{{ post.title }}
+{{ post.summary }}
+ + {% endif %} {% endfor %} +Computers only understand 0s and 1s, so first we need to understand [Number system](https://www.rapidtables.com/math/number/Numeral_system.html) ( Binary, Octal, Decimal and Hexadecimal)
Computers are good with 0s and 1s, but we need some other system to represent other symbols. [ASCII encoding](https://www.ascii-code.com/)
| +| **Day 2** |First you need to understand the device on which you will work. Since, it lets you know how exactly each instruction is executed at micro level.
Cover the complete [Computer Component](https://www.javatpoint.com/computer-components) and [Computer Memory](https://www.javatpoint.com/computer-memory) heading and all its subheadings.
| +| **Day 3** | Most of us use android in our day to day life. So, it becomes really important to have basic android fundamentals, which you can read [here](Network security is one of the most important aspects to consider when working over the internet, LAN or other method. While there is no network that is immune to attacks, a stable and efficient network security system is essential to protect client data. But, before that we need to know the network fundamentals, which you can cover [here](https://www.geeksforgeeks.org/computer-network-tutorials/).
Must cover BASICS and NETWORK SECURITY AND CRYPTOGRAPHY headings.
| +| **Day 5** | There are different methodologies used in the field of cybersecurity. To secure a system against a particular method you need to know it. You can read some of them [here](https://www.geeksforgeeks.org/types-of-hacking/). | +| **Day 6** |Before we proceed further, we need to know about [operating systems](https://www.techtarget.com/whatis/definition/operating-system-OS) and why to choose [linux over windows](https://www.mygreatlearning.com/blog/linux-vs-windows/).
[Here](https://www.stackscale.com/blog/popular-linux-distributions/), you can get an overview of the popular linux distros available. Now, you will [Install Kali Linux in VirtualBox](https://www.youtube.com/watch?v=irGTD6jmYhc)
| +| **Day 7** | Building and working with the fundamentals can be tedious sometimes. So, you need tools developed by cyber communities over years to tackle problems easily. You can learn about different [important tools](https://www.geeksforgeeks.org/top-10-kali-linux-tools-for-hacking/) that are used in the security field. | + +**TASKS:** + +1. Develop a Base 12 Number System +1. Convert your name (ASCII text) to base 2,8,10,12 and 16 number systems. +1. Identify network devices around you and figure what purpose it serves and how. +1. Install a different OS distro in the virtualbox, run some services and test it with the tools installed in the first OS. + +## Week 2: More on Linux, Python and Bash + +Throughout the journey exploring info-security the Linux operating system will play a very crucial role may it be from initially getting onto challenges or till the reverse engineering. And thus, it becomes important to have a good understanding of Linux - the basic commands, and thus, the Unix filesystem. + +And Python & bash are scripting languages and really helpful when it comes to automating the facilities of an existing system. This will be very useful, while searching for some critical keywords, in a very big file, for example. + +| **Days** | **Resources** | +| :------------ | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | +| **Day 1 & 2** |**Linux Fundamentals**
Basic commands: To access the Linux os from the terminal, you must know of some basic commands. Like given [here](https://preview.redd.it/isnefnt32wn21.jpg?auto=webp&s=b6c48a27ab33a3d428b554d278eba617e35bf3a2).
**Unix Filesystem**
When working with Linux, it becomes important to understand the filesystem and the hierarchy tree, this will be useful till RE as well.
Which can be covered from [here](https://homepages.uc.edu/~thomam/Intro_Unix_Text/File_System.html).
**OverTheWire: Bandit [[Link](https://overthewire.org/wargames/bandit/)]**
These are interesting level-based challenges that will help you learn useful commands! This will help you understand how powerful and useful the terminal is!
“... You will encounter many situations in which you have no idea what you are supposed to do. Don’t panic! Don’t give up! The purpose of this game is for you to learn the basics. Part of learning the basics is reading a lot of new information. …” [It is recommended to read through the instructions and man(ual) pages before getting started!]
| +| **Day 5** |**Python**
It will be used in scripting, like for searching some flags, when it will not be possible to do so manually.
Basic Python - [Link](https://www.w3schools.com/python/default.asp)
Python for scripting and automation: [Link](https://learn.microsoft.com/en-us/windows/python/scripting)
| +| **Day 6** |**Bash scripting**
Bash scripting is one of the easiest types of scripting to learn, and is best compared to Windows Batch scripting. Bash is very flexible, and has many advanced features that you won’t see in batch scripts.
Learn Bash scripting - see this [article](https://linuxhint.com/3hr_bash_tutorial/) or [check this](https://help.ubuntu.com/community/Beginners/BashScripting).
| +| **Day 7** |**Practising scripting**
Here are some examples on python scripting: [Link](https://linuxhint.com/python_scripts_beginners_guide/), you should try solving them on your own.
To practise bash scripting, you can check [this website](https://exercism.org/tracks/bash), it has some good exercises for practice, or [this](https://tryhackme.com/room/bashscripting) also.
| + +_Get familiar with Git fundamentals [Part 1](https://medium.com/programming-club-iit-kanpur/a-guide-to-git-the-fundamentals-2d3db6b4df53), [Part 2](https://medium.com/programming-club-iit-kanpur/a-guide-to-git-branches-and-merging-ae27f6b72f3b) , [article](https://www.freecodecamp.org/news/git-and-github-for-beginners/)_ + +_Learn regex - [tutorial](https://regexlearn.com/learn/regex101) OR [Video](https://www.youtube.com/playlist?list=PL4cUxeGkcC9g6m_6Sld9Q4jzqdqHd2HiD)_ + +## Week 3: Cyber Security and Web Exploitation + +Now after getting all your fundamentals cleared, let's dive into cyber security and its applications. This week will mainly focus on learning web exploitation. After the end of this week, you will be able to penetrate some loosely built websites and might even find bugs on IITK websites as well ?! + +| **Day** | **Resources** | +| :-------- | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| **Day 1** |What is **Web Exploitation** and what does it cover?
Now let's start learning languages such as HTML and JS which build up the client side of the web application. On the client side, HTML gives structure to the web application while JS gives logical code of how we can interact with it. Learn **HTML** from - [HTML playlist](https://www.youtube.com/playlist?list=PLr6-GrHUlVf_ZNmuQSXdS197Oyr1L9sPB)
Watching till 20 should be fine for now.
| +| **Day 2** |Do a crash course in **JS** - [JS crash course](https://www.youtube.com/watch?v=hdI2bqOjy3c)
MDN web doc reference for JS - [JS](https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/JavaScript_basics)
You will find MDN webdocs a great information source on how the web works. Also go through this video -
[Hacker101 - JavaScript for Hackers (Created by @STÖK)](https://youtu.be/FTeE3OrTNoA?t=120)
Learn **Fetch API** from this crash course [Fetch API](https://www.youtube.com/watch?v=Oive66jrwBs&t=0s) and from the MDN web docs - [Fetch API - MDN Web Docs](https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API)
Also try to learn the terms that you find new in the MDN web docs.
An important tool for web exploitation is the developer tools that almost all browsers provide. Here is a crash course on it -
**SQL** is the language for querying data from databases and that is where all information is stored. So a knowledge of SQL is important in interfering with these queries - [SQL tutorial](https://sqlzoo.net/wiki/SQL_Tutorial).
**PHP** is a server-side scripting language and a lot of old web applications are still using them. Crash Course on PHP - [PHP Crash Course for beginners | 2020](https://youtu.be/6mO1UA1r-6Q)
Refer to PHP docs - [PHP docs](https://www.php.net/manual/en/)
| +| **Day 4** |Now after spending the last two days solely learning, now let's try to apply our knowledge and that's how you actually learn hacking!
Here you can **apply your knowledge of JS** - [HTS](https://www.hackthissite.org/missions/javascript/)
Go to the JavaScript challenges and try to solve all of them.
**XSS attacks** are a type of injection attack in which a vulnerable website is manipulated so as to send malicious scripts to some other client’s browser - [XSS attacks](https://owasp.org/www-community/attacks/xss/)
Here is a game where you can try XSS attacks yourselves - [XSS game](https://xss-game.appspot.com/)
Often to exploit reflected XSS one would need a https endpoint which is provided by online websites like [RequestBin](https://pipedream.com/requestbin)
Another popular attack vector is **SQL injection** where the SQL queries that get data out of databases are interfered to take out data without proper authentication - [SQL injection](https://www.hacksplaining.com/prevention/sql-injection)
Know
| +| **Day 5** |**OWASP Top-10** lists the top-10 web application vulnerabilities in the present day so this is a must know information for people into web security - [OWASP Top-10](https://owasp.org/www-project-top-ten/)
[The TOP 10 VULNERABILITIES In Web Applications In 2022 | OWASP Top 10 Explained](https://youtu.be/xGecBCc3lEk)
**BurpSuite** is another handy tool for web exploitation. You can intercept and manipulate the requests sent from your browser and many more things! - [BurpSuite](https://linuxhint.com/burpsuite_tutorial_beginners/)
[Burpsuite Basics (FREE Community Edition)](https://youtu.be/G3hpAeoZ4ek)
**DVWA** (Damn Vulnerable Web Application) will let you discover various vulnerabilities and bugs on a MySQL+PHP-based web application.
First of all run the web application in a dockerized environment - [Installing Docker](https://docs.docker.com/engine/install/ubuntu/) + [DVWA docker image](https://hub.docker.com/r/vulnerables/web-dvwa/) [DVWA solutions](https://www.youtube.com/playlist?list=PLHUKi1UlEgOJLPSFZaFKMoexpM6qhOb4Q)
This is not to be done completely in a day but you should go on doing it at your own pace.
| +| **Day 6** |**Brute Forcing Web app authentication .**
**Web app authentication forms are easy targets for exploitation**
**Using either [BurpSuit](https://portswigger.net/support/using-burp-to-brute-force-a-login-page) or perhaps a more preferable method using [Hydra](https://www.freecodecamp.org/news/how-to-use-hydra-pentesting-tutorial/).**
| +| **Day 7** |Now getting better in web exploitation or any other application of cyber security is only through practice. Try solving the **OTW Natas** challenges - [Natas](https://overthewire.org/wargames/natas/) and solving various web-exploitation CTF challenges on picoCTF - [picoCTF](https://play.picoctf.org/practice).
Have a look at [CTF checklists](https://fareedfauzi.gitbook.io/ctf-checklist-for-beginner/web) to help you through these challenges.
Also you may find this liveoverflow playlist really informative - [Web Exploitation](https://www.youtube.com/playlist?list=PLhixgUqwRTjx2BmNF5-GddyqZcizwLLGP)
Whenever stuck remember Google Is Your Best Friend
| + +## Week 4: Cryptography + +| **Day** | **Resources** | +| :------------ | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| **Day 1** |Intro to **Cryptography** – refer [doc](https://docs.google.com/document/d/1zU-Yp7tQTTbbaXmVg2DIIyFojZfZ2QS4zvW0kdS80M8/edit#)
The main idea behind cryptography is to transform data into form which can only be understood by intended targets. Even if someone interferes in between, the information remains secure
There are many types of **cryptography techniques** some common ones are mentioned here -
- [Base encoding](https://code.tutsplus.com/tutorials/base-what-a-practical-introduction-to-base-encoding--net-27590)
- [Vigenere cipher](https://www.geeksforgeeks.org/vigenere-cipher/)
- [Caesar cipher](https://www.geeksforgeeks.org/caesar-cipher-in-cryptography/)
- [Morse code](https://www.youtube.com/watch?v=D8tPkb98Fkk)
- [Hashing Functions](https://www.tutorialspoint.com/cryptography/cryptography_hash_functions.htm)
- [Symmetric vs Asymmetric Encryption](https://www.javatpoint.com/symmetric-encryption-vs-asymmetric-encryption): [Video](https://www.youtube.com/watch?v=ERp8420ucGs)
| +| **Day 2** |Let’s do some **practice** on cryptography
- [OTW Krypton](https://overthewire.org/wargames/krypton/)
- [Picoctf](https://play.picoctf.org/practice?category=2&page=1)
Some tools - [dcode](https://www.dcode.fr/), [cyberchef](https://gchq.github.io/CyberChef/), [cryptolab](https://manansingh.github.io/Cryptolab-Offline/cryptolab.html), [xortool](https://github.com/hellman/xortool), [John the Ripper](http://www.openwall.com/john/), [Ciphey](https://github.com/ciphey/ciphey)**,**
| +| **Day 3** |To start with cryptography you can start with the following [cryptohack](https://cryptohack.org) modules :
- [Introduction to Cryptography](https://cryptohack.org/courses/intro/course_details/)
- [Modular Arithmetic](https://cryptohack.org/courses/modular/)
| +| **Day 4 & 5** |Let us proceed to one of the more practical aspect of cryptography [Public Key Cryptography](https://www.tutorialspoint.com/cryptography/public_key_encryption.htm)
- These [interactive exercises](https://cryptohack.org/courses/public-key/) are excellent for getting familiar with the different public key methods.
- Read some basic attacks on the RSA cryptosystem(Wiener's attack, Low public exponent attack, Partial key exposure, etc) For more attacks, check the RSA section of the following page:
Some more advanced topics in cryptography
- [Symmetric Cryptography](https://cryptohack.org/courses/symmetric/)
- [Elliptic Curve](https://cryptohack.org/courses/elliptic/)
- (optional) [Post Quantum Cryptography](https://www.youtube.com/watch?v=6qD-T1gjtKw) , [selected algorithms](https://csrc.nist.gov/projects/post-quantum-cryptography/selected-algorithms-2022), [exercises from cryptohack](https://cryptohack.org/challenges/post-quantum/)
| + +_You can try more challenges on [ Cryptopals](https://cryptopals.com/), [cryptohack](https://cryptohack.org/challenges/) & [picoCTF](https://play.picoctf.org/practice?category=2&page=1)._ + +## Week 5: Network Tools + +| **Day** | **Resources** | +| :---------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| **Day 1** |**Nmap** scans the network that a computer is connected to and outputs a list of ports, device names, operating systems, and several other identifiers that help the user understand the details behind their connection status.
This **[playlist](https://www.youtube.com/playlist?list=PLBf0hzazHTGM8V_3OEKhvCM9Xah3qDdIx)** will guide you on using nmap for scanning networks.
| +| **Day 2&3** |Wireshark is a packet sniffer and analysis tool. It captures network traffic from ethernet, Bluetooth, wireless, etc.., and stores that data for offline analysis.
**[Wireshark Playlist](https://www.youtube.com/playlist?list=PLBf0hzazHTGPgyxeEj_9LBHiqjtNEjsgt)**
**Challenges for practice:**
Challenge 1:
Challenge 2:
Challenge 3:
Challenge 4:
Challenge 5:
Challenge 6:
**Metasploi**t - World’s most used penetration testing framework used for both penetration testing and development platform for creating security tools and exploits.
Metasploit **- [playlist](https://www.youtube.com/playlist?list=PLBf0hzazHTGN31ZPTzBbk70bohTYT7HSm)**
| +| **Day 7** |**BeEF** - It utilizes the client side attack vectors to asses the security level of the target environment. Beef hacking involves hooking one or more web browsers and using them to launch command modules to attack the target system within the browser context
BeEF **- [video](https://www.youtube.com/watch?v=ZOOkeUnQsjk)**
| + +## Week 6: Forensics + +| **Day** | **Resource** | +| :-------- | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| **Day 1** |**Forensics:** The art of recovering the digital trail left on a computer. There are plenty of methods to find data which is seemingly deleted, not stored, or worse, covertly recorded.
[**Metadata**](https://youtu.be/HU_euJyxYB4), often described as data about data, helps in understanding the history of a particular electronic file, including when the file was created, modified and accessed, among other information that can be used to describe the file.
[File signatures](https://en.wikipedia.org/wiki/List_of_file_signatures), or magic numbers, are unique byte sequences at the start of files that identify their format or type. They allow systems to recognize file types reliably, independent of file extensions. For example, PDFs start with 25 50 44 46 2D, and JPEGs start with FFD8. Magic numbers are essential for file verification, security, and data recovery.
**Tools** :
[file](https://linux.die.net/man/1/file) (usually pre-installed) : used to determine file type
[strings ](https://linux.die.net/man/1/strings): print the strings of printable characters in files.
[binwalk](https://github.com/ReFirmLabs/binwalk/wiki/Quick-Start-Guide) : Analyze, reverse engineer, and extract firmware images.
[xxd](https://linuxhandbook.com/xxd-command/) : creates a hex dump of a given file or standard input. It can also convert a hex dump back to its original binary form.
[Hexeditor](https://github.com/chipmunk-sm/HexEditor) (alternatively [hexed.it](http://hexed.it) or [this](https://marketplace.visualstudio.com/items?itemName=ms-vscode.hexeditor)) : Used to read and edit the actual data in files, particularly the file headers.
[Exiftool](https://linux.die.net/man/1/exiftool) : Used to read and write meta information in files.
[Exiv2](http://www.exiv2.org/manpage.html): Image metadata manipulation tool.
| +| **Day 2** |**Image Forensics**
Watch this video for an intro to Image steganography:
[Least Significant Bit ](https://medium.com/@renantkn/lsb-steganography-hiding-a-message-in-the-pixels-of-an-image-4722a8567046) steganography.
**Tools:**
[Aperi'Solve](https://www.aperisolve.com/)– A fully automated tool designed to run forensics analysis over a massive amount of images
[Steghide](https://github.com/StefanoDeVuono/steghide) - Hide data in various kinds of images.
[Stegseek](https://github.com/RickdeJager/stegseek) - fast steghide cracker that can be used to extract hidden data from files
[Zsteg](https://github.com/zed-0xff/zsteg) - PNG/BMP analysis
[sherloq](https://github.com/GuidoBartoli/sherloq)
| +| **Day 3** |Some Beginner Challenges :
Challenge 1:
Challenge 2 :
Challenge 3:
**Audio Forensics**
[Audacity ](http://sourceforge.net/projects/audacity/)- Analyze sound files (mp3, m4a, whatever).
[Wavsteg](https://github.com/ragibson/Steganography#WavSteg) - python3 tool that can hide data and files in wav files and can also extract data from wav files
Audio Spectrograms:
[This tool ](https://www.sonicvisualiser.org/)can be used to manipulate and find data hidden in different channels of an Audio file.
[Here ](https://kamransaifullah.medium.com/milkshake-stenography-challenge-solution-de046379bff5) is a very simple example of the above tool in action.
Morse Code:
Conversion of Morse code from wav file: https://morsecode.world/international/decoder/audio-decoder-adaptive.html
DTMF :
A tool to extract keys being pressed in the DTMF tone can be extracted using [this tool](https://github.com/ribt/dtmf-decoder).
| +| **Day 5** |**Memory Forensics**
[Volatility](https://github.com/volatilityfoundation/volatility) [ For python3 : [volatility3](https://github.com/volatilityfoundation/volatility3) ]- A very popular memory forensic tool a very good guide to using it is available here :
[Part 1](https://westoahu.hawaii.edu/cyber/forensics-weekly-executive-summmaries/memory-ctf-with-volatility-part-1/) links to further parts can be found on the same website.
Note:Volatility Framework had a major revision with Volatility3 , multiple guides available on the internet still refer to the older version i.e. Volatility2 . Keep that in mind :)
[OfflineRegistryView](https://www.nirsoft.net/utils/offline_registry_view.html) : Tool for Windows that allows you to read offline Registry files from external drives.
[Extundelete ](http://extundelete.sourceforge.net/)- Used for recovering lost data from mountable images.
[Rekall ](https://github.com/google/rekall)– Memory Forensic Framework
A good collection of all forensic tools can be seen [here ](https://forensics.wiki/)
| +| **Day 6** |**Others**
[Stegsnow](https://www.kali.org/tools/stegsnow/) : Program for concealing messages in text files by appending tabs and spaces on the end of lines, and for extracting messages from files containing hidden messages.
[foremost](https://www.kali.org/tools/foremost/) : A tool for recovering files based on their headers, footers, and internal data structures.
gimp: A tool for editing images
[pdfcrack](https://www.kali.org/tools/pdfcrack/): A tool for recovering PDF passwords.
| +| **Day 7** | Try more challenges from [picoCTF](https://play.picoctf.org/practice?category=4&page=1), I am sure you will learn more things . | + +## Week 7: Binary Exploitation and Reverse Engineering + +This week we’ll be covering basic reverse engineering and binary exploitation. Before starting with this we recommend that you watch[ this video](https://www.youtube.com/watch?v=75gBFiFtAb8) to gain a basic understanding of what exactly you will be studying about. + +| **Day** | **Resources** | +| :--------------- | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| **Day 1** |**Reverse-engineering** is the act of dismantling an object to see how it works. Here, we’ll be dismantling the codes and applications.
[**Reverse Engineering Basics (click)**](https://docs.google.com/document/d/1kDLLi0rs76Vhkg7MpJs-LRanbmNUeJy6hsg9BuQFrJc/edit?usp=sharing)
- What is Reverse Engineering?
- Introduction to assembly - [intro](https://www.youtube.com/watch?v=4gwYkEK0gOk) , [x86 assembly](https://www.youtube.com/watch?v=75gBFiFtAb8)
- [Memory layout](https://aticleworld.com/memory-layout-of-c-program/)
- [Registers](https://www.youtube.com/watch?v=1GfMuBn6ZB0)
- Assembly Instructions
| +| **Day 2** |**Ghidra** is a software reverse engineering framework that helps in analysing and reversing software binaries, decompiling a software binary and studying the source code underneath.
- Installing Ghidra [Link](https://github.com/dannyquist/re/blob/master/ghidra/ghidra-getting-started.md) + [Link](https://htmlpreview.github.io/?https://github.com/NationalSecurityAgency/ghidra/blob/stable/GhidraDocs/InstallationGuide.html)
- Ghidra Getting started: [Video](https://www.youtube.com/watch?v=fTGTnrgjuGA&t=67s) (Linux) OR [Video](https://ghidra-sre.org/GhidraGettingStartedVideo/GhidraGettingStartedVideo.mp4) (Windows) OR [Video](https://www.youtube.com/watch?v=oTD_ki86c9I)
This playlist will guide you on Reverse Engineering with Ghidra: [Playlist](https://www.youtube.com/playlist?list=PL_tws4AXg7auglkFo6ZRoWGXnWL0FHAEi)**.**
| +| **Day 3** | Some interesting challenges archive - [Flareon challenges](https://github.com/fareedfauzi/Flare-On-Challenges/tree/master/Challenges) | +| **Day 4, 5 & 6** |**Binary Exploitation** - finding a vulnerability in the program and exploiting it to gain control of a shell or modifying the program’s functions.
Really [good series ](https://www.youtube.com/playlist?list=PLhixgUqwRTjxglIswKp9mpkfPNfHkzyeN)to understand how to actually perform binary exploitation.
The [walkthrough](https://guyinatuxedo.github.io/index.html) cover a lot of things,try to the chapters/challenges in following order: 1.4, 1.5, 1.6, 2.0, 2.1, 2.3, 2.4, 2.5, 2.8
You can also try **array indexing** and **bad seed** sections if you are curious.
Ever wondered why you use a format specifier in printf and not the variable directly like in python? Try out the **Format String** section.
| +| **Day 7** | Now that you are familiar with buffer overflow and writing payload using pwntools, you can do **[Ropemporium](https://ropemporium.com/)** challenges from 1 to 4 . | + +You can also try [this book](https://ir0nstone.gitbook.io/notes/types/stack/introduction) which covers a lot of topics in a concise manner. If you get confident in the above mentioned topics, try [microcorruption](https://microcorruption.com/). + +## Week 8: OSINT + +| **Day** | **Resource** | +| :-------- | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| **Day 1** |**OSINT**: Open source intelligence is the collection and analysis of data gathered from open sources like social media, news articles, company websites etc. to produce actionable intelligence.
