{kind=link}
{kind=link}
The objective of this project is to build classification models that can predict whether a costumer will default on its credit card payment in the following month
The data used refers to Taiwanese costumers' behavior in regards to its credit card payments.
Dataset contains the following features:
- Amount of the given credit (NT dollar): it includes both the individual consumer credit and his/her family (supplementary) credit
- Gender
- Education
- Marital status
- Age (year)
- History of past payment
- Amount of bill statements (NT dollar)
- Amount of previous payment (NT dollar)
The dataset to be used can be found on http://archive.ics.uci.edu/ml/datasets/default+of+credit+card+clients#
Several different models were trained and tested, such as:
- Logistic Regression
- K-Nearest Neighbors
- Naive Bayes
- Decision Tree Classifier
- Bagged Trees
- Random Forest
- XGBoost
Out of these, the best performing model was Random Forest

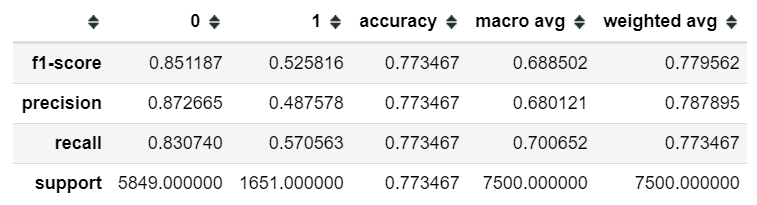
The model achieve an accuracy of 77% in predicting which costumers would default in the following month.