character limit hit, move here for the next version, this will no longer be updated: https://rentry.org/sdupdates2
!!! danger Warnings:
1. Ckpts/hypernetworks/embeddings are ==not== interently safe as of right now. They can be pickled/contain malicious code. Use your common sense and protect yourself as you would with any random download link you would see on the internet.
2. Monitor your GPU temps and increase cooling and/or undervolt them if you need to. There have been claims of GPU issues due to high temps.
!!! Links are dying. If you happen to have a file listed in https://rentry.org/sdupdates#deadmissing or that's not on this list, please get it to me.
!!! info There is now a github for this rentry: https://github.com/questianon/sdupdates. This should allow you to see changes across the different updates. There is also a WIP embedding directory here: https://github.com/questianon/sdupdates/wiki
!!! note If you know how to do stuff in markdown and html/can make a webpage easily/want to contribute in any way, contact me
- News: https://rentry.org/sdupdates#newsfeed
- Prompting: https://rentry.org/sdupdates#prompting
- Models, Embeddings, and Hypernetworks: https://rentry.org/sdupdates#models-embeddings-and-hypernetworks
- Embeddings: https://rentry.org/sdupdates#embeddings
- Hypernetworks: https://rentry.org/sdupdates#hypernetworks
- Aesthetic Gradients: https://rentry.org/sdupdates#aesthetic-gradients
- Models, embeds, and hypernetworks that might be sus: https://rentry.org/sdupdates#polar-resources
- DEAD/MISSING: https://rentry.org/sdupdates#deadmissing
- Training: https://rentry.org/sdupdates#training
- Datasets: https://rentry.org/sdupdates#datasets
- FAQ: https://rentry.org/sdupdates#common-questions-ctrlcmd-f
- Link Dump: https://rentry.org/sdupdates#rentrys-link-dump-will-sort
- Confirmed Drama: https://rentry.org/sdupdates#confirmed-drama
- Unconfirmed Drama: https://rentry.org/sdupdates#unconfirmed-drama
- Fed Bait Information: https://rentry.org/sdupdates#fed-bait-information
- Hall of Fame: https://rentry.org/sdupdates#hall-of-fame
- Miscellaneous: https://rentry.org/sdupdates#misc
- Github: https://github.com/questianon/sdupdates/
!!! note Don't forget to git pull to get a lot of new optimizations + updates, if SD breaks go backward in commits until it starts working again
Instructions:
* If on Windows:
1. go to the webui directory
2. git pull
3. pip -r install requirements.txt
* If on Linux:
1. go to the webui directory
2. source ./venv/bin/activate
a. if this doesn't work, run python -m venv venv beforehand
3. git pull
4. pip -r install requirements.txt
10/31
- You might be able to get more performance on windows by disabling hardware scheduling
- New inpainting options added
- Extensions manager added for AUTOMATIC1111's webui
- Pixiv adding AI art filter: https://www.pixiv.net/info.php?id=8729
- VAE selector PR: AUTOMATIC1111/stable-diffusion-webui#3986
- Open sourced, AI-powered creator released
- https://github.com/carefree0910/carefree-creator#webui--local-deployment
- Can run local and through their servers
- Copied from their github:
- An infinite draw board for you to save, review and edit all your creations.
- Almost EVERY feature about Stable Diffusion (txt2img, img2img, sketch2img, variations, outpainting, circular/tiling textures, sharing, ...).
- Many useful image editing methods (super resolution, inpainting, ...).
- Integrations of different Stable Diffusion versions (waifu diffusion, ...).
- GPU RAM optimizations, which makes it possible to enjoy these features with an NVIDIA GeForce GTX 1080 Ti
- ERNIE-ViLG 2.0 (new open source text to image generator developed by Baidu): https://arxiv.org/abs/2210.15257
- https://github.com/PaddlePaddle/ERNIE
- Supposedly has benefits over SD?
- (old news) Google AI video showcase: https://imagen.research.google/video/
- (old news) Facebook Img2video: https://makeavideo.studio/
- (Info by anon) A look into better trainings: https://arxiv.org/pdf/2210.15257.pdf
train multiple denoisers, use one for the starting few steps to form rough shapes, use one for the last few steps to finalize detail while training, use a image classifier to mark regions corresponding to subjects in the text descriptor. If text descriptor doesn't exist, add it to the prompt modify attention function to increase the attention weight between subjects found by the classifier modify loss function to give regions marked by the classifier more weight
- PaintHua.com - New GUI focusing on Inpainting and Outpainting
- Training a TI on 6gb: https://pastebin.com/iFwvy5Gy
- Have xformers enabled.
This diff does 2 things.
- enables cross attention optimizations during TI training. Voldy disabled the optimizations during training because he said it gave him bad results. However, if you use the InvokeAI optimization or xformers after the xformers fix it does not give you bad results anymore. This saves around 1.5GB vram with xformers
>2. unloads vae from VRAM during training. This is done in hypernetworks, and idk why it wasn't in the code for TI. It doesn't break anything and doesn't make anything worse.
>This saves around .2 GB VRAM
>
>After you apply this, turn on Move VAE and CLIP to RAM and Use cross attention optimizations while training
- Google AI demonstration: https://youtu.be/YxmAQiiHOkA
- Deconvolution and Checkerboard Artifacts: https://distill.pub/2016/deconv-checkerboard/
10/30
- (oldish news) Mubert, text to music released: https://github.com/MubertAI/Mubert-Text-to-Music
- app to listen: https://apps.apple.com/app/apple-store/id1154429580
- search for music: https://mubert.com/render
- Huggingface demo: https://huggingface.co/spaces/Mubert/Text-to-Music
- Stable diffusion "deepfake" (good with few keyframes)
- Git pull for some updates
- Hypernetwork training fixed (continuing training off old checkpoints for HNs and embeds is still broken)
- shrink the size of ckpts and grow them back to their original size: https://github.com/bmaltais/dehydrate
- not sure if safe, but it seems to work
- Blender camera animations to deforum released: https://github.com/micwalk/blender-export-diffusion
- New Windows based Dreambooth solution with Adam8bit support (should run on 8gb and 12gb cards): https://github.com/bmaltais/kohya_ss
- instructions: https://note.com/kohya_ss/n/n61c581aca19b
- new, so not sure if pickled
- Img2music (fun): https://huggingface.co/spaces/fffiloni/img-to-music
- GUI helper for manual tagging and cropping released: https://github.com/arenatemp/sd-tagging-helper
- Dreambooth PR: AUTOMATIC1111/stable-diffusion-webui#3995
- Video diffusion models: https://video-diffusion.github.io/
- Dataset shuffling should be fixed now so that it actually shuffles.
10/29
- SD multiplayer: https://huggingface.co/spaces/huggingface-projects/stable-diffusion-multiplayer
- kind of like r/place
- Big inpainting updated released (composition stays the same but style changes)
- Unreal engine 5 plugin released
- Hires broken on the latest commit
- (old news) new hypernetwork training added
10/28
- Largest Korean hypernetwork/embedding sharing forum post with a ton of hypernetworks/embeddings + images (highly recommended)
- https://arca.live/b/hypernetworks/60940948
- has an English explanation of some stuff at the top
- koreanon requests for good embeddings to be posted in the comments with artist name
Rumor on /g/ that AUTOMATIC1111 was conscripted into the russian armyFalse rumor, AUTOMATIC1111 said that he's fine and is just resting from Stable Diffusion and will probably:- work on PRs soon
- "make a tab for extensions for list and easy install from URL"
- Custom poseable doll released
- Note for training: You can set a learning rate of "0.1:500, 0.01:1000, 0.001:10000" in textual inversion and it will follow the schedule
- Parseq released
- parameter sequencer
- "Generate videos with tight control and flexible interpolation over many Stable Diffusion parameters (such as seed, scale, prompt weights, denoising strength...), as well as input processing parameter (such as zoom, pan, 3D rotation...)"
- https://github.com/rewbs/sd-parseq
- Img2tiles script released
- Stable Diffusion Prompt Book released
- Organized by openart.ai in collab with PublicPrompts (https://publicprompts.art/)
- https://bit.ly/PromptBook
- https://openart.ai/promptbook
- https://www.reddit.com/r/StableDiffusion/comments/yfm8go/im_glad_to_announce_the_release_of_the_stable/
- AI Pictionary released
- CIO statement from a few days ago
- (old news) Imagic running with Stable Diffusion
- (old news) government letter to Stability AI: https://eshoo.house.gov/sites/eshoo.house.gov/files/9.20.22LettertoNSCandOSTPonStabilityAI.pdf
- (old news) Deviant Art CEO supports ai (?)
- https://www.deviantart.com/wannabby, check their posts about AI
- (old news) imagic: img2img but better
10/27
- hypernetwork training is currently broken (unsure if fixed now)
10/26
- Created https://github.com/questianon/sdupdates
- Rentry backup for now
- Features people might like:
- Commit history so you know what's new
- Watch so you can get notifications
- The formatting might be nicer
- New generative models, supposedly faster than diffusers
- https://github.com/Newbeeer/Poisson_flow
- More info: https://www.assemblyai.com/blog/an-introduction-to-poisson-flow-generative-models/
- electrodynamics inspired (the current diffusion model is thermodynamics/statistical physics inspired)
- 10-20x faster
- https://colab.research.google.com/drive/1neY6OovzZELul9t2OTdThUitptNVnuHR?usp=sharing
- Automatic1111's webui supports subfolders and symlinks
- saves space + allows for organization
- https://www.reddit.com/r/StableDiffusion/comments/ye2fwh/tip_automatic1111_supports_model_subfolders/
- Stable Diffusion plugin for Krita and Photoshop (not much info, so not sure if safe)
10/21 - 10/25 (big news bolded, big thanks to asuka-test-imgur-anon-who-also-made-the-speedrun-tutorial for some info)
- Latest git pull can break SD (windows)
- AUTOMATIC1111/stable-diffusion-webui#3688
- update with "git pull origin master" instead of "git pull" until the branch is deleted on the github side
- gaming cock flower arrangement club (Japanese lore)
- Deforum (video animation) extension released
- Many new VAE's (finetunes) released
- Check https://rentry.org/sdmodels for most of them
- NovelAI explanation of all their implemations
- Infinite outpainting: https://github.com/lkwq007/stablediffusion-infinity
- Safer pickleless (unpickleable) format, still needs to be implemented
- https://github.com/huggingface/safetensors
- "This repository implements a new simple format for storing tensors safely (as opposed to pickle) and that is still fast (zero-copy)."
- Temp folder storing generations, space issues (might be fixed now)
- Dreambooth training (now with gui https://github.com/smy20011/dreambooth-gui ), referenced via prompt (?)
- Guided inpainting (video inpainting with keyframes)
- If you build Hydrus from source, someone made a fork to import the tags and other metadata automatically.
- AUTOMATIC1111's history tab now an extension:
- Imagic Stable Diffusion training in 11 GB VRAM
- Interpolate script for AUTOMATIC1111's webui
- Text2LIVE: Text-Driven Layered Image and Video Editing
- AUTOMATIC1111's webui has an api
- StabilityAI released a new VAE
- Improves eyes, hands, colors, and img2img
- https://huggingface.co/stabilityai
- Tutorial + how to use on ALL models (applies for the NAI vae too): https://www.reddit.com/r/StableDiffusion/comments/yaknek/you_can_use_the_new_vae_on_old_models_as_well_for/
- Aesthetic Gradients released
- voldy's announcement https://desuarchive.org/g/thread/89343235/#89345163
- breakdown of new interface https://desuarchive.org/g/thread/89343235/#89345258
- more explanation https://desuarchive.org/g/thread/89343235/#89345322
- https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Extensions
- https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients
- Lama Cleaner released with v1.5 support
- https://github.com/Sanster/lama-cleaner
- Good at watermark removal
- https://www.reddit.com/r/StableDiffusion/comments/y90hzz/lama_cleaner_add_runwaysd15inpainting_support_the
- Mini tutorial in the comments
- Dance Diffusion (AI Music) released by HarmonAI
- Discord: https://discord.gg/MunJTXwk
- AI Music by Google
- 8-10gb Dreambooth for AUTOMATIC1111's webui WIP
- hlky’s/sd-webui rebranded as Sygil.dev
- Working on Project Nataili, a common Standard Diffusion backend
- Goal is to centralize all resources
- https://www.reddit.com/r/StableDiffusion/comments/yd5p5s/hlkyssdwebui_announcing_sygildev_project_nataili/
- visualise.ai
- Account required
- Free unlimited 512x512/64 step runs
- Optimized dreambooth
- train under 10 minutes without class images on multiple subjects, retrainable-ish model
- Tutorial: https://www.reddit.com/r/StableDiffusion/comments/yd9oks/new_simple_dreambooth_method_is_out_train_under/
- Github: https://github.com/TheLastBen/fast-stable-diffusion
- Many sites banned AI art
- Hypernetwork structures added
- more numbers = more vram needed = deeper hypernetwork = better results (?)
- Deep hypernetworks are suited for training with large datasets
- Waifu Diffusion 1.4 roadmap:
- https://gist.github.com/harubaru/313eec09026bb4090f4939d01f79a7e7
- Release date: December 1
- Discord: https://discord.gg/SqrKhArt
- Extensions added to AUTOMATIC1111's webui
- Test embeddings before you download them
- UMI AI, a wildcard engine, released
- Free
- Tutorial: https://www.patreon.com/posts/umi-ai-official-73544634
- Discord (SFW and NSFW): https://discord.gg/9K7j7DTfG2
- More info in https://rentry.org/sdupdates#prompting
- 3D AI stuff
- Pose Estimation
10/20
- SD v1.5 released by RunwayML
- Uncensored, legitimate 1.5
- Huggingface: https://huggingface.co/runwayml/stable-diffusion-v1-5
- Tweet: https://twitter.com/runwayml/status/1583109275643105280
- https://nitter.it/runwayml/status/1583109275643105280#m
- https://rentry.org/sdmodels
- Reddit thread: https://www.reddit.com/r/StableDiffusion/comments/y91pp7/stable_diffusion_v15/
- Drama recap: https://www.reddit.com/r/StableDiffusion/comments/y99yb1/a_summary_of_the_most_recent_shortlived_so_far/
- https://rentry.org/sdupdates#confirmed-drama for recap + links
10/19
- Git pull for a lot of new stuff
- theme argument: https://github.com/AUTOMATIC1111/stable-diffusion-webui/commit/665beebc0825a6fad410c8252f27f6f6f0bd900b
- A lot of optimizations
- Layered hypernetworks
- Time left estimation (if jobs take more than 60 sec)
- Minor UI changes
- Runway released new SD inpainting/outpainting model
- Stability AI event recap
- https://www.reddit.com/r/StableDiffusion/comments/y6v0v9/stability_event_happening_now_news_so_far/
- Animation API next week
- DreamStudio Pro in progress (automatic gen of video from music + latent space exploration)
- will fund 100 PHDs this year
- Their cluster is 4000 A100s on AWS and plans to grow 5x-10x next year
- will reduce price of Dreamstudio by half
- Game universes created with AI: https://twitter.com/Plinz/status/1582202096983498754
- Dreambooth GUI: https://github.com/smy20011/dreambooth-gui
- NAI possibly tinkering with their backend based on tests by touhou anons
- better hands
- Unreal Engine 5 SD plugin: https://github.com/albertotrunk/UE5-Dream
- Underreported: You can highlight a part of your prompt and ctrl + up/down to change weights
10/18
- Clarification on censoring SD's next model by the question asker
- https://rentry.org/sdupdates#confirmed-drama
- TLDR: SD will probably release a censored model before releasing their 1.5 model because of legal issues (like with CP)
10/17
- $101 million in funding from Stability AI for opensource and free AI
- xformers degrading quality
- AUTOMATIC1111/stable-diffusion-webui#2967
- It's a bug that causes the variance with --xformers
- New trinart model
- Discovered hi-res generations are affected by the video card used
- https://desuarchive.org/g/thread/89259005/#89260871
- TLDR: 3000s series are similar, 2000s and 1000s will vary
10/16
- Remote code execution exploit discovered 2 days ago
-
AUTOMATIC pushed an update to deal with this. Use the hide_ui_dir_config if you plan on using --share after updating. Set a password.
-
Gradio fix in progress: gradio-app/gradio#2470
-
https://www.reddit.com/r/StableDiffusion/comments/y56qb9/security_warning_do_not_use_share_in/
-
- Deforum script released for AUTOMATIC1111's webui
- Google open sourced their prompt-to-prompt method
10/15
- Embeddings now shareable via images
- No need to download .pt files anymore
- To use, finish training an embedding, download the image of the embedding (the one with the circles at the edges), and place it in your embeddings folder. The name at the top of the image is the name you use to call the embedding.
- https://www.reddit.com/r/StableDiffusion/comments/y4tmzo/auto1111_new_shareable_embeddings_as_images/
- Example (2nd and 3rd image): https://www.reddit.com/gallery/y4tmzo
- Stability AI update pipeline (https://www.reddit.com/r/StableDiffusion/comments/y2x51n/the_stability_ai_pipeline_summarized_including/)
- This week:
- Updates to CLIP (not sure about the specifics, I assume the output will be closer to the prompt)
- Clip-guidance comes out open source (supposedly)
- Next week:
- DNA Diffusion (applying generative diffusion models to genetics)
- A diffusion based upscaler ("quite snazzy")
- A new decoding architecture for better human faces ("and other elements")
- Dreamstudio credit pricing adjustment (cheaper, that is more options with credits)
- Discord bot open sourcing
- Before the end of the year:
- Text to Video ("better" than Meta's recent work)
- LibreFold (most advanced protein folding prediction in the world, better than Alphafold, with Havard and UCL teams)
- "A ton" of partnerships to be announced for "converting closed source AI companies into open source AI companies"
- (Potentially) CodeCARP, Code generation model from Stability umbrella team Carper AI (currently training)
- (Potentially) Gyarados (Refined user preference prediction for generated content by Carper AI, currently training)
- (Potentially) CHEESE (some sort of platform for user preference prediction for generated content)
- (Potentially) Dance Diffusion, generative audio architecture from Stability umbrella project HarmonAI (there is already a colab for it and some training going on i think)
- This week:
- Animation Stable Diffusion:
- Stable Diffusion in Blender
- https://airender.gumroad.com/l/ai-render
- Uses Dreamstudio for now
- DreamStudio will now use CLIP guidance
- Stable Diffusion running on iPhone
- Cycle Diffusion: https://github.com/ChenWu98/cycle-diffusion
- txt2img > img2img editors, look at github to see examples
- Information about difference merging added to FAQ
- Distributed model training planned
- SD Training Labs server
- Gradio updated
- Optimized, increased speeds
- Git pulling should be safe
10/14
- Fed bait claims
- You can generate forever by right clicking on the generate button
- Can now load checkpoint, clip skip, and hypernet from infotext for AUTO's webui
- Advanced Prompt Tuning, minimizes prompt typing and optimzes output quality
- https://github.com/7eu7d7/APT-stable-diffusion-auto-prompt
- planned to be PR on AUTO's repo once updated
- 3D photo inpainting
- Beginner's guide released:
- New method for merging models on AUTOMATIC1111's UI
- Double model merging + difference merging using a third model
10/13
- Emad QnA Summary
- Image animation
- Motion Diffusion available (text to a video of human motion)
- Text to video available for everyone
- VR SD in the works
- Emad's statement on censoring SAI's next model: https://desuarchive.org/g/thread/89182040#89182584
- NSFW model is hard to train right now, meaning the next release will have:
- No more nudity
- Violence allowed
- Opt-out tool coming for artists who do not want their art to be trained
- NSFW model is hard to train right now, meaning the next release will have:
- New method for training styles that doesn't require as many computing resources
- Method for faster and low step count generations
10/12
- StabilityAI is only releasing SFW models from now on
10/11
- Training embeddings and hypernetworks are possible on --medvram now
- Easy to setup local booru by booru anon, might be pickled (NOW OPEN SOURCE, HIGHLY RECOMMENDED): https://github.com/demibit/stable-toolkit
- Planned to be open source in about a week
- Can now train hypernetworks, git pull and find it in the textual inversion tab
- Sample (bigrbear): https://files.catbox.moe/wbt30i.pt
- Anon (might be wrong): xformers now works on a lot of cards natively, try a clean install with --xformers
- Early Anime Video Generation, trained by dep
10/10
- New unpickler for new ckpts: https://rentry.org/safeunpickle2
HENTAI DIFFUSION MIGHT HAVE A VIRUSconfirmed to be safe by some kind people- github taken down because of nude preview images, hf files taken down because of complaints, windows defender false positive, some kind anons scanned the files with a pickle scanner and and it came back safe
- automatic's repo has security checks for pickles
- anon scanned with a "straced-container", safe
- NAI's euler A is now implemented in AUTOMATIC1111's build
- git pull to access
- New open-source (?) generation method revealed making good images in 4 steps
- Supposedly only 64x64, might be wrong
- Discovered that hypernetworks were meant to create anime using the default SD model
10/9
- Full NAI frontend + backend implementation: https://desuarchive.org/g/thread/89095460#89097704 (PICKLE??, careful might actually be pickled)
- 1:1 recreation, is NAI ran locally (offline NAI)
- 8GB VRAM required
- has danbooru tag suggestions, past generation history, and mobile support (from anon)
- Unlimited prompt tokens
- NAI 1:1 Recreation for Euler (ASUKA, https://desuarchive.org/g/thread/89097837#89098634 https://boards.4chan.org/h/thread/6887840#p6888020)
- detailed setup guide: AUTOMATIC1111/stable-diffusion-webui#2017
- xformers working for 30s series and up, anything below needs tinkering (https://rentry.org/25i6yn)
- Use --xformers to enable for 30s series, --force-enable-xformers for others
- Deepdanbooru integrated: Use --deepdanbooru as an argument to webui-user.bat and find the interrogation change in img2img
- CLIP layer thing integrated, check settings after update
- v2.pt working
- VAE working
- Full models working
Google Docs with a prompt list/ranking/general info for waifu creation: https://docs.google.com/document/d/1Vw-OCUKNJHKZi7chUtjpDEIus112XBVSYHIATKi1q7s/edit?usp=sharing Anon's prompt collection: https://mega.nz/folder/VHwF1Yga#sJhxeTuPKODgpN5h1ALTQg Tag effects on img: https://pastebin.com/GurXf9a4
- Anon says that "8k, 4k, (highres:1.1), best quality, (masterpiece:1.3)" leads to nice details
Japanese prompt collection: http://yaraon-blog.com/archives/225884 GREAT CHINESE TOME OF PROMPTING KNOWLEDGE AND WISDOM 101 GUIDE: https://docs.qq.com/doc/DWHl3am5Zb05QbGVs
- Site: https://aiguidebook.top/
- Backup: https://www105.zippyshare.com/v/lUYn1pXB/file.html
- translated + download: https://mega.nz/folder/MssgiRoT#enJklumlGk1KDEY_2o-ViA
- another backup? https://note.com/sa1p/n/ne71c846326ac
GREAT CHINESE SCROLLS OF PROMPTING ON 1.5: HEIGHTENED LEVELS OF KNOWLEDGE AND WISDOM 101: https://docs.qq.com/doc/DWGh4QnZBVlJYRkly GREAT CHINESE ENCYCLOPEDIA OF PROMPTING ON GENERAL KNOWLEDGE: SPOOKY EDITION: https://docs.qq.com/doc/DWEpNdERNbnBRZWNL GREAT JAPANESE TOME OF MASTERMINDING ANIME PROMPTS AND IMAGINATIVE AI MACHINATIONS 101 GUIDE https://p1atdev.notion.site/021f27001f37435aacf3c84f2bc093b5?p=f9d8c61c4ed8471a9ca0d701d80f9e28
- author: https://twitter.com/p1atdev_art/ Japenese wiki: https://seesaawiki.jp/nai_ch/d/
Database of prompts: https://publicprompts.art/
Krea AI prompt database: https://github.com/krea-ai/open-prompts Prompt search: https://www.ptsearch.info/home/ Another search: http://novelai.io/ 4chan prompt search: https://desuarchive.org/g/search/text/masterpiece%20high%20quality/
Japanese prompt generator: https://magic-generator.herokuapp.com/ Build your prompt (chinese): https://tags.novelai.dev/ NAI Prompts: https://seesaawiki.jp/nai_ch/d/%c8%c7%b8%a2%a5%ad%a5%e3%a5%e9%ba%c6%b8%bd/%a5%a2%a5%cb%a5%e1%b7%cf
Japanese wiki: https://seesaawiki.jp/nai_ch/ Korean wiki: https://arca.live/b/aiart/60392904 Korean wiki 2: https://arca.live/b/aiart/60466181
NAI to webui translator (not 100% accurate): https://seesaawiki.jp/nai_ch/d/%a5%d7%a5%ed%a5%f3%a5%d7%a5%c8%ca%d1%b4%b9
Tip Dump: https://rentry.org/robs-novel-ai-tips Tips: https://github.com/TravelingRobot/NAI_Community_Research/wiki/NAI-Diffusion:-Various-Tips-&-Tricks Info dump of tips: https://rentry.org/Learnings Outdated guide: https://rentry.co/8vaaa Tip for more photorealism: https://www.reddit.com/r/StableDiffusion/comments/yhn6xx/comment/iuf1uxl/
- TLDR: add noise to your img before img2img
SD 1.4 vs 1.5: https://postimg.cc/gallery/mhvWsnx Model merge comparisons: https://files.catbox.moe/rcxqsi.png
Deep Danbooru: https://github.com/KichangKim/DeepDanbooru Demo: https://huggingface.co/spaces/hysts/DeepDanbooru
Embedding tester: https://huggingface.co/spaces/sd-concepts-library/stable-diffusion-conceptualizer
Collection of Aesthetic Gradients: https://github.com/vicgalle/stable-diffusion-aesthetic-gradients/tree/main/aesthetic_embeddings
Euler vs. Euler A: AUTOMATIC1111/stable-diffusion-webui#2017 (comment)
- Euler: https://cdn.discordapp.com/attachments/1036718343140409354/1036719238607540296/euler.gif
- Euler A: https://cdn.discordapp.com/attachments/1036718343140409354/1036719239018590249/euler_a.gif
Seed hunting:
- By nai speedrun asuka imgur anon:
made something that might help the highres seed/prompt hunters out there. this mimics the "0x0" firstpass calculation and suggests lowres dimensions based on target higheres size. it also shows data about firstpass cropping as well. it's a single file so you can download and use offline. picrel. https://preyx.github.io/sd-scale-calc/ view code and download from https://files.catbox.moe/8ml5et.html for example you can run "firstpass" lowres batches for seed/prompt hunting, then use them in firstpass size to preserve composition when making highres.
