{
@@ -2122,7 +2118,7 @@ public void delete(Key key) {
线性探测法的成本取决于连续条目的长度,连续条目也叫聚簇。当聚簇很长时,在查找和插入时也需要进行很多次探测。例如下图中 2\~5 位置就是一个聚簇。
-
+
α = N/M,把 α 称为使用率。理论证明,当 α 小于 1/2 时探测的预计次数只在 1.5 到 2.5 之间。为了保证散列表的性能,应当调整数组的大小,使得 α 在 [1/4, 1/2] 之间。
diff --git "a/convert/\350\256\241\347\256\227\346\234\272\346\223\215\344\275\234\347\263\273\347\273\237.md" "b/convert/\350\256\241\347\256\227\346\234\272\346\223\215\344\275\234\347\263\273\347\273\237.md"
index e4a3a31..d93b11b 100644
--- "a/convert/\350\256\241\347\256\227\346\234\272\346\223\215\344\275\234\347\263\273\347\273\237.md"
+++ "b/convert/\350\256\241\347\256\227\346\234\272\346\223\215\344\275\234\347\263\273\347\273\237.md"
@@ -12,7 +12,7 @@ PDF制作github: https://github.com/sjsdfg/CS-Notes-PDF
并发是指宏观上在一段时间内能同时运行多个程序,而并行则指同一时刻能运行多个指令。
-并行需要硬件支持,如多流水线或者多处理器。
+并行需要硬件支持,如多流水线、多核处理器或者分布式计算系统。
操作系统通过引入进程和线程,使得程序能够并发运行。
@@ -32,7 +32,7 @@ PDF制作github: https://github.com/sjsdfg/CS-Notes-PDF
多个进程能在同一个处理器上并发执行使用了时分复用技术,让每个进程轮流占有处理器,每次只执行一小个时间片并快速切换。
-虚拟内存使用了空分复用技术,它将物理内存抽象为地址空间,每个进程都有各自的地址空间。地址空间和物理内存使用页进行交换,地址空间的页并不需要全部在物理内存中,当使用到一个没有在物理内存的页时,执行页面置换算法,将该页置换到内存中。
+虚拟内存使用了空分复用技术,它将物理内存抽象为地址空间,每个进程都有各自的地址空间。地址空间的页被映射到物理内存,地址空间的页并不需要全部在物理内存中,当使用到一个没有在物理内存的页时,执行页面置换算法,将该页置换到内存中。
### 4. 异步
@@ -835,7 +835,9 @@ FIFO 常用于客户-服务器应用程序中,FIFO 用作汇聚点,在客户
举例:一个系统为某进程分配了三个物理块,并有如下页面引用序列:
-$7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1$
+$$
+7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1
+$$
开始运行时,先将 7, 0, 1 三个页面装入内存。当进程要访问页面 2 时,产生缺页中断,会将页面 7 换出,因为页面 7 再次被访问的时间最长。
@@ -849,7 +851,9 @@ FIFO 常用于客户-服务器应用程序中,FIFO 用作汇聚点,在客户
因为每次访问都需要更新链表,因此这种方式实现的 LRU 代价很高。
-$4,7,0,7,1,0,1,2,1,2,6$
+$$
+4,7,0,7,1,0,1,2,1,2,6
+$$
diff --git "a/convert/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md" "b/convert/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
index b91bc3c..c1d7165 100644
--- "a/convert/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
+++ "b/convert/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
@@ -16,19 +16,21 @@ PDF制作github: https://github.com/sjsdfg/CS-Notes-PDF
互联网服务提供商 ISP 可以从互联网管理机构获得许多 IP 地址,同时拥有通信线路以及路由器等联网设备,个人或机构向 ISP 缴纳一定的费用就可以接入互联网。
