{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The purpose of this project is to analyze data made available by different Brazilian government institutions and see whether it is possible to predict which candidates will be investigated for irregularities in their campaign financial activities.
This task was accomplished using a XGBoost binary classification model
Pandas, Numpy, matplotlib, scipy, sklearn, xgboost, itertools, bs4, requests, selenium, re, csv, os, shutil, pickle, benfordslaw, unidecode
This project used 26k political campaign instances, of which 8.5 thousand were found to be suspicious.
In order to cross reference data from different files it is necessary to construct a table with all possible identification information about the candidates. the data can be found at:
- 2018 elections: http://agencia.tse.jus.br/estatistica/sead/odsele/consulta_cand/consulta_cand_2018.zip
- 2014 elections: http://agencia.tse.jus.br/estatistica/sead/odsele/consulta_cand/consulta_cand_2014.zip
- 2010 elections: http://agencia.tse.jus.br/estatistica/sead/odsele/consulta_cand/consulta_cand_2010.zip
Additionally, the data listed above also provides features such as the position the candidate is running for, their age, gender, party affiliation, etc
The election results from 2018 and from the two preceding elections were used.
- election results:
- 2018 elections: http://agencia.tse.jus.br/estatistica/sead/odsele/votacao_partido_munzona/votacao_partido_munzona_2018.zip
- 2014 elections: http://agencia.tse.jus.br/estatistica/sead/odsele/votacao_candidato_munzona/votacao_candidato_munzona_2014.zip
- 2010 elections: http://agencia.tse.jus.br/estatistica/sead/odsele/votacao_candidato_munzona/votacao_candidato_munzona_2010.zip
Both revenues and expenditures reported for each campaign were used.
The final figures used consisted of all cash flows added up by category (types of revenue/expenditure)
information about the assets reported for each candidate can be downloaded from:
- 2018: http://agencia.tse.jus.br/estatistica/sead/odsele/bem_candidato/bem_candidato_2018.zip
- 2014: http://agencia.tse.jus.br/estatistica/sead/odsele/bem_candidato/bem_candidato_2014.zip
- 2010: http://agencia.tse.jus.br/estatistica/sead/odsele/bem_candidato/bem_candidato_2010.zip
The data used is the court case number for the initial application for candidacies. This data is contained within the same zip file downloaded to build the campaign identifiers ( http://agencia.tse.jus.br/estatistica/sead/odsele/consulta_cand/consulta_cand_2018.zip)
The first step is to get a list of those application cases so that later on they can be excluded from a the list of court cases that deal with possible infractions
The next step is to get the dataset containing the court cases related to the 2018 elections and their subject matter
The data can be downloaded from the following link: http://agencia.tse.jus.br/estatistica/sead/odsele/processual/processos_eleitorais_assuntos_2018.zip
With the list of all court cases subjects at hand, it is necessary to manually select which one could be related to infraction in campaign financing. The selection criteria in this case is arguably subjective. However, common sense and some basic knowledge of election regulation in Brazil allows for the selection of a group of themes explicitly shown in the notebook
With the list of target themes at hand, the next step is to create a list of all court cases that match one of those themes, excluding the initial application cases
The final list will be then be used as reference for which cases need to be scraped off the internet. Scraped data will contain all selected court cases, people and entities involved, and subject matter
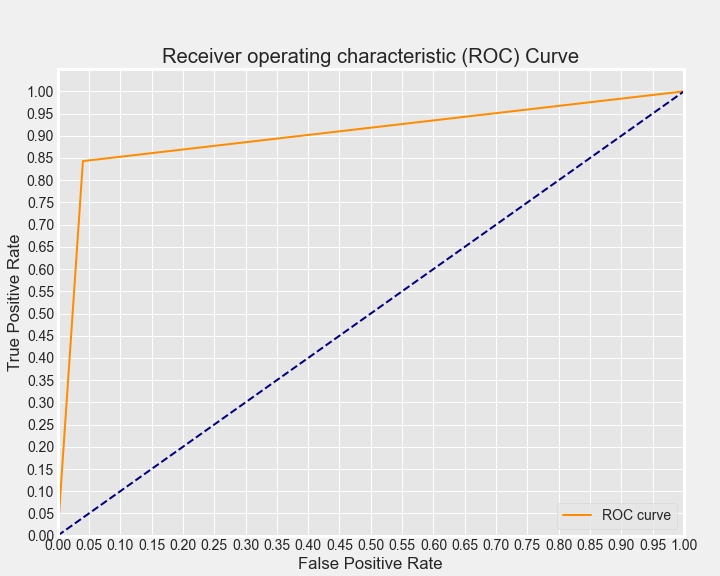
The model used was a XGBoost, on a cross validation ratio of 70%/30% Results:
- 92% overall accuracy
- 84% recall on "suspicious" class (minority)
- 91% precision on "suspicious" class
- AUC = 90.1%


- explore court cases with other subject matter. Scrape more and then analyze the description
- regroup the court cases with a NLP clustering model and use the clusters as new categories for classification models
- build unsupervised learning models that can reproduce or surpass level of results