Cyber criminals use OSINT to collect information on a target before attacking; also, OSINT can be used to help guess a user’s password.
**Sock Puppets**
Sock puppets, also known as research accounts, are online fictitious identities used to conceal the true identity of the OSINT investigator and to gain access to information that requires an account to access. Sock puppets are also created to isolate OSINT research, ensuring a separation between the personal and work lives of OSINT investigators.
This is **OPTIONAL** at introduction level, but a good practice!
How to create effective sock puppet, check
-
- [Art of the sock](https://www.secjuice.com/the-art-of-the-sock-osint-humint/)
-
Some Tools:
- Fake Name Generator:
- AI Generated face images:
**Search Engines**
- [Google](https://www.google.com/)
- [Advanced Google Search](https://www.google.com/advanced_search)
- [Search Guide](http://www.googleguide.com/print/adv_op_ref.pdf)
- [Yandex](https://yandex.com/)
- [Baidu](http://www.baidu.com/)
- [DuckDuckGo](https://duckduckgo.com/)
- [Bing](https://www.bing.com/)
Another **important tool** that is used in a lot of investigations is
**Image OSINT**
Have an Image and need to gather information about it ? Has it been posted anywhere before? What other similar images are on the internet?
Tools:
- [Google Image Search](https://images.google.com/)
- [Yandex Image Search](https://yandex.com/images/)
- [Tinyeye Image Search](https://tineye.com/)
Example OSINT on street art:
**Geolocation OSINT**
Have to figure out where in the world you may be, using a photo of that location !
Tools:
- [Google Maps ](https://www.google.com/maps)(another useful tool that it provides is the **Streetview**)
- [EarthCam](https://www.earthcam.com/): Webcams from around the world
- [N2YO](https://www.n2yo.com/): Satellite Tracker
- [Geoguessr](https://www.geoguessr.com/): browser-based geography game in which players are tasked to guess locations from Google Street View imagery.
- [PlonkIt](https://www.plonkit.net/guide): Very detailed guide to Geoguessing.
| +| **Day 4** |
**Social Media OSINT**
- [Twitter Advanced Search](https://twitter.com/search-advanced)
-
-
-
-
-
-
- Discord
-
- More tools:
-
-
**Github OSINT**
-
Other than these, Google Search and Wayback Machine are your best mates !
| +| **Day 5** |**Email and Password OSINT**
Tools:
-
-
-
-
-
-
-
**Username OSINT**
-
-
**People OSINT**
-
-
-
**PGP keys OSINT**
-
- [MIT PGP Public Key Server](https://pgp.mit.edu/)
**Cryptocurrency OSINT**
- [Etherscan](https://etherscan.io/)
- [Etherchain](https://etherchain.org/)
- [Blockchain explorer](https://www.blockchain.com/)
- [NFT Finder](https://www.nyckel.com/nft-finder/?)
**Dark Web**
-
-
- More Resources:
**Wireless Network OSINT**
-
Try some of the following challenges:
- [Sakura Room (TryHackMe)](https://tryhackme.com/room/sakura)
- [OhSINT room (TryHackMe)](https://tryhackme.com/room/ohsint)
- [SoMeSINT room (TryHackMe)](https://tryhackme.com/r/room/somesint)
-
-
+ +
 +
+ +
+ +
++ +
Other resources are as follows:- + +- [Medium Blog by Paritosh Mahto](https://medium.com/mlpoint/pandas-for-machine-learning-53846bc9a98b#:~:text=Pandas%20is%20one%20of%20the%20tools%20in%20Machine%20Learning%20which,transforming%20and%20visualizing%20from%20data.&text=Pandas%20is%20an%20open%2Dsource,Numpy%20developed%20by%20Wes%20McKinney.) +- [Pandas in 15 minutes](https://www.youtube.com/watch?v=tRKeLrwfUgU) + + + +### 👾 Day 6: Matplotlib - a powerful tool for visualization + +
+ +
+
+The average annual temperature above the industrial era around the globe
+
+ +Both of the above figures show the same data. However, it is easier to visualize and observe patterns in the second image. (A scatter plot) + +Matlotlib is a powerful library that provides tools (histograms, scatter plots, pie charts, and much more) to make sense of data. + +The best source to refer to is the +[documentation](https://matplotlib.org/stable/index.html) +in case of discrepancies. + +Below are the links to some valuable resources covering the basics of +Matplotlib:- + +- [Code With Harry](https://www.youtube.com/watch?v=VFsRLjSc8GA) +- [Free Code Camp](https://www.youtube.com/watch?v=3Xc3CA655Y4) + + + +### 👾 Day 7: Play around in Kaggle + +Use this day as a practice field, to utilize all your skills you learnt. Head over to [Kaggle](https://www.kaggle.com/) and download any dataset you like. Apply the skills you procured and analyze trends in different data sets.
Here is a brief walkthrough of the UI. +[All about Kaggle](https://docs.google.com/document/d/18zGKJEnq-ln1GkidD7Ueudm5iJOsHsMrhdHC7cTlAZc/edit?usp=sharing) + + +## 🦝 Week 2 (Basic Mathematics for ML, KNN, Linear Regression) + +
-
+Note, that I shall be constantly referring to Andrew NG's CS229 Course Lecture Videos , for they are the gold standard in any introductory Machine Learning course. The Lecture Notes of these course are pretty well made and can be referred to when needed. For additional notes, assignments, problem sets etc, refer the course site . Note that I shall not be always redirecting you to these videos since they are pretty mathematically rigorous. I shall be sometimes providing them as the main learning content, while other times adding them as Bonus Content, i.e. not having knowledge about those topics is completely fine but added knowledge and mathematical rigor will always help. In order to effectively absorb the videos, I recommend that you constantly refer to the overprovided lecture notes.
+
-
+Along with CS229, following are some great compilation of resources, which you can prolly explore in your free time or refer to if you're stuck at any topic:
+
- This website maintained by Aman Chadha contains comprehensive notes of most of the important Stanford ML Courses, Important Research papers and AI Resource Compilations. +
- YouTube channel StatQuest by Josh Starmer contains comprehensive tutorials on basic ML concepts, with great visualizations and intuition pumps. It's good for building logic, but does not gets into the mathematics behind ML. +
- The Website of Marius Hobbhahn contains some really insightful blogs which go into the depths of mathematics behind ML. He specifically covers Bayesian Machine Learning for that is his main research interest. + +
+ +
+
+ML Algorithms Classifications
+
+ +Apart from this classification, Machine Learning Algorithms can be broadly categorized into **Supervised, Unsupervised, Semi-Supervised and Reinforcement Machine Learning**. +In **_supervised machine learning_**, labeled datasets are used to train algorithms to classify data or predict outcomes accurately. This means that the data provided to you have some kind of label or information attached, and this label is the value which the Algorithm has to learn to predict. For instance, feeding a dataset with images of cats and dogs, with each image labelled as either a cat or a dog into an algorithm which learns how to classify an image into a cat or a dog will come under Supervised Machine Learning. + +**_Unsupervised machine learning_**, uses machine learning algorithms to analyze and cluster unlabeled datasets. These algorithms discover hidden patterns or data groupings without the need for human intervention. For instance, an algorithm which takes unlabeled images of cats and dogs as inputs, analyzes the similarities and differences between different types of images and forms clusters (or groups), wherein dogs belong to a given cluster and cats belong to another cluster is an example of unsupervised learning. This usually involves transforming the information, mapping the transformed information into some n-dimensional space and then using some similarity metrics to cluster the data. New data can be placed in the cluster by mapping it in the same space. + +As the name suggests, **_Semi Supervised learning_** lies somewhere between supervised and unsupervised learning. It uses a smaller labeled data set to guide classification and feature extraction from a larger, unlabeled data set. Semi-supervised learning can solve the problem of not having enough labeled data for a supervised learning algorithm. + +**_Reinforcement Learning algorithms_** form policies and learn via trial and error. Whether the policy is correct or wrong is determined via positive or negative reinforcements provided to the agent on completion of certain tasks (Similar to how you are appreciated when you get a great rank in JEE Advanced, but prolly scolded or beaten by your parents when you're caught consuming drugs; or you become happy when you get a text from a certain someone, but become dejected when you don't talk to them for a long time. Concept of reinforcement is derived from real life 🦝). This process can be discrete or continuous. For instance, building an agent to play games like Flappy Bird or Pokemon. + +For a better understanding of these classifications, refer to [this](https://www.geeksforgeeks.org/types-of-machine-learning/) article by GfG and [this](https://www.javatpoint.com/types-of-machine-learning) page by javapoint. + +Now that we have a high level idea of how the domain of Machine Learning looks like, let's start understanding some algorithms. + +#### 🐼K Nearest Neighbor Algorithm (KNN) + +
+ +
+
+KNN Algorithm
+
+ +KNNs are one of the first classification algorithms. Watch the first 5 videos of [this](https://youtube.com/playlist?list=PLBv09BD7ez_68OwSB97WXyIOvvI5nqi-3) playlist to know more. This would be a good point to implement the KNN Algorithm on your own, only using NumPy, Pandas and MatPlotLib. This will not only help you in understanding how the algorithm works but also help in building programming logic in general. + +Building algorithms from scratch is important, but using modules to implement algos is fast and convenient when an alteration in the algo is not required. Try to implement a KNN via SciKitLearn by following [this](https://www.digitalocean.com/community/tutorials/k-nearest-neighbors-knn-in-python) tutorial. + + + +### 👾 Day 5 and 6: Linear Regression and Gradient Descent + +#### 🐼 Hypothesis Function + +A hypothesis function was the function that our model is supposed to learn by looking at the training data. Once the model is trained, we are going to feed unseen data into hypothesis function and it is magically going to predict a correct (or nearly correct) answer! +The hypothesis function is itself a function of the weights of the model. These are parameters associated with the input features that we can tweak to get the hypothesis closer to the ground truth. + +#### 🐼 Cost Functions + +But how do we ascertain whether our hypothesis function is good enough? That's the job of the cost function. It gives us a measure of how poor or how wrong the hypothesis function is performing in comparison to the ground truth. Here are some commonly used cost functions: +https://www.javatpoint.com/cost-function-in-machine-learning + +Now, we have a function we need to minimize and a function (cost function) that we need to predict (hypothesis function). The Cost function usually draws a comparison between the actual result and the predicted result. Since the predicted result is obtained by puttin the values of the features in the hypothesis function, the cost function contains in it the hypotesis function. Moreover, since we are minimizing the cost function, it is intuitive to make its derivative zero in order to get the values for which minimum error (ie, minimum cost function) is achieved. This is done via an algorithm called Gradient Descent. + +#### 🐼 Gradient Descent + +
+ +
+
+Gradient Descent
+
+ +Gradient descent is simply an algorithm that optimizes the weights of the hypothesis function to minimize the cost function (i.e., to get closer to the actual output). Gradient Descent is used to minimize the objective function by updating the parameters (which are usually all the weights and biases of the neural network) in a direction of maximum descent. That is, the parameters are updated in the direction of the negative gradient of the objective function. The gradient of the parameters multiplied by the learning rate (which is a hyperparameter set usually via heuristic approaches like grid search or Bayesian optimization) is subtracted from the parameters, and this process is iterated until a minimum is reached. The learning rate determines the size of the steps taken. A larger learning rate can lead to skipping the minima and aimless oscillations throughout the function and a small learning rate can lead to a huge number of steps and an extremely high amount of training time. +A major problem with Batch Gradient Descent is that it performs redundant computations because it calculates the gradients for similar training examples before updating the parameters, hence increasing the training time. The problem of redundancy is solved by **Stochastic Gradient Descent**. + +#### 🐼 Stochastic Gradient Descent + +As opposed to Vanilla Gradient Descent, Stochastic Gradient Descent updates the parameters after evaluating the gradients for each training example. Hence, it updates the parameters before evaluating the gradient for other similar training examples in the dataset, so the training speed increases. +But, since only one training sample is used for a single update, the fluctuations in cost function over the epochs are very high. There is a lot of noise in the graph of Cost Function vs number of epochs but the smoothened graph is usually a reducing graph. + +It is easier for the SGD to reach a better minima due to a greater amount of fluctuations as opposed to Batch GD wherein the cost function reaches the nearest local minima. But these fluctuations can also lead to the function overshooting but this is usually solved by gradually reducing the learning rate towards the end of the training. Can we find a middle ground which captures the benefits of Stochastic as well as Vanilla Gradient Descent? + +#### 🐼 Mini Batch Gradient Descent + +Mini Batch Gradient Descent tries to incorporate the best of both, Batch GD and SGD by dividing the training dataset into smaller batches and then updating the parameters after evaluation of gradients of the training samples in each mini-batch. The updated parameters are the difference between the previous parameters and the product of the learning rate and average gradients of the training samples in the mini-batch. This approach reduces the variance which is observed in SGD which leads to stable convergence and is computationally more efficient than Batch GD as it updates the parameters more frequently. + +In future sections, we will dig deep into the problems which might arise during Gradient Descent and how the algorithm can be optimized. Now, since we have an idea about the fundamental concepts, let's delve into one of the simplest, yes widely used algorithm utilizing them: Linear Regression. + +#### 🐼 Linear Regression + +
+ +
+
+Linear Regression
+
+ +Go through [this](https://towardsdatascience.com/linear-regression-detailed-view-ea73175f6e86) article on linear regression. For a deeper intuition, watch [this](https://www.youtube.com/watch?v=1-OGRohmH2s) video. You can refer to [this](https://www.youtube.com/watch?v=IHZwWFHWa-w&ab_channel=3Blue1Brown), [this](https://www.youtube.com/watch?v=sDv4f4s2SB8&ab_channel=StatQuestwithJoshStarmer) and [this](https://www.youtube.com/watch?v=sDv4f4s2SB8&ab_channel=StatQuestwithJoshStarmer) for a better understanding of Gradient Descent. + +This would be a good time to program Linear Regression from scratch by only using Numpy, Pandas and MatPlotLib. Before that, in order to structure your code effectively, it is imporant to understand Object Oriented Programming, which you can learn from [here](https://www.datacamp.com/tutorial/python-oop-tutorial). Once you've gone through OOPs, you are ready to code your own linear regression model. Use [this](https://www.kaggle.com/datasets/harrimansaragih/dummy-advertising-and-sales-data) dataset for training and testing the model. + +Follow [this](https://www.dataspoof.info/post/everything-that-you-should-know-about-linear-regression-in-python/) article to understand the implementation using various libraries. If you are further interested, you may see _Statistics, 11th Edition_ by Robert S. Witte, Chapter 7. + +For those who are curious to delve into the intricacies and maths behind LR and GS, you can watch [this](https://youtu.be/4b4MUYve_U8?si=0baDG_bJF8gW_FeF) video by Andrew NG (Highly Recommended). + + + +### 👾 Day 7: Preparation for Next Week + +Towards the end of the week, let us revise some tools in linear algebra. [This](https://www.freecodecamp.org/news/how-machine-learning-leverages-linear-algebra-to-optimize-model-trainingwhy-you-should-learn-the-fundamentals-of-linear-algebra/#:~:text=Linear%20Algebra%20is%20the%20mathematical,as%20vectors%2C%20matrices%20and%20tensors.) has some motivation regarding the content. Revise Vectors, Dot Product, Outer Product of Matrices, Eigenvectors from MTH102 course lectures [here](https://drive.google.com/drive/folders/1DfKwYNYUWB_ALvCRtScFKGAJw3j00v0f). Revise some concepts on multivariable mathematics (MTH101) [here](https://home.iitk.ac.in/~psraj/mth101/lecture_notes.html). + + + +## 🦝 Week 3 (EDA, Cross Validation, Regularizations) + +This week, we shall deviate a bit from Machine Learning Algorithms and learn about various techniques which help in making **ML Pipelines** more effective and improve the accuracy of the models. These include, but are not limited to **Exploratory Data Analysis, preprocessing techniques, Cross Validation and Regularizations**. + + + +### 👾 Day 1: Exploratory Data Analysis (EDA) + +Lets first understand the purpose of EDA in ML. The purpose of EDA as the name suggests is to understand the datasets, getting to know what useful comes out from it. Discovering patterns, spotting anomalies etc are also its part. It becomes very essential to do EDA For better understanding lets go through the articles below. + +- [https://www.ibm.com/topics/exploratory-data-analysis](https://www.ibm.com/topics/exploratory-data-analysis) +- [https://www.analyticsvidhya.com/blog/2021/08/exploratory-data-analysis-and-visualization-techniques-in-data-science/](https://www.analyticsvidhya.com/blog/2021/08/exploratory-data-analysis-and-visualization-techniques-in-data-science/) +- [This](https://www.youtube.com/watch?v=QiqZliDXCCg) video goes well with the first link. +- Finally see [this](https://www.analyticsvidhya.com/blog/2021/08/how-to-perform-exploratory-data-analysis-a-guide-for-beginners/) to understand how to do EDA. + For Practice you can surely try doing EDA on datasets available on Kaggle. + + + +### 👾 Day 2: Visualizing things with Seaborn + +
+ +
+
+Seaborn Plots
+
+ +Seaborn is a robust Python library designed for data visualization, built on top of Matplotlib. It offers a high-level interface for creating visually appealing and informative statistical graphics, making it an ideal tool for exploratory data analysis (EDA). With Seaborn, you can generate complex visualizations with minimal code, allowing you to focus more on deriving insights from the data rather than on coding details. The library includes built-in themes and color palettes that enhance the visual quality of your plots effortlessly. + +Seaborn simplifies the creation of common plot types such as histograms, bar charts, box plots, and scatter plots, while also providing advanced visualization options like pair plots, heatmaps, and violin plots. These advanced techniques are particularly useful for uncovering relationships and patterns within the data. Seamlessly integrating with Pandas data structures, Seaborn makes it easy to visualize data frames directly. Overall, Seaborn is an essential tool for data scientists and analysts, significantly improving their ability to understand and communicate data insights effectively. + +The best source for learning about a python library is always its official Documentation. [Here](https://seaborn.pydata.org/) is its link. +Sometimes it may feel complicated and difficult to directly learn from the documentation. To ease the process. First go through the below links and for further learing, doubts or assistance refer to the documentation. + +- [https://www.geeksforgeeks.org/introduction-to-seaborn-python/](https://www.geeksforgeeks.org/introduction-to-seaborn-python/) +- You can see [this](https://www.datacamp.com/tutorial/seaborn-python-tutorial) or [this](https://elitedatascience.com/python-seaborn-tutorial) whichever seems better to you. These are tutorials for Seaborn. +- If looking for a youtube tutorial [this](https://www.youtube.com/watch?v=6GUZXDef2U0) may help. + When you are done and confident you can surely try applying your learnt skills on kaggle datasets. + + + +### 👾 Day 3: Data Preprocessing + +Data preprocessing involves transforming raw data into a format suitable for analysis and modeling. This step is crucial as it improves the quality of data and enhances the performance of machine learning models. More then just quality and performance, it is sometimes necessary to preprocess data so that we can feed it in machine learning pipeline or else errors pop around while running the code. +Important practices under Data Preprocessing include + +- Handling Missing Values: Missing data can introduce bias and reduce the accuracy of your machine learning models. Ignoring missing values can lead to misleading results because most algorithms are not designed to handle them. Properly addressing missing values ensures the integrity of your dataset and enhances the performance of your models. Follow [this](https://www.analyticsvidhya.com/blog/2021/10/handling-missing-value/) to understand how to do it. +- Data Transformation: Most machine learning algorithms require numerical input. Categorical data needs to be converted into a numerical format to be processed by these algorithms. Encoding categorical variables allows the model to interpret and learn from the data correctly. For intro go through [this](https://www.akkio.com/post/data-transformation-in-machine-learning). Then you should read [this](https://www.geeksforgeeks.org/data-transformation-in-machine-learning/#google_vignette). Make sure to go through hyperlinks in the content of second link. + + + +### 👾 Day 4: Statistical Measures + +There are a few tools and statistical measures which are extremely important evaluating the accuracy and performance of machine learning model. Today we shall discuss about these measures. + +🐼 [Confusion Matrix](https://www.youtube.com/watch?v=Kdsp6soqA7o&list=PLblh5JKOoLUICTaGLRoHQDuF_7q2GfuJF&index=3) +🐼 [Sensitivity and Specificity](https://www.youtube.com/watch?v=vP06aMoz4v8&list=PLblh5JKOoLUICTaGLRoHQDuF_7q2GfuJF&index=6) +🐼 [Bias and Variance](https://www.youtube.com/watch?v=EuBBz3bI-aA&list=PLblh5JKOoLUICTaGLRoHQDuF_7q2GfuJF&index=6) +Bias and Variance are 2 particularly important metrics, used often in model evaluation and referred to multiple times throughout this roadmap, so I'd recommend you to go through the following resources as well for a better understanding: + +- [https://medium.com/@theDrewDag/finding-the-right-balance-between-bias-and-variance-in-machine-learning-750b188cb9d6](https://medium.com/@theDrewDag/finding-the-right-balance-between-bias-and-variance-in-machine-learning-750b188cb9d6) +- [https://towardsdatascience.com/understanding-the-bias-variance-tradeoff-165e6942b229](https://towardsdatascience.com/understanding-the-bias-variance-tradeoff-165e6942b229) + +If you don't understand certain sections, don't worry! You'll eventually develop an understanding as we progress through this journey. +🐼 [Precision, Recall and F1 Score](https://towardsdatascience.com/a-look-at-precision-recall-and-f1-score-36b5fd0dd3ec) +🐼 [ROC and AUC](https://www.youtube.com/watch?v=4jRBRDbJemM&list=PLblh5JKOoLUICTaGLRoHQDuF_7q2GfuJF&index=8) +🐼 [Entropy](https://www.youtube.com/watch?v=YtebGVx-Fxw&list=PLblh5JKOoLUICTaGLRoHQDuF_7q2GfuJF&index=11) +🐼 [Mutual Information](https://www.youtube.com/watch?v=eJIp_mgVLwE&list=PLblh5JKOoLUICTaGLRoHQDuF_7q2GfuJF&index=12) +🐼 [Odds](youtube.com/watch?v=ARfXDSkQf1Y&list=PLblh5JKOoLUICTaGLRoHQDuF_7q2GfuJF&index=17) and [Log Odds](https://www.youtube.com/watch?v=8nm0G-1uJzA&list=PLblh5JKOoLUICTaGLRoHQDuF_7q2GfuJF&index=18) + +You can also go through the following articles for understanding more metrics: + +- [12 Eval Metrics for ML](https://www.analyticsvidhya.com/blog/2019/08/11-important-model-evaluation-error-metrics/) +- [How to Choose Loss Functions](https://machinelearningmastery.com/how-to-choose-loss-functions-when-training-deep-learning-neural-networks/) +- [Intuition Behind Log Loss Score](https://towardsdatascience.com/intuition-behind-log-loss-score-4e0c9979680a) +- [Binary Cross Entropy and Log Loss](https://www.aporia.com/learn/understanding-binary-cross-entropy-and-log-loss-for-effective-model-monitoring/) + + + +### 👾 Day 5: Data Splits and Cross Validation + +Every Model has to be trained on some data and to evaluate how well it captures the generalized pattern, it is to be evaluate using an unexplored data. The train data is used for training, and test data is used for testing the model. +But what will you do if the model performs well on the training data but pathetically on the test data. Such a situation is called Overfitting wherein the model captures the patterns of the training data points very well, but the general pattern is not recognized. To prevent this, we can use the "validation" data set. The splitting of data into the train, validation and test datasets is called the train validation test split. + +This split helps assess how well a machine learning model will generalize to new, unseen data. It also prevents overfitting, where a model performs well on the training data but fails to generalize to new instances. By using a validation set, practitioners can iteratively adjust the model’s parameters to achieve better performance on unseen data. More on this later. On the basis of the need this split can be an 80-10-10, 70-15-15 or 60-20-20 split (usually a larger training set is preferred). + +There are certain values (formally called, parameters) for instance the batch size or step size in the case of linear regression which need to be manually set by the user before the training of the model. Such parameters are called Hyperparameters, and it is important to set them in such a manner that the model generalizes. The process of evaluating such values is called Hyperparameter tuning and is done via Cross Validation and iterative sampling. Cross Validation requires using the Validation Dataset to continuously validate the model during and select the best values of Hyperparameters. + +Watch [this](https://www.youtube.com/watch?v=bq4LytNAjjM) video to understand the theory behind hyper parameter tuning using cross validation, and [this](https://www.youtube.com/watch?v=ATnZmBxIvmQ) for implementing Cross Validation and Grid Search via SciKitLearn. + +Iterative Sampling for [Hyperparameter tuning](https://machinelearningmastery.com/scikit-optimize-for-hyperparameter-tuning-in-machine-learning/) can be done via various methods like Grid Search (Just brute forcing your way through all the values. This is very expensive in terms of time and might miss out certain values in case of continuous values since we'd need to have some step size), Randomized Search (Might be faster, but way more inefficient because as the name suggests, it's random) and Bayesian Optimization. + +Bayesian Optimization uses Bayes Theorem, Surrogate Functions and Gaussian Regression in order to predict the next best parameter value. It is fairly easy to implement via [SciKitLearn](https://scikit-learn.org/stable/modules/grid_search.html), but completely understanding the mathematics behind it might be pretty complex and can be skipped at this point. But for the stats and math enthusiasts, you can refer [this](https://towardsdatascience.com/a-conceptual-explanation-of-bayesian-model-based-hyperparameter-optimization-for-machine-learning-b8172278050f) article for understanding the theory and [this](https://machinelearningmastery.com/what-is-bayesian-optimization/) for implementing it from scratch. + +Bonus: Go through [CS229 lecture 8](https://www.youtube.com/watch?v=rjbkWSTjHzM&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU&index=8) on Data Splits, Models & Cross-Validation + + + +### 👾 Day 6: Regularization + +
