[Day26] 架構優化: Redis Pagenation Cache 實作
本次的程式碼與目錄結構可以參考 FastAPI Tutorial : Day26 branch
昨天 終於完成基本的 Redis Cache 了!
也看到在 get user by id 以 50000 筆 Query 時
有 Redis Cache 的效能比起單純 DB 來的快了約 1.4 倍!
 ( 原本需要約 500 秒 )
( 原本需要約 500 秒 )
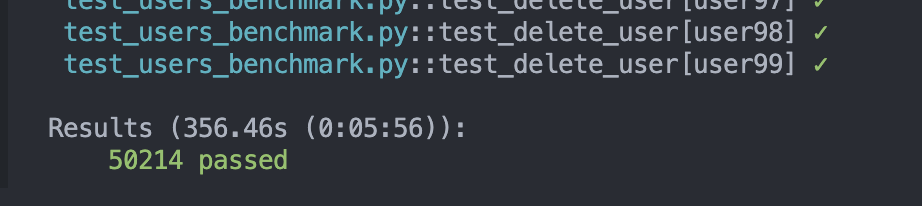 ( Redis Cache 只需要約 350 秒 )
( Redis Cache 只需要約 350 秒 )
今天會把 Pagenation 的結果也加入到 Redis Cache 中 !
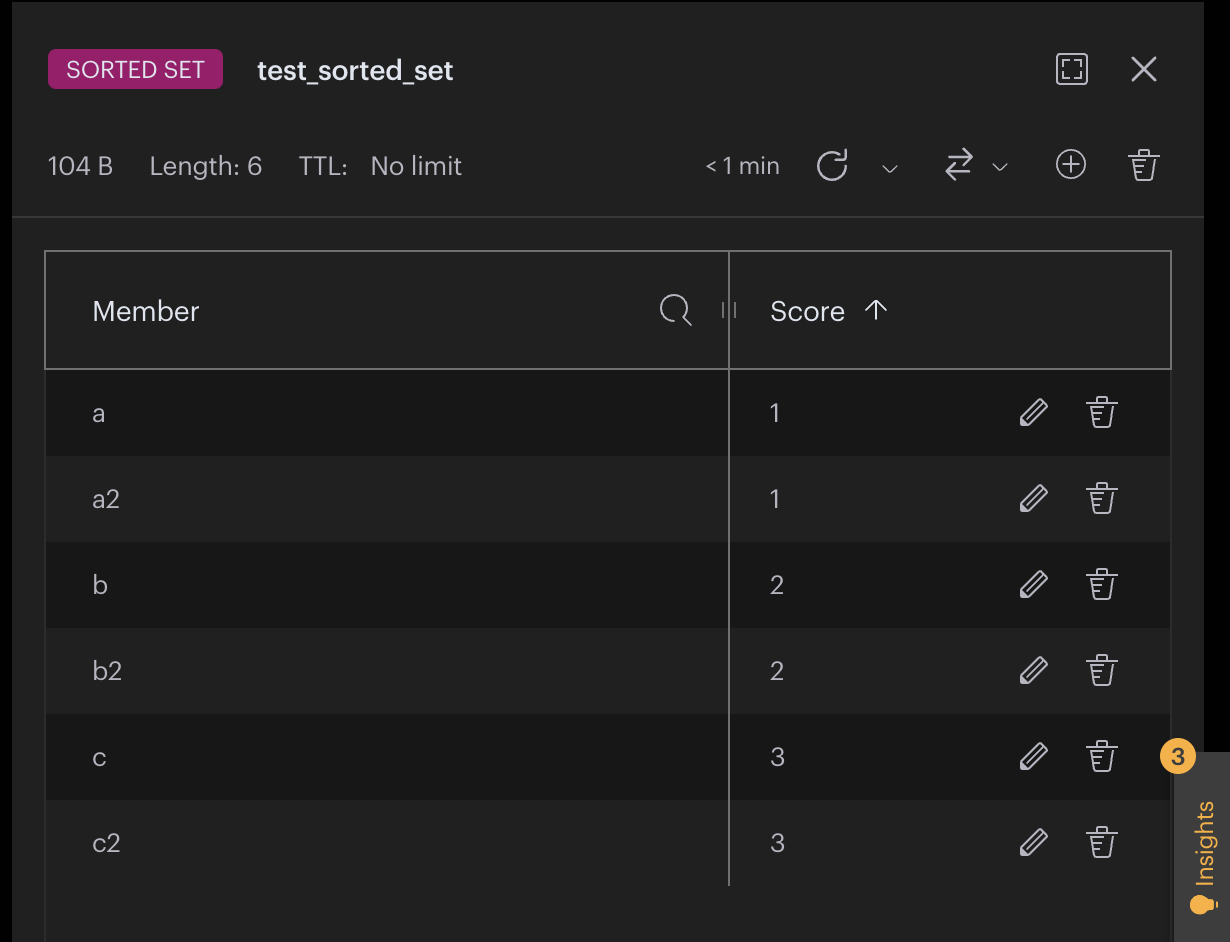
Redis 的 sorted set 功能可以理解成一個 排序的集合
可以想像成一個 Red Black Tree 或 AVL Tree 存在 Redis 中
所以所有的操作都是 O(log(n)) 的時間複雜度
可以使用的操作有:
ZADD: 新增一個元素到sorted set中ZRANGE: 取得sorted set中的元素ZREMBYRANGE: 刪除sorted set中的元素
我們知道 sorted set 中的每個元素都是一個 key-score 的 pair
key : 用來識別元素的唯一值 ( type:
str)
score : 用來排序元素的值 ( type:float)
所以我們可以把 user_id 當作 score
把 user_id 對應到的 user data stringfy 後當作 key
ZADD 還有以下參數設定:
NX: 創建新的元素,如果該元素已經存在則不做任何事XX: 只更新已經存在的元素,如果該元素不存在則不做任何事
透過 redis-py 可以使用以下方式新增元素到 sorted set 中:
redis.zadd(name='sorted_set_name', mapping={ 'key1': 1, 'key2': 2 })如果要修改已經存在的元素,可以使用以下方式:
redis.zadd(name='sorted_set_name', mapping={ 'key1': 2, 'key2': 4 }, xx=True)而設定
xx=True是依據key來改變score
所以在我們這邊要實作 Pagenation Cache 的應用中不太適用
應該需要先刪除原本的元素再新增新的元素
ZRANGE 可以取得 sorted set 中 區間的元素
可以設定 start 與 end 來取得區間的元素
能夠以:
- score 值作為區間的範圍
- index 作為區間的範圍
在
redis-py中redis.zrange回傳 type 會是list
我們 Pageation Cache 的應用中,會以 index 作為區間的範圍
如果要以 index 作為區間的範圍,需要設定
byscore=False
並且我們只需要 key 的值,所以設定withscores=False
redis_result:list = rc.zrange(name=cache_key,start=left,end=right,withscores=False,byscore=False)ZREMBYRANGE 代表 Sorted set : Remove By Range
因為我們把 user_id 作為 score
所以可以透過 ZREMBYRANGE 以 user_id 來刪除 sorted set 中的元素
rc.zremrangebyscore(name=page_key,min=value_key,max=value_key)延續昨天實作 get_user_by_id 的 Cache decorator
我們一樣提供 prefix 參數來設定 Cache 的前綴
並抓取被包裝 function 中的 last 與 limit 參數當作 sorted set 的 start 與 end
database/redis_cache.py
def generic_pagenation_cache_get(prefix:str,cls:object):
'''
pageation cache using redis sorted set
'''
rc = redis.Redis(connection_pool=redis_pool)
def inner(func):
