Wiki Archifiltre

Archifiltre est un logiciel libre d'analyse et de traitement d’arborescences de fichiers bureautiques non-structurés, développé par les ministères sociaux. Son objectif est de proposer, à tout utilisateur de fichiers bureautiques, un outil de visualisation d’arborescences complètes afin de pouvoir les analyser, les auditer, les trier, les enrichir et les verser dans un système d'archivage électronique (SAE).
Vous manquez d'informations sur des fonctionnalités, vous souhaitez des cas d'usages particuliers ? Faites nous vos propositions en cliquant sur le lien ci-dessous !Ce wiki est à jour pour la version 3.1.1


Ce wiki est adapté pour les versions à partir de la v.3.0. Retrouvez le wiki adapté aux versions précédentes ici.





1. Commencer avec Archifiltre
1.1 Installer Archifiltre
1.2 Paramétrer Archifiltre
1.3 Charger mon répertoire
1.4 Restaurer votre travail perdu
1.5 Sauvegarder ma session de travail
2. Utiliser les fonctionnalités d'Archifiltre
2.1 L’onglet « général »
2.1.1 La zone des caractéristiques
2.1.2 Les outils de visualisation
2.1.3 Les outils de navigation
3. Utiliser les exports d'Archifiltre
3.1 Le rapport d'audit
3.2 L'export csv (avec et sans empreintes)
3.3 L'export csv hiérarchisé
3.4 L'export Excel
3.5 L'export ReSIP
3.6 L'export METS (beta)
3.7 Le script de suppression
4. Mener une opération d'audit et de collecte
4.1 Je souhaite étudier la structure d'une arborescence
Cas 1 - Une arborescence mal structurée
Cas 2 - Des doublons de répertoires au sein de l'arborescence
Cas 3 - Une arborescence chronologique
Cas 4 - Visualiser une arborescence par nombre de fichiers
4.2 Je souhaite faire des recommandations techniques sur une arborescence
4.2.1 - S'appuyer sur le rapport d'audit
4.2.2 - Etudier les chemins d'accès
4.2.2 - Etudier les chemins d'accès
4.3 Je souhaite faire des préconisations à partir d'Archifiltre
4.3.1 - Première étape : Faire une analyse macro de l'arborescence
4.3.2 - Deuxième étape : proposer un rapport d'audit
4.4 Je souhaite trouver facilement des éliminables
4.4.1 - Identifier des parties de l'arborescence qui ne sont plus alimentées
4.4.2 - Identifier les données pour lesquelles la durée d'utilité administrative est échue et le sort final l'élimination
4.4.3 - Identifier des versions intermédiaires
4.4.4 - Identifier des redondances (doublons)
5. Traiter un fonds d'archives électroniques
Vous pouvez télécharger gratuitement l'outil Archifiltre en cliquant sur le bouton ci-dessous :

En cliquant sur le bouton télécharger, le site déterminera automatiquement votre système d'exploitation (Windows, Linux ou Max). Le téléchargement se lance automatiquement.
Attention : Pour Windows, le site Archifiltre va automatiquement télécharger la version 64 bits. Si vous souhaitez avoir la version 32 bits, rendez-vous sur le site en cliquant ICI
Le fichier s'enregistre sous le nom « Archifiltre.exe ». Double-cliquez pour lancer l'exécution de l'outil. Il n'y a pas d'installation à faire, Archifiltre s’exécute immédiatement !
Attention : Il est possible que votre système d'exploitation ou votre antivirus vous demande si ce programme est sûr, il n'y a pas d'inquiétude à avoir, le logiciel est sans danger, vous pouvez forcer l'installation. Si vous voulez vous en assurer le code est ouvert et disponible ICI et les informations sur la sécurité de l'outil sont disponible sur la page F.A.Q.

Cliquer sur le bouton « Paramètres » en bas à gauche. Une fenêtre s’ouvre et vous permet de paramétrer différents éléments.

La langue de votre choix : Archifiltre est disponible en français, anglais et allemand.
Votre politique de confidentialité : Archifiltre utilise les outils Sentry (remontées des anomalies techniques) et Matomo (remontées des statistiques d'utilisations). Retrouvez plus d'informations sur notre F.A.Q
Il y a différentes façons de charger l'arborescence que l'on souhaite étudier. Il est possible de réaliser un glisser-déposer ou d'ouvrir une fenêtre de dialogue.


Vous pouvez également retrouver les répertoires les plus utilisés sur votre gauche. Cliquez dessus pour les analyser à nouveau. Cet accès est uniquement un raccourci, les arborescences doivent charger à chaque fois.

Votre répertoire commence à être chargé dans Archifiltre. Profitez-en pour découvrir les nouvelles fonctionnalités de la version en cliquant ICI

En cas d'erreur, il est possible d'annuler en cliquant sur le bouton central Annuler le chargement. Le chargement est arrêté, il est possible de charger à nouveau une arborescence.
Depuis la version V3.0.0, l’équipe Archifiltre a fait le choix d'arrêter l'indexation des fichiers systèmes, temporaires et cachés Ces fichiers générés par les systèmes d'exploitation sont bloquants pour les SAE, alourdissent l’analyse d’une arborescence et faussent les calculs d’empreintes. De même, les dossiers vides ne sont plus importés dans Archifiltre. De ce fait, il peut y avoir une différence de volume de votre arborescence entre celui qui est affiché dans votre système d'exploitation (comprenant également le volume des fichiers système et cachés) et le volume affiché dans Archifiltre. La différence entre les 2 volumes correspond au volume de fichiers systèmes, temporaires ou cachés.
Attention : Plus votre arborescence est volumineuse, plus il y a de métadonnées à charger. La visualisation de l’arborescence peut pendre quelques minutes voire quelques heures en fonction du nombre de fichiers et de la puissance de votre ordinateur. Si vous analysez un espace serveur, l’outil sera également dépendant de la qualité de votre connexion à votre espace serveur.
Votre ordinateur a planté pendant votre session de travail ? Il possible de restaurer votre travail en relançant Archifiltre et en cliquant sur « Recharger la session précédente ». Vous retrouverez votre travail là où il s'est arrêté.

Votre connexion à un espace serveur s’est coupée pendant le calcul d’empreintes de votre répertoire ? Vous allez recevoir une notification vous indiquant qu’une erreur s’est produite lors du chargement des empreintes.

Cliquez sur la notification. Vous allez voir la liste de l’ensemble des éléments dont le calcul d’empreinte n’a pas pu se faire. Il est possible de trier par colonnes pour chercher un élément en particulier. Pour avoir l'exhaustivité des éléments de la liste des erreurs, vous pouvez également générer la liste des erreurs en cliquant sur le bouton « exporter ». Cela génère un fichiers csv renseignant l'élément (fichier ou répertoire), le code d'erreur et la description de l'erreur. Pour reprendre votre travail, cliquez sur le bouton « réessayer » en bas à droite pour relancer le calcul d’empreinte.

Pour sauvegarder son travail et retrouver l’ensemble de ses enrichissements, il suffit de cliquer sur la petite disquette en haut à droite. Une fenêtre de dialogue s’ouvre pour choisir le lieu d’enregistrement de votre session de travail. Le fichier généré est un format JSON. Ce fichier JSON peut être redéposé dans Archifiltre suite à la sauvegarde. Lorsqu'on redépose ce fichier, s’ouvre alors votre arborescence et l’ensemble des enrichissements réalisés auparavant.

Attention : Certains utilisateurs n’ont pas d’extension lors de l’enregistrement du fichier. Il convient alors d’écrire soi-même l’extension « .json » pour le bon déroulement de l’enregistrement : « nomdufichier.json ».
Découvrez l'onglet « général » en moins de 5 minutes grâce à notre tutoriel vidéo ! 👇

L’onglet général a pour objectif de nous aider à appréhender l’arborescence à analyser. Dans cet onglet, nous avons l’ensemble des métadonnées et caractéristiques de l’arborescence et des éléments. A cela s’ajoute l’ensemble des outils de visualisation pour prendre en main et guider notre analyse.
Pour une meilleure immersion et visualisation de l’arborescence à analyser, il est possible de masquer l’onglet des caractéristiques en cliquant sur le bouton « masquer » en haut à droite de la zone des caractéristiques.
Dans la partie gauche de la zone des caractéristiques nous retrouvons l’ensemble des métadonnées relatives à l’arborescence.
Nous visualisons son nom (modifiable en cliquant sur le crayon), le nombre de dossiers, de fichiers et sa volumétrie (en octet, mégaoctet ou gigaoctet). Enfin, nous avons les dates extrêmes de l’arborescence avec la date du fichier le plus ancien et celle du fichier le plus récent.
A droite de la zone des caractéristiques, nous retrouvons l’ensemble des métadonnées relatives à l’élément sélectionné dans l’arborescence.
Nous avons son nom, sa volumétrie (en octet, mégaoctet ou gigaoctet), son mime type (son identifiant de format de données), son hash (empreinte) et les dernières dates de modification.

En cliquant sur un dossier ou sur un fichier, les données propres à l’élément s’affichent dans la zone des métadonnées, mais également en bas de la visualisation avec la taille de l’objet et aussi le pourcentage de l’espace qu’il occupe au sein du répertoire total.

| FOCUS | Explication |
|---|---|
| Qu'est-ce que la date médiane ? | Nous avons fait le choix de la date médiane. La date médiane est la date à laquelle la moitié des fichiers contenus dans ce dossier ont été « clôturés ». Il y a autant d’éléments modifiés avant qu’après cette date médiane. La date moyenne n’est pas une valeur fiable, elle est inexploitable si un dossier contient un fichier très ancien ou très récent, dénotant avec l’ensemble du contenu. |
| Qu'est-ce que le hash ? | Le hash est le résultat d'un calcul informatique qui attribue à un élément un code. Ce code est attribué en hashant (d'où le nom) l'ensemble du contenu de l'élement. Ainsi, un document ne peut avoir qu'un code unique (comme un code génétique). Si deux documents sont identiques, ils auront alors le même code. Si un document est modifié, ne serait-ce que d'une virgule, son code est également modifié. Pour plus d'informations veuillez consulter ce lien. A noter : Le hash d’un dossier parent est calculé à partir du hash des dossiers et fichiers enfants. |

Par volume : c’est l’option de visualisation qui est activée par défaut. Elle permet de voir votre arborescence selon une pondération par volume/poids (en octets) de vos dossiers: l'élément affiché en 1er est plus volumineux que le second, etc.
Par dates : cette visualisation classe les dossiers et fichiers des plus anciens aux plus récents.
Par ordre alphanumérique : cette visualisation classe les éléments dans l’ordre alphanumérique. Cette visualisation nous permet donc de retrouver le classement des dossiers comme sur notre explorateur de fichiers sur notre ordinateur.

