| title | tags | authors | affiliations | date | bibliography | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Human-Learn: Human Benchmarks in a Scikit-Learn Compatible API |
|
|
|
May 3rd 2020 |
paper.bib |
This package contains scikit-learn compatible tools that make it easier to construct and benchmark rule-based systems designed by humans. There are tools to turn Python functions into scikit-learn compatible components and interactive jupyter widgets that allow the user to draw models. One can also use it to design rules on top of existing models that, for example, can trigger a classifier fallback when outliers are detected.
There has been a transition from rule-based systems to ones that use machine learning. Initially, systems converted data to labels by applying rules, like in \autoref{fig:rulebased}.

Recently, it has become much more fashionable to take data with labels and to use machine-learning algorithms to figure out appropriate rules, like in \autoref{fig:mlbased}.

We started wondering if we might have lost something in this transition. Machine learning is a general technique, but it's proven to be very hard te debug. This is especially painful when wrong predictions are made. Tools like SHAP [@NIPS2017_7062] and LIME [@lime] try to explain why algorithms make certain decisions in hindsight, but even with the benefit of hindsight, it is tough to understand what is happening.
At the same time, it is also true that many classification problems can be done by natural intelligence. This package aims to make it easier to turn the act of exploratory data analysis into a well-understood model. These "human" models are very explainable from the start. If nothing else, they can serve as a simple benchmark representing domain knowledge which is a great starting point for any predictive project.
Human-learn can be installed via pip.
pip install human-learn
The library features components to easily turn Python functions into scikit-learn compatible components [@sklearn_api].
import numpy as np
from hulearn.classification import FunctionClassifier
def fare_based(dataf, threshold=10):
"""
The assumption is that folks who paid more are wealthier and are more
likely to have recieved access to lifeboats.
"""
return np.array(dataf['fare'] > threshold).astype(int)
# The function is now turned into a scikit-learn compatible classifier.
mod = FunctionClassifier(fare_based)Besides the FunctionClassifier, the library also features a FunctionRegressor and a FunctionOutlierDetector. These can all take a function and turn the keyword parameters into grid-searchable parameters.
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import (
precision_score,
recall_score,
accuracy_score,
make_scorer
)
# The GridSearch object can now "grid-search" over this model.
grid = GridSearchCV(mod,
cv=2,
param_grid={'threshold': np.linspace(0, 100, 30)},
scoring={'accuracy': make_scorer(accuracy_score),
'precision': make_scorer(precision_score),
'recall': make_scorer(recall_score)},
refit='accuracy')
grid.fit(X, y)The example below shows a FunctionClassifier that predicts all women
and children from the upper class survive, based on the "woman and children first"-quote
from the Titanic movie.
def make_prediction(dataf, age=15):
women_rule = (dataf['pclass'] < 3.0) & (dataf['sex'] == "female")
children_rule = (dataf['pclass'] < 3.0) & (dataf['age'] <= age)
return women_rule | children_rule
mod = FunctionClassifier(make_prediction)We've compared the performance of this model with a RandomForestClassifier.
The validation-set results are shown in the table below.
| Model | accuracy | precision | recall |
|---|---|---|---|
| Women & Children Rule | 0.808157 | 0.952168 | 0.558621 |
| RandomForestClassifier | 0.813869 | 0.785059 | 0.751724 |
The simple rule-based model seems to offer a relevant trade-off, even if it's only used as an initial benchmark.
These function-based models can be very powerful because they allow the user the define rules for situations for which there is no data available. In the case of financial fraud, if a child has above median income, this should trigger risk. Machine learning models cannot learn if there is no data but rules can be defined even if, in this case, a child with above median income doesn't appear in the training data. An ideal use-case for this library is to combine rule based systems with machine learning based systems. An example of this is shown in \autoref{fig:tree}.