async def wrapper(*args, **kwargs):
# dont cache when set keyword
if kwargs.get('keyword'):
return await func(*args, **kwargs)
# must pass parameter with key in caller function
left = kwargs.get('last')
limit = kwargs.get('limit')
right = left + limit
cache_key = f"{prefix}_page"
# ...
return wrapper
return inner接著一樣嘗試從 Redis 抓取 Cache
但因為 zrange 回傳的是 list[str]
所以我們還需要把回傳的 string 轉回 cls 物件
database/redis_cache.py
# ...
try:
redis_result:list = rc.zrange(name=cache_key,start=left,end=right,withscores=False,byscore=False)
if len(redis_result) > 0:
data = []
for row_str in redis_result:
row_dict = ast.literal_eval(row_str)
data.append(cls(**row_dict))
return data
except Exception as e:
pass
# ...如果沒有 Cache 的話
先等 CRUD function 回傳結果後再將結果遍歷並存入 Redis
database/redis_cache.py
# ...
sql_result = await func(*args, **kwargs)
if not sql_result:
return sql_result
for row in sql_result:
rc.zadd(name=cache_key,mapping={ str(row._asdict()) :row.id} )
return sql_result
# ...因為 update_user_by_id 與 delete_user_by_id 都會影響到 sorted set
修改 update_user_by_id 的 decorator
以 user_id 作為 score 刪除 sorted set 中的元素
這邊加上
pagenation_key參數是因為update_user_by_id會影響到sorted set
如果有設定pagenation_key的話,就會會更新pagenation_key的sorted set
database/redis_cache.py
def generic_cache_update(prefix:str,key:str,update_with_page:bool=False,pagenation_key:str=None):
# ...
if update_with_page:
try:
page_key = f"{prefix}_page"
old_redis_result:str = rc.zrange(name=page_key,start=value_key,end=value_key,withscores=False,byscore=True)[0]
# remove old value
rc.zremrangebyscore(name=page_key,min=value_key,max=value_key)
# add new value
rc.zadd(name=page_key,mapping={ str( merge_dict( merge_dict( ast.literal_eval(old_redis_result) , sql_dict ), {pagenation_key:value_key}) ) : value_key} ,nx=True )
except Exception as e:
pass
# ...修改 delete_user_by_id 的 decorator
以 user_id 作為 score 刪除 sorted set 中的元素
同樣也是以 user_id 作為 score 刪除 pagenation_key 的 sorted set 中的元素
database/redis_cache.py
def generic_cache_delete(prefix:str,key:str):