Par volume : c’est l’option de visualisation qui est activée par défaut. Elle permet de voir votre arborescence selon une pondération par volume/poids de vos dossiers. Le dossier le plus volumineux est le dossier prenant le plus de place visuellement.
Par nombre : C’est une solution alternative pour visualiser votre arborescence. L’ordre affiché du répertoire reste le même, mais la pondération se fait selon le nombre de fichiers contenus dans les dossiers. Un dossier avec de nombreux fichiers, même peu volumineux, apparaîtra plus grand qu’un dossier contenant peu de fichiers.

Par type : La visualisation se repose sur une différentiation entre les dossiers les typologies de fichiers. Au plus bas de votre répertoire, vous visualisez les fichiers. Des codes couleurs ont été attribués aux fichiers selon leur nature. Ils reprennent en partie les couleurs utilisés par les logiciels de bureautique : rouge foncé (pdf), rouge clair (présentations de type Powerpoint), vert (tableurs), bleu clair (messageries), bleu foncé (traitement de texte), violet clair (images), violet foncé (vidéo), rose (fichiers audio) et gris (tous les autres formats y compris dossiers compressés, formats particuliers). Vous pouvez connaître les extensions inclues dans les typologies en téléchargeant l'export « rapport d'audit ».

Par dates : l’affichage pondéré est celui que vous avez choisi. En revanche, l'ordre classement et les couleurs attribuées aux dossiers et aux fichiers dépendent de leurs métadonnées de dates. Le classement se fait du plus ancien au plus récent et se visualise par une couleur foncée pour ce qui est ancien et une couleur claire pour ce qui est récent.

Si vous souhaitez naviguer plus profondément dans l’arborescence, il suffit de double-cliquer sur l'élément pour effectuer un zoom. En zoomant, cela repondère à nouveau la visualisation avec les éléments fils. Si vous souhaitez revenir sur la visualisation d’ensemble, il suffit de cliquer sur le bouton en haut à gauche « retour à la racine ».



Il est possible d'effectuer un zoom lorsqu'Archifiltre ne peut afficher tous les éléments. En effet, s'il y a de nombreux éléments et que les volumes sont petits, alors la visualisation par volume ou par nombre ne permet pas de voir tous les éléments. Pour pouvoir les visualiser il faut approcher son curseur de la zone en question et d'utiliser la roulette de sa souris vers l'avant. Si vous n'avez pas de souris, il est possible d'utiliser le touchpad en mettant deux doigts sur celui-ci et en allant vers l'arrière. Vous pouvez retrouver la démonstration en vidéo ICI
Le fil d'Ariane permet de suivre le chemin d’accès du dossier parents jusqu’à l’élément enfant qu'on étudie. On peut également copier le chemin d'accès en sélectionnant le niveau du chemin d'accès désiré puis en cliquant sur la petite icône apparaissant à côté. Lorsqu'un élément est renommé, il est possible de voir l'ancien nom dans le fil d'Ariane, il apparait en italique et entre parenthèses.

La copie du chemin d'accès peut être utile lors de l'enrichissement d'une arborescence pour réaliser un lien (dans un tag ou une description) entre deux éléments. Les deux unités peuvent être enrichies par les chemins permettant de faire un lien intellectuel entre les deux.
Elle vous permet de savoir où vous êtes dans l’arborescence, lorsque vous naviguez au sein de celle-ci. Lorsqu’on descend de plusieurs sous-niveaux, la carte vous permet de vous resituer dans l’arborescence, dans la zone en surbrillance.
Peut être utile lors d'une analyse pour un audit ou pour un traitement afin d’orienter son niveau d’analyse. Lorsqu’on étudie une partie infinitésimale de l’arborescence, mieux vaut ne pas s’y attarder trop longtemps.

Depuis Archifiltre, il est possible de consulter un élément, que ce soit un dossier ou un fichier. Pour cela il suffit de cliquer sur un élément, puis sur la petite loupe dans la zone des caractéristiques de l’élément. Le document ou le dossier sélectionné s’ouvre. Cela n’est possible que si la connexion n’est pas rompue. Il n’est pas possible de consulter un document issu d’un espace serveur si nous n’avons plus la connexion à celui-ci, par exemple.

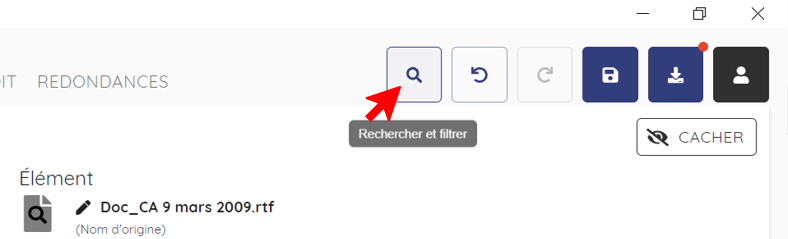
Pour rechercher un élément au sein de l’arborescence, il est possible de cliquer sur la petite loupe en haut à droite « rechercher et filtrer ». La recherche va s'effectuer dans le nom des éléments. Il est possible d'appliquer en plus des filtres à sa recherche (préciser le type, la taille ou le tag) mais aussi de trier les résultats en triant selon les colonnes du tableau (nom, type, taille, dernière modification, chemin). Lorsque l'élement recherché est retrouvé, il est possible de cliquer sur l'oeil pour retrouver sa localisation dans l'arborescence ou de lui appliquer le tag « à éliminer ».

Cet onglet a pour objectif d’enrichir et d'améliorer l’arborescence à travers l’ajout de métadonnées : renommage, tag, description, reclassement.
Découvrez l'onglet « enrichissement » en moins de 5 minutes grâce à notre tutoriel vidéo ! 👇

Dans cet onglet, l'essentiel des actions se déroulent dans la zone des métadonnées. Nous allons présenter chaque actions, leur fonctionnalités, quand et comment les utiliser. A chaque élément sélectionné, la zone des métadonnées vous renseigne sur le nom de l'élément, sa volumétrie, son mime-type (son identifiant format de donnée), son hash (empreinte) et les dernières dates de modifications.

Il est possible de renommer un élément (fichier ou dossier) en cliquant sur son titre.
Le renommage n’est effectif que dans Archifiltre. En renommant, vous attribuez un nouveau nom à l’objet tout en conservant l’ancien nom (visible entre parenthèses en dessous, ou dans le fil d'Ariane). Le renommage se retrouve dans l'export csv (deux colonnes : nom et nouveau nom). Il est possible d'appliquer les renommages, en masse, à partir d'un script. Pour un versement vers un SAE, le renommage sera automatiquement pris en compte.
La visualisation d'un renommage dans Archifiltre est notifiée par un liseré bleu clair dans les stalactites.
Cette fonctionnalité peut être utile dans le cadre d’une proposition de modification de l’arborescence ou bien lors du traitement d’un fonds électronique vers un SAE.

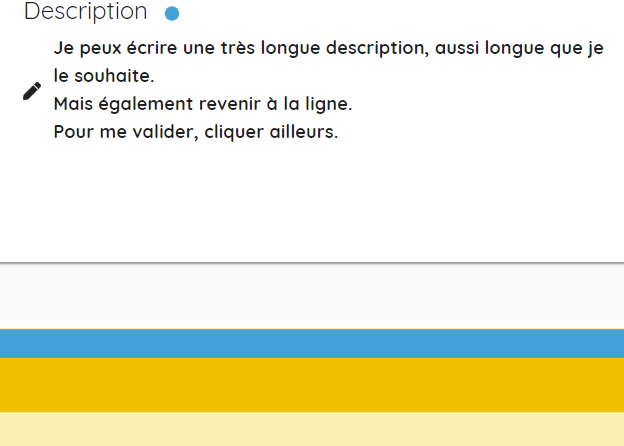
La description permet d’ajouter à un dossier ou à un fichier des informations. Plusieurs types d'informations peuvent être rajoutées, il n'y a pas de limites. Dans un cadre d'audit ou de collecte, cela peut être une remarque, un échange avec le service, la justification d'un tag ou la justification de l'élimination. Pour un traitement pour un versement dans un SAE, la description équivaut à la « Présentation du contenu » (ISAD-G) ou « scope content » (balise de l'EAD).
La visualisation de l'ajout d'une description se fait avec un liseré bleu sur l'item enrichi.
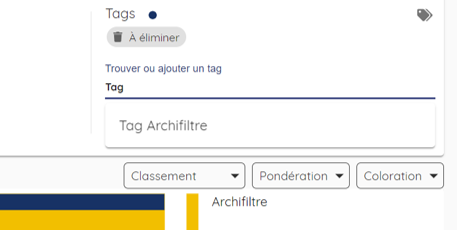
Le tag permet d’appliquer à un dossier ou à un fichier une information concise. Cet tag s’ajoute à la bibliothèque des tags. Pour appliquer un tag, il suffit de le taper dans la zone de texte, si le tag existe déjà, il est alors immédiatement proposé. Pour supprimer un tag sur un élément, il faut sélectionner l’élément, aller dans la zone « tag » et cliquer sur la petite croix à droite du tag en question.
Le tag peut être utile dans le cadre d’un audit en appliquant des actions à réaliser (à éliminer, à archiver, à transférer…) ou dans le cadre du traitement en appliquant une action, un terme d'indexation ou pour faire un rapprochement intellectuel entre deux éléments dans l’arborescence (du type répertoire méthodique).
Lorsqu’un tag est appliqué, il se visualise par un liseré bleu foncé sur le haut de l'item.
Attention, lorsqu'on applique un tag sur un dossier, le tag s’applique du niveau parent ainsi qu'à tous les éléments fils.
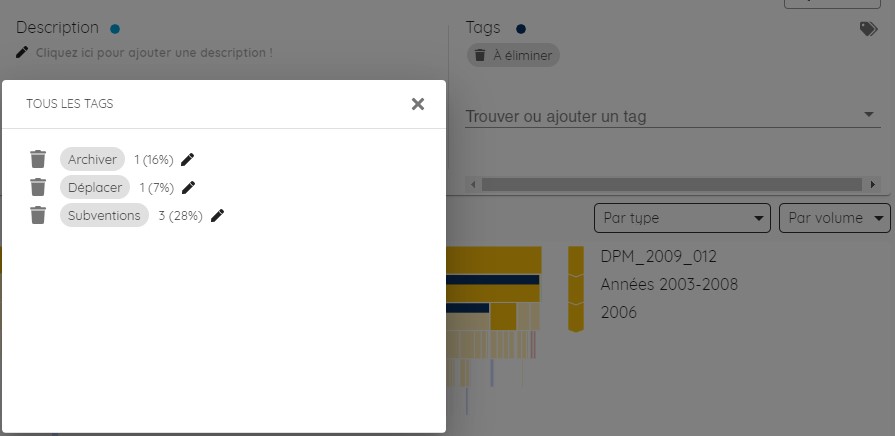
Elle permet de retrouver l’ensemble des tags qui ont été appliqués dans l'arborescence analysée. Cette bibliothèque également d'avoir des élements de statistiques : comptabiliser le nombre de tags et la volumétrie sur laquelle ils ont été appliqués (données en pourcentage). Il est possible de supprimer l’ensemble du tag appliqué dans l’arborescence en cliquant sur la corbeille. Il est aussi possible de renommer un tag depuis la bibliothèque en cliquant sur le petit crayon.
La bibliothèque de tag peut être utile pour faire un retour le traitement effectué avec le pourcentage d'éléments à éliminer, etc.
Ce tag est un tag automatisé qui permet d'appliquer, virtuellement, l'action « à éliminer » à un élément ou à un ensemble d'éléments du répertoire. Ce tag automatisé a plusieurs actions :
Il permet de rédiger un bordereau d'élimination. Lorsqu'il est appliqué, il suffit de télécharger le rapport d'audit et de se rendre sur la dernière page du document. Vous retrouverez un bordereau d'élimination. Pour avoir la liste entière (récolement) de l'ensemble des éléments éliminés, il convient de télécharger un export csv ou excel (voir colonne « à éliminer »).
Il permet également de supprimer les éléments tagués de l'export ReSIP ou METS. Ainsi les éléments ne sont pas importés dans le SAE.
Ce tag se matérialise par un liseré rouge sur l’élément.
Pour supprimer ce tag, il suffit de cliquer sur l’élément en question puis sur la petite corbeille à gauche du tag.