-
+
目前的互联网是一种多层次 ISP 结构,ISP 根据覆盖面积的大小分为第一层 ISP、区域 ISP 和接入 ISP。互联网交换点 IXP 允许两个 ISP 直接相连而不用经过第三个 ISP。
-
+
## 主机之间的通信方式
- 客户-服务器(C/S):客户是服务的请求方,服务器是服务的提供方。
+
+
- 对等(P2P):不区分客户和服务器。
-
+
## 电路交换与分组交换
@@ -46,7 +48,7 @@ PDF制作github: https://github.com/sjsdfg/CS-Notes-PDF
总时延 = 排队时延 + 处理时延 + 传输时延 + 传播时延
-
+
### 1. 排队时延
@@ -60,7 +62,9 @@ PDF制作github: https://github.com/sjsdfg/CS-Notes-PDF
主机或路由器传输数据帧所需要的时间。
-$delay=\frac{l(bit)}{v(bit/s)}$
+$$
+delay=\frac{l(bit)}{v(bit/s)}
+$$
其中 l 表示数据帧的长度,v 表示传输速率。
@@ -68,17 +72,20 @@ PDF制作github: https://github.com/sjsdfg/CS-Notes-PDF
电磁波在信道中传播所需要花费的时间,电磁波传播的速度接近光速。
-$delay=\frac{l(m)}{v(m/s)}$
+$$
+delay=\frac{l(m)}{v(m/s)}
+$$
其中 l 表示信道长度,v 表示电磁波在信道上的传播速度。
## 计算机网络体系结构
-
+
+
### 1. 五层协议
-- **应用层** :为特定应用程序提供数据传输服务,例如 HTTP、DNS 等。数据单位为报文。
+- **应用层** :为特定应用程序提供数据传输服务,例如 HTTP、DNS 等协议。数据单位为报文。
- **传输层** :为进程提供通用数据传输服务。由于应用层协议很多,定义通用的传输层协议就可以支持不断增多的应用层协议。运输层包括两种协议:传输控制协议 TCP,提供面向连接、可靠的数据传输服务,数据单位为报文段;用户数据报协议 UDP,提供无连接、尽最大努力的数据传输服务,数据单位为用户数据报。TCP 主要提供完整性服务,UDP 主要提供及时性服务。
@@ -104,7 +111,7 @@ PDF制作github: https://github.com/sjsdfg/CS-Notes-PDF
TCP/IP 体系结构不严格遵循 OSI 分层概念,应用层可能会直接使用 IP 层或者网络接口层。
-
+
### 4. 数据在各层之间的传递过程
@@ -194,21 +201,27 @@ TCP/IP 体系结构不严格遵循 OSI 分层概念,应用层可能会直接
### 5. 码分复用
-为每个用户分配 m bit 的码片,并且所有的码片正交,对于任意两个码片 $\vec{S}$ 和 $\vec{T}$ 有
+为每个用户分配 m bit 的码片,并且所有的码片正交,对于任意两个码片 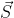 和
和 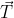 有
-
有
-$\frac{1}{m}\vec{S}\cdot\vec{T}=0$
+$$
+\frac{1}{m}\vec{S}\cdot\vec{T}=0
+$$
-为了讨论方便,取 m=8,设码片 $\vec{S}$ 为 00011011。在拥有该码片的用户发送比特 1 时就发送该码片,发送比特 0 时就发送该码片的反码 11100100。
+为了讨论方便,取 m=8,设码片 为 00011011。在拥有该码片的用户发送比特 1 时就发送该码片,发送比特 0 时就发送该码片的反码 11100100。
在计算时将 00011011 记作 (-1 -1 -1 +1 +1 -1 +1 +1),可以得到
-$\frac{1}{m}\vec{S}\cdot\vec{S}=1$
+$$
+\frac{1}{m}\vec{S}\cdot\vec{S}=1
+$$
-$\frac{1}{m}\vec{S}\cdot\vec{S'}=-1$
+$$
+\frac{1}{m}\vec{S}\cdot\vec{S'}=-1
+$$
-其中 $\vec{S'}$ 为 $\vec{S}$ 的反码。
+其中 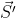 为 的反码。
-利用上面的式子我们知道,当接收端使用码片 $\vec{S}$ 对接收到的数据进行内积运算时,结果为 0 的是其它用户发送的数据,结果为 1 的是用户发送的比特 1,结果为 -1 的是用户发送的比特 0。
