你好,欢迎来到本课程,很高兴你参与到Go学习。我希望本教学内容可以提供一个较好的学习体验。
本课程还可以通过访问网站 或者 Educative.io. 你的⭐是我的最大动力!
-
开始
-
第一章
-
第二章
-
第三章
-
第四章
-
附录
Go (也常称为 Golang,注:Golang其实是因为当初go这个域名被抢注使用golang作为域名,所以其实它不是一个正确的称呼,现在还用了go.dev)是由Google于2007年开发并且在2009年开源的一门编程语言。
专注于设计一个简单,可读以及高效。组合了高效,快速及安全的一门静态编译型语言,同时具备动态语言的简单特性,使得编程更有趣了。
也就是说,它们想组合Python和C++最好的部分,以便构建一个可靠、高效利用多核处理器的系统。
在开始该课程前,我们聊聊为什么要学习Go。
Go非常简单学习,并且有一个非常活跃的社区支持。
作为一个多范式编程语言,你可以使用它来构建类似后端服务,云计算,甚至是最近流行的数据科学。
非常适合构建分布式系统。流行的Kubernetes和Docker也都是Go实现的。
Go仅包含25个关键字,容易阅读,编写及维护。语言自身也想当简洁。
但其实Go又不简单,后面我会学习Go几个强大的特性。
Go发展迅猛,被越来越多的公司采用,同时诞生了许多高收入工作机会。
希望这能让你对Go产生浓厚的兴趣,让我们来开始课程。
本教程我们开始安装Go以及配置代码编辑器。
我们可以从下载区域安装Go。

以下指令摘至官网
-
打开下载的安装包,根据对话框来进行Go安装。 安装包将Go分发在
/usr/local/go. 安装包还将/usr/local/go/bin目录放置在PATH环境变量。 你可能需要重新打开终端会话使其生效。 -
通过打开命令提示符敲入如下指令来确保Go成功安装:
$ go version
- 确认正确输出了Go安装的版本号。
- 移除之前已安装Go目录
/usr/local/go(如果存在), 然后将归档文件解压到目录/usr/local, 创建一个全新的Go目录/usr/local/go:
$ rm -rf /usr/local/go && tar -C /usr/local -xzf go1.19.1.linux-amd64.tar.gz
(你可以需要使用root用户来执行,或者使用sudo)
不要untar 归档目录至已经存在的/usr/local/go 目录下. 这样会导致安装失败。
- 添加
/usr/local/go/bin到PATH环境变量. 可以通过添加如下行到$HOME/.profile或者/etc/profile(对系统全局安装):
export PATH=$PATH:/usr/local/go/bin
注意: 以上改变如果在未重启系统情况下可能不会立即生效。要立即生效,只需在shell命令行下执行 source $HOME/.profile.
- 通过打开命令对话框敲入如下命令来确保Go安装成功:
$ go version
- 确认命令正确输出了Go安装的版本号。
- 打开下载的MSI文件,根据提示框来安装Go。
默认,安装器会将Go安装至Program Files 或 Program Files (x86)目录。 你可以根据需要进行修改。安装完后,你需要关闭并重新打开命令对话框以便安装器对环境变量的变更生效。
- 确保Go正确安装.
- 系统中单机开始菜单。
- 在菜单搜索框输入cmd,按回车。
- 在命令对话框中输入如下命令:
$ go version
- 确认命令正确输出了Go安装的版本号。

你可以选用你青睐的其它代码编辑器。
确保VS Code安装了 Go 扩张以便我们更佳的开发体验。
这就是我们Go安装和配置内容,让我们开始编写我们第一个hello world!
让我们编写第一个你好世界程序,我们从初始化一个module开始,使用go mod命令来操作。
$ mkdir example
$ go mod init example等等...module是什么鬼?别急,后面我们再讨论!我们先暂定module就是Go包的一个
继续,让我们来创建一个main.go文件,编写一个简单输出世界你好的程序。
package main
import "fmt"
func main() {
fmt.Println("你好世界!")
}fmt是Go标准库
现在,让我们快速分解这里的代码,熟悉一下Go程序结构。
首先,我们定义了main包名。
package main然后,我们导入包。
import "fmt"最后类似其它编程语言C, Java或者C#一样定义了main入口函数。
func main() {
...
}这里先记个大概,后面课程我们会学习functions,imports和其它详情。
最后,我们通过使用go run命令来执行代码。
$ go run main.go
你好世界!恭喜,你完成第一个Go程序的编写!
本章,我们将学习变量。我还会学习Go提供给我们的不同数据类型。
让我们从定义一个变量开始。
以下定义了一个未初始化变量:
var foo string定义并且初始化:
var foo string = "Go is awesome"多个定义:
var foo, bar string = "Hello", "World"
// 或者
var (
foo string = "Hello"
bar string = "World"
)虽然类型省略了,但是能被自动推断:
var foo = "What's my type?"短声明方式,这里忽略var关键字,类型是隐式申明。大部分我们会用这种方式来申明变量。
我们同时使用:=来声明和赋值变量。
foo := "Shorthand!"注意: 短声明仅在 函数 体使用.
我还可以使用const关键字来定义常量,正如其名,它值是固定不能更改。
const constant = "This is a constant"还有一个重要点是,只有常量可以赋值给其它常量。
const a = 10
const b = a // ✅ 有效
var a = 10
const b = a // ❌ a (variable of type int) is not constant (InvalidConstInit)非常好!让我们看看Go里的一些基本数据类型。我们从字符串开始。
在Go,字符串是字节序列。它们使用双引号定义或者反引号来定义多行字符串。
var name string = "My name is Go"
var bio string = `I am statically typed.
I was designed at Google.`接下来是用来定义布尔值的bool。他只有两种值 true or false。
var value bool = false
var isItTrue bool = true操作符
布尔类型还可以使用如下操作符
| Type | Syntax |
|---|---|
| Logical | && ! |
| Equality | == != |
现在,我们谈谈数值类型, 先从
有符号和无符号整型
Go内建几个不同大小的数值类型,用于存储有符号和无符号整型
通用的int和uint类型大小是平台依赖的,在32位系统位32位宽度,在64位系统即64位宽度
var i int = 404 // 平台依赖
var i8 int8 = 127 // -128 to 127
var i16 int16 = 32767 // -2^15 to 2^15 - 1
var i32 int32 = -2147483647 // -2^31 to 2^31 - 1
var i64 int64 = 9223372036854775807 // -2^63 to 2^63 - 1类似有符号整型,我们还有无符号整型。
var ui uint = 404 // 平台依赖
var ui8 uint8 = 255 // 0 to 255
var ui16 uint16 = 65535 // 0 to 2^16
var ui32 uint32 = 2147483647 // 0 to 2^32
var ui64 uint64 = 9223372036854775807 // 0 to 2^64
var uiptr uintptr // Integer representation of a memory address如你所看到的,这里还存在无符号整型uintptr类型,它一个整型用来保存内存地址。并不推荐使用它,所以我们大可不必担心它。
该用哪个?
推荐在使用整型时选用int,除非我们需要特性大小或者无符号的整型。
整型别名
接下来,我们来看看整型的别名。
Byte and Rune
Go有两个附加的整型称作byte和rune,它们分别使用uint8和int32作为原生类型。
type byte = uint8
type rune = int32一个 rune 表示一个unicode码点。.
var b byte = 'a'
var r rune = '🍕'浮点类型
接下来,我们看看用来存储小数的浮点类型。
Go包含两种浮点类型float32和float64。两种类型遵从IEEE-754标准。
默认浮点值使用的是float64
var f32 float32 = 1.7812 // IEEE-754 32位
var f64 float64 = 3.1415 // IEEE-754 64位操作符
Go提供了一些对数值操作的操作符。
| Type | Syntax |
|---|---|
| Arithmetic | + - * / % |
| Comparison | == != < > <= >= |
| Bitwise | & ^ << >> |
| Increment/Decrement | ++ -- |
| Assignment | = += -= *= /= %= <<= >>= &= |= ^= |
复数
在Go有两种复数类型,complex128实部和虚部使用float64,complex64实部和虚部使用float32。
我们可以使用内建的complex函数或者使用字面值来定义复数。
var c1 complex128 = complex(10, 1)
var c2 complex64 = 12 + 4i现在,我们来讨论一下零值。在Go,任何声明变量在没有显示声明其初始值时均会初始化为_零值_。例如,我们看定义如下变量:
var i int
var f float64
var b bool
var s string
fmt.Printf("%v %v %v %q\n", i, f, b, s)$ go run main.go
0 0 false ""所以,正如我们所看到int和float为赋值为0,bool赋值为false,string被赋值为空字符串。这和其它编程语言有一些不一样。例如,但部分未显示赋值初始化的变量会被定义为null或者undefined。
很好,那Printf这些百分号是啥?正如你所猜到,它们是用来格式化用的,后面我们学习它们。
继续,我们现在已经知道数据类型工作方式,那让我们看看如何做数据转换。
i := 42
f := float64(i)
u := uint(f)
fmt.Printf("%T %T", f, u)$ go run main.go
float64 uint正如我们所看到的,这里打印了float64和unit。
注意这里是一种不同的解析方式
类型别名首次在Go 1.9出现。它允许开发者提供一个现存类型其它名字。并且可以和底层类型交互使用。
package main
import "fmt"
type MyAlias = string
func main() {
var str MyAlias = "I am an alias"
fmt.Printf("%T - %s", str, str) // 输出: string - I am an alias
}最后,还可以自定义类型,它不能像类型别名一样与原始类型相等性比较。
package main
import "fmt"
type MyDefined string
func main() {
var str MyDefined = "I am defined"
fmt.Printf("%T - %s", str, str) // Output: main.MyDefined - I am defined
}有啥区别
自定义类型比仅仅是给原始类型定义一个别名,它还完全是一个全新的类型。不能与原始类型互换使用。
这个可能会让你有点迷糊,我们来看看例子来更清晰一点。
package main
import "fmt"
type MyAlias = string
type MyDefined string
func main() {
var alias MyAlias
var def MyDefined
// ✅ 有效
var copy1 string = alias
// ❌ Cannot use def (variable of type MyDefined) as string value in variable
var copy2 string = def
fmt.Println(copy1, copy2)
}正如我们所看到的,我们不能像类型别名那样用自定义类型来与原始类型互换使用。
本教程中,我们将学习关于字符串格式化,有时也称之为模板化。
fmt包含许多函数。为节省篇幅,我们仅讨论常用的一些函数。我们先从fmt.Print开始。
...
fmt.Print("What", "is", "your", "name?")
fmt.Print("My", "name", "is", "golang")
...$ go run main.go
Whatisyourname?Mynameisgolang如你所见,Print做任何格式操作,它仅简单接收字符串参数然后打印它。
接下来,还有一个类似Print的Println函数,但是它会在末尾增加换行符,并且在参数字符串之间增加空格。
...
fmt.Println("What", "is", "your", "name?")
fmt.Println("My", "name", "is", "golang")
...$ go run main.go
What is your name?
My name is golang是不是好看多了!
接下来,有一个Printf,也叫做 "Print Formatter" ,允许我们对数值,字符串,布尔等数据进行格式化。
我们来看看例子。
...
name := "golang"
fmt.Println("What is your name?")
fmt.Printf("My name is %s", name)
...$ go run main.go
What is your name?
My name is golang这里%s被name变量值替换了。
这里%s是什么意思呢?
这些称为 占位符,它用来告诉函数如何格式化参数。我们控制宽度,类型和精度等等。可以参考手册。
现在,让我们马不停蹄的了解更多例子。这里我们试着计算一个百分比然后将它打印到终端。
...
percent := (3/5) * 100
fmt.Printf("%f", percent)
...$ go run main.go
58.181818如果我们指向打印出58.18仅包含两个精度的小数,我们可以使用.2f格式化占位符。
同时还想增加一个百分号,这里百分号需要 转义 。
...
percent := (3/5) * 100
fmt.Printf("%.2f %%", percent)
...$ go run main.go
58.18 %我们看一组对应的Sprint, Sprintln, 和 Sprintf。这些工作机制和之前print的函数一样,唯一的区别是它仅返回格式化字符串而不是打印它们。
让我们来看个例子。
...
s := fmt.Sprintf("hex:%x bin:%b", 10 ,10)
fmt.Println(s)
...$ go run main.go
hex:a bin:1010这里Sprintf格式化我们的整型为16进制和2进制表示形式并返回为字符串数据格式。
最后我们看看多行字符串字面量。
...
msg := `
Hello from
multiline
`
fmt.Println(msg)
...真棒!但这只是冰山一角。请你查看go doc里的fmt包来了解更多信息。
如果你是具备C/C++背景的话,使用起来会感觉很自然,但是如果接触的是其它语言的话,如Python或者JavaScript,用法可能会有一些区别。但是它非常强大,你将看到它被广泛使用。
让我们聊聊流程控制,从if/else开始。
它工作方式与你之前接触的其它编程语言基本一致,就是表达式不再使用()括号包起来。
func main() {
x := 10
if x > 5 {
fmt.Println("x is gt 5")
} else if x > 10 {
fmt.Println("x is gt 10")
} else {
fmt.Println("else case")
}
}$ go run main.go
x is gt 5我们还可以使用紧凑型if语句。
func main() {
if x := 10; x > 5 {
fmt.Println("x is gt 5")
}
}注意:该模式很常用
接下来,我们学习switch语句,它使得条件逻辑变得短小。
在Go中,switch仅运行匹配case子句表达式,它不需要手动添加break语句到每个case子句中。
也就是说它从上到下执行,当匹配case子句后将停止执行其它case子句。
让我们看看例子:
func main() {
day := "monday"
switch day {
case "monday":
fmt.Println("time to work!")
case "friday":
fmt.Println("let's party")
default:
fmt.Println("browse memes")
}
}$ go run main.go
time to work!switch同样也支持短声明方式:
switch day := "monday"; day {
case "monday":
fmt.Println("time to work!")
case "friday":
fmt.Println("let's party")
default:
fmt.Println("browse memes")
}我们可以通过显示使用fallthrough关键字让go继续执行后面的case子句(无论条件是否匹配)。
switch day := "monday"; day {
case "monday":
fmt.Println("time to work!")
fallthrough
case "friday":
fmt.Println("let's party")
default:
fmt.Println("browse memes")
}执行该代码,我们看到当第一个case子句匹配后,switch语句遇到fallthrough关键字后继续执行了后面的case子句。
$ go run main.go
time to work!
let's party我们还可以在switch中不带任何表达式,相当于switch true。
x := 10
switch {
case x > 5:
fmt.Println("x is greater")
default:
fmt.Println("x is not greater")
}现在,让我们将注意转移到循环。
在Go中,我们只有一个循环类型语句即for。
但是它用途非常广泛。和if语句一样,我们不需要像其它语句一样使用括号()包起来。
我们从基础for循环开始。
func main() {
for i := 0; i < 10; i++ {
fmt.Println(i)
}
}基础for循环使用冒号分隔了三部分:
- 初始语句: 在首次循环执行前执行。
- 条件表达式: 在每次循环都会进行判断。
- 后置语句: 每次循环结束后执行。
Break 和 continue
正如预期,Go在for语句中也支持break和continue控制语句。让我们来看个例子:
func main() {
for i := 0; i < 10; i++ {
if i < 2 {
continue
}
fmt.Println(i)
if i > 5 {
break
}
}
fmt.Println("We broke out!")
}所以,continue用来跳过本次循环语句,break用来结束循环语句。
同样,初始语句和后置语句是可选的,这样for可以表现为while同样的形式。
func main() {
i := 0
for ;i < 10; {
i += 1
}
}注意:我们还可以移除多余的分号使其更简洁。
最后,如果我们条件表达式部分的话,它就成为了一个无限循环语句了。
func main() {
for {
// do stuff here
}
}本章,我们讨论Go中使用函数,先看看如何定义一个简单的函数。
func myFunction() {}我们如下 执行:
...
myFunction()
...我们来传递一参数
func main() {
myFunction("Hello")
}
func myFunction(p1 string) {
fmt.Println(p1)
}$ go run main.go我们看出打印出了输入参数。如果多个参数数据类型一致的话还可以使用短申明方式:
func myNextFunction(p1, p2 string) {}现在让我们来返回一个值。
func main() {
s := myFunction("Hello")
fmt.Println(s)
}
func myFunction(p1 string) string {
msg := fmt.Sprintf("%s function", p1)
return msg
}Go语言支持多返回值!
func main() {
s, i := myFunction("Hello")
fmt.Println(s, i)
}
func myFunction(p1 string) (string, int) {
msg := fmt.Sprintf("%s function", p1)
return msg, 10
}另一个特性是具名返回值,返回值可以在申明时指定其具体的名字,这样类似是函数体当中变量一样。
func myFunction(p1 string) (s string, i int) {
s = fmt.Sprintf("%s function", p1)
i = 10
return
}注意我们使用return语句时并没有带任何值,这也称为 裸返回。
虽然这个特性很有趣,但是请谨慎使用,因为这在大型函数减少可读性。
接下来,让我们谈谈函数作为值,Go函数作为一等公民(first class),我们可以将它们作为值来使用。我们来试试!
func myFunction() {
fn := func() {
fmt.Println("inside fn")
}
fn()
}这里的fn我们还可以使用 匿名函数 的方式处理。
func myFunction() {
func() {
fmt.Println("inside fn")
}()
}注意我们我们通过再末尾使用括号来执行它
我们继续来在返回函数中使用闭包。简单来讲就是函数体内引用外部变量。
闭包是此法作用域的,也就是说函数内可以访问定义时作用域值。
func myFunction() func(int) int {
sum := 0
return func(v int) int {
sum += v
return sum
}
}...
add := myFunction()
add(5)
fmt.Println(add(10))
...这里我们将得到15结果,因为sum变量 绑定 到函数中。我们应该掌握这个强大特性。
现在让我们来看看函数可变参数,也即函数通过使用...操作符来可以接收零个或者多个参数。
以下是一个可接收多个参数的函数例子。
func main() {
sum := add(1, 2, 3, 5)
fmt.Println(sum)
}
func add(values ...int) int {
sum := 0
for _, v := range values {
sum += v
}
return sum
}很酷对吧?别担心range关键字,后面课程我们会再讨论。
事实上: fmt.Println 就是个可变参数函数,所以我们才可以传递多个值
在Go中,init是一个特别的生命周期函数,它执行于main函数之前。
类似main函数,init函数不接收任何参数也不返回任何值。我们来看看例子:
package main
import "fmt"
func init() {
fmt.Println("Before main!")
}
func main() {
fmt.Println("Running main")
}正如预期,init函数执行于main函数之前。
$ go run main.go
Before main!
Running main不像main函数,可以在单个或者多个文件定义任意多个init函数。
在单个文件中定义多个init函数,执行顺序为定义顺序,当init函数定义在多个文件时,它的执行顺序依赖名字排序。
package main
import "fmt"
func init() {
fmt.Println("Before main!")
}
func init() {
fmt.Println("Hello again?")
}
func main() {
fmt.Println("Running main")
}如果我们执行该代码,我们将会看到init函数会根据定义的顺序执行。
$ go run main.go
Before main!
Hello again?
Running maininit函数是可选的,经常用来作为全局基础设置,例如数据库连接,获取配置文件,配置环境等。
最后,我们来讨论defer关键字,它允许在函数结束后延迟执行代码。
func main() {
defer fmt.Println("I am finished")
fmt.Println("Doing some work...")
}我们是否可以拥有多个defer函数?当然,它会将多个函数置入 defer栈,例如:
func main() {
defer fmt.Println("I am finished")
defer fmt.Println("Are you?")
fmt.Println("Doing some work...")
}$ go run main.go
Doing some work...
Are you?
I am finished正如上面所见,defer语句是一个栈结构,以 后进先出 的形式来执行。
所以,Defer非常有用,常用来做清理或者错误处理的工作。
函数还支持泛型,不过我们后面再讨论。
本章,我们来学习模块。
简单来说,一个模块就是在$GOPATH/src目录外,定义一个目录包含go.mod文件且包含Go 包集合。
Go模块首次出现在 Go.11,带来了原生支持版本和模块。早期,我们需要配置GO111MODULE=on来打开试验性模块特性。不过在Go 1.13开始默认打开。
但是什么是GOPATH?