+ +
+
+Under-fitting and Over-fitting
+
+Yesterday we learnt about overfitting and why it is bad for any Machine Learning model. To solve this problem, let's ask the question as to why overfitting occurs? Because it gives too much importance to the training data points and tries to fit a curve which passes through all the points. So, we need to reduce the importance given to these exact points and account for some sort of variance as well. This can be done by by adding a penalty term to the loss function, discouraging the model from assigning too much importance to individual features or coefficients. This technique is called Regularization. + +There primarily exist 3 types of regularizations: Lasso (L1), Ridge (L2) and Elastic Net (L1-L2) regularizations. The only difference amongst them is what kind of penalty term is added. + +[This](https://www.geeksforgeeks.org/regularization-in-machine-learning/) is a great article which would provide you a pretext (Bias, Variance, Overfitting, Underfitting) as well as explain the penalty terms of different types of regularizations. + +Now go back to the Linear Regression Model you built from scratch and try to incorporate these 3 regularizations (separately, obviously) in the model. Train them and compare the accuracies. Try to tune the regularization based hyperparameters using Bayesian Optimization and Cross Validation. What conclusion do you draw from the results and comparisons? Is the change in accuracy significant and in the positive direction? Why or why not? + + + +### 👾 Day 7: Bonus and Revision + +Week 4 will actively use the fundamentals covered in Week 2, so I'd recommend you to go through your notes and revise gradient descent and linear algebra. If you're confident with these topics, you can cover these bonus topics from [the second lecture of Stanford CS229](https://www.youtube.com/watch?v=het9HFqo1TQ). I've explained these topics in brevity for introduction, but **I recommend you to go through the lecture for understanding.** + +#### 🐼 Locally Weighted Regression + +If a target(output)-feature relationship is non linear, in that case linear regression produces low accuracy score because it can only capture linear relationships. One workaround could be manually adding a feature that is related non linearly with the initial feature (for instance, $x^n$). As you'd remember, this is called feature engineering and helps a lot in capturing non linearities. But the issue is that this requires a huge amount of EDA and the feature created might not be very accurate because this is a manual procedure. Hence, for these kinds of problems, we use locally weighted regression. + +In Locally weighted regression, if we want to predict the target (output value) for a given set of features (input vector), we try to fit our weights to minimize a loss function which a weighted loss function. This weight is determined by the proximity of a point to the given input vector. Since we are giving more weight to proximate point and the weight is exponential in nature with respect to distance, the likelihood of accuracy is less. Such type of learning algorithm is called a Parametric learning algorithm because the time required to make the prediction is proportional to the size of the training data. + +#### 🐼 Probabilistic Interpretation + +Have you other wondered why the Loss function we select is a **Mean Square Loss**? Why isn't this linear or cubic? You'd read at various places that this is to make it more computationally efficient, or to make the derivatives linear which makes things easy for us. This is correct but these are not the correct reasonings as to why Mean Square Loss is used, but these are just implications of using it. The correct reasoning is that when we use **Maximum Likelihood Estimation**. We chose the parameters (i.e. the weights) which maximize the Likelihood Function. Again, for mathematics and details, refer the video linked above. + + + +## 🦝 Week 4 (Naive Bayes, Logistic Regression, Decision Trees) + +By now you should have a grasp over what regression means. We have seen that we can use linear regression to predict a continuous variable like house pricing. But what if I want to predict a variable that takes on a yes or no value? For example, if I give the model an email, can it tell me whether it is spam or not? Such problems are called classification problems and they have very widespread applications from cancer detection to forensics. + +This week we will be going over three introductory classification models: **logistic regression**, **decision trees** and **Naive Bayes Classifiers**. Note that decision trees can be used for both: regression and classification tasks. + + + + + + + +### 👾 Day 1 - Logistic Regression + +#### 🐼 Logistic Regression Algorithm and Utility + +The logistic regression model is built similarly to the linear regression model, except that now instead of predicting values in a continuous range, we need to output in binary, i.e., 0 and 1. + +Let's take a step back and try to figure out what our hypothesis should be like. A reasonable claim to make is that our hypothesis is basically the probability that y=1 (Here y is the label, i.e., the variable we are trying to predict). If our hypothesis function outputs a value closer to 1, say 0.85, it means it is reasonably confident that y should be 1. On the other hand, if the hypothesis outputs 0.13, it means there is a very low probability that y is 1, which means it is probable that y is 0. Now, building upon the concepts from linear regression, how do we restrict (or in the immortal words of 3B1B - "squishify") the hypothesis function between 0 and 1? We feed the output from the hypothesis function of the linear regression problem into another function that has a domain of all real numbers but has a range of (0,1). An ideal function with this property is the **logistic function** which looks like this: + +[https://www.desmos.com/calculator/se75xbindy](https://www.desmos.com/calculator/se75xbindy). +Hence the name logistic regression. + +However, we aren't done yet. As you may remember we used the mean squared error as a cost function. However, if we were to use this cost function with our logistic hypothesis function, we run into a mathematical wall. This is because the resulting hypothesis as a function of its weights would become non-convex and gradient descent does not guarantee a solution for non-convex functions. Hence we will have to use a different cost function called binary cross-entropy. + +Have a look at these articles: + +- [https://bit.ly/3FAxwI5](https://bit.ly/3FAxwI5) +- [https://towardsdatascience.com/understanding-binary-cross-entropy-log-loss-a-visual-explanation-a3ac6025181a](https://towardsdatascience.com/understanding-binary-cross-entropy-log-loss-a-visual-explanation-a3ac6025181a) + +We can now use gradient descent. + +#### 🐼 Implementation in Python + +For a thorough understanding of how to use the above concepts to build up the logistic regression model refer to this article: +[https://towardsdatascience.com/logistic-regression-detailed-overview-46c4da4303bc](https://towardsdatascience.com/logistic-regression-detailed-overview-46c4da4303bc) + +One thing you must always keep in mind is that while learning about new concepts, there is no substitute for actually implementing what you have learnt. Come up with your own implementation for logistic regression. You may refer to other people's implementations. +This will surely not be an easy task but even if you fail, you will have learnt a lot of new things along the way and have gotten a glimpse into the inner workings of Machine Learning. + +Some resources to help you get started: + +- [https://github.com/SSaishruthi/LogisticRegression_Vectorized_Implementation/blob/master/Logistic_Regression.ipynb](https://github.com/SSaishruthi/LogisticRegression_Vectorized_Implementation/blob/master/Logistic_Regression.ipynb) +- [https://towardsdatascience.com/building-a-logistic-regression-in-python-step-by-step-becd4d56c9c8](https://towardsdatascience.com/building-a-logistic-regression-in-python-step-by-step-becd4d56c9c8) +- [https://realpython.com/logistic-regression-python/](https://realpython.com/logistic-regression-python/) + +Some datasets you might want to use to train your model on: + +- Iris Dataset - [https://archive.ics.uci.edu/ml/datasets/iris](https://archive.ics.uci.edu/ml/datasets/iris) +- Titanic Dataset - [https://www.kaggle.com/c/titanic/data](https://www.kaggle.com/c/titanic/data) +- Bank Marketing Dataset - [https://archive.ics.uci.edu/ml/datasets/bank+marketing#](https://archive.ics.uci.edu/ml/datasets/bank+marketing#) +- Wine Quality Dataset - [https://archive.ics.uci.edu/ml/datasets/wine+quality](https://archive.ics.uci.edu/ml/datasets/wine+quality) + +#### 🐼 Bonus + +For mathematical representation, you can watch the relevant sections of [the second lecture of Stanford CS229](https://www.youtube.com/watch?v=het9HFqo1TQ), and also explore **NEWTONS METHOD** for optimzation. + + + +### 👾 Day 2: Gaussian Discriminant Analysis and Naive Bayes + +Today's content is largely derived from [Lecture 5 of CS229](https://www.youtube.com/watch?v=nt63k3bfXS0&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU&index=6), so you're recommended to watch the lecture and refer to the notes. (Also, don't get fooled by the term "Naive", this algorithm is pretty smart; not as Naive as you 👾) + +#### 🐼 Generative v/s Discriminative Learning Algorithms + +The algorithms we've explored so far (Linear Regression, Logistic Regression) model $p(y|x;\theta)$ that is the conditional distribution of $y$ given $x$. These models try to learn mappings directly from the space of inputs $X$ to the labels are called discriminative learning algorithms. The alfgorithms which model $p(x|y)$ are called Generative Learning Algorithms. These Generative algorithms take a particular class label ($y$), and then learns how that class looks like ($x$) (essentially, $p(x|y)$). This when done iteratively helps the model to learn how the features of a given class look like. + +#### 🐼 Bayes Rule and it's applications + +Let's use some High School probability to work on Generative Learning Algorithms. +$p(x|y=1)$ models the distribution of features of class 1, and $p(x|y=0)$ models the features of class 0. Now we can calculate $p(x)$ using: + +$$ +p(x) = p(x|y=1)p(y=1) + p(x|y=0)p(y=0) +$$ + +Now, we use the good ol' Bayes Rule: + +$$ +p(y|x) = \frac{p(x|y)p(y)}{p(x)} +$$ + +#### 🐼 Gaussian Discriminant Analysis (GDA) + +We assume that $p(x|y)$ is distributed like the Multivariate Gaussian Distribution (A Multivariate form of the Bell Shaped Gaussian distribution). Refer to page 37 of [CS229 Notes](https://cs229.stanford.edu/lectures-spring2022/main_notes.pdf). This means: + +$$ +y \sim Bernoulli(\phi) +$$ + +$$ +x|y=0 \sim N(\mu_0, \Sigma) +$$ + +$$ +x|y=1 \sim N(\mu_1, \Sigma) +$$ + +Now, we can write the probability distributions, calculate the log likelihood (similar to what we did in the case of linear regression, and find the values of parameters which maximize the log likelihood). The final equation we get is: + +$$ +\Sigma = \frac{1}{n} \sum_{i=1}^{n} (x^{(i)}-\mu_{y^{i}})(x^{(i)}-\mu_{y^{i}})^T +$$ + +One disadvantage of GDA is that it can be sensitive to outliers and may overfit the data if the number of training examples is small relative to the number of parameters being estimated. Additionally, GDA may not perform well when the decision boundary between classes is highly nonlinear. + +For a better mathematical understanding, and differences between Logistic Regression and GDA, refer to the following article: +[https://aman.ai/cs229/gda/](https://aman.ai/cs229/gda/) +This article is highly inspired from the CS229 notes, but also includes additional visualizations and analysis, so itis pretty insightful. + +Moreover, this [website maintained by Aman Chadha](https://aman.ai/) contains comprehensive notes on most of the important Andrew NG courses, and Stanford ML courses, and a list of important ML papers. Fun Stuff. + +#### 🐼 Naive Bayes Classifier + +- The Naive Bayes classifier applies Bayes' theorem with the "naive" assumption of independence between every pair of features. +- In practice, we calculate the posterior probability for each class and choose the class with the highest probability as the predicted class. +- It is naive as is does not preserve the sentence order, "Hardik drinks water" and "water drinks Hardik" are same to it. +- Despite it being naive, it has been found to work well in tasks like spam detection and other binary classification tasks. + +#### Types of Naive Bayes Classifiers + +There are several types of Naive Bayes classifiers, each suited for different types of data: + +1. **Gaussian Naive Bayes**: Assumes that the continuous features follow a Gaussian (normal) distribution.[Gaussian Naive Bayes video]() +2. **Multinomial Naive Bayes**: Suitable for discrete data, such as word counts in text classification.[Multinomial Naive Bayes video](https://www.youtube.com/watch?v=O2L2Uv9pdDA) + +You can also go through these [Lecture Slides](https://www.cs.toronto.edu/~urtasun/courses/CSC411_Fall16/09_naive_bayes.pdf) after CS229 lecture notes if you find it difficult to comprehend. + +You can now go ahead and make your own Spam Mail Classifier using Naive Bayes Algorithm. +Tip: Reading about Laplace smoothing and Event models for text classification might help. + + + +### 👾 Day 3: Decision Trees + +
+ +
+
+Decision Tree
+
+ +Now let's move onto another interesting classification paradigm: the decision tree. Till now we have primarily looked into linear models, which are easily able to accurately model data which shows some form of linear pattern, or a pattern which is reducible to a linear problem. Today we shall be discussing a non-linear model. + +This model is even more powerful and intuitive than logistic regression. You have probably used a decision tree unconsciously at some point in your life to take a decision. You'd have come across a meme which claims that Machine Learning is nothing but a huge collection of _if statements_ and _for loops_ and learning about Decision Trees will reinforce that claim. I'm not a huge fan of putting memes in roadmaps and documents (largely because they mess up the formatting and it just takes away the seriousness; which might be ironic coming from me for I have randomly used raccoon emoticons in the doc 🦝, but that's a story for another day), so I'm not including it here but you get the point. + +For this topic, the main resource would be [this](https://www.youtube.com/watch?v=_L39rN6gz7Y&list=PLblh5JKOoLUKAtDViTvRGFpphEc24M-QH) playlist on classification and regression trees by the Musical ML Teacher: [Josh Starmer](https://www.youtube.com/@statquest) + +In case you aren't familiar with what a tree is have a look at [https://www.programiz.com/dsa/trees](https://www.programiz.com/dsa/trees) + +
+ +
+
+Above is a decision tree someone might use to decide whether or not to buy a specific car
+
+ +In an essence, you recursively ask questions (if-else statements) until you reach a point where you have an answer. In the dataset, we'll have a number of features, including continuous features and categorical features. How does the decision tree get to know what and how many questions to ask? More specifically the question(s) should be about which features(s)? Do we ask one question per feature or multiple questions? Do we ask any questions about a particular feature at all? And in which order should questions be asked? + +If you analyze these questions and how a human would answer these, you'd conclude that the answer to these questions is related to how much "information" do we gain about the output when we get the answer to a particular question. How do we quantify "information" mathematically such that we can use this "information metric" to somehow construct this tree. Statisticians have tried to encapsulate information objectively via certain metrics like Entropy, Gini Impurity, Information Gain etc. Go through the following articles before proceeding. + +- [Entropy in Machine Learning](https://www.javatpoint.com/entropy-in-machine-learning) +- [More on Entropy](https://www.analyticsvidhya.com/blog/2020/11/entropy-a-key-concept-for-all-data-science-beginners/) +- [Gini Index and Information Gain](https://medium.com/analytics-steps/understanding-the-gini-index-and-information-gain-in-decision-trees-ab4720518ba8) + +Moving on to how to build a decision tree, refer to the following: + +- [https://towardsdatascience.com/decision-trees-in-machine-learning-641b9c4e8052](https://towardsdatascience.com/decision-trees-in-machine-learning-641b9c4e8052) +- [https://www.ibm.com/in-en/topics/decision-trees](https://www.ibm.com/in-en/topics/decision-trees) + +Concurrently, you can follow the following videos for intuitive understanding and visualization: + +- [Classification Trees](https://www.youtube.com/watch?v=_L39rN6gz7Y&list=PLblh5JKOoLUKAtDViTvRGFpphEc24M-QH&index=1) +- [Feature Selection](https://www.youtube.com/watch?v=wpNl-JwwplA&list=PLblh5JKOoLUKAtDViTvRGFpphEc24M-QH&index=2) +- [Regression Trees](https://www.youtube.com/watch?v=g9c66TUylZ4&list=PLblh5JKOoLUKAtDViTvRGFpphEc24M-QH&index=3) +- [Pruning Regression Trees](https://www.youtube.com/watch?v=D0efHEJsfHo&list=PLblh5JKOoLUKAtDViTvRGFpphEc24M-QH&index=4) + +So far we have not really looked into much code. But as always no concept is complete without implementation. + +You may refer to the following for help: + +- [https://machinelearningmastery.com/implement-decision-tree-algorithm-scratch-python/](https://machinelearningmastery.com/implement-decision-tree-algorithm-scratch-python/) +- [https://towardsdatascience.com/implementing-a-decision-tree-from-scratch-f5358ff9c4bb](https://towardsdatascience.com/implementing-a-decision-tree-from-scratch-f5358ff9c4bb) +- [https://www.kaggle.com/code/prashant111/decision-tree-classifier-tutorial](https://www.kaggle.com/code/prashant111/decision-tree-classifier-tutorial) +- [https://towardsdatascience.com/an-exhaustive-guide-to-classification-using-decision-trees-8d472e77223f](https://towardsdatascience.com/an-exhaustive-guide-to-classification-using-decision-trees-8d472e77223f) + +The following video presents a great pipeline to implement A Classficiation Tree Model: +[https://www.youtube.com/watch?v=q90UDEgYqeI&list=PLblh5JKOoLUKAtDViTvRGFpphEc24M-QH&index=5](https://www.youtube.com/watch?v=q90UDEgYqeI&list=PLblh5JKOoLUKAtDViTvRGFpphEc24M-QH&index=5) + +Finally, solve the Titanic challenge on Kaggle: +[https://www.kaggle.com/competitions/titanic](https://www.kaggle.com/competitions/titanic) + +Bonus: You can go through the first section of [Lecture 10 of CS229](https://www.youtube.com/watch?v=wr9gUr-eWdA&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU&index=10) for a formal mathematical formulation of Decision Trees. This is not necessary coz after soo much practice and reading you'd have a decent understanding but if you have time to spare, this is definitely better than scrolling through dumb insta reels. + + + +### 👾 Day 4: Ensemble Methods + +
+ +
+
+Ensemble Methods
+
+ +Ensemble simply means combining the output of various models in a particular manner in an attempt to improve the accuracy of the combined (ensembled) model. Ensemble methods can include simple methods (like majority voting, weighted voting, simple averaging, weighted averaging), stacking (Improves predictions), boosting (Deceases Bias), bagging (Decreases Variance) etc. Refer to the following articles for understanding these ensemble learning methods: + +- [https://www.ibm.com/topics/ensemble-learning](https://www.ibm.com/topics/ensemble-learning) +- [https://www.toptal.com/machine-learning/ensemble-methods-machine-learning](https://www.toptal.com/machine-learning/ensemble-methods-machine-learning) + +We'll dive deep into Bagging today, and cover Boosting and various Boosting Algorithms later in Week 6. If you wish, you can cover it post Bagging as well. Follow these videos for Baggin: + +- [Intro to Bagging by IBM (Article)](https://www.ibm.com/topics/bagging) +- [Bagging Tutorial and Implementation in Python (Video)](https://www.youtube.com/watch?v=RtrBtAKwcxQ) + +Today was a light day, but be ready to go into the forest to encounter some Tygers 🐯 + + + +### 👾 Day 5: Random Forests + +> "Trees have one aspect that prevents them from being the ideal tool for predictive learning, namely inaccuracy" +> ~ _The Elements of Statistical Learning_ + +
+ +
+
+Random Forests
+
+ +So what do we do? Combine tones of trees to create a forest! Simple enough? No! +We use Bagging (Bootstrapping and Aggregation) in order to combine multiple trees (those trees are not built like standard Decision Trees, but follow a specific procedure), an this forms a Random Forest. Go through the following videos to understand Random Forests: + +- [https://www.youtube.com/watch?v=J4Wdy0Wc_xQ&list=PLblh5JKOoLUIE96dI3U7oxHaCAbZgfhHk](https://www.youtube.com/watch?v=J4Wdy0Wc_xQ&list=PLblh5JKOoLUIE96dI3U7oxHaCAbZgfhHk) +- [https://www.youtube.com/watch?v=sQ870aTKqiM&list=PLblh5JKOoLUIE96dI3U7oxHaCAbZgfhHk&index=2](https://www.youtube.com/watch?v=sQ870aTKqiM&list=PLblh5JKOoLUIE96dI3U7oxHaCAbZgfhHk&index=2) + +Now try to implement Random Forests from scratch on your own! + +Bonus: You can find the original research paper on Random Forests over [here](https://www.stat.berkeley.edu/~breiman/randomforest2001.pdf) and an overview of the same in this [Berkley Article](https://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm). Following the research paper is tough and not really recommended at this level (Even I haven't read it), but for mathematical and theoretical insights, you can refer the overview. + + + +### 👾 Day 6: Support Vector Machines + +
