Python编写的异步+分布式+通用mini爬虫,可以支持爬取队列、Request定制、IP代理访问和页面抓取、Response数据清洗、本地化 存储等功能。
工作流:
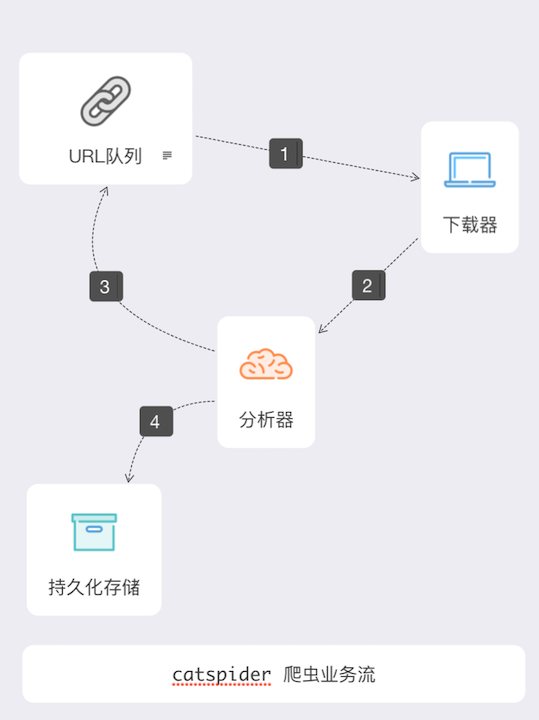
组件说明:
1、爬虫队列 queue
- 基于队列,存储待爬取分析的URL链接、先进先出
- 队列URL来源:初始URL、来自分析器的URL存入
- 基于REDIS实现队列,服务器端统一管理队列存入取出操作
2、下载器 downloader
- 从队列取出url,发起Request请求,下载url网页内容或json格式内容
- 支持Request的user-agent代理轮转
- 支持Reqeuset进行ip代理下载网页
3、分析器 xanalyzer
- 从下载器接受已经下载内容,进行数据清洗
- 使用Beautiful Soup的、re正则表达式、Json格式提取内容
- 将需要新抓取的url存入爬虫队列
- 将清洗完成的数据,传入存储组件
4、持久化存储
- 从分析器接受清洗后数据,保存到SQL/NOSQL数据库中
- 使用SQLAlchemy ORM管理SQL数据库保存
- 保存到远端数据库
MVP Version:(进度:30%)
- 完成队列保存、取出、下载、分析、保存业务流闭环。
- 使用MVP版本实现公众号内容抓取和保存(Wechatplatform)
V2: (计划中)
- 支持异步请求和处理
- Redis
- Requests
- Gevent
.
├── README.md
├── catspider.py # 执行入口
├── core
│ ├── __init__.py # 初始化文件
│ ├── setting.py # 项目设置
│ ├── xanalyzer.py # 数据清洗部分
│ ├── xdownloader.py # 下载器,制造request、设置header轮转、IP代理、异步多线程下载页面等功能
│ ├── xitem.py # 爬虫数据本地化存储
│ └── xqueue.py # 爬虫队列
└── requirements.txt # pip 库列表
使用流程:
- 定义first url,放入爬虫队列
- 在setting.py配置下载器参数
- xanalyzer.py编写数据清洗和提取规则,新url放入爬虫队列,清洗出来数据转存xitem
- xitem.py存储数据
执行工作流:
- python catspider.py start 等可以附带参数
- 爬虫从队列头部取出
- 囤好币(币种的行情、背景信息) https://github.com/defland/tunhaobi (5%进度)