Операционная система является основным программным обеспечением, которое управляет всем аппаратным и другим программным обеспечением на компьютере. Операционная система, также известная как ОС, взаимодействует с аппаратным обеспечением компьютера и предоставляет службы, которые могут использовать приложения.
))
Операционная система является основным набором программного обеспечения на устройстве, которое поддерживает все вместе. Операционные системы взаимодействуют с оборудованием устройства. Они обрабатывают всё: от клавиатуры и мыши до Wi-Fi-радио, устройств хранения и отображения. Другими словами, операционная система обрабатывает устройства ввода и вывода. Операционные системы используют драйверы устройств, написанные разработчиками оборудования для связи со своими устройствами.
Операционные системы также включают в себя множество программных продуктов, таких как общие системные службы, библиотеки и интерфейсы прикладного программирования (API), которые разработчики могут использовать для написания программ, работающих в операционной системе.
Операционная система находится между приложениями, которые Вы запускаете, и оборудованием, используя аппаратные драйверы в качестве интерфейса между ними. Например, когда приложение хочет что-то напечатать, оно переносит эту задачу в операционную систему. Операционная система отправляет инструкции на принтер, используя драйверы принтера для отправки правильных сигналов. Приложению, которое печатает, не нужно заботиться о том, какой принтер у Вас есть, или понять, как он работает. ОС обрабатывает детали.
ОС также обрабатывает многозадачность, выделяя аппаратные ресурсы среди нескольких запущенных программ. Операционная система контролирует, какие процессы выполняются, и распределяет их между различными ЦП, если у Вас есть компьютер с несколькими процессорами или ядрами, позволяя нескольким процессам работать параллельно. Она также управляет внутренней памятью системы, выделяя память между запущенными приложениями.
Операционная система — это одна большая часть программного обеспечения, которая отвечает за многое. Например, операционная система также контролирует файлы и другие ресурсы, к которым могут обращаться программы.
Большинство программных приложений написано для операционных систем, что позволяет операционной системе делать много работы. Например, при запуске Minecraft Вы запускаете его в операционной системе. Minecraft не должен точно знать, как работает каждый отдельный аппаратный компонент. Minecraft использует различные функции операционной системы, а операционная система переводит их в низкоуровневые аппаратные инструкции.

Когда мы говорим, что «компьютеры» запускают операционные системы, мы не просто имеем в виду традиционные настольные ПК и ноутбуки. Ваш смартфон — это компьютер, как и планшеты, смарт-телевизоры, игровые консоли, смарт-часы и маршрутизаторы Wi-Fi. Amazon Echo или Google Home — это компьютерное устройство, работающее под управлением операционной системы.
Знакомые настольные операционные системы включают Microsoft Windows, Apple MacOS, Google Chrome OS и Linux. Основными операционными системами для смартфонов являются iOS от Apple и Android от Google.
Другие устройства, такие как маршрутизатор Wi-Fi, могут запускать «встроенные операционные системы». Это специализированные операционные системы с меньшим количеством функций, чем имеет обычная операционная система, разработанная специально для одной задачи — например, для работы с маршрутизатором Wi-Fi, навигации или управления банкоматом.
Операционные системы также включают другое программное обеспечение, включая пользовательский интерфейс, который позволяет людям взаимодействовать с устройством. Это может быть рабочий стол на ПК, сенсорный интерфейс на телефоне или голосовой интерфейс на цифровом помощнике.
Операционная система — это большое программное обеспечение, состоящее из множества различных приложений и процессов. Линия между тем, что является операционной системой и что такое программа, может иногда быть немного размытой. Точного официального определения операционной системы нет.
Например, в Windows приложение File Explorer (или Windows Explorer) является неотъемлемой частью операционной системы Windows — оно даже обрабатывает отрисовку Вашего рабочего интерфейса — и приложением, работающим в этой операционной системе.

На низком уровне «ядро» является основной компьютерной программой, лежащей в основе Вашей операционной системы. Эта отдельная программа является одной из первых вещей, загружаемых при запуске Вашей операционной системы. Оно обрабатывает выделение памяти, преобразование программных функций в инструкции для процессора Вашего компьютера и обработку входных и выходных данных с аппаратных устройств. Ядро, как правило, запускается в изолированной области, чтобы предотвратить его несанкционированное использование другим программным обеспечением на компьютере. Ядро операционной системы очень важно, но это всего лишь одна часть операционной системы.
Но и здесь не все конкретно. Например, Linux — это просто ядро. Однако Linux по-прежнему часто называют операционной системой. Android также называется операционной системой, и она построена на ядре Linux. Такие Linux-дистрибутивы, как Ubuntu, используют ядро Linux и добавляют к нему дополнительное программное обеспечение. Они также называются операционными системами.
Довольно подробная статья на эту тему тут
ОС Windows обычно называют лучшей ОС для начинающих пользователей. По данным NetMarketShare за 2020 год мировая доля ОС Windows на настольных компьютерах составляет 87%, в то время как macOS занимает 9% рынка, а Linux — всего лишь 2%.
Несмотря на недавние улучшения в программном обеспечении, переносимого с других платформ или разрабатываемом на Linux, Windows по-прежнему является «королем совместимости».
Пользователи Windows могут быть уверены, что практически любое ПО (даже самое малоизвестное и устаревшее) будет работать, даже если его перестали развивать сами разработчики. Windows имеет отличную поддержку устаревшего ПО.