Script for tagging (like in NAI) in AUTOMATIC's webui: https://github.com/DominikDoom/a1111-sd-webui-tagcomplete Danbooru Tag Exporter: https://sleazyfork.org/en/scripts/452976-danbooru-tags-select-to-export Another: https://sleazyfork.org/en/scripts/453380-danbooru-tags-select-to-export-edited Tags (latest vers): https://sleazyfork.org/en/scripts/453304-get-booru-tags-edited Basic gelbooru scraper: https://pastebin.com/0yB9s338 UMI AI:
- free
- SFW and NSFW
- Goal: ultimate char-gen
- Tutorial: https://www.patreon.com/posts/umi-ai-official-73544634
- Why you should use it: https://www.patreon.com/posts/umi-ai-ultimate-73560593
- Examples:
- Straddling Sluts random prompt:
https://i.imgur.com/eDpRdjj.png https://i.imgur.com/1mZ0u6q.png https://i.imgur.com/cOjwAMm.png
- Cocksucking Cunts prompt.
https://i.imgur.com/GdVCZuV.png https://i.imgur.com/i5WTTB5.png https://i.imgur.com/xj3mp8V.png
- Bedded Bitches prompt.
https://i.imgur.com/urwxn6S.png https://i.imgur.com/5gfC1oP.png
- Oneshot H-Manga prompt.
https://i.imgur.com/oBec2uO.jpeg https://i.imgur.com/UiWYTgr.jpeg https://i.imgur.com/GuhU0Kz.jpeg
- Discord: https://discord.gg/9K7j7DTfG2
- Author is looking for help filling out and improving wildcards
- Ex: https://cdn.discordapp.com/attachments/1032201089929453578/1034546970179674122/Popular_Female_Characters.txt
- Author: Klokinator#0278
- Looking for wildcards with traits and tags of characters
- Planned updates
- Code will get cleaned up
- the 'species' are rudimentary rn but stuff like 'superior slimegirls' are the direction I want to head with species moving forward
- the genders are still unigender, but I'll be separating m/f very soon
- and finally, I just need to add shitloads more content and scenarios
- Code: https://github.com/Klokinator/UnivAICharGen/
Random Prompts: https://rentry.org/randomprompts Python script of generating random NSFW prompts: https://rentry.org/nsfw-random-prompt-gen Prompt randomizer: https://github.com/adieyal/sd-dynamic-prompting Prompt generator: https://github.com/h-a-te/prompt_generator
- apparently UMI uses these?
http://dalle2-prompt-generator.s3-website-us-west-2.amazonaws.com/ https://randomwordgenerator.com/ funny prompt gen that surprisingly works: https://www.grc.com/passwords.htm Unprompted extension released: https://github.com/ThereforeGames/unprompted
- Wildcards on steroids
- Powerful scripting language
- Can create templates out of booru tags
- Can make shortcodes
- "You can pull text from files, set up your own variables, process text through conditional functions, and so much more "
Ideas for when you have none: https://pentoprint.org/first-line-generator/
PaintHua.com - New GUI focusing on Inpainting and Outpainting
I didn't check the safety of these plugins, but they're open source, so you can check them yourself Photoshop/Krita plugin (free): https://internationaltd.github.io/defuser/ (kinda new and currently only 2 stars on github)
Photoshop: https://github.com/Invary/IvyPhotoshopDiffusion Photoshop plugin (paid, not open source): https://www.flyingdog.de/sd/ Krita plugins (free):
- https://github.com/sddebz/stable-diffusion-krita-plugin (listed in the OP, outdated? dead?)
- https://github.com/Interpause/auto-sd-krita (a fork from above, more improvement)
- https://www.flyingdog.de/sd/en/ (https://github.com/imperator-maximus/stable-diffusion-krita)
GIMP: https://github.com/blueturtleai/gimp-stable-diffusion
Blender: https://github.com/carson-katri/dream-textures https://github.com/benrugg/AI-Render
Script collection: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Custom-Scripts Prompt matrix tutorial: https://gigazine.net/gsc_news/en/20220909-automatic1111-stable-diffusion-webui-prompt-matrix/ Animation Script: https://github.com/amotile/stable-diffusion-studio Animation script 2: https://github.com/Animator-Anon/Animator Video Script: https://github.com/memes-forever/Stable-diffusion-webui-video Masking Script: https://github.com/dfaker/stable-diffusion-webui-cv2-external-masking-script XYZ Grid Script: https://github.com/xrpgame/xyz_plot_script Vector Graphics: https://github.com/GeorgLegato/Txt2Vectorgraphics/blob/main/txt2vectorgfx.py Txt2mask: https://github.com/ThereforeGames/txt2mask Prompt changing scripts:
- https://github.com/yownas/seed_travel
- https://github.com/feffy380/prompt-morph
- https://github.com/EugeoSynthesisThirtyTwo/prompt-interpolation-script-for-sd-webui
- https://github.com/some9000/StylePile
Interpolation script (img2img + txt2img mix): https://github.com/DiceOwl/StableDiffusionStuff
img2tiles script: https://github.com/arcanite24/img2tiles Script for outpainting: https://github.com/TKoestlerx/sdexperiments Img2img animation script: https://github.com/Animator-Anon/Animator/blob/main/animation_v6.py
- Can use in txt2img mode and combine with https://film-net.github.io/ for content aware interpolation
Giffusion tutorial:
>git clone https://github.com/megvii-research/ECCV2022-RIFE
this is my git diff on requirements.txt to work alone side webui python environment
>-torch==1.6.0
>+torch==1.11.0
>-torchvision==0.7.0
>+torchvision==0.12.0
pip3 install -r requirements.txt
the most important part
>download the pretrained HD models and copy them into the same folder as inference_video.py
get ffmpeg for your OS (if you dont have ffmpeg it is good to have besides this app)
>https://ffmpeg.org/download.html
after this need to make sure ffmpeg.exe is in your PATH variable
then i typed
>python inference_video.py --exp=1 --video=1666410530347641.mp4 --fps=60
and it created the mp4 you see (i converted it into webm with this command)
>ffmpeg.exe -i 1666410530347641.mp4 1666410530347641.webm
Example: https://i.4cdn.org/h/1666414810239191.webmImg2img megalist + implementations: AUTOMATIC1111/stable-diffusion-webui#2940
Runway inpaint model: https://huggingface.co/runwayml/stable-diffusion-inpainting Inpainting Tips: https://www.pixiv.net/en/artworks/102083584 Rentry version: https://rentry.org/inpainting-guide-SD
Extensions: Artist inspiration: https://github.com/yfszzx/stable-diffusion-webui-inspiration
- https://huggingface.co/datasets/yfszzx/inspiration
- delete the 0 bytes folders from their dataset zip or you might get an error extracting it
History: https://github.com/yfszzx/stable-diffusion-webui-images-browser Collection + Info: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Extensions Deforum (video animation): https://github.com/deforum-art/deforum-for-automatic1111-webui
- Math: https://docs.google.com/document/d/1pfW1PwbDIuW0cv-dnuyYj1UzPqe23BlSLTJsqazffXM/edit
- Blender camera animations to deforum: https://github.com/micwalk/blender-export-diffusion
- Tutorial: https://www.youtube.com/watch?v=lztn6qLc9UE
Aesthetic Gradients: https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients Aesthetic Scorer: https://github.com/tsngo/stable-diffusion-webui-aesthetic-image-scorer Autocomplete Tags: https://github.com/DominikDoom/a1111-sd-webui-tagcomplete Prompt Randomizer: https://github.com/adieyal/sd-dynamic-prompting Wildcards: https://github.com/AUTOMATIC1111/stable-diffusion-webui-wildcards/
Clip interrogator: https://colab.research.google.com/github/pharmapsychotic/clip-interrogator/blob/main/clip_interrogator.ipynb 2: https://github.com/pharmapsychotic/clip-interrogator
Inpaint guide: https://archived.moe/h/thread/6930399/#6930453
Anon: By request, a very quick inpainting guide:
The key to good inpainting is understanding how "Inpaint at full resolution" actually works. The linked guides are obsolete and old at this. So I will tell you.
Inpaint at full resolution first determines the minimum rectangular box that fits all your mask. Then, it resizes the base image within that box into whatever your setting is for resolution. Note that when inpainting at full resolution, the resolution sliders determine THIS INPAINTING SPACE. In other words, you can inpaint for a 2048 by 2048 pixel image while having your sliders set for 256 by 256 pixels. There are some bugs with inpainting at full resolution with height > width https://pythontechworld.com/issue/automatic1111/stable-diffusion-webui/2524 so my recommendation is to just set it to 512 by 512 always.
Next, whatever is in your base image that would fit into the bounding box is rescaled and put into the inpainting space whose size is determined by your height and width sliders.
The padding for full resolution inpainting option ADDS ADDITIONAL PIXELS FROM THE BASE IMAGE TO YOUR BOUNDING BOX. It is extremely important to set this correctly. Essentially, it adds surrounding context from BEYOND your bounding box to the inpainting space. It MUST be set to a nonzero value if you want to match anything not interior to your mask. Set it very high if you want high context. The total input to the inpainting space is your window.
Next, what happens is essentially an img2img transformation on your window: which is the scaled image taken from the mask + original image bounding box. Set your prompts accordingly! Close-up is a very valuable tag to use in inpainting. Don't include prompts that are only relevant outside your window. DO include prompts that can determine composition within your window EVEN IF THEY AREN'T IN YOUR INPAINTING MASK.
Krita guide by anon:
- Get https://krita.org/en/ https://github.com/Interpause/auto-sd-krita/wiki/Quick-Switch-Using-Existing-AUTOMATIC1111-Install https://github.com/Interpause/auto-sd-krita/wiki/Install-Guide#plugin-installation
- then you can run prompts in th app or pull one in then to inpaint like a boss, you add a new layer https://files.catbox.moe/xy6z32.png
- then use a white brush to brush the bits you want to change https://files.catbox.moe/esdqk7.png
- Turn off the layer off by hitting the eye icon but leave it selected https://files.catbox.moe/wzaiw9.png
- if you set everythign up right you have this section https://files.catbox.moe/n43yrh.png
- type what your after hit inpaint
Positive: Biggest tip: just write what you want. the AI will generally understand and create it
- NAI's default (generally good) positive prompts to add at the beginning of all prompts: masterpiece, best quality
- can swap best for highest, high, etc.
- Group the things that you want that are similar together (e.g. things relating to body type, things relating to clothing, etc.), and put these groups in order of most important to least important
- Anon's order:
the picture's quality the picture's subject their physical appearance their emotion their clothing their pose the picture's setting
- "Anime screencap" creates scenes from an anime
- from anon: to use character (franchise/series/show/etc.), you have to format it as character \(franchise\)
- the tokenizer struggles to parse underscores, ymmv
- img2img -> prompt gets you more consistency
Negative:
- NAI's default (remove "nsfw" if you want nsfw outputs): nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
Tags: https://danbooru.donmai.us/tags Tag Groups: https://danbooru.donmai.us/wiki_pages/tag_groups Most Popular Tags: https://danbooru.donmai.us/tags?commit=Search&search%5Bhide_empty%5D=yes&search%5Border%5D=count
Faces and heads:
Expressions:
Camera Angles:
Hair Styles:
Hands
- Hands: writing "in the style of Serpieri" increased hand quality in SD v1.4
Colors:
Posture
Posing
-
Daz3d
-
faces and heads: http://www.relativitybook.com/CoolStuff/facebank.html
download FaceGen Modeller demo (or """purchase"" full version >/ptg/. the demo is still full featured with a shoopably manageable watermark):
https://facegen.com/modeller_demo.htm
install it, load the .fg files from the first link into the app, or make your own, the app does this easily with 1 or 2 photos. fuck around with the expression/camera angle/lighthing. printscreen or use the app's built-in render if you want custom resolution (File > Image > Custom > Save). use it as a base for img2img outpaint/inpaint.
Locations
Clothes
VAE:
- SD 1.4 Anime styled: https://huggingface.co/hakurei/waifu-diffusion-v1-4/blob/main/vae/kl-f8-anime.ckpt
Sex pose https://litter.catbox.moe/las83s.txt
Booru tag scraping:
- https://sleazyfork.org/en/scripts/451098-get-booru-tags
- script to run in browser, hover over pic in Danbooru and Gelbooru
- https://rentry.org/owmmt
- another script
- https://pastecode.io/s/jexs5p9c
- another script, maybe pickle
- press tilde on dan, gel, e621
- https://textedit.tools/
- if you want an online alternative
- https://github.com/onusai/grab-booru-tags
- works with e621, dev will try to get it to work with rule34.xxx
- https://pastecode.io/s/jexs5p9c
- https://pastecode.io/s/61owr7mz
- Press ] on the page you want the tags from
- Another script: https://pastecode.io/s/q6fpoa8k
- Another: https://pastecode.io/s/t7qg2z67
- Github for scraper: https://github.com/onusai/grab-booru-tags
Wildcards:
-
Guide (ish): https://is2.4chan.org/h/1665343016289442.png
-
A few wildcards: https://cdn.lewd.host/EtbKpD8C.zip
-
https://github.com/Lopyter/stable-soup-prompts/tree/main/wildcards
-
https://github.com/Lopyter/sd-artists-wildcards
- Allows you to split up the artists.csv from Automatic by category
-
Another wildcard script: https://raw.githubusercontent.com/adieyal/sd-dynamic-prompting/main/dynamic_prompting.py
-
wildcardNames.txt generation script: https://files.catbox.moe/c1c4rx.py
-
Another script: https://files.catbox.moe/hvly0p.rar
-
Script: https://gist.github.com/h-a-te/30f4a51afff2564b0cfbdf1e490e9187
-
UMI AI: https://www.patreon.com/posts/umi-ai-official-73544634
-
Wildcard dump:
- faces https://rentry.org/pu8z5
- focus https://rentry.org/rc3dp
- poses https://rentry.org/hkuuk
- times https://rentry.org/izc4u
- views https://rentry.org/pv72o
- Clothing: https://pastebin.com/EyghiB2F
-
Another dump: https://github.com/jtkelm2/stable-diffusion-webui-1/tree/master/scripts/wildcards
-
Big NAI Wildcard List: https://rentry.org/NAIwildcards
-
316 colors list: https://pastebin.com/s4tqKB8r
-
82 colors list: https://pastebin.com/kiSEViGA
-
Backgrounds: https://pastebin.com/FCybuqYW
-
More clothing: https://pastebin.com/DrkG1MRw
-
Dump: https://www.dropbox.com/s/oa451lozzgo7sbl/wildcards.zip?dl=1
-
483 txt files, huge dump (for Danbooru trained models): https://files.catbox.moe/ipqljx.zip
- old 329 version: https://files.catbox.moe/qy6vaf.zip
- old 314 version: https://files.catbox.moe/11s1tn.zip
-
Styles: https://pastebin.com/71HTfsML
-
Word list (small): https://cdn.lewd.host/EtbKpD8C.zip
-
Emotions/expressions: https://pastebin.com/VVnH2b83
-
Clothing: https://pastebin.com/cXxN1fJw
-
More clothing: https://files.catbox.moe/88s7bf.zip
-
Dump: https://www.mediafire.com/file/iceamfawqhn5kvu/wildcards.zip/file
-
Locations: https://pastebin.com/R6ugwd2m
-
Clothing/outfits: https://pastebin.com/Xhhnyfvj
-
Locations: https://pastebin.com/uyDJMnvC
-
Clothes: https://pastebin.com/HaL3rW3j
-
Color (has nouns): https://pastebin.com/GTAaLLnm
-
Artists: https://pastebin.com/1HpNRRJU
-
Animals: https://pastebin.com/aM4PJ2YY
-
Characters: https://files.catbox.moe/xe9qj7.txt
-
Backgrounds: https://pastebin.com/gVue2q8g
-
WIP random h-manga scene generator: https://files.catbox.moe/ukah7u.jpg
-
Collection from https://rentry.org/NAIwildcards: https://files.catbox.moe/s7expb.7z
-
Outfits: https://files.catbox.moe/y75qda.txt
-
Collection: https://cdn.lewd.host/4Ql5bhQD.7z
-
Settings + Minerals: https://pastebin.com/9iznuYvQ
-
Hairstyles: https://pastebin.com/X39Kzxh7
-
Hairstyles 2: https://pastebin.com/bRWu1Xvv
-
subject filewords: https://pastebin.com/XRFhwXj8
-
subject filewords but less emphasis on filewords: https://pastebin.com/LxZGkzj1
-
subject filewords v3: https://pastebin.com/hL4nzEDW
-
Danbooru Poses: https://pastebin.com/RgerA8Ry
-
Character training text template: https://files.catbox.moe/wbat5x.txt
-
Outfits: https://pastebin.com/Z9aHVpEy
-
Danbooru tag group wildcard dump organized into folders: https://files.catbox.moe/hz5mom.zip
- by uploader anon: "I recommend using Dynamic Prompting rather than the normal Wildcards extension. It does everything the Wildcards extension does and then some, * being a thing is especially great and so is |"
-
Poses: https://rentry.org/m9dz6
Wildcard extension: https://github.com/AUTOMATIC1111/stable-diffusion-webui-wildcards/
Some artists (may or may not work with NAI):
-
SD 1.5 artists (might lag your pc): https://docs.google.com/spreadsheets/d/1SRqJ7F_6yHVSOeCi3U82aA448TqEGrUlRrLLZ51abLg/htmlview#
-
pre-modern art: https://www.artrenewal.org/Museum/Search#/
-
SD 1.4 artists: https://rentry.org/artists_sd-v1-4
-
Link list: https://pastebin.com/HD7D6pnh
-
Artist comparison grids: https://files.catbox.moe/y6bff0.rar
-
Artist Comparison: https://reddit.com/r/NovelAi/comments/y879x1/i_made_an_experiment_with_different_artists_here/
-
Site: https://sdartists.app/
-
Comparison: https://imgur.com/a/hTEUmd9
-
Comparison: https://proximacentaurib.notion.site/e28a4f8d97724f14a784a538b8589e7d?v=ab624266c6a44413b42a6c57a41d828c
-
Comparison: https://imgur.com/a/ADPHh9q
-
Extension: https://github.com/yfszzx/stable-diffusion-webui-inspiration
-
Huge comparison of artists (3gb, 90x90 different artist combinations on untampered WD v1.3.)
-
Huge tested list: https://proximacentaurib.notion.site/e28a4f8d97724f14a784a538b8589e7d?v=42948fd8f45c4d47a0edfc4b78937474
-
artists and themes: https://dict.latentspace.observer/
-
SD 1.5 artist study: https://docs.google.com/spreadsheets/d/1SRqJ7F_6yHVSOeCi3U82aA448TqEGrUlRrLLZ51abLg/edit#gid=2005893444
-
Artist comparisons for NAI: https://www.reddit.com/r/NovelAi/comments/y879x1/i_made_an_experiment_with_different_artists_here/
-
Artist rankings: https://www.urania.ai/top-sd-artists
Anon's list of comparisons:
- Stable Diffusion v1.5, Waifu Diffusion v1.3, Trinart it4
- Berry Mix, CLIP 2:
- Berry Mix, CLIP 1:
- Artist + Artist, WD v1.3 (incomplete):
https://mega.nz/file/ACtigCpD#f9zP9h1AU_0_4DPsBnvdhnUYdQmIJMb4pyc6PJ4J-FU
Creating fake animes:
1:1 NAI/Novel AI Cheatsheet:
- 1:1 NAI cheatsheet by anon:
-
Use unpruned/full model
-
Load with ema weights (use .yaml config from base stable-diffusion, set use_ema to true) (minor)
-
Doubles ram
-
Anon: "I copied the one from this path (which is what voldy defaults to if one isn't specified): /repositories/stable-diffusion/configs/stable-diffusion/v1-inference.yaml
And then on line 18 I set use_ema to True, and put that copy into the models folder with the correct name (name of model.yaml)."
-
-
CLIP layer = 2
-
Reset sigma noise / strength to the default value of 1 (no need to use 0.69 / 0.67)
-
Set eta noise seed delta to 31337
-
If using Euler a, eta noise seed delta = 31337
-
If prompt has weights, manually adjust the weight accordingly (voldy uses 1.1, NAI uses 1.05)
-
Use --no-half argument (minor)
-
Adding Variety https://www.reddit.com/r/StableDiffusion/comments/yaziws/how_to_get_more_variety_in_your_ai_images_tutorial/
Photoshop Workflow Example https://www.reddit.com/r/StableDiffusion/comments/wyduk1/show_rstablediffusion_integrating_sd_in_photoshop/
Tips to find a good img
anon: like i mentioned before, if using a non-ancestral sampler such as euler that trends to converge on the same image after a bunch of steps, you can roll seeds with 20 or less steps and very small resolution, then stop when you find a good seed and generate again with higher quality. saves scads of time when trying to make some really complicated 125 token prompt
so get a good image first with 512 rerolls use the same seed but now with highres enabled
Anon's best output settings [txt2img]
Positive: none Negative: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, 3 legs, 3 arms Sampling Steps - 47/51 Euler a Width - 512 normal/768 2 characters or better landscapes Height - 512 normal/768 full body CFG Scale: 12/12,5/18
[img2img]
Positive: complete image/none Negative: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name, 3 legs, weird Sampling Steps - 51 Euler a Width - 512 normal/768 2 characters or better landscapes Height - 512 normal/768 full body CFG Scale: 18 Denoising strength: 0,5/0,68
Anon's workflow: Artist list: https://rentry.org/anime_and_titties Expressions and (STYLE): https://rentry.org/faces-faces-faces
Anon's order: the picture's quality the picture's subject their physical appearance their emotion their clothing their pose the picture's setting
Lazy Prompting
go to *booru of your choice pick an image you really like click tags -> plain editor copypaste to prompt profit
Anon's Refinement Technique:
- generate a picture with the prompt that you want, be very precise. I personally generate pictures that are 512x512 initially.