+ +
+
+Support Vector Machine Hyperplane
+
+ +Logistic Regression will not be able to classify points wherein the decision boundary is non-linear. For that we'd have to create an augmented feature matrix wherein we include features like $x_{i}^2, x_{i}^3$ and hope that they work, because we never know which degree of polynomial might be required to fit a boundary. +Moreover, the issue with GDA is that it might work with slightly non linear boundaries, but again fails with highly non linear ones. + +Support Vector Machines help us in classifying points which are separated by n-dimensional highly non-linear boundaries. + +[This article by IBM](https://www.ibm.com/topics/support-vector-machine) provides a great overview of SVMs. For a greater understanding, go through this video on [Introduction to SVMs](https://www.youtube.com/watch?v=efR1C6CvhmE) + +Then, watch [Lecture 6 of CS229](https://www.youtube.com/watch?v=lDwow4aOrtg&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU&index=8), which would clarify any problems you might be facing with building your Spam Main detector and provide you with an introduction to SVMs + + + +### 👾 Day 7: Kernel Methods + +
+ +
+
+Support Vector Machine Kernels
+
+ +SVM algorithms use a set of mathematical functions that are defined as the kernel. The function of kernel is to take data as input and transform it into the required form. Different SVM algorithms use different types of kernel functions. A crucial mathematical method to work with SVMs is the kernel. Follow the following videos to get an understanding of Kernel Methods in SVMs: + +- [The Polynomial Kernel](https://www.youtube.com/watch?v=Toet3EiSFcM) +- [The Radial Kernel](https://www.youtube.com/watch?v=Qc5IyLW_hns) + +Following article displays the implementation of SVM on Breast Cancer Data using SciKitLearn: [https://www.geeksforgeeks.org/support-vector-machine-algorithm/](https://www.geeksforgeeks.org/support-vector-machine-algorithm/) + +Bonus: Check out [Lecture 7 of CS229](https://www.youtube.com/watch?v=8NYoQiRANpg&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU&index=10) for mathematical formulation of SVMs and Kernel Methods. + + + +## 🦝 Week 5 (Perceptron and Neural Networks) + +_The next month of this roadmap will be devoted to Neural Networks and their applications._ + + + +### 👾 Day 1,2,3 - The perceptron and General Linear Models + +(lmao there's a specific reason why 3 days have been allotted to a topic which is not widely talked about, so just try to stick with me for a few days; post that you'll feel like a different person 🙃🦝) +Content on of this week is largely derived from [the fourth lecture of CS229](https://www.youtube.com/watch?v=iZTeva0WSTQ&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU&index=4), so you can constantly refer the video and the lecture notes for better understanding. Knowledge for Mathematical formulation of GLMs is recommended but not compulsory; it provides a great intuition behind similarity patterns in various ML algorithms and groups them under a larger class. + +#### 🐼 Perceptrons + +
+ +
+
+Perceptron Model
+
+ +The ultimate goal of Artificial Intelligence is to mimic the way the human brain works. The brain uses neurons and firing patterns between them to recognize complex relationships between objects. We aim to simulate just that. The algorithm for implementing such an "artificial brain" is called a neural network or an artificial neural network (ANN). + +At its core, an ANN is a system of classifier units which work together in multiple layers to learn complex decision boundaries. + +The basic building block of a neural net is the **perceptron.** These are the "neurons" of our neural network. + +- [https://towardsdatascience.com/what-is-a-perceptron-basics-of-neural-networks-c4cfea20c590](https://towardsdatascience.com/what-is-a-perceptron-basics-of-neural-networks-c4cfea20c590) +- [https://www.javatpoint.com/perceptron-in-machine-learning](https://www.javatpoint.com/perceptron-in-machine-learning) + +Do you see the similarity with logistic regression? What are the limitations of using the Perceptron Learning Algorithm? Do you think that Logistic regression is just a softer version of the Perceptron Learning Algorithm? + +You'd notice that there is a fundamental similarity between the update functions of linear regression, logistric regression as well as the perceptron; with the only difference being in the hypothesis function part of the update. What does this signify? Is there a deeper correlation or is this just a coincidence? Let's explore further. + +#### 🐼 Exponential Families + +For understanding exponential families, we'd have to understand basic probability distributions (which we covered in the second week) and the probabilistic interpretation of linear regression (refer the probabilstic interpretation of this [video lecture](https://www.youtube.com/watch?v=het9HFqo1TQ&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU&index=4) for a refresher) + +- A refresher on probability distributions:[Probability Distribution Function For Machine Learning](https://www.enjoymathematics.com/blog/probability-distribution-function-for-machine-learning) +- Bonus Material:[Medium Article on Prob Distributioins for ML and DL](https://jonathan-hui.medium.com/probability-distributions-in-machine-learning-deep-learning-b0203de88bdf) + +_Note that Exponential Families and GLMs come under the probabilstic interpretation of Machine Learning (which you'd study in CS772: Probabilistic ML if you take the course (and get it lmao)) and is not at all important for building ML models of the level you'd be building as a beginner. But these become largely important when you delve deep into statistical modelling of data. So if you feel that this is boring or is taking a huge amount of time to understand, you can prolly move on to Day 2 and come back to this section later._ + +Anyways, back to the discussion. Recall that when we were trying to model data using linear regression, we approximated Y (the output) as a sum of a function of X and an error term $\epsilon$. We assumed gaussian probability distribution about the mean 0 for the distribution of $\epsilon$. Note that gaussian distribution is a specialized case of a class of functions called "exponential families", which are defined by: + +$$ +p(y|\theta) = exp(\eta (\theta)T(y) + A(\theta)+B(y)) +$$ + +wherein: + +- $y$ is the data +- $\theta$ are the parameters (which are to be altered, like weights and biases) +- $exp(B(y))$ is the base measure +- $\eta (\theta)$ is called the natural parameter +- $T(y)$ is the sufficient statistic +- $A(\theta)$ is the log-partition function or cumulant function. + +You'd find different representations of the same thing at different places, but the form remains more or less same. + +If you take specific values of the functions, and do some maniputlations to this function, you'd end up with famous distributions that we have studied, for instance, Gaussian (linear regression), Bernoulli (logistic regression), Poisson etc. Exponential families have several key properties that make them particularly important and useful in modeling data and machine learning: + +- Data Reduction: Exponential families have sufficient statistics $T(x)$ that summarize all the information needed from the data to compute the likelihood. This means we can reduce the data to these statistics without losing information about the parameter estimation. Computation of likelihood is important, because as observed earlier, the maximum likelihood provides a method to evaluate the ideal cost function, which when extremized gives us the values of the parameters (weights and biases in case of NNs) which make the hypothesis approach the natural function. +- Efficiency: Using sufficient statistics reduces the dimensionality of the problem, leading to more efficient computations. +- Linear Combination: The natural parameters 𝜂(𝜃) and the sufficient statistics $T(x)$ combine linearly in the exponent. This linearity simplifies the algebra involved in statistical inference. +- Normalization: The log-partition function $A(\theta)$ ensures that the probability distribution is properly normalized (i.e., integrates to 1). It also plays a crucial role in deriving other properties of the distribution. +- Moments: The log-partition function helps in calculating the moments (mean, variance, etc.) of the distribution. +- Simplified Algorithms: The mathematical properties of exponential families enable the development of efficient algorithms for parameter estimation (e.g., Maximum Likelihood Estimation, Expectation-Maximization). + +CS229 lectures notes and lecture should be enough to understand exponential families. For a better understanding, refer to the following resources: + +- [Lecture Notes by Osvaldo Simeone](https://nms.kcl.ac.uk/osvaldo.simeone/ml4eng/Chapter_9.pdf) +- [A (visual) Tutorial on Exponential Families by Marius Hobbhahn](https://www.mariushobbhahn.com/2021-06-10-ExpFam_tutorial/) + +
- Sidenote: This Man Marius Hobbhahn is an absolute legend who primarily works on Bayesian ML and has written pretty insightful blogs on the mathematical aspect of ML. Moreover, he's a pretty successful debater. Do check out this website for intrinsically interesting stuff 🦝🙃
+ +
+
+SoftMax Regression
+
+ +- The SoftMax function is used to convert the raw scores (also known as logits) produced by the model into probabilities. +- If there are different classes their predicted values could range form $-\infty$ to $+\infty$ , what SoftMax does is it converts these values into probabilities, such that sum of all the probabilities is 1. +- This help us understand which class has the highest probability, thus suggesting the object we are predicting for belongs to that class. + **Resources:** +- https://medium.com/@tpreethi/softmax-regression-93808c02e6ac +- [Video by Andrew Ng](https://www.youtube.com/watch?v=LLux1SW--oM) + +Also, go through the SoftMax Regression Section of Generalized Linear Models to get a hang of how it has been derived. + + + +### 👾 Day 4: Introduction to Neural Networks and Backpropagation + +
+ +
+
+Neural Network Architecture
+
+ +If you've understood the perceptron, and the basic idea behind Machine Learning, understanding Neural Networks is not really a big deal. Firstly, for an introduction, watch the videos by 3Blue1Brown on [Introduction to Neural Networks](https://www.youtube.com/watch?v=aircAruvnKk&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi), [Gradient Descent in Neural Networks](https://www.youtube.com/watch?v=IHZwWFHWa-w&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=3), [Backpropagation Intuition](https://www.youtube.com/watch?v=Ilg3gGewQ5U&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=3) and [Backpropagating Calculus](https://www.youtube.com/watch?v=Ilg3gGewQ5U&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=4). + +Then, read these articles for better theoretical understanding: + +- [https://medium.com/deep-learning-demystified/introduction-to-neural-networks-part-1-e13f132c6d7e](https://medium.com/deep-learning-demystified/introduction-to-neural-networks-part-1-e13f132c6d7e) +- [https://medium.com/ravenprotocol/everything-you-need-to-know-about-neural-networks-6fcc7a15cb4](https://medium.com/ravenprotocol/everything-you-need-to-know-about-neural-networks-6fcc7a15cb4) +- [https://machinelearningmastery.com/difference-between-backpropagation-and-stochastic-gradient-descent/](https://machinelearningmastery.com/difference-between-backpropagation-and-stochastic-gradient-descent/) + +Refer to the following articles to get a feel of the mathematics under the hood. + +- [https://towardsdatascience.com/deriving-the-backpropagation-equations-from-scratch-part-1-343b300c585a](https://towardsdatascience.com/deriving-the-backpropagation-equations-from-scratch-part-1-343b300c585a) +- [https://towardsdatascience.com/understanding-backpropagation-algorithm-7bb3aa2f95fd](https://towardsdatascience.com/understanding-backpropagation-algorithm-7bb3aa2f95fd) + +Lastly, go through CS229 [Lecture 11: Intro to Neural Networks](https://www.youtube.com/watch?v=MfIjxPh6Pys&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU&index=11) and [Lecture 12: Backpropagation](https://www.youtube.com/watch?v=zUazLXZZA2U&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU&index=12) which shall provide a better mathematical foundation. + + + +### 👾 Day 5: Debugging ML Models and Errors + +Once again, like the first 3 days the content for this week is largely derived from [CS229 lecture 13](https://www.youtube.com/watch?v=ORrStCArmP4&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU&index=14), and the same will be the base resource for the day. + +Debugging ML model workflows is one of the most important skills, for a model more often than not, does not work for the first time (at least not accurately) you program it (unless, obv if you're just copy pasting a code from kaggle, GPT or blog, and in that case we won't really call it "building" a pipeline). Therefore,the stuff you learn today will be pretty useful in building real world applications and projects. So let's get started with some diagnostics and methods :) + +#### 🐼 Bias v/s Variance Diagnostic + +In Week 3, we talked about two crucial metrics: Bias and Variance. In this section, we'll understand how they can be exploited for debugging ML models. For a quick refresher, you can go through [this](https://ngugijoan.medium.com/bias-and-variance-6cf244080082#:~:text=High%20variance%20in%20statistics%20means,resulting%20in%20a%20broader%20distribution.) blog. + +The learning curve (error v/s training set size) of a high variance model largely looks like this: + + +2 metrics to detect such a curve: + +- Test error decreases as training set size increases. +- Large gap between training and test error + +These metrics suggest, that to fix these issues, following tactics might be helpful: +a) Get more training examples, as test error decreases as training set size increases; so the test set graph might extrapolate +b) Try a smaller set of features. High variance in statistics means that the data points in a dataset are widely spread out from the mean, which is often due to a high set of features. So reducing the number of features might help. + +Whereas the high bias counterpart looks as follows: + + +2 metrics to detect such a curve: + +- Training error is unacceptably high +- There's a small gap between training and test error + +Increasing the training set might not help as the error is largely constant of the training examples. + +These metrics suggest, that to fix these issues, following tactics might be helpful: + +1. Using a larger set of features, so that patterns are captures in a much better manner. After this, if the model has a high variance, increasing the number of training examples might help. +2. Try to quaitatively analyze the features, perform Exploratory Data Analysis, Data Preprocessing and Feature Engineering as these techniques might help in extracting features with better correlation. + +#### 🐼 The Optimization Problem v/s Maximization Problem Diagnostic + +In any ML Problem, we try to maximize a particular function, and for maximizing that function, we use an optimization algorithm. In an application, the issue with our model design might either be a wrong choice of Cost Function, or a wrong choice of optimization algorithm. How do we identify what exactly is wrong? + +Let's say we are trying to solve a problem and model A performs better than model B on a particular metric (metric which is important for your use case), but you need to deploy model B only, prolly because its exponentially faster or because model A has other inherent issues. How do we identify the problem. Let's say model B tries to optimize the cost function J. We don't really care about the cost function which A optimizes so let's keep that aside. $\theta_A$ are the params of model A and $\theta_B$ are params of B. There are 2 cases: +a) $J(\theta_A) > J(\theta_B)$: This means that the optimization algorithm failed to converge, and we should prolly run the algorithm for more iterations or go for another optimization algorithm, like Newton's method. +a) $J(\theta_A) <= J(\theta_B)$: This means that the optimization algorithm succeeded in optimizing the cost function, but the cost function selection is bad so we much change it. We can do this by either changing the cost function completely or altering the hyperparameters of the regularization (because that tweaks the cost function). + +This is a theoretical overview of some of the commonly used diagnostics. For more detailed examples and workflows, go through the video linked in the beginning of the section. + + + +### 👾 Day 6, 7: Implement a Neural Network from Scratch + +Dedicate these two days to try to implement a neural network in python from scratch. Try to have one input, one hidden, and one output layer. + +You may train your model on any of the datasets given in the roadmap. + +[https://towardsdatascience.com/an-introduction-to-neural-networks-with-implementation-from-scratch-using-python-da4b6a45c05b](https://towardsdatascience.com/an-introduction-to-neural-networks-with-implementation-from-scratch-using-python-da4b6a45c05b) + + + +## 🦝 Week 6 (Optimizations, Feature Selection, Boosting Algorithms and Tensorflow) + + + +### 👾 Day 1, 2: Optimization Algorithms + +#### 🐼 Problems with Vanilla Gradient Descent + +There are multiple issues which arise when we implement Gradient Descent on complex (non quadratic) cost functions: + +1. **Local Minimas and Saddle Points:** Loss Functions are convex in nature, which might lead to the Gradient Descent Algorithm converging at a nonoptimal local minimum. The networks usually get trapped at various saddle points and local minima. A greater issue is encountered with saddle points as they are surrounded by plateaus of similar error, making it extremely hard to escape from these points. +2. **The difficulty is choosing an optimal learning rate:** A low learning rate leads to extremely slow convergence and a high learning rate leads to difficulty in convergence as the function skips the minima and fluctuates and oscillates around the graph. +3. **Non-Dynamic nature of training rate schedules:** If we try to alter the training rate according to a pre-set schedule, we are not able to dynamically alter the training rate according to the dataset’s characteristics. +4. **Application of same learning rate to all parameters:** Certain weights and other parameters need not be updated to the same extent, but in vanilla gradient descent, all parameters are updated according to the same learning rate which might not be required. + +In order to solve these problems, let's take a look at a few optimization techniques. + +#### 🐼 Momentum Based Optimization + +Momentum-based optimization techniques make use of a term that contains information about the past values of the gradient in order to update the weights. The momentum-based gradient descent builds inertia in a direction in the search space to overcome the oscillations of noisy gradients. It uses Exponentially Decaying Moving Averages because the information about the older gradients is not as relevant as the information about the newer gradients. + +$$ +x_{k+1} = x_k − sz_k +$$ + +Where: + +$$ +z_k = \Delta f_k + βz_{k−1} +$$ + +Here, $z_k$ captures the information of the past gradients. The multiplication by $\beta$ in this recursive function ensures that as the gradient gets older, its information is lost, that is its weight in the calculation in alteration of parameters reduces as a power of $\beta$. This not only ensures that the number of steps in the optimization is reduced but also ensures that the model is not stuck in saddle points or local minima and it explores beyond these points also during descent. + +
+ +
+
+Momentum Based Optimization Visualization
+
+ +
+ +
+
+SGD without and with momentum
+
+ +[This](https://www.scaler.com/topics/momentum-based-gradient-descent/) article gives a great insight into the inherent problems with Gradient Descent and provides the implementation of Momentum in Gradient Descent. + +For Math nerds, [this](https://www.youtube.com/watch?v=wrEcHhoJxjM) video by Legendary Mathematician Gilbert Strang (you might read/might have read his book on Linear Algebra for MTH113) provides a great mathematical understanding from a Linear Algebra perspective. + +#### 🐼 Nestrov Accelerated Gradient + +A major issue with momentum-based optimization is that the model tends to overshoot because when it is about it reach the optimum value, it is coming down with a lot of momentum, which might lead to overshooting. +To solve this problem, Nestrov Accelerated Gradient tries to ”look ahead” to where the parameters will be to calculate the gradient. The standard momentum method first computes the momentum at a point and then takes a jump in the direction of the accumulated gradient, but as opposed to that Nestrov Momentum first takes the jump in the direction of the accumulated gradient and then measures the gradient at the point it reaches to make the correction. This additional optimization prevents overshooting. This is given by: + +$$ +v_t = \lambda v_{t−1} + \eta \Delta J(\theta − \lambda v_{t−1}) +$$ + +where: + +$$ +\theta = \theta − v_t +$$ + +
+ +
+
+NAG visualization
+
+ +The following videos will provide and great visualization and intuitive understanding of NAG: +[A 4 min quick visualization](https://www.youtube.com/watch?v=uHOTRHqnakQ&t=128s) +[Another great visualization](https://www.youtube.com/watch?v=iudXf5n_3ro) + +Try to code NAG from scratch. + +#### 🐼 Learning Rate Adaptation: Adagrad + +The same learning rate might not be ideal for all parameters for an optimization algorithm, for sometimes it might need a higher rate to quickly descent, or sometimes it might require a lower rate. Adagrad is an optimzation algorithm that adapts the learning rate to the parameters, performing larger updates for infrequent and smaller updates for frequent parameters. Refer to [this](https://www.youtube.com/watch?v=nqL9xYmhEpg) videos for a detailed explaination of how Adagrad works and then try to implement it from scratch. + +#### 🐼 Adam + +Adam stands for Adaptive Moment Estimation. It is a method that computes adaptive learning rates for +each parameter. It aims to use the best of both worlds of using moments and using a learning rate custom to each parameter(based on their frequency). It maintains two moving average estimates of gradients and squares of gradients, and updates parameters using these estimates. It is preferred as the optimization algorithm for most Neural Networks because of the following reasons: + +1. Adam converges faster compared to traditional optimization algorithms SGD due to its adaptive learning rate. By adjusting the learning rates individually for each parameter, Adam can make more significant progress in optimizing the loss function. +2. Adam has found to work well across various deep learning architectures and tasks, including image classification, natural language processing, and reinforcement learning. +3. Adam has default hyperparameters that typically work well across different tasks and datasets, reducing the need for manual tuning. + +For a detailed explanation of how Adam works, and its visualization refer to [this video](https://www.youtube.com/watch?v=MD2fYip6QsQ&t=286s). + +
+ +
+
+Comparison of various optimizers
+
+ +
- This Paper by Sebastian Ruder is a 🦝 **MUST READ** 🦝 and provides a great insight into Vanilla, Stochastic and Mini Batch Gradient Descent, their shortcoming and all momentum based optimized versions of Gradient Descent, ie **NAG, Adagrad, Adadelta, RMSprop, Adam, AdaMax and Nadam**. It then, goes on to provide comparative visualizations of these optimizations and proposes methods to parallelize and distribute the running of SGD. Lastly, it provides additional strategies for optimizing SGD like Shuffling and Curriculum Learning, Batch normalization, Early stopping and Gradient noise. If you wish to go deep into any of these subtopics, you can read the research papers cited in this paper and other references provided. I just stress enough on the importance of this paper and the amount of knowledge you'd gain by just understanding it.