# ...
try:
page_key = f"{prefix}_page"
rc.zremrangebyscore(name=page_key,min=value_key,max=value_key)
except Exception as e:
pass
# ...我們這邊以 500 個 User 的資料
隨機取合法的 last 與 limit 來測試來模擬 Pagenation 的情況
10000筆資料:不加上 Cache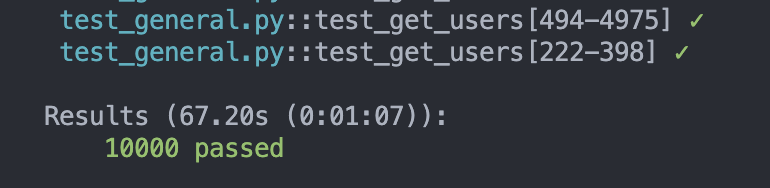
67.20 秒
10000筆資料:加上 Cache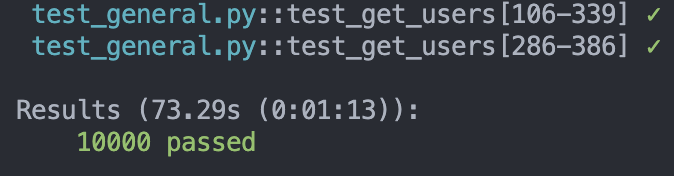
73.29 秒
50000筆資料:不加上 Cache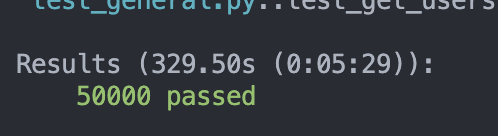
329.50 秒
50000筆資料:加上 Cache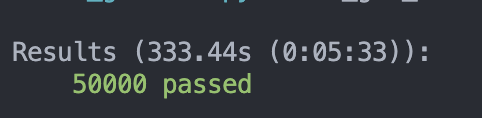
333.44 秒
結果發現以目前的方式為 Pagenation 做 Cache 並沒有比較快
甚至還比直接從 DB 取結果慢一些
我們知道透過 Redis 取結果應該會比直接從 DB 取結果快
但我們剛剛 Benchmark 的結果卻是 Cache 的方式沒有特別快
那代表將 redis cache 結果轉為 pydantic response 太慢了
再次觀察剛剛將 sorted set 的結果轉為 pydantic model 的程式碼
redis_cache.py
# ...
try:
redis_result:list = rc.zrange(name=cache_key,start=left,end=right,withscores=False,byscore=False)
if len(redis_result) > 0:
data = []
for row_str in redis_result:
row_dict = ast.literal_eval(row_str)
data.append(cls(**row_dict))
return data
except Exception as e:
pass
# ...我們是先將個別 user 的 json string 透過 ast.literal_eval 轉為 dict
再透過 cls(**row_dict) 轉為 pydantic model 再全部存入 list 中
這樣的操作會使得轉換的時間變長
隨然遍歷過程中的時間複雜度為O(n)
將json string轉為dict再加入list的常數
遠比直接將json string相加的常數還大非常多
既然我們個別的 user 都已經是 json string 了
那我們可以直接將所有的 user 的 json string 結果串接起來
最後再一次轉為 list[dict] ( 並且 list 中的 dict 有符合 pydantic model )
redis_cache.py
# ...
try:
redis_result:list = rc.zrange(name=cache_key,start=left,end=right,withscores=False,byscore=False)
str_result = ""
if len(redis_result) > 0:
for row_str in redis_result:
str_result += row_str + ","
return ast.literal_eval(f"[{str_result[:-1]}]")
except Exception as e:
print("redis error")
print(e)
pass
# ...我們同樣是以 500 個 User 的資料
隨機取合法的 last 與 limit 來測試來模擬 Pagenation 的情況
不過這次有優化將 sorted set 結果轉為符合 pydantic model 的方式
10000筆資料:不加上 Cache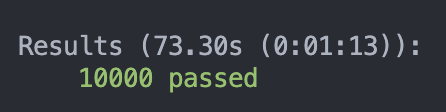
73.30 秒
10000筆資料:加上 Cache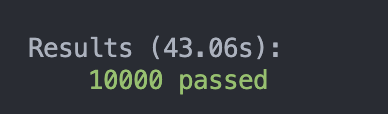
43.06
50000筆資料:不加上 Cache
329.50 秒
50000筆資料:加上 Cache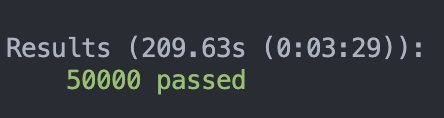
209.63 秒
可以發現這次的 Benchmark 有比較快了
大約快了約 1.5 ~ 1.7 倍 !
經過好幾天的嘗試
終於完成 Pagenation Cache 的實作
我們以 Sorted Set 來儲存 Pagenation 的結果
以 user_id 作為 score
再以 user_id 對應到的 user data stringfy 後當作 key
最後以 將所有的 user 的 json string 結果串接起來 再一次轉為 list[dict]
達到以 Redis 來 Cache Pagenation 的效果
經過 Benchmark 後發現效能比起直接從 DB 取結果快了約 1.5 倍