- once you get a decent picture to come out of the generation, it will be used as the base "sketch" to feed to img2img.
- if you want to, increase the resolution but if you do so set the denoising to about .60
- once you have the resolution you want and everything, keep reprocessing the image with a denoising of about 0.2 - 0.3.
- if something on the image bothers you, work on it in an image editor, for example using a brush of the same colour of the what's adjacent to the detail you want to remove, or if you want to add something (like refining fingers), make sure to use the pencil with a contrasted colour (I generally use black).
- after editing, always reprocess the image with a denoising of about 0.3
- once the result satisfies you enough, use the "R-ESRGAN 4x+ Anime6B" upscaler if you want the image upscaled.
!!! Models, embeddings, and hypernetworks can be pickled. Download at your own risk. Use https://rentry.org/safeunpickle2 to unpickle
Organized list: https://rentry.org/sdmodels RISKY (MAJOR PICKLE WARNING) BUT A LOT OF MODELS HERE: https://bt4g.org/search/.ckpt/1 Collection: https://docs.google.com/spreadsheets/d/1fzsjGDlmbbPEnJWY9V2q5a99ySrK1Rj37sk7YJz8fCc/edit#gid=0 Organized list: https://cyberes.github.io/stable-diffusion-models/
Groups (add more later):
- Waifu Diffusion (https://huggingface.co/hakurei/waifu-diffusion-v1-4)
- Stability AI
- Zeipher (https://ai.zeipher.com/)
Upcoming models:
- Waifu Diffusion v1.4: https://huggingface.co/hakurei/waifu-diffusion-v1-4
Stable Diffusion v1.4
- Torrent: magnet:?xt=urn:btih:3A4A612D75ED088EA542ACAC52F9F45987488D1C&tr=udp://tracker.opentrackr.org:1337
- HuggingFace: https://huggingface.co/CompVis/stable-diffusion-v-1-4-original
- Login required
- Google Drive: https://drive.google.com/file/d/1wHFgl0ivCmIZv88hVZXkb8oy9qCuaBGA/view
Waifu Diffusion VAE (250k images)
- https://huggingface.co/hakurei/waifu-diffusion-v1-4/blob/main/vae/kl-f8-anime.ckpt
- https://twitter.com/haruu1367/status/1579286947519864833
- "finetuned the SD 1.4 vae on a bunch of anime-styled images"
- Supposedly improves eyes and fingers
- To load, rename .ckpt to .vae.pt
Waifu Diffusion v1.3
- https://huggingface.co/hakurei/waifu-diffusion-v1-3
- Click "Files and versions" to view all epochs
- 600,000 high-resolution Danbooru images, 10 Epochs
- Release Notes: https://gist.github.com/harubaru/f727cedacae336d1f7877c4bbe2196e1
Waifu Diffusion v1.2 Pruned Torrent:
magnet:?xt=urn:btih:153590fd7e93ee11d8db951451056c362e3a9150&dn=wd-v1-2-full-ema-pruned.ckpt&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2F9.rarbg.com%3A2810%2Fannounce&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=https%3A%2F%2Fopentracker.i2p.rocks%3A443%2Fannounce&tr=http%3A%2F%2Ftracker.openbittorrent.com%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.torrent.eu.org%3A451%2Fannounce&tr=udp%3A%2F%2Fopen.stealth.si%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.tiny-vps.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fzecircle.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fyahor.ftp.sh%3A6969%2Fannounce&tr=udp%3A%2F%2Fvibe.sleepyinternetfun.xyz%3A1738%2Fannounce&tr=udp%3A%2F%2Fv2.iperson.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fuploads.gamecoast.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker2.dler.org%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker1.bt.moack.co.kr%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.theoks.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.tcp.exchange%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.swateam.org.uk%3A2710%2Fannounce&tr=udp%3A%2F%2Ftracker.publictracker.xyz%3A6969%2Fannounce&tr=http%3A%2F%2Ftracker.bt4g.com%3A2095%2FannounceFull EMA Torrent:
magnet:?xt=urn:btih:f45cecf4e9de86da83a78dd2cccd7f27d5557a52&dn=wd-v1-2-full-ema.ckpt&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2F9.rarbg.com%3A2810%2Fannounce&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=https%3A%2F%2Fopentracker.i2p.rocks%3A443%2Fannounce&tr=http%3A%2F%2Ftracker.openbittorrent.com%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.torrent.eu.org%3A451%2Fannounce&tr=udp%3A%2F%2Fopen.stealth.si%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.tiny-vps.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fzecircle.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fyahor.ftp.sh%3A6969%2Fannounce&tr=udp%3A%2F%2Fvibe.sleepyinternetfun.xyz%3A1738%2Fannounce&tr=udp%3A%2F%2Fv2.iperson.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fuploads.gamecoast.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker2.dler.org%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker1.bt.moack.co.kr%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.theoks.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.tcp.exchange%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.swateam.org.uk%3A2710%2Fannounce&tr=udp%3A%2F%2Ftracker.publictracker.xyz%3A6969%2Fannounce&tr=http%3A%2F%2Ftracker.bt4g.com%3A2095%2FannounceTrinart2
- https://huggingface.co/naclbit/trinart_stable_diffusion_v2/tree/main
- Uses dropouts, 10k more images than Trinart1, new tagging strategy, and trained for longer
Trinart1
- https://huggingface.co/naclbit/trinart_stable_diffusion/tree/main
- 3.5 epochs, 30k images
- Obsolete
gg1342_testrun1_pruned
magnet:?xt=urn:btih:c95e266e15e13cf0e2d69b29338a89a94d736546&dn=gg1342_testrun1_pruned.ckpt&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2F9.rarbg.com%3A2810%2Fannounce&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=https%3A%2F%2Fopentracker.i2p.rocks%3A443%2Fannounce&tr=http%3A%2F%2Ftracker.openbittorrent.com%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.torrent.eu.org%3A451%2Fannounce&tr=udp%3A%2F%2Fopen.stealth.si%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.tiny-vps.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fzecircle.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fyahor.ftp.sh%3A6969%2Fannounce&tr=udp%3A%2F%2Fvibe.sleepyinternetfun.xyz%3A1738%2Fannounce&tr=udp%3A%2F%2Fv2.iperson.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fuploads.gamecoast.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker2.dler.org%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker1.bt.moack.co.kr%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.theoks.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.tcp.exchange%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.swateam.org.uk%3A2710%2Fannounce&tr=udp%3A%2F%2Ftracker.publictracker.xyz%3A6969%2Fannounce&tr=http%3A%2F%2Ftracker.bt4g.com%3A2095%2Fannounce
* 280 NSFW nude solo women + 80 SFW fiction characters
**Hentai Diffusion**
* https://huggingface.co/Deltaadams/Hentai-Diffusion/tree/main
* Based on Waifu Diffusion 1.2, trainede on 150k images from rule34 and gelbooru, focused training on hands and poses
* Updated weekly
**RD1412**
* Pruned FP16
``` python
magnet:?xt=urn:btih:da8986f9059ce4f64f84e7390eb542558b2cd466&dn=RD1412-pruned-fp16.ckpt&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337%2fannounce&tr=udp%3a%2f%2f9.rarbg.com%3a2810%2fannounce&tr=udp%3a%2f%2ftracker.openbittorrent.com%3a6969%2fannounce&tr=http%3a%2f%2ftracker.openbittorrent.com%3a80%2fannounce&tr=udp%3a%2f%2fopentracker.i2p.rocks%3a6969%2fannounce&tr=https%3a%2f%2fopentracker.i2p.rocks%3a443%2fannounce&tr=udp%3a%2f%2fopen.stealth.si%3a80%2fannounce&tr=udp%3a%2f%2ftracker.torrent.eu.org%3a451%2fannounce&tr=udp%3a%2f%2ftracker.tiny-vps.com%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.moeking.me%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.0x.tf%3a6969%2fannounce&tr=udp%3a%2f%2fp4p.arenabg.com%3a1337%2fannounce&tr=udp%3a%2f%2fopen.demonii.com%3a1337%2fannounce&tr=udp%3a%2f%2fmovies.zsw.ca%3a6969%2fannounce&tr=udp%3a%2f%2fipv4.tracker.harry.lu%3a80%2fannounce&tr=udp%3a%2f%2fexplodie.org%3a6969%2fannounce&tr=udp%3a%2f%2fexodus.desync.com%3a6969%2fannounce&tr=udp%3a%2f%2fbt.oiyo.tk%3a6969%2fannounce&tr=https%3a%2f%2ftracker.nanoha.org%3a443%2fannounce&tr=https%3a%2f%2ftracker.lilithraws.org%3a443%2fannounce
- Pruned FP32
magnet:?xt=urn:btih:ab4c2d7308a3fa694f7409407399a1cc5d4c7ed9&dn=RD1412-pruned-fp32.ckpt&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337%2fannounce&tr=udp%3a%2f%2f9.rarbg.com%3a2810%2fannounce&tr=udp%3a%2f%2ftracker.openbittorrent.com%3a6969%2fannounce&tr=http%3a%2f%2ftracker.openbittorrent.com%3a80%2fannounce&tr=udp%3a%2f%2fopentracker.i2p.rocks%3a6969%2fannounce&tr=https%3a%2f%2fopentracker.i2p.rocks%3a443%2fannounce&tr=udp%3a%2f%2fopen.stealth.si%3a80%2fannounce&tr=udp%3a%2f%2ftracker.torrent.eu.org%3a451%2fannounce&tr=udp%3a%2f%2ftracker.tiny-vps.com%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.moeking.me%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.0x.tf%3a6969%2fannounce&tr=udp%3a%2f%2fp4p.arenabg.com%3a1337%2fannounce&tr=udp%3a%2f%2fopen.demonii.com%3a1337%2fannounce&tr=udp%3a%2f%2fmovies.zsw.ca%3a6969%2fannounce&tr=udp%3a%2f%2fipv4.tracker.harry.lu%3a80%2fannounce&tr=udp%3a%2f%2fexplodie.org%3a6969%2fannounce&tr=udp%3a%2f%2fexodus.desync.com%3a6969%2fannounce&tr=udp%3a%2f%2fbt.oiyo.tk%3a6969%2fannounce&tr=https%3a%2f%2ftracker.nanoha.org%3a443%2fannounce&tr=https%3a%2f%2ftracker.lilithraws.org%3a443%2fannounce RD1212
- Pruned FP16
magnet:?xt=urn:btih:f4e78d085169d2077a316bd9b75723812c1ab429&dn=HenDiff_RD1212-pruned-fp16.ckpt&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337%2fannounce&tr=udp%3a%2f%2f9.rarbg.com%3a2810%2fannounce&tr=udp%3a%2f%2ftracker.openbittorrent.com%3a6969%2fannounce&tr=http%3a%2f%2ftracker.openbittorrent.com%3a80%2fannounce&tr=udp%3a%2f%2fopentracker.i2p.rocks%3a6969%2fannounce&tr=https%3a%2f%2fopentracker.i2p.rocks%3a443%2fannounce&tr=udp%3a%2f%2fopen.stealth.si%3a80%2fannounce&tr=udp%3a%2f%2ftracker.torrent.eu.org%3a451%2fannounce&tr=udp%3a%2f%2ftracker.tiny-vps.com%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.moeking.me%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.0x.tf%3a6969%2fannounce&tr=udp%3a%2f%2fp4p.arenabg.com%3a1337%2fannounce&tr=udp%3a%2f%2fopen.demonii.com%3a1337%2fannounce&tr=udp%3a%2f%2fmovies.zsw.ca%3a6969%2fannounce&tr=udp%3a%2f%2fipv4.tracker.harry.lu%3a80%2fannounce&tr=udp%3a%2f%2fexplodie.org%3a6969%2fannounce&tr=udp%3a%2f%2fexodus.desync.com%3a6969%2fannounce&tr=udp%3a%2f%2fbt.oiyo.tk%3a6969%2fannounce&tr=https%3a%2f%2ftracker.nanoha.org%3a443%2fannounce&tr=https%3a%2f%2ftracker.lilithraws.org%3a443%2fannounce- Pruned FP32
magnet:?xt=urn:btih:2a6b60f454dcf89b81e7db034fcb1536b774628c&dn=HenDiff_RD1212-pruned-fp32.ckpt&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337%2fannounce&tr=udp%3a%2f%2f9.rarbg.com%3a2810%2fannounce&tr=udp%3a%2f%2ftracker.openbittorrent.com%3a6969%2fannounce&tr=http%3a%2f%2ftracker.openbittorrent.com%3a80%2fannounce&tr=udp%3a%2f%2fopentracker.i2p.rocks%3a6969%2fannounce&tr=https%3a%2f%2fopentracker.i2p.rocks%3a443%2fannounce&tr=udp%3a%2f%2fopen.stealth.si%3a80%2fannounce&tr=udp%3a%2f%2ftracker.torrent.eu.org%3a451%2fannounce&tr=udp%3a%2f%2ftracker.tiny-vps.com%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.moeking.me%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.0x.tf%3a6969%2fannounce&tr=udp%3a%2f%2fp4p.arenabg.com%3a1337%2fannounce&tr=udp%3a%2f%2fopen.demonii.com%3a1337%2fannounce&tr=udp%3a%2f%2fmovies.zsw.ca%3a6969%2fannounce&tr=udp%3a%2f%2fipv4.tracker.harry.lu%3a80%2fannounce&tr=udp%3a%2f%2fexplodie.org%3a6969%2fannounce&tr=udp%3a%2f%2fexodus.desync.com%3a6969%2fannounce&tr=udp%3a%2f%2fbt.oiyo.tk%3a6969%2fannounce&tr=https%3a%2f%2ftracker.nanoha.org%3a443%2fannounce&tr=https%3a%2f%2ftracker.lilithraws.org%3a443%2fannounce- Full EMA
magnet:?xt=urn:btih:D0B89A0516205157EA0CBDDBBB49BC60C611A3B7&dn=RD1212.ckpt&tr=udp%3a%2f%2ftracker.openbittorrent.com%3a80%2fannounce&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337%2fannounceBare Feet / Full Body b4_t16_noadd
- Focused on bare feet and full body nude female images, good for genitalia and photorealistic feet
- Pruned FP16 v3
magnet:?xt=urn:btih:9530a8a0b43f83366216ab853b4419aa2056da58&dn=bf_fb_v3_t4_b16_noadd-ema-pruned-fp16.ckpt&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337%2fannounce&tr=udp%3a%2f%2f9.rarbg.com%3a2810%2fannounce&tr=udp%3a%2f%2ftracker.openbittorrent.com%3a6969%2fannounce&tr=http%3a%2f%2ftracker.openbittorrent.com%3a80%2fannounce&tr=udp%3a%2f%2fopentracker.i2p.rocks%3a6969%2fannounce&tr=https%3a%2f%2fopentracker.i2p.rocks%3a443%2fannounce&tr=udp%3a%2f%2ftracker.torrent.eu.org%3a451%2fannounce&tr=udp%3a%2f%2ftracker.tiny-vps.com%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.skyts.net%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.pomf.se%3a80%2fannounce&tr=udp%3a%2f%2ftracker.moeking.me%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.dler.org%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.0x.tf%3a6969%2fannounce&tr=udp%3a%2f%2fp4p.arenabg.com%3a1337%2fannounce&tr=udp%3a%2f%2fopen.stealth.si%3a80%2fannounce&tr=udp%3a%2f%2fopen.demonii.com%3a1337%2fannounce&tr=udp%3a%2f%2fmovies.zsw.ca%3a6969%2fannounce&tr=udp%3a%2f%2fexplodie.org%3a6969%2fannounce&tr=udp%3a%2f%2fexodus.desync.com%3a6969%2fannounce&tr=udp%3a%2f%2fbt.oiyo.tk%3a6969%2fannounce- Pruned FP32 v3
magnet:?xt=urn:btih:1f6bab17c548e35ac2a412e3e9119e5f4e00bb50&dn=bf_fb_v3_t4_b16_noadd-ema-pruned-fp32.ckpt&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337%2fannounce&tr=udp%3a%2f%2f9.rarbg.com%3a2810%2fannounce&tr=udp%3a%2f%2ftracker.openbittorrent.com%3a6969%2fannounce&tr=http%3a%2f%2ftracker.openbittorrent.com%3a80%2fannounce&tr=udp%3a%2f%2fopentracker.i2p.rocks%3a6969%2fannounce&tr=https%3a%2f%2fopentracker.i2p.rocks%3a443%2fannounce&tr=udp%3a%2f%2ftracker.torrent.eu.org%3a451%2fannounce&tr=udp%3a%2f%2ftracker.tiny-vps.com%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.skyts.net%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.pomf.se%3a80%2fannounce&tr=udp%3a%2f%2ftracker.moeking.me%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.dler.org%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.0x.tf%3a6969%2fannounce&tr=udp%3a%2f%2fp4p.arenabg.com%3a1337%2fannounce&tr=udp%3a%2f%2fopen.stealth.si%3a80%2fannounce&tr=udp%3a%2f%2fopen.demonii.com%3a1337%2fannounce&tr=udp%3a%2f%2fmovies.zsw.ca%3a6969%2fannounce&tr=udp%3a%2f%2fexplodie.org%3a6969%2fannounce&tr=udp%3a%2f%2fexodus.desync.com%3a6969%2fannounce&tr=udp%3a%2f%2fbt.oiyo.tk%3a6969%2fannounce
Lewd Diffusion
- 70k images from Danbooru, based on Waifu Diffusion 1.2
- Dataset: https://drive.google.com/drive/folders/1f_BYi88LLTZUzBHkUz8PDgw6l7M7swkd?usp=sharing
- Dataset stats: https://docs.google.com/spreadsheets/d/1BzNSXyT4fhiM64DwIJSCyAXuhRQ9fkxqcr-t1frIYkc/edit
- 2 epochs
magnet:?xt=urn:btih:U5RICVYDEJL6LIJJWFKQOIVO5GMGCJNW&dn=last-pruned.ckpt&xl=3852165809&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce
- 1 epoch
magnet:?xt=urn:btih:fca8782a5a9861a6beb1aa3b48938bd1da1a665e&dn=LD-70k-1e-pruned.ckpt&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2F9.rarbg.com%3A2810%2Fannounce&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=https%3A%2F%2Fopentracker.i2p.rocks%3A443%2Fannounce&tr=http%3A%2F%2Ftracker.openbittorrent.com%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.torrent.eu.org%3A451%2Fannounce&tr=udp%3A%2F%2Fopen.stealth.si%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.tiny-vps.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fzecircle.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fyahor.ftp.sh%3A6969%2Fannounce&tr=udp%3A%2F%2Fvibe.sleepyinternetfun.xyz%3A1738%2Fannounce&tr=udp%3A%2F%2Fv2.iperson.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fuploads.gamecoast.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker2.dler.org%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker1.bt.moack.co.kr%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.theoks.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.tcp.exchange%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.swateam.org.uk%3A2710%2Fannounce&tr=udp%3A%2F%2Ftracker.publictracker.xyz%3A6969%2Fannounce&tr=http%3A%2F%2Ftracker.bt4g.com%3A2095%2Fannounce
- 0 epochs, 40k images
magnet:?xt=urn:btih:f6976fbe3b9f93469bb62eb0c4950643b09f1f83&dn=Lewd-diffusion-pruned.ckpt&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2F9.rarbg.com%3A2810%2Fannounce&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=https%3A%2F%2Fopentracker.i2p.rocks%3A443%2Fannounce&tr=http%3A%2F%2Ftracker.openbittorrent.com%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.torrent.eu.org%3A451%2Fannounce&tr=udp%3A%2F%2Fopen.stealth.si%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.tiny-vps.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fzecircle.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fyahor.ftp.sh%3A6969%2Fannounce&tr=udp%3A%2F%2Fvibe.sleepyinternetfun.xyz%3A1738%2Fannounce&tr=udp%3A%2F%2Fv2.iperson.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fuploads.gamecoast.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker2.dler.org%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker1.bt.moack.co.kr%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.theoks.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.tcp.exchange%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.swateam.org.uk%3A2710%2Fannounce&tr=udp%3A%2F%2Ftracker.publictracker.xyz%3A6969%2Fannounce&tr=http%3A%2F%2Ftracker.bt4g.com%3A2095%2Fannounce
Yiffy
- During training explicit was misspelled as explict
- Tags:
- 18 epochs (210k images from e621):
magnet:?xt=urn:btih:b177dd04ae7062b541c82ad26f897e0a9fa514f4&dn=yiffy-e18.ckpt&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337%2fannounce
- 15 epochs (210k images from e621):
magnet:?xt=urn:btih:2b8d5f308244eddf56d4a350df84d63045e65dd6&dn=yiffy-e15.ckpt&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2F9.rarbg.com%3A2810%2Fannounce&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=https%3A%2F%2Fopentracker.i2p.rocks%3A443%2Fannounce&tr=http%3A%2F%2Ftracker.openbittorrent.com%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.torrent.eu.org%3A451%2Fannounce&tr=udp%3A%2F%2Fopen.stealth.si%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.tiny-vps.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fzecircle.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fyahor.ftp.sh%3A6969%2Fannounce&tr=udp%3A%2F%2Fvibe.sleepyinternetfun.xyz%3A1738%2Fannounce&tr=udp%3A%2F%2Fv2.iperson.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fuploads.gamecoast.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker2.dler.org%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker1.bt.moack.co.kr%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.theoks.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.tcp.exchange%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.swateam.org.uk%3A2710%2Fannounce&tr=udp%3A%2F%2Ftracker.publictracker.xyz%3A6969%2Fannounce&tr=http%3A%2F%2Ftracker.bt4g.com%3A2095%2Fannounce
- 13 epochs
- first 4 epochs were trained on ~70k images with lama infilling (the cause of all of our headaches, because the network found a pattern in the edges and started replicating it everywhere)
- next 6 epochs were trained on ~120k images with random cropping and a lower LR
- last epochs were done on a different dataset, not bigger than 150k * https://iwiftp.yerf.org/Furry/Software/Stable%20Diffusion%20Furry%20Finetune%20Models/Finetune%20models/yiffy-e13.ckpt
magnet:?xt=urn:btih:6d749325cbdcf1fc044483fb0d53c233b60735dc&dn=yiffy-e13.ckpt&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2F9.rarbg.com%3A2810%2Fannounce&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=https%3A%2F%2Fopentracker.i2p.rocks%3A443%2Fannounce&tr=http%3A%2F%2Ftracker.openbittorrent.com%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.torrent.eu.org%3A451%2Fannounce&tr=udp%3A%2F%2Fopen.stealth.si%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.tiny-vps.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fzecircle.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fyahor.ftp.sh%3A6969%2Fannounce&tr=udp%3A%2F%2Fvibe.sleepyinternetfun.xyz%3A1738%2Fannounce&tr=udp%3A%2F%2Fv2.iperson.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fuploads.gamecoast.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker2.dler.org%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker1.bt.moack.co.kr%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.theoks.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.tcp.exchange%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.swateam.org.uk%3A2710%2Fannounce&tr=udp%3A%2F%2Ftracker.publictracker.xyz%3A6969%2Fannounce&tr=http%3A%2F%2Ftracker.bt4g.com%3A2095%2Fannounce
Furry
- 300k images from e621
- Tags:
- Epoch 4
magnet:?xt=urn:btih:a9635389ae4c5583b0cc76ec8f6dce35438b3016&dn=furry_epoch4.ckpt&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2F9.rarbg.com%3A2810%2Fannounce&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=https%3A%2F%2Fopentracker.i2p.rocks%3A443%2Fannounce&tr=http%3A%2F%2Ftracker.openbittorrent.com%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.torrent.eu.org%3A451%2Fannounce&tr=udp%3A%2F%2Fopen.stealth.si%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.tiny-vps.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fzecircle.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fyahor.ftp.sh%3A6969%2Fannounce&tr=udp%3A%2F%2Fvibe.sleepyinternetfun.xyz%3A1738%2Fannounce&tr=udp%3A%2F%2Fv2.iperson.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fuploads.gamecoast.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker2.dler.org%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker1.bt.moack.co.kr%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.theoks.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.tcp.exchange%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.swateam.org.uk%3A2710%2Fannounce&tr=udp%3A%2F%2Ftracker.publictracker.xyz%3A6969%2Fannounce&tr=http%3A%2F%2Ftracker.bt4g.com%3A2095%2Fannounce
magnet:?xt=urn:btih:d62bc9a088b206565005cab915a58fd26da1802e&dn=furry_epoch1.ckpt&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2F9.rarbg.com%3A2810%2Fannounce&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=https%3A%2F%2Fopentracker.i2p.rocks%3A443%2Fannounce&tr=http%3A%2F%2Ftracker.openbittorrent.com%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.torrent.eu.org%3A451%2Fannounce&tr=udp%3A%2F%2Fopen.stealth.si%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.tiny-vps.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fzecircle.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fyahor.ftp.sh%3A6969%2Fannounce&tr=udp%3A%2F%2Fvibe.sleepyinternetfun.xyz%3A1738%2Fannounce&tr=udp%3A%2F%2Fv2.iperson.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Fuploads.gamecoast.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker2.dler.org%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker1.bt.moack.co.kr%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.theoks.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.tcp.exchange%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.swateam.org.uk%3A2710%2Fannounce&tr=udp%3A%2F%2Ftracker.publictracker.xyz%3A6969%2Fannounce&tr=http%3A%2F%2Ftracker.bt4g.com%3A2095%2Fannounce
Zack3D_Kinky-v1
- Over 100k images, filtered aesthetics, NSFW, trained on SD v1.4, good for furry, specializes in kinks like transformation, latex, tentacles, goo, ferals, bondage, etc.