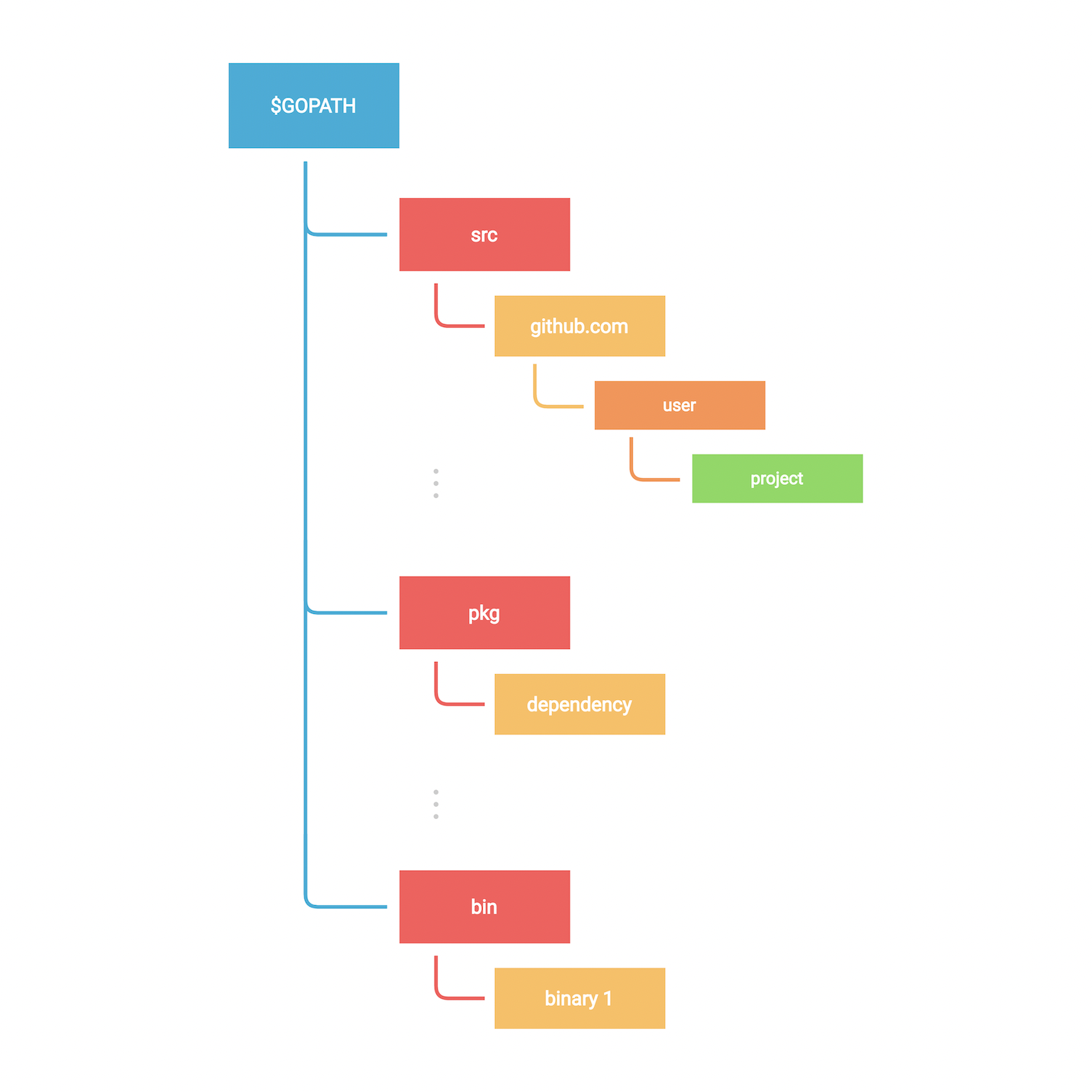
GOPATH是一个变量,用来定义根工作目录,它包含:
- src: 包含结构化的Go源码
- pkg: 包含编译的包代码
- bin: 包含编译的二进制可执行文件
早期,我们就通过使用go mod init命令来创建模块,通过使用go.mod文件来配置。
$ go mod init example这里要提醒的是如果你打算将模块发布到Github中,你可以使用对应Github仓库地址。例如:
$ go mod init github.com/golang/example现在我们来看看go.mod,该文件模块路径和依赖关系。
module <name>
go <version>
require (
...
)如果我们需要添加依赖,可以使用go install命令:
$ go install github.com/rs/zerolog你还会在根目录下看到go.sum文件被创建。该文件包含已使用依赖模块的哈希值。
我可以使用go list命令列出所有的依赖:
$ go list -m all如果依赖没被使用,我们还可以简单使用go mod tidy进行清理:
$ go mod tidy结束模块的讨论,让我们来聊聊vendoring。
Vendoring是用来对项目使用的第三方包的完整拷贝。它会伴随项目一起进行贮存。
通过使用go mod vendor命令来实现。
我们就可以使用go mod tidy来重新安装模块了。
package main
import "github.com/rs/zerolog/log"
func main() {
log.Info().Msg("Hello")
}$ go mod tidy
go: finding module for package github.com/rs/zerolog/log
go: found github.com/rs/zerolog/log in github.com/rs/zerolog v1.26.1$ go mod vendor├── go.mod
├── go.sum
├── go.work
├── main.go
└── vendor
├── github.com
│ └── rs
│ └── zerolog
│ └── ...
└── modules.txt
本章,我们聊聊包。
一个包仅就是一个目录来存放一个或者多个Go源文件,或者是其它包。
也就是说每个Go源代码文件都必须属于一个包,包定义在源文件开头处:
package <package_name>目前,我们已经在package main里完成基础工作。按照约定,可执行程序称为 Commands,其它称为 Packages。
main包应该包含一个main()函数,作为可执行程序入口。
让我们通过创建一个custom包,存放在code.go文件中。
package custom在继续前,我们来聊聊导入和导出。和其它语言一样,go同样有导入导出,不过它更佳优雅。
基本上,任何使用大写字母开头标识的值(例如变量和函数)都可以导出给其它包使用。
例如custom包
package custom
var value int = 10 // 不被导出
var Value int = 20 // 被导出小写字母标识的变量将没有被导出,属于custom包的私有变量。
那好,我们如何导入与访问呢?让我们在main.go文件中导入custom包。
我们可以使用我已经之前通过go.mod初始化的模块。
---go.mod---
module example
go 1.18
---main.go--
package main
import "example/custom"
func main() {
custom.Value
}注意包名为导入路径的最后部分。
我们可以如下方式导入多个包:
package main
import (
"fmt"
"example/custom"
)
func main() {
fmt.Println(custom.Value)
}我们还可以对于相同包名时使用别名来避免冲突:
package main
import (
"fmt"
abcd "example/custom"
)
func main() {
fmt.Println(abcd.Value)
}Go不限于使用本地包,可以使用go install使用外部包,例如下载一个简单的日志包github.com/rs/zerolog/log.
$ go install github.com/rs/zerologpackage main
import (
"github.com/rs/zerolog/log"
abcd "example/custom"
)
func main() {
log.Print(abcd.Value)
}同时,确保使用go doc查看安装包的说明文档
最后,我要指出的是Go没有强制 "目录结构" 约束,请尽量按照简单易于理解的方式来组织你的包。
本章,我们学习首次在Go 1.18出现的多模块工作区。
工作区允许我们无需修改go.mod文件同时拥有多个模块。工作区各个模块各自以根模块方式来解决依赖。
为更好理解,我们创建一个hello模块:
$ mkdir workspaces && cd workspaces
$ mkdir hello && cd hello
$ go mod init hello为演示目的,我们简单实现main.go,并安装示例包。
package main
import (
"fmt"
"golang.org/x/example/stringutil"
)
func main() {
result := stringutil.Reverse("Hello Workspace")
fmt.Println(result)
}$ go install golang.org/x/example
go: downloading golang.org/x/example v0.0.0-20220412213650-2e68773dfca0
go: added golang.org/x/example v0.0.0-20220412213650-2e68773dfca0运行后,我们可以看到反转的字符串。
$ go run main.go
ecapskroW olleH这也没什么,但是如果我们想要修改所依赖的stringutil模块呢?
之前,我们需要使用在go.mod文件使用replace指令来实现,但是现在我们可以使用工作区来实现。
让我们在workspaces目录来创建工作区。
$ go work init该命令会创建 go.work 文件。
$ cat go.work
go 1.18我们将添加hello模块到工作区。
$ go work use ./hello它将更新go.work文件引用我们的hello模块。
go 1.18
use ./hello现在让我们下载stringutil,修改Reverse函数的实现。
$ git clone https://go.googlesource.com/example
Cloning into 'example'...
remote: Total 204 (delta 39), reused 204 (delta 39)
Receiving objects: 100% (204/204), 467.53 KiB | 363.00 KiB/s, done.
Resolving deltas: 100% (39/39), done.example/stringutil/reverse.go
func Reverse(s string) string {
return fmt.Sprintf("I can do whatever!! %s", s)
}最后,我们添加example包到工作区。
$ go work use ./example
$ cat go.work
go 1.18
use (
./example
./hello
)完美,现在让我们执行hello模块,注意Revese函数的变更。
$ go run hello
I can do whatever!! Hello Workspace这时1.18被低估的特性,但是在某些场景下非常有用.
在讲解模块时,我们谈及了模块相关的go命令,让我们继续讨论其它重要的命令。
我们从go fmt开始,用来格式化代码,强制规则让我们不用去过多烦恼代码格式。
$ go fmt如果你是来自JavaScript或者Python背景的话可能会觉得很奇怪,不过不用去担心代码格式相当的好。
接下来,还有go vet用来检测包中错误。
$ go vet还有go env打印所有的go环境信息,我们后面还会学习这些构建参数信息。
最后,go doc用来查看包里的文档,这是查看fmt包文档示例:
$ go doc -src fmt Printf让我们使用go help命令来查看其它可用命令。
$ go help列出的有:
go fix 找出一些过时的API并且重新为新式API
go generate 用来生成代码
go install 编译安装包和依赖
go clean 清理编译器生成的文件
一些其它的命令如go build和go test我们将会在后面课程学习到。
Go提供一种极佳特性,使用二进制静态编译高效代码传递代码。
我们可以使用go build命令来实现编译。
package main
import "fmt"
func main() {
fmt.Println("I am a binary!")
}$ go build这将生成模块的二进制文件。例如,这里是example。
我们还可以指定输出的名字:
$ go build -o app我们现在来执行它。
$ ./app
I am a binary!太简单了
现在我们来聊聊一些编译时参数:
GOOS和GOARCH
我们可以使用go tool命令来列出支持的CPU架构。
$ go tool dist list
android/amd64
ios/amd64
js/wasm
linux/amd64
windows/arm64
.
.
.这里是从macOS编译Wwndows可执行文件的例子:
$ GOOS=windows GOARCH=amd64 go build -o app.exeCGO_ENABLED
该变量允许配置CGO, Go用来执行C代码。
它帮助我们生成 静态链接 二进制程序而不需要外部依赖。
它非常有用,比如我们像将我们go二进制程序使用最小化外部依赖方式执行。
我们这样使用:
$ CGO_ENABLED=0 go build -o app本章,我们来讨论指针。那么什么是指针?
简单来说,指针旧是用一个变量来存储另一个变量的内存地址。
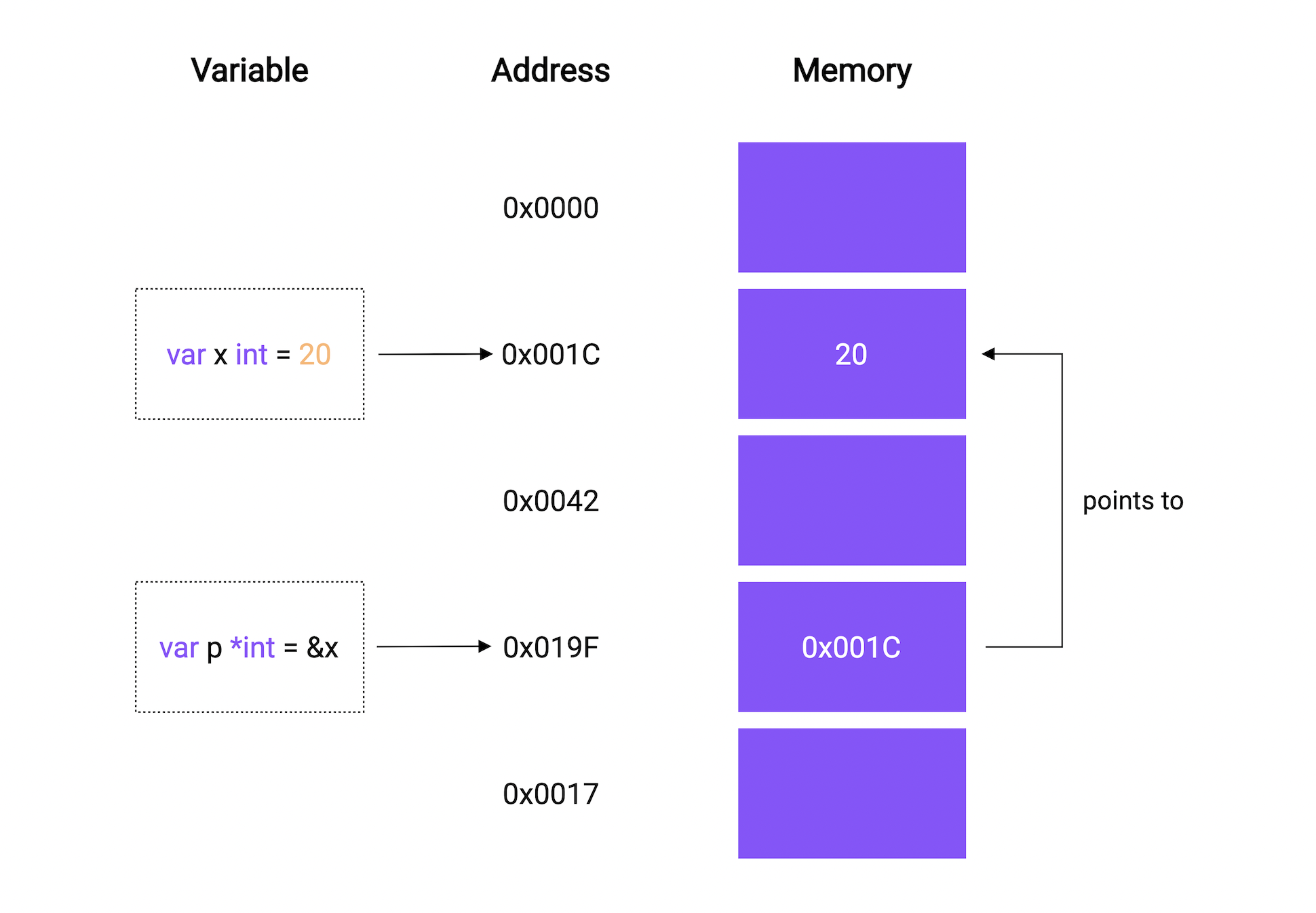
它可以这样使用:
var x *TT是类似int,string,float等类型。
我们来看看实际的例子:
package main
import "fmt"
func main() {
var p *int
fmt.Println(p)
}$ go run main.go
nil这里打印出了nil,nil又是什么?
nil是一个预定义的标识符,用来表示指针,接口,通道,map和切片的零值。
就类似我们在变量和数据类型章节所提及,未初始化int零值为0,bool为false等。
好,现在我们来为指针赋值。
package main
import "fmt"
func main() {
a := 10
var p *int = &a
fmt.Println("address:", p)
}我们使用&符号来引用变量的内存地址。
$ go run main.go
0xc0000b8000这里即a变量的内存地址。
我还可以使用*符号来指针所指向存储的值。称为解引用。
例如,我们通过对p指针使用*操作符来取得a的变量的值。
package main
import "fmt"
func main() {
a := 10
var p *int = &a
fmt.Println("address:", p)
fmt.Println("value:", *p)
}$ go run main.go
address: 0xc000018030
value: 10我们不但能通过指针访问,还可以修改。
package main
import "fmt"
func main() {
a := 10
var p *int = &a
fmt.Println("before", a)
fmt.Println("address:", p)
*p = 20
fmt.Println("after:", a)
}$ go run main.go
before 10
address: 0xc000192000
after: 20我认为还是想当简洁的!
指针可以用来实现引用传递函数参数。
下面是例子:
myFunction(&a)
...
func myFunction(ptr *int) {}还有另外一种初始化指针的方式,使用new函数,并传递类型作为参数。它分配对应容纳该类型指针并返回。
看看例子:
package main
import "fmt"
func main() {
p := new(int)
*p = 100
fmt.Println("value", *p)
fmt.Println("address", p)
}$ go run main.go
value 100
address 0xc000018030有个奇思妙想就是指针能否指向指针?答案是:可以。
package main
import "fmt"
func main() {
p := new(int)
*p = 100
p1 := &p
fmt.Println("P value", *p, " address", p)
fmt.Println("P1 value", *p1, " address", p)
fmt.Println("Dereferenced value", **p1)
}$ go run main.go
P value 100 address 0xc0000be000
P1 value 0xc0000be000 address 0xc0000be000
Dereferenced value 100注意p1存储为p的地址.
Go不支持同C/C++的指针运算。
p1 := p * 2 // Compiler Error: invalid operation但是,我们可以使用==来匹配两个指针是否相等。
p := &a
p1 := &a
fmt.Println(p == p1)为什么需要指针?
没有绝对的答案,指针给我们一个有用特性是可以不需要通过拷贝数据的方式来高效传递数据。
而且被大量使用。
最后,如果你其它语言转过来没有接触过指针概念,先不着急,先尝试构建一个指针工作的心智模型。
本章,我们来学习结构体。
struct是通过包含一系列命名字段的自定义类型。通常用来将一组相关数据组合在一个单元里。
如果你具备面向对象背景,将结构体想象成一个类,但是它仅支持组合,不支持继承。
我们可以如下定义一个struct:
type Person struct {}我们使用type关键字来创建一个新类型,然后紧跟名字,接着是struct关键字用来指明为结构体。
现在,让我们增加一些字段:
type Person struct {
FirstName string
LastName string
Age int
}同时,如果相同类型我们还可以联合申明。
type Person struct {
FirstName, LastName string
Age int
}现在我们已经有结构体了,我们可以类似其它数据类型方式来定义:
func main() {
var p1 Person
fmt.Println("Person 1:", p1)
}$ go run main.go
Person 1: { 0}正如所见,所有的结构体字段使用零值来初始化。所以FirstName和LastName设置为""空字符串且Age设置为0。
我们还可以使用 "结构体字面量" 来初始化。
func main() {
var p1 Person
fmt.Println("Person 1:", p1)
var p2 = Person{FirstName: "Karan", LastName: "Pratap Singh", Age: 22}
fmt.Println("Person 2:", p2)
}为提高可读性,我们通过换行隔开且最后也要声明逗号。x
var p2 = Person{
FirstName: "Karan",
LastName: "Pratap Singh",
Age: 22,
}$ go run main.go
Person 1: { 0}
Person 2: {Karan Pratap Singh 22}还可以只指明部分字段初始化:
func main() {
var p1 Person
fmt.Println("Person 1:", p1)
var p2 = Person{
FirstName: "Karan",
LastName: "Pratap Singh",
Age: 22,
}
fmt.Println("Person 2:", p2)
var p3 = Person{
FirstName: "Tony",
LastName: "Stark",
}
fmt.Println("Person 3:", p3)
}$ go run main.go
Person 1: { 0}
Person 2: {Karan Pratap Singh 22}
Person 3: {Tony Stark 0}Person 3的Age字段同样使用了默认零值。
Go结构体还支持不带字段名的初始化方式。
func main() {
var p1 Person
fmt.Println("Person 1:", p1)
var p2 = Person{
FirstName: "Karan",
LastName: "Pratap Singh",
Age: 22,
}
fmt.Println("Person 2:", p2)
var p3 = Person{
FirstName: "Tony",
LastName: "Stark",
}
fmt.Println("Person 3:", p3)
var p4 = Person{"Bruce", "Wayne"}
fmt.Println("Person 4:", p4)
}不过要注意的是,这里需要初始化时提供所有的值否则会报错。
$ go run main.go
# command-line-arguments
./main.go:30:27: too few values in Person{...} var p4 = Person{"Bruce", "Wayne", 40}
fmt.Println("Person 4:", p4)我们还可以定义一个匿名结构体。
func main() {
var p1 Person
fmt.Println("Person 1:", p1)
var p2 = Person{
FirstName: "Karan",
LastName: "Pratap Singh",
Age: 22,
}
fmt.Println("Person 2:", p2)
var p3 = Person{
FirstName: "Tony",
LastName: "Stark",
}
fmt.Println("Person 3:", p3)
var p4 = Person{"Bruce", "Wayne", 40}
fmt.Println("Person 4:", p4)
var a = struct {
Name string
}{"Golang"}
fmt.Println("Anonymous:", a)
}让我们来看看如何访问单个字段。
func main() {
var p = Person{
FirstName: "Karan",
LastName: "Pratap Singh",
Age: 22,
}
fmt.Println("FirstName", p.FirstName)
}我也创建一个指向结构体的指针。
func main() {
var p = Person{
FirstName: "Karan",
LastName: "Pratap Singh",
Age: 22,
}
ptr := &p
fmt.Println((*ptr).FirstName)
fmt.Println(ptr.FirstName)
}上面两个语句是相等,我们无需显示对指针进行解引用。我们也可以使用内建的new函数。
func main() {
p := new(Person)
p.FirstName = "Karan"
p.LastName = "Pratap Singh"
p.Age = 22
fmt.Println("Person", p)
}$ go run main.go
Person &{Karan Pratap Singh 22}当两个结构体所有字段均相等,那么两个结构体即相等。
func main() {
var p1 = Person{"a", "b", 20}
var p2 = Person{"a", "b", 20}
fmt.Println(p1 == p2)
}$ go run main.go
true和变量函数一致,结构体字段通过使用首字母标识是否导出。
type Person struct {
FirstName, LastName string
Age int
zipCode string
}zipCode不会导出。Person结构体也一样,如果我们改为person,它也不会被导出。
type person struct {
FirstName, LastName string
Age int
zipCode string
}##嵌入和组合
之前我们提到,Go不支持继承,但是我们使用嵌入达到相同目的。
type Person struct {
FirstName, LastName string
Age int
}
type SuperHero struct {
Person
Alias string
}新结构体将包含原始结构体所有属性。它的行为与原始结构体一致。
func main() {
s := SuperHero{}
s.FirstName = "Bruce"
s.LastName = "Wayne"
s.Age = 40
s.Alias = "batman"
fmt.Println(s)
}$ go run main.go
{{Bruce Wayne 40} batman}不过,大多情况下不建议这样使用。我们通常仅定义为一个普通字段而不是嵌入方式。
type Person struct {
FirstName, LastName string
Age int
}
type SuperHero struct {
Person Person
Alias string
}Hence, we can rewrite our example with composition as well.
func main() {
p := Person{"Bruce", "Wayne", 40}
s := SuperHero{p, "batman"}
fmt.Println(s)
}$ go run main.go
{{Bruce Wayne 40} batman}这里没有对错,有时用嵌入会带来便利。
结构体标签允许我们为字段添加元信息,可以方便使用relect包来自定义行为。
如下方式定义标签。
type Animal struct {
Name string `key:"value1"`
Age int `key:"value2"`
}你将常在编码包中看见它们,例如XML, JSON, YAML, ORMS和配置管理。
以下是JSON编码器中的结构体标签用例:
type Animal struct {
Name string `json:"name"`
Age int `json:"age"`
}最后,我们来讨论结构传递。
结构体为值类型,当我赋值结构给另外一个变量时,将会生成一个全新的结构体拷贝。
同样当然我们传递结构体给函数时,函数同样会获得一个全新的拷贝。
package main
import "fmt"
type Point struct {
X, Y float64
}
func main() {
p1 := Point{1, 2}
p2 := p1 // Copy of p1 is assigned to p2
p2.X = 2
fmt.Println(p1) // Output: {1 2}
fmt.Println(p2) // Output: {2 2}
}空结构体占用0字节存储。
package main
import (
"fmt"
"unsafe"
)
func main() {
var s struct{}
fmt.Println(unsafe.Sizeof(s)) // Output: 0
}让我们聊聊方法。有时也称为带有receiver的函数。
严格上来说,Go并不是一个面向对象编程语言。它没有类,对象和继承。
然而,Go有类型,而且你还可以给类型定义 方法。
方法相对函数来说,除了多一个 receiver 参数外没有其它差别。让我们来看看如何定义方法。
func (receiver) Name(params) (returnTypes) {}_receiver_参数包含一个名字和类型。它们在出现在func关键字和方法名之间。
例如,让我们定义一个Car结构。
type Car struct {
Name string
Year int
}现在,我们定义个方法IsLatest用来返回该车是否生产与五年内。
func (c Car) IsLatest() bool {
return c.Year >= 2017
}正如你所见,我们可以使用receiver变量c来访问Car实例。我习惯将它对应面向对象里的this关键字。
现在我们可以在初始化结构体后来访问该方法了,和其它语言中类访问方法类似:
func main() {
c := Car{"Tesla", 2021}
fmt.Println("IsLatest", c.IsLatest())
}上面所有例子我都使用值receiver。
使用值receiver时,传递的是值拷贝。因此,任何在方法内的修改并不会影响到调用方。
例如,我们创建一个UpdateName来尝试更新Car的名字。
func (c Car) UpdateName(name string) {
c.Name = name
}现在,让我们来执行。
func main() {
c := Car{"Tesla", 2021}
c.UpdateName("Toyota")
fmt.Println("Car:", c)
}$ go run main.go
Car: {Tesla 2021}貌似名字并没有被修改,现在我们试着用指针receiver看看。
func (c *Car) UpdateName(name string) {
c.Name = name
}$ go run main.go
Car: {Toyota 2021}如预期,使用指针receiver将会修改原始调用方的值。
让我们看一些方法特性!
