In this blog, I will share my experience with data pre-processing, what is meant by data pre-processing and why we need it, how I encountered many unknown errors in making models with large data, and will show all images of my errors through which you can understand the need for data pre-processing.
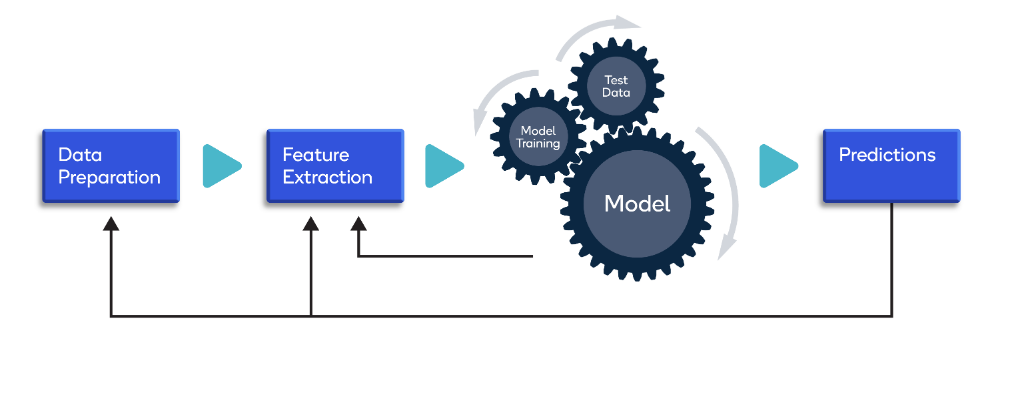
The method of converting raw data into useful data, that can be used further to analyze or predict.

{kind=link}
-
Making data consistent - It means removing the duplicate data during preprocessing which makes data consistent for further analysis.
-
Improving accuracy - As pre-processing removes missing or inconsistent data which results in improved accuracy of the dataset.
In my dataset(10k+ data with dtype=float32) has some of the data '-inf' as their values.

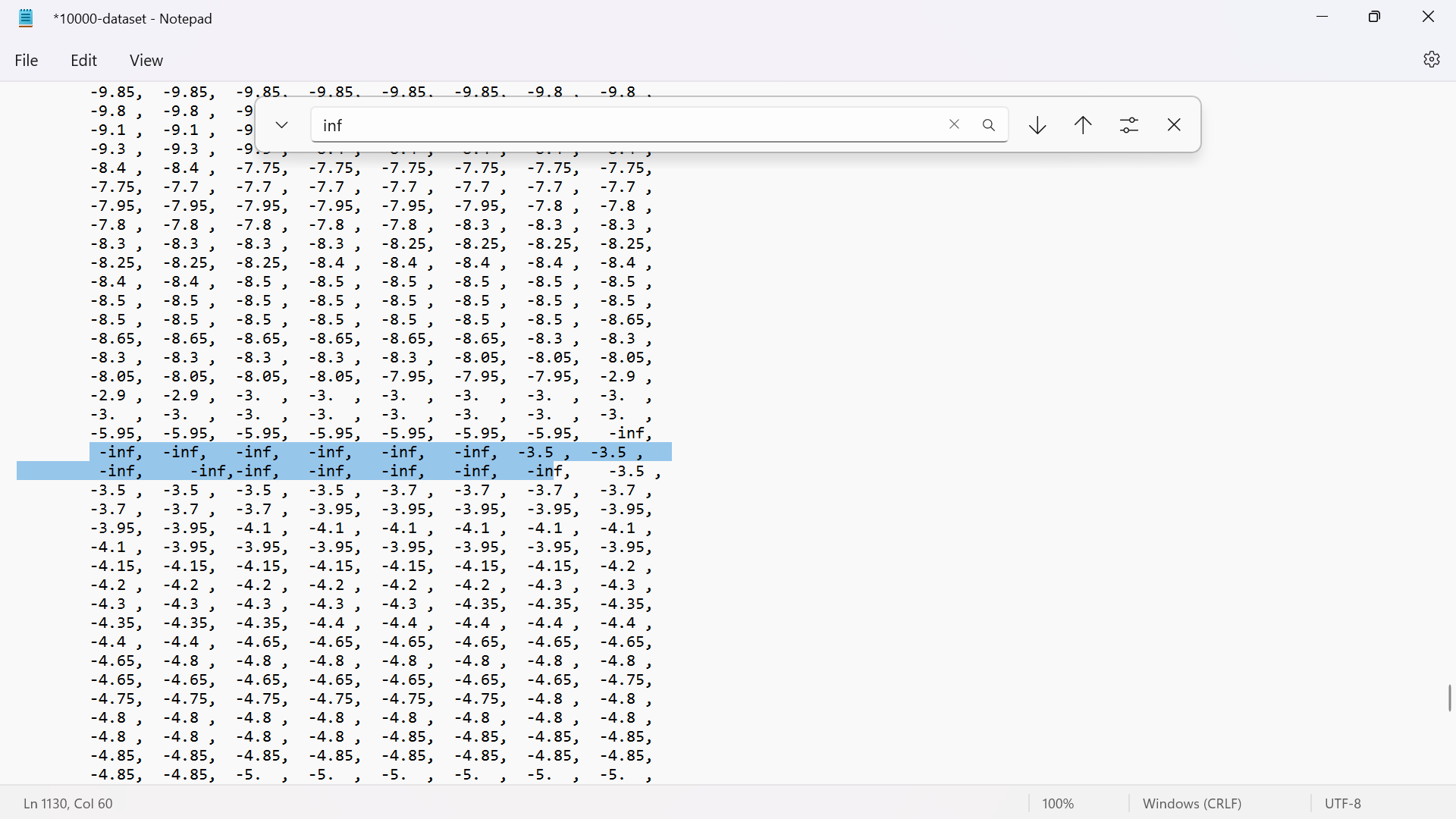{kind=link}
which results in mse(mean square error) loss as 'nan' and accuracy as 0.00 .