- Uses e621 tags with underscores
magnet:?xt=urn:btih:807a71d3ed3f887e41c492cf24fbd3c6f5a81534&dn=Zack3D_Kinky-v1.ckpt&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337%2fannounce&tr=udp%3a%2f%2fopen.tracker.cl%3a1337%2fannounce
Anal Vore AVHumanFurryPony7
- 7 epochs, continued from Zack3D_Kinky-v1
- Tags
Gape Model
Pony Models
Purplesmart.AI's Pony v1: https://mega.nz/file/ZT1xEKgC#Xxir5udMmU_mKaRZAbBkF247Yk7DqCr01V0pDzSlYI0
CookieSD's sfw/nsfw model: https://drive.google.com/drive/folders/14JyQE36wYABH-0TSV_HBEsBJ3r8ZITrS
Pussy Diffusion 10/14 (only use for inpainting)
- trained on sankaku+e621 on gaping_anus,gaping_pussy,large_penetration,fisting, prolapse
- https://gofile.io/d/Viv9CJ
- https://bbs.kfpromax.com/read.php?tid=963487
- 链接: https://pan.baidu.com/s/1sC69cgSTWGuXCY79K5C_DA 提取码: 7qdp
a merged model of 80 NAI 20 TRIN120k
- https://mega nz/file/jB5lwa6J#ciSArZnJQLszvhatiMK2NTKFNjKYUhHJlXt9At3WRss
Berrymix Recipe Rentry: https://rentry.org/berrymix
Make sure you have all the models needed, Novel Ai, Stable Diffusion 1.4, Zeipher F111, and r34_e4. All but Novel Ai can be downloaded from HERE Open the Checkpoint Merger tab in the web ui Set the Primary Model (A) to Novel Ai Set the Secondary Model (B) to Zeipher F111 Set the Tertiary Model (C) to Stable Diffusion 1.4 Enter in a name that you will recognize Set the Multiplier (M) slider all the way to the right, at "1" Select "Add Difference" Click "Run" and wait for the process to complete Now set the Primary Model (A) to the new checkpoint you just made (Close the cmd and restart the webui, then refresh the web page if you have issues with the new checkpoint not being an option in the drop down) Set the Secondary Model (B) to r34_e4 Ignore Tertiary Model (C) (I've tested it, it wont change anything) Enter in the name of the final mix, something like "Berry's Mix" ;) Set Multiplier (M) to "0.25" Select "Weighted Sum" Click "Run" and wait for the process to complete Restart the Web Ui and reload the page just to be safe At the top left of the web page click the "Stable Diffusion Checkpoint" drop down and select the Berry's Mix.ckpt (or whatever you named it) it should have the hash "[c7d3154b]"
-
Berry + Novelai VAE (Might be malicious): https://mega.nz/folder/8HUikarD#epAOm3l2hltC_s_oiSC9dg
-
Another berry + vae: https://anonfiles.com/Rdq7j7F0ye/Berry_zip
-
Dump of ckpt merges, might be pickled, uploader anon says to download at your own risk, could also be a fed bait or something: https://droptext.cc/bfxwb
-
NAI + Tri + Tri:
magnet:?xt=urn:btih:976D8785EA6C067951E3AE5B9A7FD3A0ED9D3DBE&dn=animefull-final-pruned_0.8-trinart2_step115000_0.2-Weighted_Sum-merged_0.9-trinart_characters_it4_v1_0.1-Weighted_sum-merged.ckpt&tr=udp%3a%2f%2ftracker.openbittorrent.com%3a80%2fannounce&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337%2fannounceFruit Salad Mix (might not be worth it to make)
Fruit Salad Guide
Recipe for the "Fruit Salad" checkpoint: Make sure you have all the models needed, Novel Ai, Stable Diffusion 1.5, Trinart-11500, Zeipher F111, r34_e4, Gape_60 and Yiffy. Open the Checkpoint Merger tab in the web ui Set the Primary Model (A) to Novel Ai Set the Secondary Model (B) to Yiffy e18 Set the Tertiary Model (C) to Stable Diffusion 1.4 Enter in a name that you will recognize Set the Multiplier (M) slider to the left, at "0.1698765" Select "Add Difference" Click "Run" and wait for the process to complete Now set the Primary Model (A) to the new checkpoint you just made (Close the cmd and restart the webui, then refresh the web page if you have issues with the new checkpoint not being an option in the drop down) Set the Secondary Model (B) to r34_e4 Set the Tertiary Model (C) to Zeipher F111 (I've tested it, it changes EVERYTHING) Set Multiplier (M) to "0.56565656" Select "Weighted Sum" Click "Run" and wait for the process to complete Restart the Web Ui and reload the page just to be safe Now download a previous version of WebUI, which still contains the "Inverse Sigmoid" option for checkpoint merger. Now set the Primary Model (A) to the new checkpoint you just made Set the Secondary Model (B) to Trinart-11500 Set Multiplier (M) to "0.768932" Select "Inverse Sigmoid"(this is kind of like Sigmoid but inverted) Click "Run" and wait for the process to complete Restart the Web Ui and reload the page just to be safe Now set the Primary Model (A) to the new checkpoint you just made. Set the Secondary Model (B) to SD 1.5 Set the Tertiary Model (C) to Gape_60 Set the name of the final mix to something you will remember, like "Fruit's Salad" ;) Set Multiplier (M) to "1" Select "Weighted Sum" Click "Run" and wait for the process to complete Restart the Web Ui and reload the page just to be safe At the top left of the web page click the "Stable Diffusion Checkpoint" drop down and select the Fruit's Salad.ckpt (or whatever you named it)
-
Older files you need uploaded by anon (which means it might be pickled): https://codeload.github.com/AUTOMATIC1111/stable-diffusion-webui/zip/f7c787eb7c295c27439f4fbdf78c26b8389560be
-
NAI + hypernetworks (uploaded by UMI AI dev, I didn't audit the files myself for changes/pickles):
- DL 1: https://anonfiles.com/U5Acl7F0y2/Novel_AI_Hypernetworks_zip
- DL 2: https://pixeldrain.com/u/FMJ4TQbM
- https://cdn.discordapp.com/attachments/1034551880220672181/1036386279597822082/unknown.png
- https://cdn.discordapp.com/attachments/1034551880220672181/1036386279207731262/unknown.png
- https://cdn.discordapp.com/attachments/1034551880220672181/1036386278813474857/unknown.png
-
Scarlett's Mix (good at cute witches): https://rentry.org/scarlett_mix
-
Mega mixing guide (has a different berry mix): https://rentry.org/lftbl
Links:
-
https://huggingface.co/jinofcoolnes
- For preview pics/descriptions:
-
Toolkit anon: https://huggingface.co/demibit/
-
Big collection: https://publicprompts.art/
-
Big collection of sex models (Might be a large pickle, so be careful): https://rentry.org/kwai
-
Collection: https://cyberes.github.io/stable-diffusion-dreambooth-library/
-
Nami: https://mega.nz/file/VlQk0IzC#8MEhKER_IjoS8zj8POFDm3ZVLHddNG5woOcGdz4bNLc
-
https://huggingface.co/IShallRiseAgain/StudioGhibli/tree/main
-
Jinx: https://huggingface.co/jinofcoolnes/sksjinxmerge/tree/main
-
Arcane Vi: https://huggingface.co/jinofcoolnes/VImodel/tree/main
-
Lucy (Edgerunners): https://huggingface.co/jinofcoolnes/Lucymodel/tree/main
-
Gundam (full ema, non pruned): https://huggingface.co/Gazoche/stable-diffusion-gundam
-
Starsector Portraits: https://huggingface.co/Severian-Void/Starsector-Portraits
-
Evangelion style: https://huggingface.co/crumb/eva-fusion-v2
-
Robo Diffusion: https://huggingface.co/nousr/robo-diffusion/tree/main/models
-
Arcane Diffusion: https://huggingface.co/nitrosocke/Arcane-Diffusion
-
Wikihow style: https://huggingface.co/jvkape/WikiHowSDModel
- 60 Images. 2500 Steps. Embedding Aesthetics + 40 Image Embedding options
- Their patreon: https://www.patreon.com/user?u=81570187
-
Lain girl: https://mega.nz/file/VK0U0ALD#YDfGgOu8rquuR5FbFxmzKD5hzxO1iF0YQafN0ipw-Ck
-
Wikiart: https://huggingface.co/valhalla/sd-wikiart-v2/tree/main/unet
- diffusion_pytorch_model.bin, just rename to whatever.ckpt
-
Megaman zero: https://huggingface.co/jinofcoolnes/Zeromodel/tree/main
-
Cyberware: https://huggingface.co/Eppinette/Cyberware/tree/main
-
taffy (keyword: champi): https://drive.google.com/file/d/1ZKBf63fV1Zm5_-a0bZzYsvwhnO16N6j6/view?usp=sharing
-
Disney (3d?): https://huggingface.co/nitrosocke/modern-disney-diffusion/
-
El Risitas (KEK guy): https://huggingface.co/Fictiverse/ElRisitas
-
Cyberpunk Anime Diffusion: https://huggingface.co/DGSpitzer/Cyberpunk-Anime-Diffusion
-
Kurzgesagt (called with "kurzgesagt! style"): https://drive.google.com/file/d/1-LRNSU-msR7W1HgjWf8g1UhgD_NfQjJ4/view?usp=sharing
- SHA-256: d47168677d75045ae1a3efb8ba911f87cfcde4fba38d5c601ef9e008ccc6086a
-
Robodiffusion (good outputs for "meh" prompting): https://huggingface.co/nousr/robo-diffusion
-
2D Illustration style: https://huggingface.co/ogkalu/hollie-mengert-artstyle
-
Rebecca (edgerunners, by booru anon, info is in link): https://huggingface.co/demibit/rebecca
-
Kiwi (by booru anon): https://huggingface.co/demibit/kiwi
-
Ranni (Elden Ring): https://huggingface.co/bitspirit3/SD-Ranni-dreambooth-finetune
-
Modern Disney style (modi, mo-di): https://huggingface.co/nitrosocke/mo-di-diffusion
-
Silco: https://huggingface.co/jinofcoolnes/silcomodel/tree/main
-
Lara: https://huggingface.co/jinofcoolnes/Oglaramodel/tree/main
-
theofficialpit bimbo (26 pics for 2600 steps, Use "thepit bimbo" in prompt for more effect): https://mega.nz/file/wSdigRxJ#WrF8cw85SDebO8EK35gIjYIl7HYAz6WqOxcA-pWJ_X8
-
DCAU (Batman_the_animated_series): https://huggingface.co/IShallRiseAgain/DCAU/blob/main/DCAUV1.ckpt
- https://www.reddit.com/r/StableDiffusion/comments/yf2qz0/initial_version_of_dcau_model_im_making/
- hand captioning 782 screencap, 44,000 steps, training set for the regularization images
-
NSFW: https://megaupload.nz/N7m7S4E7yf/Magnum_Opus_alpha_22500_steps_mini_version_ckpt
-
Hardcore: https://pixeldrain.com/u/Stk98vyH
- Trained on 3498 images and around 250K steps
- porn, sex acts of all sorts: anal sex, anilingus, ass, ass fingering, ball sucking, blowjob, cumshot, cunnilingus, dick, dildo, double penetration, exposed pussy, female masturbation, fingering, full nelson, handjob, large ass, large tits, lesbian kissing, massive ass, massive tits, o-face, sixty-nine, spread pussy, tentacle sex (try also oral/anal tentacle sex and tentacle dp), tit fucking, tit sucking, underboob, vaginal sex, long tongue, tits
- Example grid from training (single shot batch): https://cdn.discordapp.com/attachments/1010982959525929010/1035236689850941440/samples_gs-995960_e-000046_b000000.png
- Trained on 3498 images and around 250K steps
-
disney 2d animation style: https://huggingface.co/nitrosocke/classic-anim-diffusion
-
Kim Jung Gi: https://drive.google.com/drive/folders/1uL-oUUhuHL-g97ydqpDpHRC1m3HVcqBt
-
Pyro's Blowjob Model: https://rentry.org/pyros-sd-model
!!! info If an embedding is >80mb, I mislabeled it and it's a hypernetwork
!!! info Use a download manager to download these. It saves a lot of time + good download managers will tell you if you have already downloaded one
- Text Tutorial: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Textual-Inversion
- Make sure to use pictures of your subject in varied areas, it gives more for the AI to work with
- Tutorial 2: https://rentry.org/textard
- Another tutorial: https://imgur.com/a/kXOZeHj
- Test embeddings: https://huggingface.co/spaces/sd-concepts-library/stable-diffusion-conceptualizer
- Collection: https://huggingface.co/sd-concepts-library
- Collection 2: https://mega.nz/folder/fVhXRLCK#4vRO9xVuME0FGg3N56joMA
- Collection 3: https://cyberes.github.io/stable-diffusion-textual-inversion-models/
- Korean megacollection:
- https://arca.live/b/hypernetworks?category=%EA%B3%B5%EC%9C%A0
- (includes mega compilation of artists): https://arca.live/b/hypernetworks/60940948
- Original: https://arca.live/b/hypernetworks/60930993
- Large collection of stuff from korean megacollection: https://mega.nz/folder/sSACBAgC#kNiPVzRwnuzs8JClovS1Tw
- Large Vtuber collection dump (not sure if pickled, even linker anon said to be careful, but a big list anyway): https://rentry.org/EmbedList
- Waifu Diffusion collection: https://gitlab.com/cattoroboto/waifu-diffusion-embeds
Found on 4chan:
-
Embeddings + Artists: https://rentry.org/anime_and_titties (https://mega.nz/folder/7k0R2arB#5_u6PYfdn-ZS7sRdoecD2A)
-
Random embedding I found: https://ufile.io/c3s5xrel
-
Embeddings: https://rentry.org/embeddings
-
Anon's collection of embeddings: https://mega.nz/folder/7k0R2arB#5_u6PYfdn-ZS7sRdoecD2A
-
Collection: https://gitgud.io/ZeroMun/stable-diffusion-tis/-/tree/master/embedding
-
Collection: https://gitgud.io/sn33d/stable-diffusion-embeddings
-
Collection from anon's "friend" (might be malicious): https://files.catbox.moe/ilej0r.7z
-
Collection from anon: https://files.catbox.moe/22rncc.7z
-
Collection: https://gitlab.com/rakurettocorp/stable-diffusion-embeddings/-/tree/main/
-
Collection: https://gitlab.com/mwlp/sd
-
Senri Gan: https://files.catbox.moe/8sqmeh.rar
-
Collection: https://gitgud.io/viper1/stable-diffusion-embeddings
-
Henreader embedding, all 311 imgs on gelbooru, trained on NAI: https://files.catbox.moe/gr3hu7.pt
-
Kantoku (NAI, 12 vectors, WD 1.3): https://files.catbox.moe/j4acm4.pt
-
Asanagi (NAI): https://files.catbox.moe/xks8j7.pt
- Asanagi trained on 135 images augmented to 502 for 150296 steps on NAI Anime Full Pruned with 16 vectors per token with init word as voluptuous
- training imgs: https://litter.catbox.moe/2flguc.7z
-
DEAD LINK Asanagi (another one): https://litter.catbox.moe/g9nbpx.pt
-
Imp midna (NAI, 80k steps): mega.nz/folder/QV9lERIY#Z9FXQIbtXXFX5SjGf1Ba1Q
-
imp midna 2 (NAI_80K): mega.nz/file/1UkgWRrD#2-DMrwM0Ph3Ebg-M8Ceoam_YUWhlQWsyo1rcBtuKTcU
-
inverted nipples: https://anonfiles.com/300areCby8/invertedNipples-13000_zip (reupload)
- Dead link: https://litter.catbox.moe/wh0tkl.pt
-
Takeda Hiromitsu Embedding 130k steps: https://litter.catbox.moe/a2cpai.pt
-
Takeda embedding at 120000 steps: https://filebin.net/caggim3ldjvu56vn
-
Nenechi embedding: https://mega.nz/folder/E0lmSCrb#Eaf3wr4ZdhI2oettRW4jtQ
-
Touhou Fumo embedding (57 epochs): https://birchlabs.co.uk/share/textual-inversion/fumo.cpu.pt
-
Abigail from Great Pretender (24k steps): https://workupload.com/file/z6dQQC8hWzr
-
Naoki Ikushima (40k steps): https://files.catbox.moe/u88qu5.pt
-
Gigachad: https://easyupload.io/nlha2m
-
Kusada Souta (95k steps): https://files.catbox.moe/k78y65.pt
-
Yohan1754: https://files.catbox.moe/3vkg2o.pt
-
Repo for some: https://git.evulid.cc/wasted-raincoat/Textual-Inversion-Embeds/src/branch/master/simonstalenhag
-
automatic's secret embedding list: https://gitlab.com/16777216c/stable-diffusion-embeddings
-
Kaneko Kazuma (Kazuma Kaneko): https://litter.catbox.moe/6glsh1.pt
-
Senran Kagura (850 CGs, deepdanbooru tags, 0.005 learning rate, 768x768, 3000 iterations): https://files.catbox.moe/jwiy8u.zip
-
Abmono (14.7k): https://www.mediafire.com/file/id2uh4gkzvavsbc/abmono-14700.pt/file
-
DEAD LINK Deadflow (190k, "bitchass"(?)): https://litter.catbox.moe/03lqr6.pt
-
Aroma Sensei (86k, "aroma"): https://files.catbox.moe/wlylr6.pt
-
Zun (75:25 weighted sum NAI full:WD): https://www.fluffyboys.moe/sd/zunstyle.pt
-
Kurisu Mario (20k): https://files.catbox.moe/r7puqx.pt
- creator anon: "I suggest using him for the first 40% of steps so that the AI draws the body in his style, but it's up to you. Also, put speech_bubble in the negative prompt, since the training data had them"
-
ATDAN (33k): https://files.catbox.moe/8qoag3.pt
-
Valorant (25k): https://files.catbox.moe/n7i9lq.pt
-
Takifumi (40k, 153 imgs): https://freeufopictures.com/ai/embeddings/takafumi/
-
40hara (228 imgs, 70k, 421 after processing): https://freeufopictures.com/ai/embeddings/40hara/
-
Tsurai (160k, NAI): https://mega.nz/file/bBYjjRoY#88o-WcBXOidEwp-QperGzEr1qb8J2UFLHbAAY7bkg4I
-
Wagashi (12k, shitass(?)), no associated pic or replies so might be pickled: https://litter.catbox.moe/ktch8r.pt
-
jtveemo (150k): https://a.pomf.cat/kqeogh.pt
- Creator anon: "I didn't crop out any of the @jtveemo stuff so put twitter username in the negatives."
-
Nahida (Genshin Impact): https://files.catbox.moe/nwqx5b.zip
-
Arcane (SD 1.4): https://files.catbox.moe/z49k24.pt
- People say this triggered the pickle warning, so it might be pickled.
-
Gothica: https://litter.catbox.moe/yzp91q.pt
-
Mordred: https://a.pomf.cat/ytyrvk.pt
-
100k steps tenako (mugu77): https://www.mediafire.com/file/1afk5fm4f33uqoa/tenako-mugu77-100000.pt/file
-
erere-26k (fuckass(?)): https://litter.catbox.moe/cxmll4.pt
-
Great Mosu (44k): https://files.catbox.moe/6hca0u.pt
-
no idea what this embedding is, apparently it's an artist?: https://files.catbox.moe/2733ce.pt
-
Dohna Dohna, Rance remakes (305 images (all VN-style full-body standing character CGs). 12000 steps): https://files.catbox.moe/gv9col.pt
- trained only on dohna dohna's VN sprites
- Onono imoko
-
Senri Gan: https://files.catbox.moe/8sqmeh.rar
- 2 hypernetworks and 5 TI
- Anon: "For the best results I think using hyper + TI is the way. I'm using TI-6000 and Hyper-8000. It was trained on CLIP 1 Vae off with those rates 5e-5:100, 5e-6:1500, 5e-7:10000, 5e-8:20000."
-
om_(n2007): https://files.catbox.moe/gntkmf.zip
-
Kenkou Cross: https://mega.nz/folder/ZYAx3ITR#pxjhWOEw0IF-hZjNA8SWoQ
-
Baffu (~47500 steps): https://files.catbox.moe/l8hrip.pt
- Biased toward brown-haired OC girl (Hitoyo)
-
Danganronpa: https://files.catbox.moe/3qh6jb.pt
-
Hifumi Takimoto: https://files.catbox.moe/wiucep.png
- 18500 steps, prompt tag is takimoto_hifumi. Trained on NAI + Trinart2 80/20, but works fine using just NAI
-
Power (WIP): https://files.catbox.moe/bzdnzw.7z
-
shiki_(psychedelic_g2): https://files.catbox.moe/smeilx.rar
-
Embeddings using the old version of TI
-
Takeda Hiromitsu reupload: https://www.mediafire.com/file/ljemvmmtz0dqy0y/takeda_hiromitsu.pt/file
-
Takeda Hiromitsu (another reupload): https://a.pomf.cat/eabxqt.pt
-
Pochi: https://files.catbox.moe/7vegvg.rar
- Author's notes: Smut version was trained on a lot of doujins and it looks more like her old style from the start of smut version of Ane doujin (compare to chapter 1 and you can see that it worked). 200k version is looking a bit more like her recent style but I can see it isn't going to work the way I hoped.