- Go足够聪明使用正确的方式来调用方法,指针receiver只是Go提供方便的语法糖。
(&c).UpdateName(...)- 如果我们方法中没有使用receiver我们还可以忽略调用名字。
func (Car) UpdateName(...) {}- 方法不但可以定义在结构体中,非结构体类型也同样可以。
package main
import "fmt"
type MyInt int
func (i MyInt) isGreater(value int) bool {
return i > MyInt(value)
}
func main() {
i := MyInt(10)
fmt.Println(i.isGreater(5))
}为什么使用方法来替代函数呢?
没有确切的答案一种方式比另一种好。它们在适合不同场景。
其中一个我能想到的是方法可以避免命名冲突。
因为方法绑定给了具体类型,所以对于多个receiver可以拥有相同名字。
当然还有是因为个人喜好,例如 "方法调用比函数调用更容易阅读和理解"。
本章,我们来学习Go里的数组和切片。
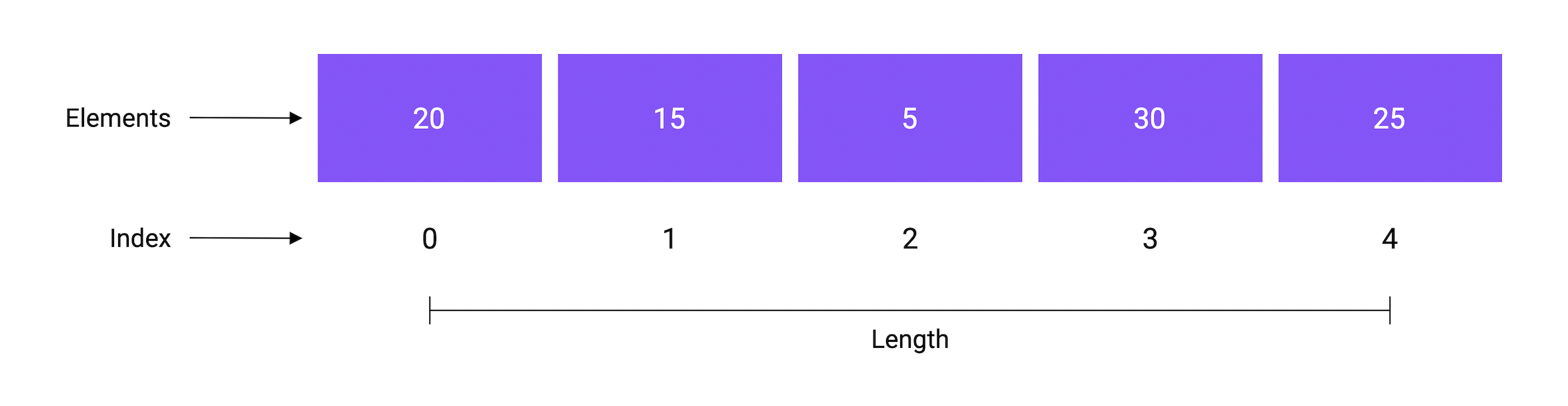
数组包含是包含相同类型固定大小的元素集合。它们使用顺序存储可以用下标访问。
我可以如下方式申明:
var a [n]T这里n是长度,T可以是任意类型,如整型,字符串或者自定义结构体。
现在我们来申明一个长度为4的整型数组,然后打印它。
func main() {
var arr [4]int
fmt.Println(arr)
}$ go run main.go
[0 0 0 0]默认,所有数组元素会初始化为相应元素的数组类型。
我们还可以使用数组字面量来初始化数组。
var a [n]T = [n]T{V1, V2, ... Vn}func main() {
var arr = [4]int{1, 2, 3, 4}
fmt.Println(arr)
}$ go run main.go
[1 2 3 4]同样可以使用短申明方式。
...
arr := [4]int{1, 2, 3, 4}和其它语言一样,我们可以使用根据存储顺序的下标来访问元素。
func main() {
arr := [4]int{1, 2, 3, 4}
fmt.Println(arr[0])
}$ go run main.go
1现在,我们来谈谈遍历。
有多种遍历数组的方式。
第一种是使用len函数来获取到数组长度使用for循环遍历。
func main() {
arr := [4]int{1, 2, 3, 4}
for i := 0; i < len(arr); i++ {
fmt.Printf("Index: %d, Element: %d\n", i, arr[i])
}
}$ go run main.go
Index: 0, Element: 1
Index: 1, Element: 2
Index: 2, Element: 3
Index: 3, Element: 4另一种是使用range关键字来使用for循环来遍历。
func main() {
arr := [4]int{1, 2, 3, 4}
for i, e := range arr {
fmt.Printf("Index: %d, Element: %d\n", i, e)
}
}$ go run main.go
Index: 0, Element: 1
Index: 1, Element: 2
Index: 2, Element: 3
Index: 3, Element: 4正如我们所看到的,和之前的输出结果一致。
range是多用途的,可以用在很多场景。
for i, e := range arr {} // 基本使用方式
for _, e := range arr {} // 使用 _ 忽略下标
for i := range arr {} // 只获取下标
for range arr {} // 仅循环数组不获取值和小标Go也可以创建多维数组。
我们看看例子。
func main() {
arr := [2][4]int{
{1, 2, 3, 4},
{5, 6, 7, 8},
}
for i, e := range arr {
fmt.Printf("Index: %d, Element: %d\n", i, e)
}
}$ go run main.go
Index: 0, Element: [1 2 3 4]
Index: 1, Element: [5 6 7 8]我们还是用...符号让编译器自动推断数组长度。
func main() {
arr := [...][4]int{
{1, 2, 3, 4},
{5, 6, 7, 8},
}
for i, e := range arr {
fmt.Printf("Index: %d, Element: %d\n", i, e)
}
}$ go run main.go
Index: 0, Element: [1 2 3 4]
Index: 1, Element: [5 6 7 8]现在我们聊聊数组特性。
数组的长度是其类型的一部分,数组a和b是完全不同的类型,不能相互赋值。
也就是我们不能改变数组大小,因为改变大小也就意味着改变其类型了。
package main
func main() {
var a = [4]int{1, 2, 3, 4}
var b [2]int = a // Error, cannot use a (type [4]int) as type [2]int in assignment
}Go里的数组不像其它类似C,C++和Java那样是引用类型。
也就是说将数组赋给一个新变量或者传递给函数时,将会对数组完全拷贝。
所以,如果我们对拷贝的数组做任何修改,原数组不会受影响。
package main
import "fmt"
func main() {
var a = [7]string{"Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"}
var b = a // Copy of a is assigned to b
b[0] = "Monday"
fmt.Println(a) // Output: [Mon Tue Wed Thu Fri Sat Sun]
fmt.Println(b) // Output: [Monday Tue Wed Thu Fri Sat Sun]
}我知道不会想,数组非常有用,但是又受限于它的固定大小。
这样旧引入的切片,那么切片是什么?
切片是数组的片段,切片构建于数组之上,提供了更多功能,可扩展性和更佳方便。
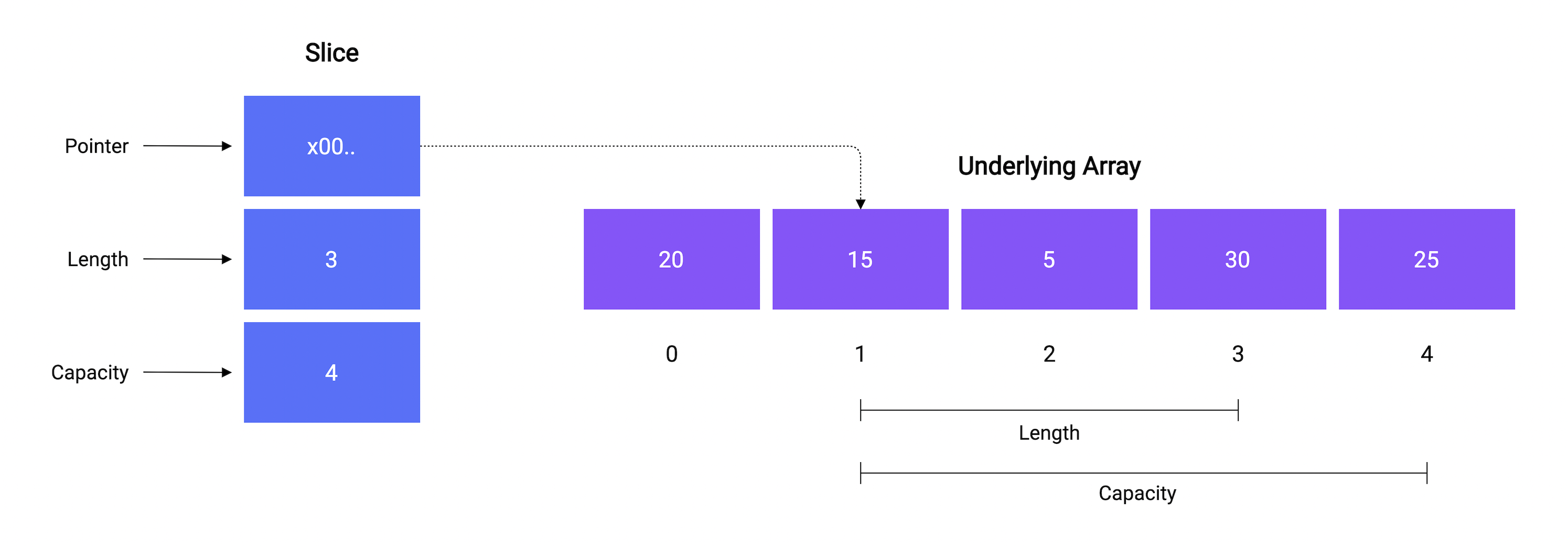
切片由以下三部分组成:
- 指针指向数组下标
- 切片包含数组的长度
- 可以容纳元素的最大容量
和len函数一样,我们也可以使用内建cap函数来获取切片容量,例如:
package main
import "fmt"
func main() {
a := [5]int{20, 15, 5, 30, 25}
s := a[1:4]
// 输出: Array: [20 15 5 30 25], Length: 5, Capacity: 5
fmt.Printf("Array: %v, Length: %d, Capacity: %d\n", a, len(a), cap(a))
// 输出: Slice [15 5 30], Length: 3, Capacity: 4
fmt.Printf("Slice: %v, Length: %d, Capacity: %d", s, len(s), cap(s))
}别担心,我们会详细讲解这里所有的东西。
我们来看看如何申明切片。
var s []T我们不需要给切片提供长度,试试看字符串切片
func main() {
var s []string
fmt.Println(s)
fmt.Println(s == nil)
}$ go run main.go
[]
true不同于数组,切片的零值为nil。
也有多种初始化切片的方式。一种是使用内建的make函数。
make([]T, len, cap) []Tfunc main() {
var s = make([]string, 0, 0)
fmt.Println(s)
}$ go run main.go
[]和数组一样,也可以使用切片字面量来初始化切片。
func main() {
var s = []string{"Go", "TypeScript"}
fmt.Println(s)
}$ go run main.go
[Go TypeScript]另一种方式是从数组创建切片。由于切片是数组的片段。我们可以使用low(上标)和high(下标)来创建数组。
a[low:high]func main() {
var a = [4]string{
"C++",
"Go",
"Java",
"TypeScript",
}
s1 := a[0:2] // 从0到2
s2 := a[:3] // 开头到第三个
s3 := a[2:] // 从第二个到最后
fmt.Println("Array:", a)
fmt.Println("Slice 1:", s1)
fmt.Println("Slice 2:", s2)
fmt.Println("Slice 3:", s3)
}$ go run main.go
Array: [C++ Go Java TypeScript]
Slice 1: [C++ Go]
Slice 2: [C++ Go Java]
Slice 3: [Java TypeScript]不指定上标即从0开始,不指定下标即数组长度 (len(a)).
除了可以从数组构建切片,同样也可以切片上构建切片。
var a = []string{
"C++",
"Go",
"Java",
"TypeScript",
}
var b = a[:]
fmt.Println("Slice a: ", a)
fmt.Println("Slice b: ", b)我们可以使用遍历数组相同的方式来遍历切片,使用结合len函数或者range关键字使用for循环遍历。
我们来看看Go提供的切片函数。
copy
copy()函数从一切切片拷贝元素到另一个切片中,它接收两个切片参数,一个是目标切片,一个是圆切片。它会返回拷贝元素的长度。
func copy(dst, src []T) int我们看看如何使用它。
func main() {
s1 := []string{"a", "b", "c", "d"}
s2 := make([]string, len(s1))
e := copy(s2, s1)
fmt.Println("Src:", s1)
fmt.Println("Dst:", s2)
fmt.Println("Elements:", e)
}$ go run main.go
Src: [a b c d]
Dst: [a b c d]
Elements: 4成功将源切片4个元素拷贝到目标切片。
append
append函数用来给切片追加元素。
它接收一个切片参数和要追加的元素。它返回包含其所有元素的新切片。
append(slice []T, elems ...T) []T让我们来尝试给切片追加元素。
func main() {
s1 := []string{"a", "b", "c", "d"}
s2 := append(s1, "e", "f")
fmt.Println("s1:", s1)
fmt.Println("s2:", s2)
}$ go run main.go
s1: [a b c d]
s2: [a b c d e f]执行append后包含新元素的切片被返回。
如果切片不够容量来存放追加元素情况下,切片会申请一个更大容量的底层数组。
所有原数会拷贝至新数组,然后添加追加元素。
最后我们来讨论切片的特性。
所有的切片均是引用类型,和数组不一样。
也就是改变切片数组其实是改变所引用的底层数组元素。
package main
import "fmt"
func main() {
a := [7]string{"Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"}
s := a[0:2]
s[0] = "Sun"
fmt.Println(a) // Output: [Sun Tue Wed Thu Fri Sat Sun]
fmt.Println(s) // Output: [Sun Tue]
}切片也可以作为可变参数。
package main
import "fmt"
func main() {
values := []int{1, 2, 3}
sum := add(values...)
fmt.Println(sum)
}
func add(values ...int) int {
sum := 0
for _, v := range values {
sum += v
}
return sum
}这里values...符号为对切片进行解包操作。
Go提供了内建字典类型,我们来学习如何使用它。
字典是什么呢?又为什么我们需要它呢?
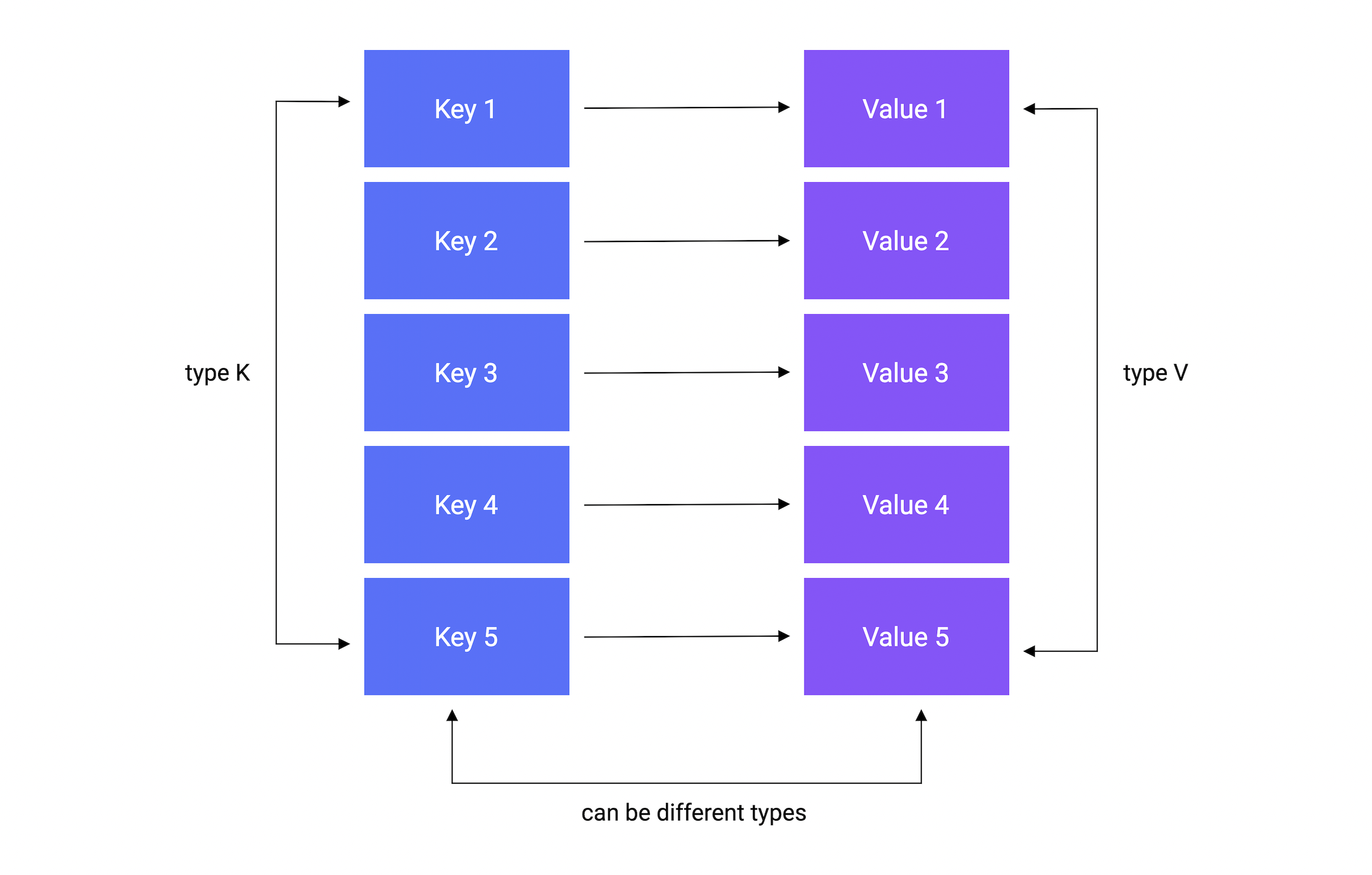
字典是一个无序的键值对集合。由键对应到值。键必须唯一,值可以相同。
它用于基于键快速查找,获取及删除数据。最常用的数据结构之一。
我们从申明开始。
字典使用如下语法申明:
var m map[K]VK是key类型,V是值类型。
例如下面申明了string为key对应int值的字典。
func main() {
var m map[string]int
fmt.Println(m)
}$ go run main.go
nil如果我们所见,map默认零值为nil。
nil字典没有键,任何尝试通过对nil字典使用键操作均会发生运行时错误(panic)。
也有好几种初始化字典的方式。
make 函数
我使用内建的make函数通过提供对应字典键值对类型来开辟内存作为底层数据结构。
func main() {
var m = make(map[string]int)
fmt.Println(m)
}$ go run main.go
map[]map 字面量
另一种方式是使用字典字面量。
func main() {
var m = map[string]int{
"a": 0,
"b": 1,
}
fmt.Println(m)
}注意最后面的逗号不能少
$ go run main.go
map[a:0 b:1]同样我们还可以字典中使用自定义类型:
type User struct {
Name string
}
func main() {
var m = map[string]User{
"a": User{"Peter"},
"b": User{"Seth"},
}
fmt.Println(m)
}设置上面还可以移除值类型,Go会自动推断!
var m = map[string]User{
"a": {"Peter"},
"b": {"Seth"},
}$ go run main.go
map[a:{Peter} b:{Seth}]让我们来看看如何在字典新增值。
func main() {
var m = map[string]User{
"a": {"Peter"},
"b": {"Seth"},
}
m["c"] = User{"Steve"}
fmt.Println(m)
}$ go run main.go
map[a:{Peter} b:{Seth} c:{Steve}]使用键从字典中获取到值。
...
c := m["c"]
fmt.Println("Key c:", c)$ go run main.go
key c: {Steve}如果我们获取的键在字典不存在会怎么样?
