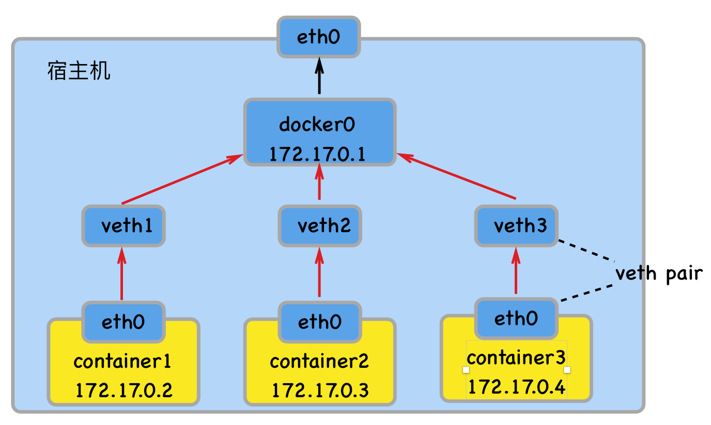
- 宿主机上需要单独的bridge网卡,如默认docker默认创建的docker0。
- 容器之间、容器与主机之间的网络通信,是借助为每一个容器生成的一对veth pair虚拟网络设备对,进行通信的。一个在容器上,另一个在宿主机上。
- 每创建一个基于bridge网络的容器,都会自动在宿主机上创建一个veth**虚拟网络设备。
- 外部无法直接访问容器。需要建立端口映射才能访问。
- 容器借由veth虚拟设备通过如docker0这种bridge网络设备进行通信。 每一容器具有单独的IP
作用: 启动的容器时,为容器进行端口映射 命令格式: docker run/create -P … 或者 docker run/create –p … 命令参数(OPTIONS): -P, --publish-all 将容器内部所有暴露端口进行随机映射 -p, --publish list 手动指定端口映射 注意: -p [HOST_IP]:[HOST_PORT]:CONTAINER_PORT 如:-p ::80 将容器的80端口随机(端口)映射到宿主机任意IP -p :8000:6379 将容器的6379端口映射到宿主机任意IP的8000端口 -p 192.168.5.1::3306 将容器的3306端口随机(端口)映射到宿主机的192.168.5.1IP上
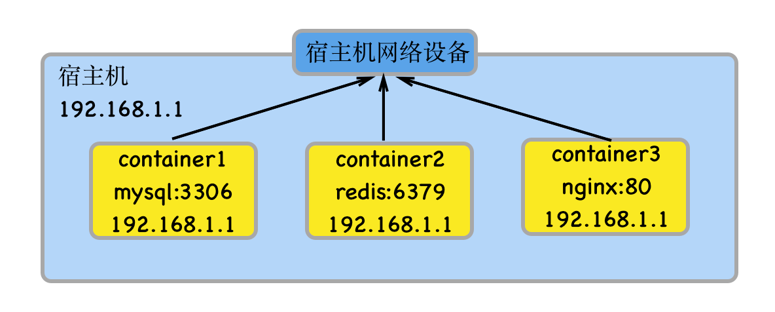
- 容器完全共享宿主机的网络。网络没有隔离。宿主机的网络就是容器的网络。
- 容器、主机上的应用所使用的端口不能重复。例如:如果宿主机已经占用了8090端口,那么任何一个host模式的容器都不可以使用8090端口了;反之同理。
- 外部可以直接访问容器,不需要端口映射。
- 容器的IP就是宿主机的IP
•Container网络模式,其实就是容器共享其他容器的网络。
•相当于该容器,,在网络层面上,将其他容器作为“主机”。它们之间的网络没有隔离。
•这些容器之间的特性同host模式。
使用方法:
Docker run/create --network container:CONTAINER …
特点:
•容器上没有网络,也无任何网络设备。
•如果需要使用网络,需要用户自行安装与配置。
应用场景: 该模式适合需要高度定制网络的用户使用。
•Overlay 网络,也称为覆盖网络。
•Overlay 网络的实现方式和方案有多种。Docker自身集成了一种,基于VXLAN隧道技术实现。
•Overlay 网络主要用于实现跨主机容器之间的通信。
应用场景:需要管理成百上千个跨主机的容器集群的网络时。
IP隧道网络原理
•macvlan网络模式,最主要的特征就是他们的通信会直接基于mac地址进行转发。
•这时宿主机其实充当一个二层交换机。Docker会维护着一个MAC地址表,当宿主机网络收到一个数据包后,直接根据mac地址找到对应的容器,再把数据交给对应的容器。
•容器之间可以直接通过IP互通,通过宿主机上内建的虚拟网络设备(创建macvlan网络时自动创建),但与主机无法直接利用IP互通。
应用场景:由于每个外来的数据包的目的mac地址就是容器的mac地址,这时每个容器对于外面网络来说就相当于一个真实的物理网络设备。因此当需要让容器来的网络看起来是一个真实的物理机时,使用macvlan模式
挂载, 联合文件系统
有三种方式来进行数据存储管理: 共享数据, 数据容器,
Bind mounts,
-
宿主机无法直接访问容器中的文件
-
容器中的文件没有持久化,导致容器删除后,文件数据也随之消失
-
容器之间也无法直接访问互相的文件
解决方案
为解决这些问题,docker加入了数据卷(volumes)机制,能很好解决上面问题,以实现:
-
容器与主机之间、容器与容器之间共享文件
-
容器中数据的持久化
-
将容器中的数据备份、迁移、恢复等
-
数据卷存在于宿主机的文件系统中,独立于容器,和容器的生命周期是分离的。
-
数据卷可以目录也可以是文件,容器可以利用数据卷与宿主机进行数据共享,实现了容器间的数据共享和交换。
-
容器启动初始化时,如果容器使用的镜像包含了数据,这些数据会拷贝到数据卷中。
-
容器对数据卷的修改是实时进行的。
-
数据卷的变化不会影响镜像的更新。数据卷是独立于联合文件系统,镜像是基于联合文件系统。镜像与数据卷之间不会有相互影响。
Docker的数据卷更多会是使用volumes方式来进行使用。使用时需注意:
-
如果挂载一个空的数据卷到容器中的一个非空目录中,那么这个目录下的文件会被复制到数据卷中。
-
如果挂载一个非空的数据卷到容器中的一个目录中,那么容器中的目录中会显示数据卷中的数据。如果原来容器中的目录中有数据,那么这些原始数据会被隐藏掉。
这两个规则都非常重要,灵活利用第一个规则可以帮助我们初始化数据卷中的内容。掌握第二个规则可以保证挂载数据卷后的数据总是你期望的结果。
一般推荐volumes
- bind mounts:将宿主机上的一个文件或目录被挂载到容器上。
- volumes:由Docker创建和管理。使用docker volume命令管理
- tmpfs mounts:tmpfs 是一种基于内存的临时文件系统。tmpfs mounts 数据不会存储在磁盘上。
利用docker run/create的参数为容器挂载数据卷
方式一: -v, --volume参数
-v 宿主机文件或文件夹路径**:**容器中的文件或者文件夹路径
方式二:--mount参数
--mount type=bind, src**=宿主机文件或文件夹路径,** dst**=**容器中的文件或者文件夹路径
注意:指定的文件和路径必须提前创建或存在
docker run -v /data /test/webserver•利用docker run/create为容器挂载数据卷
•用法:
方式一: -v, --volume参数
**-v VOLUME-NAME:**容器中的文件或者文件夹路径
方式二:--mount 参数
--mount type=volume, src**=VOLUME-NAME,** dst**=**容器中的文件或者文件夹路径
•volume对象管理:
# 使用方法
docker volume 命令管理volume数据卷对象
docker volume create 创建数据卷对象
docker volume inspect 查看数据卷详细信息
docker volume ls 查看已创建的数据卷对象
docker volume prune 删除未被使用的数据卷对象
docker volume rm 删除一个或多个数据卷对象•利用docker run/create 的--volumes-from参数指定数据卷容器
•用法:
docker run/create --volumes-from CONTAINER
作用: 基于已有镜像创建镜像, 一般容器只作为环境使用, 不推荐在运行容器时安装软件, 因为在容器停止后所有数据会丢失,
语法说明: 非常类似于 shell 命令, 基本思路完全一致
使用dockerfile创建开发环境思路:
开发环境应该是构建好的, 而不是运行容器时构建!
# 安装时 不安装recommend
apt-get install -y --no-install-recommends
# 移除apt 安装缓存
rm -rf /var/lib/apt/lists/*
# 禁用package更新
`apt-mark hold ${NV_CUDNN_PACKAGE_NAME}`
# 安装pip 禁用缓存
pip install --no-cache-dir -r requirements.txt
- 基本思路: 编写好
Dockerfile文件 >> 通过docker build创建镜像 >> 创建容器 >> 连接容器/镜像
Docker指南: Dockerfile是一个描述如何创建Docker镜像所需步骤的文本文件
Dockerfile其实就是根据特定的语法格式撰写出来的一个普通的文本文件
利用docker build命令依次执行在Dockerfile中定义的一系列命令,最终生成一个新的镜像(定制镜像)
GitHub search path:Dockerfile path:docker-compose
# 最常见的是将代码复制到 app或code目录
# 而Go这样的二进制文件则一般直接放在PATH相关的目录中, 或者 创建用户 放到 用户文件夹中
WORKDIR /app /code /src /project-name /app-name
# 安装更新和必要package
RUN <<EOF
apt-get update
apt-get install -y --no-install-recommends git
EOF
# 创建用户和组
RUN <<EOF
useradd -s /bin/bash -m vscode
groupadd docker
usermod -aG docker vscode
EOF# 将其他阶段构建的文件复制到新的stage中
COPY --from=builder /app/myapp .USAGE
# 环境变量
ADD
ARG # 定义普通变量
CMD # 执行命令(脚本), 通常启动服务
COPY # 复制文件到container
ENV # 设置环境变量
EXPOSE # 暴露端口
FROM <image>[:<tag>] [as <name>] # 初始化镜像
LABEL
RUN
STOPSIGNAL
USER
VOLUME
WORKDIR # 设置工作目录, 如果存在则创建
ONBUILDhe docker build command builds an image from
a Dockerfile and a context. The build’s context is the set of files at a specified location PATH or URL.
The PATH is a directory on your local filesystem. The URL is a Git repository location.
A context is processed recursively. So, a PATH includes any subdirectories and the URL includes the repository and
its submodules. This example shows a build command that uses the current directory as context:
$ docker build .
Sending build context to Docker daemon 6.51 MB
...
The build is run by the Docker daemon, not by the CLI. The first thing a build process does is send the entire context ( recursively) to the daemon. In most cases, it’s best to start with an empty directory as context and keep your Dockerfile in that directory. Add only the files needed for building the Dockerfile.
Warning: Do not use your root directory,
/, as thePATHas it causes the build to transfer the entire contents of your hard drive to the Docker daemon.
To use a file in the build context, the Dockerfile refers to the file specified in an instruction, for example,
a COPY instruction. To increase the build’s performance, exclude files and directories by adding a .dockerignore
file to the context directory. For information about how
to create a .dockerignore file see the
documentation on this page.
Traditionally, the Dockerfile is called Dockerfile and located in the root of the context. You use the -f flag
with docker build to point to a Dockerfile anywhere in your file system.
$ docker build -f /path/to/a/dockerfile .
You can specify a repository and tag at which to save the new image if the build succeeds:
$ docker build -t shykes/myapp .
To tag the image into multiple repositories after the build, add multiple -t parameters when you run the build
command:
$ docker build -t shykes/myapp:1.0.2 -t shykes/myapp:latest .
Before the Docker daemon runs the instructions in the Dockerfile, it performs a preliminary validation of
the Dockerfile and returns an error if the syntax is incorrect:
$ docker build -t test/myapp .
Sending build context to Docker daemon 2.048 kB
Error response from daemon: Unknown instruction: RUNCMD
The Docker daemon runs the instructions in the Dockerfile one-by-one, committing the result of each instruction to a
new image if necessary, before finally outputting the ID of your new image. The Docker daemon will automatically clean
up the context you sent.
Note that each instruction is run independently, and causes a new image to be created - so RUN cd /tmp will not have
any effect on the next instructions.
Whenever possible, Docker will re-use the intermediate images (cache), to accelerate the docker build process
significantly. This is indicated by the Using cache message in the console output. (For more information, see
the Build cache section in
the Dockerfile best practices guide):
$ docker build -t svendowideit/ambassador .
Sending build context to Docker daemon 15.36 kB
Step 1/4 : FROM alpine:3.2
---> 31f630c65071
Step 2/4 : MAINTAINER SvenDowideit@home.org.au
---> Using cache
---> 2a1c91448f5f
Step 3/4 : RUN apk update && apk add socat && rm -r /var/cache/
---> Using cache
---> 21ed6e7fbb73
Step 4/4 : CMD env | grep _TCP= | (sed 's/.*_PORT_\([0-9]*\)_TCP=tcp:\/\/\(.*\):\(.*\)/socat -t 100000000 TCP4-LISTEN:\1,fork,reuseaddr TCP4:\2:\3 \&/' && echo wait) | sh
---> Using cache
---> 7ea8aef582cc
Successfully built 7ea8aef582ccBuild cache is only used from images that have a local parent chain. This means that these images were created by
previous builds or the whole chain of images was loaded with docker load. If you wish to use build cache of a specific
image you can specify it with --cache-from option. Images specified with --cache-from do not need to have a parent
chain and may be pulled from other registries.
When you’re done with your build, you’re ready to look into Pushing a repository to its registry.
# FROM <image>[:<tag> | @<digest>] [as <name>]
#
ARG VERSION=latest
FROM ubuntu:$VERSION
# ARG 显然的, 参数应该在 FROM 之前
基础镜像可能并未安装某些命令,
使用 \ 和 ; 来组织命令, 下面两种写法相同
RUN <command> # shell form 推荐
RUN ["executable", "param1", "param2"] # exec form
# 用法示例
RUN /bin/bash -c ' source $HOME/.bashrc; \
echo $HOME'
RUN /bin/bash -c 'source $HOME/.bashrc; echo $HOME'
RUN ["/bin/bash", "-c", "echo hello"]
# 多行命令
RUN <<EOF
useradd -s /bin/bash -m vscode
groupadd docker
usermod -aG docker vscode
EOF
# 方式二 次选 -S --system
RUN <<EOF
addgroup -S docker
adduser -S --shell /bin/bash --ingroup docker vscode
EOF作用: CMD的主要作用是为 正在执行的容器提供默认命令. The main purpose of a CMD is to provide defaults for an
executing container.
重要提示:一个dockerfile只能有一条CMD命令, 当有多条命令时, 仅最后一条命令将会生效.
CMD ["executable", "param1", "param2"] # exec form 推荐
CMD ["param1", "param2"] # as default parameters toENTRYPOINT
CMD command param1 param2 # shell form为镜像添加元数据, 一个LABEL 其实是一个键值对. 使用引号来包含空格, 使用反斜杠进行换行.
The LABEL instruction adds metadata to an image. A LABEL is a key-value pair. To include spaces within a LABEL
value, use quotes and backslashes as you would in command-line parsing.
一个镜像可以包含多个 LABEL , 也可以在一行指定多个标签.
LABEL <key>=<value> <key>=<value> <key>=<value>
# 用法示例
LABEL "com.example.vendor"="ACME Incorporated"
LABEL com.example.label-with-value="foo"
LABEL version="1.0"
LABEL description="This text illustrates \
that label-values can span multiple lines."expose 暴露, 端口暴露
EXPOSE 指令告诉 Docker 容器在运行时监听指定端口.
The EXPOSE instruction informs Docker that the container listens on the specified network ports at runtime. You can
specify whether the port listens on TCP or UDP, and the default is TCP if the protocol is not specified.
EXPOSE <port> [<port>/<protocol>...]
# 用法示例
EXPOSE 80/tcp
EXPOSE 80/udpIn this case, if you use -P with docker run, the port will be exposed once for TCP and once for UDP. Remember
that -P uses an ephemeral high-ordered host port on the host, so the port will not be the same for TCP and UDP.
Regardless of the EXPOSE settings, you can override them at runtime by using the -p flag. For example
docker run -p 80:80/tcp -p 80:80/udp ...To set up port redirection on the host system,
see using the -P flag. The docker network
command supports creating networks for communication among containers without the need to expose or publish specific
ports, because the containers connected to the network can communicate with each other over any port. For detailed
information, see the overview of this feature).
ENV 指令为环境变量赋值(当前文件的环境变量). 这个值段将会对应后续的所有指令在构建阶段有效
The ENV instruction sets the environment variable to the value. This value will be in the environment for all
subsequent instructions in the build stage and can
be replaced inline in many as well.
第一种形式下, 第一个空格后面的所有字符串将作为value
The ENV instruction has two forms. The first form, ENV , will set a single variable to a value. The entire string
after the first space will be treated as the <value> - including whitespace characters. The value will be interpreted
for other environment variables, so quote characters will be removed if they are not escaped.
第二种形式下:支持两种字符串形式: "" 和 \space
The second form, ENV <key>=<value> ..., allows for multiple variables to be set at one time. Notice that the second
form uses the equals sign (=) in the syntax, while the first form does not. Like command line parsing, quotes and
backslashes can be used to include spaces within values.
ENV <key> <value>
ENV <key>=<value> <key>=<value> ...
# 用法示例 `\ ` 表示空格
ENV myName="John Doe" myDog=Rex\ The\ Dog \
myCat=fluffy
ENV myName John Doe
ENV myDog Rex The Dog
ENV myCat fluffy
ADD指令从src新文件,目录和链接 复制并添加 到dest镜像的文件系统
The ADD instruction copies new files, directories or remote file URLs from src and adds them to the filesystem of
the image at the path dest.
Multiple `` resources may be specified but if they are files or directories, their paths are interpreted as relative to the source of the context of the build.
Each `` may contain wildcards and matching will be done using Go’s filepath.Match rules.
ADD [--chown=<user>:<group>] <src>...<dest>
ADD [--chown=<user>:<group>] ["<src>",... "<dest>"] # 这种情况适用于路径包含空格的情况
# 用法示例
ADD hom* /mydir/ # adds all files starting with "hom"
ADD hom?.txt /mydir/ # ? is replaced with any single character, e.g., "home.txt"
ADD test relativeDir/ # adds "test" to `WORKDIR`/relativeDir/
ADD test /absoluteDir/ # adds "test" to /absoluteDir/
ADD --chown=55:mygroup files* /somedir/
ADD --chown=bin files* /somedir/
ADD --chown=1 files* /somedir/
ADD --chown=10:11 files* /somedir/COPY
COPY指令从src : 新文件和目录 复制并添加 到dest : 镜像的文件系统
The COPY instruction copies new files or directories from src and adds them to the filesystem of the container at
the path dest.
Multiple src resources may be specified but the paths of files and directories will be interpreted as relative to the
source of the context of the build.