- By accident I started with 70 pics where half of them were doujins to give reference for smut. Complete data is 200 with again those same 35 doujins for smut. I realized that I used half smut instead of full set so I went back to around 40k steps and then gave it complete 200 picture set hoping it would course correct since non smut is more recent art style. Now it looks like it didn't course correct and will never do that. On the other hand recent iterations are less horny.
-
Power (Chainsaw Man): https://files.catbox.moe/c1rf8w.pt
-
ooyari:
- 70k (last training): https://litter.catbox.moe/gndvee.pt
- 20k (last stable loss trend): https://litter.catbox.moe/i7nh3x.pt
- 60k (lowest loss rate state in trending graph): https://litter.catbox.moe/8wot9a.pt
-
Kunaboto (195 images. 16 vectors per token, default learning rate of 0.005): https://files.catbox.moe/uk964z.pt
-
Erika (Shadowverse): https://files.catbox.moe/y9cgr0.pt
-
Luna (Shadowverse): https://files.catbox.moe/zwq5jz.pt
-
Fujisaka Lyric: https://files.catbox.moe/8j6ith.pt
-
Hitoyo (maybe WIP?): https://files.catbox.moe/srg90p.pt
-
Hitoyo (58k): https://files.catbox.moe/btjsfg.pt
-
kunaboto v2 (Same dataset, just a different training rate of 0.005:25000,0.0005:75000,0.00005:-1, 70k): https://files.catbox.moe/v9j3bz.pt
-
Hitoyo (another, final vers?) (100k steps, bonnie-esque): https://files.catbox.moe/l9j1f4.pt
-
Fatamoru: https://litter.catbox.moe/pn9xep.pt
- Dead link: https://litter.catbox.moe/xd2ht9.pt
-
Zip of Fatamoru, Morgana, and Kaneko Kazuma: https://litter.catbox.moe/9bf77l.zip
-
Tekuho (NAI model, Clip Skip 2, VAE unloaded, Learning rate 0.002:2000, 0.0005:5000, 0.0001:9000): https://mega.nz/folder/VB5XyByY#HLvKyIJ6U5nMXx6i3M__VQ
- manually cropped about 150 images, making sure that all of them have a full body shot, a shot from torso and up, and if applicable a closeup on the face
- Images not from Danbooru
- Best results around 4000 steps
-
Embed of a girl anon liked (2500 steps, keyword "jma"): https://files.catbox.moe/1qlhjf.pt
-
Carpet Crawler: https://anonfiles.com/i3a2o0E5y0/carpetcrawlerv2-12500_pt
- Embedding trained on nai-final-pruned at 8 vectors up to 20k steps. Turned into ugly overtrained garbage over 125000 steps so this is the one I'm releasing. Not good for much other than eldritch abominations.
- https://www.deviantart.com/carpet-crawler/gallery
- recommend using it in combination with other horror artist embeddings for best results.
-
nora higuma (Fuckass, 0.0038, 24k, 1000+ dataset, might be pickle): https://litter.catbox.moe/tkj61z.pt
- dead link: https://litter.catbox.moe/25n10h.pt
-
mdf an (Bitchass train: 0.0038, steps: 48k, loss rate trend: 0.095, dataset: 500+, issue: nsfw majority, will darken sfw images): https://litter.catbox.moe/lxsnyi.pt
- dead link: https://litter.catbox.moe/4liook.p
-
subachi (shitass, train: 0.0038, steps: 48k, loss rate trend: 0.118, dataset: 500+, issue: due to artist's style, it's on sigma male mode; respecting woman is not an option with this embedding): https://litter.catbox.moe/6nykny.pt
- dead link: https://litter.catbox.moe/idskrg.pt
-
DEAD LINK Omaru-polka: https://litter.catbox.moe/qfchu1.pt
-
Embed for "veemo" (?), used to make this picture (https://s1.alice.al/vt/image/1665/54/1665544747543.png): https://files.catbox.moe/18bgla.pt
-
Reine:
- 39,5k steps, pretty high vectors per token: https://files.catbox.moe/s2s5qg.pt
- smaller clip skip and less steps, trained it to 13k: https://files.catbox.moe/nq126i.pt
-
Big reine collection: https://files.catbox.moe/xe139m.zip
-
Ilulu (64k steps with a learning rate of 0.001): https://files.catbox.moe/8acmvo.pt
-
meme50 (WIP, 0.004 LR, 20k): https://litter.catbox.moe/a31cuf.pt
-
random embed from furry thread (6500 steps, 10 vectors, 1 placeholder_string, init_word "girl" these four images used): https://files.catbox.moe/4qiy0k.pt
-
Cookie (from furry thread, apprently good with inpainting): https://files.catbox.moe/9iq7hh.pt
-
Cutie (cyclops, from furry thread, 8k steps): https://files.catbox.moe/aqs3x3.pt
-
Felino's artstyle (from furry thread, 7 images): https://files.catbox.moe/vp21w4.pt
-
Yakov (from mlp thread): https://i.4cdn.org/mlp/1666224881260593.png
-
Rebecca (by booru anon, info is in link): https://huggingface.co/demibit/rebecca
-
eastern artists combinination: https://mega.nz/file/SlQVmRxR#nLBxMj7_Zstv4XqfuEcF-pgza3T1NPlejCm1KGBbw70
-
Elana (Shadowverse): https://files.catbox.moe/vbpo7m.pt
-
Info by anon: I just grab all the good images I can find, tag with BLIP and Deepdanbooru in the preprocessing, and pick a number of vectors based on how many images I have (16 here since not a lot). Other than that, I trained 6500 steps at 1 batch size under the schedule:
0.02:200, 0.01:1000, 0.005:2000, 0.002:3000, 0.0005:4000, 0.00005
-
-
Power (60k): https://files.catbox.moe/72dfvc.pt
-
Sakimichan (DEAD LINK): https://mega.nz/file/eE8QDKrI#y7kdyWgPUjI4ZkY8PSq89F28eU_Vz_0EgTbG6yAowH8
-
Takeda, Mogudan Fourchanbal (?, from KR site): https://files.catbox.moe/430rus.pt
-
Mikan (30 tokens, 36 images (before flipping/splitting), 5700steps, 5e-02:2000, 5e-03:4000): https://files.catbox.moe/xwdohx.pt
- creator: I've been getting best results with these tags: (orange hair and (hair tubes:1.2), (dog ears and dog tail and (huge ahoge:1.2):1.2)), green eyes
- apparently it's not very effective. a hypernetwork is WIP
-
Furry styled embed? (6000, 5.5k most): https://files.catbox.moe/s19ub3.7z
-
Mutsuki (Blue Archive) embedding (10k step,150 image, no clip skip [set the "stop at last layers of clip model" option at 1 to get good results], 0.02:300, 0.01:1000, 0.005:2000, 0.002:3000, 0.0005:4000, 0.0005, vae disabled by renaming): https://files.catbox.moe/6yklfl.pt
-
as109 (trained with 1000+ dataset, 0.003 learning rate, 0.12 loss rate trend, 25k step snapshot): https://litter.catbox.moe/5iwbi5.pt
-
sasamori tomoe (0.92 loss trend, 60k+ steps, 0.003 learning rate. 500+ dataset, pruned pre 2015 images. biased to doujin, weak to certain positions (mostly side)): https://litter.catbox.moe/mybrvu.pt
-
egami(500+ dataset, 0.03 learning rate, 0.13 loss trend, 40k steps): https://litter.catbox.moe/dpqp1k.pt
-
pink doragon (20k+ steps, 0.0031 learning rate, 0.113 loss trend, 800+ dataset): https://litter.catbox.moe/mml9b9.pt
- kind of failure: fancy recent artworks are ignored due to dataset bias - will train with 2018+ data.
- leaning to BIG ASS and BIG TIDDIES.
-
Kiwi (by booru anon): https://huggingface.co/demibit/kiwi
-
Labiata (8 vectors/token): https://files.catbox.moe/0kri2d.pt
-
Akari (another, one I missed): https://files.catbox.moe/dghjhh.pt
-
Arona from Blue Archive (I'm pretty sure): https://files.catbox.moe/4cp6rl.pt
-
Emma (arcane, 50 vector embedding trained on ~250 pics for ~13500 steps): https://files.catbox.moe/2cd7s3.pt
-
blade4649 embedding (10k steps, 352 images,16 vectors,learning rate at 0.005): https://files.catbox.moe/5evrpn.pt
-
fechtbuch of Mair: https://files.catbox.moe/vcisig.pt
-
Longsword (mainly for img2img): https://files.catbox.moe/r442ma.pt
-
Le Malin (listless Lapin skin, 10k steps with 712 inputs): https://files.catbox.moe/3rhbvq.pt
-
minakata hizuru (summertime girl): https://files.catbox.moe/9igh8t.pt
-
Roon (Azur Lane) (NAI model, 10k steps but with 83 different inputs): https://files.catbox.moe/9b77mp.pt
-
arcane-32500: https://files.catbox.moe/nxe9qr.pt
-
mashu003 (https://mashu003.tumblr.com/) (all danbooru images used as dataset): https://files.catbox.moe/kk7v9w.pt
-
Takimoto Hifumi (18500 steps, prompt tag is takimoto_hifumi. Trained on NAI + Trinart2 80/20, but works fine using just NAI): https://files.catbox.moe/wiucep.png
-
momosuzu nene: https://mega.nz/folder/s8UXSJoZ#2Beh1O4aroLaRbjx2YuAPg
-
Harada Takehito (disgaea artist) (78k steps with 150 images): https://files.catbox.moe/e2iatm.pt
-
Mda (1700 images and trained for 20k): https://files.catbox.moe/tz37dj.pt
-
Polka (NAI, 16 vectors, 5500 steps): https://files.catbox.moe/pmzyhi.png
-
Asutora style embedding (mainly reflected in coloring and shading, since his faces are very inconsistent): https://mega.nz/folder/nZoECZyI#vkuZJoQyBZN8p66n4DP62A
Found on Discord:
- Nahida v2: https://cdn.discordapp.com/attachments/1019446913268973689/1031321278713446540/nahida_v2.zip
- Nahida (50k, very experimental, not enough images): https://files.catbox.moe/2794ea.pt
Found on Reddit:
- look at the 2nd and 3rd images: https://www.reddit.com/gallery/y4tmzo
!!! info If a hypernetwork is <80mb, I mislabeled it and it's an embedding
!!! info Use a download manager to download these. It saves a lot of time + good download managers will tell you if you have already downloaded one
- anon: "Requires extremely low learning rate, 0.000005 or 0.0000005" Good Rentry: https://rentry.co/naihypernetworks Hypernetwork Dump: https://gitgud.io/necoma/sd-database Collection: https://gitlab.com/mwlp/sd Another collection: https://www.mediafire.com/folder/bu42ajptjgrsj/hn Senri Gan: https://files.catbox.moe/8sqmeh.rar Big dumpy of a lot of hypernets (has slime too): https://mega.nz/folder/kPdBkT5a#5iOXPnrSfVNU7F2puaOx0w Collection of asanuggy + maybe some more: https://mega.nz/folder/Uf1jFTiT#TZe4d41knlvkO1yg4MYL2A Collection: https://mega.nz/folder/fVhXRLCK#4vRO9xVuME0FGg3N56joMA Mogudan, Mumumu (Three Emu), Satou Shouji + constant updates: https://mega.nz/folder/hlZAwara#wgLPMSb4lbo7TKyCI1TGvQ Korean megacollection:
- https://arca.live/b/hypernetworks?category=%EA%B3%B5%EC%9C%A0
- (includes mega compilation of artists): https://arca.live/b/hypernetworks/60940948?category=%EA%B3%B5%EC%9C%A0&p=1
Chinese telegram (uploaded by telegram anon): magnet:?xt=urn:btih:8cea1f404acfa11b5996d1f1a4af9e3ef2946be0&dn=ChatExport%5F2022-10-30&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce
I've made a full export of the Chinese Telegram channel.
It's 37 GB (~160 hypernetworks and a bunch of full models). If you don't want all that, I would recommend downloading everything but the 'files' folder first (like 26 MB), then opening the html file to decide what you want.
- Dead link: https://t.me/+H4EGgSS-WH8wYzBl
Big collection: https://drive.google.com/drive/folders/1-itk7b_UTrxVdWJcp6D0h4ak6kFDKsce?usp=sharing
- https://drive.google.com/drive/folders/1-itk7b_UTrxVdWJcp6D0h4ak6kFDKsce?usp=sharing
- https://arca.live/b/aiart/60927159?p=1
- https://arca.live/b/hypernetworks/60927228?category=%EA%B3%B5%EC%9C%A0&p=2
Found on 4chan:
- bigrbear: https://files.catbox.moe/wbt30i.pt
- Senran Kagura v3 (850 images, 0.000005 learn rate, 20000 steps, 768x768): https://files.catbox.moe/m6jynp.pt
- CGs from the Senran Kagura mobile game (NAI model): https://files.catbox.moe/vyjmgw.pt
- Ran for 19,000 steps with a learning rate of 0.0000005. Source images were 768x576. It seems to only reproduce the art style well if you specify senran kagura, illustration, game cg, in your prompt.
- Old version (19k steps, learning rate of 0.0000005. Source images were 768x576. NAI model. 850 CGs): https://files.catbox.moe/di476p.pt
- Senran Kagura again (850, deepdanbooru, 0.000006, 768x576, 7k steps): https://files.catbox.moe/f40el4.pt
- CGs from the Senran Kagura mobile game (NAI model): https://files.catbox.moe/vyjmgw.pt
- Danganronpa: https://files.catbox.moe/9o5w64.pt
- Trained on 100 images, up to 12k with 0.000025 rate, then up to 18.5k with 0.000005
- Also seed 448840911 seems to be great quality for char showcase with just name + base NAI prompts.
- Alexi-trained hypernetwork (22000 steps): https://files.catbox.moe/ukzwlp.pt
- Reupload by anon: https://files.catbox.moe/slbk3m.pt
- works best with oppai loli tag
- https://files.catbox.moe/xgozyz.zip
- Etrian Odyssey Shading hypernetwork (20k steps, WIP, WD 1.3)
- colored drawings by Hass Chagaev (6k steps, NAI): https://files.catbox.moe/3jh1kk.pt
- Morgana: https://litter.catbox.moe/3holmx.pt
- EOa2Nai: https://files.catbox.moe/ex7yow.7z
- EO (WD 1.3): https://files.catbox.moe/h5phfo.7z
- Taran Jobu (oppai loli, WIP, apparently it's kobu not jobu)
- Higurashi (NAI:SD 50:50): https://litter.catbox.moe/lfg6ik.pt
- by op anon: "1girl, [your tags here], looking at viewer, solo, art by higurashi", cfg 7, steps about 40"
- Tatata (15 imgs, 10k steps): https://files.catbox.moe/7hp2es.pt
- Zankuro (0.75 NAI:WD, 51 imgs, 25k+ steps): https://files.catbox.moe/tlurbe.pt
- Training info + hypernetwork: https://files.catbox.moe/4do43z.zip
- Test Hypernetwork (350 imgs where half are flipped, danooru tags, 0.00001 learning rate for 3000 steps, 0.000004 until step 7500): https://files.catbox.moe/coux0u.pt
- Kyokucho (40k steps, good at 10-15k, NAI:WD1.2): https://workupload.com/file/TFRuGpdGZZn
- Final Ixy (more detail in discord section): https://mega.nz/folder/yspgEBhQ#GLo7mBc1EH7RK7tQbtC68A
- Old Ixy (more data, more increments): https://mega.nz/file/z8AyDYSS#zbZFo9YLeJHd8tWcvWiRlYwLz2n4QXTKk04-cKMmlrg
- Old Ixy (less increments, no training data): https://mega.nz/file/ixxzkR5T#cxxSNxPF1KmszJDqiP4K4Ou8tbl1SFKL6DdQC58k6zE
- Grandblue Fantasy character art (836 images, 5e-5:100, 5e-6:1500, 5e-7:10000, 5e-8:20000 learn rate, 20000 steps, 1024x1024): https://files.catbox.moe/2uiyd4.pt
- Bombergirl (Stats: 178 images, 5e-8 learn rate continuing from old Bombergirl, 20000 steps, 768x768): https://files.catbox.moe/9bgew0.pt
- Old Bombergirl (178 imgs, 0.000005 learning rate, 10k, 768x768): https://files.catbox.moe/4d3df4.pt
- Aki99 (200 images , 512x512, 0.00005, 19K steps, NAI): https://files.catbox.moe/bwff89.pt
- Aki99 (200 images , 512x512, 0.0000005, 112K steps, learning prompt: [filewords], NAI): https://www.mediafire.com/file/sud6u1vb0gvqswu/aki99-112000.7z/filehttps://files.catbox.moe/6hca0u.pt
- Great Mosu: https://files.catbox.moe/mc1l37.pt
- mda starou: https://a.pomf.cat/xcygvk.pt
- Mogudan (12 vectors per token, 221 image dataset, preprocessing: split oversize, flipped mirrors, deepdanbooru auto-tag, 0.00005 learning rate, 62,500 steps): https://mega.nz/file/UtAz1CZK#Y5OSHPkD38untOPSEkNttAVi2tdRLBFEsKVkYCFFaHo
- Onono Imoko: https://files.catbox.moe/amfy2x.pt
- Dataset: https://files.catbox.moe/dkn85w.zip
- Etrian Odyssey (training rate 5e-5:100, 5e-6:1500, 5e-7:10000, 5e-8:20000,20k steps, 512 x 512 pics): https://files.catbox.moe/94qm83.7z
- Jesterwii: https://files.catbox.moe/hlylo4.zip
- jtveemo (v1): https://mega.nz/folder/ctUXmYzR#_Kscs6m8ccIzYzgbCSupWA
- 35k max steps, 0.000005 learning rate, 180 images, ran through deepbooru and manually cleaned up the txt files for incorrect/redundant tags.
- Recommended the 13500.pt, or something near it
- Recommended: https://files.catbox.moe/zijpip.pt
- Artsyle based on Yuugen (HBR) (Stats: 103 images, 5e-5:100, 5e-6:1500, 5e-7:10000, 5e-8:20000 learn rate, 20000 steps, 1024x1024,Trained on NAI model): https://files.catbox.moe/bi2ts0.7z
- Alexi: https://files.catbox.moe/3yj2lz.pt (70000 steps)
- as usual, works best with oppai loli tag. chibi helps as well
- changes from original one i noticed during testing: -hair shading is more subtle now -nipple color transition is also more subtle -eyelashes not as thick as before, probably because i used more pre-2022 pictures. actually bit sad about it, but w/e -eyes in general look better, i recommend generating on 768×768 with highres fix -blonde hair got a pink gradient for some reason -tends to hide dicks between the breasts more often, but does it noticeably better -likes to add backgrounds, i think i overcooked it a bit so those look more like artifacts, perhaps with other prompts it will look better -less hags -from my test prompts, it looked like it breaks anatomy less often now, but i mostly tested pov paizuri -became kinda worse at non-paizuri pictures, less sharpness. because of that, i'm also including 60000 steps version, which is slightly better at that, but in the end, it's a matter of preference, whether to use newer version or not: https://files.catbox.moe/1zt65u.pt
- Ishikei: https://www.mediafire.com/folder/obbbwkkvt7uhk/ishikemono
- Mogudan, Mumumu (Three Emu), Satou Shouji: https://mega.nz/folder/hlZAwara#wgLPMSb4lbo7TKyCI1TGvQ
- creator anon: "this will be the future folder where I will be uploading all my textual inversions. Mumumu hypernetwork is training now, Satou Shouji dataset has been prepped, now to scrape Onomeshin's art from Gelbooru"
- Mumumu: 109 images, 75k steps
- Curss style (slime girls): https://files.catbox.moe/0sixyq.pt
- WIP Collection of hypernets: https://litter.catbox.moe/xxys2d.7z
- DEAD LINK Mumumu's art: https://mega.nz/folder/tgpikL6C#Mj0sHUnr-O6u4MOMDRTiMQ
- Senri Gan: https://files.catbox.moe/8sqmeh.rar
- 2 hypernetworks and 5 TI
- Anon: "For the best results I think using hyper + TI is the way. I'm using TI-6000 and Hyper-8000. It was trained on CLIP 1 Vae off with those rates 5e-5:100, 5e-6:1500, 5e-7:10000, 5e-8:20000."
- Ulrich: https://files.catbox.moe/jhgsxw.zip
- akisora: https://files.catbox.moe/gfdidn.pt
- lilandy: https://files.catbox.moe/spzm60.pt
- shadman: https://files.catbox.moe/kc850y.pt
- anon: "if anyone else wants to try training, can recommend - 0.00005:2000, 0.000005:4000, 0.0000005:6000 learning rate setup (6k steps total with 250~1000 images in dataset)"
- not sure what this is, probably a style: https://files.catbox.moe/lnxwks.pt
- ndc hypernet, muscle milfs: https://files.catbox.moe/hsx4ml.pt
- Asanuggy: https://mega.nz/folder/Uf1jFTiT#TZe4d41knlvkO1yg4MYL2A
- Tomubobu: https://files.catbox.moe/bzotb7.pt
- Works best with jaggy lines, oekaki, and clothed sex tags.
- satanichia kurumizawa macdowell (around 552 pics in total with 44.5k steps, most of the datasets are fanarts but some of them are from the anime, tagged with deepdanbooru, flipped and manually cropped): https://files.catbox.moe/g519cu.pt
- Imazon v1: https://files.catbox.moe/0e43tq.pt
- Imazon v2: https://files.catbox.moe/86pkaq.pt
- WIP Baffu: https://gofile.io/d/4SNmm5
- Ilulu (74k steps at 0.0005 learning rate, full NAI, init word "art by Ilulu"): https://files.catbox.moe/18ad25.pt
- belko paizuri (86k swish + normalization): https://www.mediafire.com/folder/urirter91ect0/belkomono
- WIP: training/0.000005/swish/normalization
- Pinvise (Suzutsuki Kirara) (NAI-Full with 5e-6 for 8000 steps and 5e-7 until 12000 steps on 200 (400 with flipped) images): https://litter.catbox.moe/glk7ni.zip
- Bonnie: https://files.catbox.moe/sc50gl.pt
- Another batch of artists hypernetworks (some are with 1221 structure, so bigger size)
- https://files.catbox.moe/srhrn6.pt - diathorn
- https://files.catbox.moe/dytn06.pt - gozaru
- https://files.catbox.moe/69t1im.pt - Sunahara Wataru
- kunaboto (new swish activation function + dropout using a learning rate of 5e-6:12000, 5e-7:30000): https://files.catbox.moe/lynmxm.pt
- aesthetic: https://files.catbox.moe/qrka4m.pt
- Reine: https://litter.catbox.moe/1yjgjg.pt
- Om (nk2007):
- 250 images (augmented to 380), learning rate: 5e-5:380,5e-6:10000,5e-7:20000, template: [filewords]
- 10k step : https://files.catbox.moe/8kqb4c.pt
- 16k step : https://files.catbox.moe/7vtcgt.pt
- 20k step (omHyper): https://files.catbox.moe/f8xiz1.pt
- Spacezin: https://mega.nz/folder/Os5iBQDY#42xOYeZq08ZG0j8ds4uL2Q
- excels at his massive tits, covered nipples, body form, sharp eyes, all that nice stuff
- no cbt data
- using the new swish activation method +dropout, works very well, trained at 5e-6 to 14000
- data it was trained on and cfg test grid included in the folder
- Hypernetwork trained on 13 handpicked images from spacezin
- recommend using spacezin in the prompt, using 14000 step hypernetwork, lesser steps are included for testing
- Aesthetic gradient embedding included
- amagami artstyle (30k,5e-6:12000, 5e-7:30000,swish+dropout): https://files.catbox.moe/3a2cll.7z
- Ken Sugimori (pokemon gen1 and gen2) art: https://files.catbox.moe/uifwt7.pt
- mikozin: https://mega.nz/folder/a0wxgQrR#OnJ0dK_F6_7WZiWscfb5hg
- Trained a hypernetwork on mikozin's art, using nai full pruned, swish activation method+dropout
- placing mikozin in the prompt will make it have a stronger effect, as all the training prompts include the [name] at the end.