+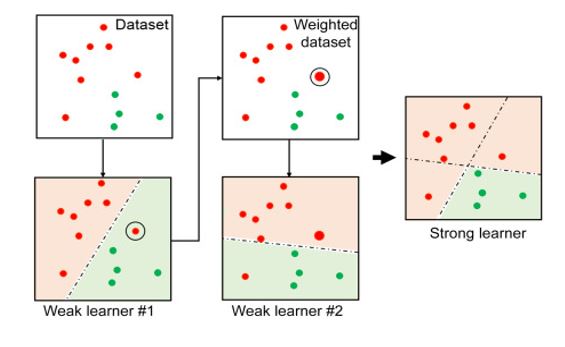 +
+
+AdaBoost: Ensemble of multiple weak learners (stumps)
+
+ +AdaBoost involves the following steps: + +1. **Sample Weights Initialization:** Sample weights are initialized for all the data points, and set to $1/n$, wherein $n$ is the number of data points +2. **Initial Stump Creation:** On the basis of Gini Index, stump is selected (This is similar to how we used Gini Index to determine the split in the case of Decision Trees) +3. **Calculate Influence:** Influence of this weak classifier is calculated. This influence score determines the New Sample Weight (will explain that in the next point) of the data point. If the error of the stump is 100%, this means that if we flip the results, the accuracy will be 100%, but if error is 50%, the outputs are completely random so the influence of the weak classifier should be 0. This logic is captured well but the following function: + + $$ + Influence, \alpha = \frac{1}{2} log(\frac{1-Total Error}{Total Error}) + $$ + +4. **Updating sample weights:** $$ +New Sample Weight = Old Weight * e^{\pm \alpha} +$$ +5. **New Sample Weight Normalization** +6. Up sampling of the rows is done on the basis of the Normalized New Sample Weights, which determines the rows and weights for the next stump + +The Process continues till a defined endpoint, for instance: number of stumps or accuracy threshold. + +Go through the following resources for understanding AdaBoost: + +- [Video Tutorial by StatQuest](https://www.youtube.com/watch?v=LsK-xG1cLYA) +- [Lecture Notes on AdaBoost by Prof Alan Yuille, JHU](https://www.cs.jhu.edu/~ayuille/courses/Stat161-261-Spring14/LectureNotes7.pdf) provide a mathematical description of the algorithm +- [Article from paperspace](https://blog.paperspace.com/adaboost-optimizer/) provides visualizations and implementation pseudocode + +After completing going through these 3 resources, try to implement AdaBoost from scratch. + +#### 🐼 Gradient Boosting + +
+ +
+
+Gradient Boosting
+
+ +Gradient Boosting is an optimized version of AdaBoost, and differs from AdaBoost in the following manner: + +1. Contrary to AdaBoost, which tweaks the instance weights at every interaction, Gradient Boost tries to fit the new predictor to the residual errors made by the previous predictor. +2. Gradient Boost starts by making a single leaf instead of a tree or stump. +3. Eventual models are trees. But unlike Ada Boost, these trees are larger than a stump. But Gradient Boost still restricts the size of a tree. + +The following videos provide a great intuitive as well as mathematical insight into Gradient Boosting: + +- [Regression using GradBoost Introduction](https://www.youtube.com/watch?v=3CC4N4z3GJc&list=PLblh5JKOoLUJjeXUvUE0maghNuY2_5fY6) and [GradBoost Regression Mathematical Intuition](https://www.youtube.com/watch?v=2xudPOBz-vs&list=PLblh5JKOoLUJjeXUvUE0maghNuY2_5fY6&index=2) +- [GradBoost Classification Introduction](https://www.youtube.com/watch?v=jxuNLH5dXCs&list=PLblh5JKOoLUJjeXUvUE0maghNuY2_5fY6&index=3) and [GradBoost Classification Mathematical Intuition](https://www.youtube.com/watch?v=StWY5QWMXCw&list=PLblh5JKOoLUJjeXUvUE0maghNuY2_5fY6&index=4) + +These videos will be more than enough for thoroughly understanding GradBoost, post which you can work on programming it from scratch using Python. + +#### 🐼 Extreme Gradient Boost (XGBoost) + +Gradient Boosting is a great algorithm, but it has one fundamental issue: it is highly prone to overfitting. XGBoost is an optimized version of Gradient Boosting, which also includes pruning and regularization at various steps in order to prevent overfitting. The main features which differentiate XGBoost from Gradient Boost are: + +1. A Unique XGBoost Tree is constructed on the basis of similarity scores and gains as opposed to the standard Gradient boost Trees opposed to the standard Gradient boost Tree +2. Overfitting is prevented using the regularization parameter $\lambda$ which reduces the sensitivity of prediction to an individual observation +3. Pruning of branches is conducted, and the extent of pruning can be controlled via the $\gamma$ threshold or $\lambda$ + +Go through the following videos for understanding XGBoost Algorithm: + +- [XGBoost Regression](https://www.youtube.com/watch?v=OtD8wVaFm6E&list=PLblh5JKOoLULU0irPgs1SnKO6wqVjKUsQ) +- [XGBoost Classification](https://www.youtube.com/watch?v=8b1JEDvenQU&list=PLblh5JKOoLULU0irPgs1SnKO6wqVjKUsQ&index=2) +- [XGBoost Mathematics](https://www.youtube.com/watch?v=ZVFeW798-2I&list=PLblh5JKOoLULU0irPgs1SnKO6wqVjKUsQ&index=3) +- [XGBoost Optimizations](https://www.youtube.com/watch?v=oRrKeUCEbq8&list=PLblh5JKOoLULU0irPgs1SnKO6wqVjKUsQ&index=4) +- [Programming XGBoost in Python from Scratch](https://www.youtube.com/watch?v=GrJP9FLV3FE&list=PLblh5JKOoLULU0irPgs1SnKO6wqVjKUsQ&index=5) + +After these 5 videos, you'd have a strong grasp over XGBoost, hence over Boosting algorithms in general. Post completion, I highly recommend you to watch [CS229 Lecture 10](https://www.youtube.com/watch?v=wr9gUr-eWdA&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU&index=12), as Dr Raphael Townshend very brilliantly explain the mathematical formulations of Decision Trees, Random Forests and Boosting Algorithms. This shall also act as a revision video for all the contents we have covered so far regarding Trees and Boosting. Don't forget to refer the [lecture notes](https://cs229.stanford.edu/lectures-spring2022/main_notes.pdf) as well. + + + +### 👾 Day 6, 7: TensorFlow + +We will now start building models. For this, we are going to use Tensorflow. It enables us to implement various models that you have learned about in previous weeks. + +The TensorFlow platform helps you implement best practices for data automation, model tracking, performance monitoring, and model retraining. + +First, install tensorflow. Follow this link: + +[https://www.tensorflow.org/install](https://www.tensorflow.org/install) + +Keras - Keras is the high-level API of TensorFlow 2: an approachable, highly-productive interface for solving machine learning problems, with a focus on modern deep learning. It provides essential abstractions and building blocks for developing and shipping machine learning solutions with high iteration velocity. + +[https://www.tutorialspoint.com/keras/keras_installation.htm](https://www.tutorialspoint.com/keras/keras_installation.htm) + +Go through this article to know more about keras and tensorflow. + +[https://towardsdatascience.com/tensorflow-vs-keras-d51f2d68fdfc](https://towardsdatascience.com/tensorflow-vs-keras-d51f2d68fdfc) + +Through the following link, you can access all the models implemented in keras, and the code you need to write to access them + +[https://keras.io/api/](https://keras.io/api/) + +You can have a brief overview of the various features keras provides. + +[https://www.tensorflow.org/tutorials](https://www.tensorflow.org/tutorials) + +Go through the above tutorial. There are various subsections for keras basics, loading data, and so on. These will give you an idea on how to use keras and also how to build a model, process data and so on. You can see the Distributed Training section if you have time, but do go through other sections. + + + +## 🦝 Week 7: Mastering Clustering and Unsupervised Machine Learning + + + +### 👾 DAY 1: Introduction to Unsupervised Learning and Clustering + +#### a. **Unsupervised Learning: Discovering Hidden Patterns** + +Unsupervised learning is a type of machine learning that looks for previously undetected patterns in a dataset with no pre-existing labels and with a minimum of human supervision. Unlike supervised learning, there are no predefined target variables. The goal is to identify patterns, groupings, or structures within the data. + +🔍 **Learn More:** +Get started with this comprehensive overview on [**unsupervised learning**](https://www.altexsoft.com/blog/unsupervised-machine-learning/). + +#### b. **Clustering: Grouping Data Intelligently** + +Clustering is a fundamental unsupervised learning technique used to group similar data points together. It aims to divide the data into clusters, where points in the same cluster are more similar to each other than to those in other clusters. + +🔍 **Discover Clustering:** +Dive into clustering basics with [**this guide**](https://towardsdatascience.com/overview-of-clustering-algorithms-27e979e3724d). + + + +### 👾 DAY 2: K-Means Clustering + +#### a. **Understanding K-Means Clustering** + +K-Means is one of the simplest and most popular clustering algorithms. It partitions the data into K clusters, where each data point belongs to the cluster with the nearest mean. This iterative process aims to minimize the variance within each cluster. +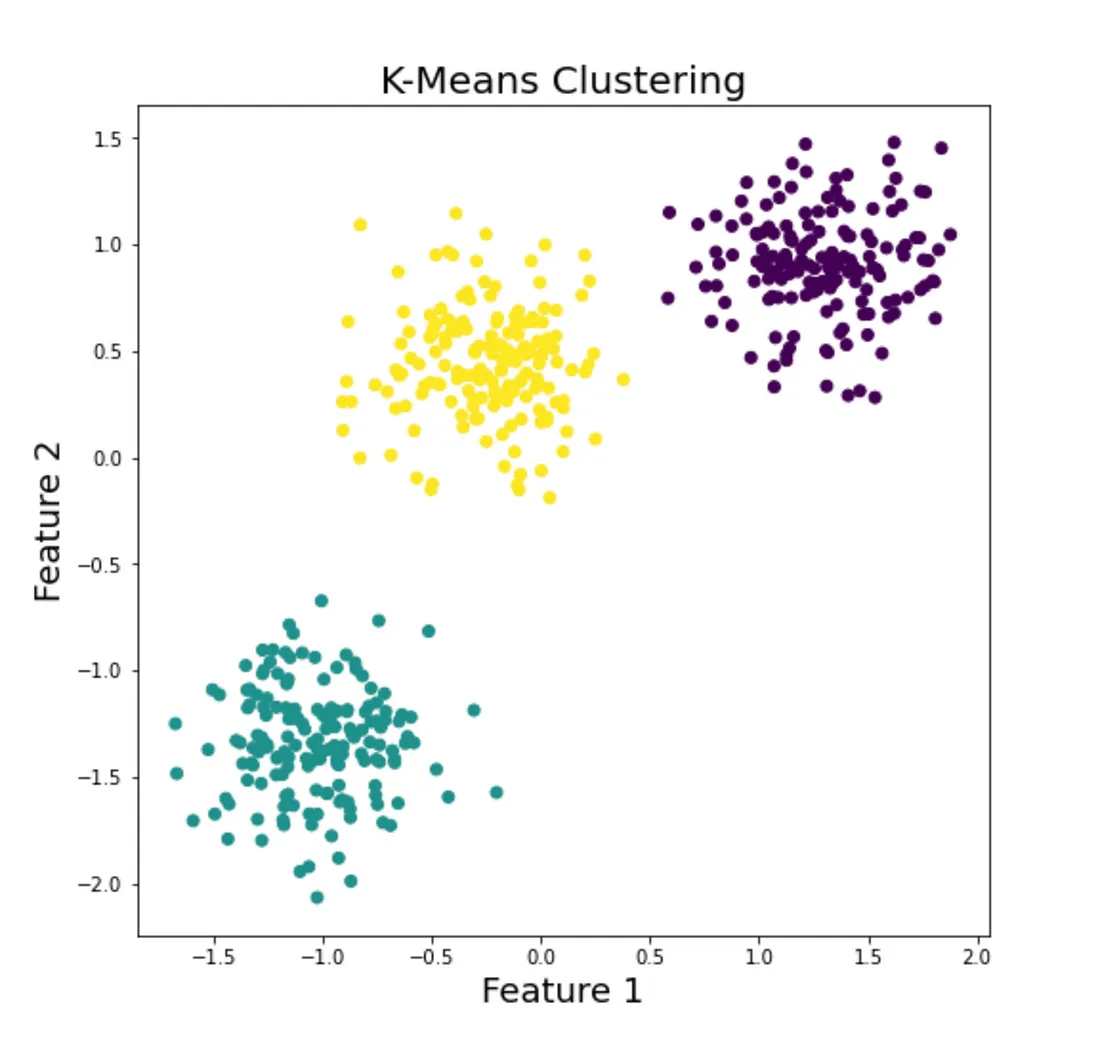 + +🧠 **How It Works:** + +1. Initialize K centroids randomly. +2. Assign each data point to the nearest centroid. +3. Update centroids by calculating the mean of the assigned points. +4. Repeat until convergence (centroids no longer change). + +🔍 **Explore More:** +Learn about K-Means in detail [**here**](https://www.analyticsvidhya.com/blog/2019/08/comprehensive-guide-k-means-clustering/). + +#### b. **Hands-On with K-Means** + +Get hands-on experience by implementing K-Means clustering in Python. + +🔍 **Follow Along with Code:** +Check out this step-by-step tutorial on K-Means implementation [**here**](https://realpython.com/k-means-clustering-python/). + + + +### 👾 DAY 3: Hierarchical Clustering + +#### a. **Hierarchical Clustering: Building Nested Clusters** + +Hierarchical clustering builds a hierarchy of clusters. It can be divided into Agglomerative (bottom-up approach) and Divisive (top-down approach) clustering. + +🧠 **How It Works:** + +- **Agglomerative:** Start with each data point as a single cluster and merge the closest pairs iteratively until all points are in a single cluster. +- **Divisive:** Start with one cluster containing all data points and recursively split it into smaller clusters. + +🔍 **Deep Dive:** +Understand hierarchical clustering with this [**guide**](https://www.javatpoint.com/hierarchical-clustering-in-machine-learning). + +#### b. **Visualizing Dendrograms** + +Dendrograms are tree-like diagrams that illustrate the arrangement of clusters produced by hierarchical clustering. They help to visualize the process and results of hierarchical clustering. + +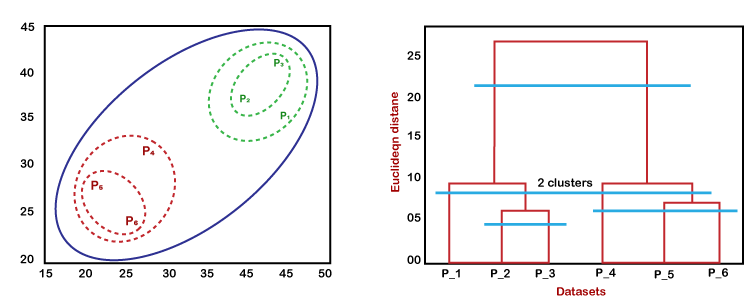 + + + +### 👾 DAY 4: Density-Based Clustering (DBSCAN) + +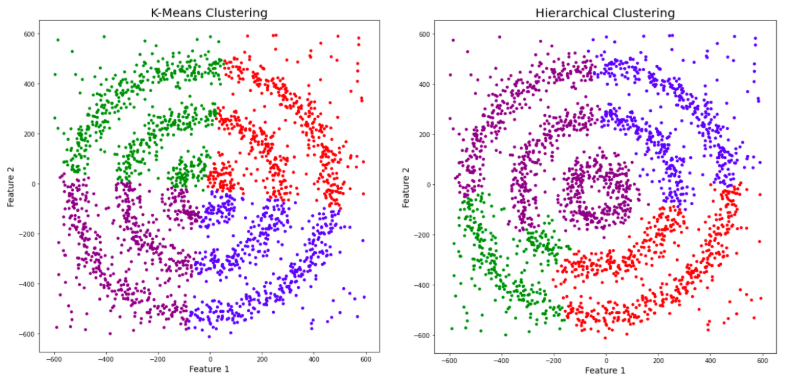 + + +#### a. **DBSCAN: Clustering Based on Density** + +Density-Based Spatial Clustering of Applications with Noise (DBSCAN) is a clustering algorithm that groups together points that are closely packed and marks points that are far away as outliers. It is particularly effective for datasets with noise and clusters of different shapes and sizes. + +🧠 **How It Works:** + +1. Select a point and find all points within a specified distance (epsilon). +2. If there are enough points (minimum samples), form a cluster. +3. Expand the cluster by repeating the process for each point in the cluster. +4. Mark points that don't belong to any cluster as noise. + +🔍 **Learn More:** +Understand DBSCAN and its code in detail [**here**](https://scikit-learn.org/stable/modules/clustering.html#dbscan). + +#### b. **Implementing DBSCAN** + +Get practical experience by implementing DBSCAN in Python. + +🔍**Take a look at the documentation:** +You can go through the sklearn documentation for a better insight of DBSCAN. +https://scikit-learn.org/stable/auto_examples/cluster/plot_dbscan.html#sphx-glr-auto-examples-cluster-plot-dbscan-py + +https://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html + + + +### 👾 DAY 5: Evaluation Metrics for Clustering + +Clustering is only useful if we can evaluate the quality of the clusters it produces. This day will focus on understanding and using various metrics to assess clustering performance. These metrics help us determine how well our clustering algorithms are grouping similar data points and separating dissimilar ones. + +#### a. **Silhouette Score** + +**Definition:** +The silhouette score measures how similar an object is to its own cluster compared to other clusters. It ranges from -1 to 1, where a high value indicates that the object is well matched to its own cluster and poorly matched to neighboring clusters. + +**How It Works:** + +- For each data point: + + 1. Calculate the average distance to all other points in the same cluster (a). + 2. Calculate the average distance to all points in the nearest cluster (b). + 3. The silhouette score for a point is given by: + $$ + s = \frac{b - a}{\max(a, b)} + $$ + +- The overall silhouette score is the average of individual silhouette scores. + +#### b. **Davies-Bouldin Index** + +**Definition:** +The Davies-Bouldin Index (DBI) measures the average similarity ratio of each cluster with the cluster that is most similar to it. Lower DBI values indicate better clustering as they represent smaller within-cluster distances relative to between-cluster distances. + +**How It Works:** + +- For each cluster: + 1. Compute the average distance between each point in the cluster and the centroid of the cluster (within-cluster scatter). + 2. Compute the distance between the centroids of the current cluster and all other clusters (between-cluster separation). + 3. Calculate the DBI for each cluster and take the average. + 4. The DBI is given by: + $$ + \text{DBI} = \frac{1}{N} \sum_{i=1}^{N} \max_{j \neq i} \left( \frac{s_i + s_j}{d_{ij}} \right) + $$ + where $s_i$ and $s_j$ are the average distances within clusters $i$ and $j$, and $d_{ij}$ is the distance between the centroids of clusters $i$ and $j$. + +#### c. **Adjusted Rand Index (ARI)** + +**Definition:** +The Adjusted Rand Index (ARI) measures the similarity between two clustering by considering all pairs of samples and counting pairs that are assigned in the same or different clusters in the predicted and true clustering. It adjusts for chance grouping. + +**How It Works:** + +- Compute the Rand Index (RI): + 1. Count pairs of points that are in the same or different clusters in both true and predicted clusters. + 2. The RI is the ratio of the number of correctly assigned pairs to the total number of pairs. +- Adjust the RI to account for chance clustering, resulting in ARI. + +**Formula:** + +$$ +\text{ARI} = \frac{\text{RI} - \text{Expected\_RI}}{\max(\text{RI}) - \text{Expected\_RI}} +$$ + +#### d. **Practical Guide to Evaluating Clusters** + +1. **Silhouette Analysis**: + + - **When to Use:** To determine the optimal number of clusters and understand cluster cohesion and separation. + - **Practical Example:** Implement silhouette analysis using Python’s scikit-learn library to evaluate K-means clustering results. + +2. **Davies-Bouldin Index**: + + - **When to Use:** To assess the quality of clustering where the clusters are of different shapes and sizes. + - **Practical Example:** Use the Davies-Bouldin Index to compare different clustering algorithms on a given dataset. + +3. **Adjusted Rand Index**: + - **When to Use:** To compare the clustering results with ground truth labels. + - **Practical Example:** Compute the ARI to evaluate the clustering performance on a labeled dataset, such as customer segments with predefined categories. + +🔍 **Explore Metrics in Practice:** +Explore the given metrices and its computation [**here**](https://www.geeksforgeeks.org/clustering-metrics/). + +#### e. **Visualizing Clustering Results** + +Visualization is a powerful tool for interpreting and presenting clustering results. Common visualization techniques include: + +- **Scatter plots**: Useful for low-dimensional data, showing cluster assignments and centroids. +- **Heatmaps**: Visualize distance matrices or similarity matrices. +- **Dendrograms**: Illustrate the hierarchical clustering process. + + + +### 👾 DAY 6: Dimensionality Reduction Techniques + +Dimensionality reduction is crucial in unsupervised learning as it helps in simplifying models, reducing computation time, and mitigating the curse of dimensionality. This day will focus on understanding and applying different techniques for reducing the number of features in a dataset while preserving as much information as possible. + +#### a. **Principal Component Analysis (PCA)**(**Already discussed**) + +#### b. **t-Distributed Stochastic Neighbor Embedding (t-SNE)** + +**Definition:** +t-SNE is a nonlinear technique for dimensionality reduction that is particularly well suited for visualizing high-dimensional datasets. It converts similarities between data points to joint probabilities and tries to minimize the Kullback-Leibler divergence between the joint probabilities of the low-dimensional embedding and the high-dimensional data. + +**How It Works:** + +- Compute pairwise similarities in the high-dimensional space. +- Define a probability distribution over pairs of high-dimensional objects. +- Define a similar distribution over the points in the low-dimensional space. +- Minimize the Kullback-Leibler divergence between these two distributions using gradient descent. + +🔍 **Learn More:** +Understand the intricacies of t-SNE and its implementation [**here**](https://distill.pub/2016/misread-tsne/). + +#### c. **Linear Discriminant Analysis (LDA)** + +**Definition:** +LDA is a linear technique used for both classification and dimensionality reduction. It aims to find a linear combination of features that best separates two or more classes of objects or events. LDA is particularly useful when the data exhibits clear class separations. + +**How It Works:** + +- Compute the mean vectors for each class. +- Compute the scatter matrices (within-class scatter and between-class scatter). +- Compute the eigenvalues and eigenvectors for the scatter matrices. +- Select the top k eigenvectors to form a new matrix. +- Transform the original data using this matrix to get the reduced dataset. + +🔍 **Learn More:** +Dive deeper into LDA and its application [**here**](https://sebastianraschka.com/Articles/2014_python_lda.html). + +#### d. **Uniform Manifold Approximation and Projection (UMAP)** + +**Definition:** +UMAP is a nonlinear dimensionality reduction technique that is based on manifold learning and is particularly effective for visualizing clusters in high-dimensional data. It constructs a high-dimensional graph of the data and then optimizes a low-dimensional graph to be as structurally similar as possible. + +**How It Works:** + +- Construct a high-dimensional graph representation of the data. +- Optimize a low-dimensional graph to preserve the topological structure. +- Use stochastic gradient descent to minimize the cross-entropy between the high-dimensional and low-dimensional representations. + +🔍 **Learn More:** +Learn about UMAP and its effectiveness in data visualization [**here**](https://umap-learn.readthedocs.io/en/latest/). + +#### e. **Practical Guide to Dimensionality Reduction** + +1. **Principal Component Analysis (PCA)**: + + - **When to Use:** When you need to reduce dimensions linearly and want to preserve variance. + - **Practical Example:** Use PCA to reduce the dimensions of a dataset before clustering. + +2. **t-Distributed Stochastic Neighbor Embedding (t-SNE)**: + + - **When to Use:** When you need to visualize high-dimensional data in 2 or 3 dimensions. + - **Practical Example:** Apply t-SNE to visualize customer segments in an e-commerce dataset. + +3. **Linear Discriminant Analysis (LDA)**: + + - **When to Use:** When you need to perform dimensionality reduction for classification tasks. + - **Practical Example:** Use LDA to reduce the number of features in a labeled dataset before applying a classifier. + +4. **Uniform Manifold Approximation and Projection (UMAP)**: + - **When to Use:** When you need a fast and scalable way to visualize high-dimensional data. + - **Practical Example:** Employ UMAP to visualize clusters in genetic data. + +🔍 **Explore Techniques in Practice:** +Learn how to apply these dimensionality reduction techniques using Python and real datasets in this [**comprehensive guide**](https://towardsdatascience.com/dimensionality-reduction-for-visualizing-machine-learning-datasets-430c85105a8d). + +By the end of Day 6, you will have a thorough understanding of various dimensionality reduction techniques, how to implement them, and when to apply each method effectively. This knowledge will be crucial for handling high-dimensional data in unsupervised learning tasks. 🚀 + + + +### 👾 DAY 7: Practical Applications and Project Work + +#### a. **Applying Clustering to Real-World Data** + +Put your knowledge into practice by applying clustering algorithms to real-world datasets. This will solidify your understanding and help you tackle real-life problems. + +🔍 **Try It Out:** +Explore practical clustering applications on [**kaggle**](https://www.kaggle.com/datasets). + +#### b. **Project: Customer Segmentation** + +Work on a project to segment customers based on their purchasing behavior. This project will help you understand how clustering can be used for market segmentation, personalized marketing, and more. + +🔍 **Follow Along with Project:** +Check out this customer segmentation project [**here**](https://www.kaggle.com/code/kushal1996/customer-segmentation/notebook). + +By following this week, you'll gain a strong foundation in clustering and unsupervised learning, empowering you to uncover hidden patterns and insights in your data. Happy clustering! 🚀 + + +## 🦝 Week 8 and beyond (Tensorflow, PyTorch, Projects) + +### 👾 TensorFlow Project + +You will now do a project. You can make use of models available in keras. You would also need to use some pre-processing. + +Go to this link, download the dataset and get working! + +[https://www.kaggle.com/datasets/mirichoi0218/insurance](https://www.kaggle.com/datasets/mirichoi0218/insurance) + +P.S. some features aren't as useful as others, so you may want to use feature selection + +[https://www.javatpoint.com/feature-selection-techniques-in-machine-learning](https://www.javatpoint.com/feature-selection-techniques-in-machine-learning). + +Don't worry if your results aren't that good, this isn't really a task to be done in 1 day. It's basically to give you hands-on experience. Also, there are notebooks available on Kaggle for this problem given, you can take hints from there as well. There are many similar datasets available on Kaggle, you can try those out too! Also, as you learn more topics in ML, you will get to know how to further improve accuracy. So just dive in and make a (working) model. + +Some More Topics: + +Following are some links which cover various techniques in ML. You may not need them all in this project, but you may need them in the future. Feel free to read and learn about them anytime, they are basically to help you build more efficient models and process the data more efficiently. Thus, you can cover these topics in the future as well. + +[https://machinelearningmastery.com/overfitting-and-underfitting-with-machine-learning-algorithms/](https://machinelearningmastery.com/overfitting-and-underfitting-with-machine-learning-algorithms/) + +[https://towardsdatascience.com/regularization-in-machine-learning-76441ddcf99a](https://towardsdatascience.com/regularization-in-machine-learning-76441ddcf99a) + +[https://towardsdatascience.com/train-validation-and-test-sets-72cb40cba9e7](https://towardsdatascience.com/train-validation-and-test-sets-72cb40cba9e7) + +[https://machinelearningmastery.com/k-fold-cross-validation/](https://machinelearningmastery.com/k-fold-cross-validation/) + +### 👾 PyTorch + +By the time you'd reach this subsection, you should have been capable enough to find resources for studying specific topics, or in this case read the documentation to understand the working of a specific library. + +For the sake of the roadmap, you can find a high level overview of PyTorch [here](https://www.youtube.com/watch?v=ORMx45xqWkA), and a crash course over [here](https://www.youtube.com/watch?v=V_xro1bcAuA&t=36151s). Moreover, I can't stress enough on the importance of [documentation](https://pytorch.org/docs/stable/index.html) in programming, so keep referring the same all the time for additional insights. + +Moreover, mess around, find competitions to win, problems to solve via AI and build something valuable which impacts the society in a positive manner 🦝❤️. + +### 👾 Additional Topics + +The Machine Learning BOOM is going on and everyday new models and products are being released in the market, including new architectures and research paper. Post going through this roadmap, you can delve into these topics, which can include but are not limited to: + +1. Reinforcement Learning +2. [Kolmogorov-Arnold Networks](https://arxiv.org/abs/2404.19756): For this you'd require an understanding of Kolmogorov-Arnold Representation Theorem, A little bits of high school mathematics and the use of SPLINES :) +3. Liquid Neural Networks: [This Research Paper](https://arxiv.org/pdf/2006.0443) and [This Medium Article](https://medium.com/@hession520/liquid-neural-nets-lnns-32ce1bfb045a) are good enough to provide an intro to LNNs, post which you can build upon your own. +4. Spiking Neural Networks +5. Audio Analysis with Machine Learning (Audio Machine Learning) + +For understanding Machine Learning from a Probabilistic and Theoretical perspective, you can go through this book: [Elements of Statistical Learning](https://hastie.su.domains/ElemStatLearn/printings/ESLII_print12_toc.pdf) . + +Machine Learning after this point largely gets divided into 2 segments: Computer Vision (The domain where you can differentiate Cute Raccoons 🦝 from Red Pandas ) and Natural Language Processing (wherein you can extract information from text; prolly analyze the sentiment of those texts and respond accordingly with a convincing response 🥰). + +I'm assuming that if you've followed the whole roadmap and have at the end reached this section, you'd have fallen in love with Machine Learning 🦝 and would like to explore more. You can refer to PClub Roadmaps on Computer Vision and Natural Language Processing (mess around, see what you like) and continue your journey :) + +**_Sit Vis Vobsicum_** + +**Contributors** + +- Anwesh Sen Saha \| +91 84519 62003 +- Dhruv Singh \| +91 96216 88942 +- Kartik Kulkarni \| +91 91750 09924 +- Ridin Datta \| +91 74390 79526 +- Talin Gupta \| +91 85589 13121 +- Tejas Ahuja \| +91 87007 94886 +- Aarush Singh Kushwaha \| +91 96432 16563 +- Harshit Jaiswal | +91 97937 40831 +- Himanshu Sharma \| +91 99996 33455 +- Kshitij Gupta \| +91 98976 05316 diff --git a/_posts/2024-06-07-web3-roadmap.md b/_posts/2024-06-07-web3-roadmap.md new file mode 100644 index 0000000..e7f297e --- /dev/null +++ b/_posts/2024-06-07-web3-roadmap.md @@ -0,0 +1,124 @@ +--- +layout: post +title: "Web3 Roadmap" +date: 2024-06-7 02:00:00 +0530 +author: Pclub +website: https://github.com/life-iitk +category: Roadmap +tags: + - roadmap + - crypto + - web3 +categories: + - roadmap +hidden: true +image: + url: /images/ml-roadmap/web3-roadmap.jpg +--- + +## Roadmap to Web3 and Blockchains + +### What is Web3? + +Web3 is a term used to describe the next generation of the World Wide Web, which aims to bring more interactivity and flexibility to the internet. It is based on the idea of using decentralized, distributed technologies like blockchain and peer-to-peer networks to give users more control over their online experiences. + +### Why learn Blockchain and Web3? + +Blockchains and web3 technologies are emerging as powerful tools for building decentralized, secure, and transparent systems. Learning about these technologies can provide valuable insights into how they work and how they can be used to create innovative solutions for a wide range of industries. Additionally, as the adoption of blockchains and web3 technologies continues to grow, knowledge of these technologies can also be a valuable skill for job seekers in the tech industry. + +_Note:_ In case of any doubts while going through this roadmap, You can post your query on the Web3 Channel on the discord server of Programming Club, IIT Kanpur. + +## Week 1: Introduction + +Bitcoin is a remarkable cryptographic achievement, and the ability to create something that is not duplicable in the digital world has enormous value — Eric Schmidt + +Blockchain is the tech. Bitcoin is merely the first mainstream manifestation of its potential — Marc Kenigsberg + +The above given quotes sound good. You can appreciate it better if you have an idea regarding what BitCoin and Blockchain really are. So, this week we will introduce you to Web3, blockchains, and BitCoin. + +| Days | Resources | +| ------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| Day 1-2 | You must’ve come across the term Web3. Ever wondered what exactly it is? Web 3.0 generally refers to the next generation of the world wide web. Just like Web 2.0 started from an abstract concept of sending information on an open network, Web 3.0 goes deeper into building a fairer and more transparent internet. For this reason, Web 3.0 is often associated with blockchain technology.