Archifiltre affiche les métadonnées de dates provenant du système d'exploitation. Or il est possible que le système d'exploitation affiche des dates incohérentes (par exemple des dates postérieures à celle du jour). Il est donc possible de corriger ces erreurs dans l'outil. Lorsqu'on corrige une date, les métadonnées de dates extrêmes des parents sont modifiées. L'ensemble des exports reprennent également la date corrigée.
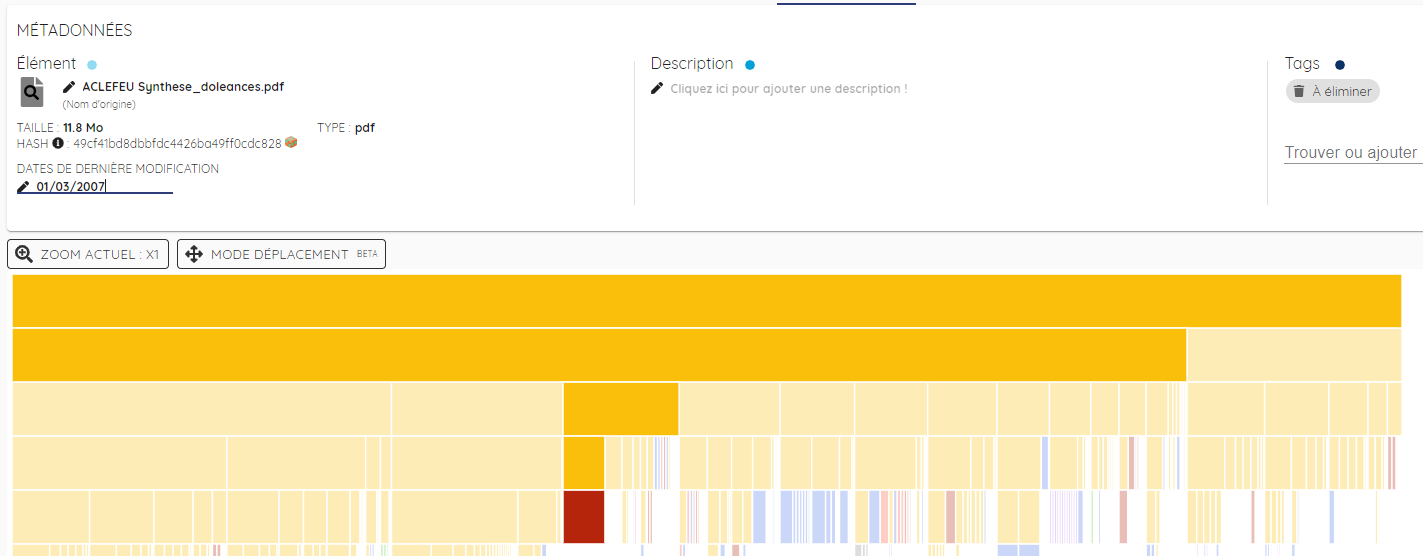
Ce mode, encore en développement, permet de déplacer des éléments au sein de l’arborescence. Les déplacements ne sont effectifs que dans Archifiltre, en mode image. Pour déplacer un élément, cliquer sur le bouton « mode déplacement ». Sélectionner l’élément, et faites-le glisser jusqu’au dossier parent de destination (il est important de le placer dans le niveau n+1 pour qu'il s'intègre au niveau fils souhaité).
Une fois l’élément déplacé, il est visualisable quelques secondes avec un encadré rouge. Si vous souhaitez annuler l’opération, cliquer sur le bouton « annuler » en haut à droite d’Archifiltre ou avec le raccourci clavier [ctrl]+[Z].
Lorsqu’on effectue un déplacement dans un Archifiltre, cet enrichissement se retrouve à différents endroits. Il est visualisable immédiatement dans Archifiltre mais aussi à partir de l’export csv (champ « nouveau chemin ») ainsi que dans l’export ReSIP. Le reclassement est donc effectif dans le SAE et conserve la métadonnée de l’ancienne localisation de l’élément.

Cet onglet a pour objectif d’étudier l’arborescence dans une approche d’analyse et audit à l'échelle macro.
Il est possible dans cet onglet d’étudier le nombre de fichiers de l’arborescence et le niveau de profondeur de l’arborescence. Un graphique permet également de connaître la répartition des fichiers par type.
Il est possible de générer un rapport d’audit depuis la fenêtre des exports d'Archifiltre. Ce rapport d’audit, au format d'un fichier de traitement de texte, peut être modifié, autant que l’on souhaite. Dans ce rapport, sont présentés automatiquement :
- Les chiffres clés de l’arborescence
- La répartition des éléments par type d’extension
- Un top 5 des répertoires/dossiers les plus anciens
- Un top 5 des répertoires/dossiers les plus volumineux
- Chiffres clés sur les doublons
- Un top 5 des éléments les plus récurrents dans l’arborescence
- Un top 5 des éléments présents plusieurs fois les plus volumineux
- La liste des éléments ayant le tag « à éliminer »
Pour voir plus précisément le contenu du rapport d'audit, cliquer sur le lien suivant : Le rapport d'audit

Découvrez l'onglet « Redondances » en moins de 5 minutes grâce à notre tutoriel vidéo ! 👇
Dans cet onglet, l’objectif est de pouvoir travailler sur les éléments en redondances dans l’arborescence.
Pourquoi avons-nous fait le choix d’utiliser le terme de « redondance » plutôt que celui de « doublon », plus commun ?
D’une part, nos expériences nous permettent de nous rendre compte que nous retrouvons bien plus qu’un doublon dans les arborescences. D’autre part, le terme de « doublon », dans le jargon archivistique, sous-entend l’inutilité du deuxième élément. Or, la présence d’une information à plusieurs endroits peut avoir un sens. Si le calcul d’empreintes nous permet de retrouver l’ensemble des redondances, le SEDA 2.1 nous permet également de conserver un seul fichier et les métadonnées des localisations. Redondance ne rime pas avec impertinence. Attention donc aux apriori !

Dans cet onglet, Archifiltre nous renseigne sur la part des redondances (en orange) sur l'ensemble sur versement (en gris). Parmi ces redondances, une répartition nous est présentée sous la forme d'un graphique mais aussi d'un tableur avec le type, le nombre de fichiers, l'espace occupé sur l'arborescence et le pourcentage que cela représente.

La deuxième partie de l'onglet est la liste de l’ensemble des éléments redondants de l’arborescence. Ce regroupement des redondances permet, outre une meilleure lisibilité, de réfléchir à leur existence et de déterminer, si nécessaire, l’élément de référence. L'élément redondant peut être tagué « à éliminer », si l'ensemble des redondances sont à éliminer, il est possible d'appliquer le tag sur la ligne supérieure pour l'appliquer aux lignes inférieures.
Enfin, pour faciliter l’accès aux éléments redondants, un moteur de recherche permet de saisir les mots clefs pour retrouver les éléments redondants que l’on souhaite étudier.

Pour rechercher un élément au sein de l’arborescence, il est possible de cliquer sur la petite loupe en haut à droite « rechercher et filtrer ».
Il est possible d'appliquer des filtres à sa recherche (préciser le type, la taille ou le tag) mais aussi de trier les résultats en triant selon les colonnes du tableau (nom, type, taille, dernière modification, chemin). Lorsque l'élément recherché est retrouvé, il est possible de cliquer sur l'oeil pour retrouver sa localisation dans l'arborescence ou de lui appliquer le tag « à éliminer ».
La liste des résultats peut être également exportée au format csv en cliquant sur le bouton « exporter ».
Lorsqu’on a identifié un élément, il est possible de cliquer sur l’œil, tout à droite de la ligne. Cela renvoie à l’arborescence et montre où se situe l’élément.
Pour une recherche plus fine et/ou l’application d’un plus grand nombre de filtres, il convient de générer le csv de l’arborescence depuis les exports d’Archifiltre. L’export csv a la complétude d’un récolement de l’ensemble des fichiers et dossiers de l’arborescence et contient l’ensemble des enrichissements.

Pour réaliser un export depuis Archifiltre, il suffit de cliquer sur le bouton en haut à droite "exporter". Une fenêtre s'ouvre et propose de télécharger différents exports. Il est possible de tous les sélectionner et de choisir un dossier de destination commun. Il également possible de faire cette action unitairement.
Attention : Il n'est pas possible de choisir un autre lieu d'enregistrement pour l'export ReSIP. Il doit obligatoirement être téléchargé à la racine du répertoire étudié.