- has a number of influences on your output, but mostly gives a very soft, painted style to the output image
- Aesthetic gradient embedding also included, but not necessary
- check the training data rar to read the filewords to see if you want to call anything it was specifically trained on
- Found on Discord (copied from SD Training Labs discord, so grammar mistakes may be present):
- Pippa (trained on NAI 70%full-30%sfw): https://files.catbox.moe/uw1y8g.pt
- reine (WIP): https://files.catbox.moe/od4609.pt
- WiseSpeak/RubbishFox (updated): https://files.catbox.moe/pzix7f.pt
- Info: Uses 176 Fanbox images that were preprocessed with splitting, flipping and mild touchup to remove text in Paint on about 1/4th of the images. I removed images from the Preprocess folder that did not have discernable character traits. Most images are of Tamamo since that is his waifu. Total images after split, flip, and corrections was 636. Took 13 hours at 0.000005 Rate at 512x512. Seems maybe a bit more touchy than the 61.5K file, but I believe that when body horror isn't present you can match the RubbishFox's style better.
- Style from furry thread: https://files.catbox.moe/vgojsa.pt
- 2bofkatt (from furry thread): https://files.catbox.moe/cw30m8.pt
- Hypernetwork trained on all 126 cards from the first YGO set in North America, 'Legend Of The Blue Eyes White Dragon' released on 03/08/2002: https://mega.nz/folder/ILkwRZLb#UJ03LDIfcMiFTn6-pyNyXQ
- WiseSpeak (Rubbish Fox on Twitter): https://files.catbox.moe/kyllcc.pt
- Info: Uses 176 images that were preprocessed with splitting, flipping and mild touchup to remove text in Paint on about 1/4th of the images. I removed images from the Preprocess folder that did not have discernable character traits. Most images are of Tamamo since that is his waifu. Total images after split, flip, and corrections was 636. Took 8 hours at 0.000005 Rate at 512x512
- 93k, less overtrained: https://files.catbox.moe/fluegz.pt
- Large collection of stuff from korean megacollection: https://mega.nz/folder/sSACBAgC#kNiPVzRwnuzs8JClovS1Tw
- Crunchy: https://files.catbox.moe/tv1zf4.pt
- Obui styled hypernetwork (125k steps): https://files.catbox.moe/6huecu.pt
- KurosugatariAI (2 hypernets, 1 embed, embedding is light at 17 token weight. at 24 or higher creator anon thinks the effect would be better): https://mega.nz/folder/TAggRTYT#fbxf3Ru8PkXz_edIkD2Ttg
- Amagami (Layer structure 1, 1.5 1.5 1; mish; xaviernormal; No layer normalization; Dropout O (appling only at 2nd layer due to bug); LR 8e-06 fixed; 20k done): https://files.catbox.moe/ucziks.7z
- Reine (from VTuber dump, might be pickled): https://files.catbox.moe/uf09mp.pt
- Onono imoko: https://mega.nz/file/67AUDQ4K#8n4bzcxGGUgaAVy7wLXvVib0jhVjt2wPS-jsoCxcCus
- Info moved to discord section
- Sironora:
- minakata hizuru (summertime girl): https://files.catbox.moe/gmbnnr.pt
- a1 (4.5k): https://files.catbox.moe/x6zt6u.pt
- 焦茶 / cogecha hypernetwork, trained against NAI (DEAD LINK): https://mega.nz/folder/BLtkVIjC#RO6zQaAYCOIii8GnfT92dw
- 山北東 / northeast_mountain hypernetwork, trained against NAI (DEAD LINK): https://mega.nz/folder/RflGBS7R#88znRpu7YC1J1JYa9N-6_A
- emoting mokou (cursed): https://mega.nz/folder/oPUTQaoR#yAmxD_yqeGqyIGfOYCR4PQ
- Cutesexyrobutts and gram: https://files.catbox.moe/silh2p.7z
- Scott: https://files.catbox.moe/qgqbs7.7z
- zunart (NAI, steps from 20000 to 50000): https://mega.nz/file/T9RmlbCQ#_JPkZqY5f0aaNxVc8MnU3WQHW4bv_yCWzJqOwL8Uz1U
- HBRv3D aka Heaven Burns Red (yuugen) retrained on new dataset of 142 mixed images: https://files.catbox.moe/urjkbm.7z
- Setting was 1,2,1 relu ,Learning rate: 5e-6:12000, 5e-7:30000
- momosuzu nene: https://mega.nz/folder/s8UXSJoZ#2Beh1O4aroLaRbjx2YuAPg
- TATATA and Alkemanubis: https://mega.nz/folder/zYph3LgT#oP3QYKmwqurwc9ievrl9dQ
- Tatata: Contains dataset, hypernetworks for steps 10000-19000 with a 1000 steps step, as well as full res sfw and nsfw comparisons.
- It was created before layer structure option, so it parameters are 1, 2, 1 layer structure, linear activation function.
- Alkemanubis: Alkemanubis is with elu activation function and normalisation, Alkemanubis4 is with swish and dropout, Alkemanubis5 is with linear and dropout. All have 1, 2, 4, 2, 1 layer structure.
- dataset and more fullres preview grid are inside too.
- HKSW (wrong eye color because of dataset): https://files.catbox.moe/dykyab.pt
- Nanachi (retrained, 4700 steps, sketches are good, VAE turned off): https://mega.nz/folder/PfhRUbST#6oXUaNjk_B6nhJzjc_M0UA
- Included is: Nanachi and Puuzaki Puuna (VAE was turned on during training)
- HiRyS: https://mega.nz/file/Mk8jTZ4I#TdlF5Bxwz_gAuQeR0PWa_YUZotcQkA34d6m49I6eUMc
- Dead link, I think this is the same hypernetwork: https://litter.catbox.moe/rx8uv0.pt
Found on Korean Site of Wisdom (WIP):
- Terada Tera: https://drive.google.com/file/d/1APwInBROTUdyeoW92yHFn_zBh7rY7b7I/view?usp=sharing
- Kyokai (Ono no Imoto, from KR site): https://kioskloud.xyz/d/634d88968d286fc0ffdf3408-YFISZ3XFW4RXUSTONJEHIM2YNUXGILTU
- musouduki (KR, 50K): https://mega.nz/file/81JUUbTB#NKz4SI-_oc_2Gx4bgwpVUzRndZhmYe8ugMbsXr-Uolc
- Molu: https://drive.google.com/drive/folders/10OxPPHtoCgMoHsUZvT2xWfoU4R2omAEu
- oekakizuki
- kyokucho (40k, works best at 10k-15k)
- Big collection: https://drive.google.com/drive/folders/1-itk7b_UTrxVdWJcp6D0h4ak6kFDKsce?usp=sharing
- dohna dohna
- Ashiomi Masato
- Migonon:
Found on Discord:
-
Art style of Rumiko Takahashi
Base: Novel AI's Final Pruned [126 images, 40000 steps, 0.00005 rate] Tips: "by Rumiko Takahashi" or "Shampoo from Ranma" etc.
-
Amamiya Kokoro (天宮こころ) a Vtuber from Njiisanji [NSFW / SFW] (Work on WD / NAI)
(Training set: 36 Input images, 21500 Steps, 0.000005 Learning rate. Training model: NAI-Full-Prunced Start with nijisanji-kokoro to get a good result. Recommend Hypernetwork Strength rate: 0.6 to 1.0
-
Haru Urara (ハルウララ) from Umamusume ウマ娘 [NSFW / SFW] (Work on WD / NAI)
Training set: 42 Input images, 21500 Steps, 0.000005 Learning rate. Training model: NAI-Full-Prunced Start with uma-urara to get a good result. Recommend Hypernetwork Strength rate: 0.6 to 1.0
-
Genshin Impact [SFW]
992 images, official art including some game assets 15k steps trained on nai use "character name genshin impact" or "genshin impact)" for best results
-
45k step version: https://files.catbox.moe/newhp6.pt
-
Ajitani Hifumi (阿慈谷 ヒフミ) from Blue Archive [NSFW / SFW] (Work on WD / NAI)
Training set: 41 Input images, 20055 Steps, 0.000005 Learning rate. Model: NAI-Full-Prunced Start with ba-hifumi to get a good result. Recommend Hypernetwork Strength rate: 0.6 to 1.0 1.0 Is a little bit overkill I thought about. If you want to go different costume like swimsuit or casual, I think 0.4 to 0.7 is the best ideal rate.
-
Higurashi no Nako Koro ni // ryukishi07's artstyle
Trained on Higurashi's original VN sprites. Might do Umineko's sprites next, or mix the two together. 8k steps, 15k steps, 18k steps included.
-
Trained Koharu of Blue Archive. I'm not very good at English, so it's painful to read this describe.
Training set: 41 images, 20000 steps, 0.000005 learning rate. Model: WD1.3 merged NAI (3/7 - Sigmoid)
-
queencomplexstyle (no training info): https://files.catbox.moe/32s6yb.pt
-
Shiroko of Blue Archive. Training set: 14 images at 20000 steps 0.000005 learning rate. The tag is 'ba-shiroko'
-
Queen Complex
(https://queencomplex.net/gallery/?avia-element-paging=2) [NSFW] "It's a cool style, and it has nice results. Don't need to special reference anything, seems to work fine regardless of prompt." Base Model: Novel AI Training set: 52 images at 4300 steps 0.00005 learning rate (images sourced from link above and cropped)
-
Raichiyo33 style hypernetwork. Not perfect but seems good enough.
Trained with captions from booru tags for compability with model + art by raichiyo33 in the beginning over NAI model. Use "art by raichiyo33" in the begining of prompt to triggering. Some useful tips:
- with tag "traditional media" produce more beautiful results
- try to avoid too much negativ promts. I use only "bad anatomy, bad hands, lowres, worst quality, low quality, blurry, bad quality" even that seems too much. With many UC tags (especially with full NAI set of uc) it will produce almost generic NAI result.
- Use CLIP -2 (because its trained over NAI, ofc)
-
Genshin Impact [SFW]
992 images, official art including some game assets 15k steps trained on nai use "character name genshin impact" or "genshin impact)" for best results
-
Gyokai-ZEN (aliases: Gyokai / Onono Imoko / shunin) [NSFW / SFW] (For NAI)
Includes training images Training set: 329 Input images, Various steps included. Main model is 21,000 steps. Training model: NAI-Full-Pruned. Recommend Hypernetwork Strength rate: 0.6 to 1.0. Lower strength is good for the overtrained model. Emphasise the hypernet by using the prompt words "gyokai" or "art by gyokai".
Note: the prompt words "color halftone" or "halftone" can be good at adding the little patterns in the shading often seen in onono imoko's style. HOWEVER: This often results in a noise/grain which often can be fixed if you render at a resolution higher than 768x768 (with hi-res fix) Omit these options from your prompt if the noise is too much in the image. Your outputs will be sharper and cleaner, but unfortunately less in the style.
gyokai-zen-1.0 is 16k steps at 0.000005, then up to 21k steps at 0.0000005 gyokai-zen-1.0-16000 is a bit less trained (16k steps) and sometimes outputs cleaner at full strength. gyokai-zen-1.0-overtrain is at 22k steps all at 0.000005. It can sometimes be a bit baked in.
-
yapo (ヤポ) Art Style [NSFW / SFW] (Work on WD / NAI)
Training set: 51 Input images, 8000 Steps, 0.0000005 Learning rate. Training model: NAI-Full-Prunced Start with in style of yapo / yapo to get a good result. Recommend Hypernetwork Strength rate: 0.4 to 0.8
- Preview Link: https://imgur.com/a/r2sOV41
- Download Link: https://anonfiles.com/N6B4d4D7y9/yapo_pt
-
Lycoris recoil chisato
Training set: 100 Input images, 21500 Steps, 0.000005 Learning rate. Training model: NAI-Full-Prunced Start with "cr-chisato" Recommend Hypernetwork Strength rate: 0.4 to 0.8. clip skip : 1 Euler
-
Liang Xing styled
Artstation: https://www.artstation.com/liangxing 20,000 steps at varying learning rates down to 0.000005, 449 training images. Novel AI base. Requires that you mention Liang Xing in some form as that was what I used in the training document. "in the style of Liang Xing" as an example.
-
アーニャ(anya)(SPY×FAMILY) [NSFW / SFW] (Work on WD / NAI)
Training set: 46 Input images, 20500 Steps, 0.00000005 Learning rate. Training model: NAI-Full-Prunced Start with Anya to get a good result. Recommend Hypernetwork Strength rate: 0.6 to 0.9
- Preview Link: https://imgur.com/a/ZbmIVRe
- Download Link: https://anonfiles.com/ZdKej8D5ya/Anya_pt
-
cp-lucy
Training set: 67 Input images, 21500 Steps, 0.000005 Learning rate. Training model: NAI-Full-Prunced Start with "cp-lucy" / clip skip : 1 Recommend Hypernetwork Strength rate: 0.6 to 0.9
-
バッチ (azur bache) (アズールレーン) [NSFW / SFW] (Work on WD / NAI)
Training set: 55 Input images, 20050 Steps, 0.00000005 Learning rate. Training model: NAI-Full-Prunced Start with azur-bache to get a good result. Recommend Hypernetwork Strength rate: 0.6 to 1.0
-
Ixy (by ixyanon):
Hypernetwork trained on ixy's style from 100 handpicked images from them, using split oversized images. Trained in Nai-full-pruned recommend using white pupils in the prompt, ixy for a greater effect of their style Uses: will generally make your output more flat in shading, very good at frilly stuff, and white pupils of course Grid examples located in the folder.
-
Blue Archives Azusa
Training set: 28 Input images, 20000 Steps, 5e-6:12000, 5e-7:30000 Learning rate. Training model: NAI-Full-Prunced Start with ba-azusa to get a good result. Recommend Hypernetwork Strength rate: 0.6 to 1.0 clip skip : 1
-
Makoto Shinkai HN
trained on a roughly ~150 images, 1,2,2,1 for 30,000 steps on NAI model, use "art by makotoshinkaiv2" to trigger it (experimental, it might not be that much different from base model but I have noticed that it improved composition when paired with the aesthetic gradient) 1007 frames from the entire 5 Centimeter Per Second (Byousoku 5 Centimeter) (2007) animovie by Makoto Shinkai
- Dataset (for the aesthetic gradient and for general hypernetwork training/finetuning of a model if anyone else wants to attempt to get this style down.):
- 1: https://cdn.discordapp.com/attachments/1022209206146838599/1033198526714363954/5_Centimeters_Per_Second.7z.001
- 2: https://cdn.discordapp.com/attachments/1022209206146838599/1033198659321475184/5_Centimeters_Per_Second.7z.002
- 3: https://cdn.discordapp.com/attachments/1022209206146838599/1033198735657803806/5_Centimeters_Per_Second.7z.003
- Link: https://cdn.discordapp.com/attachments/1032726084149583965/1033200762085453874/makotoshinkaiv2.pt
- Aesthetic Gradient: https://cdn.discordapp.com/attachments/1033147620966801609/1033196207478161488/makoto_shinkai.pt
- Dataset (for the aesthetic gradient and for general hypernetwork training/finetuning of a model if anyone else wants to attempt to get this style down.):
-
Hypernetwork based on the following prompts:
- cervix, urethra, puffy pussy, fat_mons, spread_pussy, gaping_anus, prolapse, gape, gaping
This hypernetwork was made by me (IWillRemember) (IWillRemember#1912 on discord) if you have any questions you can find me here on discord!
This hyper network was trained for 2000 steps at different learning rates on different batches of images (usually 25 images each batch)
I suggest using an HYPERNETWORK STRENGTH OF 0,5 or maybe up to 0,8 since it's really strong ; it is compatible with almost all anime like models and it performs great even with semi realistic ones.
The examples are made using the Nai model , but it works with ally , and any other anime based model if strength is adjusted acccordingly , also it COULD work with f111 and other models with the right prompts , to get really fat labia majora/minora , and/or gaping
- Link: https://mega.nz/file/pSN3mYoS#Q7e8tJWPSYGxdsyJMwhhtE5Jj8-A5e-sYZHhzbi3QAg
- Examples: https://cdn.discordapp.com/attachments/1018623945739616346/1033541564603039845/unknown.png, https://cdn.discordapp.com/attachments/1018623945739616346/1033542053444988938/unknown.png, https://cdn.discordapp.com/attachments/1018623945739616346/1033544232310411284/unknown.png, https://cdn.discordapp.com/attachments/1018623945739616346/1033550933151469688/unknown.png
-
(reupload from the 4chan section) Hypernetwork trained on spacezin's art, 13 handpicked images flipped and used oversized crop, data is the rar in the link
by ixyanon Trained in Nai-full-pruned, using swish activation method with dropout, 5e-6 training rate recommend using spacezin in the prompt, lesser steps are included for testing and usage if 20k is too much Uses: booba with covered nipples, sharp eyes and all that stuff you'd expect from him. Aesthetic gradient embedding included, helps a lot to use, nails the style significantly further if you can find good settings...
-
Hypernetwork trained on mikozin's art (reupload from 4chan section)
Trained in Nai-full-pruned, using swish activation method with dropout, 5e-6 training rate placing mikozin in the prompt will make it have a stronger effect has a number of effects, but mostly gives a very soft, painted style to the output image Aesthetic gradient embedding included, not necessary but could be neat! Data it was trained on included in the mega link, if you want something specific from the data it was trained on it'll help looking at the fileword txts
-
yabuki_kentarou(1,1_relu_5e-5)-8750
Source image count: 75 (white-bg, hi-res, and hi-qual) Dataset image count: 154 (split, 512x512) Dataset stress test: excellent (LR 0.0005, 2000 steps) Model: NAI [925997e9] Layer: 1, 1 Learning rate: 0.00005 Steps: 8750
Collection of Aesthetic Gradients: https://github.com/vicgalle/stable-diffusion-aesthetic-gradients/tree/main/aesthetic_embeddings
- Scat (??): https://files.catbox.moe/8hklc5.pt
- Horse (?): https://files.catbox.moe/idm0vf.pt
- MLP nsfw f16 f32 (might be pickled): https://drive.google.com/drive/folders/14JyQE36wYABH-0TSV_HBEsBJ3r8ZITrS?usp=sharing
If you have one of these, please get it to me
Embed:
- Omaru-polka: https://litter.catbox.moe/qfchu1.pt
- Sakimichan: https://mega.nz/file/eE8QDKrI#y7kdyWgPUjI4ZkY8PSq89F28eU_Vz_0EgTbG6yAowH8
Hypernetworks:
- Chinese telegram (dead link): https://t.me/+H4EGgSS-WH8wYzBl
- HiRyS: https://litter.catbox.moe/rx8uv0.pt
- Huge training from KR site: https://mega.nz/folder/wKVAybab#oh42CNeYpnqr2s8IsUFtuQ
- 焦茶 / cogecha hypernetwork, trained against NAI: https://mega.nz/folder/BLtkVIjC#RO6zQaAYCOIii8GnfT92dw
- 山北東 / northeast_mountain hypernetwork, trained against NAI: https://mega.nz/folder/RflGBS7R#88znRpu7YC1J1JYa9N-6_A
Datasets:
- expanded ie_(raarami) dataset: https://litter.catbox.moe/j4mpde.zip
- Toplessness: https://litter.catbox.moe/mttar5.zip
- https://gofile.io/d/R74OtT
- Onono imoko (NSFW + SFW, 300 cropped images): https://files.catbox.moe/dkn85w.zip
- thanukiart (colored): https://www.dropbox.com/sh/mtf094lb5o61uvu/AABb2A83y4ws4-Rlc0lbbyHSa?dl=0
- Training guide for textual inversion/embedding and hypernetworks: https://pastebin.com/dqHZBpyA
- Hypernetwork Training by ixynetworkanon: https://rentry.org/hypernetwork4dumdums
- Training with e621 content: https://rentry.org/sd-e621-textual-inversion
- Anon's guide: https://rentry.org/stmam
- Anon2's guide: https://rentry.org/983k3
- Full Textual Inversion folder: https://files.catbox.moe/c6502c.7z
- Wiki: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Textual-Inversion
- Wiki 2: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#textual-inversion
Use pics where:
- Character doesn't blend with background and isn't overlapped by random stuff
- Character is in different poses, angles, and backgrounds
- Resolution is 512x512 (crop if it's not)
-
Manually tagging the pictures allows for faster convergence than auto-tagging. More work is needed to see if deepdanbooru autotagging helps convergence
-
Dreambooth on 8gb: https://github.com/huggingface/diffusers/tree/main/examples/dreambooth#training-on-a-8-gb-gpu
-
Finetune diffusion: https://github.com/YaYaB/finetune-diffusion
- Can train models locally
-
Training guide: https://pastebin.com/xcFpp9Mr
-
Reddit guide: https://www.reddit.com/r/StableDiffusion/comments/xzbc2h/guide_for_dreambooth_with_8gb_vram_under_windows/
-
Reddit guide (2): https://www.reddit.com/r/StableDiffusion/comments/y389a5/how_do_you_train_dreambooth_locally/
-
Dreambooth (8gb of vram if you have 25gb+ of ram and Windows 11): https://pastebin.com/0NHA5YTP
-
Another 8gb Dreambooth: https://github.com/Ttl/diffusers/tree/dreambooth_deepspeed/examples/dreambooth#training-on-a-8-gb-gpu
-
Dreambooth: https://rentry.org/dreambooth-shitguide
-
Dreambooth: https://rentry.org/simple-db-elinas
-
Dreambooth (Reddit): https://www.reddit.com/r/StableDiffusion/comments/ybxv7h/good_dreambooth_formula/
-
Hypernetworks: AUTOMATIC1111/stable-diffusion-webui#2670
-
Runpod guide: https://rentry.org/runpod4dumdums
-
Small guide written on hypernetwork activation functions.: AUTOMATIC1111/stable-diffusion-webui#2670 (comment)
-
Dataset tag manager that can also load loss.: https://github.com/starik222/BooruDatasetTagManager
-
Tips on hypernetwork layer structure: AUTOMATIC1111/stable-diffusion-webui#2670 (comment)
-
Prompt template + info: https://github.com/victorchall/EveryDream-trainer
-
github + some documentation: https://github.com/cafeai/stable-textual-inversion-cafe
-
Documentation: https://www.reddit.com/r/StableDiffusion/comments/wvzr7s/tutorial_fine_tuning_stable_diffusion_using_only/
-
Site where you can train (I think): https://www.astria.ai/
-
Colab 3: https://github.com/XavierXiao/Dreambooth-Stable-Diffusion
-
Colab 4 (fast): https://github.com/TheLastBen/fast-stable-diffusion
-
GUI helper for manual tagging and cropping: https://github.com/arenatemp/sd-tagging-helper
-
Embed vector, clip skip, and vae comparison: https://desuarchive.org/g/thread/89392239#89392432
-
Hypernet comparison discussion: AUTOMATIC1111/stable-diffusion-webui#2284
-
Comparison of linear vs relu activation function on a number of different prompts, 12K steps at 5e-6.