Each src may contain wildcards and matching will be done using
Go’s filepath.Match rules.
COPY [--chown=<user>:<group>] <src>... <dest>
COPY [--chown=<user>:<group>] ["<src>",... "<dest>"] (this form is required for paths containing whitespace)
# 用法示例
COPY hom* /mydir/ # adds all files starting with "hom"
COPY hom?.txt /mydir/ # ? is replaced with any single character, e.g., "home.txt"
COPY test relativeDir/ # adds "test" to `WORKDIR`/relativeDir/
COPY test /absoluteDir/ # adds "test" to /absoluteDir/
COPY --chown=55:mygroup files* /somedir/
COPY --chown=bin files* /somedir/
COPY --chown=1 files* /somedir/
COPY --chown=10:11 files* /somedir/ENTRYPOINT 指令指定容器在可执行状态下的启动命令
An ENTRYPOINT allows you to configure a container that will run as an executable.
For example, the following will start nginx with its default content, listening on port 80:
# 启动Nginx, 并且将监听端口绑定80端口
docker run -i -t --rm -p 80:80 nginx
ENTRYPOINT ["executable", "param1", "param2"] # (exec form, preferred)
ENTRYPOINT command param1 param2 # (shell form)
# 用法示例
FROM ubuntu
ENTRYPOINT ["top", "-b"]
CMD ["-c"]Both CMD and ENTRYPOINT instructions define what command gets executed when running a container. There are few rules
that describe their co-operation.
- Dockerfile should specify at least one of
CMDorENTRYPOINTcommands. ENTRYPOINTshould be defined when using the container as an executable.CMDshould be used as a way of defining default arguments for anENTRYPOINTcommand or for executing an ad-hoc command in a container.CMDwill be overridden when running the container with alternative arguments.
The table below shows what command is executed for different ENTRYPOINT / CMD combinations:
| No ENTRYPOINT | ENTRYPOINT exec_entry p1_entry | ENTRYPOINT [“exec_entry”, “p1_entry”] | |
|---|---|---|---|
| No CMD | error, not allowed | /bin/sh -c exec_entry p1_entry | exec_entry p1_entry |
| CMD [“exec_cmd”, “p1_cmd”] | exec_cmd p1_cmd | /bin/sh -c exec_entry p1_entry | exec_entry p1_entry exec_cmd p1_cmd |
| CMD [“p1_cmd”, “p2_cmd”] | p1_cmd p2_cmd | /bin/sh -c exec_entry p1_entry | exec_entry p1_entry p1_cmd p2_cmd |
| CMD exec_cmd p1_cmd | /bin/sh -c exec_cmd p1_cmd | /bin/sh -c exec_entry p1_entry | exec_entry p1_entry /bin/sh -c exec_cmd p1_cmd |
Note: If
CMDis defined from the base image, settingENTRYPOINTwill resetCMDto an empty value. In this scenario,CMDmust be defined in the current image to have a value.
The VOLUME instruction creates a mount point with the specified name and marks it as holding externally mounted
volumes from native host or other containers. The value can be a JSON array, VOLUME ["/var/log/"], or a plain string
with multiple arguments, such as VOLUME /var/log or VOLUME /var/log /var/db. For more information/examples and
mounting instructions via the Docker client, refer to Share Directories via
Volumes
documentation.
The docker run command initializes the newly created volume with any data that exists at the specified location within
the base image. For example, consider the following Dockerfile snippet:
VOLUME ["/data"]
# 用法示例
FROM ubuntu
RUN mkdir /myvol
RUN echo "hello world" > /myvol/greeting
VOLUME /myvolThis Dockerfile results in an image that causes docker run to create a new mount point at /myvol and copy
the greeting file into the newly created volume.
Keep the following things in mind about volumes in the Dockerfile.
- Volumes on Windows-based containers: When using Windows-based containers, the destination of a volume inside the
container must be one of:
- a non-existing or empty directory
- a drive other than
C:
- Changing the volume from within the Dockerfile: If any build steps change the data within the volume after it has been declared, those changes will be discarded.
- JSON formatting: The list is parsed as a JSON array. You must enclose words with double quotes (
") rather than single quotes ('). - The host directory is declared at container run-time: The host directory (the mountpoint) is, by its nature,
host-dependent. This is to preserve image portability, since a given host directory can’t be guaranteed to be
available on all hosts. For this reason, you can’t mount a host directory from within the Dockerfile. The
VOLUMEinstruction does not support specifying ahost-dirparameter. You must specify the mountpoint when you create or run the container.
Docker容器连接
docker run -it --link list [command]
#
FROM python:3.7
# 复制文件
COPY
# # Nginx
#
# VERSION 0.0.1
FROM ubuntu
LABEL Description="This image is used to start the foobar executable" Vendor="ACME Products" Version="1.0"
RUN apt-get update && apt-get install -y inotify-tools nginx apache2 openssh-server# Firefox over VNC
#
# VERSION 0.3
FROM ubuntu
# Install vnc, xvfb in order to create a 'fake' display and firefox
RUN apt-get update && apt-get install -y x11vnc xvfb firefox
RUN mkdir ~/.vnc
# Setup a password
RUN x11vnc -storepasswd 1234 ~/.vnc/passwd
# Autostart firefox (might not be the best way, but it does the trick)
RUN bash -c 'echo "firefox" >> /.bashrc'
EXPOSE 5900
CMD ["x11vnc", "-forever", "-usepw", "-create"]# Multiple images example
#
# VERSION 0.1
FROM ubuntu
RUN echo foo > bar
# Will output something like ===> 907ad6c2736f
FROM ubuntu
RUN echo moo > oink
# Will output something like ===> 695d7793cbe4
# You'll now have two images, 907ad6c2736f with /bar, and 695d7793cbe4 with
# /oink.# 将当前目录的所有文件服务复制到工作目录
COPY . .
# 将指定目录复制到目标目录
COPY dir ./dir/docker compose up
# 启动时并重构镜像
docker compose up --build
docker compose --env-file .env.production # 简单绑定
volumes:
- ./volumes/db/data:/var/lib/postgresql/data# mysql
# postgres
healthcheck:
test: [ "CMD", "pg_isready" ]
interval: 1s
timeout: 3s
retries: 30l
# redis
healthcheck:
test: [ "CMD", "redis-cli", "ping" ]
# 创建集群
docker swarm init --advertise-addr <MANAGER-IP>
docker swarm join- 孙健波
阅读数:333912015 年 3 月 12 日 09:23
Docker 这么火,喜欢技术的朋友可能也会想,如果要自己实现一个资源隔离的容器,应该从哪些方面下手呢?也许你第一反应可能就是 chroot 命令,这条命令给用户最直观的感觉就是使用后根目录 / 的挂载点切换了,即文件系统被隔离了。然后,为了在分布式的环境下进行通信和定位,容器必然需要一个独立的 IP、端口、路由等等,自然就想到了网络的隔离。同时,你的容器还需要一个独立的主机名以便在网络中标识自己。想到网络,顺其自然就想到通信,也就想到了进程间通信的隔离。可能你也想到了权限的问题,对用户和用户组的隔离就实现了用户权限的隔离。最后,运行在容器中的应用需要有自己的 PID, 自然也需要与宿主机中的 PID 进行隔离。
由此,我们基本上完成了一个容器所需要做的六项隔离,Linux 内核中就提供了这六种 namespace 隔离的系统调用,如下表所示。
| Namespace | 系统调用参数 | 隔离内容 |
|---|---|---|
| UTS | CLONE_NEWUTS | 主机名与域名 |
| IPC | CLONE_NEWIPC | 信号量、消息队列和共享内存 |
| PID | CLONE_NEWPID | 进程编号 |
| Network | CLONE_NEWNET | 网络设备、网络栈、端口等等 |
| Mount | CLONE_NEWNS | 挂载点(文件系统) |
| User | CLONE_NEWUSER | 用户和用户组 |
表 namespace 六项隔离
实际上,Linux 内核实现 namespace 的主要目的就是为了实现轻量级虚拟化(容器)服务。在同一个 namespace 下的进程可以感知彼此的变化,而对外界的进程一无所知。这样就可以让容器中的进程产生错觉,仿佛自己置身于一个独立的系统环境中,以此达到独立和隔离的目的。
需要说明的是,本文所讨论的 namespace 实现针对的均是 Linux 内核 3.8 及其以后的版本。接下来,我们将首先介绍使用 namespace 的 API,然后针对这六种 namespace 进行逐一讲解,并通过程序让你亲身感受一下这些隔离效果(参考自 http://lwn.net/Articles/531114/ )。
namespace 的 API 包括 clone()、setns() 以及 unshare(),还有 /proc 下的部分文件。为了确定隔离的到底是哪种 namespace,在使用这些 API 时,通常需要指定以下六个常数的一个或多个,通过|(位或)操作来实现。你可能已经在上面的表格中注意到,这六个参数分别是 CLONE_NEWIPC、CLONE_NEWNS、CLONE_NEWNET、CLONE_NEWPID、CLONE_NEWUSER 和 CLONE_NEWUTS。
使用 clone() 来创建一个独立 namespace 的进程是最常见做法,它的调用方式如下。
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg);
clone() 实际上是传统 UNIX 系统调用 fork() 的一种更通用的实现方式,它可以通过 flags 来控制使用多少功能。一共有二十多种 CLONE_* 的 flag(标志位)参数用来控制 clone 进程的方方面面(如是否与父进程共享虚拟内存等等),下面外面逐一讲解 clone 函数传入的参数。
- 参数 child_func 传入子进程运行的程序主函数。
- 参数 child_stack 传入子进程使用的栈空间
- 参数 flags 表示使用哪些 CLONE_* 标志位
- 参数 args 则可用于传入用户参数
在后续的内容中将会有使用 clone() 的实际程序可供大家参考。
从 3.8 版本的内核开始,用户就可以在 /proc/[pid]/ns 文件下看到指向不同 namespace 号的文件,效果如下所示,形如 [4026531839] 者即为 namespace 号。
$ ls -l /proc/$$/ns <<-- $$ 表示应用的 PID
total 0
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 net -> net:[4026531956]
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 pid -> pid:[4026531836]
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 user->user:[4026531837]
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 uts -> uts:[4026531838]
如果两个进程指向的 namespace 编号相同,就说明他们在同一个 namespace 下,否则则在不同 namespace 里面。/proc/[pid]/ns 的另外一个作用是,一旦文件被打开,只要打开的文件描述符(fd)存在,那么就算 PID 所属的所有进程都已经结束,创建的 namespace 就会一直存在。那如何打开文件描述符呢?把 /proc/[pid]/ns 目录挂载起来就可以达到这个效果,命令如下。
# touch ~/uts
# mount --bind /proc/27514/ns/uts ~/uts
如果你看到的内容与本文所描述的不符,那么说明你使用的内核在 3.8 版本以前。该目录下存在的只有 ipc、net 和 uts,并且以硬链接存在。
上文刚提到,在进程都结束的情况下,也可以通过挂载的形式把 namespace 保留下来,保留 namespace 的目的自然是为以后有进程加入做准备。通过 setns() 系统调用,你的进程从原先的 namespace 加入我们准备好的新 namespace,使用方法如下。
int setns(int fd, int nstype);
- 参数 fd 表示我们要加入的 namespace 的文件描述符。上文已经提到,它是一个指向 /proc/[pid]/ns 目录的文件描述符,可以通过直接打开该目录下的链接或者打开一个挂载了该目录下链接的文件得到。
- 参数 nstype 让调用者可以去检查 fd 指向的 namespace 类型是否符合我们实际的要求。如果填 0 表示不检查。
为了把我们创建的 namespace 利用起来,我们需要引入 execve() 系列函数,这个函数可以执行用户命令,最常用的就是调用 /bin/bash 并接受参数,运行起一个 shell,用法如下。
fd = open(argv[1], O_RDONLY); /* 获取 namespace 文件描述符 */
setns(fd, 0); /* 加入新的 namespace */
execvp(argv[2], &argv[2]); /* 执行程序 */
假设编译后的程序名称为 setns。
# ./setns ~/uts /bin/bash # ~/uts 是绑定的 /proc/27514/ns/uts
至此,你就可以在新的命名空间中执行 shell 命令了,在下文中会多次使用这种方式来演示隔离的效果。
最后要提的系统调用是 unshare(),它跟 clone() 很像,不同的是,unshare() 运行在原先的进程上,不需要启动一个新进程,使用方法如下。
int unshare(int flags);
调用 unshare() 的主要作用就是不启动一个新进程就可以起到隔离的效果,相当于跳出原先的 namespace 进行操作。这样,你就可以在原进程进行一些需要隔离的操作。Linux 中自带的 unshare 命令,就是通过 unshare() 系统调用实现的,有兴趣的读者可以在网上搜索一下这个命令的作用。
系统调用函数 fork() 并不属于 namespace 的 API,所以这部分内容属于延伸阅读,如果读者已经对 fork() 有足够的了解,那大可跳过。
当程序调用 fork()函数时,系统会创建新的进程,为其分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的进程中,只有少量数值与原来的进程值不同,相当于克隆了一个自己。那么程序的后续代码逻辑要如何区分自己是新进程还是父进程呢?
fork() 的神奇之处在于它仅仅被调用一次,却能够返回两次(父进程与子进程各返回一次),通过返回值的不同就可以进行区分父进程与子进程。它可能有三种不同的返回值:
- 在父进程中,fork 返回新创建子进程的进程 ID
- 在子进程中,fork 返回 0
- 如果出现错误,fork 返回一个负值
下面给出一段实例代码,命名为 fork_example.c。
#include <unistd.h>
#include <stdio.h>
int main (){
pid_t fpid; //fpid 表示 fork 函数返回的值
int count=0;
fpid=fork();
if (fpid < 0)printf("error in fork!");
else if (fpid == 0) {
printf("I am child. Process id is %d/n",getpid());
}
else {
printf("i am parent. Process id is %d/n",getpid());
}
return 0;
}
编译并执行,结果如下。
root@local:~# gcc -Wall fork_example.c && ./a.out
I am parent. Process id is 28365
I am child. Process id is 28366
使用 fork() 后,父进程有义务监控子进程的运行状态,并在子进程退出后自己才能正常退出,否则子进程就会成为“孤儿”进程。
下面我们将分别对六种 namespace 进行详细解析。
UTS namespace 提供了主机名和域名的隔离,这样每个容器就可以拥有了独立的主机名和域名,在网络上可以被视作一个独立的节点而非宿主机上的一个进程。
下面我们通过代码来感受一下 UTS 隔离的效果,首先需要一个程序的骨架,如下所示。打开编辑器创建 uts.c 文件,输入如下代码。
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char child_stack[STACK_SIZE];
char* const child_args[] = {
"/bin/bash",
NULL
};
int child_main(void* args) {
printf("在子进程中!\n");
execv(child_args[0], child_args);
return 1;
}
int main() {
printf("程序开始: \n");
int child_pid = clone(child_main, child_stack + STACK_SIZE, SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
printf("已退出\n");
return 0;
}
编译并运行上述代码,执行如下命令,效果如下。
root@local:~# gcc -Wall uts.c -o uts.o && ./uts.o
程序开始:
在子进程中!
root@local:~# exit
exit
已退出
root@local:~#
下面,我们将修改代码,加入 UTS 隔离。运行代码需要 root 权限,为了防止普通用户任意修改系统主机名导致 set-user-ID 相关的应用运行出错。
//[...]
int child_main(void* arg) {
printf("在子进程中!\n");
sethostname("Changed Namespace", 12);
execv(child_args[0], child_args);
return 1;
}
int main() {
//[...]
int child_pid = clone(child_main, child_stack+STACK_SIZE,
CLONE_NEWUTS | SIGCHLD, NULL);
//[...]
}
再次运行可以看到 hostname 已经变化。
root@local:~# gcc -Wall namespace.c -o main.o && ./main.o
程序开始:
在子进程中!
root@NewNamespace:~# exit
exit
已退出
root@local:~# <- 回到原来的 hostname
也许有读者试着不加 CLONE_NEWUTS 参数运行上述代码,发现主机名也变了,输入 exit 以后主机名也会变回来,似乎没什么区别。实际上不加 CLONE_NEWUTS 参数进行隔离而使用 sethostname 已经把宿主机的主机名改掉了。你看到 exit 退出后还原只是因为 bash 只在刚登录的时候读取一次 UTS,当你重新登陆或者使用 uname 命令进行查看时,就会发现产生了变化。
Docker 中,每个镜像基本都以自己所提供的服务命名了自己的 hostname 而没有对宿主机产生任何影响,用的就是这个原理。
容器中进程间通信采用的方法包括常见的信号量、消息队列和共享内存。然而与虚拟机不同的是,容器内部进程间通信对宿主机来说,实际上是具有相同 PID namespace 中的进程间通信,因此需要一个唯一的标识符来进行区别。申请 IPC 资源就申请了这样一个全局唯一的 32 位 ID,所以 IPC namespace 中实际上包含了系统 IPC 标识符以及实现 POSIX 消息队列的文件系统。在同一个 IPC namespace 下的进程彼此可见,而与其他的 IPC namespace 下的进程则互相不可见。
IPC namespace 在代码上的变化与 UTS namespace 相似,只是标识位有所变化,需要加上 CLONE_NEWIPC 参数。主要改动如下,其他部位不变,程序名称改为 ipc.c。(测试方法参考自: http://crosbymichael.com/creating-containers-part-1.html )
//[...]
int child_pid = clone(child_main, child_stack+STACK_SIZE,
CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);
//[...]
我们首先在 shell 中使用 ipcmk -Q 命令创建一个 message queue。
root@local:~# ipcmk -Q
Message queue id: 32769
通过 ipcs -q 可以查看到已经开启的 message queue,序号为 32769。
root@local:~# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
0x4cf5e29f 32769 root 644 0 0
然后我们可以编译运行加入了 IPC namespace 隔离的 ipc.c,在新建的子进程中调用的 shell 中执行 ipcs -q 查看 message queue。
root@local:~# gcc -Wall ipc.c -o ipc.o && ./ipc.o
程序开始:
在子进程中!
root@NewNamespace:~# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
root@NewNamespace:~# exit
exit
已退出
上面的结果显示中可以发现,已经找不到原先声明的 message queue,实现了 IPC 的隔离。
目前使用 IPC namespace 机制的系统不多,其中比较有名的有 PostgreSQL。Docker 本身通过 socket 或 tcp 进行通信。
PID namespace 隔离非常实用,它对进程 PID 重新标号,即两个不同 namespace 下的进程可以有同一个 PID。每个 PID namespace 都有自己的计数程序。内核为所有的 PID namespace 维护了一个树状结构,最顶层的是系统初始时创建的,我们称之为 root namespace。他创建的新 PID namespace 就称之为 child namespace(树的子节点),而原先的 PID namespace 就是新创建的 PID namespace 的 parent namespace(树的父节点)。通过这种方式,不同的 PID namespaces 会形成一个等级体系。所属的父节点可以看到子节点中的进程,并可以通过信号等方式对子节点中的进程产生影响。反过来,子节点不能看到父节点 PID namespace 中的任何内容。由此产生如下结论(部分内容引自: http://blog.dotcloud.com/under-the-hood-linux-kernels-on-dotcloud-part )。
- 每个 PID namespace 中的第一个进程“PID 1“,都会像传统 Linux 中的 init 进程一样拥有特权,起特殊作用。
- 一个 namespace 中的进程,不可能通过 kill 或 ptrace 影响父节点或者兄弟节点中的进程,因为其他节点的 PID 在这个 namespace 中没有任何意义。
- 如果你在新的 PID namespace 中重新挂载 /proc 文件系统,会发现其下只显示同属一个 PID namespace 中的其他进程。
- 在 root namespace 中可以看到所有的进程,并且递归包含所有子节点中的进程。
到这里,可能你已经联想到一种在外部监控 Docker 中运行程序的方法了,就是监控 Docker Daemon 所在的 PID namespace 下的所有进程即其子进程,再进行删选即可。
下面我们通过运行代码来感受一下 PID namespace 的隔离效果。修改上文的代码,加入 PID namespace 的标识位,并把程序命名为 pid.c。
//[...]
int child_pid = clone(child_main, child_stack+STACK_SIZE,
CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS
| SIGCHLD, NULL);
//[...]