To get a better understanding, go through the following video: [What is Web 3.0?](https://youtu.be/2uYuWiICCM0)
Another term you surely have heard is blockchain, which is a system of recording information in a way that makes it difficult or impossible to change, hack, or cheat the system.
A blockchain is essentially a digital ledger of transactions that is duplicated and distributed across the entire network of computer systems on the blockchain. To get a better idea of how this is achieved you can refer to the following videos:
- [What is Blockchain? \| Technology behind Bitcoin](https://youtu.be/UqQMSVfugFA)
- [Cryptography \| Blockchain](https://youtu.be/2sPpuMclSQU)
For better understanding, [read](https://onezero.medium.com/how-does-the-blockchain-work-98c8cd01d2ae). | +| Day 3 | A question that arises is why we need a blockchain. Refer to the following video to find the answers to your curiosity: [Why blockchain](https://youtu.be/Dh7OyB5lJ08)?
Other than this, in recent times, there has been a lot of buzz about bitcoins and cryptocurrency, with lots of investors investing in it, calling it the future. Let’s go behind the curtains to find out [How does bitcoin actually work?](https://youtu.be/bBC-nXj3Ng4) | +| Day 4 | Extra Reading to increase your understanding:
- [Fork blockchain -Wikipedia](
- [Merkle tree - Wikipedia](https://en.wikipedia.org/wiki/Merkle_tree)
The two most widely known consensus mechanisms are:
- [Proof of Work \| ethereum.org](https://ethereum.org/en/developers/docs/consensus-mechanisms/pow/)
- [Proof of Stake \| ethereum.org](https://ethereum.org/en/developers/docs/consensus-mechanisms/pos/)
- [Proof of Work vs Proof of Stake: Basic Mining Guide - Blockgeeks](https://blockgeeks.com/guides/proof-of-work-vs-proof-of-stake/)
- [Proof-of-stake (PoS) \| ethereum.org](https://ethereum.org/en/developers/docs/consensus-mechanisms/pos/)
- [51% Attack: Definition, Who Is At Risk, Example, and Cost](https://www.investopedia.com/terms/1/51-attack.asp)
- [Consensus mechanisms \| ethereum.org](https://ethereum.org/en/developers/docs/consensus-mechanisms/)
Smart contracts allow participants to transact with each other without a trusted central authority. A sender must sign transactions and spend Ether, Ethereum's native cryptocurrency, as a cost of processing transactions on the network.
Check this now: [Intro to Ethereum \| ethereum.org](https://ethereum.org/en/developers/docs/intro-to-ethereum/), [Vitalik Buterin Describing Ethereum](https://www.youtube.com/watch?v=TDGq4aeevgY)
Ethereum was conceived in 2013 by programmer Vitalik Buterin when he released the Ethereum Whitepaper ([Ethereum Whitepaper \| ethereum.org](https://ethereum.org/en/whitepaper/)).
In 2014, the development work began and was crowdfunded, and the network went live on 30th July 2015. | +| Day 3 | Ethereum currently runs on the Proof of Stake(PoS) consensus mechanism post “The Merge” which shifted Ethereum from Proof of Work(PoW) to Proof of Stake. The Merge was executed on 15th September 2022. Read more about the merge here: [The Merge \| ethereum.org](https://ethereum.org/en/upgrades/merge/#:~:text=by%20~99.95%25.-,What%20was%20The%20Merge%3F,be%20secured%20using%20staked%20ETH.) | +| Day 4 | Smart contracts are the fundamental building blocks of [Ethereum applications](https://ethereum.org/en/dapps/).
Nick Szabo coined the term "smart contract". In 1994, he wrote [an introduction to the concept](https://www.fon.hum.uva.nl/rob/Courses/InformationInSpeech/CDROM/Literature/LOTwinterschool2006/szabo.best.vwh.net/smart.contracts.html) and, in 1996, [an exploration of what smart contracts could do](https://www.fon.hum.uva.nl/rob/Courses/InformationInSpeech/CDROM/Literature/LOTwinterschool2006/szabo.best.vwh.net/smart_contracts_2.html).
Here is an interesting explanation of Smart Contracts by Vitalik Buterin:
[Smart Contracts - Vitalik Buterin](https://www.youtube.com/watch?v=r0S4qIMf4Pg&ab_channel=TheBitcoin%26CryptoPodcastwithJeffKirdeikis) | +| Day 5 | Anyone can write a smart contract and deploy it to the network. You just need to learn how to code in a [smart contract language](https://ethereum.org/en/developers/docs/smart-contracts/languages/) and have enough ETH to deploy your contract.
Deploying a smart contract is technically a transaction, so you need to pay [Gas](https://ethereum.org/en/developers/docs/gas/) in the same way you need to pay gas for a simple ETH transfer. However, gas costs for contract deployment are far higher.
Ethereum has developer-friendly languages for writing smart contracts:
- Solidity
- Vyper
- [Smart Contracts \| ethereum.org](https://ethereum.org/en/developers/docs/smart-contracts/)
- [Smart Contracts \| Blockgeeks](https://blockgeeks.com/guides/smart-contracts/)
- [Smart Contracts \| IBM](https://www.ibm.com/in-en/topics/smart-contracts)
- [Ethereum Virtual Machine (EVM) \| ethereum.org](https://ethereum.org/en/developers/docs/evm/)
- [Ethereum Virtual Machine (Solidity Documentation)](https://docs.soliditylang.org/en/latest/introduction-to-smart-contracts.html#index-6)
- [Oracles | ethereum.org](https://ethereum.org/en/developers/docs/oracles/)
(OOP) | It is mentioned that solidity is an object-oriented language. No idea what that means?
Well, simply speaking, everything around us is an object. The notion that everything is an object is the concept that underlies object-oriented programming, or OOP for short. These objects contain data, which we also refer to as attributes or properties, and methods. Objects can also interact with each other.
To learn more about the concepts of OOP, you can refer to this [link](https://www.devopsschool.com/blog/object-oriented-programming-oop-concept-simplified/). | +| Day 2
(Solidity Basics) | Now, we are good to go forward to learn about Solidity. It is influenced by C++, Python, and JavaScript and is designed to work on Ethereum, specifically the Ethereum Virtual Machine (EVM). Solidity is statically typed, and supports inheritance, libraries and complex user-defined types among other features.
You will see it is possible to create contracts for voting, crowdfunding, blind auctions, multi-signature wallets and more using solidity. We aim to create and understand the implementations of such complex problems in the real world.
Moving on to references and tutorials for solidity, [TutorialsPoint](https://www.tutorialspoint.com/solidity/index.htm) is a very nice source for learning the basics of solidity. You can skip the Environment setup part and follow the remaining basic part for a quick review of the syntax of solidity.
These 3 are the most important parts of the basic tutorial, though:
- the different [variable types](https://www.tutorialspoint.com/solidity/solidity_variables.htm) in solidity
- [variable scope](https://www.tutorialspoint.com/solidity/solidity_variable_scope.htm) in solidity
- some [predefined variables](https://www.tutorialspoint.com/solidity/solidity_special_variables.htm) that are very important in solidity for various purposes (you might have seen a few of them in the remix samples)
It is always advisable to make modular programs. So, next in line, we have [functions](https://www.tutorialspoint.com/solidity/solidity_functions.htm).
Solidity has different types of functions, such as view functions that do not modify the state (any variable of the smart contract outside the function) and pure functions that do not read AND modify the state. These are mainly for security purposes and to ensure that unauthorized access to the state does not happen when it is not needed. | +| Day 3
(Solidity Continued) | You can read about these [Function modifiers](https://www.tutorialspoint.com/solidity/solidity_function_modifiers.htm) which are something new in solidity which isn't there in any language that I am aware of. It uses the symbol \_; to act as a placeholder for another function, and another function gets inserted into that placeholder when some condition is met.
Go through further topics in the [tutorial](https://www.tutorialspoint.com/solidity/index.htm). (after functions till error handling)
To get familiar with the OOP concepts of solidity, read about [Contracts](https://www.tutorialspoint.com/solidity/solidity_contracts.htm) (basically like classes), [Inheritance](https://www.tutorialspoint.com/solidity/solidity_inheritance.htm) and [Constructors](https://www.tutorialspoint.com/solidity/solidity_constructors.htm) in solidity. | +| Day 4
(Remix IDE) | The best way to try out Solidity right now is using [Remix](https://remix.ethereum.org/). Remix is a web browser-based IDE that allows you to write Solidity smart contracts and then deploy and run the smart contracts.
Now, try out whatever you learned from solidity tutorials in Remix. | +| Day 5-7
(Assignment) | Now, you are familiar with solidity and remix. Here is one assignment you should try out to check if you have completely understood the topics. [Assignment](https://docs.google.com/document/d/1wCvzXhwPgOYUu13LM_OI_w4j--JaMdV-S3ElOATTnb0/edit?usp=sharing) | + +If you prefer to do a step-by-step tutorial and search away on google and docs whenever a new term pops up, then follow this tutorial from [Dapp University](https://www.dappuniversity.com/articles/solidity-tutorial). However, please have a look at the above pages after you are done with it! [Solidity](https://docs.soliditylang.org/en/latest/) is the official solidity documentation if you like to follow official docs. + +## Week 4: WebDev + +In this week, we will learn about web development which is necessary for developing Decentralized Applications + +Also, feel free to take reference from the WebDev Roadmap. ([link](https://docs.google.com/document/d/1V9595eyH3hKFhtuuCZvXwLHxxxihJK1qa2GG6kQlOCg/edit)) + +In the first 4 days, we will cover the basic building blocks of front-end web development(HTML, CSS,JS). + +| Day Number | Info & Resources | +| ---------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | +| Day 1 | [HTML Tutorial (w3schools.com)](https://www.w3schools.com/html/default.asp) (Read till HTML Forms Section) | +| Day 2 | [CSS Tutorial (w3schools.com)](https://www.w3schools.com/css/default.asp)
(No need to go much deep into CSS for now, read till CSS Align) | +| Day 3-4 | [JavaScript Tutorial (w3schools.com)](https://www.w3schools.com/js/default.asp) (Read till JS Modules) | +| Day 5-6 | **React** is a popular front-end Javascript library developed by **Facebook**. Here are some resources to learn it.
[Getting Started – React](https://reactjs.org/docs/getting-started.html)
[Full Modern React Tutorial - YouTube](https://youtube.com/playlist?list=PL4cUxeGkcC9gZD-Tvwfod2gaISzfRiP9d) | +| Day 7 | Node.js is a JavaScript runtime built on Chrome's V8 JavaScript engine. It is a popular choice for developing backends if you are already familiar with Javascript.
Here is a video to get you started:
[Node.js Tutorial for Beginners: Learn Node in 1 Hour](https://youtu.be/TlB_eWDSMt4)
About Rest API:
[RESTful APIs in 100 Seconds // Build an API from Scratch with Node.js Express](https://youtu.be/-MTSQjw5DrM) | + +## Week 5: Dapps, NFTs, DeFi and more + +After learning about the blockchain, the nodes, the consensus, all the major components of this technology and then frontend development, you'll start to wonder, "_What kind of applications can I develop using all this knowledge?_" The applications built on top of Blockchain are called Decentralised Applications, or DApps. + +| Day Number | Resources | +| ---------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------- | +| Day 1 | Generally Dapps have: -
- A standard Front-end built using JavaScript or frameworks/libraries like React, Vue, etc.
- A Solidity/Rust backend, built on top of the blockchain
Now moving on, as you guys know how to create Smart Contracts, you need a way to connect your DApp front-end with your local or remote Solidity backend, using anything from HTTP to Websockets. To do so you can choose between two JavaScript Libraries:
1) Web3.js - web3.js is a collection of libraries that allow you to connect with a local or remote Ethereum node using HTTP, Websockets, and other communication protocols directly from your JavaScript Based front-end.
2) Ethers.js - Ethers.js is a lightweight JavaScript library used as an alternative to Web3.js to connect the JavaScript front-end with Smart Contacts.
Check this: [Web3.js Intro · Web3.js · #1 Ethereum Blockchain Developer Crash Course](https://www.youtube.com/watch?v=t3wM5903ty0) | +| Day 2 | If you don’t like JavaScript we have an alternative Web3.py - A Python library for interacting with Ethereum, inspired by Web3.js, many functions are similar.
[Intro to Web3.py · Ethereum For Python Developers | Dapp University](https://www.dappuniversity.com/articles/web3-py-intro) | +| Day 3-4 | Now that you guys know about the whole frontend-backend stuff and how to connect them with your Dapps, we will move on to more advanced tools that are actually used in doing an actual project.
First, you need to know about [Ganache](https://www.tutorialspoint.com/ethereum/ethereum_ganache_for_blockchain.htm); it's like a local blockchain simulator that helps us deploy and test our blockchain/smart contract using its fake addresses and balance tokens. You might be thinking that we get similar things on Remix IDE, so what's the difference? The difference comes in when we have to deploy big projects where we will use Truffle, and Truffle works with Ganache. Moreover, as you know Solidity is not the only language used in blockchains, there are many other languages that work on Ganache but not on Remix.
Hope you got some idea about Ganache, because now we are moving onto Truffle; It basically provides a developing environment for big projects which need integration of frontend and your smart contract. (Don't mix these with cake types 😅)
Advantage of all this is that using Ganache and Truffle will allow you to use your local editor like VS Code. (It's similar to making an actual app using frontend and backend) It is what you can deploy your contracts to when trying to make the miner’s lives easier. You can plug front ends into back ends through localhost and all that good stuff.
Here is a nice tutorial to install and run Truffle frameworks: [Truffle Guide](https://trufflesuite.com/guides/pet-shop/) | +| Day 5 | Moving towards the end of this roadmap, let's explore NFTs short for Non Fungible Tokens; they represent ownership of digitally scarce goods such as pieces of art or collectibles. These tokens can be implemented on any smart contract based blockchains. It's like the owner of the token owns the information stored under the token, because they store this information (metadata), they can be sold and bought just like any other physical collectible. But does that mean there is a single unique NFT of a type? No, you might have seen or bought multiple copies of the same NFTs, it totally depends on the owner of the NFT on deciding the number of copies to exist, like an artwork which has multiple copies around the world. This is sort of a technical mistake. Technically nothing stops you from creating multiple NFTs pointing to the same metadata, NFTs that contain unauthorized copies of some copyright content etc.
Enough about NFTs right? Now let's move to the most widely used purpose of a blockchain, its Digital Finance or DeFi. Blockchain technology has enabled permissionless networks that can be used by anyone, where built-in economic incentives ensure that network services can be maintained indefinitely without the aid of any individual company or central authority. Isn't it great? This means that there is no third party lurking around our transaction and we are no longer dependent on them to verify it. But there is a downside to everything; Volatility is one of them and also you have to maintain your own records for tax purposes. Regulations can vary from region to region.
NFTs are also used in DeFi, they can be used as collateral while taking a digital loan.
Here are some cool blogs to better understand NFTs and DeFi: [What is NFT and How Does NFT Work? Everything You Need to Know](https://www.simplilearn.com/tutorials/blockchain-tutorial/what-is-nft)
[What Is Decentralized Finance (DeFi) and How Does It Work?](https://www.investopedia.com/decentralized-finance-defi-5113835#:~:text=Decentralized%20finance%2C%20or%20DeFi%2C%20uses,enables%20the%20development%20of%20applications) | +| Day 6-7 | Having completed this roadmap, we would recommend testing your newly developed skill using a self project.
Some of the fascinating ideas to think about are:
- A Crowdfunding Platform using smart contracts- this would enable a safe way of funding, nowadays, the fundings get mixed or displaced, goes to someone else. Many problems like these would be tackled by this idea.
- Peer to Peer Ridesharing - think an app like Uber developed on blockchains.
There is also a playlist of other projects by [Education Ecosystem](https://www.youtube.com/playlist?list=PLQbzkJk10-f5vKvZzA-wxH7BqTUI0K8Vr) (Note these are in Node.js but as you know it's better to always learn along) | + +### What’s Next ? + +To get a strong grasp on all the topics related to web3, try creating as many projects as you can. Also explore [Hardhat](https://hardhat.org/) and [Alchemy](https://www.alchemy.com/). + +Technologists and journalists have described Web3 as a possible solution to concerns about the over-centralization of the web in a few "Big Tech" companies. Some have expressed the notion that Web3 could improve data security, scalability, and privacy beyond what is currently possible with Web 2.0 platforms. Some Web 2.0 companies, including Reddit and Discord, have explored incorporating Web3 technologies into their platforms. + +Therefore, there are a lot of opportunities in web3 as web3 projects are building infrastructure that matters, making way for traditional companies to join the fray. + +We wish you all the best for your journey ahead! + +Contributors:- + +- Devansh Jain 9464327218 +- Mohd Hamza 8795115039 +- Geetika Gupta 9817323838 +- Pratham Sahu 7619678791 +- Divyansh Mittal 8851231264 +- Shivam Mishra 8604397668 diff --git a/_posts/2024-06-07-webdev-roadmap.md b/_posts/2024-06-07-webdev-roadmap.md new file mode 100644 index 0000000..b3304b0 --- /dev/null +++ b/_posts/2024-06-07-webdev-roadmap.md @@ -0,0 +1,139 @@ +--- +layout: post +title: "Web Development Roadmap" +# summary: "Start on your journey to make professional websites." +date: 2024-06-7 02:00:00 +0530 +author: Pclub +website: https://github.com/life-iitk +category: Roadmap +tags: + - roadmap + - dev + - web +categories: + - roadmap +hidden: true +image: + url: /images/ml-roadmap/webdev-roadmap.jpg +--- + +# Roadmap to Web Development + +### What is Web Development? + +Web Development refers to the process of creating and maintaining websites on the internet. It can be broadly classified into frontend and backend development. Frontend Development means writing code that your browser will run, whereas backend code runs on a server. + +### Why learn Web Development? + +Web Development is easy to start with and introduces you to a variety of programming concepts. It even introduces you to the most popular programming language in the world i.e JavaScript. Secondly, it is an evergreen skill, the internet isn’t going to disappear anytime soon, after all. Also it is a good way to deploy projects related to other domains. Made a new SOTA machine learning model? Show it to the world by making a web app! + +_Note:_ In case of any doubts while going through this roadmap, You can post your query on the Webdev Channel on the discord server of Programming Club,IIT Kanpur. + +## Week 1(Basics) + +Let us dive into the world of web development by learning the basics of how the web works and making our first website. This week you’ll be learning about HTML and CSS, which are the basic building blocks of websites. + +| Day Number | Resources | +| ---------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| Day 1 | Let us start by learning how the web actually works, what does it mean to actually make a website?
[How does the web work?](https://www.youtube.com/watch?v=hJHvdBlSxug)
From week 3 we’ll be talking a lot about servers, it helps to know about what exactly is a server.
[What is a server?](https://www.youtube.com/watch?v=VXmvM2QtuMU)
What are the rules that govern the web?
[Blog on web protocols](https://biratkirat.medium.com/how-does-web-work-7fb8c8a41ae7)
Note: You don’t need to spend a lot of time here if you know the basics like domain names, DNSs, servers, web browsers, hosting. | +| Day 2 | Now let’s actually get started with coding! I recommend you to install VS Code(you can use any other editor that you like, but VSCode has a few extensions that really help) and set it up like [this](https://www.youtube.com/watch?v=4NfFFsQC77M). For Linux users: [Link](https://code.visualstudio.com/docs/setup/linux)
Familiarise yourself with the interface and the basic shortcuts (creating a new file, closing the file, saving the file, etc.).