-
Clip skip comparison: https://files.catbox.moe/f94fhe.jpg
-
Hypernetwork comparison: https://files.catbox.moe/q8h8o3.png
-
FIND COMPARISON OF ALL MODELS (self note)
-
Image Scraper: https://github.com/mikf/gallery-dl
-
Bulk resizer: https://www.birme.net/?target_width=512&target_height=512
-
Model merging math: https://github.com/AUTOMATIC1111/stable-diffusion-webui/commit/c250cb289c97fe303cef69064bf45899406f6a40#comments
-
Old model merging: https://github.com/eyriewow/merge-models
-
Model merge guide: https://rentry.org/lftbl
-
Supposedly empty ckpt to help with memory issues, might be pickled: https://easyupload.io/ggfxvc
-
Aesthetic Gradients: https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients
-
1 img TI: https://huggingface.co/lambdalabs/sd-image-variations-diffusers
-
You can set a learning rate of "0.1:500, 0.01:1000, 0.001:10000" in textual inversion and it will follow the schedule
-
Tip: combining natural language sentences and tags can create a better training
-
Training a TI on 6gb (not sure if safe or even works, instructions by uploader anon): https://pastebin.com/iFwvy5Gy
- Have xformers enabled.
This diff does 2 things.
- enables cross attention optimizations during TI training. Voldy disabled the optimizations during training because he said it gave him bad results. However, if you use the InvokeAI optimization or xformers after the xformers fix it does not give you bad results anymore. This saves around 1.5GB vram with xformers
>2. unloads vae from VRAM during training. This is done in hypernetworks, and idk why it wasn't in the code for TI. It doesn't break anything and doesn't make anything worse.
>This saves around .2 GB VRAM
>
>After you apply this, turn on Move VAE and CLIP to RAM and Use cross attention optimizations while training
- By anon:
No idea if someone else will have a use for this but I needed to make it for myself since I can't get a hypernetwork trained regardless of what I do.
https://mega.nz/file/LDwi1bab#xrGkqJ9m-IsqsTQNixVkeWrGw2HvmAr_fx9FxNhrrbY
That link above is a spreadsheet where you paste the hypernetwork_loss.csv data into A1 cell (A2 is where numbers should start). Then you can use M1 to set how many epochs of the most recent data you want to use for the red trendline (green is the same length but starting before red). Outlayer % is if you want to filter out extreme points 100% means all points are considered for trendline 95% filters out top and bottom 5 etc. Basically you can use this to see where the training started fucking up.
- Anon's best:
Creation: 1,2,1 Normalized Layers Dropout Enabled Swish XavierNormal (Not sure yet on this one. Normal or XavierUniform might be better)
Training:
Rate: 5e-5:1000, 5e-6:5000, 5e-7:20000, 5e-8:100000 Max Steps: 100,000
- Anon's Guide:
-
Having good text tags on the images is rather important. This means laboriously going through and adding tags to the BLIP tags and editing the BLIP tags as well, and often manually describing the image. Fortunately my dataset had only like...30 images total, so I was able to knock it out pretty quick, but I can imagine it being completely obnoxious for a 500 image gallery. Although I guess you could argue that strict prompt accuracy becomes less important as you have more training examples. Again, if they would just add an automatic deepdanbooru option alongside the BLIP for preprocessing that would take away 99% of the work.
-
Vectors. Honestly I started out making my embedding at 8, it was shit. 16, still shit but better. 20, pretty good, and I was like fuck it let's go to 50 and that was even better still. IDK. I don't think you can go much higher though if you want to use your tag anyway where but the very beginning of a 75 token block. I had heard that having more tokens = needing more images and also overfitting but I did not find this to be the case.
-
The other major thing I needed to do is make a character.txt for textual inversion. For whatever reason, the textual inversion templates literally have NO character/costume template. The closest thing is subject which is very far off and very bad. Thus, I had to write my own: https://files.catbox.moe/wbat5x.txt
-
Yeah for whatever reason the VAE completely fries and fucks up any embedding training and you can only find this from reading comments on 4chan or in the issues list of the github. The unload VAE when training DOES NOT WORK for textual embedding. Again, I don't know why. Thus it is absolutely 100% stone cold essential to rename or move your vae then relaunch everything before you do any textual inversion training. Don't forget to put it back afterwards (and relaunch again) because without the VAE everything is a blurry mess and faces and like sloth from the goonies.
So all told, this is the process:
-
Get a dataset of images together. Use the preprocess tab and the BLIP and the split and flip and all that.
-
Laboriously go through EVERY SINGLE IMAGE YOU JUST MADE while simultaneously looking at their text file BLIP descriptions and updating them with the booru tags or deepdanbooru tags (which you have to have manually gotten ahead of time if you want them), and making sure the BLIP caption is at least roughly correct, and deleting any image which doesn't feature your character after the cropping operation if it was too big. EVERY. SINGLE. IMAGE. OAJRPIOANJROPIanrpianfrpianra
-
Now that the hard parts over, just make your embedding using the make embedding page. Choose some vector amount (I mean I did good with 50 whatever), set girl as your initialization or whatever's appropriate.
-
Go to train page and get training. Everything on the page is pretty self explanatory. I used 5e-02:2000, 5e-03:4000, 5e-04:6000, 5e-05 for the learning rate schedule but you can fool around. Make sure the prompt template file is pointed at an appropriate template file for what you're trying to do like the character one I made, and then just train. Honestly, it shouldn't take more than 10k steps which goes by pretty quick even with batch size 1.
OH and btw, obviously use https://github.com/mikf/gallery-dl to scrape your image dataset from whichever boorus you like. Don't forget the --write-tags flag!
Vector guide by anon: Think of vectors per token as the number of individual traits the ai will associate with your embedding. For something like "coffee cup", this is going to be pretty low generally, like 1-4. For something more like an artist's style, you're going to want it to be higher, like 12-24. You could go for more, but you're really eating into your token budget on prompts then.
Its also worth noting, the higher the count, the more images and more varied images you're going to want.
You want the ai to find things that are consistent thematics in your image. If you use a small sample size, and all your images just happen to have girls in a bikini, or all with blonde hair, that trait might get attributed to your prompt, and suddenly "coffee cup" always turns out blonde girls in bikinis too.
- ie_(raarami): https://mega.nz/folder/4GkVQCpL#Bg0wAxqXtHThtNDaz2c90w
- Expanded (DEAD LINK): https://litter.catbox.moe/j4mpde.zip
- Toplessness: https://litter.catbox.moe/mttar5.zip
- Reine: https://files.catbox.moe/zv6n6q.zip
- Power: https://files.catbox.moe/wcpcbu.7z
- Baffu: https://files.catbox.moe/ejh5sg.7z
- tatsuki fujimoto: https://litter.catbox.moe/k09588.zip
Questions to add: What model is the best? How do i convert img1 to img2? What is the abs easiest way to download this? How do i speed up generation? what is a tokenizer? what is parsing? what is float 16? what is a vae?
What's all the new stuff?
Check here to see if your question is answered:
- https://scribe.froth.zone/m/global-identity?redirectUrl=https%3A%2F%2Fblog.novelai.net%2Fnovelai-improvements-on-stable-diffusion-e10d38db82ac
- https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac
- https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki
How do I set this up?
Refer to https://rentry.org/nai-speedrun (has the "Asuka test") Easy guide: https://rentry.org/3okso Standard guide: https://rentry.org/voldy Paperspace: https://rentry.org/865dy
AMD Guide: https://rentry.org/sdamd
- After setting stuff up using this guide, refer back to https://rentry.org/nai-speedrun for settings
What's the "Hello Asuka" test?
It's a basic test to see if you're able to get a 1:1 recreation with NAI and have everything set up properly. Coined after asuka anon and his efforts to recreate 1:1 NAI before all the updates.
Refer to
- AUTOMATIC1111/stable-diffusion-webui#2017
- Very easy Asuka 1:1 Euler A: https://boards.4chan.org/h/thread/6893903#p6894236
- Asuka Euler guide: https://imgur.com/a/DCYJCSX
- Asuka Euler a guide: https://imgur.com/a/s3llTE5
What is pickling/getting pickled?
ckpt files and python files can execute code. Getting pickled is when these files execute malicious code that infect your computer with malware. It's a memey/funny way of saying you got hacked.
- Automatic1111's webui should unpickle the files for you: https://github.com/AUTOMATIC1111/stable-diffusion-webui/search?q=pickle&type=commits
- https://docs.python.org/3/library/pickle.html
I want to run this, but my computer is too bad. Is there any other way? Check out one of these:
- Free online browser SD: https://huggingface.co/spaces/stabilityai/stable-diffusion
- https://promptart.labml.ai/playground
- https://novelai.manana.kr/
- https://boards.4channel.org/g/thread/89199040
- https://www.mage.space/
- https://github.com/TheLastBen/fast-stable-diffusion
- https://github.com/ShivamShrirao/diffusers/blob/main/examples/dreambooth/DreamBooth_Stable_Diffusion.ipynb
- visualise.ai
- Account required
- Free unlimited 512x512/64 step runs
- img2img with stable horde: https://tinybots.net/artbot
- Free, GPU-less, powered by Stable Horde: https://dbzer0.itch.io/lucid-creations
- Free crowdsourced distributed cluster for Stable Diffusion: https://stablehorde.net/
- https://creator.nightcafe.studio/
- Service of free image generation: Artificy.com
- Free for personal use
- We use all most fresh, models for example
- Different aspect ratios, predefined styles
- Fast and simple interface
- Social network features: make & share!
- Work in progress every day
- https://www.craiyon.com/
- DALL·E mini
- http://aiart.house
- HF demo list: https://pastebin.com/9X1BPf8S
Are there any alternatives to gradio for sharing my stuff online?
Try ngrok (https://ngrok.com/, recommended by anon)
- free
- custom links
- connection limit of ~60 users
- anon thinks it gives more control for the host over Gradio
Is there an invisible watermark?
If you're using AUTOMATIC1111's webui and referring to this: https://github.com/ShieldMnt/invisible-watermark#attack-performance, then no. The setting in the settings is never read.
- code not used in the commit that added the setting in the settings: https://github.com/AUTOMATIC1111/stable-diffusion-webui/commit/f98338faa84ecce503e68d8ba13d5f7bbae52730
How do I get more of a strong effect on my embedding?
(might be outdated info) Embeddings take your image and find tokens from the current model that match the image, and when you use the embedding, it called on those specific tokens. So, it really depends on what embedding you're trying to create (how close it is to the default model, how pronounced the imgs are, etc). Plus, you can always add more emphasis for more of an effect
How does the increasing prompt token limit work?
With the token counter for each word, let's say you have the prompt:
girl (1), blue (2),..., apple (74), banana (75), orange (76), kiwi (77)
The prompt would split after banana because banana consists of 1 token and the weights would reset to start from strong again. So it's basically like
girl (1), blue (2),..., apple (74), banana (75) AND orange (1), kiwi (2)
What is a vae?
Check out https://en.wikipedia.org/wiki/Variational_autoencoder TLDR: a filter that changes output
What is dreambooth?
- Read this for info: https://dreambooth.github.io/
What is difference merging/why is there a way to merge three models?
The first two models are merged using standard interpolation. The third model is for a difference merge.
- For models A, B, and C:
- The formula is A + (B - C) * (1 - M), where
- A is the model where the learning is going to be transfered
- B is the model that has been finetuned (trained) on a certain object
- C is the base model that was used to finetune B
- B-C is difference between B and C, which is added to A
- (1-M) is the multiplier > how much of the difference to add to A
- (1-M) is in the slider in the UI, where the slider being on the right makes (1-M) = 1
- The formula is A + (B - C) * (1 - M), where
How would distributed training work?
According to NeonTheCoder: "well a model trained ontop of another would be the same, plus added data, and slided data. if you subtract the original from that you should be left with the difference, and the new data. then if you add that ontop of another model, it should only be adding the difference it made from original SD to the target model, and the new data"
Basically: You train a model, subtract the original model so you only have the "trainings", then add the trainings to aonther model. This means you can delegate training tasks to different people and add up all the results.
Why doesn't my 4090 work?
You need to update your cuDNN or use an updated xformer. https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl Uploaded cuDNN files by anon (which means it might be pickled): https://pomf2.lain.la/f/5u34v576.7z
- Goes into stable-diffusion-webui\venv\Lib\site-packages\torch\lib if you're using venv, otherwise wherever your torch is installed.
What GPU should I buy?
Refer to https://docs.google.com/spreadsheets/d/1Zlv4UFiciSgmJZncCujuXKHwc4BcxbjbSBg71-SdeNk/. Generally, higher VRAM is better.
What does Stability AI's "no nudity" for their SFW model mean for us?
It's only speculation, but probably a loss in accurate anatomy and overall NSFW stuff. We can always train NSFW into the released model, though the quality will probably be worse than if Stability AI did it (thousands/millions of images vs billions of images).
What's the difference between an embedding and a hypernetwork?
By anon: Embeddings add new tokens to the vocabulary but leave the model unchanged, hypernet alters the behavior of the network itself within the layers - hypernet has a lot more capacity to change the behavior but you can obviously only have one active at once
Why does my output differ from someone else's output?
Check to see if your settings match theirs. Also, using an optimization such as lowvram, medvram, and xformers will cause variations in outputs.
Hi-res generations are affected by the video card used * https://desuarchive.org/g/thread/89259005/#89260871
Why do I keep getting/how do I fix a black output when using .vae with the NAI model?
Using --no-half-vae will fix the random black images when using the .vae
How do you add upscalers?
Put the files into stable-diffusion-webui/models/ESRGAN or GFPGAN, it should say on https://upscale.wiki/wiki/Model_Database
How do you add embeddings?
Make a folder in your webui install (next to webui-user.bat) named embeddings > put your .pt and .bin embedding files here
Why are my faces blurry/messed up/ugly/deformed/etc.?
This could be because of a variety of things. Generally, to fix this, try generating at a higher resolution, using hi-res fix, inpainting your face normally, inpainting your face at full resolution, editing a good face on top of your face and img2img-ing, adding pretty face (or some variant) to the positive prompt and ugly face (or some variant) to the negative prompt, and making the ai focus more on the face with a closer shot (e.g. "portrait shot").
What is textual inversion?
Textual inversion makes the ai brute forces tags that it thinks matches your imgs and creates an embedding. Doing this on a subject in many situations (e.g. different environments and poses) generally allows the AI to create better embedding
Stuff doesn't work/is outdated!
Git pull or do a fresh install by git cloning into another folder. You can also git reset --hard [commit id], but be careful of overwriting your outputs/embeddings/models
What is ENSD?
ENSD is eta noise seed delta (in the settings). It shifts your seed and does some eta/sigma stuff. NAI uses 31337
Is the leaked NAI model safe?
The risk isn't 0, but there hasn't been any reports of getting hacked/pickled yet. Only you can decide if it's safe enough for you to use.
Is anything here safe??
Similarly, the risk isn't 0, but no one has gotten hacked from any links here as far I ask know.
Help! I need a prompt and I don't know where to start
Find a prompt someone else used and repurpose it for yourself. Think if what you like and just start writing tags/descriptions. If you need a tag but don't know the Danbooru equivalent, you can usually find it by searching danbooru [write what tag you want here]
How do I make better pictures?
For a general workflow:
- paint something really crude, it can literally be blobs of color
- img2img with a prompt
- edit original img or prompt or output input
- reimg2img/inpaint
- repeat last few steps until you get what you want
Step 1 can be replaced with just starting with a txt2img if you want the AI to decide for you
What is no-half and full precision?
Most new GPUs will use half precision since it lowers VRAM. Only use no-half and/or full-precision if you want to get the absolute best quality (minor difference) or if you are running a 16xx card.
How to inpaint?
- Good guide: https://rentry.org/drfar
- TLDR: Mask > describe ONLY the part you're inpainting > generate
Why doesn't inpainting work?
- Try running in incognito/private browsing mode, adblockers and certain plugins/extensions break inpainting
- Try refreshing/restarting the webui
How do you get NAI (NovelAI) 1:1?
Does order of prompts matter?
Yes, the order = priority that the AI will put in your img
How do I setup NAIFU?
Read the text file that tells you how to in the download
By anon: (Windows):
- Make sure you install Python and check "Add Python to PATH": https://www.python.org/downloads/windows/
- Download the naifu torrent from this link:https://rentry.org/sdg_FAQ#naifu-novelai-model-backend-frontend.
- Inside of the naifu folder, right click program.zip and click "extract here" with 7zip or WinRAR.
- Run setup.bat and let it finish.
- Run run.bat and once it's running, open a new browser window/tab and make sure that you type in http://localhost:6969/ into the address bar.
- Bada bing bada boom you should have the site running locally on your PC.
What upscaler should I use?
I recommend SD Upscaler, it adds details as well as upscales. For a while LSDR was regarded as the best, this might've changed though. Some anons like swinir, some like esrgan4x, ymmv
How do I know if X is loaded?
Ususally, the console will tell you. It will not tell you if hypernetworks or v2.pt is loaded
How do I update?
open command prompt in auto's folder and type "git pull". Or, right click in the folder, git bash here, git pull. To make sure you have the requirements, run "pip install -r requirements.txt" in the same fashion.
Recommended Settings (need to update this)?
- default NAI negatives: nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
- Supposedly adding "artist name" into here improves results
- Prefix all prompts with masterpiece, best quality
- Apparently NAI adds another hidden "masterpiece" after "best quality", but this might've been debunked already
For non-NAI models: Clip skip 0, everything else is good (afaik don't use hypernetworks, v2, yaml, VAE)
What are (parentheses), [brackets], {this thing}, <>, and decimals?
() is more emphasis, [] is less emphasis, {} is NAI's "implementation" of (), <> is for embeddings, decimals specify the number of ()'s so you don't need to type in a bunch.
(boobs) would have more weight than [boobs] in the final result, (boobs:1.4) would increase the boobage by ~40% more than what they would've normally been, (boobs:0.6) will decrease it by ~40%. If using multiple (parenthesis) instead of decimals, is changed by a multiplier of 1.1 with each new parenthesis >(n) = (n:1.1) >((n)) = (n:1.21) >(((n))) = (n:1.331) >((((n)))) = (n:1.4641) >(((((n)))) = (n:1.61051) >((((((n)))))) = (n:1.771561)
[n] = (n:0.9090909090909091)
[[n]] = (n:0.8264462809917355)
[[[n]]] = (n:0.7513148009015778)
[[[[n]]]] = (n:0.6830134553650707)
[[[[[n]]]]] = (n:0.6209213230591552)
[[[[[[n]]]]]] = (n:0.5644739300537775)
([prompt]:[number less than 1]) = [using this syntax] * I don't think decimals work with this syntax, it's undocumented in AUTOMATIC's wiki
2 of {} = 1 of (), accurate with a difference of <1%
by anon: exceeding 3x () or [] is less predictable and can overcook your prompt
How do you escape/use () for series names (or whatever is in () that isn't supposed to be weighted) in prompts?
- https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#prompt-editing
- character \(franchise\)
What is prompt editing?
- https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#prompt-editing
- Follows the format of [P1:P2:[step # to change from P1 to P2]]
- Good for creating a base with P1 and adding details with P2
- Loads one prompt for x steps, then runs the next prompt
- If the number is between 0 and 1, it's a fraction (percentage) of the number of steps after which to make the switch. If it's an integer greater than zero, it's just the step after which to make the switch.
- Example: The prompt is "a [fantasy:cyberpunk:16] landscape" The model will draw a fantasy landscape for 16 steps. After step 16, it will switch to drawing a cyberpunk landscape
What is AND?
AND combines prompts together:
A good metaphor to remember when prompting: P1 AND P2 AND P3 for 10 steps = P1 step 1, P2 step 2, P3 step 3, P1 step 4, etc... P1 step 10. It's good for combining two different prompts together, such as a background prompt and a subject prompt.
By kind anon: each prompt creates a "guidance" vector saying how to change the image to "match" the prompt, whatever that is, and AND makes you have TWO prompts pulling the image in different directions (that get added together)
What are negative prompts?
By kind anon: this is also how negative prompts work-- it computes how to change the image to go towards the negative prompt, and SUBTRACTS that to move away from it
What are positive prompts?
- Positive prompts calculate how much each step should move toward the positive prompt. Adding weights increases how much towards (or past) the positive prompt the AI will travel
What's my best option if I want to imitate a specific artstyle?
You could try finding someone similar, doing textual inversion, or describing the artsyle (eg thick stroke, lineart, etc.)
**What are hypernetworks, VAE, v2.pt, etc? **
Hypernetworks are like styles for your generation
VAE's fix faces and eyes, is generally good, but seems to dull colors
- Disable if training
v2.pt censors and generally changes the whole composition. a lot of people don't like it
yaml doesn't seem to do anything except double ram usage
What is Deep Danbooru?
Deep Danbooru is an autotagger. The AI automatically finds Danbooru tags that it thinks matches the picture it's given. To activate it
- git pull, edit webui-user.bat
- add the --deepdanbooru argument to webui-user.bat so it looks like COMMANDLINE_ARGS=--deepdanbooru
- find the interrogation change in img2img.
How do I get NAIFU to automatically save images for me?
Edit run.bat. Ctrl + f to "export SAVE_files". Remove the "::" and change the word from export to set.
How do you load the VAE?
Rename it to [your model's name here].vae.pt and put it next to your model in the models/Stable-diffusion folder
How do you load hypernetworks?/How do you use hypernetworks?
create a hypernetworks folder in the models folder and place all the .pt files there
How do you load the v2.pt?
place the v2.pt in the same folder as your webui-user.bat file (the root folder) and add https://rentry.org/nai-prior-v2 into your scripts folder (rename the text file to [anything].py
How do you load the yaml?
It's not recommended to load the yaml because it doubles ram for no change in output, but if you really want to, rename it to [model name].yaml and place it next to your model.
Asukaimguranon: I will report that the yaml didn't double my vram usage outright, but i experienced something like a memory leak because it oom crashed after a dozen gens at most (compared to non-yaml for hundreds of gens no problem). the gens i did get matched non-yaml 1:1 so there's basically no reason to use yaml ever.
What are wildcards?
by anon: wildcard just lets you create a text file with a list of prompt words, and then you reference that text file to randomly pick from it, so you could randomize hair color, or pose, specific character, etc
Where do you get wildcards?
Got this info from a kind anon in hdg: Search archive or git for wildcard pastebin and copy what you want. Then, download wildcards.py from AUTOMATIC1111's wiki. Place script + pastebin text files (which are in a folder named wildcards, the text files are named [wildcard name here].txt) in /scripts. Activate wildcards in AUTO's gui. In a prompt, you would write [wildcard name here] to choose a random name from that txt file. To use weights: ([wildcards name here]:[weight amount])
-
Example wildcards: https://github.com/jtkelm2/stable-diffusion-webui-1/tree/master/scripts/wildcards
-
Dump: check links
What is interpolation when merging models?
It determines how much of each model is in the output model. if number is 40 for linear: 40% primary, 60% secondary. If number is 40 for sigmoid or inverse sig, this percent is weighted according to the graphs. sigmoid: primary checkpoint gets less weight than if using weighted sum. inverse sigmoid: opposite to sigmoid
- https://archived.moe/g/thread/89007676#89008490
- Calculate values yourself: https://github.com/AUTOMATIC1111/stable-diffusion-webui/commit/c250cb289c97fe303cef69064bf45899406f6a40#comments
- Graph + Info: AUTOMATIC1111/stable-diffusion-webui#2658 (comment)
Can you make X?