编译运行可以看到如下结果。
root@local:~# gcc -Wall pid.c -o pid.o && ./pid.o
程序开始:
在子进程中!
root@NewNamespace:~# echo $$
1 <<-- 注意此处看到 shell 的 PID 变成了 1
root@NewNamespace:~# exit
exit
已退出
打印 $$ 可以看到 shell 的 PID,退出后如果再次执行可以看到效果如下。
root@local:~# echo $$
17542
已经回到了正常状态。可能有的读者在子进程的 shell 中执行了 ps aux/top 之类的命令,发现还是可以看到所有父进程的 PID,那是因为我们还没有对文件系统进行隔离,ps/top 之类的命令调用的是真实系统下的 /proc 文件内容,看到的自然是所有的进程。
此外,与其他的 namespace 不同的是,为了实现一个稳定安全的容器,PID namespace 还需要进行一些额外的工作才能确保其中的进程运行顺利。
当我们新建一个 PID namespace 时,默认启动的进程 PID 为 1。我们知道,在传统的 UNIX 系统中,PID 为 1 的进程是 init,地位非常特殊。他作为所有进程的父进程,维护一张进程表,不断检查进程的状态,一旦有某个子进程因为程序错误成为了“孤儿”进程,init 就会负责回收资源并结束这个子进程。所以在你要实现的容器中,启动的第一个进程也需要实现类似 init 的功能,维护所有后续启动进程的运行状态。
看到这里,可能读者已经明白了内核设计的良苦用心。PID namespace 维护这样一个树状结构,非常有利于系统的资源监控与回收。Docker 启动时,第一个进程也是这样,实现了进程监控和资源回收,它就是 dockerinit。
PID namespace 中的 init 进程如此特殊,自然内核也为他赋予了特权——信号屏蔽。如果 init 中没有写处理某个信号的代码逻辑,那么与 init 在同一个 PID namespace 下的进程(即使有超级权限)发送给它的该信号都会被屏蔽。这个功能的主要作用是防止 init 进程被误杀。
那么其父节点 PID namespace 中的进程发送同样的信号会被忽略吗?父节点中的进程发送的信号,如果不是 SIGKILL(销毁进程)或 SIGSTOP(暂停进程)也会被忽略。但如果发送 SIGKILL 或 SIGSTOP,子节点的 init 会强制执行(无法通过代码捕捉进行特殊处理),也就是说父节点中的进程有权终止子节点中的进程。
一旦 init 进程被销毁,同一 PID namespace 中的其他进程也会随之接收到 SIGKILL 信号而被销毁。理论上,该 PID namespace 自然也就不复存在了。但是如果 /proc/[pid]/ns/pid 处于被挂载或者打开状态,namespace 就会被保留下来。然而,保留下来的 namespace 无法通过 setns() 或者 fork() 创建进程,所以实际上并没有什么作用。
我们常说,Docker 一旦启动就有进程在运行,不存在不包含任何进程的 Docker,也就是这个道理。
前文中已经提到,如果你在新的 PID namespace 中使用 ps 命令查看,看到的还是所有的进程,因为与 PID 直接相关的 /proc 文件系统(procfs)没有挂载到与原 /proc 不同的位置。所以如果你只想看到 PID namespace 本身应该看到的进程,需要重新挂载 /proc,命令如下。
root@NewNamespace:~# mount -t proc proc /proc
root@NewNamespace:~# ps a
PID TTY STAT TIME COMMAND
1 pts/1 S 0:00 /bin/bash
12 pts/1 R+ 0:00 ps a
可以看到实际的 PID namespace 就只有两个进程在运行。
注意:因为此时我们没有进行 mount namespace 的隔离,所以这一步操作实际上已经影响了 root namespace 的文件系统,当你退出新建的 PID namespace 以后再执行 ps a 就会发现出错,再次执行 mount -t proc proc /proc 可以修复错误。
在开篇我们就讲到了 unshare() 和 setns() 这两个 API,而这两个 API 在 PID namespace 中使用时,也有一些特别之处需要注意。
unshare() 允许用户在原有进程中建立 namespace 进行隔离。但是创建了 PID namespace 后,原先 unshare() 调用者进程并不进入新的 PID namespace,接下来创建的子进程才会进入新的 namespace,这个子进程也就随之成为新 namespace 中的 init 进程。
类似的,调用 setns() 创建新 PID namespace 时,调用者进程也不进入新的 PID namespace,而是随后创建的子进程进入。
为什么创建其他 namespace 时 unshare() 和 setns() 会直接进入新的 namespace 而唯独 PID namespace 不是如此呢?因为调用 getpid() 函数得到的 PID 是根据调用者所在的 PID namespace 而决定返回哪个 PID,进入新的 PID namespace 会导致 PID 产生变化。而对用户态的程序和库函数来说,他们都认为进程的 PID 是一个常量,PID 的变化会引起这些进程奔溃。
换句话说,一旦程序进程创建以后,那么它的 PID namespace 的关系就确定下来了,进程不会变更他们对应的 PID namespace。
Mount namespace 通过隔离文件系统挂载点对隔离文件系统提供支持,它是历史上第一个 Linux namespace,所以它的标识位比较特殊,就是 CLONE_NEWNS。隔离后,不同 mount namespace 中的文件结构发生变化也互不影响。你可以通过 /proc/[pid]/mounts 查看到所有挂载在当前 namespace 中的文件系统,还可以通过 /proc/[pid]/mountstats 看到 mount namespace 中文件设备的统计信息,包括挂载文件的名字、文件系统类型、挂载位置等等。
进程在创建 mount namespace 时,会把当前的文件结构复制给新的 namespace。新 namespace 中的所有 mount 操作都只影响自身的文件系统,而对外界不会产生任何影响。这样做非常严格地实现了隔离,但是某些情况可能并不适用。比如父节点 namespace 中的进程挂载了一张 CD-ROM,这时子节点 namespace 拷贝的目录结构就无法自动挂载上这张 CD-ROM,因为这种操作会影响到父节点的文件系统。
2006 年引入的挂载传播(mount propagation)解决了这个问题,挂载传播定义了挂载对象(mount object)之间的关系,系统用这些关系决定任何挂载对象中的挂载事件如何传播到其他挂载对象(参考自: http://www.ibm.com/developerworks/library/l-mount-namespaces/ )。所谓传播事件,是指由一个挂载对象的状态变化导致的其它挂载对象的挂载与解除挂载动作的事件。
- 共享关系(share relationship)。如果两个挂载对象具有共享关系,那么一个挂载对象中的挂载事件会传播到另一个挂载对象,反之亦然。
- 从属关系(slave relationship)。如果两个挂载对象形成从属关系,那么一个挂载对象中的挂载事件会传播到另一个挂载对象,但是反过来不行;在这种关系中,从属对象是事件的接收者。
一个挂载状态可能为如下的其中一种:
- 共享挂载(shared)
- 从属挂载(slave)
- 共享 / 从属挂载(shared and slave)
- 私有挂载(private)
- 不可绑定挂载(unbindable)
传播事件的挂载对象称为共享挂载(shared mount);接收传播事件的挂载对象称为从属挂载(slave mount)。既不传播也不接收传播事件的挂载对象称为私有挂载(private mount)。另一种特殊的挂载对象称为不可绑定的挂载(unbindable mount),它们与私有挂载相似,但是不允许执行绑定挂载,即创建 mount namespace 时这块文件对象不可被复制。
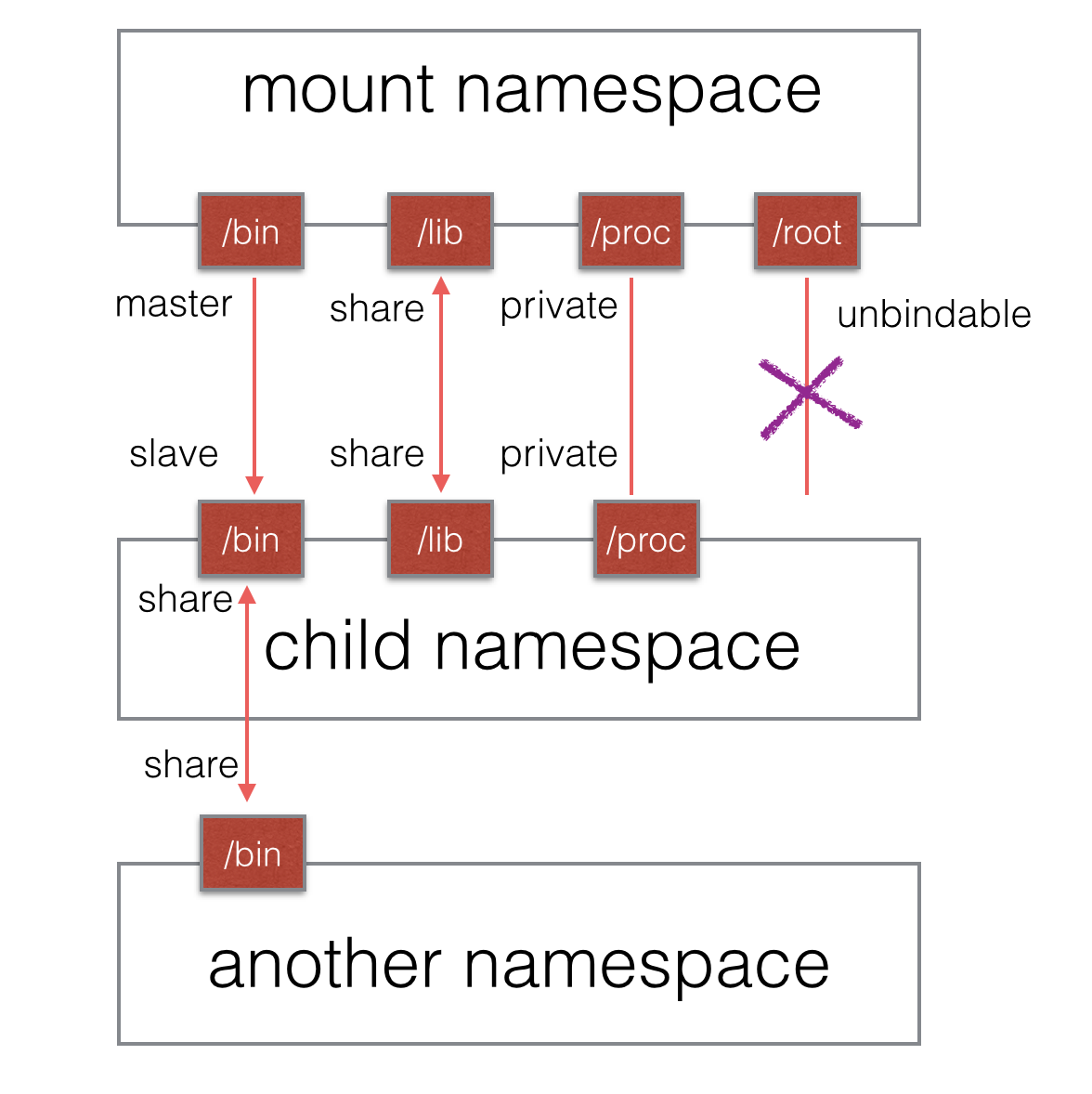
图 1 mount 各类挂载状态示意图
共享挂载的应用场景非常明显,就是为了文件数据的共享所必须存在的一种挂载方式;从属挂载更大的意义在于某些“只读”场景;私有挂载其实就是纯粹的隔离,作为一个独立的个体而存在;不可绑定挂载则有助于防止没有必要的文件拷贝,如某个用户数据目录,当根目录被递归式的复制时,用户目录无论从隐私还是实际用途考虑都需要有一个不可被复制的选项。
默认情况下,所有挂载都是私有的。设置为共享挂载的命令如下。
mount --make-shared <mount-object>
从共享挂载克隆的挂载对象也是共享的挂载;它们相互传播挂载事件。
设置为从属挂载的命令如下。
mount --make-slave <shared-mount-object>
从从属挂载克隆的挂载对象也是从属的挂载,它也从属于原来的从属挂载的主挂载对象。
将一个从属挂载对象设置为共享 / 从属挂载,可以执行如下命令或者将其移动到一个共享挂载对象下。
mount --make-shared <slave-mount-object>
如果你想把修改过的挂载对象重新标记为私有的,可以执行如下命令。
mount --make-private <mount-object>
通过执行以下命令,可以将挂载对象标记为不可绑定的。
mount --make-unbindable <mount-object>
这些设置都可以递归式地应用到所有子目录中,如果读者感兴趣可以搜索到相关的命令。
在代码中实现 mount namespace 隔离与其他 namespace 类似,加上 CLONE_NEWNS 标识位即可。让我们再次修改代码,并且另存为 mount.c 进行编译运行。
//[...]
int child_pid = clone(child_main, child_stack+STACK_SIZE,
CLONE_NEWNS | CLONE_NEWPID | CLONE_NEWIPC
| CLONE_NEWUTS | SIGCHLD, NULL);
//[...]
执行的效果就如同 PID namespace 一节中“挂载 proc 文件系统”的执行结果,区别就是退出 mount namespace 以后,root namespace 的文件系统不会被破坏,此处就不再演示了。
通过上节,我们了解了 PID namespace,当我们兴致勃勃地在新建的 namespace 中启动一个“Apache”进程时,却出现了“80 端口已被占用”的错误,原来主机上已经运行了一个“Apache”进程。怎么办?这就需要用到 network namespace 技术进行网络隔离啦。
Network namespace 主要提供了关于网络资源的隔离,包括网络设备、IPv4 和 IPv6 协议栈、IP 路由表、防火墙、/proc/net 目录、/sys/class/net 目录、端口(socket)等等。一个物理的网络设备最多存在在一个 network namespace 中,你可以通过创建 veth pair(虚拟网络设备对:有两端,类似管道,如果数据从一端传入另一端也能接收到,反之亦然)在不同的 network namespace 间创建通道,以此达到通信的目的。
一般情况下,物理网络设备都分配在最初的 root namespace(表示系统默认的 namespace,在 PID namespace 中已经提及)中。但是如果你有多块物理网卡,也可以把其中一块或多块分配给新创建的 network namespace。需要注意的是,当新创建的 network namespace 被释放时(所有内部的进程都终止并且 namespace 文件没有被挂载或打开),在这个 namespace 中的物理网卡会返回到 root namespace 而非创建该进程的父进程所在的 network namespace。
当我们说到 network namespace 时,其实我们指的未必是真正的网络隔离,而是把网络独立出来,给外部用户一种透明的感觉,仿佛跟另外一个网络实体在进行通信。为了达到这个目的,容器的经典做法就是创建一个 veth pair,一端放置在新的 namespace 中,通常命名为 eth0,一端放在原先的 namespace 中连接物理网络设备,再通过网桥把别的设备连接进来或者进行路由转发,以此网络实现通信的目的。
也许有读者会好奇,在建立起 veth pair 之前,新旧 namespace 该如何通信呢?答案是 pipe(管道)。我们以 Docker Daemon 在启动容器 dockerinit 的过程为例。Docker Daemon 在宿主机上负责创建这个 veth pair,通过 netlink 调用,把一端绑定到 docker0 网桥上,一端连进新建的 network namespace 进程中。建立的过程中,Docker Daemon 和 dockerinit 就通过 pipe 进行通信,当 Docker Daemon 完成 veth-pair 的创建之前,dockerinit 在管道的另一端循环等待,直到管道另一端传来 Docker Daemon 关于 veth 设备的信息,并关闭管道。dockerinit 才结束等待的过程,并把它的“eth0”启动起来。整个效果类似下图所示。
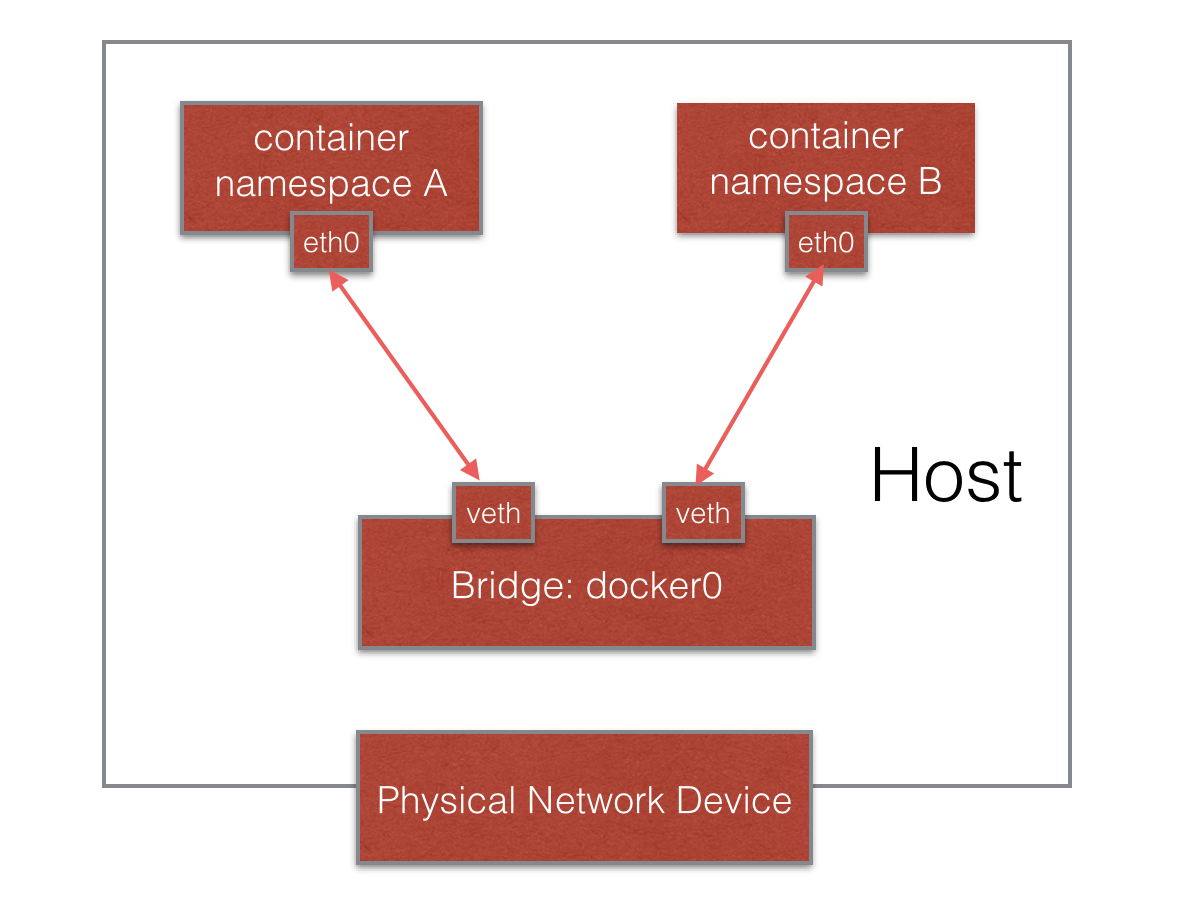
图 2 Docker 网络示意图
跟其他 namespace 类似,对 network namespace 的使用其实就是在创建的时候添加 CLONE_NEWNET 标识位。也可以通过命令行工具 ip 创建 network namespace。在代码中建立和测试 network namespace 较为复杂,所以下文主要通过 ip 命令直观的感受整个 network namespace 网络建立和配置的过程。
首先我们可以创建一个命名为 test_ns 的 network namespace。
# ip netns add test_ns
当 ip 命令工具创建一个 network namespace 时,会默认创建一个回环设备(loopback interface:lo),并在 /var/run/netns 目录下绑定一个挂载点,这就保证了就算 network namespace 中没有进程在运行也不会被释放,也给系统管理员对新创建的 network namespace 进行配置提供了充足的时间。
通过 ip netns exec 命令可以在新创建的 network namespace 下运行网络管理命令。
# ip netns exec test_ns ip link list
3: lo: <LOOPBACK> mtu 16436 qdisc noop state DOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
上面的命令为我们展示了新建的 namespace 下可见的网络链接,可以看到状态是 DOWN, 需要再通过命令去启动。可以看到,此时执行 ping 命令是无效的。
# ip netns exec test_ns ping 127.0.0.1
connect: Network is unreachable
启动命令如下,可以看到启动后再测试就可以 ping 通。
# ip netns exec test_ns ip link set dev lo up
# ip netns exec test_ns ping 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_req=1 ttl=64 time=0.050 ms
...