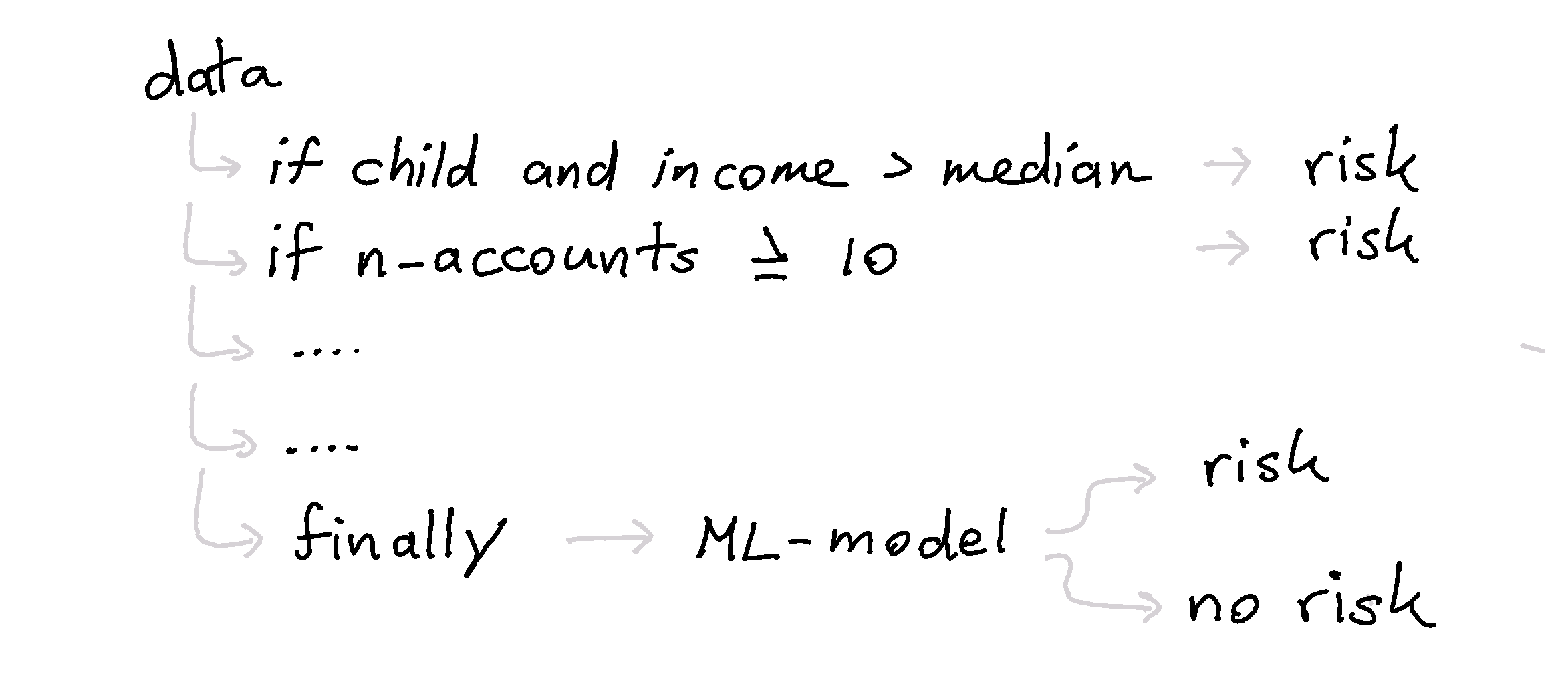
This example also demonstrates the main difference between this library and Snorkel [@snorkel]. This library offers methods to turn domain knowledge immediately into models, as opposed to labelling-functions.
Human-learn also hosts interactive widgets, made with Bokeh, that might help construct rule-based models more expressively. These widgets can be used from the familiar Jupyter environment. An example of such a drawn widget is shown below in \autoref{fig:draw}.
from hulearn.experimental.interactive import InteractiveCharts
df = load_penguins()
clf = InteractiveCharts(df, labels="species")
# It is best to add charts in their own seperate notebook cells
clf.add_chart(x="bill_length_mm", y="bill_depth_mm")This interface allows the user to draw machine learning models. They can be used for classification, outlier detection, labeling tasks, or general data exploration. The snippet below demonstrates how to define a classifier based on the drawings.
from hulearn.classification import InteractiveClassifier
# This classifier uses a point-in-poly method to convert the drawn
# data from `clf` into a scikit-learn classifier.
model = InteractiveClassifier(json_desc=clf.data())
This project was developed in my spare time while being employed at Rasa. They have been very supportive of me working on my own projects on the side, and I would like to recognize them for being a great employer.
I also want to acknowledge that I'm building on the shoulders of giants. The popular drawing widget in this library would not have been possible without the wider Bokeh [@bokeh], Jupyter [@jupyter] and scikit-learn [@sklearn] communities.
There have also been small contributions on Github from Joshua Adelman, Kay Hoogland, and Gabriel Luiz Freitas Almeida.