...
d := m["d"]
fmt.Println("Key d:", d)你可能猜到了,它将返回该字典值类型的零值。
$ go run main.go
Key c: {Steve}
Key d: {}当你通过键来获取值时,它同时会返回一个布尔值,如果该值为true说明键存在,否则false即不存在。
我们看看例子:
...
c, ok := m["c"]
fmt.Println("Key c:", c, ok)
d, ok := m["d"]
fmt.Println("Key d:", d, ok)$ go run main.go
Key c: {Steve} Present: true
Key d: {} Present: false我们通过给key重新赋值来更新该key的值。
...
m["a"] = "Roger"$ go run main.go
map[a:{Roger} b:{Seth} c:{Steve}]还可以使用内建的delete函数来删除键。
如下:
...
delete(m, "a")第一个参数是字典,第二个参数为要删除的键。
delete() 并不返回任何值,所以键不存在的话那旧啥也不会发生。
$ go run main.go
map[a:{Roger} c:{Steve}]同数组和切片一样,我们可以使用range来遍历字典。
package main
import "fmt"
func main() {
var m = map[string]User{
"a": {"Peter"},
"b": {"Seth"},
}
m["c"] = User{"Steve"}
for key, value := range m {
fmt.Println("Key: %s, Value: %v", key, value)
}
}$ go run main.go
Key: c, Value: {Steve}
Key: a, Value: {Peter}
Key: b, Value: {Seth}注意字典是一个无序集合,所以不能保证遍历每次都会以相同的顺序。
最后我们谈谈字典特性。
字典是引用类型,也就是当我们将字典赋于一个新变量时,它们两引用的底层数据结构是同一个。
因此,任何一方的改变都会影响到另一方。
package main
import "fmt"
type User struct {
Name string
}
func main() {
var m1 = map[string]User{
"a": {"Peter"},
"b": {"Seth"},
}
m2 := m1
m2["c"] = User{"Steve"}
fmt.Println(m1) // Output: map[a:{Peter} b:{Seth} c:{Steve}]
fmt.Println(m2) // Output: map[a:{Peter} b:{Seth} c:{Steve}]
}本章我们来聊聊接口。
Go中的接口是一个用来定义一系列方法签名的抽象类型。接口定义相同对象类型的行为。
这里行为概念我们后面会讨论
我们通过例子来尝试更好的理解。
一个接近真实的接口例子就是电源插座。想象我们需要连接不同的设备到电源插座。

我们尝试来实现它。我们使用的设备类型如下:
type mobile struct {
brand string
}
type laptop struct {
cpu string
}
type toaster struct {
amount int
}
type kettle struct {
quantity string
}
type socket struct{}我们定一个Draw方法到类型上,比如mobile将输出类型的属性。
func (m mobile) Draw(power int) {
fmt.Printf("%T -> brand: %s, power: %d", m, m.brand, power)
}我定义Plug方法到socket类型上,它接收一个mobile类型作为第一个参数。
func (socket) Plug(device mobile, power int) {
device.Draw(power)
}我们尝试在main函数 "插入" 我们的mobile类型到socket类型里 。
package main
import "fmt"
func main() {
m := mobile{"Apple"}
s := socket{}
s.Plug(m, 10)
}执行该代码,我们将得到如下结果。
$ go run main.go
main.mobile -> brand: Apple, power: 10很好,那如果我们需要连接我们的laptop类型呢?
package main
import "fmt"
func main() {
m := mobile{"Apple"}
l := laptop{"Intel i9"}
s := socket{}
s.Plug(m, 10)
s.Plug(l, 50) // Error: cannot use l as mobile value in argument
}正如所看到的,这里抛出了一个错误。
咋搞?定义一个新方法?例如 PlugLaptop?
当然可以,不过每次新增类型都要新增对应方法到socket类型的话就太不理想了。
我们可以通过简单定义一个PowerDrawer的接口,并且在Plug函数中接收任何满足该接口标准,就是必须实现接口定义的Draw签名方法。
socket也不需要知道任何关于device的信息,仅仅需要调用其Draw方法。
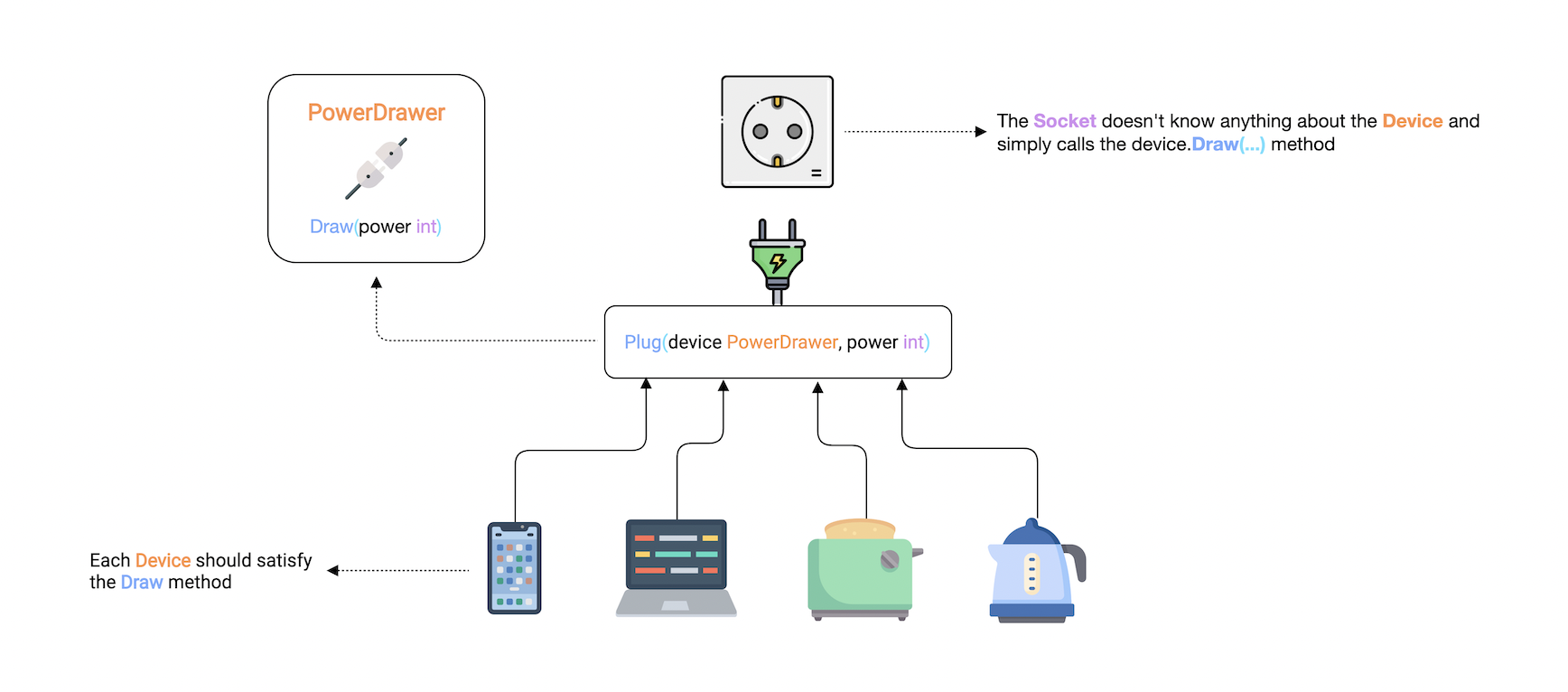
现在,让我们尝试实现PowerDrawer接口,它看起来类似如下:
按照约定使用 "-er" 作为名字的后缀。早期我们还有提及,一个接口仅需描述其 期望行为, 比如咱们例子里的 Draw 方法。
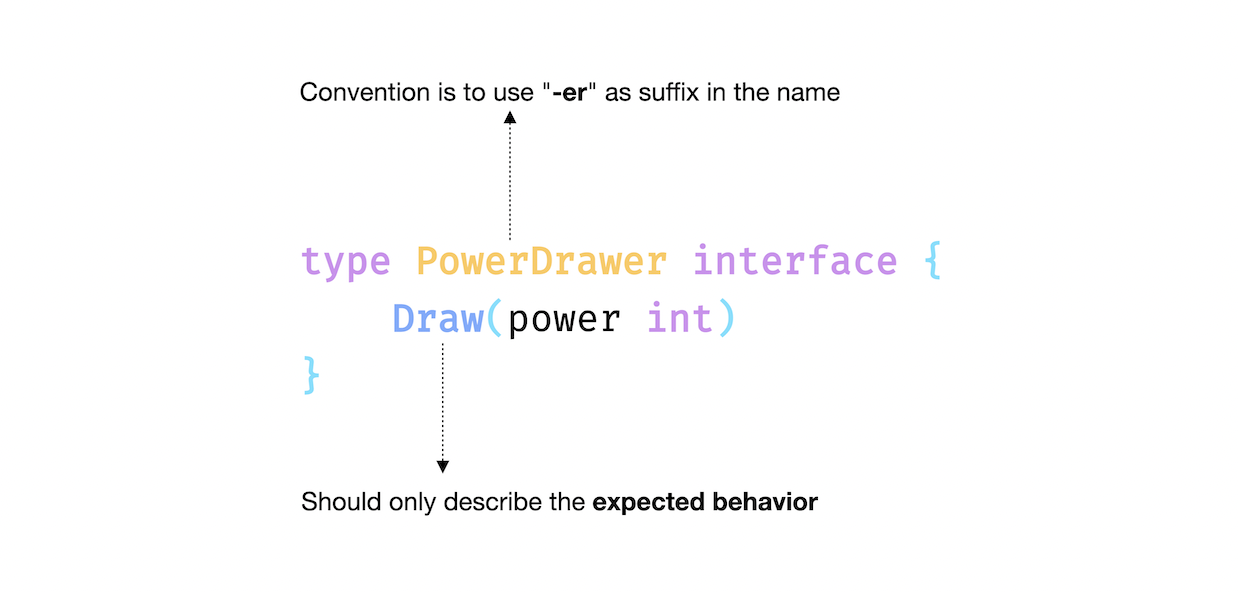
type PowerDrawer interface {
Draw(power int)
}现在,我们需要更新Plug方法,将PowerDrawer接口类型作为其接收参数。
func (socket) Plug(device PowerDrawer, power int) {
device.Draw(power)
}为满足接口,我们需要为各个device类型添加Draw方法。
type mobile struct {
brand string
}
func (m mobile) Draw(power int) {
fmt.Printf("%T -> brand: %s, power: %d\n", m, m.brand, power)
}
type laptop struct {
cpu string
}
func (l laptop) Draw(power int) {
fmt.Printf("%T -> cpu: %s, power: %d\n", l, l.cpu, power)
}
type toaster struct {
amount int
}
func (t toaster) Draw(power int) {
fmt.Printf("%T -> amount: %d, power: %d\n", t, t.amount, power)
}
type kettle struct {
quantity string
}
func (k kettle) Draw(power int) {
fmt.Printf("%T -> quantity: %s, power: %d\n", k, k.quantity, power)
}现在,在接口的帮助下实现了所有devices均可连接socket!
func main() {
m := mobile{"Apple"}
l := laptop{"Intel i9"}
t := toaster{4}
k := kettle{"50%"}
s := socket{}
s.Plug(m, 10)
s.Plug(l, 50)
s.Plug(t, 30)
s.Plug(k, 25)
}正常工作。
$ go run main.go
main.mobile -> brand: Apple, power: 10
main.laptop -> cpu: Intel i9, power: 50
main.toaster -> amount: 4, power: 30
main.kettle -> quantity: Half Empty, power: 25为什么需要它?
接口帮助我们解耦类型。例如,有了接口,我们不需要更新socket的实现。我们只需要给新的device定义Draw方法。
和其它语言不同,Go接口使用隐式实现,不需要额外使用implements关键字。也就是说当一个类型满足接口所有方法那么它即符合该接口。
空接口可以接收任意类型的值。
var x interface{}为什么需要它
空接口通常用来接收未知类型。
例如:
- 从API获取复杂的数据。
- 接口未知参数值,例如
fmt.Println函数。
在使用了空interface{},我们可以使用 类型断言(type assertion) 或者 类型切换(type switch) 来确定值类型。
类型断言 提供了访问底层数据的能力。
For example:
func main() {
var i interface{} = "hello"
s := i.(string)
fmt.Println(s)
}该语句推断其接口确切的类型,然后将该值赋于变量。
我们还可以测试某个接口值是否为指定类型。
类型断言返回两个值:
- 第一个为际值。
- 第二个为布尔值,标识断言是否成功。
s, ok := i.(string)
fmt.Println(s, ok)它能帮助我们测试接口是否保存的是所指定的类型。
它和从字典获取值方式类似。
如果类型失败,ok将返回为false,值类型会被赋值为该推断类型的零值,并不会发生panic。
f, ok := i.(float64)
fmt.Println(f, ok)但是如果没有接收该布尔值,推断语句就会触发panic。
f = i.(float64)
fmt.Println(f) // Panic!$ go run main.go
hello
hello true
0 false
panic: interface conversion: interface {} is string, not float64使用 switch 语句可以用来匹配空 interface{}实际值类型。
var t interface{}
t = "hello"
switch t := t.(type) {
case string:
fmt.Printf("string: %s\n", t)
case bool:
fmt.Printf("boolean: %v\n", t)
case int:
fmt.Printf("integer: %d\n", t)
default:
fmt.Printf("unexpected: %T\n", t)
}运行该代码,我们确认了该空接口为string类型。
$ go run main.go
string: hello我们看看接口的特性
零值
接口的零值为nil。
package main
import "fmt"
type MyInterface interface {
Method()
}
func main() {
var i MyInterface
fmt.Println(i) // Output: <nil>
}嵌入
我们可以像结构体那样嵌入接口。
For example
type interface1 interface {
Method1()
}
type interface2 interface {
Method2()
}
type interface3 interface {
interface1
interface2
}值可比较
接口可比较。
package main
import "fmt"
type MyInterface interface {
Method()
}
type MyType struct{}
func (MyType) Method() {}
func main() {
t := MyType{}
var i MyInterface = MyType{}
fmt.Println(t == i)
}Interface Values
在底层,我们可以认接口是由一个值和其类型的所构成的元素。
package main
import "fmt"
type MyInterface interface {
Method()
}
type MyType struct {
property int
}
func (MyType) Method() {}
func main() {
var i MyInterface
i = MyType{10}
fmt.Printf("(%v, %T)\n", i, i) // Output: ({10}, main.MyType)
}这样我即描述Go接口涵盖内容了。
它是一个强大的特性,但是记住 "Bigger the interface, the weaker the abstraction(接口越大,抽象越弱)" - Rob Pike。
本章我们聊聊错误处理。
注意我说的是错误而非异常,因为Go就没有异常处理。
而其是通过返回一个内建error接口类型来替代。
type error interface {
Error() string
}等下我们很快在绕回来,先来理解一些基础。
我们来编写一个Divide函数,该函数返回a除以b的结果。
func Divide(a, b int) int {
return a/b
}很好,我们通过返回错误来阻止0作为被除数的情况,这就引出了错误构造。
有多种方式,我们来看最常用的几种。
首先使用errors包提供的New函数。
package main
import "errors"
func main() {}
func Divide(a, b int) (int, error) {
if b == 0 {
return 0, errors.New("cannot divide by zero")
}
return a/b, nil
}注意,我们是如何返回error结果的。如果没有错误我们使用nil来作为返回值,因为其是个接口类型,而nil是它的零值。
那我们如何处理呢?先让我们在main函数来执行Divide函数。
But how do we handle it? So, for that, let's call the Divide function in our main function.
package main
import (
"errors"
"fmt"
)
func main() {
result, err := Divide(4, 0)
if err != nil {
fmt.Println(err)
// Do something with the error
return
}
fmt.Println(result)
// Use the result
}
func Divide(a, b int) (int, error) {...}$ go run main.go
cannot divide by zero这里我们通过检查err变量是否为nil来推断是否错误发生,这种方式是Go里惯法。
另一个构造错误的方式使用fmt.Errorf函数。
该函数和fmt.Sprintf相似,允许我们对信息进行格式化操作, 只不过实际返回的是error类型而非string。
它通常用来为我们错误信息附加上下文信息。
...
func Divide(a, b int) (int, error) {
if b == 0 {
return 0, fmt.Errorf("cannot divide %d by zero", a)
}
return a/b, nil
}输出类似如下结果:
$ go run main.go
cannot divide 4 by zero通过预定义错误以便在其它部分代码可以用来做错误检查,称之为错误哨兵。
package main
import (
"errors"
"fmt"
)
var ErrDivideByZero = errors.New("cannot divide by zero")
func main() {...}
func Divide(a, b int) (int, error) {
if b == 0 {
return 0, ErrDivideByZero
}
return a/b, nil
}Go中约定给哨兵错误使用Err前缀命名,例如ErrNotFound。
关键点?
这在通过返回不同错误执行不同代码分支情况下很有用。
例如,我们可以通过errors.Is函数来判断具体错误类型。
package main
import (
"errors"
"fmt"
)
func main() {
result, err := Divide(4, 0)
if err != nil {
switch {
case errors.Is(err, ErrDivideByZero):
fmt.Println(err)
// 错误发生后做一些其它操作
default:
fmt.Println("no idea!")
}
return
}
fmt.Println(result)
// 使用result
}
func Divide(a, b int) (int, error) {...}$ go run main.go
cannot divide by zero目前为止,错误构造涵盖了太多数场景。不过有时我们需要在错误里添加附加功能。
前面我们有说到error仅是个接口。基本上,任何实现了Error()方法返回一个错误消息的类型均可作为error。
我们来自定义DivisionError结构体并包含错误代码和消息。
package main
import (
"errors"
"fmt"
)
type DivisionError struct {
Code int
Msg string
}
func (d DivisionError) Error() string {
return fmt.Sprintf("code %d: %s", d.Code, d.Msg)
}
func main() {...}
func Divide(a, b int) (int, error) {
if b == 0 {
return 0, DivisionError{
Code: 2000,
Msg: "cannot divide by zero",
}
}
return a/b, nil
}这里,我们使用errors.As而不是errors.Is函数将error转换为正确类型。
func main() {
result, err := Divide(4, 0)
if err != nil {
var divErr DivisionError
switch {
case errors.As(err, &divErr):
fmt.Println(divErr)
// 错误发生后执行操作
default:
fmt.Println("no idea!")
}
return
}
fmt.Println(result)
// 使用result
}
func Divide(a, b int) (int, error) {...}$ go run man.go
code 2000: cannot divide by zero那么 errors.Is 和 errors.As不同?
Is仅检测是否为对应错误类型,而As会转换为丢应类型,这样才能实际去访问其内部属性。
类型断言也可以同样实现,不过不太建议!
func main() {
result, err := Divide(4, 0)
if e, ok := err.(DivisionError); ok {
fmt.Println(e.Code, e.Msg) // Output: 2000 cannot divide by zero
return
}
fmt.Println(result)
}最后,我想说的是Go在错误处理方面和其它传统的try/catch式编程语言走了一条不同的路径。不过这是它鼓励程序员显示错误处理,并且还提高了可读性。
前面,我们介绍了Go使用errors机制来处理错误机制的习惯用法。错误满足大部分场景,不过有时在某些情况程序将无法继续执行。
该场景,我们使用内建的panic函数
func panic(interface{})panic是内建的函数用来组织当前goroutine执行。当函数执行panic,当前函数将立即停止执行,并将控制权交换给调用方,这个动作将重复执行直到退出(伴随panic消息和堆栈追踪信息)
注意:我们在后面课程再讨论goroutines.
让我们来看看如何使用panic函数。
package main
func main() {
WillPanic()
}
func WillPanic() {
panic("Woah")
}执行后,我们在输出中看到panic信息。
$ go run main.go
panic: Woah
goroutine 1 [running]:
main.WillPanic(...)
.../main.go:8
main.main()
.../main.go:4 +0x38
exit status 2如预期,我们程序打印了panic消息,并且还带有堆栈信息,然后旧终止。
问题在于如果一个未预料的panic发生我们该怎么办?
我们可以通过使用defer关键执行内建recover函数重新将发生了panic应用获取控制权。
func recover() interface{}我们来创建一个HandlePanic函数,然后使用defer。
package main
import "fmt"
func main() {
WillPanic()
}
func handlePanic() {
data := recover()
fmt.Println("Recovered:", data)
}
func WillPanic() {
defer handlePanic()
// or defer func() { fmt.Println("Recovered:", data) }()
panic("Woah")
}$ go run main.go
Recovered: Woah正如所见,我们应用程序得到了恢复并继续执行了。
最后我要提及的是panic和recover可以考虑类似其它语言的try/catch机制。但是我们应该避免在程序使用panic和recover而是尽可能使用errors。
那么什么时候使用panic?
两个使用panic的场景:
- 无法恢复的error
当应用遇到某个场景以致没法再继续执行。
例如,启动应用时高度依赖某个配置文件,那如果这个配置文件不存在那程序只能停止执行。
- 开发的error
这个是常见场景,例如,解nil指针引用将引发panic。
本章,我们聊聊Go中的测试。从一个简单的例子开始。
我们创建一个math包,它包含一个Add函数,返回其两个整型做加法运算的结果。
package math
func Add(a, b int) int {
return a + b
}在main包中如下使用:
package main
import (
"example/math"
"fmt"
)
func main() {
result := math.Add(2, 2)
fmt.Println(result)
}执行我们将得到其结果。
$ go run main.go
4现在,我们来对我们的Add函数编写测试。在Go,使用_test后缀文件名来对应测试。所以我们的add.go对应为add_test.go。我们的项目结构类似如下:
.
├── go.mod
├── main.go
└── math
├── add.go
└── add_test.go我们命名包为math_test,导入标准库的testing包。是的,Go内建测试库,这点和其它编程语言不一样。
但是为什么要用math_test命名包,而不是简单使用math包?
是的,当然可以,不过我个人喜欢通过分开包名解耦来编写测试。
现在让我们来创建TestAdd函数。它接收一个testing.T参数,该参数提供了拥有的辅助方法。
package math_test
import "testing"
func TestAdd(t *testing.T) {}在添加测试逻辑之前,先尝试来执行它。这个时候我们不能使用go run命令,而是go test命令。
$ go test ./math
ok example/math 0.429s这里我们传入了math包路径,我们也可以使用相对路径./..来测试所有的包。
$ go test ./...
? example [no test files]
ok example/math 0.348s如果Go没有找到任何需要测试的包,它将会告知我们。
很好,让我们编写代码。我们通过检查返回的值,如果与预期值不匹配执行t.Fail方法来让测试失败。
package math_test
import "testing"
func TestAdd(t *testing.T) {
got := math.Add(1, 1)
expected := 2
if got != expected {
t.Fail()
}
}真棒,我们测试通过了!