这样只是启动了本地的回环,要实现与外部 namespace 进行通信还需要再建一个网络设备对,命令如下。
# ip link add veth0 type veth peer name veth1
# ip link set veth1 netns test_ns
# ip netns exec test_ns ifconfig veth1 10.1.1.1/24 up
# ifconfig veth0 10.1.1.2/24 up
- 第一条命令创建了一个网络设备对,所有发送到 veth0 的包 veth1 也能接收到,反之亦然。
- 第二条命令则是把 veth1 这一端分配到 test_ns 这个 network namespace。
- 第三、第四条命令分别给 test_ns 内部和外部的网络设备配置 IP,veth1 的 IP 为 10.1.1.1,veth0 的 IP 为 10.1.1.2。
此时两边就可以互相连通了,效果如下。
# ping 10.1.1.1
PING 10.1.1.1 (10.1.1.1) 56(84) bytes of data.
64 bytes from 10.1.1.1: icmp_req=1 ttl=64 time=0.095 ms
...
# ip netns exec test_ns ping 10.1.1.2
PING 10.1.1.2 (10.1.1.2) 56(84) bytes of data.
64 bytes from 10.1.1.2: icmp_req=1 ttl=64 time=0.049 ms
...
读者有兴趣可以通过下面的命令查看,新的 test_ns 有着自己独立的路由和 iptables。
ip netns exec test_ns route
ip netns exec test_ns iptables -L
路由表中只有一条通向 10.1.1.2 的规则,此时如果要连接外网肯定是不可能的,你可以通过建立网桥或者 NAT 映射来决定这个问题。如果你对此非常感兴趣,可以阅读 Docker 网络相关文章进行更深入的讲解。
做完这些实验,你还可以通过下面的命令删除这个 network namespace。
# ip netns delete netns1
这条命令会移除之前的挂载,但是如果 namespace 本身还有进程运行,namespace 还会存在下去,直到进程运行结束。
通过 network namespace 我们可以了解到,实际上内核创建了 network namespace 以后,真的是得到了一个被隔离的网络。但是我们实际上需要的不是这种完全的隔离,而是一个对用户来说透明独立的网络实体,我们需要与这个实体通信。所以 Docker 的网络在起步阶段给人一种非常难用的感觉,因为一切都要自己去实现、去配置。你需要一个网桥或者 NAT 连接广域网,你需要配置路由规则与宿主机中其他容器进行必要的隔离,你甚至还需要配置防火墙以保证安全等等。所幸这一切已经有了较为成熟的方案,我们会在 Docker 网络部分进行详细的讲解。
User namespace 主要隔离了安全相关的标识符(identifiers)和属性(attributes),包括用户 ID、用户组 ID、root 目录、 key (指密钥)以及特殊权限 。说得通俗一点,一个普通用户的进程通过clone() 创建的新进程在新user namespace 中可以拥有不同的用户和用户组。这意味着一个进程在容器外属于一个没有特权的普通用户,但是他创建的容器进程却属于拥有所有权限的超级用户,这个技术为容器提供了极大的自由。
User namespace 是目前的六个 namespace 中最后一个支持的,并且直到 Linux 内核 3.8 版本的时候还未完全实现(还有部分文件系统不支持)。因为 user namespace 实际上并不算完全成熟,很多发行版担心安全问题,在编译内核的时候并未开启 USER_NS。实际上目前 Docker 也还不支持 user namespace,但是预留了相应接口,相信在不久后就会支持这一特性。所以在进行接下来的代码实验时,请确保你系统的 Linux 内核版本高于 3.8 并且内核编译时开启了 USER_NS(如果你不会选择,可以使用 Ubuntu14.04)。
Linux 中,特权用户的 user ID 就是 0,演示的最终我们将看到 user ID 非 0 的进程启动 user namespace 后 user ID 可以变为 0。使用 user namespace 的方法跟别的 namespace 相同,即调用 clone() 或 unshare() 时加入 CLONE_NEWUSER 标识位。老样子,修改代码并另存为 userns.c,为了看到用户权限(Capabilities) ,可能你还需要安装一下libcap-dev 包。
首先包含以下头文件以调用 Capabilities 包。
#include <sys/capability.h>
其次在子进程函数中加入 geteuid() 和 getegid() 得到 namespace 内部的 user ID,其次通过 cap_get_proc() 得到当前进程的用户拥有的权限,并通过 cap_to_text()输出。
int child_main(void* args) {
printf("在子进程中!\n");
cap_t caps;
printf("eUID = %ld; eGID = %ld; ",
(long) geteuid(), (long) getegid());
caps = cap_get_proc();
printf("capabilities: %s\n", cap_to_text(caps, NULL));
execv(child_args[0], child_args);
return 1;
}
在主函数的 clone() 调用中加入我们熟悉的标识符。
//[...]
int child_pid = clone(child_main, child_stack+STACK_SIZE,
CLONE_NEWUSER | SIGCHLD, NULL);
//[...]
至此,第一部分的代码修改就结束了。在编译之前我们先查看一下当前用户的 uid 和 guid,请注意此时我们是普通用户。
$ id -u
1000
$ id -g
1000
然后我们开始编译运行,并进行新建的 user namespace,你会发现 shell 提示符前的用户名已经变为 nobody。
sun@ubuntu$ gcc userns.c -Wall -lcap -o userns.o && ./userns.o
程序开始:
在子进程中!
eUID = 65534; eGID = 65534; capabilities: = cap_chown,cap_dac_override,[...]37+ep <<-- 此处省略部分输出,已拥有全部权限
nobody@ubuntu$
通过验证我们可以得到以下信息。
- user namespace 被创建后,第一个进程被赋予了该 namespace 中的全部权限,这样这个 init 进程就可以完成所有必要的初始化工作,而不会因权限不足而出现错误。
- 我们看到 namespace 内部看到的 UID 和 GID 已经与外部不同了,默认显示为 65534,表示尚未与外部 namespace 用户映射。我们需要对 user namespace 内部的这个初始 user 和其外部 namespace 某个用户建立映射,这样可以保证当涉及到一些对外部 namespace 的操作时,系统可以检验其权限(比如发送一个信号或操作某个文件)。同样用户组也要建立映射。
- 还有一点虽然不能从输出中看出来,但是值得注意。用户在新 namespace 中有全部权限,但是他在创建他的父 namespace 中不含任何权限。就算调用和创建他的进程有全部权限也是如此。所以哪怕是 root 用户调用了 clone() 在 user namespace 中创建出的新用户在外部也没有任何权限。
- 最后,user namespace 的创建其实是一个层层嵌套的树状结构。最上层的根节点就是 root namespace,新创建的每个 user namespace 都有一个父节点 user namespace 以及零个或多个子节点 user namespace,这一点与 PID namespace 非常相似。
接下来我们就要进行用户绑定操作,通过在 /proc/[pid]/uid_map 和 /proc/[pid]/gid_map 两个文件中写入对应的绑定信息可以实现这一点,格式如下。
ID-inside-ns ID-outside-ns length
写这两个文件需要注意以下几点。
- 这两个文件只允许由拥有该 user namespace 中 CAP_SETUID 权限的进程写入一次,不允许修改。
- 写入的进程必须是该 user namespace 的父 namespace 或者子 namespace。
- 第一个字段 ID-inside-ns 表示新建的 user namespace 中对应的 user/group ID,第二个字段 ID-outside-ns 表示 namespace 外部映射的 user/group ID。最后一个字段表示映射范围,通常填 1,表示只映射一个,如果填大于 1 的值,则按顺序建立一一映射。
明白了上述原理,我们再次修改代码,添加设置 uid 和 guid 的函数。
//[...]
void set_uid_map(pid_t pid, int inside_id, int outside_id, int length) {
char path[256];
sprintf(path, "/proc/%d/uid_map", getpid());
FILE* uid_map = fopen(path, "w");
fprintf(uid_map, "%d %d %d", inside_id, outside_id, length);
fclose(uid_map);
}
void set_gid_map(pid_t pid, int inside_id, int outside_id, int length) {
char path[256];
sprintf(path, "/proc/%d/gid_map", getpid());
FILE* gid_map = fopen(path, "w");
fprintf(gid_map, "%d %d %d", inside_id, outside_id, length);
fclose(gid_map);
}
int child_main(void* args) {
cap_t caps;
printf("在子进程中!\n");
set_uid_map(getpid(), 0, 1000, 1);
set_gid_map(getpid(), 0, 1000, 1);
printf("eUID = %ld; eGID = %ld; ",
(long) geteuid(), (long) getegid());
caps = cap_get_proc();
printf("capabilities: %s\n", cap_to_text(caps, NULL));
execv(child_args[0], child_args);
return 1;
}
//[...]
编译后即可看到 user 已经变成了 root。
$ gcc userns.c -Wall -lcap -o usernc.o && ./usernc.o
程序开始:
在子进程中!
eUID = 0; eGID = 0; capabilities: = [...],37+ep
root@ubuntu:~#
至此,你就已经完成了绑定的工作,可以看到演示全程都是在普通用户下执行的。最终实现了在 user namespace 中成为了 root 而对应到外面的是一个 uid 为 1000 的普通用户。
如果你要把 user namespace 与其他 namespace 混合使用,那么依旧需要 root 权限。解决方案可以是先以普通用户身份创建 user namespace,然后在新建的 namespace 中作为 root 再 clone() 进程加入其他类型的 namespace 隔离。
讲完了 user namespace,我们再来谈谈 Docker。虽然 Docker 目前尚未使用 user namespace,但是他用到了我们在 user namespace 中提及的 Capabilities 机制。从内核 2.2 版本开始,Linux 把原来和超级用户相关的高级权限划分成为不同的单元,称为 Capability。这样管理员就可以独立对特定的 Capability 进行使能或禁止。Docker 虽然没有使用 user namespace,但是他可以禁用容器中不需要的 Capability,一次在一定程度上加强容器安全性。
当然,说到安全,namespace 的六项隔离看似全面,实际上依旧没有完全隔离 Linux 的资源,比如 SELinux、 Cgroups 以及 /sys、/proc/sys、/dev/sd* 等目录下的资源。关于安全的更多讨论和讲解,我们会在后文中接着探讨。
本文从 namespace 使用的 API 开始,结合 Docker 逐步对六个 namespace 进行讲解。相信把讲解过程中所有的代码整合起来,你也能实现一个属于自己的“shell”容器了。虽然 namespace 技术使用起来非常简单,但是要真正把容器做到安全易用却并非易事。PID namespace 中,我们要实现一个完善的 init 进程来维护好所有进程;network namespace 中,我们还有复杂的路由表和 iptables 规则没有配置;user namespace 中还有很多权限上的问题需要考虑等等。其中有些方面 Docker 已经做的很好,有些方面也才刚刚开始。希望通过本文,能为大家更好的理解 Docker 背后运行的原理提供帮助。