Il est possible de générer un rapport d’audit depuis Archifiltre. Le rapport d'audit permet de générer automatiquement l'analyse de nombreuses données et de les structurer. Ce rapport d’audit est édité dans un fichier de traitement de texte et peut être modifié et complété.
1 Les chiffres clés sur l’arborescence :
Dans cette première partie, il s’agit de faire un état des lieux de l’arborescence du service audité : le nombre de dossiers, le nombre de fichiers, le volume de l’arborescence, les dates extrêmes, le nom du fichier le plus long, le chemin d’accès le plus long et le nombre de niveaux de profondeur maximum. L’objectif de cette première partie est de donner, à une échelle macro, les premiers problèmes de l’arborescence.

2 Répartition des éléments par types d’extension :
Cette rubrique a pour objectif de pondérer l’arborescence selon les types de fichiers produits. Cette indication n’est qu’un élément d’orientation pour un audit. Par exemple, la présence en masse de fichiers de type tableur peut indiquer la conservation d’un grand nombre de fichiers de suivi ou d’export de logiciels. Une présence très importante de fichiers de type média peut indiquer une utilisation non appropriée ou abusive de l'espace réseau commun.

3 Top 5 des répertoires/dossiers le plus anciens :
Dans cette partie, sont mis en avant les dossiers dont les dernières dates de modification sont les plus anciennes du répertoire. Cette information peut être une orientation pour collecter ou éliminer réglementairement ces dossiers.

4 Top 5 des répertoires/dossiers les plus volumineux :
A l’instar des archives papier, la volumétrie reste toujours un premier indicateur pour approcher un fonds à évaluer, collecter, traiter.

5, 6 et 7 Les redondances :
Dans ces deux parties, sont renseignés les éléments en redondance au sein du répertoire avec une estimation du volume et de la quantité que cela représente.



8 Liste des éléments à éliminer
Dans cette partie, nous avons une liste générée automatiquement dès que nous utilisons le tag « à éliminer ». Cette partie est donc une aide synthétique pour la rédaction d'un bordereau d'élimination.

En bref,
| Données clefs sur l'arborescence | Top 5 |
|---|---|
| - Les chiffres clés de l’arborescence | - Un top 5 des répertoires/dossiers les plus anciens |
| - La répartition des éléments par type d’extension | - Un top 5 des éléments les plus récurrents dans l’arborescence |
| - Chiffres clés sur les doublons | - Un top 5 des éléments présents plusieurs fois les plus volumineux |
| - La liste des éléments ayant le tag « à éliminer » | - Un top 5 des répertoires/dossiers les plus volumineux |
L’export csv est un tableur contenant l’ensemble des métadonnées des éléments analysés. Chaque ligne du tableur correspond à un fichier ou un dossier de l’arborescence. Dans le csv, sont présentés :
| Chemin d'accès | longueur du chemin d'accès | Nom de l'élément | Extension | Poids (en octet) | Date de première modification | Date de dernière modification | Nouveau chemin d'accès | Nouveau nom | Description | Fichier/Répertoire | Profondeur | Nombre de fichiers | Type | Empreintes | Redondances | Tag 1 | Tag 2 | ... |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| \Users\utilisateur\Documents\Archifiltre\wiki.doc | 53 | wiki.doc | 649500 | 12/11/2020 | 12/11/2020 | Notice utilisateur | fichier | 4 | 1 | msword | 155b1c8627cd936f34a0c499c1a22625 | Non | Tag 1 | Tag2 | ... |
Attention : Il est possible qu’en ouvrant le csv avec Microsoft Excel, les accents ne soient pas lisibles. Pour régler le problème il faut ouvrir Excel, aller dans l’onglet « données », sélectionner « données externes » puis fichier texte. Lorsque la fenêtre de dialogue est ouverte, sélectionner le csv exporté depuis Archifiltre. Une nouvelle fenêtre s’ouvre, pour l’information « origine du fichier », sélectionner « 65001 : Unicode (UTF-8) » (en bas de la liste), puis cliquer sur suivant. Pour l’information séparateurs, sélectionner « point-virgule ». Cliquer sur suivant puis terminer. Le csv est ouvert et lisible dans Excel.
Découvrez comment régler le problème de l'accentuation en 2 minutes grâce à notre tutoriel vidéo ! 👇
L'export csv hiérarchisé permet de voir d'une autre façon l'arborescence étudiée. Chaqueniveau correspond à une colonne du tableau.
| Colonne 1 | Colonne 2 | Colonne 3 | Colonne 4 | Colonne 5 | Colonne 6 |
|---|---|---|---|---|---|
| Niveau 1 | |||||
| Niveau 2 | |||||
| Niveau 3 | |||||
| fichier | |||||
| fichier | |||||
| Niveau 2 | fichier | ||||
| Niveau 3 | |||||
| fichier |
L’export contient exactement les mêmes données que les csv. En revanche, il contient deux onglets, l'un avec le récolement de toutes les métadonnées, l'autre avec la forme hiérarchisée des éléments de l'arborescence (une colonne par niveau d'arborescence).
L’export ReSIP est un export au format csv qui est exploitable par le logiciel ReSIP (développé par le programme VITAM)
Dans cet export est indiqué au format SEDA 2.1
| ID | Parent ID | File | DescriptionLevel | Title | StartDate | EndDate | TransactedDate | CustiodalHistory | Description | Content.tag |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | \Users\utilisateur\Documents\Archifiltre\wiki.doc | wiki.doc | Item | 07/10/2012 | 07/10/2012 | 12/11/2020 | Cet élément était originellement intitulé "XX" | Description | tag1 |
Le format METS est un format créé par la Digital Library Foundation et maintenu par la Bibliothèque du Congrès. En France, il est principalement utilisé par les bibliothécaires, notamment à la Bibliothèque nationale de France.
Cet export a la même constitution qu'un SIP (Submission Information Package) selon la norme OAIS (Open Archival Information System). Il est constitué d'un manifeste (= bordereau de versement) et des objets à archiver, le tout sous un format compressé. La différence est que dans le manifeste, les champs renseignés sont différents. Le format METS peut renseigner l'ensemble de ces éléments :
| Colonne | Description |
|---|---|
| metsHdr | donne des informations sur le fichier METS lui-même : par exemple la date de création et de dernière modification du fichier, le créateur du fichier, identifiant du fichier… |
| dmdSec | comprend l’information bibliographique ; il peut également servir à décrire des sous parties d’un document (page d’un livre, face d’une cassette audio…) ; |
| amdSec | comprend des métadonnées de gestion du document numérique décrit, divisées en 4 sous-sections : |
| sourceMD donne des informations sur la source dont le document numérique décrit est issu ; par exemple il s’agit du document physique original dans le cas d’une numérisation ; | |
| techMD donne des informations techniques sur le document dans son ensemble (identifiants, version…) ainsi que sur chacun des fichiers qui le composent (format de fichier, caractéristiques techniques du fichier) ; | |
| digiprovMD donne des informations sur l’historique du document numérique, depuis sa création (numérisation, océrisation…) jusqu’au moment présent en passant par toutes les opérations (entrée dans un entrepôt, conversion de format…) qu’il a pu subir ; | |
| rightsMD donne des informations sur le statut juridique du document : libre de droit / sous droit, et les restrictions de communication qui en découlent (diffusable ou non, copie autorisée ou pas, etc.) ; | |
| fileSec | fait l’inventaire de l’ensemble des fichiers qui composent le document, qu’il classe en différentes familles nommées « fileGrp » (par exemple : master, ocr, table des matières…). Il exprime les caractéristiques techniques de base de chacun de ces fichiers : taille, empreinte, emplacement du fichier… ; |
| structMap | (seule section obligatoire) décrit une structure du document, qui correspond à la fois à un mode de navigation particulier et à une vue particulière sur le document. Chacune de ces cartes de structure permet d’identifier plusieurs niveaux de granularité dans le document : |
| Types de cartes de structure | La carte de structure par défaut est physique, et peut être complétée par des cartes de structure de type logique. Une carte de structure physique exprime une navigation linéaire dans le document et correspond à la manière dont le document numérique est segmenté — par exemple numérisation et navigation page à page pour un imprimé — tandis qu’une carte de structure logique permet une navigation non linéaire et indépendante de la manière dont le document a été numérisé (par exemple table des matières structurée en XML permettant de naviguer dans un ouvrage numérisé) ; |
| niveaux de granularité | Chaque carte de structure exprime les différents niveaux de granularité qui composent le document. Par exemple : titre de périodique, fascicule, page, fichier constituent 4 niveaux de granularité différents d’un périodique numérisé. Ce système permet, grâce à des liens internes, de relier toute information exprimée dans une ou une sous-section au niveau de granularité adéquat. Par exemple, la description bibliographique concerne le document dans son ensemble, tandis que le signalement d’une page particulière comme une page de titre ne concernera qu’un élément particulier. |
| structLink | permet d’exprimer des liens structurels entre différents éléments du document, par exemple des hyperliens entre une page et une autre si le document décrit est un site Web ; |
| behaviorSec | permet d’associer explicitement des fichiers à des programme permettant de les lire. |
Cette partie s'appuie sur un article de la BnF, pour le retrouver et se documenter d'avantage, cliquer sur le bouton suivant : 
Lorsque plusieurs éléments sont taggués "à éliminer" dans Archifiltre, il est possible de télécharger un script de suppression. Pour exécuter ce script, il suffit de télécharger cet export, de faire un clique-droit dessus puis de cliquer sur "Exécuter avec PowerShell". Vous pouvez retrouver une démonstration vidéo en cliquant ICI.
Attention : Lorsqu'on exécute ce script, cette action est irrémédiable. Il n'est pas possible d'annuler la suppression des éléments.

Le génie d’Archifiltre vous permet de réaliser tous vos souhaits, il ne reste plus qu’à le choisir !

Dans cette situation, la visualisation d’Archifiltre est pondérée par le poids/volume des dossiers. Cette visualisation permet, en quelques secondes, de constater que le répertoire n’est pas construit dans une logique fonctionnelle ou organisationnelle. Dans cet exemple, le dysfonctionnement se remarque dès le deuxième niveau du répertoire.
Que faire ? Analysez le répertoire en ayant connaissance de l’organigramme et des grandes fonctions de la structure. Par exemple, si on analyse le répertoire d’un service d’archives, il ne sera pas difficile d’y retrouver dès les premiers niveaux, ses grandes missions : collecte, classement, conservation, communication avec quelques dossiers liés à tous les services : gestion du personnel, documentation… Une visualisation à plat sans pondération doit permettre de dégager l’organisation du service. La visualisation pondérée va permettre de voir l'équilibre du fonctionnement et que tout ne se retrouve pas dans un seul dossier du deuxième niveau.
Attention : Ce cas fonctionne dans le cas où l’arborescence est essentiellement constituée de fichiers bureautique. Si un dossier comporte plusieurs fichiers volumineux (type multimédia) alors la visualisation peut être faussée. Pour s’en assurer, il convient d’essayer une visualisation pondérée selon le nombre. Cette visualisation pondère selon le nombre de fichiers/dossiers contenus dans le dossier parent.