$ go test math
ok example/math 0.412s我们来看看如果测试失败结果是怎么样的,我们仅仅修改我们期望值。
package math_test
import "testing"
func TestAdd(t *testing.T) {
got := math.Add(1, 1)
expected := 3
if got != expected {
t.Fail()
}
}$ go test ./math
ok example/math (cached)如果你看到结果如上。为了优化,我们测试缓存了。可以使用go clean命令清理缓存然后重新执行测试。
$ go clean -testcache
$ go test ./math
--- FAIL: TestAdd (0.00s)
FAIL
FAIL example/math 0.354s
FAIL以上就是测试失败的结果
这就引出了测试驱动开发。那它是什么呢?
我们有函数参数和期望变量来对比确保测试通过。那如果我们有一个切片包含一系列值的话,这就可以让我们的测试足够灵活,可以帮助我们测试多个例子。
别急,我们通过例子来学习。我们先定义一个addTestCase结构体。
package math_test
import (
"example/math"
"testing"
)
type addTestCase struct {
a, b, expected int
}
var testCases = []addTestCase{
{1, 1, 3},
{25, 25, 50},
{2, 1, 3},
{1, 10, 11},
}
func TestAdd(t *testing.T) {
for _, tc := range testCases {
got := math.Add(tc.a, tc.b)
if got != tc.expected {
t.Errorf("Expected %d but got %d", tc.expected, got)
}
}
}注意,我们定义小写字母开头的addTestCase变量。因为它没有必要作为导出变量。让我们执行我们的测试。
$ go run main.go
--- FAIL: TestAdd (0.00s)
add_test.go:25: Expected 3 but got 2
FAIL
FAIL example/math 0.334s
FAIL视乎咱们的测试失败了,让我们来修复它。
var testCases = []addTestCase{
{1, 1, 2},
{25, 25, 50},
{2, 1, 3},
{1, 10, 11},
}完美,正常了!
$ go run main.go
ok example/math 0.589s最后我们来聊聊,代码覆盖率。当编写测试时,通常我们需要有个测试涵盖的指标。通常指的就是测试覆盖率。
要计算测试所涵盖的覆盖率,仅需要在测试时指定-coverprofile参数。
$ go test ./math -coverprofile=coverage.out
ok example/math 0.385s coverage: 100.0% of statements看起来我们覆盖率很好。让我们使用go tool cover命令来查看详细报告。
$ go tool cover -html=coverage.out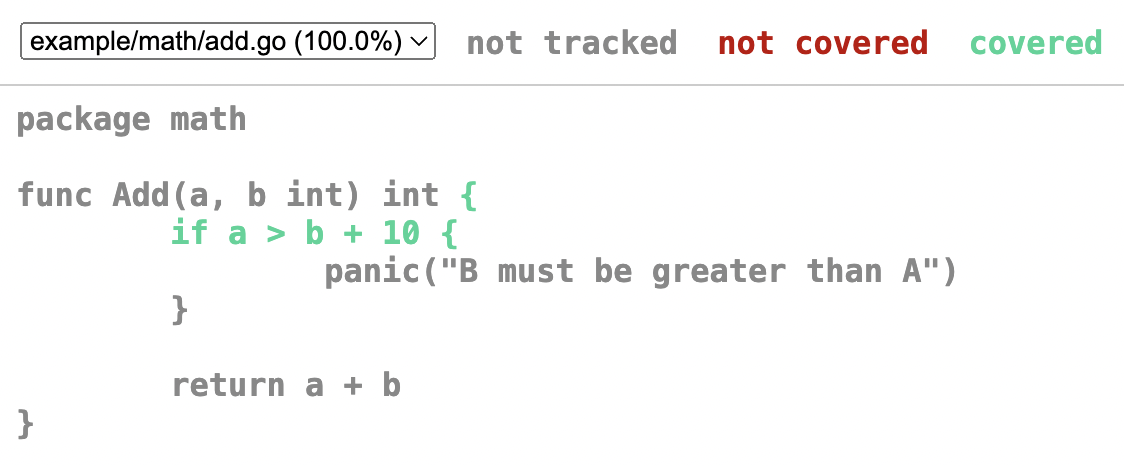
你看这里的格式具有很好的可读性。最重要的是,它内置于标准工具中。
最后,我们来看看首次出现在 Go 1.18的(fuzz testing)模糊测试。
Fuzzing是通过持续生成数据来执行自动化测试。
Go模糊测试通过覆盖指引来智能化遍历代码执行模糊测试。
由于它可以触达用户经常遗漏的边缘情况,模糊测试对于发现错误和安全具备较高价值。
让我们看看例子:
func FuzzTestAdd(f *testing.F) {
f.Fuzz(func(t *testing.T, a, b int) {
math.Add(a , b)
})
}如果我们执行它, 我们将看到它自动创建测试案例,因为我们的Add函数非常简单,它将通过测试。
$ go test -fuzz FuzzTestAdd example/math
fuzz: elapsed: 0s, gathering baseline coverage: 0/192 completed
fuzz: elapsed: 0s, gathering baseline coverage: 192/192 completed, now fuzzing with 8 workers
fuzz: elapsed: 3s, execs: 325017 (108336/sec), new interesting: 11 (total: 202)
fuzz: elapsed: 6s, execs: 680218 (118402/sec), new interesting: 12 (total: 203)
fuzz: elapsed: 9s, execs: 1039901 (119895/sec), new interesting: 19 (total: 210)
fuzz: elapsed: 12s, execs: 1386684 (115594/sec), new interesting: 21 (total: 212)
PASS
ok foo 12.692s如果我们更新更新Add函数来随机触发一个边缘情况,例如当b + 10大于a时引发panic。
func Add(a, b int) int {
if a > b + 10 {
panic("B must be greater than A")
}
return a + b
}如果我们重新执行测试,该边缘情况会被模糊测试发觉。
$ go test -fuzz FuzzTestAdd example/math
warning: starting with empty corpus
fuzz: elapsed: 0s, execs: 0 (0/sec), new interesting: 0 (total: 0)
fuzz: elapsed: 0s, execs: 1 (25/sec), new interesting: 0 (total: 0)
--- FAIL: FuzzTestAdd (0.04s)
--- FAIL: FuzzTestAdd (0.00s)
testing.go:1349: panic: B is greater than A我个人认为这时Go 1.18很棒的特性。你可以通过查看官方博客对于模糊测试的描述。
本章,我们来学习泛型,它首次出现于 Go 1.18版本,是最为期待的一个特性。
泛型意味着参数化类型。简单来说,泛型允许程序员延后确定类型。
我们通过例子来理解。
例如,我们有个针对不同类型如int,float64和string计算总和的函数。由于Go不支持方法覆写,通常我需要定义多个函数来处理。
package main
import "fmt"
func sumInt(a, b int) int {
return a + b
}
func sumFloat(a, b float64) float64 {
return a + b
}
func sumString(a, b string) string {
return a + b
}
func main() {
fmt.Println(sumInt(1, 2))
fmt.Println(sumFloat(4.0, 2.0))
fmt.Println(sumString("a", "b"))
}就如上所示,除了类型不同,函数基本上是一样的。
我们看看如何定义泛型函数。
func fnName[T constraint]() {
...
}这里T为我们的类型参数constraint是限定实现该接口的类型。
是不是有点晕,我们来试着构建sum泛型函数。
这里,我们使用T作为类型参数,并且协定interface{}为类型约束。
func sum[T interface{}](a, b T) T {
fmt.Println(a, b)
}Go 1.18可以使用any来代替空接口。
func sum[T any](a, b T) T {
fmt.Println(a, b)
}有了类型参数,我们就需要实际执行时传递所需要的类型,使得代码显得更冗长。
sum[int](1, 2) // explicit type argument
sum[float64](4.0, 2.0)
sum[string]("a", "b")幸运的是 Go 1.18具备类型推断能力使得我们在执行期间不需要指明类型。
sum(1, 2)
sum(4.0, 2.0)
sum("a", "b")让我们来执行看看是否正常工作
$ go run main.go
1 2
4 2
a b现在,让我们更新sum函数对我们变量执行加法运算。
func sum[T any](a, b T) T {
return a + b
}fmt.Println(sum(1, 2))
fmt.Println(sum(4.0, 2.0))
fmt.Println(sum("a", "b"))当我们执行时却得到了:operator + is not defined in the constraint。
$ go run main.go
./main.go:6:9: invalid operation: operator + not defined on a (variable of type T constrained by any)当使用any类型约束时,通常不支持操作符。
让我们使用接口来实现自定义约束。我们接口需要定义类型集合包含int,float和string。
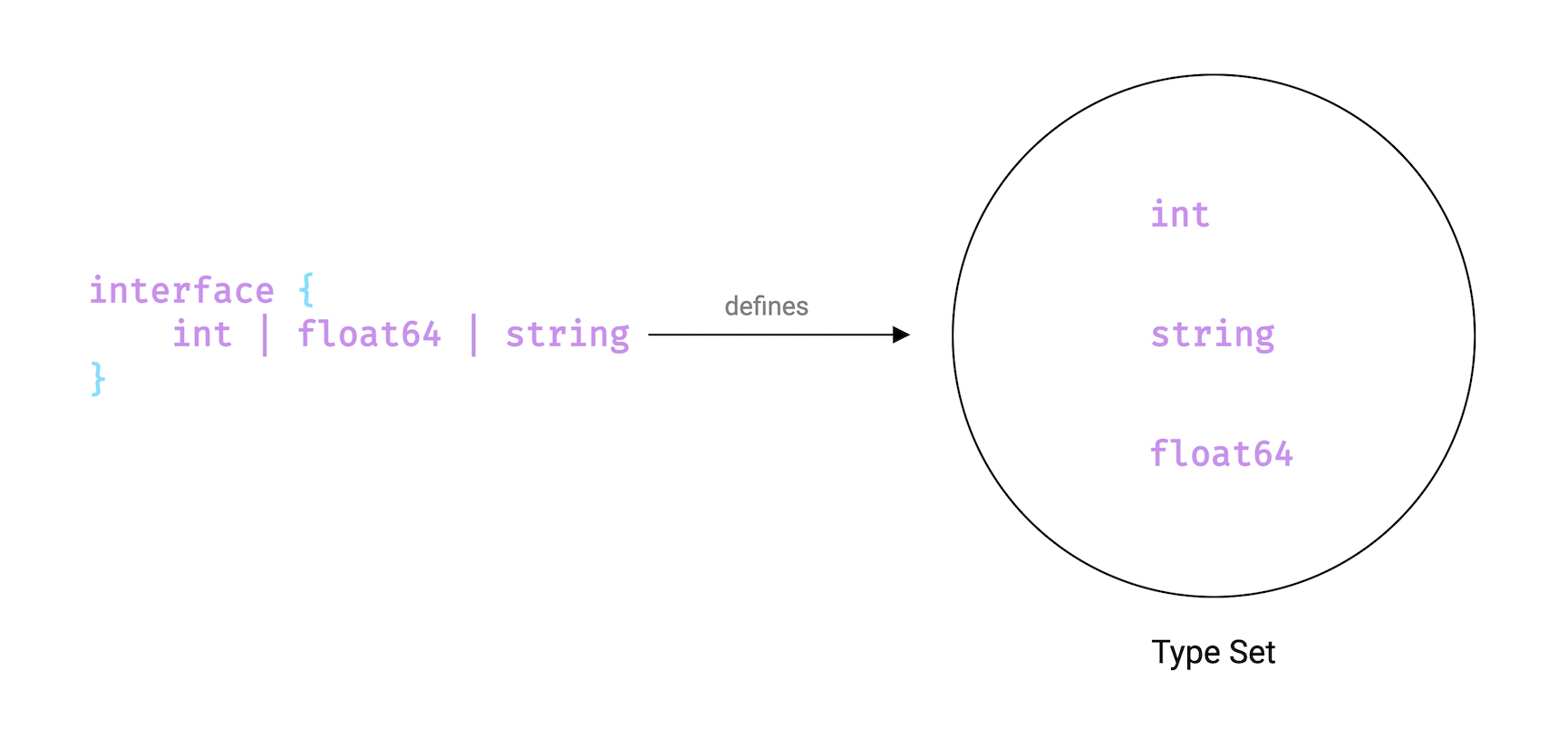
SumConstraint接口类似如下:
type SumConstraint interface {
int | float64 | string
}
func sum[T SumConstraint](a, b T) T {
return a + b
}
func main() {
fmt.Println(sum(1, 2))
fmt.Println(sum(4.0, 2.0))
fmt.Println(sum("a", "b"))
}这样就正常工作了。
$ go run main.go
3
6
abconstraints包预定义了一些作用类型参数的常用约束。
type Signed interface {
~int | ~int8 | ~int16 | ~int32 | ~int64
}
type Unsigned interface {
~uint | ~uint8 | ~uint16 | ~uint32 | ~uint64 | ~uintptr
}
type Integer interface {
Signed | Unsigned
}
type Float interface {
~float32 | ~float64
}
type Complex interface {
~complex64 | ~complex128
}
type Ordered interface {
Integer | Float | ~string
}要使用它我们需要安装constraints包。
$ go get golang.org/x/exp/constraints
go: added golang.org/x/exp v0.0.0-20220414153411-bcd21879b8fdimport (
"fmt"
"golang.org/x/exp/constraints"
)
func sum[T constraints.Ordered](a, b T) T {
return a + b
}
func main() {
fmt.Println(sum(1, 2))
fmt.Println(sum(4.0, 2.0))
fmt.Println(sum("a", "b"))
}这里我们使用了 Ordered 约束。
type Ordered interface {
Integer | Float | ~string
}~是Go新增的符号,~string代码所有底层数据类型是string。
同样正常工作
$ go run main.go
3
6
ab泛型是一个惊人特性,它允许构建抽象的函数避免在某些情况下编写重复代码。
所以,什么时候使用泛型?考虑在如下场景下:
- 函数操作数组,切片,字典还有通道。
- 通用数据结构,如栈和链表。
- 减少代码重复。
泛型作为语言附加能力,我们应该少量的使用它。建议只有在编写重复代码2到3次时考虑使用泛型。
本课程我们来学习Go最强大的特性之一并发。
我们先来一探究竟,啥是 "并发" ?
并发,根据其定义,允许将计算机程序或者算法分解为独立部分,并且独立执行。
并发执行结果与顺序执行结果相同。
使用并发我们在完成一件事情时用更少的时间,从而提高程序整体性能和效率。
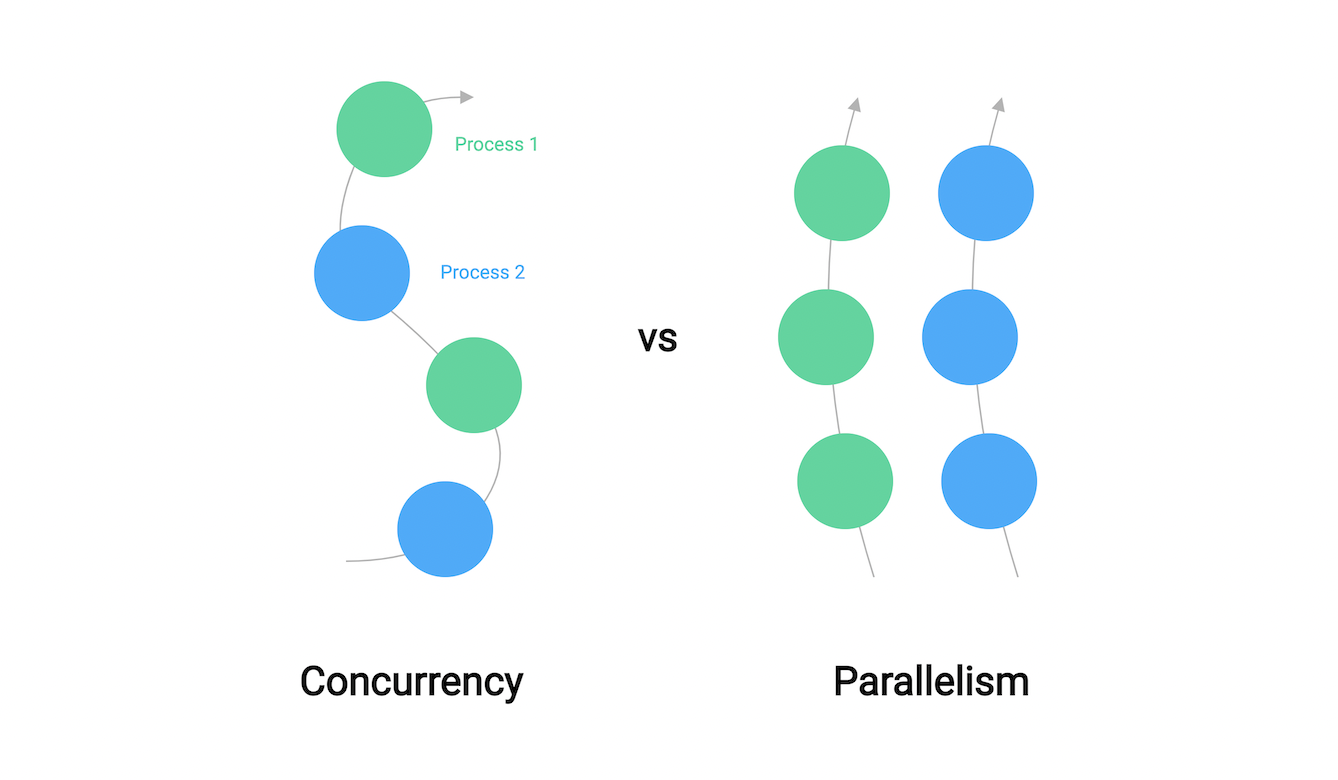
很多人对于并发和并行会混淆,因为它们某种程序上都是同时执行代码,但却概念上完全不同。
并发是同时在多个不同计算任务去做事,而并行同时去做多个计算任务。
Rob Pike对此有个完美诠释:
"并发用于在同时处理很多事件,而并行是同时做很多事件"
但Go并发不仅仅是一个语法,为了来理解Go这强大特性,我们需要理解Go是如何并发执行代码的。Go依赖一个称为CSP(Communicating Sequential Processes)并发模型。
通信顺序进程 (CSP) 是由Tony Hoare提出用来描述并发进行交互的模型。它对计算机科学领域产生了较大突破,尤其是在并发领域。
类似Go和Erlang语句都借鉴了通信顺序进程(CSP)概念。
并发实现是复杂的,但是CSP给我们的并发提供更好的结构,以便大伙使用更简单的方式来实现并发。它主张进程使用通道来通信。
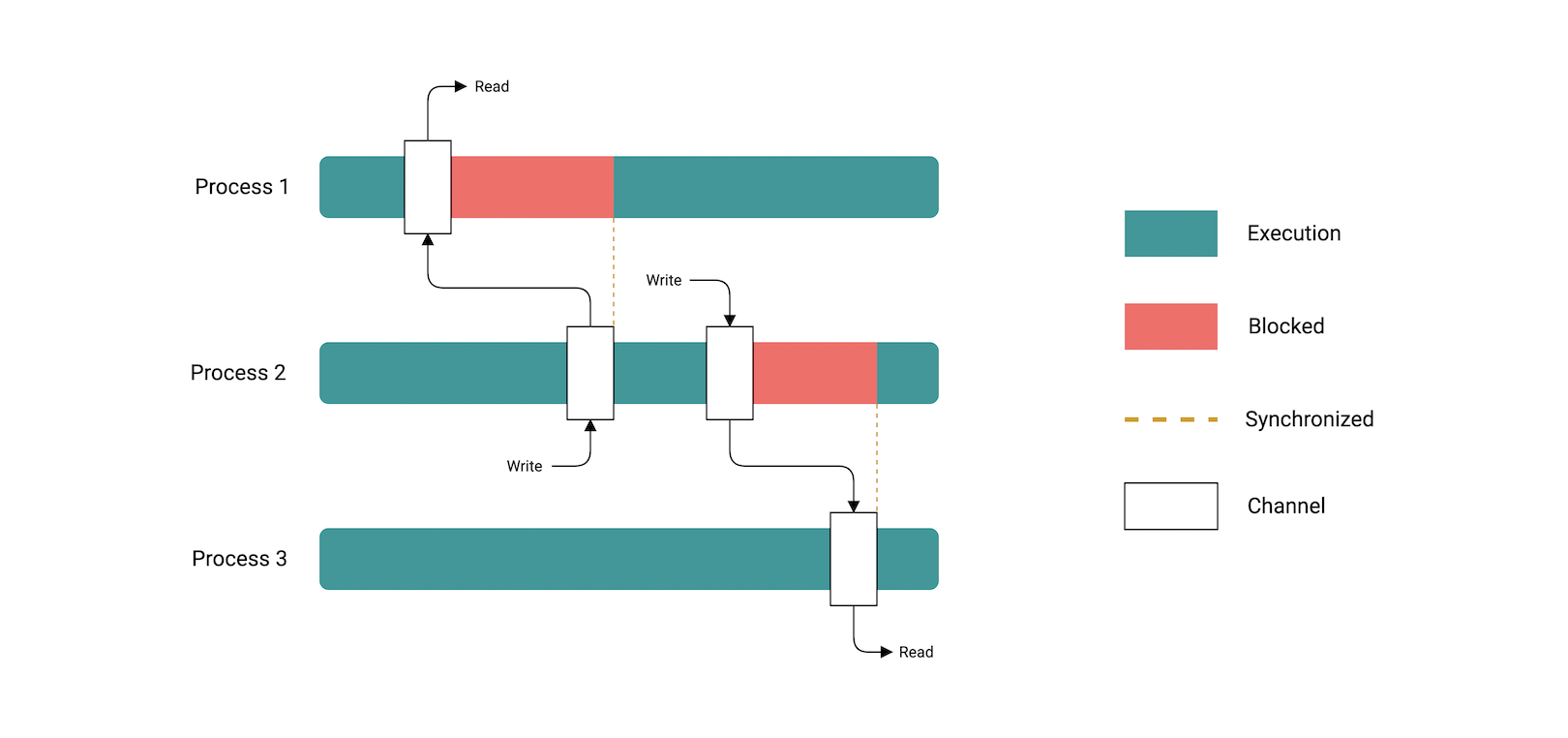
我们后面会讨论Go如何使用goroutine和通道来实现它。
我们来熟悉一些并发基本概念
当进程并发访问相同资源时产生数据竞争。
例如一个进程在读某个资源时,另一个进程同时在写入该资源。
当事件的时间或者顺序会影响代码的正确时我们就说发生了竞争条件。
当所有进程因为相互在等待其对方释放某个资源而挂起时我们就说发生死锁。
科夫曼条件
有四种条件,称之为科夫曼条件,必须满足所有条件才会发生死锁。
- 互斥
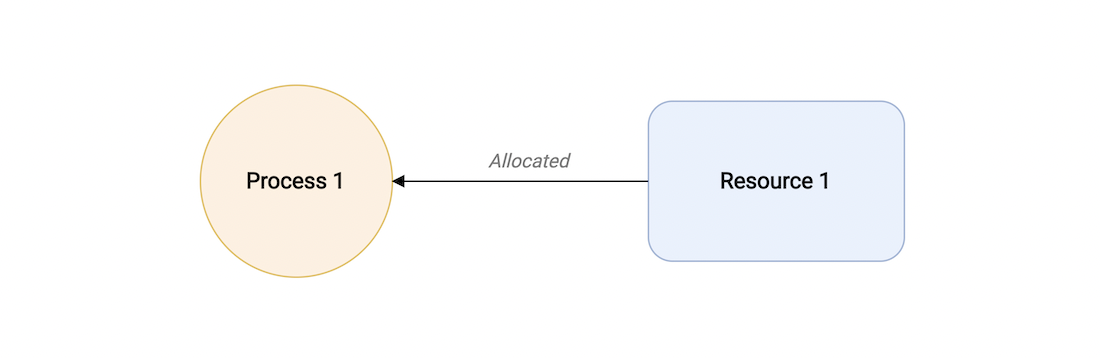
一个并发进程持有至少一个资源,并且是non-sharable(不可分享)。 A concurrent process holds at least one resource at any one time making it non-sharable.