+利用上面的式子我们知道,当接收端使用码片 对接收到的数据进行内积运算时,结果为 0 的是其它用户发送的数据,结果为 1 的是用户发送的比特 1,结果为 -1 的是用户发送的比特 0。
码分复用需要发送的数据量为原先的 m 倍。
@@ -281,7 +294,7 @@ MAC 地址是链路层地址,长度为 6 字节(48 位),用于唯一标
正是由于这种自学习能力,因此交换机是一种即插即用设备,不需要网络管理员手动配置交换表内容。
-下图中,交换机有 4 个接口,主机 A 向主机 B 发送数据帧时,交换机把主机 A 到接口 1 的映射写入交换表中。为了发送数据帧到 B,先查交换表,此时没有主机 B 的表项,那么主机 A 就发送广播帧,主机 C 和主机 D 会丢弃该帧。主机 B 向主机 A 发送数据包时,交换机查找交换表得到主机 A 映射的接口为 1,就发送数据帧到接口 1,同时交换机添加主机 B 到接口 3 的映射。
+下图中,交换机有 4 个接口,主机 A 向主机 B 发送数据帧时,交换机把主机 A 到接口 1 的映射写入交换表中。为了发送数据帧到 B,先查交换表,此时没有主机 B 的表项,那么主机 A 就发送广播帧,主机 C 和主机 D 会丢弃该帧,主机 B 回应该帧向主机 A 发送数据包时,交换机查找交换表得到主机 A 映射的接口为 1,就发送数据帧到接口 1,同时交换机添加主机 B 到接口 2 的映射。
@@ -608,13 +621,19 @@ TCP 使用超时重传来实现可靠传输:如果一个已经发送的报文
一个报文段从发送再到接收到确认所经过的时间称为往返时间 RTT,加权平均往返时间 RTTs 计算如下:
-
为 的反码。
-利用上面的式子我们知道,当接收端使用码片 $\vec{S}$ 对接收到的数据进行内积运算时,结果为 0 的是其它用户发送的数据,结果为 1 的是用户发送的比特 1,结果为 -1 的是用户发送的比特 0。
+利用上面的式子我们知道,当接收端使用码片 对接收到的数据进行内积运算时,结果为 0 的是其它用户发送的数据,结果为 1 的是用户发送的比特 1,结果为 -1 的是用户发送的比特 0。
码分复用需要发送的数据量为原先的 m 倍。
@@ -281,7 +294,7 @@ MAC 地址是链路层地址,长度为 6 字节(48 位),用于唯一标
正是由于这种自学习能力,因此交换机是一种即插即用设备,不需要网络管理员手动配置交换表内容。
-下图中,交换机有 4 个接口,主机 A 向主机 B 发送数据帧时,交换机把主机 A 到接口 1 的映射写入交换表中。为了发送数据帧到 B,先查交换表,此时没有主机 B 的表项,那么主机 A 就发送广播帧,主机 C 和主机 D 会丢弃该帧。主机 B 向主机 A 发送数据包时,交换机查找交换表得到主机 A 映射的接口为 1,就发送数据帧到接口 1,同时交换机添加主机 B 到接口 3 的映射。
+下图中,交换机有 4 个接口,主机 A 向主机 B 发送数据帧时,交换机把主机 A 到接口 1 的映射写入交换表中。为了发送数据帧到 B,先查交换表,此时没有主机 B 的表项,那么主机 A 就发送广播帧,主机 C 和主机 D 会丢弃该帧,主机 B 回应该帧向主机 A 发送数据包时,交换机查找交换表得到主机 A 映射的接口为 1,就发送数据帧到接口 1,同时交换机添加主机 B 到接口 2 的映射。
@@ -608,13 +621,19 @@ TCP 使用超时重传来实现可靠传输:如果一个已经发送的报文
一个报文段从发送再到接收到确认所经过的时间称为往返时间 RTT,加权平均往返时间 RTTs 计算如下:
-$RTTs=(1-a)*(RTTs)+a*RTT$
+$$
+RTTs=(1-a)*(RTTs)+a*RTT
+$$
+
+其中,0 ≤ a < 1,RTTs 随着 a 的增加更容易受到 RTT 的影响。
超时时间 RTO 应该略大于 RTTs,TCP 使用的超时时间计算如下:
-$RTO=RTTs+4*RTT_d$
+$$
+RTO=RTTs+4*RTT_d
+$$
-其中 RTTd 为偏差。
+其中 RTTd 为偏差的加权平均值。
## TCP 滑动窗口
diff --git "a/convert/\351\233\206\347\276\244.md" "b/convert/\351\233\206\347\276\244.md"
index 46d4bc7..74cfe4f 100644
--- "a/convert/\351\233\206\347\276\244.md"
+++ "b/convert/\351\233\206\347\276\244.md"
@@ -6,16 +6,16 @@ PDF制作github: https://github.com/sjsdfg/CS-Notes-PDF
# 一、负载均衡
-集群中的应用服务器(节点)通常被设计成无状态,用户可以请求任何一个应用服务器。
+集群中的应用服务器(节点)通常被设计成无状态,用户可以请求任何一个节点。
负载均衡器会根据集群中每个节点的负载情况,将用户请求转发到合适的节点上。