Avant d’entrer plus en détail dans un répertoire, il est important d’en étudier sa structure avec les différentes visualisations d'Archifiltre. Ici, il n’est pas difficile de voir que l’arborescence présente quatre fois une structuration similaire.
Pour qu'un tel résultat apparaisse dans une visualisation pondérée par le volume et au niveau globale du répertoire, il y a deux possibilités :
- Il y a un classement sériel (type chronologique, géographique…), les documents sont plus ou moins les mêmes, d'où leur ressemblance en volumétrie
- Il y a des dossiers très similaires créés à des endroits différents et qui comportent plusieurs redondances.
Que faire ? Pour déterminer plus précisément la situation à laquelle on est confronté, il est inévitable de rentrer plus en profondeur dans l’analyse de ces dossiers. Dans cet exemple, des dossiers et des fichiers de mêmes noms ont été retrouvés. Pour déterminer si les dossiers sont de véritables doublons, l'empreintes des dossiers et fichiers doit être utilisée. L'onglet « redondances » permet de retrouver l'ensemble des redondances et de faire le tri. Il est possible que ce ne soit pas de pures redondances s'il y a quelques fichiers de différences entre ces quatre structures. Il convient alors de faire un récolement (via le csv ou Excel) de ces quatre structures et de les comparer.
Attention : Réaliser un dé-doublonnage est plus compliqué qu’il n’y paraît. Dans cet exemple, il faut déterminer les différences entre ces quatre arborescences : Où sont les fichiers définitifs ? Est-ce qu’on retrouve l’intégralité des fichiers dans la plus grosse arborescence ? Quelle arborescence fait référence ? Un logiciel de dé-doublonnage va supprimer les fichiers sans avoir une logique de tri. La visualisation de doublons impose donc un travail de réflexion en amont et de choix d'évaluation en fonction de la connaissance du contexte. Par ailleurs, il n'est pas forcément nécessaire de dé-doublonner, cela peut avoir du sens et aider à comprendre la logique du producteur. Dans le cas d'un versement dans un SAE, le manifest du SIP peut faire référence plusieurs fois à un même élément mais cet élément ne sera conservé qu'une seule fois, il n'y a donc plus de redondances stricto sensu.

La visualisation de l'ensemble d’une arborescence peut donner les premières clefs d’une analyse ou d'un audit. Toutefois, certains services peuvent être amenés à avoir une production sérielle, qui peut être classée de façon chronologique. A plus ou moins grande échelle, tous les bureaux ont une partie d’arborescence sérielle. Le chrono-courrier d’un secrétariat, les dossiers de gestion annuelle d’un bureau des ressources humaines, le registre d’entrée ou d’élimination du bureau des archives, etc. Cette structuration est plus difficile à aborder.
Que faire ? Pour une analyse du répertoire à échelle macro, la visualisation pondérée n’apporte aucune plus-value. En revanche, il est possible de s’appuyer sur l’ensemble des métadonnées pour aborder l’arborescence d’une autre manière. Lorsqu’un répertoire a une date de dernière modification qui remonte à plusieurs années, on peut considérer alors que ce dossier est clos. A l’instar du papier, il est possible de débuter l’évaluation. Il est possible de classer l'arborescence par date ou de lui appliquer une coloration par dates pour une première approche.
Attention : Bien qu’il soit simple et efficace, le classement chronologique ne peut être utilisé que partiellement.
Visualisation par poids :

Étudier une arborescence contenant des fichiers volumineux n’est pas pertinent avec la pondération par poids. De fait, plus un fichier est volumineux, plus sa visualisation au sein de l’arborescence est importante. Si le volume par poids peut être un indicateur de tri, il n’est pas forcément un bon indicateur dans un audit ou une opération de collecte. Avec la pondération par poids, notre arborescence ci-dessous, nous oriente vers une priorisation du tri du premier et du deuxième dossier au premier niveau.
Visualisation par nombre :

Si on utilise la visualisation par nombre, avec la même arborescence, les indicateurs sont totalement différents. Ce changement de visualisation offre une nouvelle grille d’analyse de l’arborescence. Dans ce deuxième exemple, on constate que le troisième dossier dispose d’une arborescence complexe et d’une profondeur dépassant les 15 niveaux. Son analyse est donc à prioriser.
Attention : Ces indicateurs ne sont que des éléments d'analyse pour appréhender l'arborescence. Lorsque nous sommes confrontés à un archivage papier à réaliser, nous quantifions toujours ce qu'il y a à traiter pour définir notre plan d'action et adapter nos méthodes de travail selon le volume. Nous n'allons pas traiter de la même manière l'archivage d'une armoire, d'un local ou d'un service entier. Cette capacité d'adaptation de l'archiviste, se transpose ici, en électronique, avec les différents outils de visualisation.
Lorsqu’on génère un rapport d’audit automatiquement depuis Archifiltre, de nombreuses données sont analysées et structurées dans un fichier texte. Le rapport d'audit permet une analyse macro de l'arborescence. Pour retrouver le contenu plus précisément du rapport d'audit, cliquer sur le lien suivant : Le rapport d'audit
Comme pour un audit d'archives papier, le rapport d'audit nous permet d'avoir des données quantifiées ce qui nous permet de pouvoir appréhender le travail à réaliser.
Le chemin d’accès d’un élément est la chaîne de caractères décrivant la position de l'élément dans le système. En d’autres termes, le chemin d’accès, est l’ensemble des niveaux en partant du disque dur ou du serveur, jusqu’au fichier/dossier. Le fil d’Ariane dans Archifiltre est une partie du chemin d’accès.

