[Day28] FastAPI : Primary Replica 架構實作(2)
本次的程式碼與目錄結構可以參考 FastAPI Tutorial : Day28 branch
我們在 昨天 完成 PostgreSQL 中的 primary-replica 設定
在今天我們會完成在 FastAPI 中的 primary-replica 設定
讓我能夠在處理 讀取操作 時,能夠將 request 平均分配到 primary 與 replica 中
再回顧一下架構圖:
Write Read
| |
| ├──------------┐
| | |
v v v
+------------+ +------------+
| Primary | | Replica |
| Database | | Database |
+------------+ +------------+
| ^
| |
└──-- sync data ---┘
這邊我們根據昨天設定完的 primary-replica 環境
再加上 FastAPI 和 Redis
所以 FastAPI service 會 depends on Redis, Primary, Replica 這三個 service
還需要注意需要為 service 分被固定的 IP
完整的 docker-compose.yml 放在 Day28/docker-compose-primary-replica.yml
同樣是更改 run.py 和 setting/config.py
讓我們能夠直接透過 command line arguments 來載入 primary-replica 的設定
run.py
# ...
primary_replica = parser.add_argument_group(title="Primary Replica", description="Run the server in Primary Replica architecture.")
primary_replica.add_argument("--primary_replica",action="store_true", help="Run the server in Primary Replica architecture.")
# ...
if args.prod:
load_dotenv("setting/.env.prod")
elif args.test:
load_dotenv("setting/.env.test")
elif args.primary_replica:
load_dotenv("setting/.env.primary-replica") # 載入 primary-replica 的設定
else:
load_dotenv("setting/.env.dev")
# ...setting/config.py
# ...
class PrimaryReplicaSetting():
primary_database_url: str = os.getenv("ASYNC_PRIMARY_DATABASE_URL")
replica_database_url: str = os.getenv("ASYNC_REPLICA_DATABASE_URL")
redis_url:str = os.getenv("REDIS_URL")
access_token_secret:str = os.getenv("ACCESS_TOKEN_SECRET")
access_token_expire_minutes:int = int(os.getenv("ACCESS_TOKEN_EXPIRE_MINUTES"))
refresh_token_secret:str = os.getenv("REFRESH_TOKEN_SECRET")
refresh_token_expire_minutes:int = int(os.getenv("REFRESH_TOKEN_EXPIRE_MINUTES"))
# ...
@lru_cache()
def get_primary_replica_settings():
print("APP_MODE",os.getenv("APP_MODE"))
load_dotenv( f".env.{os.getenv('APP_MODE')}")
print("ASYNC_PRIMARY_DATABASE_URL",os.getenv("ASYNC_PRIMARY_DATABASE_URL"))
return PrimaryReplicaSetting()這次 config.py 改以新的 Class PrimaryReplicaSetting 來儲存 primary-replica 的設定
原本我們在 FastAPI 中的 DB Session 注入是這樣寫的:
- 先建立 engine
- 再建立 database session
# Create engine
engine = create_async_engine(
settings.database_url,
echo=True,
pool_pre_ping=True
)
# Create session
SessionLocal = async_sessionmaker(engine, expire_on_commit=False, autocommit=False)但是在 primary-replica 的環境中
我們要分別建立 primary 與 replica 的 engine 與 session
database/primer_replica.py
from sqlalchemy.ext.asyncio import create_async_engine , async_sessionmaker
from setting.config import get_primary_replica_settings
settings = get_primary_replica_settings()
primary_engine = create_async_engine(
settings.primary_database_url,
echo=True,
pool_pre_ping=True,
pool_size=8, max_overflow=0,
)
replica_engine = create_async_engine(
settings.replica_database_url,
echo=True,
pool_pre_ping=True,
pool_size=8, max_overflow=0
)
primarySession = async_sessionmaker(primary_engine, expire_on_commit=False, autocommit=False)
replicaSession = async_sessionmaker(replica_engine, expire_on_commit=False, autocommit=False)由開頭提到的 primary-replica 架構圖可以看到
我們在處理 讀取操作 時,會將 request 平均分配到 primary 與 replica 中
所以我們要建立兩個 function get_write_session 和 get_read_session
get_write_session只會回傳 primary 的 sessionget_read_session會回傳 primary 或是 replica 的 session ( 會平均的分配到 primary 或是 replica )
而我們使用 random.choice 來隨機選擇 primary 或是 replica 的 session
database/primer_replica.py
primarySession = async_sessionmaker(primary_engine, expire_on_commit=False, autocommit=False)
replicaSession = async_sessionmaker(replica_engine, expire_on_commit=False, autocommit=False)
readSessions = [primarySession,replicaSession]
@asynccontextmanager
async def get_write_db():
async with primarySession() as db:
async with db.begin():
yield db
@asynccontextmanager
async def get_read_db():
session = random.choice(readSessions)
async with session() as db:
async with db.begin():
yield db這邊我們一樣透過 decorator 來取得被包住的 CRUD 是否為 get_xxx
來判斷是否要注入 get_read_db 或是 get_write_db
而透過 decorator 來注入 session 的方式
可以參考 [Day16: 架構優化:非同步存取 DB (2)]