If you're creative enough, probably. If it was trained on that, definitely
TLDR of everything: https://rentry.org/sd-tldr Current Issues: https://rentry.org/sd-issues
Info:
- Detailed 1:1 setup NAI + current news: AUTOMATIC1111/stable-diffusion-webui#2017
- Very easy Asuka 1:1 Euler A: https://boards.4chan.org/h/thread/6893903#p6894236
- Asuka Euler guide: https://imgur.com/a/DCYJCSX
- Asuka Euler a guide: https://imgur.com/a/s3llTE5
- Beginner's Guide: https://rentry.org/nai-speedrun
- SD NAI FAQ: https://rentry.org/sdg_FAQ
- general wiki: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki
- general wiki 2: https://wiki.installgentoo.com/wiki/Stable_Diffusion
- general wiki 3: https://github.com/Maks-s/sd-akashic
- general wiki 4: https://github.com/awesome-stable-diffusion/awesome-stable-diffusion
- setup guide: https://rentry.org/voldy
- Easy to setup Standard Diffusion: https://nmkd.itch.io/t2i-gui
- Another easy to setup SD: https://github.com/cmdr2/stable-diffusion-ui
- Models: https://rentry.org/sdmodels
- Japanese 4chan: https://may.2chan.net/b/
- Japanese 4chan 2: https://find.5ch.net/search?q=JNVA%E9%83%A8
- Japanese 4chan 3: http://nozomi.2ch.sc/test/read.cgi/liveuranus/1666357371/355-
- General info: https://rentry.org/sd-nativeisekaitoo
- Guide: https://github.com/Engineer-of-Stuff/stable-diffusion-paperspace/blob/main/docs/archives/VOLDEMORT'S%20GUI%20GUIDE%20FOR%20THE%20MENTALLY%20DEFICIENT.pdf
- NAI info: https://pastebin.com/cExyWkgy
- GPU buying guide: https://rentry.org/stablediffgpubuy
- CSP SD: https://github.com/mika-f/nekodraw
- Link collection: https://github.com/pomee4/SD-LinkList
- debug guide: https://rentry.org/pf98i
Boorus:
- Danbooru: danbooru.donmai.us/
- Gelbooru: https://gelbooru.com/
- AIBooru: https://aibooru.online/
- Booru Site: https://infinibooru.moe/
- Local (classic): hydrusnetwork.github.io/
- AI art here: https://e-hentai.org/g/2343153/b4ce2a4b0b
- Easy to setup booru/image gallery by anon, highly recommended: https://github.com/demibit/stable-toolkit
- Simple: https://www.irfanview.com
- SFW: https://nastyprompts.com/
- Infinibooru: https://infinibooru.moe/posts
- Betabooru: https://betabooru.donmai.us
- Japanese pixiv for ai art: https://www.chichi-pui.com/
- discord anon (allows for generation?, runs NovelAI model): https://pixai.art/
- nsfw: https://pornpen.ai/
- /vt/ collection, updated: https://mega.nz/folder/j2AgSB6Y#3Kcq-xms0fWU4na-aaTFhA/folder/unw2EIBI
Upscalers:
- Big list: https://upscale.wiki/wiki/Model_Database
- anon recommended this: https://arc.tencent.com/en/ai-demos/imgRestore
- Anime: https://github.com/bloc97/Anime4K
- https://github.com/nihui/waifu2x-ncnn-vulkan
- Some: https://mega.nz/folder/3Jo2AAAa#4CGEwUM0dKu3kkaJa-qUIA
- online: https://replicate.com/xinntao/realesrgan
- anime: https://files.catbox.moe/c6ogfl.pth
- ultrasharp: https://mega.nz/folder/qZRBmaIY#nIG8KyWFcGNTuMX_XNbJ_g
- Waifu2x: https://github.com/nagadomi/waifu2x
- Gigapixel AI: https://www.topazlabs.com/gigapixel-ai
Face restoration
Batch resize:
Git pull/revert guide:
Horde: https://stablehorde.net
A prompt dump: https://pastebin.com/rbrtPCqZ
Part 1 NAI (with all the trackers I can find):
magnet:?xt=urn:btih:5bde442da86265b670a3e5ea3163afad2c6f8ecc&dn=novelaileak&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2F9.rarbg.com%3A2810%2Fannounce&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A6969%2Fannounce&tr=http%3A%2F%2Ftracker.openbittorrent.com%3A80%2Fannounce&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=https%3A%2F%2Fopentracker.i2p.rocks%3A443%2Fannounce&tr=udp%3A%2F%2Ftracker.torrent.eu.org%3A451%2Fannounce&tr=udp%3A%2F%2Ftracker.tiny-vps.com%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.pomf.se%3A80%2Fannounce&tr=udp%3A%2F%2Fp4p.arenabg.com%3A1337%2Fannounce&tr=udp%3A%2F%2Fopen.stealth.si%3A80%2Fannounce&tr=udp%3A%2F%2Fopen.demonii.com%3A1337%2Fannounce&tr=udp%3A%2F%2Fmovies.zsw.ca%3A6969%2Fannounce&tr=udp%3A%2F%2Fipv4.tracker.harry.lu%3A80%2Fannounce&tr=udp%3A%2F%2Fexplodie.org%3A6969%2Fannounce&tr=udp%3A%2F%2Fexodus.desync.com%3A6969%2Fannounce&tr=udp%3A%2F%2Fbt.oiyo.tk%3A6969%2Fannounce&tr=https%3A%2F%2Ftracker.nanoha.org%3A443%2Fannounce&tr=https%3A%2F%2Ftracker.lilithraws.org%3A443%2Fannounce&tr=https%3A%2F%2Ftr.burnabyhighstar.com%3A443%2FannouncePart 2 NovelAI Leak: https://rentry.org/ewahd
not sure what this is: https://rentry.org/naifunya UNPICKLER: https://rentry.org/safeunpickle2 Prebuilt xformers: https://rentry.org/25i6yn img search: https://iqdb.org Chinese NAI: https://ai.nya.la/ Guide to setting up local NAI by chinese NAI:
https://telegra.ph/NovelAI-%E5%8E%9F%E7%89%88%E7%BD%91%E9%A1%B5UI%E5%90%8E%E7%AB%AF%E9%83%A8%E7%BD%B2%E6%95%99%E7%A8%8B-10-10Rebasin (alternative merging models): https://github.com/samuela/git-re-basin WD 1.3 Torrents: https://rentry.org/WDtorrents
learn ai (recommended by emad): https://www.fast.ai/ https://jalammar.github.io/illustrated-stable-diffusion/
- SDToolkit: all in one generator + upscaler
AMD Ubundo 20.04
Mac: try using invoke ai https://github.com/invoke-ai CPU (might be outdated): https://rentry.org/cputard
Danbooru dump: https://www.gwern.net/Danbooru2021
Outdated training: https://rentry.org/informal-training-guide even more outdated: https://rentry.org/dq6vm
Free browser SD: https://huggingface.co/spaces/stabilityai/stable-diffusion https://promptart.labml.ai/playground https://novelai.manana.kr/ https://boards.4channel.org/g/thread/89199040 https://www.mage.space/ https://github.com/TheLastBen/fast-stable-diffusion https://github.com/ShivamShrirao/diffusers/blob/main/examples/dreambooth/DreamBooth_Stable_Diffusion.ipynb visualise.ai
- Account required
- Free unlimited 512x512/64 step runs img2img with stable horde: https://tinybots.net/artbot Free, GPU-less, powered by Stable Horde: https://dbzer0.itch.io/lucid-creations
AMD Guide: https://rentry.org/ayymd-stable-diffustion-v1_4-guide
Furry dump from SD Labs server: https://e621.net/db_export/ 2.5 mill posts from e621 with source links and more detailed tag info>> https://mega.nz/file/kxN0zZSC#DaGsogjU_pURYxm1T7ZB8MOvjetuU2tRJBGpJ5m8bK4 Furry model tag counts >> https://mega.nz/file/AgdHDLLD#vERcoYTWGJguTsXmysbLq1NL_xBS8txQhVvPI5E3QKE
some 4chan alt afaik, maybe loli stuff: https://2chen.moe/tech/1909555?#bottom
Japanese chan: https://www.2chan.net/
Krita: https://github.com/Interpause/auto-sd-krita cool showcase: https://www.thispersondoesnotexist.com/
Voldy to NAI ui: https://pastebin.com/0NTMWFtb
- save this to the root directory as user.css
Book: https://github.com/joelparkerhenderson/stable-diffusion-image-prompt-gallery
Celebs: https://docs.google.com/spreadsheets/u/0/d/1IqXkYDXux97aU8Y5kqqBrBvCn3CLRDhMZ7lEWsAtwUc
Multi GPU: https://hastebin.com/raw/labumiyiqo
Barebones SD: https://github.com/AmericanPresidentJimmyCarter/stable-diffusion
Explorer thing: http://cybernetnews.com/find-replace-multiple-files Messy room: https://twitter.com/8co28/status/1583434494354210817
Video FPS interpolator: https://github.com/megvii-research/ECCV2022-RIFE Another Video interpolator (Flowframes): https://nmkd.itch.io/flowframes Another: https://film-net.github.io/
Alternatives: https://github.com/brycedrennan/imaginAIry https://www.stablecabal.org/
GPU speed comparison * https://lambdalabs.com/blog/inference-benchmark-stable-diffusion/
Proof of concept: https://www.cutout.pro/photo-animer-gif-emoji/upload (then paste part of the original tone o remove the watermark) For her Voice : https://www.neural-reader.com/tts/start https://webmshare.com/play/O95LA
Image manipulation and stuff: https://imagemagick.org/index.php
Cool "is my image ai?" detection test: https://ai.azunyan1111.com/
Tracker list: https://ngosang.github.io/trackerslist/
Sampler comparison paper: https://arxiv.org/pdf/2206.00364.pdf
e621 thing: https://furry.booru.org/
img2img thing: https://huggingface.co/spaces/pharma/sd-prism
classifier guidance info: https://benanne.github.io/2022/05/26/guidance.html
Twitter anons: https://pastebin.com/k00qiJbL
Facebook thing: https://github.com/facebookincubator/AITemplate
Info for quick links: you can put CLIP_stop_at_last_layers in the quick settings list to make it more easily accessible. (you can do this for any option by going into inspect element and finding the ID, ignoring the setting_ part: https://files.catbox.moe/2lcolb.PNG )
some colab: https://rentry.org/sd-colab-automatic
alt: https://github.com/n00mkrad/text2image-gui 1 click: https://github.com/cmdr2/stable-diffusion-ui
3d: https://github.com/ashawkey/stable-dreamfusion https://dreamfusion3d.github.io/ 3d gens: https://colab.research.google.com/drive/1706ToQrkIZshRSJSHvZ1RuCiM__YX3Bz#scrollTo=i5-MWEjfBjYx https://colab.research.google.com/drive/1706ToQrkIZshRSJSHvZ1RuCiM__YX3Bz?authuser=2#scrollTo=i5-MWEjfBjYx It's a bit more effort to set up, make sure you replace line 29 of main.py with
config = yaml.full_load(open(args.config, 'r'))
https://sketchfab.com/3d-models/low-poly-beretta-m9-c79ea90735b248e588d5be49809d7b34
installer, not sure if safe: https://github.com/EmpireMediaScience/A1111-Web-UI-Installer
clip stuff: https://laion-aesthetic.datasette.io/laion-aesthetic-6pls/
AI youtubers/guides:
- https://www.youtube.com/c/RoyalSkiesLLC
- https://www.youtube.com/c/NerdyRodent
- Making art: https://www.youtube.com/user/pjgalbraith
Slerp info: https://en.wikipedia.org/wiki/Slerp#Geometric_Slerp
AI Music: https://github.com/openai/jukebox/
booru thing: https://github.com/VivaLaPanda/infinibooru
KR thing: https://novelai.manana.kr/
some hosting thing: https://zguide.zeromq.org/ old thing: https://www.thispersondoesnotexist.com/
Clipart Studio plugin for lighting: https://nyatabe.booth.pm/items/4196349
AI showcase: AI 3D animation https://twitter.com/TREE_Industries/status/1578071996033863681 https://www.youtube.com/watch?v=-TS2iLhYP28 https://www.youtube.com/watch?v=8oIQy6fxfCA AI 3D models https://www.youtube.com/watch?v=5j8I7V6blqM https://www.youtube.com/watch?v=uM5NPodZZ1U AI voice acting https://www.youtube.com/watch?v=oQx4SyM_iH4 https://www.youtube.com/watch?v=ria6qt7UUN4 AI music https://www.youtube.com/watch?v=QN0DDD7B3oU AI coding https://www.youtube.com/watch?v=pdSfgRYy8Ao&t=878s https://www.youtube.com/watch?v=_9aN1-0T8hg AI video https://www.youtube.com/watch?v=PHRg241NjJA
Dance diffusion: https://github.com/pollinations/dance-diffusion
fun way to find out if you were used for training: https://haveibeentrained.com/
Cool showcase by anons: This one is simple but very pretty, shows you how incredibly simple but powerful this technology is. https://twitter.com/tori29umai/status/1586367798988587014
This one is a fuller demonstration, converting an older music video into a hand-drawn style, just compare the facial expressions of the old and new versions, especially starting from 2:50 https://www.bilibili.com/video/BV14D4y1r7NJ/
This one is a test of style-transfer, using the famous artist Kurehito Misaki's textual inversion (illustrator of Saekano) https://www.bilibili.com/video/BV1D14y1j7KL/
This one fuses Genshin and K-ON together https://www.bilibili.com/video/BV1JR4y1Q73a/
The is the latest tech demo, rendering multi characters, and complex actions https://www.bilibili.com/video/BV1B14y1575G
twitter anons: https://twitter.com/PorchedArt https://twitter.com/FEDERALOFFICER https://twitter.com/Elf_Anon https://twitter.com/ElfBreasts https://twitter.com/BluMeino https://twitter.com/Lisandra_brave https://twitter.com/nadanainone https://twitter.com/Rahmeljackson https://twitter.com/dproompter https://twitter.com/Kw0337 https://twitter.com/AICoomer https://twitter.com/mommyartfactory https://twitter.com/ai_sneed https://twitter.com/YoucefN30829772 https://twitter.com/KLaknatullah https://twitter.com/spee321 https://twitter.com/EyeAI_ https://twitter.com/S37030315 https://twitter.com/ElfieAi https://twitter.com/Headstacker https://twitter.com/RaincoatWasted https://twitter.com/RatmanScott https://twitter.com/Merkurial_Mika https://twitter.com/epitaphtoadog https://twitter.com/lillyaiart (good stuff) https://twitter.com/LeftGRGR
collection of papers to learn about this research from its inception: https://github.com/prodramp/DeepWorks/tree/main/12-Research-Papers https://www.lesswrong.com/posts/vJFdjigzmcXMhNTsx/simulators https://arxiv.org/abs/2110.13746
something: http://blog.dlprimitives.org/
some unpickle info: https://www.reddit.com/r/sdforall/comments/y5axt7/with_lots_of_models_appearing_due_merging_and/
webm from imgs: https://ffmpeg.party/webm-from-image-sequence/
Music AIs: https://soundraw.io/ https://boomy.com/ https://www.aiva.ai/ https://huggingface.co/spaces/fffiloni/img-to-music
vocal ai: https://twitter.com/fifteenai
text to speech ai (deepfake): https://fakeyou.com/
Gradio alternative: ngrok (https://ngrok.com/)
- free
- custom links
- connection limit of ~60 users
- anon thinks it gives more control
10/20 News
TLDR from reddit:
-
RunwayML releases the v1.5 model on their repo
-
Copyright takedown notice from StabilityAI
-
RunwayML CEO releases a slightly passive agressive message reminding that they have the right to release the model, which was created by a RunwayML Researcher and a University researcher. "Thanks" StabilityAI for the offered processing power
-
Emad (StabilityAI) responds on the Discord stating the copyright takedown notice was just a mistake. He states they have never prevented the release of a model, and they just want to make sure Stable Diffusion doesn't face legal issues. No word on the disagreement in itself, but it seems to imply that RunwayML disagreed on the way StabilityAI wanted to navigate the legal issues, and decided to just release the model.
-
Takedown notice: https://www.reddit.com/r/StableDiffusion/comments/y969ph/model_15_legal_investigation_and_takedown_warning/
-
CEO Statement: https://www.reddit.com/r/StableDiffusion/comments/y97ya0/official_response_on_sd_15_model_by_chris_at/
-
Link: https://www.reddit.com/r/StableDiffusion/comments/y960o8/stability_ai_issues_takedown_request_for/
we are so open guys, we have a clause in our employee contracts stating that they have the right to release any model they work on we've never stopped developers from releasing models btw we didn't issue a takedown request btw well ok, we did issue a takedown request, but it wasn't a LEGAL request ok? there was no leak btw guys everything is fine haha folk get so riled up! one of the lead researchers of the model leaked OUR model, what a pathetic publicity stunt!
Quick Rundown:
emad confirming censorship for 1.5, no more porn Might cause anatomical issues in released model. Non-issue for NSFW though, especially with model merging
Debunked, SD will probably release a SFW model before their 1.5 model because of legal issues
drama between emad and automatic1111 Emad issued a private and public apology over it AUTOMATIC v. StabilityAI:
- Summary: https://www.reddit.com/r/StableDiffusion/comments/y1uuvj/automatic1111_did_nothing_wrong_some_people_are/
- Funny, not sure if real, apparently it is: AUTOMATIC1111/stable-diffusion-webui#2509
- Control given back to community: https://www.reddit.com/r/StableDiffusion/comments/y1nc7t/rstablediffusion_should_be_independent_and_run_by/
- Mod's story: https://www.reddit.com/r/StableDiffusion/comments/y19kdh/mod_here_my_side_of_the_story/
- by anon: I think [StabilityAI] backpedaled a bit, offered to unban automatic. Offered to give control of community places back to the community.
- automatic1111's repo removed from pinned guide on r/stablediffusion
- all old mods on stable diffusion subreddit kicked and replaced by stabilityai members. Big discourse on corruption and true open-source training
Emad will supposedly not censor the expected Stability AI model release since SAI are only training their SFW model
- Conversation from AMA:
User: is it a risk the new models (v1.X, v2, v3, vX) to be released only on dreamstudio or for B2B(2C)? what can we do to help you on this?
Emad: basically releasing NSFW models is hard right now Emad: SFW models are training
User: could you also detail in more concrete terms what the "extreme edge cases" are to do with the delay in 1.5? i assume it's not all nudity in that case, just things that might cause legal concern?
Emad: Sigh, what type of image if created from a vanilla model (ie out of the box) could cause legal troubles for all involved and destroy all this. I do not want to say what it is and will not confirm for Reasons but you should be able to guess.
User: what is the practical difference between your SFW and NSFW models? just filtering of the dataset? if so, where is the line drawn -- all nudity and violence? as i understand it, the dataset used for 1.4 did not have so much NSFW material to start with, apart from artsy nudes
Emad: nudity really. Not sure violence is NSFW
By the question asker:
just want to clarify a misunderstanding that seems to have taken hold to do with 1.5 censorship i was the person asking emad about the clarifications about "extreme edge cases" and the difference between their NSFW and SFW models the context of that question was emad was speaking about how SFW models are easier to release right now because of potential legal issues with the NSFW models, and about training a separate set of SFW models the "extreme edge cases" question was about 1.5 specifically; as far as i understood it, 1.5 is one of their NSFW models and the "extreme edge cases" that they want to censor are cp, not all nudity the "SFW vs NSFW" question was about the distinction between two category of models that emad was referring to, the SFW models are separate and trained with most (all?) nsfw content filtered from the dataset, but not violence
of course i'm not trying to shill for them or anything, and we'll see the true extent of the censorship if/when they release the models, but at the very least this is what was actually said

Quick Rundown:
drama around models supposedly trained on CP
Don't download every random model link you come across
Whether the fed bait is an actual fed bait or not cannot be confirmed
Some anons theorize that the fed bait wasn't due to the ckpt but was due to glowie anon's scraper downloading actual CP from a torrent somewhere using a DHT search engine
An anon claims to have tested the fed bait and said that the output a worse version of another existing model. Whether this is true or not cannot be confirmed
Another anon's theory: "if he truly did get his acct taken down, he mentioned auto-scraping torrents, then it's possible the fed did have a honeypot or tracking on that particular torrent (but they didn't make the content), that seems the most likely to me. if this was all a hoax to spread panic about a particular torrent, he chose a relatively unknown torrent to do it with, for example it would be explosive if he made these accusations about the original novelai torrent. he may be telling the truth, but he hasn't provided strong evidence backing up the full story, so there are a lot of grains of salt to be taken"
Editor's note: I shortened the fed bait PSA because it was not officially confirmed by sources other than by the owner of SD training and the 4channer who got baited. It also took up too much space at the top. The fed bait info was a huge dump in the first place because it was a copy paste of the announcement from the SD training server and I got confirmation from the owner of SD training, and, if the announcement was true, it was a relevant and timely warning to delete/avoid downloading the pickle model. Even if this whole thing turns out to be a huge troll by both the owner and the 4channer, this situation showcases the danger of downloading random files from the internet.
Given the severity of the situation, the fed bait warning will stay a PSA (for now) to keep people wary of random ckpts/pts/vaes they download.
That being said, future drama on this rentry will be confirmed by multiple sources before being posted at the top. For the unconfirmed drama, refer to https://rentry.org/sdupdates#unconfirmed-drama.
TLDR: fed allegedly uploaded ckpt of CP as a honeypot, anon downloaded it and got a warning from their seedbox who got a warning from Child Exploitation and Online Protection Command
!!! danger There are claims of a model trained on CP in the wild
It is alleged that these models were distributed by feds via torrents starting around October 11, 2022.
Similar (?) event last year: https://saucenao.blogspot.com/?view=classic
Original fed post:

Anon's statement: "one of our users was auto-scrapping every CKPT file on every tracker (pseudo) and they stumbled upon it, it had a weird name that literally nobody knew about until he searched on the 4chan archives and found what it was abt (pic related). then ofc he deleted it, and just a few minutes ago he told me he got a letter on his email from his seed box and it was abt "containing materials created and containing with sufficiently sexually suggestive images of minors" and it seems it was a fed bait"
Email from seedbox company:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
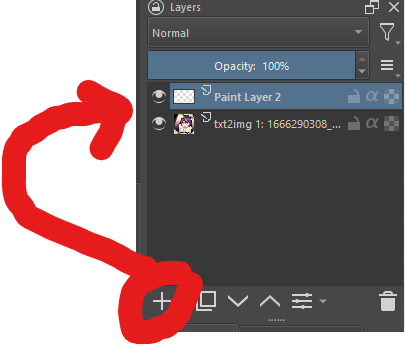{kind=link}
{kind=link}
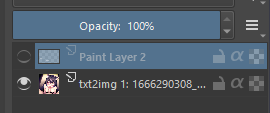{kind=link}
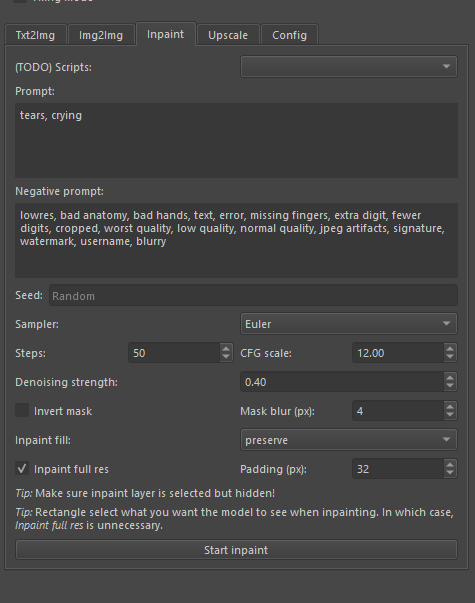{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
AUTOMATIC1111/Voldy: Best webui, for the people, madlad gigachad Leaker anon: Leaked NAI's imagen model + text gen Asuka anon: Large 1:1 NAI efforts before all the updates Booru anon: Self-hostable, intuitive, easy to setup booru Asuka Test Imgur anon: easy to follow guides, helping out the rentry Model anon: writing up https://rentry.org/sdmodels + helping out Glowie'd anon: first public fed bait Ixy anon: Good guide mogubro: A lot of hypernets. also cool name, very nice koreanon: legendary korean disciple
-> (WIP) Precursor to https://rentry.org/sdwiki / https://github.com/questianon/SDwiki <-
author socials: questianon !!YbTGdICxQOw (malt#6065, u/questianon, https://github.com/questianon, https://twitter.com/questianon), ping or tag if I need to change anything or if you have questions