负载均衡器可以用来实现高可用以及伸缩性:
- 高可用:当某个节点故障时,负载均衡器会将用户请求转发到另外的节点上,从而保证所有服务持续可用;
-- 伸缩性:根据系统整体负载情况,可以很容易地添加移除节点。
+- 伸缩性:根据系统整体负载情况,可以很容易地添加或移除节点。
-负载均衡运行过程包含两个部分:
+负载均衡器运行过程包含两个部分:
1. 根据负载均衡算法得到转发的节点;
2. 进行转发。
@@ -28,11 +28,11 @@ PDF制作github: https://github.com/sjsdfg/CS-Notes-PDF
下图中,一共有 6 个客户端产生了 6 个请求,这 6 个请求按 (1, 2, 3, 4, 5, 6) 的顺序发送。(1, 3, 5) 的请求会被发送到服务器 1,(2, 4, 6) 的请求会被发送到服务器 2。
-
+
该算法比较适合每个服务器的性能差不多的场景,如果有性能存在差异的情况下,那么性能较差的服务器可能无法承担过大的负载(下图的 Server 2)。
-
+
### 2. 加权轮询(Weighted Round Robbin)
@@ -40,7 +40,7 @@ PDF制作github: https://github.com/sjsdfg/CS-Notes-PDF
例如下图中,服务器 1 被赋予的权值为 5,服务器 2 被赋予的权值为 1,那么 (1, 2, 3, 4, 5) 请求会被发送到服务器 1,(6) 请求会被发送到服务器 2。
-
+
### 3. 最少连接(least Connections)
@@ -48,27 +48,25 @@ PDF制作github: https://github.com/sjsdfg/CS-Notes-PDF
例如下图中,(1, 3, 5) 请求会被发送到服务器 1,但是 (1, 3) 很快就断开连接,此时只有 (5) 请求连接服务器 1;(2, 4, 6) 请求被发送到服务器 2,只有 (2) 的连接断开,此时 (6, 4) 请求连接服务器 2。该系统继续运行时,服务器 2 会承担过大的负载。
-
+
最少连接算法就是将请求发送给当前最少连接数的服务器上。
例如下图中,服务器 1 当前连接数最小,那么新到来的请求 6 就会被发送到服务器 1 上。
-
+
### 4. 加权最少连接(Weighted Least Connection)
在最少连接的基础上,根据服务器的性能为每台服务器分配权重,再根据权重计算出每台服务器能处理的连接数。
-
-
### 5. 随机算法(Random)
把请求随机发送到服务器上。
和轮询算法类似,该算法比较适合服务器性能差不多的场景。
-
+
### 6. 源地址哈希法 (IP Hash)
@@ -76,7 +74,7 @@ PDF制作github: https://github.com/sjsdfg/CS-Notes-PDF
可以保证同一 IP 的客户端的请求会转发到同一台服务器上,用来实现会话粘滞(Sticky Session)
-
+
## 转发实现
@@ -91,7 +89,7 @@ HTTP 重定向负载均衡服务器使用某种负载均衡算法计算得到服
该负载均衡转发的缺点比较明显,实际场景中很少使用它。
-
+
### 2. DNS 域名解析
@@ -107,7 +105,7 @@ HTTP 重定向负载均衡服务器使用某种负载均衡算法计算得到服
大型网站基本使用了 DNS 做为第一级负载均衡手段,然后在内部使用其它方式做第二级负载均衡。也就是说,域名解析的结果为内部的负载均衡服务器 IP 地址。
-
+
### 3. 反向代理服务器
@@ -164,7 +162,7 @@ HTTP 重定向负载均衡服务器使用某种负载均衡算法计算得到服
- 当服务器宕机时,将丢失该服务器上的所有 Session。
-
+
## Session Replication
@@ -175,7 +173,7 @@ HTTP 重定向负载均衡服务器使用某种负载均衡算法计算得到服
- 占用过多内存;
- 同步过程占用网络带宽以及服务器处理器时间。
-
+
## Session Server
@@ -189,7 +187,7 @@ HTTP 重定向负载均衡服务器使用某种负载均衡算法计算得到服
- 需要去实现存取 Session 的代码。
-
+
参考:





























































































































































































































