孙健波,浙江大学SEL 实验室 硕士研究生,目前在云平台团队从事科研和开发工作。浙大团队对PaaS、Docker、大数据和主流开源云计算技术有深入的研究和二次开发经验,团队现将部分技术文章贡献出来,希望能对读者有所帮助。
- 孙健波
阅读数:400392015 年 4 月 20 日 08:10
上一篇中,我们了解了 Docker 背后使用的资源隔离技术 namespace,通过系统调用构建一个相对隔离的 shell 环境,也可以称之为一个简单的“容器”。本文我们则要开始讲解另一个强大的内核工具——cgroups。他不仅可以限制被 namespace 隔离起来的资源,还可以为资源设置权重、计算使用量、操控进程启停等等。在介绍完基本概念后,我们将详细讲解 Docker 中使用到的 cgroups 内容。希望通过本文,让读者对 Docker 有更深入的了解。
cgroups(Control Groups)最初叫 Process Container,由 Google 工程师(Paul Menage 和 Rohit Seth)于 2006 年提出,后来因为 Container 有多重含义容易引起误解,就在 2007 年更名为 Control Groups,并被整合进 Linux 内核。顾名思义就是把进程放到一个组里面统一加以控制。官方的定义如下{![ 引自:https://www.kernel.org/doc/Documentation/cgroups/cgroups.txt]}。
cgroups 是 Linux 内核提供的一种机制,这种机制可以根据特定的行为,把一系列系统任务及其子任务整合(或分隔)到按资源划分等级的不同组内,从而为系统资源管理提供一个统一的框架。
通俗的来说,cgroups 可以限制、记录、隔离进程组所使用的物理资源(包括:CPU、memory、IO 等),为容器实现虚拟化提供了基本保证,是构建 Docker 等一系列虚拟化管理工具的基石。
对开发者来说,cgroups 有如下四个有趣的特点:
- cgroups 的 API 以一个伪文件系统的方式实现,即用户可以通过文件操作实现 cgroups 的组织管理。
- cgroups 的组织管理操作单元可以细粒度到线程级别,用户态代码也可以针对系统分配的资源创建和销毁 cgroups,从而实现资源再分配和管理。
- 所有资源管理的功能都以“subsystem(子系统)”的方式实现,接口统一。
- 子进程创建之初与其父进程处于同一个 cgroups 的控制组。
本质上来说,cgroups 是内核附加在程序上的一系列钩子(hooks),通过程序运行时对资源的调度触发相应的钩子以达到资源追踪和限制的目的。
实现 cgroups 的主要目的是为不同用户层面的资源管理,提供一个统一化的接口。从单个进程的资源控制到操作系统层面的虚拟化。Cgroups 提供了以下四大功能{![参照自:http://en.wikipedia.org/wiki/Cgroups]}。
- 资源限制(Resource Limitation):cgroups 可以对进程组使用的资源总额进行限制。如设定应用运行时使用内存的上限,一旦超过这个配额就发出 OOM(Out of Memory)。
- 优先级分配(Prioritization):通过分配的 CPU 时间片数量及硬盘 IO 带宽大小,实际上就相当于控制了进程运行的优先级。
- 资源统计(Accounting): cgroups 可以统计系统的资源使用量,如 CPU 使用时长、内存用量等等,这个功能非常适用于计费。
- 进程控制(Control):cgroups 可以对进程组执行挂起、恢复等操作。
过去有一段时间,内核开发者甚至把 namespace 也作为一个 cgroups 的 subsystem 加入进来,也就是说 cgroups 曾经甚至还包含了资源隔离的能力。但是资源隔离会给 cgroups 带来许多问题,如 PID 在循环出现的时候 cgroup 却出现了命名冲突、cgroup 创建后进入新的 namespace 导致脱离了控制等等{![ 详见:https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=a77aea92010acf54ad785047234418d5d68772e2]},所以在 2011 年就被移除了。
- task(任务):cgroups 的术语中,task 就表示系统的一个进程。
- cgroup(控制组):cgroups 中的资源控制都以 cgroup 为单位实现。cgroup 表示按某种资源控制标准划分而成的任务组,包含一个或多个子系统。一个任务可以加入某个 cgroup,也可以从某个 cgroup 迁移到另外一个 cgroup。
- subsystem(子系统):cgroups 中的 subsystem 就是一个资源调度控制器(Resource Controller)。比如 CPU 子系统可以控制 CPU 时间分配,内存子系统可以限制 cgroup 内存使用量。
- hierarchy(层级树):hierarchy 由一系列 cgroup 以一个树状结构排列而成,每个 hierarchy 通过绑定对应的 subsystem 进行资源调度。hierarchy 中的 cgroup 节点可以包含零或多个子节点,子节点继承父节点的属性。整个系统可以有多个 hierarchy。
大家在 namespace 技术的讲解中已经了解到,传统的 Unix 进程管理,实际上是先启动init进程作为根节点,再由init
节点创建子进程作为子节点,而每个子节点由可以创建新的子节点,如此往复,形成一个树状结构。而 cgroups 也是类似的树状结构,子节点都从父节点继承属性。
它们最大的不同在于,系统中 cgroup 构成的 hierarchy 可以允许存在多个。如果进程模型是由init作为根节点构成的一棵树的话,那么
cgroups 的模型则是由多个 hierarchy 构成的森林。这样做的目的也很好理解,如果只有一个 hierarchy,那么所有的 task 都要受到绑定其上的
subsystem 的限制,会给那些不需要这些限制的 task 造成麻烦。
了解了 cgroups 的组织结构,我们再来了解 cgroup、task、subsystem 以及 hierarchy 四者间的相互关系及其基本规则{![ 参照自:https://access.redhat.com/documentation/en-US/RedHatEnterpriseLinux/6/html/Resource*Management*Guide/sec-RelationshipsBetweenSubsystemsHierarchiesControl*Groups*andTasks.html]}。
-
规则 1: 同一个 hierarchy 可以附加一个或多个 subsystem。如下图 1,cpu 和 memory 的 subsystem 附加到了一个 hierarchy。
图 1 同一个 hierarchy 可以附加一个或多个 subsystem
-
规则 2: 一个 subsystem 可以附加到多个 hierarchy,当且仅当这些 hierarchy 只有这唯一一个 subsystem。如下图 2,小圈中的数字表示 subsystem 附加的时间顺序,CPU subsystem 附加到 hierarchy A 的同时不能再附加到 hierarchy B,因为 hierarchy B 已经附加了 memory subsystem。如果 hierarchy B 与 hierarchy A 状态相同,没有附加过 memory subsystem,那么 CPU subsystem 同时附加到两个 hierarchy 是可以的。
图 2 一个已经附加在某个 hierarchy 上的 subsystem 不能附加到其他含有别的 subsystem 的 hierarchy 上
-
规则 3: 系统每次新建一个 hierarchy 时,该系统上的所有 task 默认构成了这个新建的 hierarchy 的初始化 cgroup,这个 cgroup 也称为 root cgroup。对于你创建的每个 hierarchy,task 只能存在于其中一个 cgroup 中,即一个 task 不能存在于同一个 hierarchy 的不同 cgroup 中,但是一个 task 可以存在在不同 hierarchy 中的多个 cgroup 中。如果操作时把一个 task 添加到同一个 hierarchy 中的另一个 cgroup 中,则会从第一个 cgroup 中移除。在下图 3 中可以看到,
httpd进程已经加入到 hierarchy A 中的/cg1而不能加入同一个 hierarchy 中的/cg2,但是可以加入 hierarchy B 中的/cg3。实际上不允许加入同一个 hierarchy 中的其他 cgroup 野生为了防止出现矛盾,如 CPU subsystem 为/cg1分配了 30%,而为/cg2分配了 50%,此时如果httpd在这两个 cgroup 中,就会出现矛盾。图 3 一个 task 不能属于同一个 hierarchy 的不同 cgroup
-
规则 4: 进程(task)在 fork 自身时创建的子任务(child task)默认与原 task 在同一个 cgroup 中,但是 child task 允许被移动到不同的 cgroup 中。即 fork 完成后,父子进程间是完全独立的。如下图 4 中,小圈中的数字表示 task 出现的时间顺序,当
httpd刚 fork 出另一个httpd时,在同一个 hierarchy 中的同一个 cgroup 中。但是随后如果 PID 为 4840 的httpd需要移动到其他 cgroup 也是可以的,因为父子任务间已经独立。总结起来就是:初始化时子任务与父任务在同一个 cgroup,但是这种关系随后可以改变。图 4 刚 fork 出的子进程在初始状态与其父进程处于同一个 cgroup
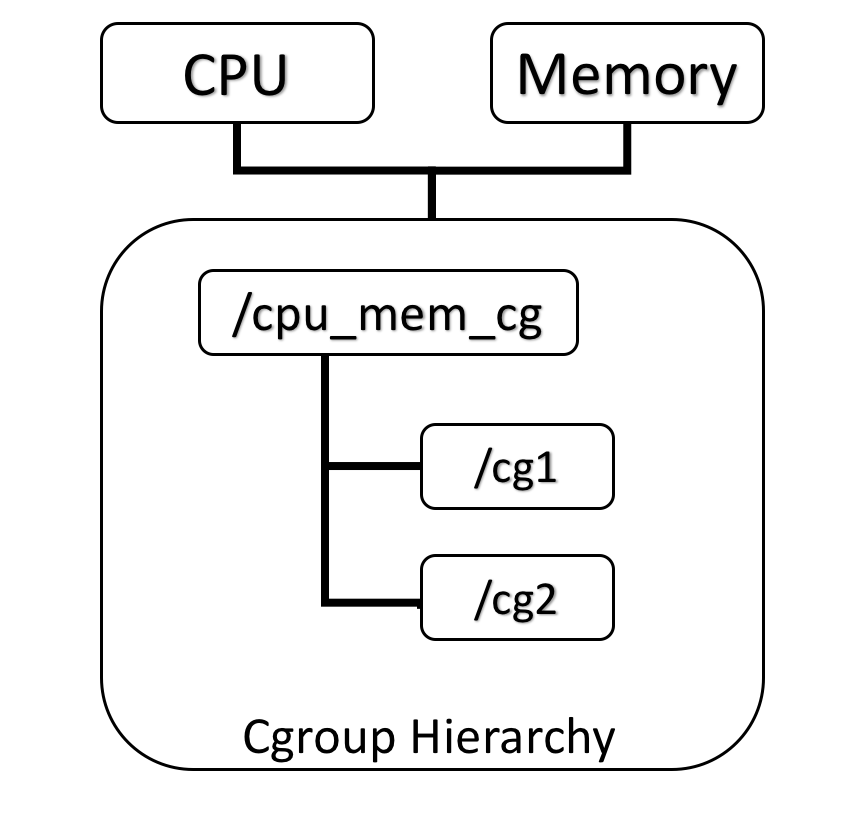
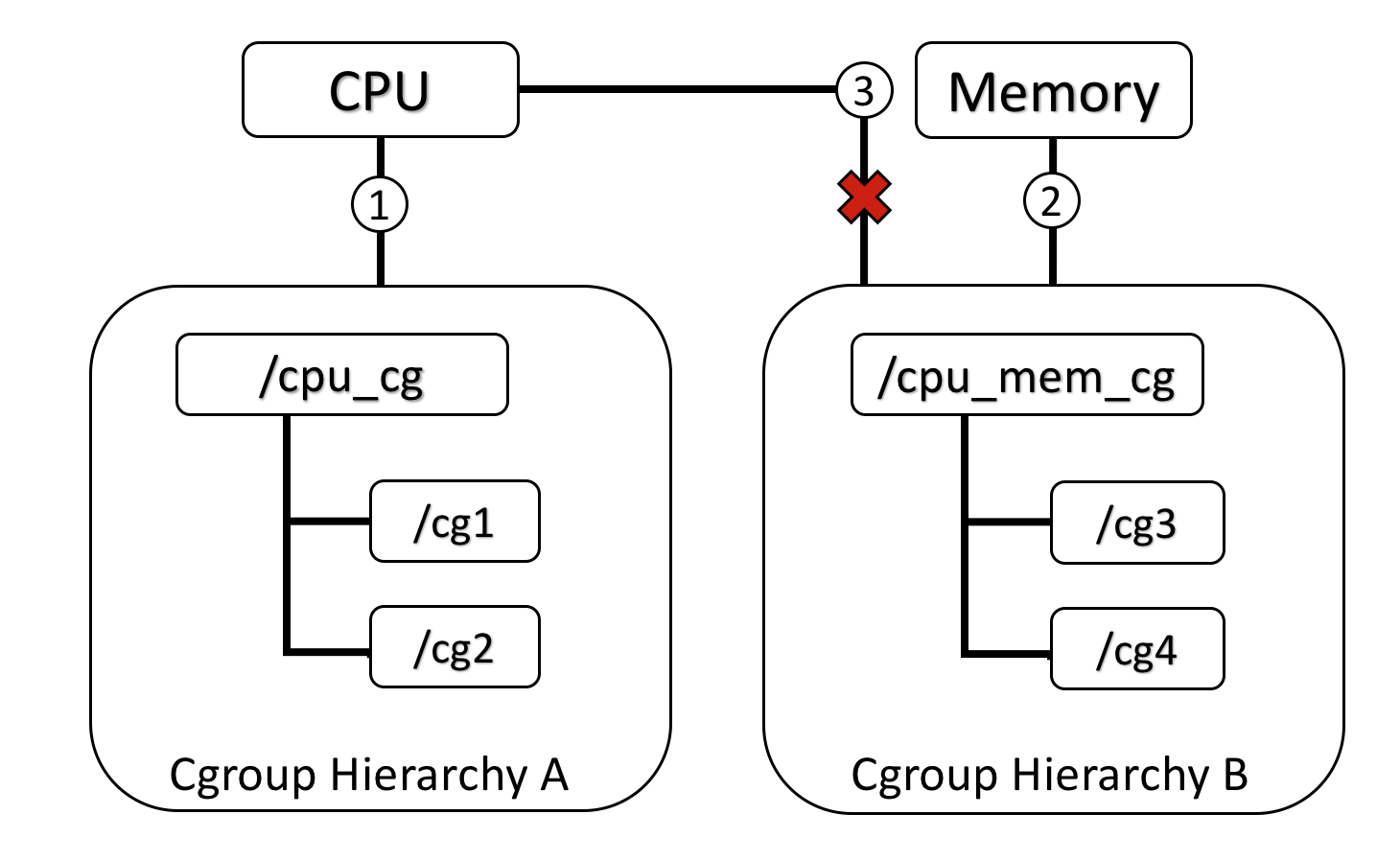
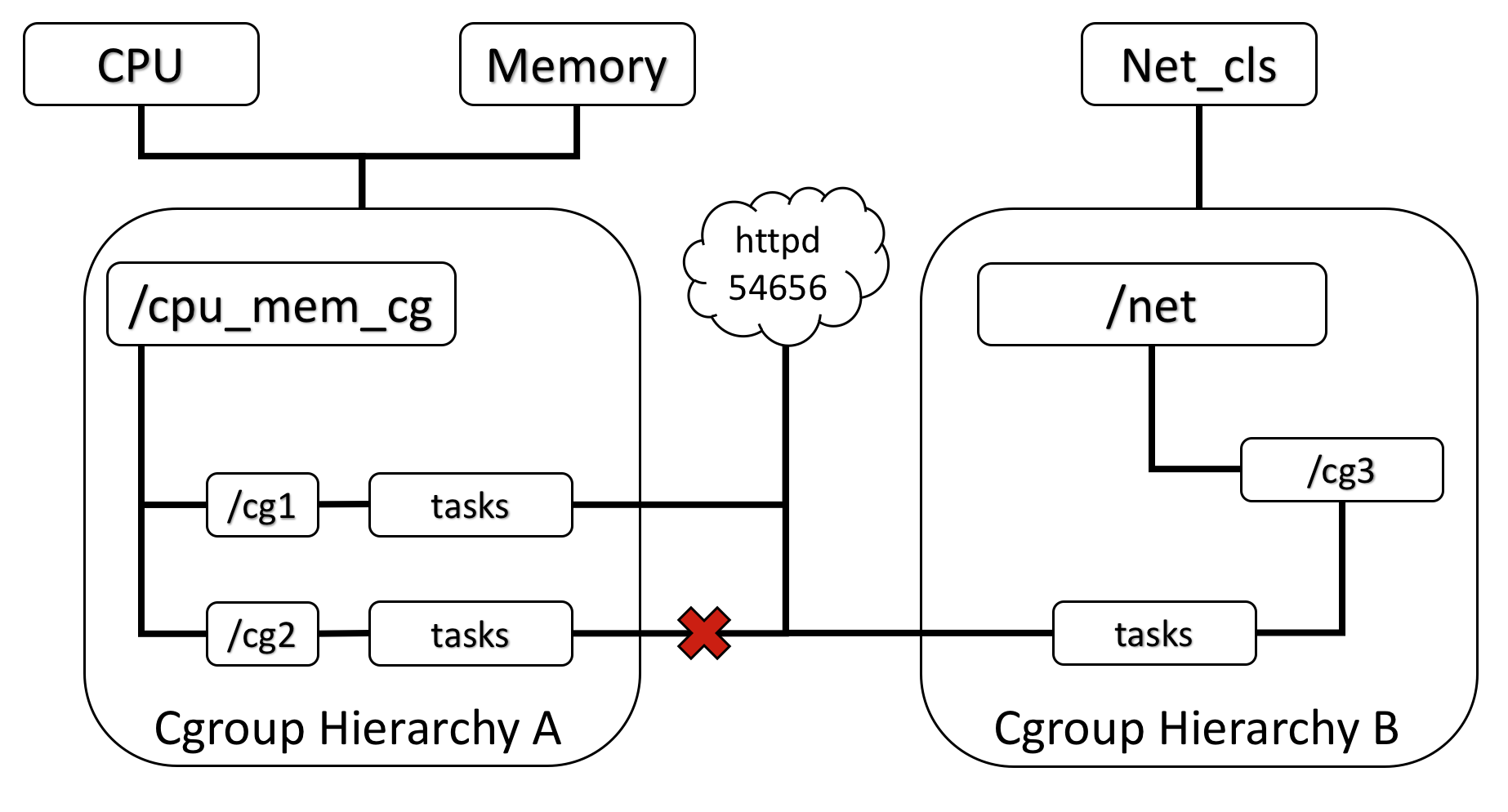
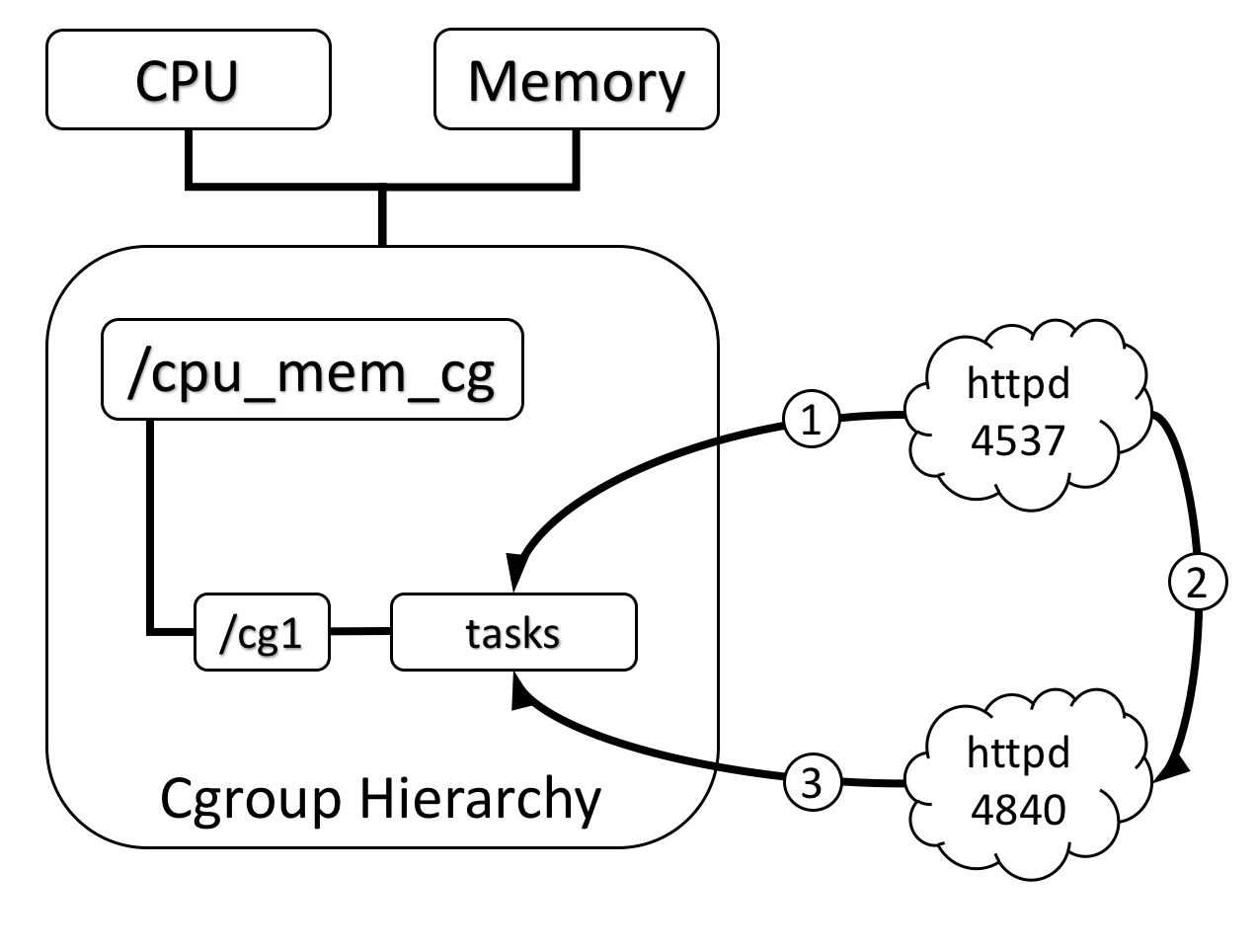
subsystem 实际上就是 cgroups 的资源控制系统,每种 subsystem 独立地控制一种资源,目前 Docker 使用如下八种
subsystem,还有一种net_cls subsystem 在内核中已经广泛实现,但是 Docker 尚未使用。他们的用途分别如下。
- blkio: 这个 subsystem 可以为块设备设定输入 / 输出限制,比如物理驱动设备(包括磁盘、固态硬盘、USB 等)。
- cpu: 这个 subsystem 使用调度程序控制 task 对 CPU 的使用。
- cpuacct: 这个 subsystem 自动生成 cgroup 中 task 对 CPU 资源使用情况的报告。
- cpuset: 这个 subsystem 可以为 cgroup 中的 task 分配独立的 CPU(此处针对多处理器系统)和内存。
- devices 这个 subsystem 可以开启或关闭 cgroup 中 task 对设备的访问。
- freezer 这个 subsystem 可以挂起或恢复 cgroup 中的 task。
- memory 这个 subsystem 可以设定 cgroup 中 task 对内存使用量的限定,并且自动生成这些 task 对内存资源使用情况的报告。
- perf*event* 这个 subsystem 使用后使得 cgroup 中的 task 可以进行统一的性能测试。{![perf: Linux CPU 性能探测器,详见 https://perf.wiki.kernel.org/index.php/MainPage]}
- *net_cls 这个 subsystem Docker 没有直接使用,它通过使用等级识别符 (classid) 标记网络数据包,从而允许 Linux 流量控制程序(TC:Traffic Controller)识别从具体 cgroup 中生成的数据包。
cgroups 的实现本质上是给系统进程挂上钩子(hooks),当 task 运行的过程中涉及到某个资源时就会触发钩子上所附带的 subsystem 进行检测,最终根据资源类别的不同使用对应的技术进行资源限制和优先级分配。那么这些钩子又是怎样附加到进程上的呢?下面我们将对照结构体的图表一步步分析,请放心,描述代码的内容并不多。
(点击放大图像)
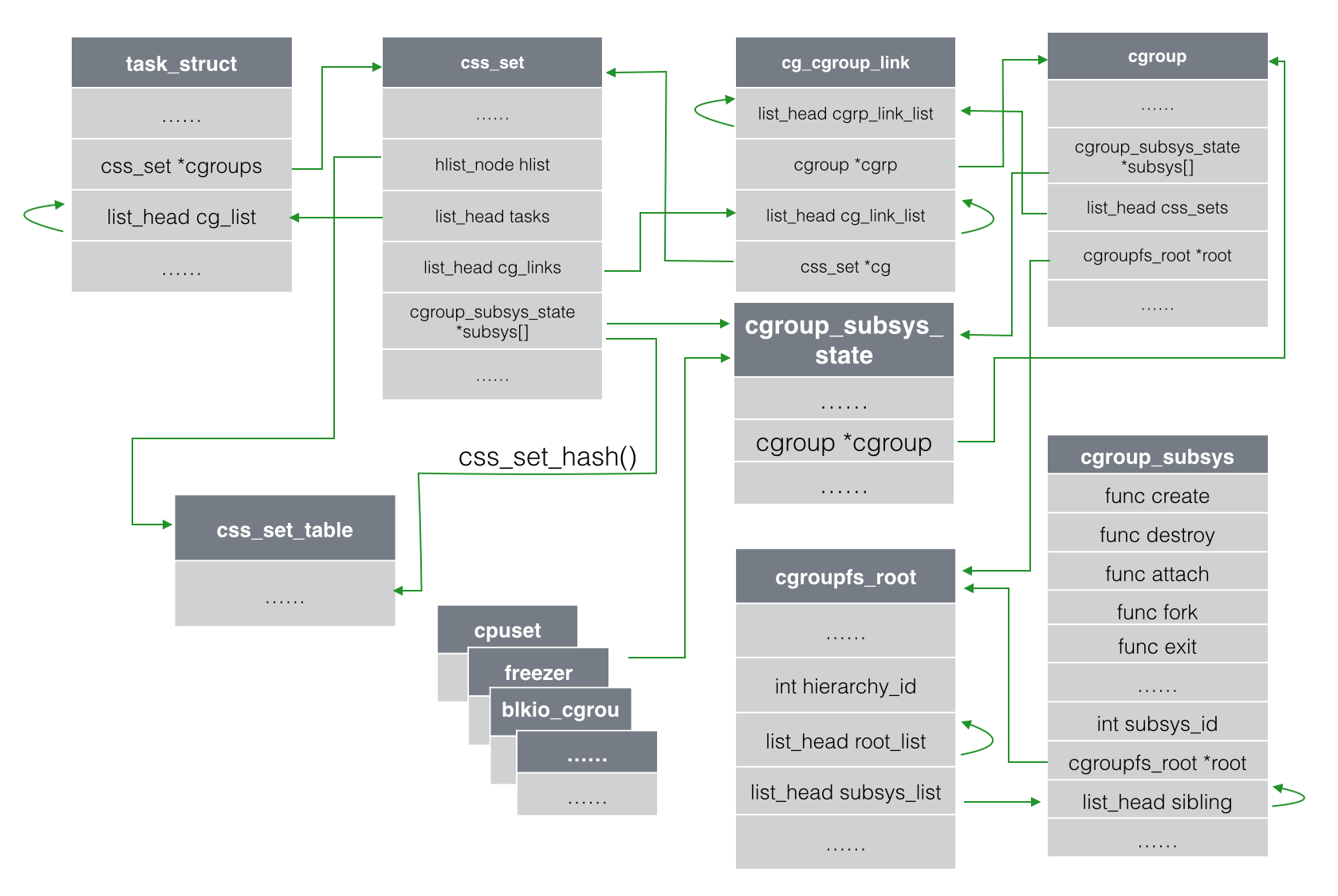
图 5 cgroups 相关结构体一览
Linux 中管理 task 进程的数据结构为task_struct(包含所有进程管理的信息),其中与 cgroup
相关的字段主要有两个,一个是css_set *cgroups,表示指向css_set(包含进程相关的 cgroups 信息)的指针,一个 task
只对应一个css_set结构,但是一个css_set可以被多个 task 使用。另一个字段是list_head cg_list
,是一个链表的头指针,这个链表包含了所有的链到同一个css_set的 task 进程(在图中使用的回环箭头,均表示可以通过该字段找到所有同类结构,获得信息)。
每个css_set结构中都包含了一个指向cgroup_subsys_state
(包含进程与一个特定子系统相关的信息)的指针数组。cgroup_subsys_state则指向了cgroup结构(包含一个 cgroup
的所有信息),通过这种方式间接的把一个进程和 cgroup 联系了起来,如下图 6。
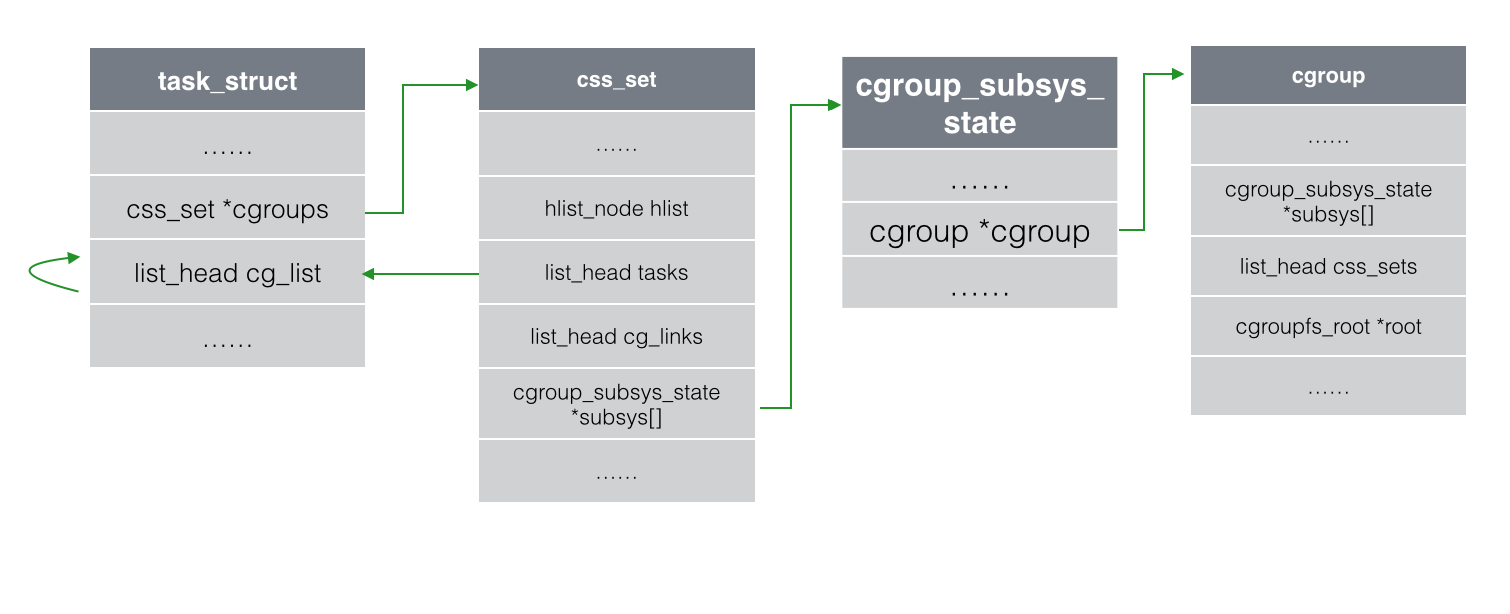
图 6 从 task 结构开始找到 cgroup 结构
另一方面,cgroup结构体中有一个list_head css_sets字段,它是一个头指针,指向由cg_cgroup_link(包含 cgroup 与 task