Pourquoi faut-il étudier les chemins d’accès ?
Pour des raisons techniques, les chemins d’accès ne peuvent dépasser 256 caractères dans la plupart des environnements Windows. Cette limite peut vite être atteinte avec une arborescence trop profonde. Elle peut également être vite atteinte à cause du nommage d’un fichier trop long. Quand la limite des 256 caractères est dépassée, les fichiers ne peuvent plus être consultés ou déplacés dans le répertoire.
Par exemple un fichier situé à un niveau 4, peut déjà être bloquant s’il est mal nommé.
J://Direction/Archives/0_Procédures-et-doc/Textes/loi n 78-753du 17 juillet 1978 portant diverses mesures d'amélioration des relations entre l'administration et le public et diverses dispositions d'ordre administratif social et fiscal
Dans cet exemple, le fichier a simplement été enregistré sans être renommé. Le chemin d’accès atteint déjà 235 caractères sur 256.
Pourquoi faut-il surveiller la longueur des chemins d’accès de mon répertoire ?
Un fichier dont le chemin d’accès dépasse le cadre maximal ne peut plus être consulté ni même déplacé. De même, lorsqu’on souhaite déplacer des dossiers, le transfert peut être bloqué en raison de chemins d’accès trop longs. Cela peut être également bloquant pour un versement dans un SAE.
Comment identifier l’ensemble de mes chemins d’accès trop longs ?
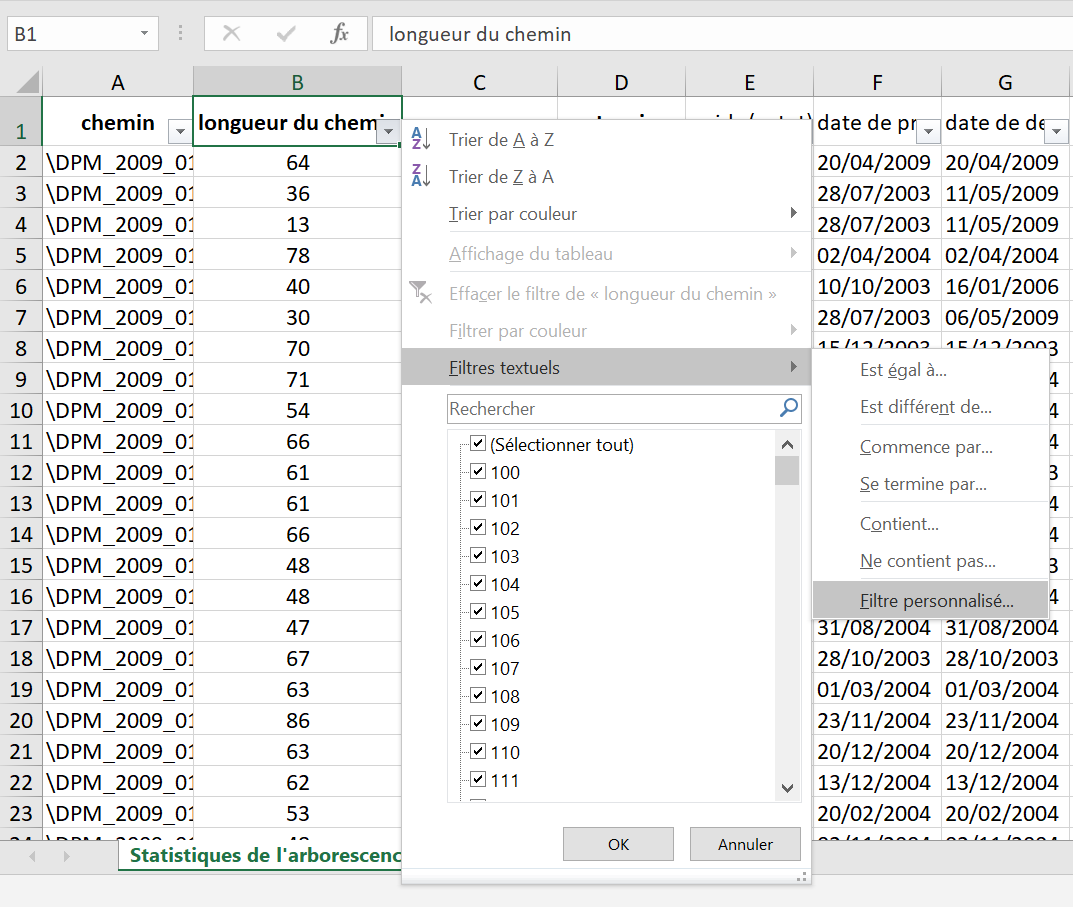
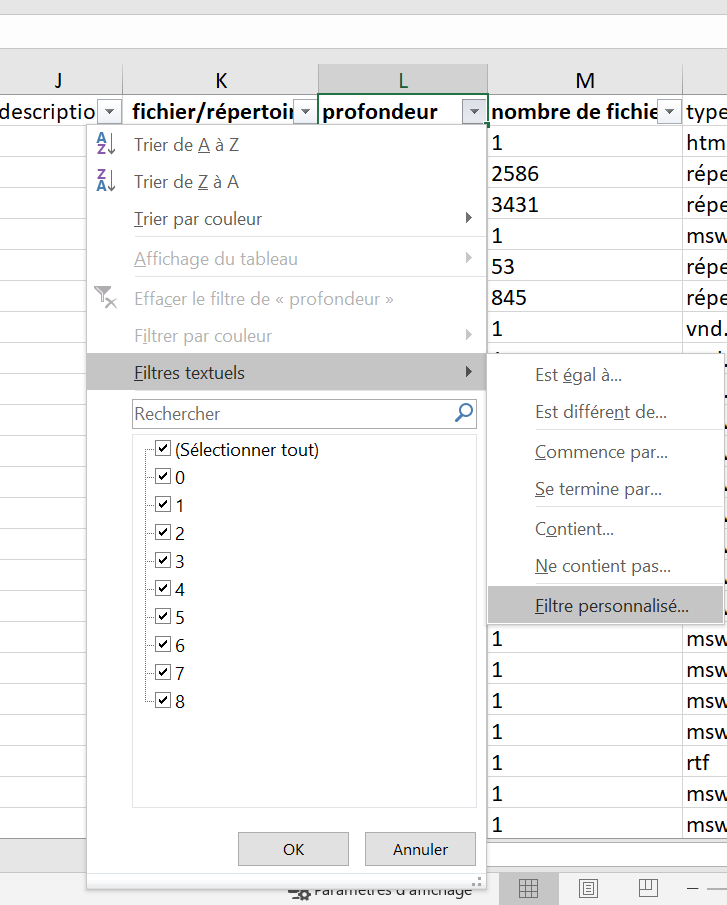
Pour connaître l’ensemble des chemins d’accès trop longs, il faut réaliser un export csv ou Excel. Dans l’export csv, une colonne est consacrée au nombre de caractères du chemin d’accès. Si on applique un filtre, il est possible de demander au tableur de ressortir l’ensemble des chemins d’accès dépassant le nombre de 256.
Comment y remédier ?
Il n’y a pas d’autre solutions que le renommage ou la restructuration de l'arborescence. Selon les situations, il peut être fait en masse ou manuellement. Si on souhaite faire en masse, il est possible d'utiliser la fonctionnalité de déplacement dans Archifiltre. En déplaçant les dossiers, on raccourcit les chemins d'accès. Dans l'export csv ou Excel, est créée une colonne « chemin » et une colonne « nouveau chemin ». Avec un script, il est possible d'éxécuter cette réorganisation en masse.
Comme expliqué dans la rubrique ci-dessus, plus il y aura de profondeur dans l’arborescence plus le chemin d’accès est allongé. En outre, plus l’utilisateur doit naviguer dans l’arborescence plus le risque de perte de l’information est important.
Quelle profondeur d’arborescence doit-on conseiller ?
Il est conseillé de ne pas dépasser plus de dix niveaux de profondeurs. Il est important de transposer sa pratique électronique à celle du papier. Qui ouvrirait plus de dix dossiers à la suite pour accéder à sa feuille ? Une arborescence trop profonde n’est pas fonctionnelle. Le risque est que l’utilisateur copie les documents ailleurs dans l’arborescence voire ne retrouve pas les documents en question.
Comment identifier les différentes profondeurs de mon arborescence ?
Pour connaître la valeur des niveaux de profondeur de mon arborescence, il faut réaliser un export csv. Dans l’export csv, une colonne est consacrée à la profondeur de l’arborescence. Si on applique un filtre, il est possible de demander au tableur de ressortir l’ensemble des niveaux de profondeur dépassant le chiffre 10.
Comme pour chaque projet, il est important de définir le cadre d’action et le rôle de chaque personne. Dans un projet d’audit ou de préconisation sur une arborescence, il est indispensable de définir les attentes et les besoins du service. De fait, si l’archiviste s’engage à fournir un livrable contenant l’ensemble des préconisations (problèmes, solutions, points forts, points faibles), le service audité doit également s’impliquer dans le plan d’action et le calendrier défini en amont.
Archifiltre permet de connaître l’ensemble des métadonnées de l’arborescence en un seul coup d’œil.
Sans même naviguer au sein de l’arborescence, il est déjà possible de dégager des pistes de réflexions, d’orientation pour nos préconisations.
L’indice de la volumétrie de l’arborescence: on peut mettre en relief ce chiffre avec celui d’autres services, calculer son pourcentage d’occupation de l’espace serveur sur l'échelle d'une direction.
Les métadonnées de dates peuvent également donner une orientation. Par exemple, le fichier le plus ancien date de 1980 et la date médiane à 2015. On peut d’ores-et-déjà estimer que des dossiers sont clos et peuvent être sûrement archivés ou éliminés.
L’indication du nombre de fichiers et de dossiers peut être parlante si l’on dispose de moyens de comparaison. Si on ne dispose pas de moyens de comparaison, on peut faire le ratio nombre de fichiers / nombres de dossiers. Ici : 104812/7721=13,5. Cette information est purement théorique et approximative, mais une arborescence où le ratio descend à moins de dix fichiers, on peut de suite savoir qu’il y a un problème d’organisation. L’arborescence est trop ramifiée et l’information perdue.
Pour débuter un rapport d’audit, il faut dans un premier temps s’appuyer sur le rapport d’audit généré automatiquement par Archifiltre, généré dans les exports. C’est un format texte et modifiable, il peut être complété et modifié sur sa forme. Chacun peut y ajouter son logo, ses références et ses analyses complémentaires.
L’audit généré automatiquement réalise des préconisations essentiellement techniques. C’est au tour de l’archiviste de l’agrémenter d’éléments d’analyse plus approfondis.
Cas 1 – Proposer des améliorations de règles de nommage
Dans cet exemple, le fil d’Ariane visualisé dans Archifiltre permet de voir l’ensemble du chemin d’accès jusqu’au fichier. On peut voir de nombreuses redondances. En les identifiant par des codes couleurs, il est facile de faire comprendre au service qu’il n’est pas utile de reprendre les informations du niveau supérieur. Chaque niveau dans l’arborescence doit avoir une information complémentaire et non redondante, sinon son existence n’est pas utile.
En retravaillant très peu l’arborescence (en renommage et en déplacement), il est possible de montrer au service que le chemin d’accès peut être fortement réduit et plus explicite. Avec l’exemple ci-dessous (anonymisé), il est possible de réduire la longueur de chemin d’accès de 46%, en le montrant via le fil d'Ariane :
| Arborescence initiale | Arborescence proposée |
|---|---|
| Nom bureau | Nom bureau |
| 5 - SUIVI DES MARCHES et des CONVENTIONS | 5_Marchés-et-conventions |
| 2 - MARCHES et CONVENTIONS | 2_Suivi |
| Section MOBILIERS DEMENAGEMENTS MANUTENTION | 1_Section-déménagements-manutention |
| MARCHE DEMENAGEMENTS | |
| Marché 2017-2021 Nom Prestataire | 1_2017-2021 |
| 1 - Prépa DCE + procd | |
| Analyse candidatures et offres | 1_Candidatures_et_offres |
| Compléments offres | 1_Compléments |
| 3 réponses | 3_Réponses |
| 2 Nom prestataire | 2_nom-prestataire |
| 2ème Réponse Groupe Presta | 1_2e_réponse |
| 2ème réponse Groupe Presta | |
| Cas pratiques - destruction mobilier, garde meuble Rectifié 22 decembre 2016.xlsx | \20161222_cas-pratique-déménagement.xlsx |
Cas 2 – Proposer des pistes de réorganisation de l’arborescence
La fin de la deuxième étape est l’occasion de lancer une réflexion sur la construction de l’arborescence et les choix qui ont été faits.
Dans chaque arborescence, il y a des cas que l’on voit revenir systématiquement et qui sont toujours sources de problèmes et qui doivent attirer notre attention.
- Les dossiers personnels :
Ces dossiers ont une logique d’organisation qui est personnelle, ils sont souvent peu utilisés par les collaborateurs, même après le départ de l'agent. Les dossiers sont souvent sources de redondances de fichiers ou de versioning (les versions intermédiaires dans le dossier perso et la version finale sur le serveur commun).
- Les dossiers thématiques :
Prenons l’exemple des dossiers de ressources humaines. Les services ont tendance à classer par thématiques :
RH > Recrutement > Contractuel > Non-abouti > Monsieur X ; Madame Y ; Madame Z ;...
Or la durée d’utilité administrative de ces dossiers est de 5 ans. Il est donc utile de créer un niveau pour réaliser un classement chronologique, facilitant ainsi le traitement.
RH > Recrutement > Contractuel > Non-abouti > 2019 (Monsieur X ; Madame Y) ; 2020 (Madame Z) ; ...
Attention : Faire des préconisations engage l’archiviste à fournir un travail en amont de toutes actions. Il est important de s’assurer de l’implication du service et de travailler par étapes. Restructurer une arborescence prend beaucoup de temps aux deux acteurs. Il faut procéder par étapes. Par exemple, définir et établir une arborescence de premier niveau puis fignoler par étapes/niveaux.
Des éliminables peuvent être identifiés dans le cadre de la collecte et de l’accompagnement des services, mais également dans le cadre de traitement d’archives définitives.
Comment trouver des éliminables dans le cadre de la collecte, d'un accompagnement des services ?
Comme pour chacune de nos actions de collecte ou d’accompagnement, des services producteurs et versants, il est nécessaire de connaitre leurs missions, les documents produits et leurs règles de gestion.
Pour identifier des parties de l’arborescence qui ne sont plus alimentées par le service producteur, on peut se fier :
- Au nom des répertoires :

- Aux dates de dernières modifications :

- Mais aussi... : à un type de format qui n'est plus utilisé, mais surtout à nos échanges avec le services !
4.4.2 - Identifier des données pour lesquelles la durée d'utilité administrative est échue et dont le sort final est l'élimination
Prenons l'exemple des marchés publics. Les marchés publics infructueux peuvent être éliminés 5 ans après la déclaration d'infructuosité. Un marché de 2013 infructueux peut donc être éliminé en 2020.
(DAF/DPACI/RES/2009/018)

Il est souvent possible d’identifier les versions provisoires des documents grâce à leur nommage, avec la présence de v1, v2, V2.1, etc. La version finale quant à elle contient souvent vf ou vdef dans son intitulé. Il est possible de les repérer en utilisant le moteur de recherche et en tapant "v1", par exemple. Cela peut permettre de ressortir un dossier contenant plein de versions d'un même document.