如何图示,有一个进程1持有单个资源1
- 等待
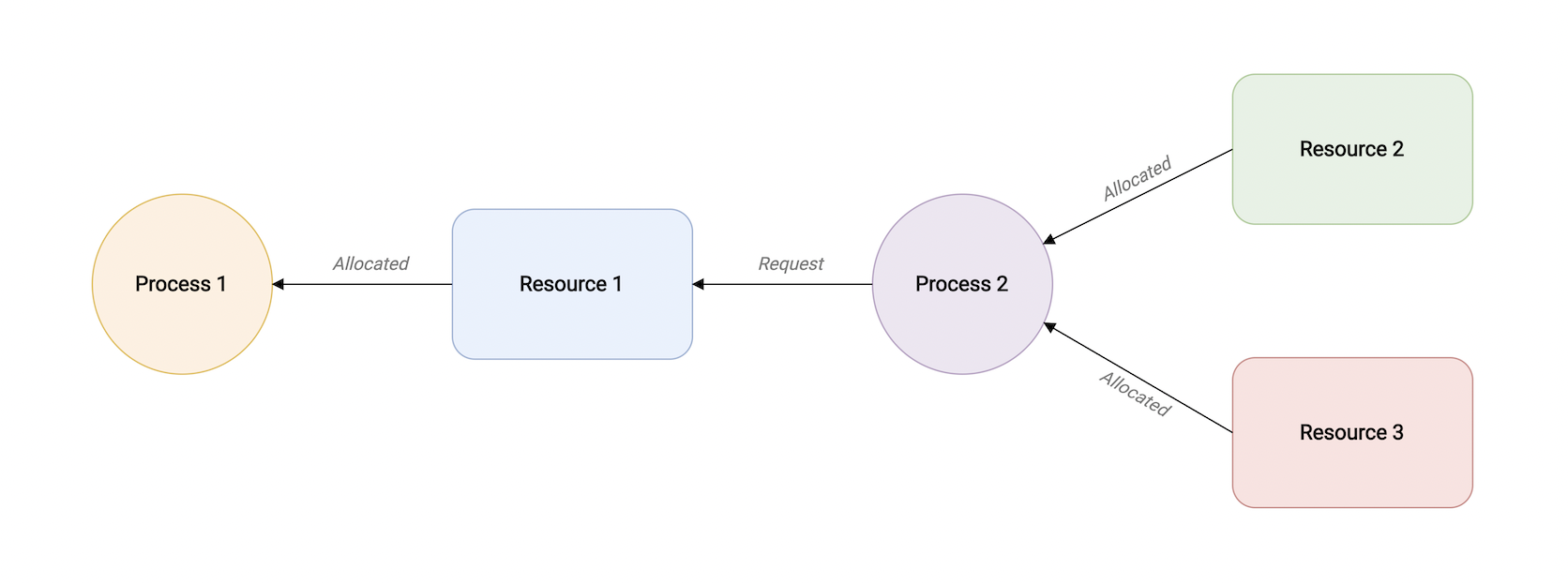
一个并发进程持有一个资源且等待另一个资源。
下面图示,进程2持有资源2和资源3,并且尝试请求被进程1持有的资源1.
- 无抢占
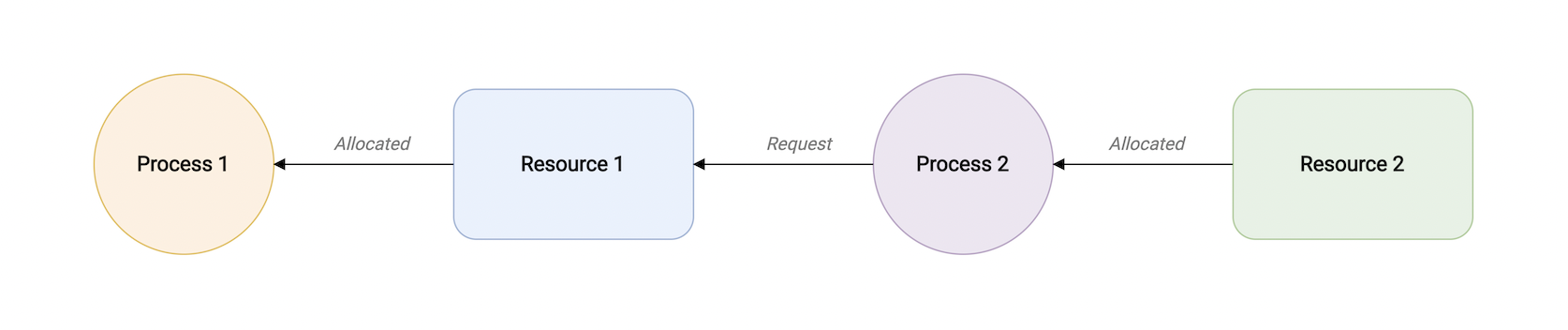
一个资源被一个并发进程持有时不能被系统抢占,只有当它自己释放时才可以被其它进程持有。
如下图示,进程2不能从进程1抢占资源1.只有当进程1z执行完成后自愿放弃资源1时才可以获得。.
- 环型等待
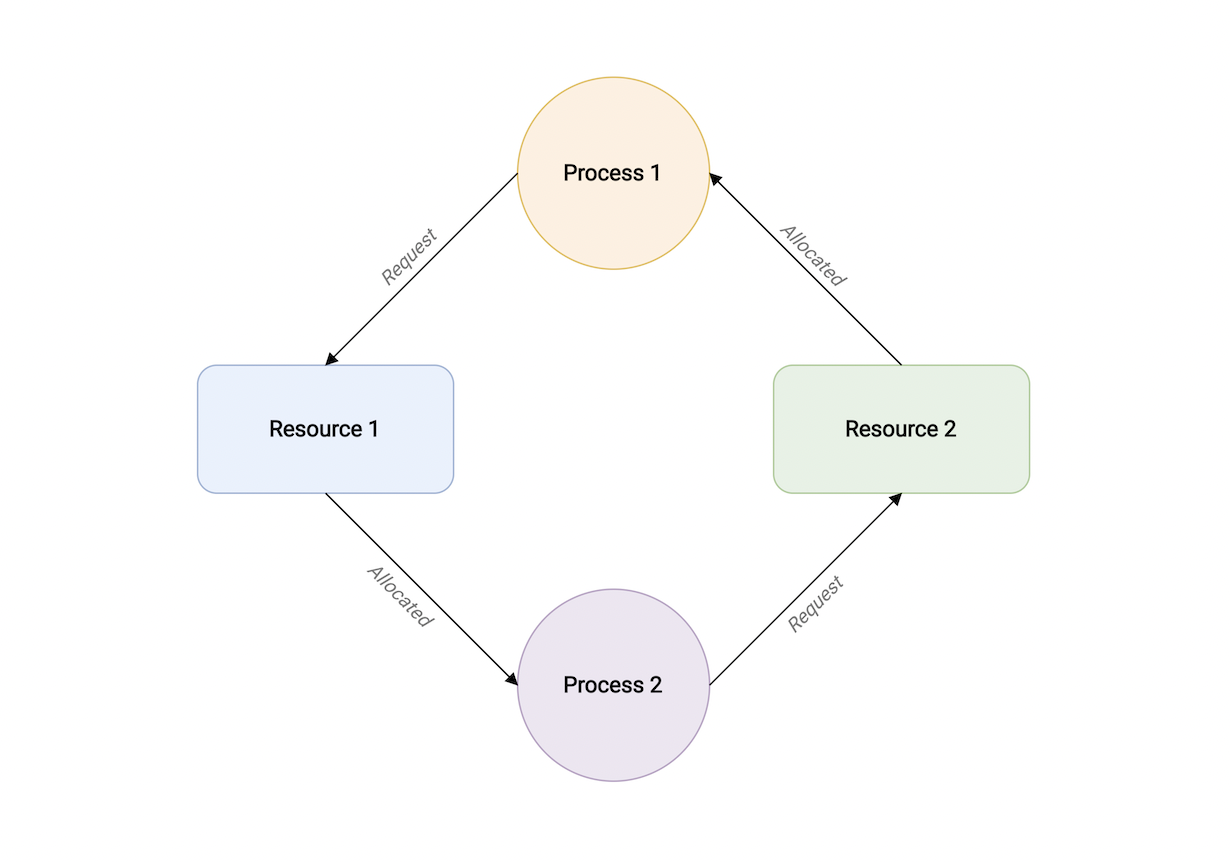
一个进程等待另一个进程资源,而另一个进程又在等待第三个进程的资源。等等,最后进程又在等待第一个进程资源,这样形成了一个环型链。
如下图示,进程1持有资源2请求资源1,同时进程2持有资源1请求资源2。这样形成了环形等待。
活锁是进程积极执行并发操作(你让我我让你),但是对于推动程序进行没有任何帮助。
当进程所需资源被其它进程抢占以致无法继续执行,我们就说发生了饥饿。
饥饿可发生在死锁,或者低效的调度算法。为了解决饥饿,我们需要一个更好资源分配算法,让每个进程都可以公平得获取到资源。
本课程我们来学习Goroutines
在学习之前,我想给大伙分享Go箴言。
"不要通过共享内存来通信,而是通过通信来共享内存。" - Rob Pike
_goroutine_是一个轻量级线程,由Go运行时管理,以便能够以同步的方式来编写异步代码。
需要知道的是实际执行goroutine时并没有实际开辟系统线程,且main函数自身也是一个goroutine。
但线程可能执行上千个goroutine,由Go运行时使用合作调度方式(cooperative scheduling)来进行调度。也就是说当一个goroutine挂起了或者完成了,调度器将其它goroutine调度到其它系统线程中执行。该高效调度方式使得不会有使得routine处于完全挂起状态。
我们可以通过使用go关键字来将一个函数转换为goroutine。
go fn(x, y, z)在编写代码之前,有必要先来讨论一下fork-join模型。
Go在goroutine被后使用fork-join模型。fork-join模型是一个将父进程分解为多个子进程且与父进程并发之前。在执行完成后,进程将结果合并到父进程中。合并这个点我们称为join pont。
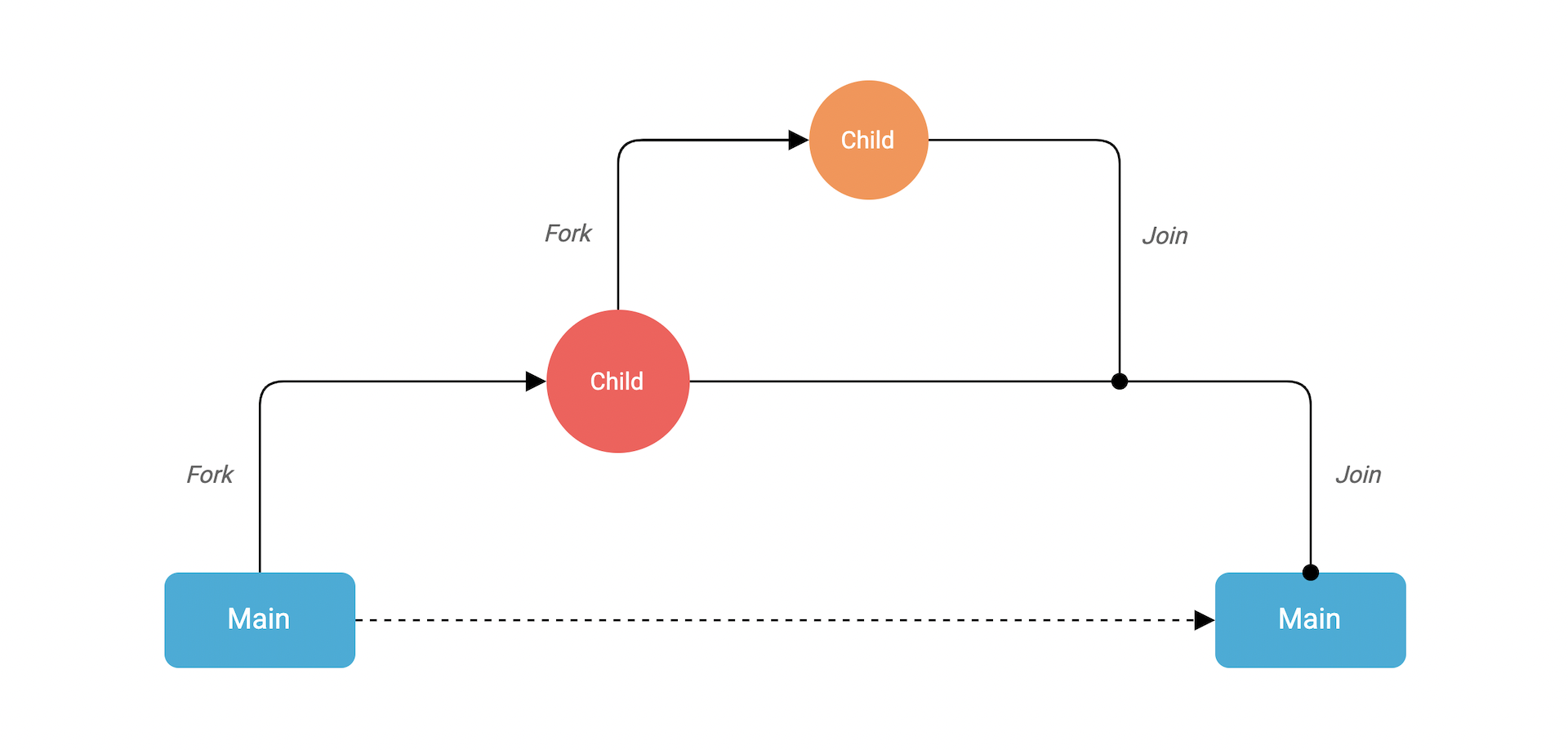
现在,让我们来编写goroutine。
package main
import "fmt"
func speak(arg string) {
fmt.Println(arg)
}
func main() {
go speak("Hello World")
}这里我们通过在speak函数前增加go关键字来执行。这样会产生独立的goroutine来执行。简单吧!
我们执行看看:
$ go run main.go
似乎我们程序并没有完全执行,没有任何输出。这是因为goroutine在main没有直言等待的话,其它goroutine会随着main goroutine一起退出。
如果我们让程序使用time.Sleep函数来等待呢?
func main() {
...
time.Sleep(1 * time.Second)
}现在我们再运行看看
$ go run main.go
Hello World现在,我们可以看到完整的输出了。
好了,虽然可以工作,但是我们还能怎么改善?