之间多对多关系的信息,后文还会再解释)形成的链表。由此获得的每一个cg_cgroup_link都包含了一个指向css_set *cg字段,指向了每一个
task 的css_set。css_set结构中则包含tasks头指针,指向所有链到此css_set的 task 进程构成的链表。至此,我们就明白如何查看在同一个
cgroup 中的 task 有哪些了,如下图 7。
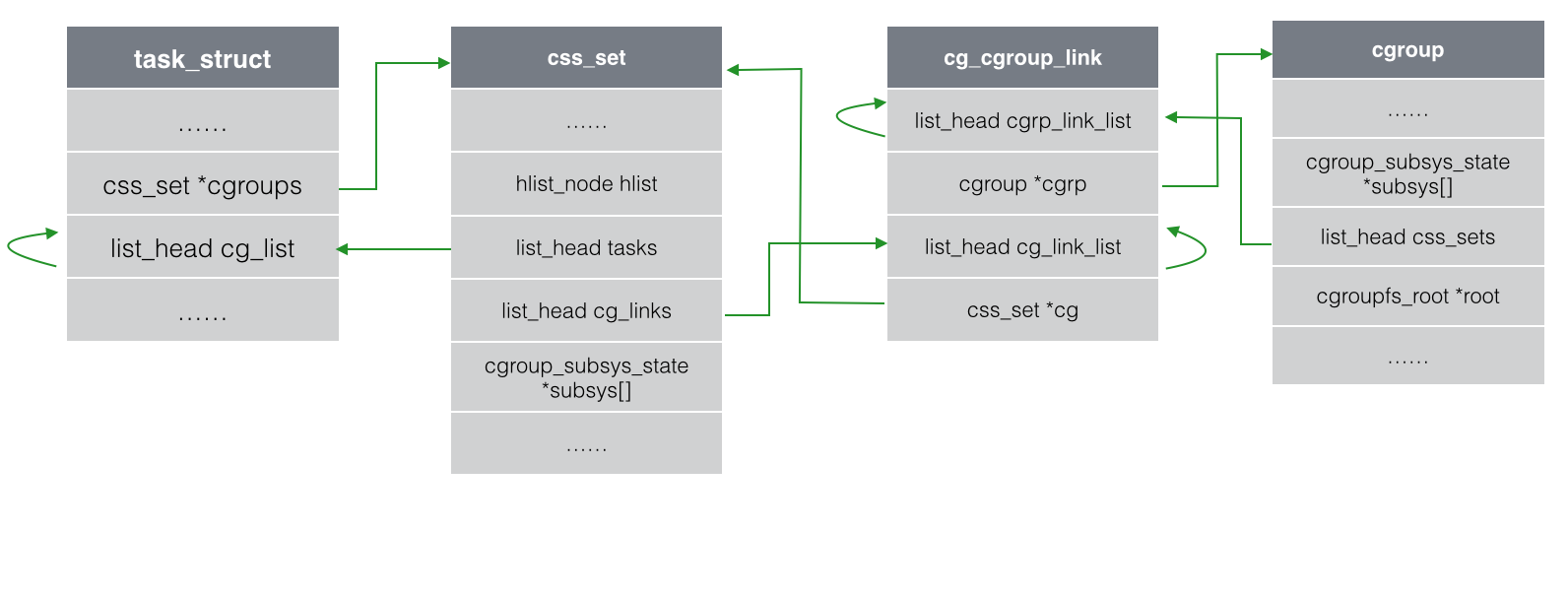
图 7 cglink 多对多双向查询
细心的读者可能已经发现,css_set中也有指向所有cg_cgroup_link构成链表的头指针,通过这种方式也能定位到所有的
cgroup,这种方式与图 1 中所示的方式得到的结果是相同的。
那么为什么要使用cg_cgroup_link结构体呢?因为 task 与 cgroup
之间是多对多的关系。熟悉数据库的读者很容易理解,在数据库中,如果两张表是多对多的关系,那么如果不加入第三张关系表,就必须为一个字段的不同添加许多行记录,导致大量冗余。通过从主表和副表各拿一个主键新建一张关系表,可以提高数据查询的灵活性和效率。
而一个 task 可能处于不同的 cgroup,只要这些 cgroup 在不同的 hierarchy 中,并且每个 hierarchy 挂载的子系统不同;另一方面,一个
cgroup 中可以有多个 task,这是显而易见的,但是这些 task 因为可能还存在在别的 cgroup 中,所以它们对应的css_set也不尽相同,所以一个
cgroup 也可以对应多个·css_set。
在系统运行之初,内核的主函数就会对root cgroups和css_set进行初始化,每次 task 进行 fork/exit 时,都会附加(attach)/
分离(detach)对应的css_set。
综上所述,添加cg_cgroup_link主要是出于性能方面的考虑,一是节省了task_struct
结构体占用的内存,二是提升了进程fork()/exit()的速度。
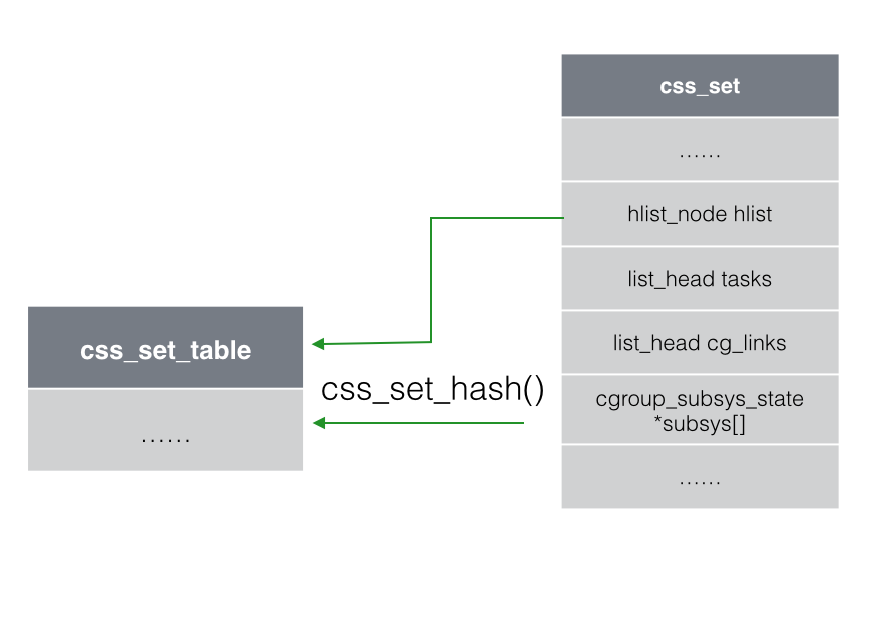
图 8 css_set 与 hashtable 关系
当 task 从一个 cgroup 中移动到另一个时,它会得到一个新的css_set指针。如果所要加入的 cgroup 与现有的 cgroup
子系统相同,那么就重复使用现有的css_set,否则就分配一个新css_set。所有的css_set通过一个哈希表进行存放和查询,如上图 8
中所示,hlist_node hlist就指向了css_set_table这个 hash 表。
同时,为了让 cgroups 便于用户理解和使用,也为了用精简的内核代码为 cgroup 提供熟悉的权限和命名空间管理,内核开发者们按照
Linux 虚拟文件系统转换器(VFS:Virtual Filesystem Switch)的接口实现了一套名为cgroup的文件系统,非常巧妙地用来表示 cgroups
的 hierarchy 概念,把各个 subsystem
的实现都封装到文件系统的各项操作中。有兴趣的读者可以在网上搜索并阅读 VFS
的相关内容,在此就不赘述了。
定义子系统的结构体是cgroup_subsys,在图 9 中可以看到,cgroup_subsys
中定义了一组函数的接口,让各个子系统自己去实现,类似的思想还被用在了cgroup_subsys_state中,cgroup_subsys_state
并没有定义控制信息,只是定义了各个子系统都需要用到的公共信息,由各个子系统各自按需去定义自己的控制信息结构体,最终在自定义的结构体中把cgroup_subsys_state
包含进去,然后内核通过container_of(这个宏可以通过一个结构体的成员找到结构体自身)等宏定义来获取对应的结构体。
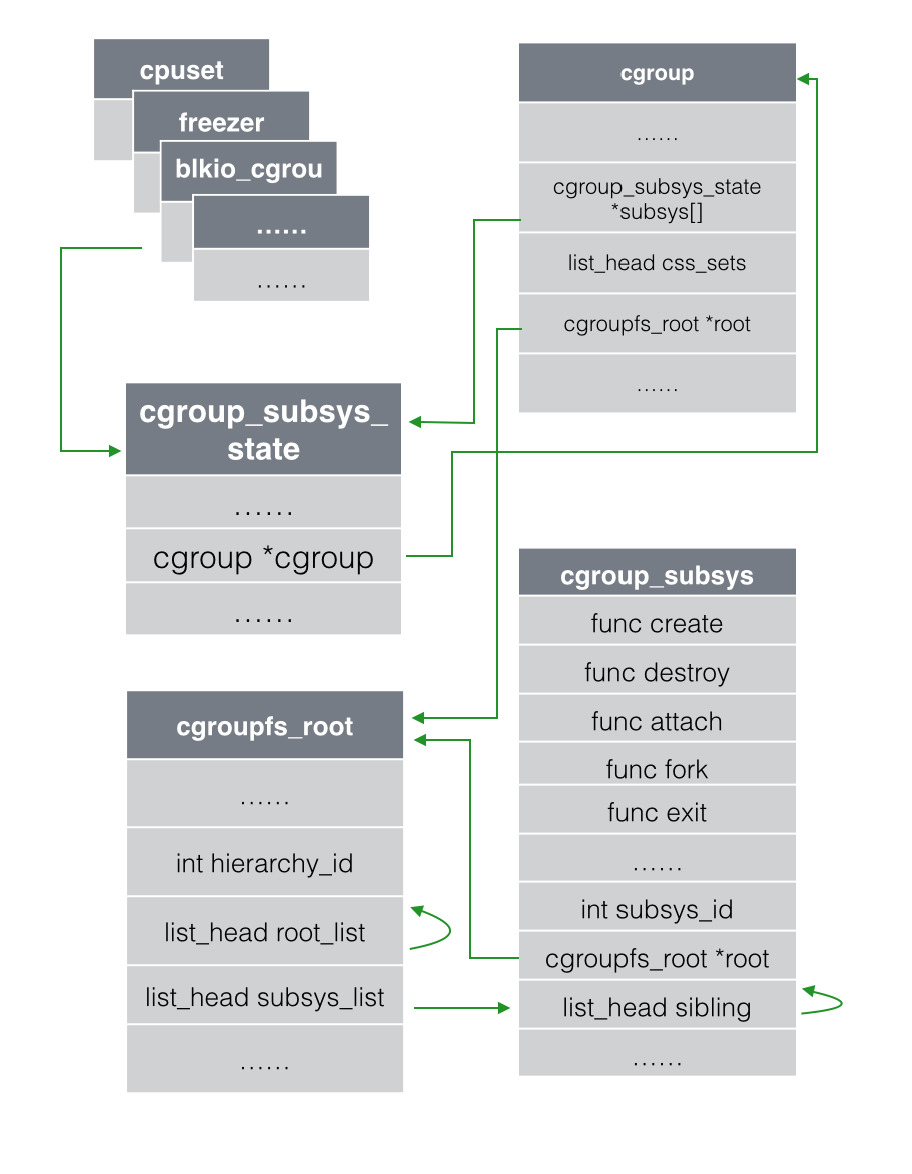
图 9 cgroup 子系统结构体
了解了 cgroups 实现的代码结构以后,再来看用户层在使用 cgroups 时的限制,会更加清晰。
在实际的使用过程中,你需要通过挂载(mount)cgroup文件系统新建一个层级结构,挂载时指定要绑定的子系统,缺省情况下默认绑定系统所有子系统。把
cgroup 文件系统挂载(mount)上以后,你就可以像操作文件一样对 cgroups 的 hierarchy 层级进行浏览和操作管理(包括权限管理、子文件管理等等)。除了
cgroup 文件系统以外,内核没有为 cgroups 的访问和操作添加任何系统调用。
如果新建的层级结构要绑定的子系统与目前已经存在的层级结构完全相同,那么新的挂载会重用原来已经存在的那一套(指向相同的 css_set)。否则如果要绑定的子系统已经被别的层级绑定,就会返回挂载失败的错误。如果一切顺利,挂载完成后层级就被激活并与相应子系统关联起来,可以开始使用了。
目前无法将一个新的子系统绑定到激活的层级上,或者从一个激活的层级中解除某个子系统的绑定。
当一个顶层的 cgroup 文件系统被卸载(umount)时,如果其中创建后代 cgroup 目录,那么就算上层的 cgroup 被卸载了,层级也是激活状态,其后代 cgoup 中的配置依旧有效。只有递归式的卸载层级中的所有 cgoup,那个层级才会被真正删除。
层级激活后,/proc目录下的每个 task PID 文件夹下都会新添加一个名为cgroup的文件,列出 task 所在的层级,对其进行控制的子系统及对应
cgroup 文件系统的路径。
一个 cgroup 创建完成,不管绑定了何种子系统,其目录下都会生成以下几个文件,用来描述 cgroup 的相应信息。同样,把相应信息写入这些配置文件就可以生效,内容如下。
tasks:这个文件中罗列了所有在该 cgroup 中 task 的 PID。该文件并不保证 task 的 PID 有序,把一个 task 的 PID 写到这个文件中就意味着把这个 task 加入这个 cgroup 中。cgroup.procs:这个文件罗列所有在该 cgroup 中的线程组 ID。该文件并不保证线程组 ID 有序和无重复。写一个线程组 ID 到这个文件就意味着把这个组中所有的线程加到这个 cgroup 中。notify_on_release:填 0 或 1,表示是否在 cgroup 中最后一个 task 退出时通知运行release agent,默认情况下是 0,表示不运行。release_agent:指定 release agent 执行脚本的文件路径(该文件在最顶层 cgroup 目录中存在),在这个脚本通常用于自动化umount无用的 cgroup。
除了上述几个通用的文件以外,绑定特定子系统的目录下也会有其他的文件进行子系统的参数配置。
在创建的 hierarchy 中创建文件夹,就类似于 fork 中一个后代 cgroup,后代 cgroup 中默认继承原有 cgroup 中的配置属性,但是你可以根据需求对配置参数进行调整。这样就把一个大的 cgroup 系统分割成一个个嵌套的、可动态变化的“软分区”。
本节主要针对 Ubuntu14.04 版本系统进行介绍,其他 Linux 发行版命令略有不同,原理是一样的。不安装 cgroups 工具库也可以使用 cgroups,安装它只是为了更方便的在用户态对 cgroups 进行管理,同时也方便初学者理解和使用,本节对 cgroups 的操作和使用都基于这个工具库。
apt-get install cgroup-bin
安装的过程会自动创建/cgroup目录,如果没有自动创建也不用担心,使用 mkdir /cgroup
手动创建即可。在这个目录下你就可以挂载各类子系统。安装完成后,你就可以使用lssubsys(罗列所有的 subsystem 挂载情况)等命令。
说明:也许你在其他文章中看到的 cgroups 工具库教程,会在 /etc 目录下生成一些初始化脚本和配置文件,默认的 cgroup
配置文件为/etc/cgconfig.conf,但是因为存在使 LXC 无法运行的
bug,所以在新版本中把这个配置移除了,详见:https://bugs.launchpad.net/ubuntu/+source/libcgroup/+bug/1096771。
在挂载子系统之前,可能你要先检查下目前子系统的挂载状态,如果子系统已经挂载,根据第 4 节中讲的规则 2,你就无法把子系统挂载到新的 hierarchy,此时就需要先删除相应 hierarchy 或卸载对应子系统后再挂载。
- 查看所有的 cgroup:
lscgroup - 查看所有支持的子系统:
lssubsys -a - 查看所有子系统挂载的位置:
lssubsys –m - 查看单个子系统(如 memory)挂载位置:
lssubsys –m memory
在组织结构与规则一节中我们提到了 hierarchy 层级和 subsystem 子系统的关系,我们知道使用 cgroup 的最佳方式是:为想要管理的每个或每组资源创建单独的 cgroup 层级结构。而创建 hierarchy 并不神秘,实际上就是做一个标记,通过挂载一个 tmpfs{![ 基于内存的临时文件系统,详见:http://en.wikipedia.org/wiki/Tmpfs]}文件系统,并给一个好的名字就可以了,系统默认挂载的 cgroup 就会进行如下操作。
mount -t tmpfs cgroups /sys/fs/cgroup
其中-t即指定挂载的文件系统类型,其后的cgroups是会出现在mount展示的结果中用于标识,可以选择一个有用的名字命名,最后的目录则表示文件的挂载点位置。
挂载完成tmpfs后就可以通过mkdir命令创建相应的文件夹。
mkdir /sys/fs/cgroup/cg1
再把子系统挂载到相应层级上,挂载子系统也使用 mount 命令,语法如下。
mount -t cgroup -o subsystems name /cgroup/name
其中 subsystems 是使用,(逗号)分开的子系统列表,name 是层级名称。具体我们以挂载 cpu 和 memory 的子系统为例,命令如下。
mount –t cgroup –o cpu,memory cpu_and_mem /sys/fs/cgroup/cg1
从mount命令开始,-t后面跟的是挂载的文件系统类型,即cgroup文件系统。-o后面跟要挂载的子系统种类如cpu、memory
,用逗号隔开,其后的cpu_and_mem不被 cgroup 代码的解释,但会出现在 /proc/mounts 里,可以使用任何有用的标识字符串。最后的参数则表示挂载点的目录位置。
说明:如果挂载时提示mount: agent already mounted or /cgroup busy,则表示子系统已经挂载,需要先卸载原先的挂载点,通过第二条中描述的命令可以定位挂载点。
目前cgroup文件系统虽然支持重新挂载,但是官方不建议使用,重新挂载虽然可以改变绑定的子系统和release agent,但是它要求对应的
hierarchy 是空的并且 release_agent 会被传统的fsnotify
(内核默认的文件系统通知)代替,这就导致重新挂载很难生效,未来重新挂载的功能可能会移除。你可以通过卸载,再挂载的方式处理这样的需求。
卸载 cgroup 非常简单,你可以通过cgdelete命令,也可以通过rmdir,以刚挂载的 cg1 为例,命令如下。
rmdir /sys/fs/cgroup/cg1
rmdir 执行成功的必要条件是 cg1 下层没有创建其它 cgroup,cg1 中没有添加任何 task,并且它也没有被别的 cgroup 所引用。
cgdelete cpu,memory:/ 使用cgdelete命令可以递归的删除 cgroup 及其命令下的后代 cgroup,并且如果 cgroup 中有 task,那么
task 会自动移到上一层没有被删除的 cgroup 中,如果所有的 cgroup 都被删除了,那 task 就不被 cgroups 控制。但是一旦再次创建一个新的
cgroup,所有进程都会被放进新的 cgroup 中。
设置 cgroups 参数非常简单,直接对之前创建的 cgroup 对应文件夹下的文件写入即可,举例如下。
- 设置 task 允许使用的 cpu 为 0 和 1.
echo 0-1 > /sys/fs/cgroup/cg1/cpuset.cpus
使用cgset命令也可以进行参数设置,对应上述允许使用 0 和 1cpu 的命令为:
cgset -r cpuset.cpus=0-1 cpu,memory:/
- 通过文件操作进行添加
echo [PID] > /path/to/cgroup/tasks上述命令就是把进程 ID 打印到 tasks 中,如果 tasks 文件中已经有进程,需要使用">>"向后添加。 - 通过
cgclassify将进程添加到 cgroupcgclassify -g subsystems:path_to_cgroup pidlist这个命令中,subsystems指的就是子系统(如果使用 man 命令查看,可能也会使用 controllers 表示),如果 mount 了多个,就是用","隔开的子系统名字作为名称,类似cgset命令。 - 通过
cgexec直接在 cgroup 中启动并执行进程cgexec -g subsystems:path_to_cgroup command argumentscommand和arguments就表示要在 cgroup 中执行的命令和参数。cgexec常用于执行临时的任务。
与文件的权限管理类似,通过chown就可以对 cgroup 文件系统进行权限管理。
chown uid:gid /path/to/cgroup
uid 和 gid 分别表示所属的用户和用户组。
- 限额类 限额类是主要有两种策略,一种是基于完全公平队列调度(CFQ:Completely Fair Queuing )的按权重分配各个 cgroup
所能占用总体资源的百分比,好处是当资源空闲时可以充分利用,但只能用于最底层节点 cgroup 的配置;另一种则是设定资源使用上限,这种限额在各个层次的