A noter : Parfois le format permet aussi d’identifier les différentes versions : par exemple les versions intermédiaires sont des documents modifiables tandis que la version définitive est figée (.pdf).
Dans Archifiltre les doublons peuvent être identifiés grâce au hash. Le hash est une fonction qui attribue à des données une empreinte numérique. Dans Archifiltre, chaque fichier ou répertoire se voit attribuer une empreinte. L'empreinte d'un dossier est calculée selon les empreintes des éléments fils contenus. Si un seul caractère est modifié dans un fichier, alors l’empreinte sera différente pour le fichier et pour le dossier parent. Si deux documents ou dossiers sont strictement identiques, ils ont alors la même empreinte. Ainsi nous pouvons repérer les redondances parfaites !
Dans ArchiFiltre, le hash de vos fichiers et répertoires apparaît ainsi dans l'onglet général :

Dans l'onglet redondance, il possible de les étudier de plus près, lorsque l'ensemble des hashs ont été calculés.

A noter :Il est parfois nécessaire d’attendre quelques minutes (ou plus, selon le nombre d’éléments) pour que les hashs de l’ensemble de vos éléments soient calculés. Une pop-up vous indique quand le chargement est terminé. Les exports et les onglets sont désormais accessibles.
Il est possible d’avoir une première approche et de commencer à travailler sur les redondances en se rendant sur l’onglet « redondances », pour étudier les redondances par types, l’espace qu’elles occupent dans l’arborescence, etc. Il est possible d'utiliser un moteur de recherche pour retrouver des redondances par mots-clefs. Une fois les redondances trouvées, il est possible d'appliquer le tag « à éliminer ».
Il est également possible de travailler sur les redondances à partir des exports avec empreintes.

Les empreintes de vos fichiers et répertoires apparaissent donc dans le fichier csv :

Grâce à la colonne juste à côté « Redondance », il est possible de ressortir l'ensemble des éléments redondants en filtrant par « Oui ».
Un travail de mise en forme conditionnelle via la colonne dédiée aux empreintes, et l'ajout d'autres filtres permettent de dégager certains éléments de l'arborescence.
Découvrez comment travailler sur l'export et en jouant avec différents filtres en 2 minutes grâce à notre tutoriel vidéo ! 👇
Cet article est en cours de rédaction, patience...

Cet article est en cours de rédaction, patience...
Comme pour les archives papiers, lorsqu’on supprime des données ou des fichiers bureautiques, il est important de réaliser un bordereau d’élimination.
A partir d’Archifiltre, différentes méthodes peuvent être réalisées pour éditer un bordereau d’élimination.
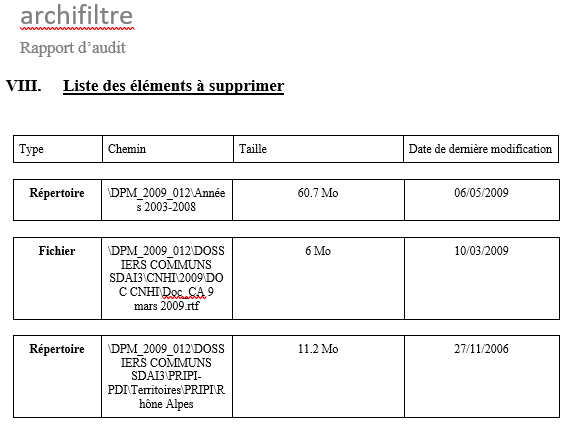
Lorsque vous utilisez le tag automatisé « A éliminer », la liste des éléments éliminés se génère automatiquement dans la dernière partie du bordereau d’élimination. Sous la forme d’un tableau sont référencés : le type, chemin, taille, date de dernière modification.
Ce tableau recense aussi bien les dossiers que les fichiers identifiés par ce tag.
Il est possible de rentrer davantage dans la précision de la rédaction du bordereau d’élimination, en utilisant l’export csv ou Excel. Ces exports génèrent la liste de tous les fichiers et dossiers et les enrichissements réalisés. En filtrant la colonne « A éliminer », on génère la liste de l’ensemble des éléments à éliminer (une ligne par fichiers ou dossiers)
Ainsi, ces exports permettent de générer un récolement complet pour le bordereau d’élimination.
Ce récolement a deux utilités : il permet de documenter l’ensemble des documents produits, ou reçus, par le service faisant l'objet d'une élimination; il permet également d'établir la liste de l'ensemble des chemins d'accès à fournir au service informatique pour une élimination en masse grâce à un script.
A noter : Avec la possibilité de récolement complet pour une élimination, il est désormais possible de documenter l’existence et la connaissance d’un fichier dans un répertoire.

A noter : Pour améliorer les échanges avec les services, il est préférable de réaliser un en-tête avec une synthèse des éléments éliminés si on utilise les exports de tableur.
Avant de procéder à l’organisation d’un cleaning-day, il est important de revenir sur sa définition et ses objectifs.
Un cleaning-day est une journée où une entité administrative consacre l’ensemble de son temps à la gestion de ses archives, en collaboration avec le service des archives. Il n’y a pas une seule et bonne manière d’organiser un cleaning-day. Cela peut se faire aussi bien sur une demie-journée que sur plusieurs semaines. Tout cela dépend des besoins, des possibilités et des attentes du service.
Beaucoup de services d’archives ont peu de moyens ou sont en sous-effectif. Mettre en place des pratiques de records management est impossible pour certains services. Mais intervenir lorsqu’une arborescence n’est plus fonctionnelle ou que l’espace serveur est à saturation, n’est pas une situation acceptable. Organiser un cleaning-day permet d’être à mi-chemin entre ces deux situations, de créer du lien avec le service producteur, de poser les jalons d’une bonne gestion documentaire et de sensibiliser les services.

L’organisation d’un cleaning-day peut émaner du service producteur. Le service des archives peut également organiser de façon ponctuelle ou cyclique selon les besoins du service en question. Il est important de veiller à ce que la plus grande partie du service producteur participe à l’atelier. Il est primordial qu’il y ait une adhésion commune mais aussi afin de sensibiliser le plus grand nombre.
Pour qu’un cleaning-day réussisse, il est important de définir en amont le périmètre.
- - Qui intervient ?
- - Quelle partie de l’arborescence est à traiter
- - Réaliser un audit de l'existant pour identifier les problèmes et point d’attentions
- - Quelles sont les attentes et objectifs : allégement, tri, réorganisation, archivage…
- - Quelle méthodologie : pendant le cleaning-day, après le cleaning-day
- - Questions technique : droits d’accès, matériel informatique, chargement du l'arborescence à l’avance…
Après avoir réalisé un audit de l’espace serveur du service producteur en amont, présenter le rapport d’audit à l’oral avant le lancement du cleaning-day. Dans cette présentation, il est important de souligner les éléments qui fonctionnent, ceux qui sont à améliorer et toutes les pistes de tri possible. Lors de cette présentation, on présente l’outil Archifiltre sous sa forme basique (visualisation de l’arborescence, des métadonnées, ouverture des éléments et appliquer un tag (archiver, éliminer, transférer)). Cette présentation permet au service de poser toutes leurs questions et d’appréhender leur arborescence dans Archifiltre.
Chaque groupe/pôle va procéder au tri d'une partie prédéfinie de l’arborescence dans Archifiltre. Il est possible de donner à un groupe les dossiers qu’il connaît et enrichit quotidiennement (on observe une légère tendance à la conservation) ou des dossiers qu’il ne connait pas pour avoir un regard plus critique (on observe une tendance à l’élimination plus facilement). Durant la séance l’archiviste circule entre les différentes postes informatiques pour répondre aux questions archivistiques ou techniques.
A la fin de la séance, il est important de centraliser les fichiers générés par Archifiltre (json) pour les instruire. En relation avec le responsable du service, le service des archives instruit les propositions de tri via les tags sur les dossiers : archiver, éliminer (voire transférer). Rédiger ensuite les bordereaux de versements et d’élimination (voir les articles correspondant) et envoyer la liste des éléments à éliminer ou archiver au service informatique pour une application en masse (voir article correspondant).
Le 👍 : Adhésion et énergie collective, échange direct entre archivistes et services producteurs.
Le 👎 : Agents déstabilisés par le cadre et perte de temps en apparence, forte implication de l’archiviste.
Après avoir réalisé un audit de l’espace serveur du service producteur, présenter le rapport d’audit à l’oral. Dans cette présentation, il est important de souligner les éléments qui fonctionnent, ceux qui sont à améliorer et toutes les pistes de tri possible. Lors de cette présentation, on peut présenter l’outil Archifiltre sous sa forme basique (visualisation de l’arborescence, des métadonnées, ouverture des éléments et appliquer un tag). Cette présentation permet au service de poser toutes leurs questions, d’appréhender leur arborescence dans Archifiltre.
Pour organiser le cleaning-day, il est important de définir un interlocuteur, de préférence le référent archives, s’il y en a un. Ensuite établir plusieurs groupes (par pôles d’activités par exemple). L’ensemble de ces groupes vont travailler en même temps sur un créneau fixe ou bien sur un délai plus large, par exemple une semaine. A la fin du temps imparti, le référent rassemble les différents fichiers générés par Archifiltre (json).
Le service archives instruit ensuite les propositions d’éliminations et entre en discussion avec le service. Lorsque les éliminations sont validées, rédiger le bordereau d’élimination (voir article correspondant) et envoyer la liste des éliminables au service informatique pour une application en masse (voir article correspondant).
Le 👍 : Autonomie des services, sensibilisation, mise en place et implication d’un référent.
Le 👎 : Retards ou non-implication de certains groupes, plusieurs fichiers à instruire.
Si un bureau souhaite réfléchir et réorganiser son espace serveur (évolution des missions, non pertinence…), il faut réaliser un audit. Avant de procéder à une réorganisation, quelle qu’elle soit, il est important d’identifier les éléments à éliminer (notamment les doublons et versionning). Il faut ensuite présenter au service le résultat de l’audit, les pistes d’amélioration et en amorcer les questions sur les pratiques documentaires.
Pour organiser ce cleaning-day, il faut mobiliser l’ensemble du service producteur. Il est impératif lors d’une réorganisation que l’ensemble des agents adhère et participe. Cette séance de cleaning-day, peut-être préparée en amont, notamment la question des éliminables pour gagner en compréhension de l’arborescence. Durant cette séance il est important de questionner la profondeur de l’arborescence, les regroupements, la gestion des dossiers de premier niveau.
Lorsque les pistes de réorganisation sont validées, le service peut procéder lui-même à la réorganisation, avec la participation ou non de l’archiviste, voire en collaboration avec le service informatique s’il y a des déplacements conséquents de fichiers/dossiers.
Le 👍 : Sensibilisation du service, adhésion commune, gain en visibilité et clarté dans la recherche d’information.
Le 👎 : Organisation en amont en plusieurs étapes.
Attention: Un cleaning-day demande du temps et de l'engagement, il est important de définir les attentions et le rôle de chacun. Pour s'entraîner, rien de tel que d'organiser un cleaning-day sur son propre espace serveur entre collègues. On dit bien que les cordonniers sont toujours les plus mal chaussés, il y a donc de quoi faire !
L'ensemble des enrichissements possibles avec Archifiltre restent virtuels, en mode image, le versement à étudier n'est pas impacté directement. Tous les enrichissements qui sont réalisés dans Archifiltre peuvent être transformés au format SEDA 2.1 via un export et ainsi être intégrés dans le système d'archivage électronique ADAMANT en passant par l'outil ReSIP qui permet de constituer un SIP.
Comme pour le papier, un versement électronique demande une préparation avant son traitement et versement final. Les principaux éléments de préparation du versement vont être d'ordres techniques.
La première étape est vérifier si le versement contient des éléments qui peuvent être bloquants.