After this you can start with learning HTML. HTML stands for HyperText Markup Language. It is used on the frontend and gives the structure to the webpage. Learn more from here: [HTML Tutorial](https://www.youtube.com/watch?v=pQN-pnXPaVg), [HTML text tutorial](https://www.w3schools.com/html/) | +| Day 3 | Now you know how to make a website, but it looks really bland, let’s add some style by using [CSS](https://www.youtube.com/watch?v=OEV8gMkCHXQ).
You can learn more about CSS from here: [CSS Tutorial](https://www.youtube.com/watch?v=yfoY53QXEnI), [CSS text reference](https://www.w3schools.com/cssref/index.php)
(NOTE: CSS is vast and you do NOT need to remember all the properties, if you have a gist of what you need to do, you can do a google search to get answers) | +| Day 4 | CSS can be frustrating at times, especially if you cannot get the things where you want them to be(layouting).
[This](https://www.youtube.com/watch?v=vHuSz4fRM88) video provides some tips regarding layouting.
You can practise your CSS skills using this [game](https://flexboxfroggy.com/). | +| Day 5 | We’ll dive a little bit deeper into CSS, there are a lot of frameworks for writing CSS like bootstrap, tailwind, SASS etc. [This](https://www.youtube.com/watch?v=ouncVBiye_M) video goes over a few of them.
One of the really helpful tools for making quick UIs is bootstrap, which is especially helpful when you are learning something more advanced and need a UI for testing [Here's a quick tutorial](https://www.youtube.com/watch?v=-qfEOE4vtxE)
These are just the basics but feel free to dig deeper as you need. | +| Day 6 | A lot of people struggle with the fact that they can’t come up with good designs, which is totally fine. As a frontend engineer it is NOT your job to come up with designs, that part goes to the UI/UX team, but it does help to know the basic design principles.
Check this: [Design fundamentals](https://www.youtube.com/watch?v=_Hp_dI0DzY4), [UI Design Blog](https://www.getcloudapp.com/blog/marketing/ui-design/) | +| Day 7 | It’s time to make something on your own! If you have an idea of a website, try making it using HTML and CSS, otherwise, try to clone an existing website like the [PClub Website](https://pclub.in/). | + +Make sure to do the exercise on Day 7 before jumping ahead, building projects is an important part of learning. Don’t forget to share your work on the #web-dev channel on the [PClub discord server](https://discord.gg/azTgV6ZUyx)! + +## Week 2(JavaScript) + +Finally, a programming language, JavaScript!!! + +Now let us start with javascript ie. the language of the web! This is where the more “logical” side of web development starts. + +| Day Number | Resources | +| ---------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| Day 1 | **Intro To JavaScript**:
A JavaScript roast for motivation and to know its history in brief. [JavaScript for the Haters](https://www.youtube.com/watch?v=aXOChLn5ZdQ)
Understanding computer languages - quick reads:
[What is a programming language?](https://www.javatpoint.com/programming-language)
[5 Types of Programming Languages](https://www.coursera.org/articles/types-programming-language)
[Difference between Compiled and Interpreted Language](https://www.geeksforgeeks.org/difference-between-compiled-and-interpreted-language/)
Introduction to programming in JavaScript: [An overview of JavaScript](https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/JavaScript_basics) | +| Day 2 | **Learning JavaScript**:
It is now time to start learning JavaScript. We have included an 8-hour YouTube video, which you can break into four parts and do one part daily.
NOTE: Code while you watch the video and attempt to create some of your own versions.
[JavaScript Programming - Full Course](https://www.youtube.com/watch?v=jS4aFq5-91M) (First Part - Till linking stylesheet - 2:00:56) | +| Day 3 | [JavaScript Programming - Full Course](https://www.youtube.com/watch?v=jS4aFq5-91M) (Second Part - Till Logical OR operator - 3:51:52) | +| Day 4 | [JavaScript Programming - Full Course](https://www.youtube.com/watch?v=jS4aFq5-91M) (Third Part - Till Style list - 5:46:13) | +| Day 5 | [JavaScript Programming - Full Course](https://www.youtube.com/watch?v=jS4aFq5-91M) (Fourth Part - Till 7:44:19)
Note: JavaScript is also used for building entire applications or as a back-end programming language but at this stage, we just want to learn the basics. | +| Day 6 | **Building games in JavaScript**:
JavaScript is now sufficiently familiar to you.
It's time to put your knowledge to use and construct something. I've included a 5-hour lesson on how to create some fun JavaScript games. This can be done over the course of the following two days in two sections.
NOTE: Code while you watch the video and attempt to create some of your own games.
[Learn JavaScript by Building 7 Games - Full Course](https://www.youtube.com/watch?v=ec8vSKJuZTk) (First Part) | +| Day 7 | [Learn JavaScript by Building 7 Games - Full Course](https://www.youtube.com/watch?v=ec8vSKJuZTk) (Second Part) | + +Now that you know javascript, try making a [Simon Says Game](https://www.mathsisfun.com/games/simon-says.html), without watching any tutorial. + +## Week 3(Backend) + +Now that you know about the frontend, let’s start working on actual functional websites with a server. + +Here we have provided 2 pathways. One through Go and the other through Python(Django). While Golang being fast & scalable is mostly used for developing microservices softwares and cloud computing , on the other hand, Python providing for a huge number of libraries & community support is mostly used for AI,ML and data analysis. You should learn any one of them right now , but after you are done with the roadmap, you are suggested to come back and go-through the alternative pathway too. + +**THE GO PATHWAY** + +| Day Number | Resources | +| ---------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | +| Day 1 | **Intro to Go**
First we’ll learn the basics of Golang for developing our entire backend from scratch. Go is a language created by google and is one of the best choices to create scalable backends. [What is Go?](https://www.youtube.com/watch?v=446E-r0rXHI).
[Go tutorial](https://go.dev/tour/list) (_suggested to complete till_ “_More types: structs, slices, and maps “ for now)_
**NOTE:** To learn the backend, what's better than starting a project. From now onwards , we will follow the book “Let's Go” by Alex Edwards which is a step-by-step guide to create your first web-application(a Snippetbox- which lets people paste and share snippets of text) in Golang from scratch.
[**Book is available here**](https://drive.google.com/drive/folders/1lbDldlXYxUPTAOciiyivg9qswzRPFsQk?usp=share_link)
In case of any doubts while going through any of the implementations of the above book , it's suggested to go through the [Go documentation](https://pkg.go.dev/std) | +| Day 2 & 3 | **Foundations**
We will follow chapter-2 from the Let's Go book. It will guide you right from installing Go on your system.
**Note:** In case you are already familiar with the VS Code environment, you can continue it as your Go IDE , else you are strongly suggested to [download Goland](https://www.jetbrains.com/go/download/#section=windows) as your IDE. You can use an educational licence to access it.
Then this book will help you to go through the basics of web-applications and then implement how to route requests to multiple , custom HTTP headers.
Then, you will learn how to integrate HTML pages and various features of frontend like CSS , javascripts that you learnt in previous weeks in this project.
Suggestion: Write the code (even though it's hard to understand) rather than just Ctrl + C/V.
Then we will cover chapter-3 of this book. This chapter is a bit small and the major concepts it covers are Dependency Injections and error handling. | +| Day 4 | **Databasing**
We will cover chapter-4 of this book. Databasing is one of the major parts of creating web-applications.But first lets see [what they are and why are they important](https://www.ramotion.com/blog/database-in-web-app-development/#:~:text=The%20database%20stores%20information%20about,data%20structures%20with%20minimal%20effort.) . This chapter helps you go through an implementation of MySQL database. | +| Day 5 | **Displaying dynamic HTML templates**
We will cover chapter-5 of this book. This portion will help you implement displaying HTML pages using the dynamic data from our MySQL database created above. | +| Day 6 | **Middlewares and RESTful routing**
We will cover chapter-6 and 7 of this book. This part of the book will provide you with an explained implementation of [Middlewares and REST APIs](https://www.youtube.com/watch?v=1oWPUpMheGk) through routers. | +| Day 7 | **Form processing and Testing**
We will cover chapter-8 and 13 of this book.
Chapter-8 helps you to implement how to process,parse and then store the data(upon validation) as entered by the user on your website.
_Upon completing this chapter, you would have created your own website from scratch._
**Note:** In case you are interested to learn the whole deployment of the web application, you may go through chapters 9 - 12 which basically help you improve your web application by displaying flash messages to users, and security improvements to the website.
Now having made your website, the next important aspect of creating any web-application is its **testing**. Chapter -13 will provide you with the basic syntaxes to creating tests to the components/services you have added to your website. | + +**THE DJANGO(PYTHON) PATHWAY** + +Django is a high-level Python web framework that encourages rapid development and clean, pragmatic design. That’s why we are providing an alternate pathway for the backend . + +| Day Number | Resources | +| ---------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| Day 1 | **Basics of Python and Django**
Let's first start learning the [basics of Python](https://www.youtube.com/watch?v=kqtD5dpn9C8). You can implement them using Google Colab in case you have not installed Jupyter notebook.
**Note** : In case you are already familiar with the basics of Python, you can skip this part and go ahead.
Now let’s [install Django](https://www.youtube.com/watch?v=HBE4K1Xu9us) on your dabbas and go through a [quick overview](https://docs.djangoproject.com/en/4.1/intro/overview/) of the functionality of Django.
(You are suggested to use a virtual environment to build your projects in Django, as this will make your code less error prone with version updates of Django and other packages. You can use the "virtualenv" package for this purpose)
**In case of any doubts while going through any of the implementations of the above book , it's suggested to go through the** [**Django documentation**](https://docs.djangoproject.com/en/4.1/)**.** | +| Day 2 | **Learning Django**
Now we will follow [this website](https://www.dj4e.com/lessons) on our journey of learning Django. Its videos are [compiled here](https://www.youtube.com/watch?v=o0XbHvKxw7Y).
**Note**: Code while you watch the video and attempt to create some of your own versions.
We will cover the basics of a web application server and HTTP protocols. Watch [this video](https://www.youtube.com/watch?v=o0XbHvKxw7Y&t=424s)(00:07:04-01:17:39) for the same.
Since we have already covered HTML and CSS before , we won’t be covering them here again.
Additionally, you might see some of the open-source [django sample codes](https://github.com/csev/dj4e-samples) available on this github repo and analyse them. | +| Day 3 | **Databasing**
Databasing is one of the major parts of creating web-applications.But first lets see [what they are and why are they important](https://www.ramotion.com/blog/database-in-web-app-development/#:~:text=The%20database%20stores%20information%20about,data%20structures%20with%20minimal%20effort.) (in case you haven’t gone through the Go pathway).
Watch [this video](https://www.youtube.com/watch?v=o0XbHvKxw7Y&t=13313s)(03:41:53-05:25:09) to see their implementation in Django. | +| Day 4 | **Generating HTML forms & dynamic routes**
We will learn now about Routes , rendering HTML templates in Django and HTTP requests. Then we build dynamic HTML forms and protect our applications from CSRF.
Watch [this video](https://www.youtube.com/watch?v=o0XbHvKxw7Y&t=19509s)(05:25:09 - 07:29:09 ) to see their implementation in Django. | +| Day 5 | **Data Modelling & Authentication**
We will learn about cookies and sessions, data modelling, and user authentication and its interaction with our application.
Then we learn about the use of Form objects in Django and how they simplify our work.
Watch [this video](https://www.youtube.com/watch?v=o0XbHvKxw7Y&t=26949s) ( 07:29:09 - 09:13:20 ) to see their implementation in Django.
**Note:** Though there are walkthroughs of sample codes present in the video , you are suggested to first analyse the relevant sample codes on your own from [Day-2 link](https://github.com/csev/dj4e-samples) as a small exercise on each day. | +| Day 6 | **Owned Objects, JS & jQuery**
We will first learn about how objects are marked as owned
([video](https://www.youtube.com/watch?v=o0XbHvKxw7Y&t=38198s) : 10:36:38 - 11:05:58 ), and then take a quick look through OOP in Java-Script([video](https://www.youtube.com/watch?v=o0XbHvKxw7Y&t=49265s) : 13:41:05 - 13:58:37) , and then take a go-through to jQuery library([video](https://www.youtube.com/watch?v=o0XbHvKxw7Y&t=53827s): 14:57:07 - 15:49:29 )to use it for manipulations of Data Browser Model(a sample walkthrough is also added).
Then we learn about JSON([video](https://www.youtube.com/watch?v=o0XbHvKxw7Y&t=58226s) : 16:10:26 - 16:40:34 )which is used as a syntax to exchange data between the running code on the server and the browser. | +| Day 7 | **Project time !**
Now having seen most of the things about Django and having gone through multiple sample codes , it is strongly recommended that you make your own backend without following any tutorial. You could try to create the backend of some PClub IITK websites (perhaps [Student Search IITK](https://search.pclub.in/)). | + +**Week 4(React)** + +Next thing you need to learn is React. React is a frontend library created and maintained by Facebook used to create Single Page Applications. It makes the process of frontend development much faster and is one of the most in-demand skills in the industry. + +| Day Number | Resources | +| ---------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| Day 1 | Learn the fundamentals of React and what kind of problems it solves. Check [Videos 1-5](https://youtube.com/playlist?list=PL0Zuz27SZ-6PrE9srvEn8nbhOOyxnWXfp) till react click events.
Check this too - [Learn React by making Tic-Tac-Toe](https://reactjs.org/tutorial/tutorial.html) | +| Day 2 | Hooks and props are fundamental features of react. Learn these topics from here: [Videos 6-10](https://www.youtube.com/playlist?list=PL0Zuz27SZ-6PrE9srvEn8nbhOOyxnWXfp) | +| Day 3 | Explore how to use APIs in react and the useEffect hook.
Check [Videos 11-15](https://www.youtube.com/playlist?list=PL0Zuz27SZ-6PrE9srvEn8nbhOOyxnWXfp) till fetching API data.
Check this blog now: [React useEffect Hook](https://www.freecodecamp.org/news/react-useeffect-absolute-beginners/) | +| Day 4 | Learn about how to add routing in your react app from
[Videos 16-21](https://youtube.com/playlist?list=PL0Zuz27SZ-6PrE9srvEn8nbhOOyxnWXfp) till state management in React. | +| Day 5 | Next is how to manage the state of your application in large projects? This is where redux comes in!
Check this : [Redux Intro](https://www.youtube.com/watch?v=_shA5Xwe8_4), [Redux Tutorial for beginners](https://www.youtube.com/watch?v=CVpUuw9XSjY) | +| Day 6 | What’s next in the React ecosystem? As I mentioned, react is a library. There are a lot of frameworks built upon react which make the process of development easier.
[What is NEXT.js?](https://www.youtube.com/watch?v=Sklc_fQBmcs)
[What is Vue js?](https://www.youtube.com/watch?v=nhBVL41-_Cw)
(NOTE: You need not to go in depth of all these frameworks right now, the world of web frameworks is vast and you do not need to learn every single one) | +| Day 7 | Now that you know the basics of React and backend development, it’s time to build a project.
[To Do List](https://www.youtube.com/watch?v=QevhhM_QfbM) | + +Now that you know about react, it’s time for a challenge, make a note posting website, [like this one](https://note.ly/#). Use what you learnt in the previous week to make sure the notes are stored in a database and are loaded back as soon as the user opens up the page! + +**Week 5(DevOps)** + +Now that you’ve made a website, how will you share it with the world? How will you maintain and monitor your website? This is where DevOps comes in! + +| Day Number | Resources | +| ---------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| Day 1 | Git
Git is an important version control tool, it is used a lot in the industry. As a developer you must know how to use it.
Let’s start by installing git,
For windows, refer [here](https://nerdschalk.com/how-to-install-and-use-git-on-windows-11/) \| For Linux, refer [here](https://git-scm.com/book/en/v2/Getting-Started-Installing-Git)
Before starting, it is really helpful to get familiar with the terminal, [shell tutorial](https://www.youtube.com/watch?v=Zl7npywCB84). Most commands you see here will also work on windows powershell.
You can learn more about here : [Git Video Tutorial](https://www.youtube.com/watch?v=IHaTbJPdB-s), [Blog on Git](https://jwiegley.github.io/git-from-the-bottom-up/) | +| Day 2 | Git+Github
Github is a platform where you can keep your code for the world to see! Is also used when multiple people have to contribute to a project.
[What If you mess up?](https://ohshitgit.com/)
To get started with github, we suggest making an account with the IITK email id to avail the student pack, which comes with a lot of benefits. To learn about github, the official docs are a great place to start [Github Docs](https://docs.github.com/en/get-started/quickstart/hello-world).
Also, to get started you need to set up an SSH key, follow [this tutorial](https://www.youtube.com/watch?v=WgZIv5HI44o).
Learn more from here: [Git + Github](https://www.youtube.com/watch?v=HkdAHXoRtos), [Learn git branching](https://learngitbranching.js.org/) | +| Day 3 | Github Actions
Now that you know about github, it is time to implement some CI/CD using github actions.
[What is CI/CD](https://www.youtube.com/watch?v=scEDHsr3APg&t=14s)
[Workflow for a React App](https://youtu.be/5I37iVCDUTU) | +| Day 4 | Docker
Docker is a tool for containerizing your applications so that they can run on any platform! It is one of the most important tools used in the industry as it saves a lot of time. Check : [What is Docker?](https://www.freecodecamp.org/news/what-is-docker-used-for-a-docker-container-tutorial-for-beginners/), [Docker Tutorial](https://www.youtube.com/watch?v=pTFZFxd4hOI&t=27s) | +| Day 5 | Deployment
Now it’s time to deploy your application to a server with everything we have learnt! DigitalOcean is a very good and economical service to do the same.
[In Depth guide to deploy a webapp on DigitalOcean with docker and Github Actions](https://www.youtube.com/watch?v=JsOoUrII3EY) | +| Day 6 | Deployment
[Deployment Guide - Part 2](https://www.youtube.com/watch?v=hf8wUUrGCgU)
(NOTE: DigitalOcean is a paid service so you don’t need to actually host your website there you can use heroku). | +| Day 7 | Kubernetes
Kubernetes is a service designed by Google which is used to manage and deploy multiple containers.
[Kubernetes Academy](https://kube.academy/) | + +**What’s Next?** + +The world of development is vast and there is a lot to explore, this roadmap is in fact just a beginning in your development journey. If you are interested, we suggest you learn more about Next.js(briefly mentioned in week4), MongoDB(a NoSql database), firebase, APIs, Regular Expressions and PostGre(another SQL database, but much more advanced and prevalent in the industry). + +Web Development is a gateway to a lot of opportunities in Open Source. The huge benefit of contributing to open source is that you can network with other developers. This means that you'll meet new people and make friends, collaborate with other developers on projects, find mentors and have an opportunity to learn from each other. [Here](https://www.geeksforgeeks.org/best-open-source-programs-for-students-to-participate/amp/) is a list of competitions for students. We wish you all the best for your journey in web development! + +**Contributors -** + +- Shivam Sharma 9773521108 +- Mihir Mittal 9004035048 +- Ankush Yadav 9024503686 +- Rahul Jha 8700367670 +- Shivam Mishra 8604397668 diff --git a/_posts/2024-07-04-app-dev-roadmap.md b/_posts/2024-07-04-app-dev-roadmap.md new file mode 100644 index 0000000..b437c21 --- /dev/null +++ b/_posts/2024-07-04-app-dev-roadmap.md @@ -0,0 +1,872 @@ +--- +layout: post +title: "App Development Roadmap" +# summary: "Start on your journey to make professional websites." +date: 2024-07-04 02:00:00 +0530 +author: Pclub +website: https://github.com/life-iitk +category: Roadmap +tags: + - roadmap + - dev + - app + - android + - ios +categories: + - roadmap +hidden: true +image: + url: /images/ml-roadmap/appdev-roadmap.jpg +--- + +# Introduction: + +## What is APP DEVELOPMENT? + +Nothing much fancy or too mysterious to tell about. But basically, app development epitomizes the meticulous orchestration of intricate software applications poised to traverse an extensive gamut of platforms including mobile apparatus, desktop interfaces, and web conduits. This cerebral undertaking is underscored... + +More of a boring stuff right? But what we believe here in PClub is that app development is the magical process of turning your wildest ideas into little digital buddies that live on your devices. Imagine having a personal army of tiny obedient robots ready to entertain you, keep you informed about your girlfriend’s message, or even help you order pizza at 2 AM. That's app development in a nutshell! Interesting, huh? :) + +## Why APP DEVELOPMENT? + +- Learning app development enhances essential technical skills like coding, problem-solving, and software design. It cultivates proficiency in programming languages alongside familiarity with development frameworks and tools. +- Mastering app development equips individuals with in-demand abilities crucial for careers in technology, providing a solid foundation for growth and specialization within the industry. + +# Getting Started: + + + +## Choosing A Framework + +What framework should I use for App Dev? + +Now here comes the most fundamental question about choosing the framework. There exist many options for that like React Native, Flutter, Ionic, Xamarin, etc. Now we will be using Flutter as our framework further in our roadmap. + +Wait, what? You want to know why? Well, why wouldn't we use Flutter? I mean who doesn't love darting around with a fluttering feeling of excitement? If this doesn’t make sense, watch these videos to find out about what Flutter is, what that darting means, and why we should use it. + +- +
+  +
+  +
+
+  +
+  +
+
+  +
+  +
+
 +
++ +Alternatively, check out this blog [Navigation and Routing](https://www.javatpoint.com/flutter-navigation-and-routing) +Or refer to the docs [Navigation and routing | Flutter](https://docs.flutter.dev/ui/navigation) + +Let us make our app interactive now. Check out these widgets first: + +- +
 +
+ +
+ +
+
+
+ +
+
+
+ +
+
+
+ +
+
Contents :
+ +Section 0: Introduction + :
+ +What is CP and Why do + it?
++-
+
+ -
+
+ -
+
+
+
+ - Codeforces
+ - Atcoder
+
+
+
+
+
+It's a mind-sport where you are given a problem and have to come up with optimized solutions + for the given constraints with your problem-solving skills and implement with your coding + skills.
+We do it because it helps us in building our logical and analytical thinking skills and also in + enhancing our knowledge. But most importantly, because it’s a lot of fun! (and it helps get a + job 👀)
+Some Popular CP Platforms are
+- Codechef
- Topcoder
- Leetcode
- Hackerrank
We will look into them further as we go on!
+➡️Getting Started +
+Learn C++ :
++-
+
+ -
+
+ -
+
+ -
+
+
+If you have already gone through ESC112( any Coding Course in C) then you may follow this + article for a smooth transition : Moving from C to C++
+If you have no prior coding experience , you can follow :
++-
+
+ -
+
+
+For youtube fans :(They also have a guide to setup)
++- Bro Code : [first 5 hours]
+ - Free Code Camp : [first 3 hours]
+
++ OR +
If you prefer to read, then :
++- USACO : PAPS(book Chapter 2)
+ - Learn C++ (Just the intro and functions
+ parts)
+
++ OR +
Register on these domain : Toph , CodeChef ; and then solve the given + problems :
+ +In the end, you truly learn the language after you have sufficient experience. Try out as many + problems from these links :
+ +Setting Up Environment + :
+We prefer VS CODE because of obvious reasons , still
+ feel free to use any other usable Code Editor like : sublime text , codeblocks , etc.
, still
+ feel free to use any other usable Code Editor like : sublime text , codeblocks , etc.
++-
+
+
+
+ -
+
+
+Windows : you can watch the same video from above from [0:1:27] to [0:8:40]
+Currently you will be able to work fine with #include<iostream> , but in + future if you’re facing issues with #include<bits/stdc++.h> on VS code then watch this video.
+Mac : Download and install VS Code from https://code.visualstudio.com/ and then Set it + up for C++. After this, it is best to change your compiler to + gcc.