最棘手的部分是在使用goroutine时知道何时会停止。还需要知道时goroutines运行在相同内存空间,所以访问共享内存时确保是同步的。
本课程我们将学习通道。
简单来说通道就是用来在goroutine之间通信的管道。一边输入一边输出,且保持相同的顺序直到通道关闭。
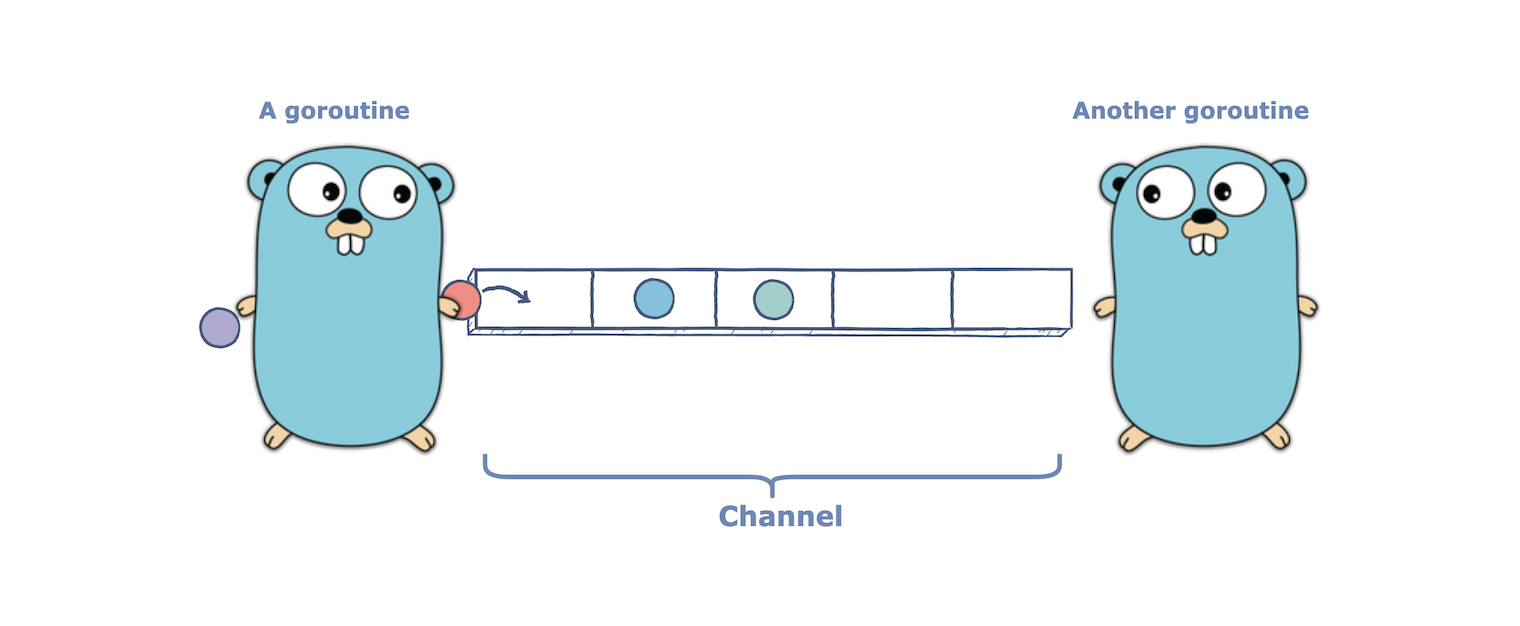
正如之前所学,Go中的通道基于通信顺序进程(CSP)。
现在我们知道通道了,让我们来学习如何申明它们。
var ch chan T这里T是我们需要发送和接收的数据类型,关键字chan代表为通道类型。
让我们尝试输出打印string通道c的值。
func main() {
var ch chan string
fmt.Println(c)
}$ go run main.go
<nil>正如我们所见,通道的零值为nil,如果我们对其发送输出将会引发panic。
和切片类似,我们可以使用内建make函数来初始化通道。
func main() {
ch := make(chan string)
fmt.Println(c)
}执行该代码,我们看到我们通道已经被初始化了。
$ go run main.go
0x1400010e060现在我们对通道有个基本了解,让我们实现goroutines之间如何使用通道通信。
package main
import "fmt"
func speak(arg string, ch chan string) {
ch <- arg // 发送
}
func main() {
ch := make(chan string)
go speak("Hello World", ch)
data := <-ch // 接收
fmt.Println(data)
}注意这里使用channel < -data发送数据,使用 data := <-channel语法来获取数据。
如果我们执行该代码:
$ go run main.go
Hello World完美,我们程序如期执行。
我们还可以定义具备缓冲区的管道来限定最大可容纳的值个数。
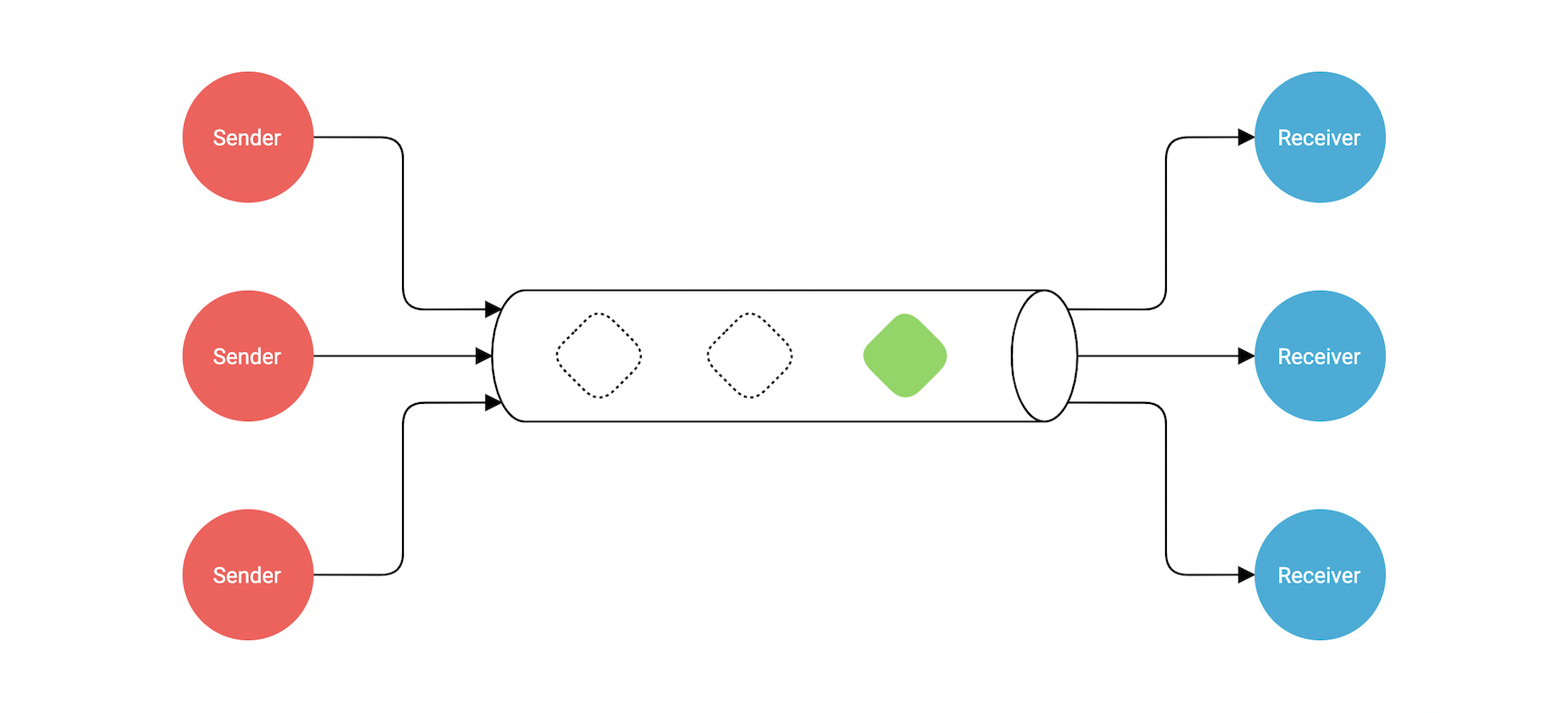
通过make函数的第二个参数来指定 缓冲长度 或者 容量。
func main() {
ch := make(chan string, 2)
go speak("Hello World", ch)
go speak("Hi again", ch)
data1 := <-ch
fmt.Println(data1)
data2 := <-ch
fmt.Println(data2)
}因为通道是缓冲,我们可以发送多个值至通道并发接收,也就是说 发送 到缓冲通道只有当通道满了才挂起,而 接收 在通道为空时挂起。
默认通道是无缓冲,具备0容量。也就是忽略make函数的第二个参数。
接下来我们看看定向通道。
当使用通道作为函数时。我们可以指明该通道是用来发送还是接收值。默认通道是可以收发的,增加定向符可以提高类型安全。
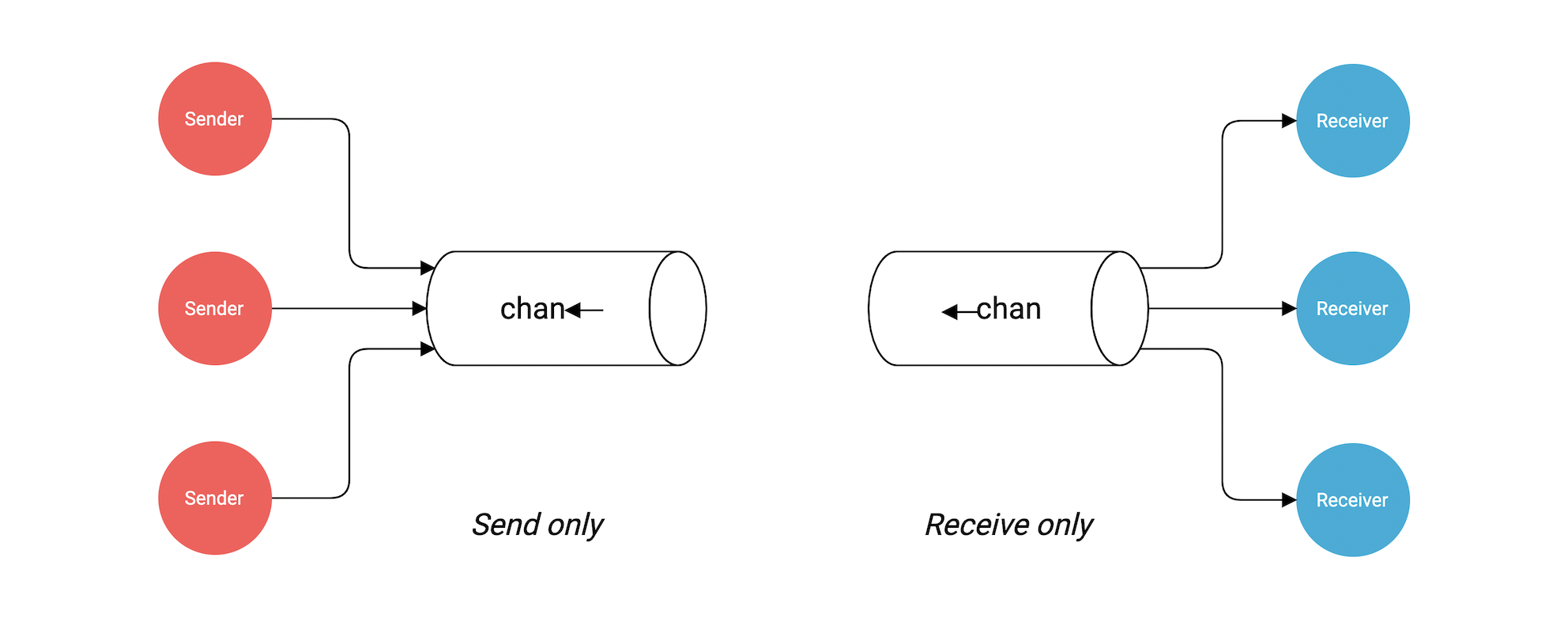
在我们例子中,我们将其speak函数所有接收第二个通道参数配置为限定发送通道。
func speak(arg string, ch chan<- string) {
ch <- arg // Send Only
}这里 chan<- 只能用来发送至,如果尝试读取操作会引发panic。
同样,和其它资源一样,一旦使用完通道我们需要关闭它。通过内建的close函数实现。
这里我们将我们通道作为参数传递给close函数。
func main() {
ch := make(chan string, 2)
go speak("Hello World", ch)
go speak("Hi again", ch)
data1 := <-ch
fmt.Println(data1)
data2 := <-ch
fmt.Println(data2)
close(ch)
}我们可以通过可选接收通道的第二个参数用来判定通道是否关闭。
func main() {
ch := make(chan string, 2)
go speak("Hello World", ch)
go speak("Hi again", ch)
data1 := <-ch
fmt.Println(data1)
data2, ok := <-ch
fmt.Println(data2, ok)
close(ch)
}如果ok的值为false那么说明没有值可以接收了,通道已经被关闭。
和我们在字典检测键是否存在相似。
最后我们来讨论通道的特性:
- 给nil通道发送值将会使通道永远挂起。
var c chan string
c <- "Hello, World!" // Panic: all goroutines are asleep - deadlock!- 从nil通道读取值也会永远挂起。
var c chan string
fmt.Println(<-c) // Panic: all goroutines are asleep - deadlock!- 给关闭的通道发送至会运发panic。
var c = make(chan string, 1)
c <- "Hello, World!"
close(c)
c <- "Hello, Panic!" // Panic: send on closed channel- 从关闭的通道获取值会返回零值。
var c = make(chan int, 2)
c <- 5
c <- 4
close(c)
for i := 0; i < 4; i++ {
fmt.Printf("%d ", <-c) // Output: 5 4 0 0
}- 在通道上使用Range。
我们也可以通过在通道上结合for和range来遍历获取值。
package main
import "fmt"
func main() {
ch := make(chan string, 2)
ch <- "Hello"
ch <- "World"
close(ch)
for data := range ch {
fmt.Println(data)
}
}本章,我们学习如何在Go使用select语句。
select语句块用来实现同时对多个通道操作。
select语句块一直等待任何一个子句可执行,如果多个子句可执行的话旧随机选择一个。
package main
import (
"fmt"
"time"
)
func main() {
one := make(chan string)
two := make(chan string)
go func() {
time.Sleep(time.Second * 2)
one <- "One"
}()
go func() {
time.Sleep(time.Second * 1)
two <- "Two"
}()
select {
case result := <-one:
fmt.Println("Received:", result)
case result := <-two:
fmt.Println("Received:", result)
}
close(one)
close(two)
}和switch语句一样,select同样指明一个默认分支,它将在没人任何case子句符合执行条件时执行,这样发送和接收时不会挂起。
func main() {
one := make(chan string)
two := make(chan string)
for x := 0; x < 10; x++ {
go func() {
time.Sleep(time.Second * 2)
one <- "One"
}()
go func() {
time.Sleep(time.Second * 1)
two <- "Two"
}()
}
for x := 0; x < 10; x++ {
select {
case result := <-one:
fmt.Println("Received:", result)
case result := <-two:
fmt.Println("Received:", result)
default:
fmt.Println("Default...")
time.Sleep(200 * time.Millisecond)
}
}
close(one)
close(two)
}空select {}语句会永远挂起。
func main() {
...
select {}
close(one)
close(two)
}我们前面所提到的,goroutine运行在相同内存空间,相互共享内存必须使用同步机制。sync包提供了一些有用原子性操作。
WaitGroup用来等待一系列goroutine集合完成。main goroutine通过执行Add来增加要等待的goroutine。每个goroutine通过执行Done来告知完成。同时,Wait在所有goroutine完成前挂起等待。
sync.WaitGroup具备如下方法:
Add(delta int)接收一个整型值,用来指定WaitGroup需要等待的goroutine个数。它需要再执行goroutine之前先执行。Done()在goroutine完成后执行。Wait()在通过Add()对应所有goroutine完成执行了Done()操作前挂起等待。
让我们看个例子。
package main
import (
"fmt"
"sync"
)
func work() {
fmt.Println("working...")
}
func main() {
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
work()
}()
wg.Wait()
}执行代码,程序如期工作。
$ go run main.go
working...我们也可以直接传递WaitGroup给函数。
func work(wg *sync.WaitGroup) {
defer wg.Done()
fmt.Println("working...")
}
func main() {
var wg sync.WaitGroup
wg.Add(1)
go work(&wg)
wg.Wait()
}不过要注意这里WaitGroup不能使用复制传递,我们需要使用 引用 传递方式。因为这样会使得计算器不一致影响程序执行逻辑。
我们通过指定传递数值到Add方法指定等待4个goroutines。
func main() {
var wg sync.WaitGroup
wg.Add(4)
go work(&wg)
go work(&wg)
go work(&wg)
go work(&wg)
wg.Wait()
}正如预期,我们所有的goroutine均被执行。
$ go run main.go
working...
working...
working...
working...Mutex是一个排它锁,用来在某个时期阻止其它进程访问数据临界区,从而防止竞争条件发生。
所以,一个数据临界区就是不能同时被多个线程执行,因为它们共享资源。
sync.Mutex 提供如下方法:
Lock()请求和持有锁。Unlock()释放锁。TryLock()尝试获取锁并返回成功状态。
让我们看看例子,我们创建一个Counter结构体,实现一个Update方法来更新内部值。
package main
import (
"fmt"
"sync"
)
type Counter struct {
value int
}
func (c *Counter) Update(n int, wg *sync.WaitGroup) {
defer wg.Done()
fmt.Printf("Adding %d to %d\n", n, c.value)
c.value += n
}
func main() {
var wg sync.WaitGroup
c := Counter{}
wg.Add(4)
go c.Update(10, &wg)
go c.Update(-5, &wg)
go c.Update(25, &wg)
go c.Update(19, &wg)
wg.Wait()
fmt.Printf("Result is %d\b", c.value)
}让我们看看输出结果
$ go run main.go
Adding -5 to 0
Adding 10 to 0
Adding 19 to 0
Adding 25 to 0
Result is 49奇怪,似乎我们获取到的值总为0,缺得到了正确的答案。
例子中,多个goroutine同时更新value变量,你或许猜到了,这并不理想。
这就是一个使用Mutex极佳的雷子。让我们开始使用sync.Mutex通过Lock()和Unlock()方法来包装临界区。
package main
import (
"fmt"
"sync"
)
type Counter struct {
m sync.Mutex
value int
}
func (c *Counter) Update(n int, wg *sync.WaitGroup) {
c.m.Lock()
defer wg.Done()
fmt.Printf("Adding %d to %d\n", n, c.value)
c.value += n
c.m.Unlock()
}
func main() {
var wg sync.WaitGroup
c := Counter{}
wg.Add(4)
go c.Update(10, &wg)
go c.Update(-5, &wg)
go c.Update(25, &wg)
go c.Update(19, &wg)
wg.Wait()
fmt.Printf("Result is %d\n", c.value);
}$ go run main.go
Adding -5 to 0
Adding 19 to -5
Adding 25 to 14
Adding 10 to 39
Result is 49看起来我们解决问题得到了正确答案。
注意:同WaitGroup一样,Mutex 也不能作为 拷贝 方式传递。
RWMutex是一个读写互斥锁。该锁可以任意读,只能单个写。
用其他话来说,相互读无需等待。只有写入时才需要持有锁。
sync.RWMutex适用大量读场景,相比sync.Mutex可以节省资源。
同 sync.Mutex, 我们可以使用 sync.RWMutex 如下方法:
Lock()获取锁。Unlock()释放锁。RLock()请求读锁。RUnlock()释放读锁。
相比Mutex,RWMutex多了RLock 和 RUnlock 方法。_
让我们添加一个GetValue方法来读取counter的值。我们将sync.Mutex修改为sync.RWMutex。
我们可以通过使用RLock和RUnlock方法以便相互读无需等待。
package main
import (
"fmt"
"sync"
"time"
)
type Counter struct {
m sync.RWMutex
value int
}
func (c *Counter) Update(n int, wg *sync.WaitGroup) {
defer wg.Done()
c.m.Lock()
fmt.Printf("Adding %d to %d\n", n, c.value)
c.value += n
c.m.Unlock()
}
func (c *Counter) GetValue(wg *sync.WaitGroup) {
defer wg.Done()
c.m.RLock()
defer c.m.RUnlock()
fmt.Println("Get value:", c.value)
time.Sleep(400 * time.Millisecond)
}
func main() {
var wg sync.WaitGroup
c := Counter{}
wg.Add(4)
go c.Update(10, &wg)
go c.GetValue(&wg)
go c.GetValue(&wg)
go c.GetValue(&wg)
wg.Wait()
}$ go run main.go
Get value: 0
Adding 10 to 0
Get value: 10
Get value: 10注意: sync.Mutex 和 sync.RWMutex 均实现了 sync.Locker 接口。
type Locker interface {
Lock()
Unlock()
}sync.Cond条件变量用来协调goroutines来共享资源。当共享资源状态变更时,它会使用通知方式来唤醒挂起的goroutines。
每个Cond关联了一个锁(通常是*Mutex或*RWMutex)。当执行条件变更或者执行Wait方法时必须持有该锁。
一个场景就是当一个进程需要处理数据,其它进程需要等待该进程处理完后才能读取。
如果使用通道或者互斥的话,只有一个进程可以等待读取该数据。没有其它机制可以通知其它机制来读取数据。然而sync.Cond可以协调共享资源。
sync.Cond 包含如下方法:
NewCond(l Locker)创建一个Cond。Broadcast()通知所有在等待的goroutines。Signal()仅唤醒一个goroutine。Wait()自动解开底层的互斥锁。
以下是一个不同goroutines通过使用Cond进行交互示例。
package main
import (
"fmt"
"sync"
"time"
)
var done = false
func read(name string, c *sync.Cond) {
c.L.Lock()
for !done {
c.Wait()
}
fmt.Println(name, "starts reading")
c.L.Unlock()
}
func write(name string, c *sync.Cond) {
fmt.Println(name, "starts writing")
time.Sleep(time.Second)
c.L.Lock()
done = true
c.L.Unlock()
fmt.Println(name, "wakes all")
c.Broadcast()
}
func main() {
var m sync.Mutex
cond := sync.NewCond(&m)
go read("Reader 1", cond)
go read("Reader 2", cond)
go read("Reader 3", cond)
write("Writer", cond)
time.Sleep(4 * time.Second)
}$ go run main.go
Writer starts writing
Writer wakes all
Reader 2 starts reading
Reader 3 starts reading
Reader 1 starts reading正如所见,所有读经过Wait方法挂起,写通过使用Broadcast方法来唤醒进程。
Once 确保多个goroutines只有一个执行。
和其它原语不同,sync.Once只有一个方法:
Do(f func())只执行f一次. 如果Do调用多次,f只被第一次调用执行。
看起来很简单,我们来看看例子:
package main
import (
"fmt"
"sync"
)
func main() {
var count int
increment := func() {
count++
}
var once sync.Once
var increments sync.WaitGroup
increments.Add(100)
for i := 0; i < 100; i++ {
go func() {
defer increments.Done()
once.Do(increment)
}()
}
increments.Wait()
fmt.Printf("Count is %d\n", count)
}$ go run main.go
Count is 1正如所见,就算我们执行了100个goroutines,也只有一个被执行。
Pool是一个可伸缩的对象池,同样是并发安全的。任何存储在的pool值不需要任何通知即可删除。还有,高负载时对象池会扩展,低负载时对象池会收缩。
主要目的重复使用对象并且重复创建和销毁对象影响性能。
Pool将不使用对象做缓存为后面使用,减轻垃圾回收器的压力。它使得非常容易构建高效,线程安全的空闲列表。但是并不适用所有的空闲列表。
Pool的用途是管理在客户端之间共享可重用的临时对象。它也提供了将创建对象开销分散到不同客户端的途径。
需要注意的是Pool本身也有一定的开销,sync.Pool对比简单列表要慢得多。首次使用时Pool也能被拷贝。
sync.Pool 提供了如下方法:
Get()提供了从Pool获取对象的抽象能力,从Pool中删除,并返回给调用方。Put(x any)将元素添加到pool。
我们来看看例子。
首先我创建一个sync.Pool, 我们可以提供一个可选生成值的函数,否则Get在没有对象时返回nil值。
package main
import (
"fmt"
"sync"
)
type Person struct {
Name string
}
var pool = sync.Pool{
New: func() any {
fmt.Println("Creating a new person...")
return &Person{}
},
}
func main() {
person := pool.Get().(*Person)
fmt.Println("Get object from sync.Pool for the first time:", person)
fmt.Println("Put the object back in the pool")
pool.Put(person)
person.Name = "Gopher"
fmt.Println("Set object property name:", person.Name)
fmt.Println("Get object from pool again (it's updated):", pool.Get().(*Person))
fmt.Println("There is no object in the pool now (new one will be created):", pool.Get().(*Person))
}运行它我们虎得到有趣的输出:
$ go run main.go
Creating a new person...
Get object from sync.Pool for the first time: &{}
Put the object back in the pool
Set object property name: Gopher
Get object from pool again (it's updated): &{Gopher}
Creating a new person...
There is no object in the pool now (new one will be created): &{}注意我们是如何使用Get进行类型推断。
可以看出sync.Pool严格来说就是一个临时对象池,适合存放一些在goroutine之间共享的临时对象。
Map和标准的map[any]any类似,但是它对于多个goroutine是并发安全,并且不需要附加锁和协同,加载,存储和删除在常量事件内。
该字典类型是 特别的。大部分时候我们优先使用Go基础map类型,通过独立的锁或者协调,实现更好类型安全,使得其容易与其它不变量一些管理。
两种情况使用该优化map类型:
- 当一个 key 只被写入一次但被多次读取时,例如在只会增长的缓存中,就存在这种业务场景
- 当多个 goroutine 读取、写入和覆盖不相交键集的条目时。这两种情况下使用
sync.Map相比单独使用Mutex或者RWMutex可以减少锁争夺。
Map零值有效,在第一次使用后不能进行拷贝。
sync.Map 提供如下方法:
Delete()通过key删除值.Load(key any)通过key来获取map里的值,如果key不存在返回nil。LoadAndDelete(key any)返回值后立即删除该key。加载的结果指示该key是否存在。LoadOrStore(key, value any)如果key已经存在就返回该值,否则,将给定的值存入。返回loaded的结果只是true说明已经存在该key,false则说明不存在并存入了所提供的值。Store(key, value any)设置key对应的值。Range(f func(key, value any) bool)通过函数参数f对map中的每个键值对进行遍历。如果函数f返回false则终止遍历。
注意:Range并不保证可以获得Map内容的一致快照。
让我们来看个例子。这里,我们启动一些goroutines并发从map中添加及获取值。
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
var m sync.Map
wg.Add(10)
for i := 0; i <= 4; i++ {
go func(k int) {
v := fmt.Sprintf("value %v", k)
fmt.Println("Writing:", v)
m.Store(k, v)
wg.Done()
}(i)
}
for i := 0; i <= 4; i++ {
go func(k int) {
v, _ := m.Load(k)
fmt.Println("Reading: ", v)
wg.Done()
}(i)
}
wg.Wait()
}如预期,我们的存储和读取操作是并发安全的。
$ go run main.go
Reading: <nil>
Writing: value 0
Writing: value 1
Writing: value 2
Writing: value 3
Writing: value 4
Reading: value 0
Reading: value 1
Reading: value 2
Reading: value 3atomic包提供了对于整型和指针实现同步算法的低级原子内存原语。
atomic包提供了几个函数针对int,uint和 uintptr类型进行5种操作:
- Add
- Load
- Store
- Swap
- Compare and Swap
我们不会介绍这里所有的函数,就让我们看看最为常用的函数如Addint32来举例。
package main
import (
"fmt"
"sync"
"sync/atomic"
)
func add(w *sync.WaitGroup, num *int32) {
defer w.Done()
atomic.AddInt32(num, 1)
}
func main() {
var n int32 = 0
var wg sync.WaitGroup
wg.Add(1000)
for i := 0; i < 1000; i = i + 1 {
go add(&wg, &n)
}
wg.Wait()
fmt.Println("Result:", n)
}这里atomic.AddInt32保证n的结果为 1000,因为原子操作的指令执行不会被中断。
go run main.go
Result: 1000本章,我们来讨论Go中一些高级并发模式。这些模式常出现于现实当中。
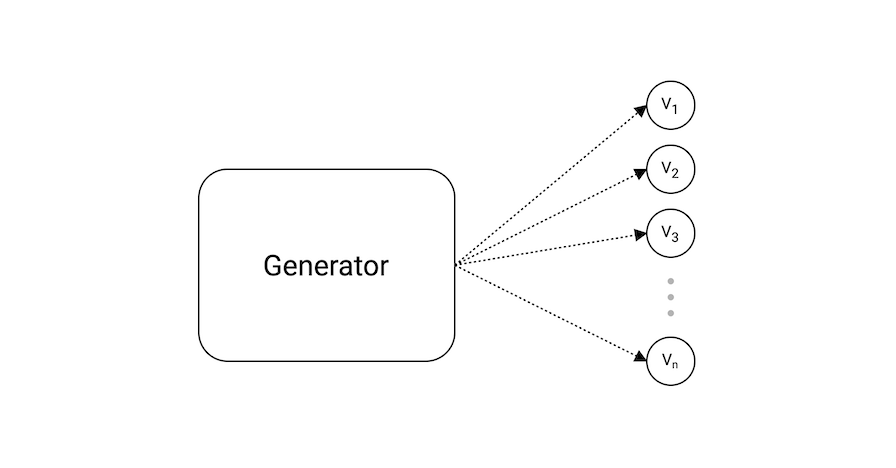
生成器模式用来生成一系列值。
在我们例子中,我们有一个generator函数,该函数简单返回一个channel,我们根据该channel来读取值。
这适用于 发送 和 接收 阻塞,直到发送方和接收方都就绪。这个特性允许我们等到下一个值被请求。
package main
import "fmt"
func main() {
ch := generator()
for i := 0; i < 5; i++ {
value := <-ch
fmt.Println("Value:", value)
}
}
func generator() <-chan int {
ch := make(chan int)
go func() {
for i := 0; ; i++ {
ch <- i
}
}()
return ch
}执行该代码,我注意到可以按需生成值。
$ go run main.go
Value: 0
Value: 1
Value: 2
Value: 3
Value: 4与JavaScript和Python的yield行为相似.