cgroup 都可以配置,但这种限制较为生硬,并且容器之间依然会出现资源的竞争。
- 按比例分配块设备 IO 资源
- blkio.weight:填写 100-1000 的一个整数值,作为相对权重比率,作为通用的设备分配比。
- blkio.weight_device: 针对特定设备的权重比,写入格式为
device_types:node_numbers weight,空格前的参数段指定设备,weight参数与blkio.weight相同并覆盖原有的通用分配比。{![查看一个设备的device_types:node_numbers可以使用:ls -l /dev/DEV,看到的用逗号分隔的两个数字就是。有的文章也称之为major_number:minor_number。]} - 控制 IO 读写速度上限
- blkio.throttle.read_bps_device
:按每秒读取块设备的数据量设定上限,格式
device_types:node_numbers bytes_per_second。 - blkio.throttle.write_bps_device
:按每秒写入块设备的数据量设定上限,格式
device_types:node_numbers bytes_per_second。 - blkio.throttle.read_iops_device
:按每秒读操作次数设定上限,格式
device_types:node_numbers operations_per_second。 - blkio.throttle.write_iops_device
:按每秒写操作次数设定上限,格式
device_types:node_numbers operations_per_second
- blkio.throttle.read_bps_device
:按每秒读取块设备的数据量设定上限,格式
- 针对特定操作 (read, write, sync, 或 async) 设定读写速度上限
- blkio.throttle.io_serviced
:针对特定操作按每秒操作次数设定上限,格式
device_types:node_numbers operation operations_per_second - blkio.throttle.io_service_bytes
:针对特定操作按每秒数据量设定上限,格式
device_types:node_numbers operation bytes_per_second
- blkio.throttle.io_serviced
:针对特定操作按每秒操作次数设定上限,格式
- 统计与监控 以下内容都是只读的状态报告,通过这些统计项更好地统计、监控进程的 io 情况。
- blkio.reset_stats:重置统计信息,写入一个 int 值即可。
- blkio.time:统计 cgroup 对设备的访问时间,按格式
device_types:node_numbers milliseconds读取信息即可,以下类似。 - blkio.io_serviced:统计 cgroup 对特定设备的 IO 操作(包括 read、write、sync 及
async)次数,格式
device_types:node_numbers operation number - blkio.sectors:统计 cgroup 对设备扇区访问次数,格式
device_types:node_numbers sector_count - blkio.io_service_bytes:统计 cgroup 对特定设备 IO 操作(包括 read、write、sync 及
async)的数据量,格式
device_types:node_numbers operation bytes - blkio.io_queued:统计 cgroup 的队列中对 IO 操作(包括 read、write、sync 及
async)的请求次数,格式
number operation - blkio.io_service_time:统计 cgroup 对特定设备的 IO 操作(包括 read、write、sync 及 async)时间 (单位为 ns)
,格式
device_types:node_numbers operation time - blkio.io_merged:统计 cgroup 将 BIOS 请求合并到 IO 操作(包括 read、write、sync 及
async)请求的次数,格式
number operation - blkio.io_wait_time:统计 cgroup 在各设备中各类型IO 操作(包括 read、write、sync 及 async)在队列中的等待时间(单位
ns),格式
device_types:node_numbers operation time - __blkio._recursive*:各类型的统计都有一个递归版本,Docker 中使用的都是这个版本。获取的数据与非递归版本是一样的,但是包括 cgroup 所有层级的监控数据。
CPU 资源的控制也有两种策略,一种是完全公平调度 (CFS:Completely Fair Scheduler)策略,提供了限额和按比例分配两种方式进行资源控制;另一种是实时调度(Real-Time
Scheduler)策略,针对实时进程按周期分配固定的运行时间。配置时间都以微秒(µs)为单位,文件名中用us表示。
- CFS 调度策略下的配置
- 设定 CPU 使用周期使用时间上限
- cpu.cfs_period_us:设定周期时间,必须与
cfs_quota_us配合使用。 - cpu.cfs_quota_us :设定周期内最多可使用的时间。这里的配置指 task 对单个 cpu 的使用上限,若
cfs_quota_us是cfs_period_us的两倍,就表示在两个核上完全使用。数值范围为 1000 - 1000,000(微秒)。 - cpu.stat:统计信息,包含
nr_periods(表示经历了几个cfs_period_us周期)、nr_throttled(表示 task 被限制的次数)及throttled_time(表示 task 被限制的总时长)。 - 按权重比例设定 CPU 的分配
- cpu.shares:设定一个整数(必须大于等于 2)表示相对权重,最后除以权重总和算出相对比例,按比例分配 CPU 时间。(如 cgroup A 设置 100,cgroup B 设置 300,那么 cgroup A 中的 task 运行 25% 的 CPU 时间。对于一个 4 核 CPU 的系统来说,cgroup A 中的 task 可以 100% 占有某一个 CPU,这个比例是相对整体的一个值。)
- RT 调度策略下的配置 实时调度策略与公平调度策略中的按周期分配时间的方法类似,也是在周期内分配一个固定的运行时间。
- cpu.rt_period_us :设定周期时间。
- cpu.rt_runtime_us:设定周期中的运行时间。
这个子系统的配置是cpu子系统的补充,提供 CPU 资源用量的统计,时间单位都是纳秒。
- cpuacct.usage:统计 cgroup 中所有 task 的 cpu 使用时长
- cpuacct.stat:统计 cgroup 中所有 task 的用户态和内核态分别使用 cpu 的时长
- cpuacct.usage_percpu:统计 cgroup 中所有 task 使用每个 cpu 的时长
为 task 分配独立 CPU 资源的子系统,参数较多,这里只选讲两个必须配置的参数,同时 Docker 中目前也只用到这两个。
- cpuset.cpus:在这个文件中填写 cgroup 可使用的 CPU 编号,如
0-2,16代表 0、1、2 和 16 这 4 个 CPU。 - cpuset.mems:与 CPU 类似,表示 cgroup 可使用的
memory node,格式同上
- ** 设备黑 / 白名单过滤 **
- devices.allow:允许名单,语法
type device_types:node_numbers access type;type有三种类型:b(块设备)、c(字符设备)、a(全部设备);access也有三种方式:r(读)、w(写)、m(创建)。 - devices.deny:禁止名单,语法格式同上。
- devices.allow:允许名单,语法
- 统计报告
- devices.list:报告为这个 cgroup 中的task 设定访问控制的设备
只有一个属性,表示进程的状态,把 task 放到 freezer 所在的 cgroup,再把 state 改为 FROZEN,就可以暂停进程。不允许在 cgroup 处于 FROZEN 状态时加入进程。 * **freezer.state **,包括如下三种状态: - FROZEN 停止 - FREEZING 正在停止,这个是只读状态,不能写入这个值。 - THAWED 恢复
- 限额类
- memory.limit_bytes:强制限制最大内存使用量,单位有
k、m、g三种,填-1则代表无限制。 - memory.soft_limit_bytes:软限制,只有比强制限制设置的值小时才有意义。填写格式同上。当整体内存紧张的情况下,task 获取的内存就被限制在软限制额度之内,以保证不会有太多进程因内存挨饿。可以看到,加入了内存的资源限制并不代表没有资源竞争。
- memory.memsw.limit_bytes:设定最大内存与 swap 区内存之和的用量限制。填写格式同上。
- memory.limit_bytes:强制限制最大内存使用量,单位有
- 报警与自动控制
- memory.oom_control:改参数填 0 或 1,
0表示开启,当 cgroup 中的进程使用资源超过界限时立即杀死进程,1表示不启用。默认情况下,包含 memory 子系统的 cgroup 都启用。当oom_control不启用时,实际使用内存超过界限时进程会被暂停直到有空闲的内存资源。
- memory.oom_control:改参数填 0 或 1,
- 统计与监控类
- memory.usage_bytes:报告该 cgroup 中进程使用的当前总内存用量(以字节为单位)
- memory.max_usage_bytes:报告该 cgroup 中进程使用的最大内存用量
- memory.failcnt:报告内存达到在
memory.limit_in_bytes设定的限制值的次数 - memory.stat:包含大量的内存统计数据。
- cache:页缓存,包括 tmpfs(shmem),单位为字节。
- rss:匿名和 swap 缓存,不包括 tmpfs(shmem),单位为字节。
- mapped_file:memory-mapped 映射的文件大小,包括 tmpfs(shmem),单位为字节
- pgpgin:存入内存中的页数
- pgpgout:从内存中读出的页数
- swap:swap 用量,单位为字节
- active_anon:在活跃的最近最少使用(least-recently-used,LRU)列表中的匿名和 swap 缓存,包括 tmpfs(shmem),单位为字节
- inactive_anon:不活跃的 LRU 列表中的匿名和 swap 缓存,包括 tmpfs(shmem),单位为字节
- active_file:活跃 LRU 列表中的 file-backed 内存,以字节为单位
- inactive_file:不活跃 LRU 列表中的 file-backed 内存,以字节为单位
- unevictable:无法再生的内存,以字节为单位
- hierarchical_memory_limit:包含 memory cgroup 的层级的内存限制,单位为字节
- hierarchical_memsw_limit:包含 memory cgroup 的层级的内存加 swap 限制,单位为字节
本文由浅入深的讲解了 cgroups 的方方面面,从 cgroups 是什么,到 cgroups 该怎么用,最后对大量的 cgroup 子系统配置参数进行了梳理。可以看到,内核对 cgroups 的支持已经较为完善,但是依旧有许多工作需要完善。如网络方面目前是通过 TC(Traffic Controller)来控制,未来需要统一整合;资源限制并没有解决资源竞争,在各自限制之内的进程依旧存在资源竞争,优先级调度方面依旧有很大的改进空间。希望通过本文帮助大家了解 cgroups,让更多人参与到社区的贡献中。
孙健波,浙江大学SEL 实验室 硕士研究生,目前在云平台团队从事科研和开发工作。浙大团队对PaaS、Docker、大数据和主流开源云计算技术有深入的研究和二次开发经验,团队现将部分技术文章贡献出来,希望能对读者有所帮助。
- https://sysadmincasts.com/episodes/14-introduction-to-linux-control-groups-cgroups
- https://access.redhat.com/documentation/en-US/Red*Hat*Enterprise_Linux/6/html/Resource*Management*Guide/index.html
- http://www.cnblogs.com/lisperl/archive/2013/01/14/2860353.html
- https://www.kernel.org/doc/Documentation/cgroups
Docker是一个用于开发、运输和运行应用程序的开放平台。Docker允许你将你的应用从基础架构中分离出来,这样可实现快速交付。 使用Docker,你可以像管理应用程序一样来管理基础架构。通过利用Docker的方法快速发送、测试和部署代码的优势,你可以显著减少编写代码和在生产环境中运行代码之间的延迟。
Docker提供了在容器隔离环境中打包和运行应用的能力。容器的隔离性和安全性允许你在宿主机上同时运行多个容器。容器是轻量级的因为它不需要额外的加载一个虚拟机管理程序,而且直接运行在宿主机的内核之上。这意着相同硬件环境下比起虚拟机你可以运行更多的容器。你甚至可以将容器运行到实际是虚拟机的宿主机中!