Ядро Linux (и сопутствующие с ним утилиты и библиотеки GNU) в большинстве дистрибутивов (Debian, Fedora, Ubuntu, Manjaro и пр.) полностью свободны (часто — бесплатны) и имеют открытый исходный код благодаря соответствующей лицензии GNU GPL и её вариациям. Компании (например, Red Hat, SUSE) предлагают платную поддержку своих дистрибутивов (Red Hat Enterprise Linux, SUSE Linux Enterprise Server), но базовое программное обеспечение по-прежнему можно скачать и установить бесплатно.
Если вы геймер и вам нужна 100% совместимость с определенным программным обеспечением, то тут без компромиссов побеждает Windows. Сервис Steam, помимо прочих клиентов и лончеров, предоставляет огромное количество игр как от ААА-издателей, так и от небольших инди-разработчиков.
Steam для Linux теперь позволяет устанавливать игры для Windows, но он все еще находится в процессе развития, и не все игры для Windows будут на нем корректно работать (если вообще запустятся). Кроме того, вы также можете поиграть в некоторые специфичные для Windows игры на Linux через Wine или Proton.
Linux поддерживает почти все основные языки программирования (Python, C/C++, Java, Ruby, Perl и др.). Кроме того, он предоставляет широкий спектр приложений, полезных для программирования и разработки различных приложений. Вы найдете множество библиотек, изначально разработанных для Linux. Многие программисты отмечают, что они могут легко выполнять рутинные задачи с помощью менеджера пакетов в Linux. Возможность писать сценарии в различных оболочках также является одной из самых убедительных причин, почему программисты предпочитают использовать Linux. Он также предоставляет встроенную поддержку протокола SSH, с помощью которого вы с легкостью сможете быстро управлять своими серверами.
В Windows же есть своя платформа .NET Framework, которая позволяет писать программные продукты. Главной особенностью данной платформы является то, что это продукт Microsoft (который создавался в качестве альтернативы платформе Java от компании Sun) и официально работает он только с семейством операционных систем Windows. Со времен выпуска .NET Framework в 2002 году появилось множество программных продуктов, библиотек и фреймворков, созданных с помощью данной платформы для работы исключительно под Windows. Основным языком программирования в .NET Framework является язык C# — объектно-ориентированный язык программирования, созданный специалистами компании Microsoft как язык разработки приложений для платформы Microsoft .NET Framework. Если Linux у разработчиков ассоциируется с поддержкой и работой с множеством различных языков программирования, то «визитной карточкой» Windows является .NET Framework и язык C#.
Если вы думаете о безопасности сервера, стабильности, свободе выбора, совместимости оборудования и экономической эффективности, то сервер на Linux превосходит аналогичный сервер на Windows во всех отношениях. Windows — это популярный вариант для настольного использования, а Linux — лучший вариант для серверных систем.
Серверный дистрибутив Linux предлагает множество различных вариантов настройки системы с широким спектром эффективных инструментов мониторинга и анализа её работоспособности. Linux, в отличие от Windows, менее уязвим к различным кибератакам и проникновению на сервер вредоносных программ. В ядре Linux практически невозможно создать какой-либо бэкдор, в то время как система Windows очень чувствительна к такому сценарию развития событий.

Во-первых, нам нужно рассмотреть один из наиболее запутанных аспектов платформы Linux. В то время как Windows сохранила вполне стандартную структуру версий, с минорными и мажорными обновлениями, в Linux же всё обстоит гораздо сложнее.
На сегодняшний день ядро Linux лежит в основе всех операционных систем на базе Linux. Однако, поскольку его исходные коды остаются открытыми, любой человек может настроить или изменить ОС для своих собственных целей. В результате мы имеем сотни индивидуальных Linux-подобных операционных систем, называемых дистрибутивами. Это делает невероятно трудным выбор между ними, гораздо более сложным, чем просто выбор между Windows 7, Windows 8 или Windows 10.
Но у такого расклада есть и свои достоинства. Учитывая природу программного обеспечения с открытым исходным кодом, эти дистрибутивы могут сильно отличаться по функциональности и сложности, ведь каждый дистрибутив Linux имеет свой цикл разработки, и многие из них постоянно развиваются.
В случае с Windows существует только одна компания — Microsoft, которая занимается разработкой и обслуживанием всей операционной системы: ядро, среда рабочего стола и большая часть предустановленного программного обеспечения. Вы должны принимать всё, что они вам предлагают, независимо от того, будет это вам полезно или нет.
Все примеры ниже будут базироваться на Ubuntu/Mint дистрибутивах.