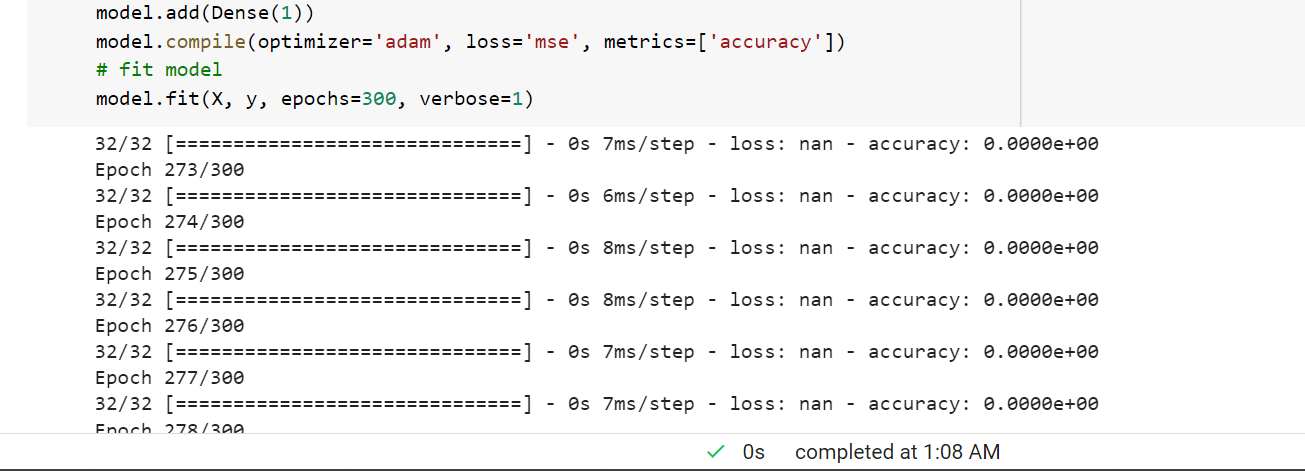{kind=link}
At the start, I was not aware why it was showing loss and accuracy like this(nan and 0.00), so I started to decrease the dataset and tried with a dataset of 100 values which of course will not make a good model but can point out the error behind 'nan' loss and 0.00 accuracy.
Fortunately, I pointed out that this 100-value dataset has not any value as '-inf', as it was present in other parts of the whole dataset, and with those 100-data I found the output, it was successful with very less accuracy. Through this experiment I again preprocessed the whole dataset(10k+) with the replacement of '-inf' as 0, to test the results.
Removing these missing values with an appropriate value, I found this result-

{kind=link}
don't just look at numbers as they aren't pointing at a good model but I got rid of 'nan' loss and 0.00 accuracy. Upon model, I'm still working.