pip install 'ms-swift[llm]' -U
pip install attrdictModel Link:
- deepseek-vl-1_3b-chat: https://www.modelscope.cn/models/deepseek-ai/deepseek-vl-1.3b-chat/summary
- deepseek-vl-7b-chat: https://www.modelscope.cn/models/deepseek-ai/deepseek-vl-7b-chat/summary
Inference for deepseek-vl-7b-chat:
# Experimental environment: A100
# 30GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift infer --model_type deepseek-vl-7b-chat
# If you want to run it on 3090, you can infer the 1.3b model
CUDA_VISIBLE_DEVICES=0 swift infer --model_type deepseek-vl-1_3b-chat7b model effect demonstration: (supports passing local paths or URLs)
"""
<<< Who are you?
I am an AI language model, designed to understand and generate human-like text based on the input I receive. I am not a human, but I am here to help answer your questions and assist you with any tasks you may have.
--------------------------------------------------
<<< <img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png</img><img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/cat.png</img>What is the difference between these two images?
The image provided is a close-up of a kitten with big blue eyes, looking directly at the camera. The kitten appears to be a domestic cat, specifically a kitten, given its small size and youthful features. The image is a high-resolution, detailed photograph that captures the kitten's facial features and fur texture.
The second image is a cartoon illustration of three sheep standing in a grassy field with mountains in the background. The sheep are white with brown faces and legs, and they have large, round eyes. The illustration is stylized with a flat, two-dimensional appearance, and the colors are bright and vibrant. The sheep are evenly spaced and facing forward, giving the impression of a peaceful, pastoral scene.
The differences between the two images are primarily in their artistic styles and subjects. The first image is a realistic photograph of a kitten, while the second image is a stylized cartoon illustration of sheep. The first image is a photograph with a focus on the kitten's facial features and fur texture, while the second image is a cartoon with a focus on the sheep's characters and the setting. The first image is a single subject, while the second image features multiple subjects in a group.
--------------------------------------------------
<<< <img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png</img>How many sheep are there in the picture?
There are four sheep in the picture.
--------------------------------------------------
<<< <img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/math.png</img>What is the result of the calculation?
The result of the calculation is 1452 + 45304 = 46756.
--------------------------------------------------
<<< <img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/poem.png</img>Write a poem based on the content of the In the tranquil waters, a boat gently floats,
A beacon of light, a lone candle's soft glow.
The night is vast, a canvas of stars above,
A serene scene, a moment of peace, it seems to offer.
The boat, a vessel of wood and a mast so tall,
Carries a passenger, a figure so still.
The water's surface, a mirror of the night sky,
Reflects the boat's silhouette, a sight so divine.
The trees, standing tall, their forms in the distance,
A forest of mystery, a silent chorus.
The stars, scattered like diamonds in the heavens,
Illuminate the night, a celestial dance.
The boat, a symbol of journey and adventure,
In the quiet of the night, it's a sight to behold.
A moment frozen in time, a memory to cherish,
In the picture of the night, a boat on the water.
"""Sample images are as follows:
cat:

animal:

math:
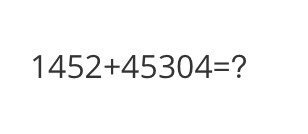
poem:

Single sample inference
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType,
get_default_template_type, inference_stream
)
from swift.utils import seed_everything
import torch
model_type = ModelType.deepseek_vl_7b_chat
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}')
model, tokenizer = get_model_tokenizer(model_type, torch.float16,
model_kwargs={'device_map': 'auto'})
model.generation_config.max_new_tokens = 256
template = get_template(template_type, tokenizer)
seed_everything(42)
query = '<img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png</img>How far is it from each city?'
response, history = inference(model, template, query)
print(f'query: {query}')
print(f'response: {response}')
# Streaming
query = 'Which city is the farthest?'
gen = inference_stream(model, template, query, history)
print_idx = 0
print(f'query: {query}\nresponse: ', end='')
for response, history in gen:
delta = response[print_idx:]
print(delta, end='', flush=True)
print_idx = len(response)
print()
print(f'history: {history}')
"""
query: <img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png</img>How far is it from each city?
response: The distance from each city is as follows:
- From "Mata", it is 14 km away.
- From "Yangjiang", it is 62 km away.
- From "Guangzhou", it is 293 km away.
These distances are clearly indicated on the green road sign with white text, providing the necessary information for travelers to gauge the distance to each city from the current location.
query: Which city is the farthest?
response: The farthest city from the current location is "Guangzhou", which is 293 km away. This is indicated by the longest number on the green road sign, which is larger than the distances to the other cities listed.
history: [['<img>http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png</img>How far is it from each city?', 'The distance from each city is as follows:\n\n- From "Mata", it is 14 km away.\n- From "Yangjiang", it is 62 km away.\n- From "Guangzhou", it is 293 km away.\n\nThese distances are clearly indicated on the green road sign with white text, providing the necessary information for travelers to gauge the distance to each city from the current location.'], ['Which city is the farthest?', 'The farthest city from the current location is "Guangzhou", which is 293 km away. This is indicated by the longest number on the green road sign, which is larger than the distances to the other cities listed.']]
"""Sample image is as follows:
road:

Multi-modal large model fine-tuning usually uses custom datasets. Here is a runnable demo:
LoRA fine-tuning:
# Experimental environment: A10, 3090, V100
# 20GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type deepseek-vl-7b-chat \
--dataset coco-en-mini \Full parameter fine-tuning:
# Experimental environment: 4 * A100
# 4 * 70GB GPU memory
NPROC_PER_NODE=4 CUDA_VISIBLE_DEVICES=0,1,2,3 swift sft \
--model_type deepseek-vl-7b-chat \
--dataset coco-en-mini \
--sft_type full \
--use_flash_attn true \
--deepspeed default-zero2Custom datasets supports json, jsonl styles. The following is an example of a custom dataset:
(Supports multi-turn conversations, supports multiple images per turn or no images, supports input of local paths or URLs)
[
{"conversations": [
{"from": "user", "value": "<img>img_path</img>11111"},
{"from": "assistant", "value": "22222"}
]},
{"conversations": [
{"from": "user", "value": "<img>img_path</img><img>img_path2</img><img>img_path3</img>aaaaa"},
{"from": "assistant", "value": "bbbbb"},
{"from": "user", "value": "<img>img_path</img>ccccc"},
{"from": "assistant", "value": "ddddd"}
]},
{"conversations": [
{"from": "user", "value": "AAAAA"},
{"from": "assistant", "value": "BBBBB"},
{"from": "user", "value": "CCCCC"},
{"from": "assistant", "value": "DDDDD"}
]}
]Direct inference:
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/deepseek-vl-7b-chat/vx-xxx/checkpoint-xxx \
--load_dataset_config true \merge-lora and inference:
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/deepseek-vl-7b-chat/vx-xxx/checkpoint-xxx \
--merge_lora true
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/deepseek-vl-7b-chat/vx-xxx/checkpoint-xxx-merged \
--load_dataset_config true