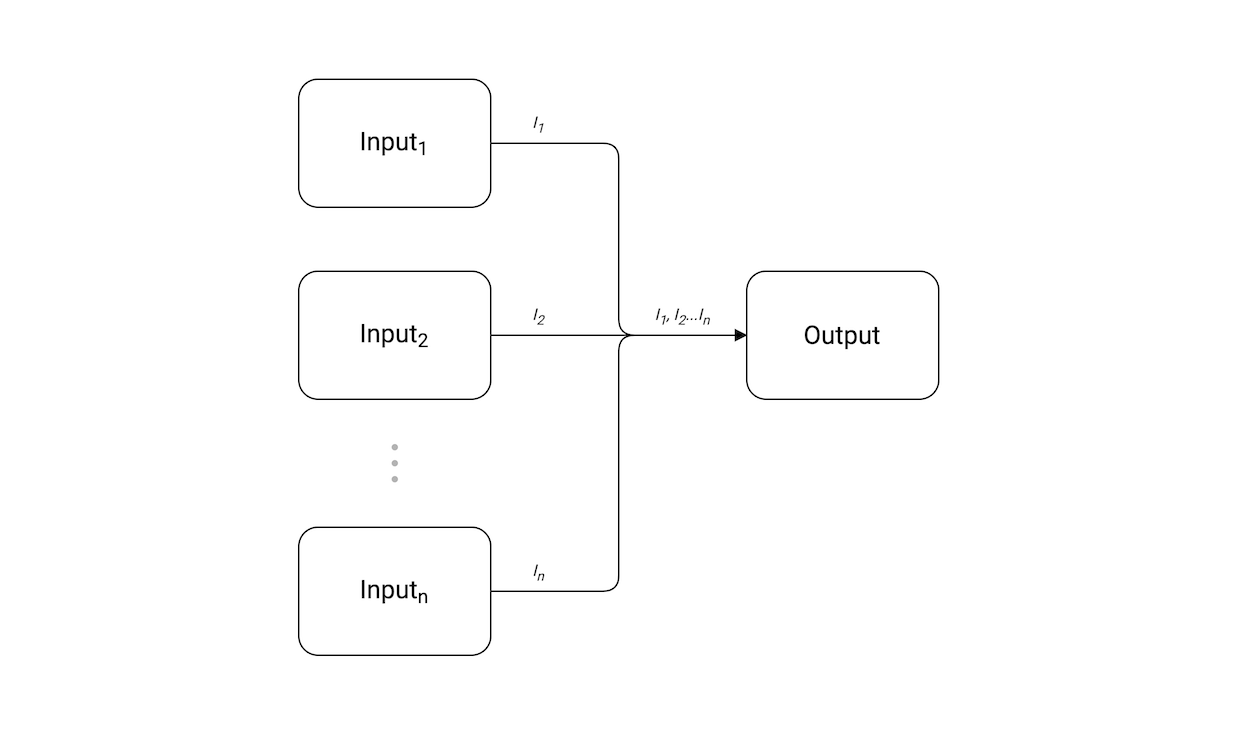
fan-in(扇入)模式是将多个输入到单个channel。基本上来说,就是复用输入。
在我们例子中,使用generateWork函数创建i1和i2输入。然后使用可变参数函数fanIn组合这些输入多个值到单个输出channel来消费这些值。
注意:输入顺序将是不确定的。
package main
import (
"fmt"
"sync"
)
func main() {
i1 := generateWork([]int{0, 2, 6, 8})
i2 := generateWork([]int{1, 3, 5, 7})
out := fanIn(i1, i2)
for value := range out {
fmt.Println("Value:", value)
}
}
func fanIn(inputs ...<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int)
wg.Add(len(inputs))
for _, in := range inputs {
go func(ch <-chan int) {
for {
value, ok := <-ch
if !ok {
wg.Done()
break
}
out <- value
}
}(in)
}
go func() {
wg.Wait()
close(out)
}()
return out
}
func generateWork(work []int) <-chan int {
ch := make(chan int)
go func() {
defer close(ch)
for _, w := range work {
ch <- w
}
}()
return ch
}$ go run main.go
Value: 0
Value: 1
Value: 2
Value: 6
Value: 8
Value: 3
Value: 5
Value: 7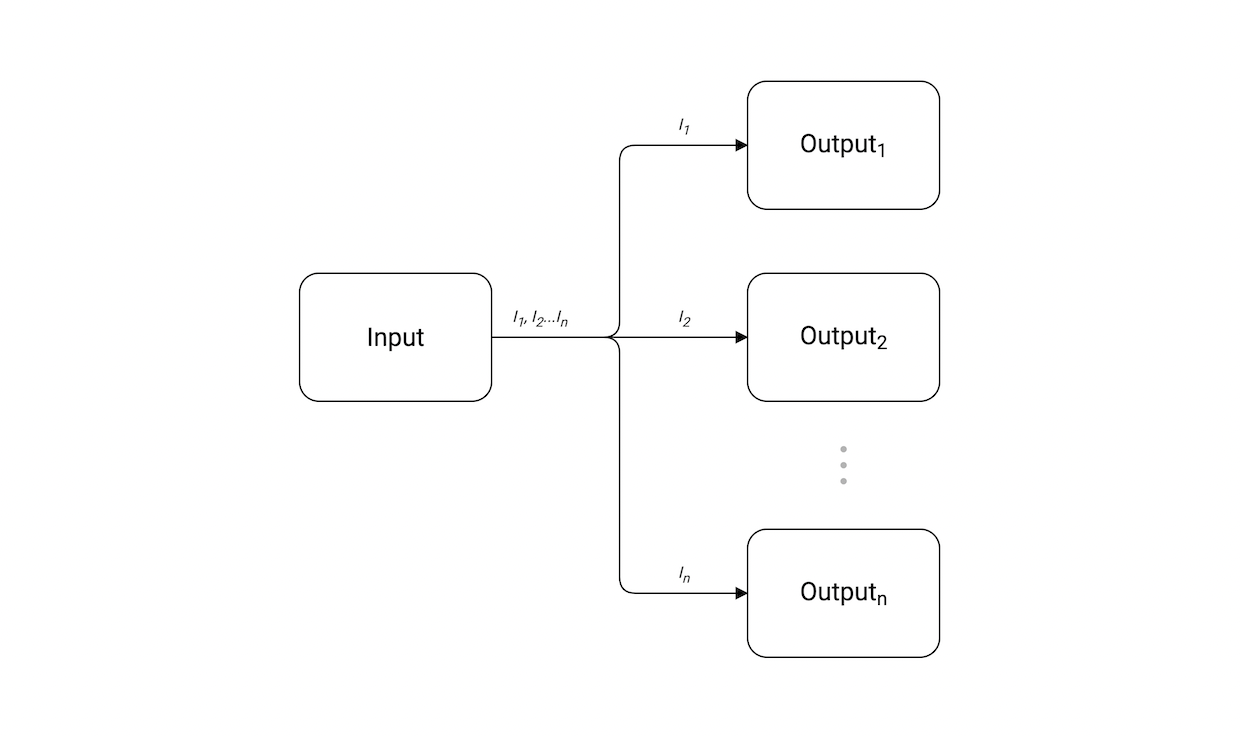
Fan-out(扇出)允许将单个输入管道输出到多个管道。该模式非常适合将工作分发到多个不同actors。
我们的例子中,我们将输入管道拆分为4个不同输出管道。对于动态数量的输出,我们可以使用select合并输出到一个共享的 “聚合” 管道。
注意:fan-out 模式不同于pub/sub(订阅发送)模式
package main
import "fmt"
func main() {
work := []int{1, 2, 3, 4, 5, 6, 7, 8}
in := generateWork(work)
out1 := fanOut(in)
out2 := fanOut(in)
out3 := fanOut(in)
out4 := fanOut(in)
for range work {
select {
case value := <-out1:
fmt.Println("Output 1 got:", value)
case value := <-out2:
fmt.Println("Output 2 got:", value)
case value := <-out3:
fmt.Println("Output 3 got:", value)
case value := <-out4:
fmt.Println("Output 4 got:", value)
}
}
}
func fanOut(in <-chan int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for data := range in {
out <- data
}
}()
return out
}
func generateWork(work []int) <-chan int {
ch := make(chan int)
go func() {
defer close(ch)
for _, w := range work {
ch <- w
}
}()
return ch
}正如所见,我们的工作分配到多个goroutines里了。
$ go run main.go
Output 1 got: 1
Output 2 got: 3
Output 4 got: 4
Output 1 got: 5
Output 3 got: 2
Output 3 got: 6
Output 3 got: 7
Output 1 got: 8
管道模式是通过channels连接的一系列 stages,每个stage是一组执行相同的函数的goroutines。
每个stage及goroutines:
- 通过 输入 管道获取 上游 的值
- 在数据上执行一些函数操作,通常会产生一个新值
- 通过 输出 管道将值发送给 下游
每个stage拥有任意个输入和输出管道,除了首个和末尾stage,只有单个输出或者输入管道。相应的,第一个stage有时称为 source 或者 producer,最后一个通常称为 sink 或者 consumer 。
通过使用管道,我们相关操作分开到每个stage,提供了如下好处:
- 独立
- 组合
在我们例子中,定义了三个stages,filter, square, 和 half.
package main
import (
"fmt"
"math"
)
func main() {
in := generateWork([]int{0, 1, 2, 3, 4, 5, 6, 7, 8})
out := filter(in) // Filter odd numbers
out = square(out) // Square the input
out = half(out) // Half the input
for value := range out {
fmt.Println(value)
}
}
func filter(in <-chan int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for i := range in {
if i%2 == 0 {
out <- i
}
}
}()
return out
}
func square(in <-chan int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for i := range in {
value := math.Pow(float64(i), 2)
out <- int(value)
}
}()
return out
}
func half(in <-chan int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for i := range in {
value := i / 2
out <- value
}
}()
return out
}
func generateWork(work []int) <-chan int {
ch := make(chan int)
go func() {
defer close(ch)
for _, w := range work {
ch <- w
}
}()
return ch
}我们程序通过管道中并发执行了。
$ go run main.go
0
2
8
18
32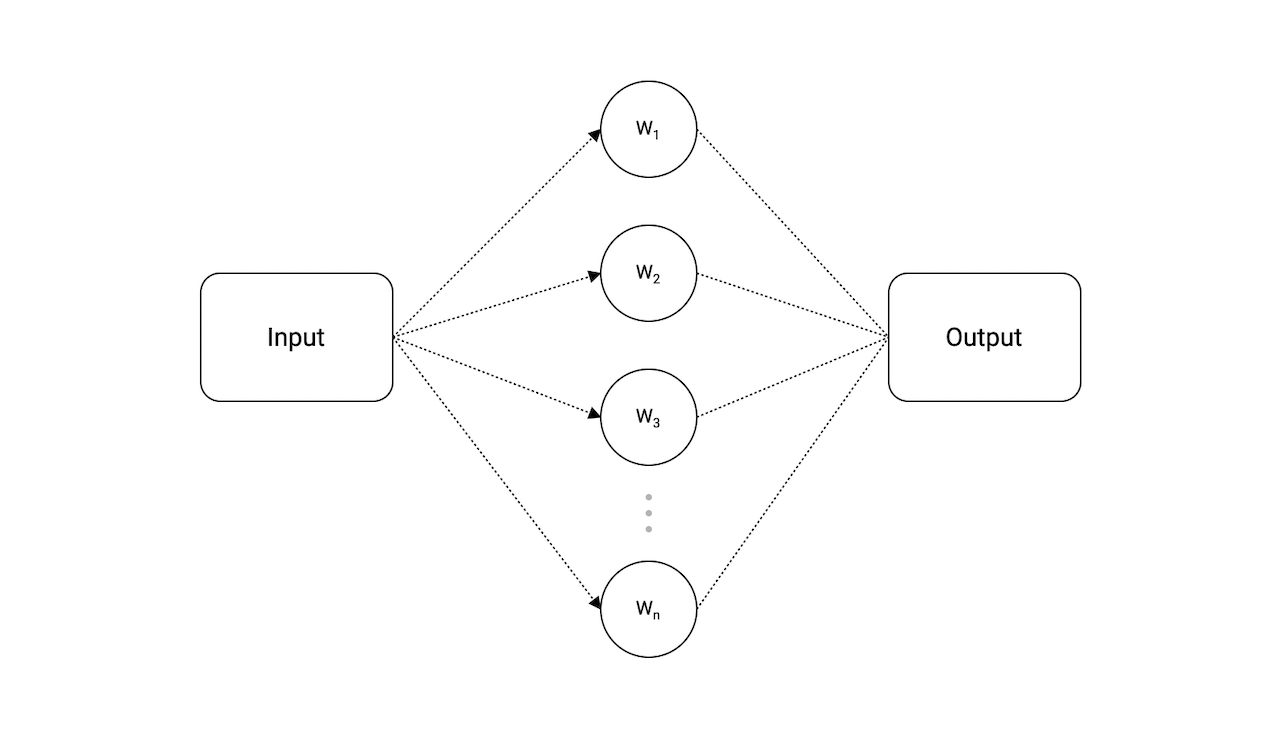
worker pool(工作池)是一个非常强大的模式,让我们使用并发将任务分布到多个workers(groutines)。
在我们例子中,我们有一个job通道来发送我们的工作,results通道用来在wokers工作完后输出结果。
最后,我们通过并发执行workers,然后从results管道来获取结果。
理想情况下,totalWorkers应该设置为runtime.NumCPU(),也即当前进程可用内存数。
package main
import (
"fmt"
"sync"
)
const totalJobs = 4
const totalWorkers = 2
func main() {
jobs := make(chan int, totalJobs)
results := make(chan int, totalJobs)
for w := 1; w <= totalWorkers; w++ {
go worker(w, jobs, results)
}
// Send jobs
for j := 1; j <= totalJobs; j++ {
jobs <- j
}
close(jobs)
// Receive results
for a := 1; a <= totalJobs; a++ {
<-results
}
close(results)
}
func worker(id int, jobs <-chan int, results chan<- int) {
var wg sync.WaitGroup
for j := range jobs {
wg.Add(1)
go func(job int) {
defer wg.Done()
fmt.Printf("Worker %d started job %d\n", id, job)
// Do work and send result
result := job * 2
results <- result
fmt.Printf("Worker %d finished job %d\n", id, job)
}(j)
}
wg.Wait()
}As expected, our jobs were distributed among our workers.
$ go run main.go
Worker 2 started job 4
Worker 2 started job 1
Worker 1 started job 3
Worker 2 started job 2
Worker 2 finished job 1
Worker 1 finished job 3
Worker 2 finished job 2
Worker 2 finished job 4
Queuing(队列)模式允许我们同时处理n个值。
在我们的例子中,我使用缓冲管道来模拟队列行为。我们简单通过发送一个空结构体到我们queue管道中,等待它被上一个进程释放以便我们可以继续处理。
这时因为 发送 到一个已满缓冲区管道将会导致挂起,当缓冲区为空时 接收 也会挂起。
这里,我们一共有10个元素,我们限制为2个元素。也即同时仅处理2个元素。
注意使用空结构struct{}作为queue管道的类型占用0字节存储。
package main
import (
"fmt"
"sync"
"time"
)
const limit = 2
const work = 10
func main() {
var wg sync.WaitGroup
fmt.Println("Queue limit:", limit)
queue := make(chan struct{}, limit)
wg.Add(work)
for w := 1; w <= work; w++ {
process(w, queue, &wg)
}
wg.Wait()
close(queue)
fmt.Println("Work complete")
}
func process(work int, queue chan struct{}, wg *sync.WaitGroup) {
queue <- struct{}{}
go func() {
defer wg.Done()
time.Sleep(1 * time.Second)
fmt.Println("Processed:", work)
<-queue
}()
}如果执行该代码,我们注意这里会短暂的停止,然后由于队列再等待出队,程序按照每两个(我们所限制的)进行处理。
$ go run main.go
Queue limit: 2
Processed: 1
Processed: 2
Processed: 4
Processed: 3
Processed: 5
Processed: 6
Processed: 8
Processed: 7
Processed: 9
Processed: 10
Work complete还有一些其它有用模式:
- Tee channel
- Bridge channel
- Ring buffer channel
- Bounded parallelism
在并发程序中,由于超时,取消或者是故障,通常需要进行抢占操作。
context包用来传递请求作用域值,取消信号,截止日期,API边界之间绑定到相关goroutines来处理请求。
让我们来讨论context包一些核心类型。
Context是一个接口类型,定义如下:
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key any) any
}Context 类型具备如下方法:
Done() <- chan struct{}返回一个通道,指示context取消或者超时。如果context不能被取消则返回nil。Deadline() (deadline time.Time, ok bool)当context被取消或者超时时返回时间。如果没有设置截止时间ok返回false。Err() error返回一个error,用来解释通道关闭原因。如果Done还没有关闭,它将返回nil。Value(key any) any返回关联键的值,如果没有返回nil。
CancelFunc告知不用等待工作完成旧发起工作了。如果它被多个goroutines同时执行,在第一执行后,后面的CancelFunc操作啥也不做。
type CancelFunc func()让我们来讨论context包提供的相关函数:
Background返回空Context。它从不取消,没有值,也没有截止时间。
常用来作为main函数,初始化或者测试,作为请求的顶级Context
func Background() Context同Background函数一样,TODO也返回一个空Context。
然后,它使用在仅当我们无法确定函数是否会接收context,也就是我们计划再未来给函数加入context。
func TODO() Context该函数接收一个派生的context,然后一对键值对,通过上下文进行传递。
也就是说一旦你赋于context值,那么所有由此context派生的context都将获得该值。
不建议利用context来传递参数,仅当使用函数明确指明参数。
func WithValue(parent Context, key, val any) ContextExample
让我们来看一个添加键值对到context的例子:
package main
import (
"context"
"fmt"
)
func main() {
processID := "abc-xyz"
ctx := context.Background()
ctx = context.WithValue(ctx, "processID", processID)
ProcessRequest(ctx)
}
func ProcessRequest(ctx context.Context) {
value := ctx.Value("processID")
fmt.Printf("Processing ID: %v", value)
}当我们执行该代码,我们看到processID通过context进行传递。
$ go run main.go
Processing ID: abc-xyz该函数通过父级context创建一个新的context,具备取消函数。父级可以是context.Background或者通过函数传递的context。
取消该context将会释放相关资源,所以当操作完成后需要执行cancel。
不建议传递cancel函数,可能会得到未预料的行为
func WithCancel(parent Context) (ctx Context, cancel CancelFunc)该函数返回从父级派生的context,当超过截止时间或者取消函数调用后将会取消。
例如,我们可以通过指定一个未来时间自动取消,当时间到达后context取消,所有的函数都会提到通知停止工作并返回。
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc)通过指定超时时间包装WithDeadline函数。
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}让我们使用例子来巩固对context的理解:
如下,我们有一个简单的HTTP服务器来处理请求。
package main
import (
"fmt"
"net/http"
"time"
)
func handleRequest(w http.ResponseWriter, req *http.Request) {
fmt.Println("Handler started")
context := req.Context()
select {
// 模拟服务器工作,等待5秒回后响应
case <-time.After(5 * time.Second):
fmt.Fprintf(w, "Response from the server")
// 处理请求取消
case <-context.Done():
err := context.Err()
fmt.Println("Error:", err)
}
fmt.Println("Handler complete")
}
func main() {
http.HandleFunc("/request", handleRequest)
fmt.Println("Server is running...")
http.ListenAndServe(":4000", nil)
}让我们打开两个终端,一个终端执行我们的例子。
$ go run main.go
Server is running...
Handler started
Handler complete另一个终端,对我们服务发起请求。如果我们等待五秒,我们拿到了输出结果。
$ curl localhost:4000/request
Response from the server如果们在完成前取消请求会发生什么呢?
注意:我们通过使用ctrl + c来中途取消请求。
$ curl localhost:4000/request
^C正如所见,我们通过请求context检测到了取消操作。
$ go run main.go
Server is running...
Handler started
Error: context canceled
Handler complete我确信你已经知道它强大的用途。
例如,我们可以使用该方法来取消不在需要,超过截止时间,超时等资源密集的工作。
恭喜,你已经完成了课程!
你已经了解了Go基础,这里有一些其它可以尝试的资源:
- Build a REST API with Go - For Beginners
- Connecting to PostgreSQL using GORM
- Web Scraping with Go
- Dockerize your Go app
- DevOps Roadmap
我希望你有一个较好的学习体验。非常乐于得到你的反馈。
祝你未来较好收货。
以下是本教材所参考的一些资源。