database/primer_replica.py
# ...
def db_session_decorator(func):
async def wrapper(*args, **kwargs):
if 'get' in func.__name__:
async with get_read_db() as db_session:
kwargs["db_session"] = db_session
result = await func(*args, **kwargs)
return result
async with get_write_db() as db_session:
kwargs["db_session"] = db_session
result = await func(*args, **kwargs)
return result
return wrapper
# ...由於原本的 pytest 都是 sync 的
又因為 Database 中 Read 的操作比 Write 的操作快
所以這邊以 parallel 的方式來打 API
這邊的 benckmark 不考慮 validation
單純以 response time 當作衡量標準
所以沒有用之前的 pytest 來測試
因為 pytest 會有 variable scope 的問題
如果使用pytest-xdist來做 parallel test
會導致UnboundLocalError
最後是使用 grequests 來快速撰寫 parallel test
test/test_parallel.py
# ... generate random test cases
url_list = get_random_page_range_list_url() + get_random_user_list_url() # test cases
# calculate the time
START = time.time()
rs = [ grequests.get(u) for u in url_list ]
responses = grequests.map(rs)
END = time.time()
print("\n")
GREEN_COL = '\033[92m'
END_COL = '\033[0m'
print(f'{GREEN_COL} Time : {END-START} {END_COL}')這邊都以 5000 個 user , 10000 個 request 來測試
其中 5000 個是 get_user_by_id 剩下 5000 個是 get_user_list
- 以原本的架構測試:
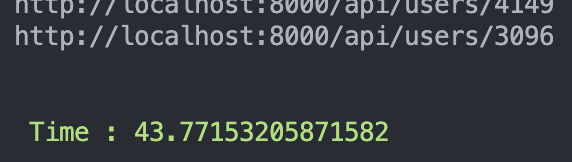
- 以primary-replica的架構測試:
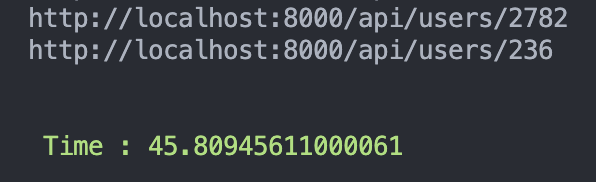
結果發現 兩個 benchmark 結果都差不多 !
經過多次更改 user 和 query 數量
benchmark 出來的結果都沒什麼差
又翻過多篇 primary replica 架構的文章
確認我們對 primary replica 架構理解沒有錯誤
也的確可以透過 primary replica 架構來提升讀取效能
所以瓶頸應該是在 後端實現 的部分
經過多種測試後
我發現是因為透過 random.choice(readSessions) 隨機分配 session 太慢了 !
其實經過 2 週的反覆改寫、測試
才發現是因為random.choice()的問題
應該是因為random.choice()本身效率的問題所造造成的
改成將一個變數 flag 一開始設為 True
當每次進入 get_read_db 時,就將變數設為 not flag
- 如果
flag為True就回傳 primary 的 session - 如果
flag為False就回傳 replica 的 session
這樣就可以達到 快速 平均分配的效果
database/primer_replica.py
# ...
flag = True
# ...
@asynccontextmanager
async def get_read_db():
flag = not flag # toggle flag
if flag:
async with primarySession() as db:
async with db.begin():
yield db
async with replicaSession() as db:
async with db.begin():
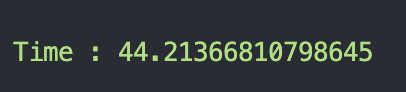
yield db同樣是以 5000 個 user , 10000 個 request 來測試
- 以原本的架構測試:
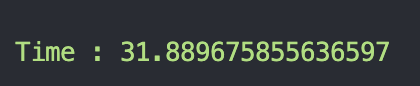
- 以primary-replica的架構測試:
再多跑幾個 primary-replica 的 benchmark
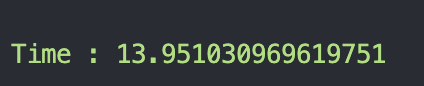

可以看到 primary-replica 的 benchmark 結果都比 原本 的好很多 !
甚至時候可以測到 primary-replica 的 benchmark 比 原本 的快 2 倍以上 !
在這次實作 primary-replica 架構時
我們遇到 隨機分配 session 的效率問題
經過 兩週 的反覆測試、改寫後
發現是 random.choice() 的效率問題
改為以 toggle flag 的 round robin 方式來平均分配 session
就達到理論上的 primary-replica 架構效果