Давайте сначала разберемся как вообще это может работать. В Linux есть такое понятие как корневая файловая система. В
качестве неё монтируется раздел жесткого диска, на котором установлен Linux. В различные подпапки подключаются другие
реальные разделы жесткого диска, например, домашний раздел подключается в папку /home, а загрузочный в папку /boot.
Но существуют не только реальные файловые системы, но и виртуальные файловые системы, созданные ядром, например, в папку
/proc монтируется файловая система procfs, которая позволяет получить доступ к параметрам ядра, а в папку /dev
монтируется devfs содержащий устройства, подключённые к компьютеру, и тоже в виде файлов.
Так вот, вообще всё это файл.

- Подключаемые устройства (принтеры, флешки и т. д.) для Linux - это файл, и в них при желании можно писать или читать данные.
- Информация о ядре - это тоже файл.
- Конфигурация ядра - это, не поверите, тоже файл.
- Сокеты - странные, но файлы.
Сокеты - это специальные файлы для взаимодействия между процессами по сети. Создаётся специальный файл, в который, допустим, один процесс пишет данные, а еще два считывают. Такой механизм нужен, чтобы явно было понятно, через какой объект данные общаются, и мы будем пользоваться такими файлами в дальнейшем.
С исторической точки зрения, когда создавалось ядро Linux, понятия UI (User Interface - то, что вы привыкли видеть на всех ваших устройствах, открытые папки, запущенные приложения открытый браузер и т. д.) просто не существовало. Все возможности ядра использовались только через консоль.
А это значит, что все выполняемые команды или параметры передавались исключительно как белый текст на чёрном фоне. Никаких красивых кнопок или понятных картиночек)
У очень большого количества программ для Linux всё еще нет никакого UI, только белые буквы на чёрном фоне. Существуют дистрибутивы (активно используются, и мы будем использовать такой через занятие)^ где всё еще существует только консоль. Запустили устройство, а всё^ что у вас есть, — это чёрный фон и белые буквы. :)
Как это работает?
- Ядро читает команду, набранную на клавиатуре из терминала.
- Команда валидируется.
- Команда запускается.
- Результат выводится на экран (ну, или допустим, пишется в файл и т. д.).
- Идём к пункту 1.
Команда — это последовательность символов, которая заканчивается нажатием клавиши Enter и впоследствии
обрабатывается оболочкой.
Чтобы интерпретировать командную строку, оболочка сначала пытается разделить строку на слова. Как и в реальной жизни слова разделяются пробелами. Первое слово в строке обычно является фактической командой. Все остальные слова в строке являются параметрами, более подробно объясняющими, что требуется.
Параметры, начинающиеся с дефиса (-), называются опциями. Если вы хотите передать команде несколько опций, их
можно (часто) сгруппировать за одним дефисом, т. е. последовательность опций -a -l -F - это то же самое, что и
-alF. Многие программы имеют больше опций, чем можно удобно сопоставить с одним символом, ну или просто требуется
более читаемое написание. Для этого используются "длинные параметры", они начинаются с двух дефисов и не собираются в
одно длинное слово: foo --bar --baz.
Параметры без дефиса в начале называются аргументами. Часто это имена файлов (например, python manage.py), которые
должна обработать команда.
Таким образом, общая структура команд может отображаться следующим образом:
:команда: <что делать?> :параметры: <как это сделать?> :аргументы: <с чем это делать?>