Tout d'abord, il est important de vérifier si le versement est composé de répertoires compressés (zip, 7z, rar…). Ils doivent être décompressés pour être traités (sinon, leur contenu n'est pas affiché dans Archifiltre). La présence de répertoires compressés est bloquant pour le SAE. Outre le blocage, il est important de décompresser les répertoires car le contenu compressé peut modifier fortement le contenu du versement dans sa globalité et donc son analyse.
Pour identifier et repérer les éléments compressés présents dans le versement, on peut exporter la liste des éléments compressés et leur localisation depuis Archifiltre en utilisant la fonctionnalité « rechercher et filtrer ».

Si on a déjà un export csv ou Excel, il est possible de l'utiliser en filtrant colonne « extension » et en sélectionnant uniquement les formats de compression (.zip, .7z, .rar). La liste de l'ensemble des éléments compressés et leur chemin d'accès sont ainsi renseignés.
Le deuxième élément tient dans le nommage des fichiers. L'ensemble des fichiers ayant un point dans leur nommage, autre que pour l'extension, seront bloqués dans l'entrée du SAE. En effet, le système va comprendre le point comme l'annonce de l'extension. Par exemple, un fichier nommé « nom.prénom.doc », le système va comprendre que « .prénom.doc » est l'extension. Il convient donc de corriger manuellement depuis votre ordinateur l'ensemble des fichiers ayant un point dans leur titre.
Le troisième élément est de vérifier l'existence de fichiers vides (de l'ordre de 0 à 1 octet).
Enfin, il est important de noter que depuis la V.3.0, Archifiltre filtre certains éléments lors de son chargement. Archifiltre n'importe plus les dossiers vides mais aussi les fichiers cachés ou systèmes (ayant pour extension .ini, .tmp, tumbs.db, .ink, .DS_Store). De fait, ces fichiers sont bloquant lors de l'entrée dans le SAE mais aussi parce que ces fichiers induisent des erreurs dans le calcul d'empreintes.
Il est possible d'enrichir le versement en ajoutant des métadonnées au versement. A l'instar des instruments de recherche rédigés dans la feuille de style SOSIE, nous ajoutons des éléments d'informations, de contextualisation à des ensembles d'archives. Ces informations sont catégorisées et standardisées par la norme ISAG (G) et au format SEDA.
- Modification de l'intitulé de l'élément :
La métadonnées de l'ancien titre sont conservées dans la balise Custodial History
Attention : Il ne faut pas mettre de guillemets dans le titre. Il convient de mettre à l'UA racine l'intitulé du versement (repris dans le titre du versement de ADAMANT et en commentaire de l'export ReSIP)

- Le tag : entre actions et liens
Le tag peut être également utilisé pour réaliser un lien intellectuel entre plusieurs éléments dans l'arborescence. Cette utilisation du tag revient à la méthodologie de la rédaction d'un répertoire méthodique.

Attention : le tag est à utiliser avec parcimonie. Au format SEDA, le tag ne remplit pas la balise « Keyword », propre aux actions. Actuellement, le tag renseigne le champ des indexations thématiques.
- Le tag « A éliminer »

- La description

Pendant cette étape, l'archiviste a pour rôle de déterminer son niveau d'intervention et la granularité de son analyse. Lorsque cette étape est terminée, nous arrivons à la deuxième étape, celle se déroulant dans ReSIP.
L'ensemble du traitement du versement ne peut être complètement réalisé depuis Archifiltre. Pour le finaliser, il convient d'utiliser ReSIP développé par le programme VITAM. C'est un outil libre et gratuit.
Pour établir le lien entre Archifiltre et ReSIP, il faut réaliser l'export « ReSIP » depuis Archifiltre.

A noter : Il est important de noter que le fichier s'enregistre automatiquement à la racine du versement en cours de traitement, il ne faut pas déplacer ce fichier.
Avant de procéder à l'import du csv dans ReSIP, il est important de vérifier les préférences d'import. Pour cela, il faut aller dans « Fichier>préférence...»

Aller dans l’onglet import, et vérifier que l’encodage des csv est bien paramétré en UTF-8 (en bas de la fenêtre) et que le séparateur est bien le point-virgule « ; ».

Il convient ensuite d'importer l'export réalisé depuis Archifiltre dans ReSIP en sélectionnant « Importer depuis un csv de métadonnées... » .

Les principales actions qui vont être menées dans ReSIP vont être le reclassement de certains élément ou la création de dossiers, la fusion de redondances, la modification des dates extrêmes, les règles d'accès et les éléments de l'introduction du versement.
- Créer un dossier
Il est possible de créer un dossier dans ReSIP pour créer un niveau intermédiaire ou regrouper plusieurs fichiers non classés. Pour le créer, il suffit de se placer au niveau sous lequel on souhaite créer l'arborescence puis effectuer un clic droit et sélectionner « Ajouter une sous-ArchiveUnit ».

Par défaut, le nom de ce dossier est « Nouvelle ArchiveUnit », pour le modifier, sélectionner le dossier et se rendre sur le fenêtre de droite, modifier puis sauvegarder.

- Traiter les redondances non-éliminables
La présence d'un document dans un dossier peut aider à sa compréhension, et la présence de ce même fichier dans un autre dossier peut avoir aussi son utilité. Si on souhaite conserver ces deux documents, il est possible de les fusionner dans ReSIP. En d'autres termes, un seul fichier est conservé, mais les métadonnées de la présence de ces doublons est conservé. Ainsi, si on consulte ces dossiers, les documents ressortent systématiquement, mais un seul fichier est conservé.


Si vous repérez un doublon à éliminer et qui a été loupé dans le traitement dans Archifiltre, il est possible de le faire dans ReSIP en le sélectionnant et en utilisant la touche « suppr » de votre clavier.
- Vérifier une dernière fois les fichiers cryptés, non-reconnus ou non pérennes
Il est possible de vérifier les éléments du versement en cours de traitement en utilisant les exports et la fonction recherche d'Archifiltre. Il est possible de vérifier une dernière fois les éléments du versement en consultant les statistiques. En cas de doutes, il convient de contacter les Archives nationales. Tous les formats ne sont pas acceptés. Certains formats demandent un traitement particulier pour assurer leur pérennité.


- Décrire les règles d'accès à un groupe d'articles
Dans ReSIP il faut définir les règles d'accès du versement au niveau racine. Ces règles d'accès se déterminent en appui des délais déterminés dans le Code du patrimoine (consultable ici). Pour appliquer un délai de communicabilité, il faut sélectioner le niveau racine puis cliquer sur «...» et sélectionner gestion.


Pour renseigner l'ID-règle, il faut consulter le référentiel des règles d'accès des Archives nationales sur le plate-forme ADAMANT.
A noter : La règle de gestion doit se faire au niveau racine du versement. Mais il est possible d'avoir des délais de communicabilité contraires de l'ensemble du versement. Un dossier peut avoir une règle d'accès différente de l'ensemble du versement. Il convient alors de suivre la même procédure.
- Régénérer les identifiants
Lors du traitement dans ReSIP, des fichiers ont pu être supprimés, déplacés, etc. Pour que les identifiants dans le SIP soient bien en continu, il ne faut pas oublier de regénérer les identifiants, l'équivalent d'une recotation.

- Vérifier la conformité du traitement au SEDA 2.1
Pour vérifier qu'il n'y ait pas d'erreurs de balises ou autres, il convient de vérifier la conformité de son versement avant le finaliser en constituant le SIP.

- Editer les informations d'export
La dernière étape avant la finalisation et la consitution du SIP est de compléter les métadonnées globales et étendues du versement.


Pour finaliser il suffit de compléter en identifiant le SIP, en indiquant le nom de l'intitulé (identique à celui de l'UA racine). Puis aller dans la l'onglet « Métadonnées globales étendues » et dans la catégorie « métadonnées de gestion globales », indiquez dans la balise « Aquisition » si c'est un versement, don ou protocole.
- Dernière étape : éditer le SIP
Pour finaliser le traitement il ne reste plus qu'à éditer le SIP. Ce SIP n'a plus qu'à être intégré dans le SAE ADAMANT des Archives nationales.

Pour éclaircir la méthodologie et l'interopérabilité entre Archifiltre et ReSIP, l'équipe Archifiltre a créé un logigramme pour comprendre les grandes étapes d'un traitement d'un versement de bureautique bureautique à partir d'Archifiltre.

Pour réaliser un versement vers As@lae (en SEDA 2.1) il est possible d’utiliser d’Archifiltre pour enrichir les paquets (SIP) et verser en SEDA 2.1 en combinant Archifiltre et le logiciel RESIP (voir article ci-dessus).
A noter :Un interfaçage entre Archifiltre et As@lae en cours de réflexion. Le projet est en attente du passage d'As@lae en version SEDA 2.1
Deux webinaires ont été réalisés pour présenter les fonctionnalités :
- Webinaire de Libriciel SCOP sur la version 2.0 d'As@lae :
Présentation de la version 2.0 d’As@lae par Frédéric Losserand (directeur des opérations) et Florent Veyres (responsable du pôle archivage chez Libriciel SCOP).

- Webinaire Archifiltre en collaboration avec Libriciel sur la chaîne de traitement avec Archifiltre, ReSIP et As@lae :
Présentation par Chloé Moser (Adjointe à la cheffe de la Mission des Archives de France, auprès des ministères sociaux, Product Owner d’Archifiltre), Thibaut Larrède (Archiviste aux ministères sociaux, expert fonctionnel d'Archifiltre) et Florent Veyres(responsable du pôle archivage chez Libriciel SCOP).