++ You can follow this tutorial to install gcc. +
➡️Basic Problem + Solving
++-
+
+
+
+ -
+
+ -
+
+
+
+ -
+
+
+ + Your first problem on Codeforces
+ Your first problem on Codeforces
++- Starting with a less interactive platform like CodeForces can be difficult, but don't
+ worry we got your back :
+ -
+
+ -
+
+ -
+
+ -
+
+ -
+
+
++- start by registering yourself on https://codeforces.com/
+
++- Here's Everyone's First
+ Problem, have a look
+
++- Head to your local IDE
+
++- When you pass the sample inputs locally, click on Submit.
+
++- You can paste your entire code to the Source Code section (OR upload your
+ solution.cpp file) and press Submit.
+
+PS : We recommend enrolling yourself in the "ITMO Academy: pilot + course" on Courses - + Codeforces. It contains great problems as well as theory + which we'll cover as we move forward. By the end of the roadmap, you can independently + finish it !
+ + More problems from CodeForces
+ More problems from CodeForces
+ + + Your first problem on CSES
+ Your first problem on CSES
++- CSES is a problem set : register yourself
+
+ -
+
+ -
+
+ -
+
+ -
+
+
++- Link : Problem 1 ;
+ here you can only submit the solution as a file. Head to your local IDE and
+ write up a 'solution.cpp'
+
++- Run locally and check the code
+
++- Press on the Submit tab and Upload the code file. The results of Online Judge
+ will be displayed in some time.
+
++- Make sure to use long long int ;)
+
+ + Your first problem on SPOJ.com : Problem
+ TEST
+ Your first problem on SPOJ.com : Problem
+ TEST
+Fast I/O (optional + for now):
+What it is :
++- Significance of fast I/O - Stack Overflow
+ OR
+
+ - Fast IO
+ in C++ for Competitive Programming! (and when to not use it)
+
+Try this problem with Fast I/O :
+ ++-
+
+
+
+
+
+
+
+ -
+
+ -
+
+
+ + Your First Problem on USACO
+ Your First Problem on USACO
+About USACO :
++- USACO has problems revolving around Farmer John's Farm and (mostly) His Cows.
+
+ - Make a new account here. Whenever you go to a problem, you can press the 'Overview'
+ tab to head to the same page for logins.
+ - You can only submit the solution as a file; apart from that you might be required to
+ get input from a file , output your answer to a file (all that will be processed on
+ server).
+ - Ex : mixmilk.in for input and mixmilk.out for output.
+ Then you need to add these lines at the start of your code:
+
+ +(know more about it here / official page )
+Or you may make your template for USACO problems like :
+Template - (Fast I/O included)
+ +First Problem
++- Link : Mixing Milk ; Head to your local IDE
+ and write up a solution.cpp.
+ - Create mixmilk.in locally in the same folder as your
+ solution.cpp; enter sample input in it (treat .in and .out as .txt files).
+ - Run locally and check the code.
+ - Upload the file, Select C++11, Submit. The results of Online Judge will be displayed
+ in some time.
+
+ + More problems on USACO :
+ More problems on USACO :
+ + + More practice to get comfortable
+ (optional)
+ More practice to get comfortable
+ (optional)
++- Brute Force
+ Problems | Toph
+ - Implementation Problems | Toph
+ - Geometry
+ Problems | Toph
+
+Basic Math + Problems
++
Some suggestions from the + Makers :
++- We believe that a lot of practice is what shapes you in CP ; apart from the questions found
+ here , it is suggested to practice more problems whenever you feel.
+
++- It is sometimes okay to look up the solution / editorial (for codeforces). Don't fret if
+ you're not able to solve a problem, you'll get it with practice.
+
++- The "
 + Expected time" is the amount of time you will need to give to prepare the theory in a heading
+ before practicing.
+ Expected time" is the amount of time you will need to give to prepare the theory in a heading
+ before practicing.
+
++- Take your time to understand things and implement them. The expected time is suggestive and
+ varies from person to person, but do not spend too much time on a single topic.
+
++- Consistency is very important in CP. It is highly recommended that you keep practicing it at
+ your own pace daily, rather than doing it all at once. It is a skill that develops over
+ time.
+
++
➡️Time Complexity +
+ ++- Why
+ you need to know about it
+ - CPH Ch 2
+
+ - Watch this
+ for more examples
+
+Solve these in O(n) :
+ +➡️Intro to STL +
+ ++- Complete C++
+ STL in 1 Video | Time Complexity and Notes Watch till 35:57.
+
+
+ - The Complete Practical Guide to C++ STL(Standard Template
+ Library) | by Abhishek Rathore | Medium
+
+Basic Array / Vectors + Problems
+ +Basic String + Problems
++-
+
+ -
+
+
+Your intro to strings : C++ Strings (With Examples)
+ +Basic Stack Problems
+ +➡️Sorting
+ ++- CPH page
+ 25 Read Chapter 3 from ‘Competitive Programmer’s Handout’
+ - Sorting Algorithms | LeetCode The Hard Way (optional)
+
+ - Tutorial with
+ Visualisation
+
++- problems :
+
+
+
+More on STL
+ ++-
+
+ -
+
+ -
+
+ -
+
+
+Continue from 35:58 : Complete C++ STL in 1 Video | Time Complexity and + Notes
+Basic Set / Multiset Problems
+ +Basic Map Problems
+ +Custom comparator
+ +Each Data Structure in STL has its own strengths and weaknesses. Try to think what to use according to + the problems.
+➡️Binary Search +
+ ++-
+
+ -
+
+ -
+
+
+Tutorial + with Visualisation
+Binary Search | Code Accepted
+ +Additional Practice
+ +➡️Bit Operations +
+ ++- Bit Manipulation | LeetCode The Hard Way
+ - CPH Bit
+ Manipulation (extra)
+ - Bit manipulation - CP Algorithms
+
++- Problems :
+
+
+
+➡️Primary Number + Theory
+ ++- Elementary Number Theory
+ - “Output the answer modulo 10^9 + 7” | Code Accepted
+ - [Blog] Modular
+ Arithmetic for Beginners - Codeforces
+
+Binary + Exponentiation
+ ++- Binary Exponentiation | Code Accepted
+ - Binary exponentiation | AlgorithmClear Blog
+ - Binary Exponentiation - Faster way to calculate Pow(x,n)
+ [Python] | Medium
+
+
+
++ or +
+ or +
Factorisation [till + O(rootN)]
+ ++- Primality Testing | Code Accepted
+
+
+
+ - Trial division
+
+
+
+we’ll cover Sieve of Eratosthenes later*
+Gcd
+ ++- Greatest Common Divisor | Code Accepted
+ - Gcd
+
+
+ - More Practice
+
+
+
+➡️Recursion
+ ++- C++
+ Recursion (With Example)
+ - The classic recursion problem : Tower of hanoi or Video
+ - Read this article on recursion (you may skip the
+ introduction ) . CSES : Chessboard and Queens try this question
+ which is an extension of the N Queens Problem .
+
++- Basic Recursion problems:
+
+
+
+➡️Complete Search +
+ ++- CPH ch 5
+
+ - Bit Masking | Code Accepted
+ - Backtracking | Code Accepted
+
++- Problems:
+
+
+
+By now, you may have realized that debugging your code efficiently is very important. For a few + tips on debugging, you can go through this article / this + video.
+➡️Section 0 Additional + Practice:
+ +Section 1: Basic + Theory
+ + +➡️Number Theory +
+Number Sieve
+ ++- (Sieve of Eratosthenes - Wikipedia)
+ - (Sieve of Eratosthenes - CpAlgorithms )
+
+
+ - Faster Prime Factorisation
+
+
+
+
++ or +
+- CSES : Counting Divisors : attempt it
+ and have a look at this solution
+ or
+
+ - Prime Factors in Log(N) Tutorial | LeetCode The Hard
+ Way :::
+
++- Problems :
+
+
+
+Modular Multiplicative + Inverse
+ ++- Modular Multiplicative Inverse | forthright48
+
+ +Additional Practice + :
+ +➡️Two Pointers / Sliding + Windows
+ ++- CPH
+ - video
+ - Problems
+
+
+ - Additional problems
+
+
+
+➡️Range Queries +
+
+ +Prefix Sums are Intensively Used in other problems to reduce Time Complexity of Solution.+- CPH Range
+ Queries (before Binary Indexed Tree)
+ - USACOBOOK
+ ch11 Prefix Sums
+ - Solved Examples Leetcode two solved illustrations; more
+ problems to solve.
+ - Maximum Sum Subsection
+
++- Problems :
+
+
+ -
+
+
++- CSES : Maximum Subarray Sum :
+
+
+
+
+Hint
+search for Kadane’s Algorithm
++- 2 D Prefix Sum
+
+
+
+Additional + Practice
+ +➡️Divide and + Conquer
+ +Read this to know what divide and conquer is. Watch this video to get more insight into this topic
+ +➡️Intro to Greedy + Algorithms
+ +
+Moving in the direction which gives the most optimal solution at every step is a major characteristic of these algorithms.++- Read Greedy Algorithms - CPH and Job Scheduling to get a better idea of these algorithms .
+ Greedy | LeetCode The Hard Way
+ - Alternatively, you may go through this video.
+
+Here are some questions :
+ + +SELF + ASSESSMENT :
+ +➡️Dynamic + Programming
+Basic Concepts + :
+
+Dynamic Programming , more famously known as DP is a technique in which we calculate and store subproblems in a particular problem.+There are two methods to apply dp in your code : recursion and iteration .
+ ++- This video explains the difference between the
+ two implementations for fibonacci numbers, then try this problem
+ :
+
+
+ - Read Chapter - 7 CPH
+ - Classic Solved Illustrations
+
++- After completing above resources for DP , you can now do the following standard problems :
+
+
+
+DP on Grids + :
+This tutorial + has some generic problems which will develop your understanding about grids . +
+ +DP Bitmask + :
+ ++- Read this blog ( it is based on the CP book of Felix & Halim ) to
+ begin with bitmasking . Follow this tutorial for further understanding .
+
+ - More resources - Advanced DP concepts (you may follow up to 45:00 )
+ - Some Problems :
+
+
+
+
+DP is a topic which can be mastered only through practice.+- Some resources for practice :
+
+
++- AtCoder DP Contest
+
+ - CF Problemset
+ (Use tag=dp in filters )
+ - CSES Problem
+ Set (DP section)
+
+SELF-ASSESSMENT ( + Topic : DP )
+ ++-
+
+
+Some Question on Dp + Probability and expected values :
+ +➡️Interactive + Problems
+ +Here + is a tutorial on how to solve interactive problems .
+Here are some questions + :
+ +Some more tools to help you in your journey :
++- Diffchecker - some problems have large output
+ files. Use this tool to compare your generated output and problem's expected output.
+
+CodeForces Chrome Extensions :
++- CF Analytics - improves the
+ Codeforces profile webpage to include statistics of problems solved by the user.
+ - CodeForces Enhancer - multiple
+ ratings graph, adds "Hide/Show solved problems" link to Problemset page
+ - Carrot - predicts actual
+ performance in the contest, how many rating points you will gain after the contest, etc.
+
+ - Conding Dude - Contest
+ Reminder
+
+➡️Section 1 Additional + Practice:
+ +Section 2: + Intermediate
+ +➡️Advanced Maths +
+ + Combinatorics
+ Combinatorics
+ ++- Read the following topics : Binomial Coefficients , Catalan Numbers
+
+ - Refer CPH Ch 22 for further reading
+ - Some questions :
+
+
+ - Some additional Problems:
+
+
+
+ + Matrices
+ Matrices
+ ++- For learning about the implementation of basic operations on matrices read CPH
+ Ch23.
+
+ - Read this Blog | CodeForces or Matrix Exponentiation | Code Accepted , it
+ would help to solve recurrence based questions using matrices .
+ - Matrix
+ Exponentiation tutorial + training contest | CodeForces
+
+
++- A few ad hoc problems based on matrices-
+
+
+
++- Some problems on Matrix Exponentiation:
+
+
+
+ + Probability
+ Probability
+ ++- Read CPH Ch 24
+ - Read blog/video
+ - Problems -
+
+
+
+ + Extra Number Theory
+ Extra Number Theory
+ ++- CPH Ch
+ 21
+ - Solving system of congruences | AlgorithmClear Blog
+ - Some more problems :
+
+
+
+➡️Range Update + Queries
+ ++- CPH Range
+ Queries (may skip Fenwick Tree, as Segment Tree is able to do anything one can
+ do with Fenwick Tree)
+ - Segment Trees
+
+ - Fenwick Trees (optional ; may read just for knowledge)
+
+
++- CS
+ Academy Tutorial OR
+ - CP Algorithms Tutorial (only read Simplest form of a
+ Segment Tree for now)
+
++- CS
+ Academy Tutorial OR
+ - CP Algorithms Tutorial
+
++- Let’s get started with practice :
+
+ - ITMO step
+ 3 go through theory , problems , solutions in order; then solve :
+
++- ITMO step 1 theory read the article below / watch
+ videos 1,3 for the same content
+
+ +➡️Graph Theory + Basics
+ ++- Here is a brief intro to graphs and its representation.
+ - You may also refer Representation of Graphs | Code Accepted, then solve this
+ problem :
+
++- Spoj - ROADNET
+
++- Here’s a video if you prefer those : Introduction to Graph Theory: A Computer Science
+ Perspective
+
+ BFS
+ and DFS
BFS
+ and DFS
+ ++- There are two basic (and extremely useful) algorithms for graph traversal : BFS and DFS.
+
+ - To understand them, read page number 117 to 122 from this handbook.
+ - Or we recommend watching these videos :
+
+ - Here are some problems :
+
+
+
++- Depth
+ First Search (DFS) Explained: Algorithm, Examples, and Code
+ - Breadth First Search (BFS): Visualized and Explained
+ (Also has the flood fill problem!)
+
+ + Cycles Detection
+ Cycles Detection
+ ++- This and This article will help you understand how to
+ find cycles.
+ - Problems :
+
+
+ - Other problems for bidirectional graphs :
+
+
+
+ + Bridges in Graphs
+ Bridges in Graphs
+ ++- [Tutorial] DFS
+ TREE | CodeForces
+ - Problems :
+
+
+
+ + Flood Fill
+ Flood Fill
+ ++- To understand flood fill, you can go through this article. It was also covered in the video above.
+
+ - Problems:
+
+
+
+ + Topological Sort
+ Topological Sort
+
+Sorting nodes of a directed graph in an order in which they can appear in a path.Note : we can only find topological sorting for an acyclic directed graph.
+ ++- You can read this or watch this to understand topological sort.
+ - CPH 16.1
+
+ - There is also Kahn's Algorithm
+ - Here are some problems:
+
+
+
+Number of topological sortings for a directed tree is discussed in Section 3 Tree Algorithms : + + DP on Trees
+ DP on Trees
+ + Subtree/DFS Problems
+ Subtree/DFS Problems
++- try these problems
+
+
+
+➡️DSU + MST
+Disjoint Set Union +
+ ++- DSU is a data structure that allows us to combine two sets, find out which set a particular
+ element belongs to and allows us to create a set from a new element.
+ - This video lecture will help you understand it well!
+
+
+
+Minimum Spanning + Trees
+ ++- PAPS Section
+ 12.4
+ - How Do You
+ Calculate a Minimum Spanning Tree?
+ - CPH
+ OR
+ - Read these articles : Kruskal , Kruskal DSU , Prim's
+ Algo OR
+ - Go through these videos : Kruskal using DSU , Prim's
+ Algo
+
++- Practice :
+
+
+
+➡️Shortest Path + Algorithms - Dijkstra, Floyd Warshall, Bellman Ford
+ ++- You can go through Ch - 13 of this book for better understanding or if video
+ lectures are more up your alley, you can watch these : Dijkstra, Bellman
+ Ford, Floyd Warshall.
+ - Problems :
+
+
+
+➡️Section 2 Additional + Practice:
+ +Optional :
++- Bacterial
+ Sampling - Find the Z matrix of the recursion - Time complexity O(log(n)) with
+ a constant of 20*20
+
+Section 3: + Advanced
+ +➡️String Hashing +
+ ++- Read ch
+ 26 to get an overview of string algorithms like hashing, z-algorithm and trie
+ structure.
+ - Refer to this video for a detailed explanation. It also explains
+ algorithms like Knuth-Morris-Pratt (KMP) algorithm.
+ - This article covers Aho-Corasick algorithm
+ - Problems :
+
+
+
+➡️Directed Graphs +
+ ++- A directed graph is a graph where the edges have a direction.
+ - Theory on Directed Graphs : CPH Ch 16
+
+ + + Cycles in Directed graphs
+ Cycles in Directed graphs
+Functional Graphs +
++- Graphs where each node has exactly one outgoing edge (outdegree = 1)
+
+
+ - Cycle Finding :
+
+
+
+ - Solve the following problems involving cycles: (a graph with vertices = n and edges >= n will
+ have atleast one cycle)
+
+
+
++- We can use Floyd's Cycle Finding Algorithm +
+ Visualization also known as Tortoise and Hare
+ Algorithm
+ - We can also use Kahn's algorithm
+
+In Kahn's Algorithm : If all nodes in the graph are not removed as zero degree -> it + implies that there must be cycles.
+ + Strongly Connected Components :
+ Strongly Connected Components :
+A part of graph (component) is said to be strongly connected if there is a path from any node to all + other + nodes in the component. +
+In Function Graphs : Every cycle alone is a SCC;
+Generally : if two cycles share a vertex they both come under the same SCC.
++- Start with CPH Ch 17 ; Learn any of these algorithms to solve
+ problems
+
+ - Try these problems :
+
+
+
++- Kosaraju's Algorithm
+
+ - Tarjan's Algorithm
+
+
++- Techdose - Youtube
+ - CP Algos Article
+
++- William Fiset - Youtube
+ - Tutorial | CodeForces
+
+If you make disjoint sets of vertices within a SCC and join edges connecting SCCs; you get a + Condensation Graph. This graph does not contain cycles as in + that case they would form another SCC. Thus it's a Directed Acyclic Graph.
++- Problems involving more ideas like condensation , topological sort :
+
+
+
+ + 2-SAT
+ 2-SAT
++- Go through one of these
+
+ - Attempt these problems
+
+
+
++- CPH
+ 17.2
+ - Blog |
+ CodeForces
+ - CP
+ Algorithms Article
+ - Algorithms Live! | Youtube
+
+ DP
+ on DAGs
DP
+ on DAGs
+DAGs stands for Directed Acyclic Graphs, Trees are a particular kind of DAG.
++- Try this simple problem to start with :
+
++- AtCoder - Longest Path
+
++- Then read CPH 16.2 and DP on Trees and Graphs | CSE 421
+ - If you prefer to watch some videos :
+
+ - Problems :
+
+
+ - DP on Trees
+
++- MultiStage Graph | Abdul Bari - Youtube
+ - Shortest/Longest path on a DAG - WilliamFiset | Youtube
+
+➡️Range Update Queries + (continued)…
+ +This topic is continued from the previous section.
++- Try this problem : CF - Xenia and Bit Operations
+ - More Complex Queries ( Continued from earlier
+ CP - Algos article)
+ - ITMO Step
+ 2 - Go through theory, problems, solutions in order then solve :
+
+
+
+ + Additional (optional) :
+ Additional (optional) :
++- ITMO step 4 (no video solutions)
+
+
+ - Range Update Seg Tree , ITMO step
+ 5
+ - Range Queries in two Dimensions
+
+ - Number of distinct integers in O(log N) - Stack
+ Overflow
+
+
+ - Longest increasing subsequence - CPAlgorithms solution with
+ data structures
+
++- Read CP Algorithms article / TopCoder article
+
+ +➡️ Sparse Table +
+ ++- Video / Theory
+ - Problems :
+
+
+ - The same idea can be applied for 2D Range minimum queries as well. Here is a blog that explains it.
+
+➡️Tree Algorithm + Problems
+ ++- CPH Ch
+ 14 / Tree Algorithms - YouTube / AlgorithmsThread 8: Tree Basics
+
+ Tree
+ Diameter
Tree
+ Diameter
++- You can go through this Article / this Blog
+ (CodeForces)
+
+
+
+ DP
+ on Trees
DP
+ on Trees
+(this section builds on from DP on DAGs)
++- Here’s a blog on DP on Trees
+ - Here are some specific problems on Trees :
+
+
+ - Number of Topological Sorting :
+
+
+
+ Tree
+ Queries
Tree
+ Queries
++- CPH 18.1 Finding
+ Ancestors + Binary Lifting - CPAlgorithms
+
+
+ - CPH 18.2 Subtree and
+ Path Queries / Euler Tour
+
+
+ - CPH 18.3 Lowest
+ common ancestor + Lowest Common Ancestor - CP Algorithms +
+ WilliamFiset | Youtube
+
+
+ - More Problems:
+
+
+
+➡️Section 3 Additional + Practice:
+ +Additional Topics +
+Convex Hull Trick, Square Root Decomposition, DP Optimizations (Knuth, Aliens, Divide and Conquer, + CHT), LiChao Tree, Mo’s Algorithm, Digit DP, Broken Profile DP, Connected Components DP, DP on Trees, + Sparse Segment Trees, Persistent Data Structures, Slope Trick, FFT, Suffix Array, Tries, Heavy Light + Decomposition, Centroid Decomposition
+NOTE : For the topics we covered above there still exist a lot of variations which might be missed out + by us or were not possible in the scope of this Roadmap.
+Continue your jouney in CP with self exploration !
+➡️ Some More Resources -
+✧ Books -
++- Competitive Programmer's
+ HandBook / CPH
+ - AN INTRODUCTION
+ TO THE USA COMPUTING OLYMPIAD
+ - Principles of Algorithmic Problem Solving
+ - Competitive Programming 2
+ - Guide to Competitive Programming | Springer
+
+✧ Problem Sets and Resources -
++- ITMO Academy:
+ pilot course - Codeforces (Recommended)
+ - USACO
+ Guide (Recommended)
+ - The Ultimate
+ Topic List
+ - CSES Problem Set
+
+ - A2OJ Ladders
+ - AtCoder
+ Problems
+ - Problems | Toph
+ - CP-Algorithms
+ - KACTL CP Templates C++
+ - T-414-ÁFLV: A
+ Competitive Programming Course
+ - Archived Problems -
+ Project Euler (if you’re into math ; improves problem solving)
+ - Number Theory
+ Articles | Brilliant
+
+✧ Blogs -
++- An awesome list
+ for competitive programming! - Codeforces
+ - Prepare — NOI.PH - Philippine
+ Programming Contest
+ - All the good
+ tutorials found for Competitive Programming - Codeforces
+ - 75 LeetCode Questions to save your time
+
+✧ YouTube Channels and Playlists -
++- Pavel Mavrin : A&DS English Course - YouTube
+ - Gaurav Sen : Competitive Programming A-Z - YouTube
+ - Errichto
+ Algorithms
+ - Colin
+ Galen
+ - AlgorithmsThread - YouTube
+ - WilliamFiset - YouTube
+ - William
+ Lin
+
++
This roadmap could never be possible without the inspiration and background support of the + Makers of the Previous Roadmap :
++- Sanat Goel
+ - Vipul Chanchlani
+ - Goutam Das
+ - Rishi Agarwal
+ - Varun Tokas
+ - Shivam Mishra
+ - Chayan Kumawat
+ - Prerak Agarwal
+ - Sankul
+
+Contributors -
++ Tattwa Shiwani | tattwash23@iitk.ac.in
+ Khushi Ranawat | rkhushi23@iitk.ac.in
+ Arnav Gupta | arnavgupta23@iitk.ac.in
+ Yatharth Dangi | yatharth23@iitk.ac.in
+ Rohit Somani | rohitvs23@iitk.ac.in +