Docker提供了工具和平台来管理容器的生命周期:
- 使用容器开开发应用和相应的支持组件
- 容器是分布式单元和允许你测试你的应用
- 准备就绪后, 使用容器编排和部署应用到生产环境。无论本地数据中心,还是云提供商或者两者混合,这都是相同的
docker login --username=someone sub.domain.com
docker tag
docker images
docker buildx build --platform linux/amd64 -t jinmao:0.1.6 --output type=docker,dest=dist/jinmao-0.1.6.tar .
docker load -i dist/jinmao-0.1.6.tar
3455 docker tag jinmao:0.1.6 registry.cn-hangzhou.aliyuncs.com/metac_server/jinmap:0.1.6
3456 docker push registry.cn-hangzhou.aliyuncs.com/metac_server/jinmap:0.1.6Configure Docker to use a proxy server: https://docs.docker.com/network/proxy/
https://docs.docker.com/config/daemon/systemd/
https://docs.docker.com/config/daemon/#configure-the-docker-daemon
Warning
在Docker Desktop 和 Docker Engine 的 代理配置方式不一样
- 容器中运行 export
- docker run -e ENV_VAR1=11
- systemd配置
这样可以让所有容器也能访问代理
systemctl status docker
sudo vim /lib/systemd/system/docker.service
Environment="HTTP_PROXY=http://127.0.0.1:7890"
Environment="HTTPS_PROXY=http://127.0.0.1:7890"
Environment="ALL_PROXY=socks5://127.0.0.1:7890"
Environment="NO_PROXY=localhost,127.0.0.1,127.0.0.0/8"
Environment="HTTP_PROXY=http://10.31.0.181:7890"
Environment="HTTPS_PROXY=http://10.31.0.181:7890/"
Environment="NO_PROXY=localhost,127.0.0.1"/etc/docker/daemon.json
{
"proxies": {
"http-proxy": "http://10.31.0.181:7890",
"https-proxy": "http://10.31.0.181:7890",
"no-proxy": "*.test.example.com,.example.org,127.0.0.0/8, 10.31.0.1/16, ssrf_proxy"
}
}~/.docker/config.json
{
"proxies": {
"http-proxy": "http://10.31.0.181:7890",
"https-proxy": "http://10.31.0.181:7890",
"no-proxy": "*.test.example.com,.example.org,127.0.0.0/8, 10.31.0.1/16, ssrf_proxy"
}
}
docker 引擎
Linux 中应该使用https://docs.docker.com/config/daemon/#configure-the-docker-daemon
或者通过网关 http://172.17.0.1:7890
{
"proxies": {
"default": {
"httpProxy": "http://192.168.0.181:7890",
"httpsProxy": "http://192.168.0.181:7890",
"noProxy": "*.test.example.com,.example.org,127.0.0.0/8"
}
}
}Tip
这种模式下127.0.0.1 localhost 192.168.0.1这样的代理无效
host.docker.internal
gateway.docker.internaldocker pull --platform linux/amd64 redis
docker save -o redis 5c435642ca4d
docker save -o prom.tar 5c435642ca4d # 思路一 将阶段一的容器作为阶段二的base容器
# 思路二 将阶段一构建的文件复制到阶段二中容器化的基本思路是通过Dockerfile来控制
网络配置 - 桥接模式
数据卷 -
--volume, -v
docker run --name python -it -v C:\docker\python:/usr/src/python -w /usr/src/python python:3.7 bash
docker run --name ubuntu -it -v C:/docker/ubuntu:/ubuntu -w /ubuntu ubuntu:latest bash
docker run --name ubuntu -it -v /c/docker/ubuntu:/ubuntu -w /ubuntu ubuntu:latest bash
# 查看容器IP
docker inspect python
# 为新容器设置密码
passwd root
# 进入启动的容器
docker attach
# 实现共享数据
-v HOST_DIR:CONTAINER_DIR
常用的容器注册处(Container Registry)
OCI
-
dockerize
services:
api:
build: .
container_name: api
ports:
- "8080:8080"
depends_on:
db:
# 这里
condition: service_healthy
db:
container_name: db
image: mysql
ports:
- "3306"
environment:
MYSQL_ALLOW_EMPTY_PASSWORD: "yes"
MYSQL_USER: "user"
MYSQL_PASSWORD: "password"
MYSQL_DATABASE: "database"
# 这里
healthcheck:
test: ["CMD", "mysqladmin" ,"ping", "-h", "localhost"]
timeout: 20s
retries: 10- 镜像加速 - 阿里云 - https://jqotns4f.mirror.aliyuncs.com
使用dockerfile定制镜像思路
从刚才的 docker commit 的学习中,我们可以了解到,镜像的定制实际上就是定制每一层所添加的配置、文件。如果我们可以把每一层修改、安装、构建、操作的命令都写入一个脚本,用这个脚本来构建、定制镜像,那么之前提及的无法重复的问题、镜像构建透明性的问题、体积的问题就都会解决。这个脚本就是 Dockerfile。 Dockerfile 是一个文本文件,其内包含了一条条的 指令(Instruction),每一条指令构建一层,因此每一条指令的内容,就是描述该层应当如何构建。 还以之前定制 nginx 镜像为例,这次我们使用 Dockerfile 来定制。 在一个空白目录中,建立一个文本文件,并命名为 Dockerfile:
$ mkdir mynginx
$ cd mynginx
$ touch Dockerfile其内容为:
FROM nginx
RUN echo '<h1>Hello, Docker!</h1>' > /usr/share/nginx/html/index.html这个 Dockerfile 很简单,一共就两行。涉及到了两条指令,FROM 和 RUN。
FROM 指定基础镜像 所谓定制镜像,那一定是以一个镜像为基础,在其上进行定制。就像我们之前运行了一个 nginx 镜像的容器,再进行修改一样,基础镜像是必须指定的。而 FROM 就是指定 基础镜像,因此一个 Dockerfile 中 FROM 是必备的指令,并且必须是第一条指令。 在 Docker Hub 上有非常多的高质量的官方镜像,有可以直接拿来使用的服务类的镜像,如 nginx、redis、mongo、mysql、httpd、php、tomcat 等;也有一些方便开发、构建、运行各种语言应用的镜像,如 node、openjdk、python、ruby、golang 等。可以在其中寻找一个最符合我们最终目标的镜像为基础镜像进行定制。 如果没有找到对应服务的镜像,官方镜像中还提供了一些更为基础的操作系统镜像,如 ubuntu、debian、centos、fedora、alpine 等,这些操作系统的软件库为我们提供了更广阔的扩展空间。 除了选择现有镜像为基础镜像外,Docker 还存在一个特殊的镜像,名为 scratch。这个镜像是虚拟的概念,并不实际存在,它表示一个空白的镜像。FROM scratch ...
如果你以 scratch 为基础镜像的话,意味着你不以任何镜像为基础,接下来所写的指令将作为镜像第一层开始存在。 不以任何系统为基础,直接将可执行文件复制进镜像的做法并不罕见,比如 swarm、etcd。对于 Linux 下静态编译的程序来说,并不需要有操作系统提供运行时支持,所需的一切库都已经在可执行文件里了,因此直接 FROM scratch 会让镜像体积更加小巧。使用 Go 语言 开发的应用很多会使用这种方式来制作镜像,这也是为什么有人认为 Go 是特别适合容器微服务架构的语言的原因之一。
RUN 执行命令RUN 指令是用来执行命令行命令的。由于命令行的强大能力,RUN 指令在定制镜像时是最常用的指令之一。其格式有两种:shell 格式:RUN <命令>,就像直接在命令行中输入的命令一样。刚才写的 Dockerfile 中的 RUN 指令就是这种格式。
RUN echo '<h1>Hello, Docker!</h1>' > /usr/share/nginx/html/index.htmlexec 格式:RUN ["可执行文件", "参数1", "参数2"],这更像是函数调用中的格式。 既然 RUN 就像 Shell 脚本一样可以执行命令,那么我们是否就可以像 Shell 脚本一样把每个命令对应一个 RUN 呢?比如这样:
FROM debian:stretch
RUN apt-get update
RUN apt-get install -y gcc libc6-dev make wget
RUN wget -O redis.tar.gz "http://download.redis.io/releases/redis-5.0.3.tar.gz"
RUN mkdir -p /usr/src/redis
RUN tar -xzf redis.tar.gz -C /usr/src/redis --strip-components=1
RUN make -C /usr/src/redis
RUN make -C /usr/src/redis install之前说过,Dockerfile 中每一个RUN指令都会建立一层,RUN 也不例外。每一个 RUN
的行为,就和刚才我们手工建立镜像的过程一样:新建立一层,在其上执行这些命令,执行结束后,commit 这一层的修改,构成新的镜像。
而上面的这种写法,创建了 7 层镜像。这是完全没有意义的,而且很多运行时不需要的东西,都被装进了镜像里,比如编译环境、更新的软件包等等。结果就是产生非常臃肿、非常多层的镜像,不仅仅增加了构建部署的时间,也很容易出错。
这是很多初学 Docker 的人常犯的一个错误。Union FS 是有最大层数限制的,比如 AUFS,曾经是最大不得超过 42 层,现在是不得超过 127
层。
上面的 Dockerfile 正确的写法应该是这样:
FROM debian:stretch
RUN buildDeps='gcc libc6-dev make wget' \
&& apt-get update \
&& apt-get install -y $buildDeps \
&& wget -O redis.tar.gz "http://download.redis.io/releases/redis-5.0.3.tar.gz" \
&& mkdir -p /usr/src/redis \
&& tar -xzf redis.tar.gz -C /usr/src/redis --strip-components=1 \
&& make -C /usr/src/redis \
&& make -C /usr/src/redis install \
&& rm -rf /var/lib/apt/lists/* \
&& rm redis.tar.gz \
&& rm -r /usr/src/redis \
&& apt-get purge -y --auto-remove $buildDeps首先,之前所有的命令只有一个目的,就是编译、安装 redis 可执行文件。因此没有必要建立很多层,这只是一层的事情。因此,这里没有使用很多个 RUN 对一一对应不同的命令,而是仅仅使用一个 RUN 指令,并使用 && 将各个所需命令串联起来。将之前的 7 层,简化为了 1 层。在撰写 Dockerfile 的时候,要经常提醒自己,这并不是在写 Shell 脚本,而是在定义每一层该如何构建。 并且,这里为了格式化还进行了换行。Dockerfile 支持 Shell 类的行尾添加 \ 的命令换行方式,以及行首 # 进行注释的格式。良好的格式,比如换行、缩进、注释等,会让维护、排障更为容易,这是一个比较好的习惯。
此外,还可以看到这一组命令的最后添加了清理工作的命令,删除了为了编译构建所需要的软件,清理了所有下载、展开的文件,并且还清理了 apt 缓存文件。这是很重要的一步,我们之前说过,镜像是多层存储,每一层的东西并不会在下一层被删除,会一直跟随着镜像。因此镜像构建时,一定要确保每一层只添加真正需要添加的东西,任何无关的东西都应该清理掉。
很多人初学 Docker 制作出了很臃肿的镜像的原因之一,就是忘记了每一层构建的最后一定要清理掉无关文件
# 通用命令
-e TZ=Asia/Shanghai
--rm
# ubuntu
docker run --name ubuntu -p 2222:22 -dit ubuntu:22.04 /bin/bash
# 作为开发环境
docker run --name ubuntu -p 2222:22 \
--cap-add=NET_ADMIN
-dit ubuntu:22.04 /bin/bash
# redis
docker run --restart always -p 6379:6379 --name redis -d redis
# redis with redis.conf and logfile
docker run \
-v ~/docker/redis/config:/usr/local/etc/redis \
-v ~/docker/redis/data:/data \
-e TZ=Asia/Shanghai \
-p 6379:6379 --name redis -d redis redis-server /usr/local/etc/redis/6379.conf --save 60 1 --loglevel warning --appendonly yes
# 持久化
# --appendonly yes --restart always
# -v ~/docker/redis/log/redis.log:/var/log/redis/redis.log \
# -v ~/docker/redis/log:/var/log/redis \
docker run --restart always \
-p 6379:6379 --name redis -d redis
# mysql
docker run -p 3306:3306 -h mysql --name mysql \
-v ~/docker/mysql/config:/etc/mysql/conf.d \
-v ~/docker/mysql/data:/var/lib/mysql \
-e TZ=Asia/Shanghai -e MYSQL_DATABASE=molook -e MYSQL_ROOT_PASSWORD=metac2022 \
-e MYSQL_USER=molook -e MYSQL_PASSWORD=metac2022 -d mysql
# --restart always
docker run --rm -p 3307:3306 --name mysql2 -e MYSQL_DATABASE=demo -e MYSQL_ROOT_PASSWORD=wawawa -it mysql /bin/bash
# config and data mount
-v ~/docker/mysql/config:/etc/mysql/conf.d \
-v ~/docker/mysql/data:/var/lib/mysql \
docker run --restart always -p 43306:3306 -h mysql --name mysql5 \
-e MYSQL_ROOT_PASSWORD=wawawa -dit mysql:5
# postgres
docker run -p 5432:5432 -h postgres --name postgres \
-v /Users/wwfyde/docker/postgres/data:/var/lib/postgresql/data \
-e TZ=Asia/Shanghai -e POSTGRES_PASSWORD=wawawa -d postgres
# default username : postgres
# -e POSTGRES_USER=molook
# -e POSTGRES_USER=molook -e POSTGRES_DB=molook \
# --restart always
# -v /Users/wwfyde/docker/postgres/data:/var/lib/postgresql/data \
docker run --rm -d -e POSTGRES_PASSWORD=wawawa -e POSTGRES_USER=molook -e POSTGRES_DB=molook postgres
# mongo
docker run --name mongo -p 27017:27017 \
-e TZ=Asia/Shanghai -v ~/docker/mongo/data:/data/db \
-v ~/docker/mongo/config:/data/configdb \
-e MONGO_INITDB_ROOT_USERNAME=admin \
-e MONGO_INITDB_ROOT_PASSWORD=admin \
-d mongo
#-v ~/docker/mongo/data:/data/db
# -e MONGO_INITDB_ROOT_USERNAME=admin \
# -e MONGO_INITDB_ROOT_PASSWORD=admin \
# --restart always
# elasticsearch
docker run --name elasticsearch \
-e TZ=Asia/Shanghai --net es \
-p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -d elasticsearch:8.8.1
# --net somenetwork \
# --restart always
# meilisearch
docker run --name meilisearch \
-e TZ=Asia/Shanghai -p 7700:7700 \
-e MEILI_ENV='development' \
-v ~/docker/meilisearch/meili_data:/meili_data \
-d getmeili/meilisearch:v1.4
# mssql
docker run -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=Mssql123' \
-e 'MSSQL_PID=Express' \
-h mssql --name mssql-demo \
-p 1433:1433 -d mcr.microsoft.com/mssql/server
# rabbitmq
docker run -d --name rabbitmq \
-e TZ=Asia/Shanghai -p 15672:15672 -p 5672:5672 \
rabbitmq:management
# guest / guest
# --restart always
# oracle
docker run --name oracle-demo \
-p 41521:1521 \
-e ORACLE_ALLOW_REMOTE=true \
-d oracleinanutshell/oracle-xe-11g
hostname: localhost
port: 49161
sid: xe
username: system
password: oracle
# grafana
docker run -d --name=grafana -p 3000:3000 -e TZ=Asia/Shanghai \
-v /Users/wwfyde/docker/grafana/data:/var/lib/grafana \
grafana/grafana
#admin:admin/wawawa123
# 解决挂载问题
ALTER PROFILE DEFAULT LIMIT PASSWORD_LIFE_TIME UNLIMITED;
oracle
# 按照官方文档创建好docke镜像后
docker run --name oracle-demo \
-d \
-p 41521:1521 \
-p 45500:5500 \
-e ORACLE_PWD=wawawa \
-e ORACLE_CHARACTERSET=AL32UTF8 \
oracle/database:18.4.0-xe
##
-v /Users/wwfyde/docker/oracle/oradata:/opt/oracle/oradata \
-v /Users/wwfyde/docker/oracle/scripts/setup:/opt/oracle/scripts/setup \
-v /Users/wwfyde/docker/oracle/scripts/startup:/opt/oracle/scripts/startup \
# 登录
sqlplus sys/Oracle123@//localhost:41521/XE
# 应该采用新的语法登录
sqlplus system@"dbhost.example/XE"部署应用时,host应该选择0.0.0.0而不是127.0.0.1, 这样本机网络下的所有主机都能访问到, 否则只能在容器中访问, 这显然是不对的.
uvicorn main:app --host 0.0.0.0 --port 8000通过端口映射, VPN等方式保证网络可访问
代理 三种方式
systemd(推荐)
config文件
export
- https://docs.docker.com/language/python/
- https://docs.docker.com/develop/
- https://docs.docker.com/develop/dev-best-practices/
- https://docs.docker.com/develop/develop-images/dockerfile_best-practices/
通常
总结: Dockerfile 和 Kubernetes 对象的对应关系
1.Dockerfile 构建的镜像 对应 Kubernetes 中的 容器(Container).
2.在 Kubernetes 中, 容器通常会被打包到 Pod 中运行.
3.Pod 通常通过 Deployment 来管理, 从而实现更高层次的管理功能(如扩展、滚动更新等).
4.Service 用于为这些 Pod 提供稳定的访问入口, 可以是集群内部访问(ClusterIP), 或者通过 LoadBalancer 暴露到外部.
5.ConfigMap 和 Secret 帮助配置管理与敏感信息存储.