**В линуксе нет дисков как C:/, D:/ итд. Есть только корневая директория /, с которой всё и начинается.
Чаще всего есть папка /home, внутри которой будут еще папки с вашими пользователями. Если у вас один пользователь, то
и папка будет одна, обычно это единственное место, где можно выполнять все действия без пароля. Как работают
разграничения пользователей дальше в лекции.
Значок ~ (тильда) означает домашний каталог текущего пользователя.
Путь может быть абсолютным или относительным. Полный, или абсолютный путь — это путь, который указывает на одно и то же место в файловой системе вне зависимости от текущего рабочего каталога или других обстоятельств. Полный путь всегда начинается с корневого каталога. Относительный путь представляет собой путь по отношению к текущему рабочему каталогу пользователя или активных приложений.
Команда pwd (print working directory) отображает абсолютный путь в текущую директорию.
Если при начале набора любого названия файла или папки нажать клавишу TAB, система подскажет вам первый файл,
начинающийся с этих символов (без символов просто подставит первый файл в папке), при повторном нажатии появится
следующий соответствующий файл, если он есть.
Команда cd (change directory) позволяет изменить текущую папку. Мы можем указать ей как абсолютный
cd /home/my_user, так и относительный cd my_images(находясь, допустим, в папке /home/my_user) пути.
Перейти на директорию уровнем выше cd .. (были в /home/my_user/my_images/, попали в /home/my_user/)
Перейти на директорию двумя уровнями выше cd ../.. (были в /home/my_user/my_images/, попали в /home)
Перейти в вашу домашнюю директорию откуда угодно cd ~.
Перейти в директорию, в которой вы находились до перехода, - cd -.
ls (list) показывает список файлов и папок в текущей директории.
С флагом -l покажет детали каждого файла.
С флагом -a покажет скрытые файлы и папки.
Часто используется с комбинированным ключом ls -la.
Последняя команда в Ubuntu/Mint и не только дистрибутивах изначально может быть заменена на алиас ll (не работает на
Mac).
Создать файл в командной строке Linux можно тремя способами.
- Команда
touch
touch /путь/к/файлу/название_файла
или
touch file.txt - создаст пустой файл
Мы всё еще можем указать абсолютный или относительный путь
- Перенаправить вывод практически любой команды в файл. Это делается при помощи символа (
>). Если помните, как снятьrequirements.txt, то точно понимаете, о чём я.
В общем виде команда выглядит так:
какая_нибудь_команда > /путь/к/файлу/наименование_файла
Как пример:
ls --help > ls_help.txt
Создаст файл ls_help.txt в текущей папке, который будет содержать результат команды ls --help с деталями по
использованию команды ls.
Если использовать символ > два раза, то данные, если файл уже будет существовать, допишутся в конец, а не перепишут
весь файл.
- Используя текстовый редактор.
В Linux существует несколько различных текстовых редакторов, существуют даже со сложными графическими интерфейсами, но
мы чаще всего будем использовать либо nano, либо vim. Я лично предпочитаю использовать nano т. к. это самый
простой и удобный (для меня) редактор, но многие предпочитают vim, так как его можно настроить настолько гибко, что
он даже особо не будет отличаться от PyCharm. Но, выбирая vim, всегда помните, что вопрос Как выйти из vim? является
самым популярным вопросом из Украины на
StackOverflow вопрос. У этого вопроса 2.9
миллиона просмотров :)
nano nano_file.txt
И для закрытия редактора используйте команды самого редактора (у nano - это Ctrl+X)
Чтобы создать папку, нужно использовать команду mkdir (make directory), также можно использовать абсолютный и
относительный путь
mkdir dir_name
Создать сразу две папки:
mkdir dir1 dir2
Создать дерево:
mkdir -p /dir1/dir2
Для удаления папки используется команда rmdir (remove directory):
rmdir dir_name
Для удаления файла используется rm (remove):
rm some_file
Эту команду можно использовать и для удаления папки, если добавить флаг -r, обозначающий рекурсивно (вместе со всем
содержимым):
rm -r dir1
Или сразу несколько папок:
rm -r dir1 dir2
Также есть флаг -f, который обозначает (force) без уточнения, уверены ли вы, что хотите удалить, флаги всё еще можно
комбинировать.
rm -rf dir1
Переименование и перемещение файлов происходит одной и той же командой mv(move):
mv название_файла новое_название
или переместить файл:
mv название_файла путь/
Для этого используется команда cp (copy):
Скопировать файл file1 и назвать копию file2:
cp file1 file2
Скопировать папку:
cp -a dir1/ dir2/
Скопировать файл в папку:
cp file1 dir1/
У всех базовых команд есть справка, и вызывается она через параметр --help, где вы можете посмотреть детали той или
иной команды:
rm --help
touch --help
Для поиска используются две основные команды find и locate.
Все детали о том как они работают тут.
Команда more (больше) нужна для чтения текстовых файлов:
more some.txt
Забудьте о её существовании)
Используйте команду less:
less <путь_к_файлу/имя_файла>
less less.txt
Есть куча параметров, таких как переход к определённой строке, поиск текста и т. д.
Как можно понять из названий, показывают начало или конец файл соответственно.
head [опции] <путь_к_файлу/имя_файла>
head error.log
tail [опции] <путь_к_файлу/имя_файла>
tail error.log
tail самая часто используемая команда для чтения логов, т. к. обычно ошибки в самом конце.
Обладает параметром -f,он нужен, чтобы при обновлении файла показывать эти обновления в режиме реального времени
(Допустим, если сервер работает, и ошибки нужно отображать прямо сейчас)
Нужны для просмотра целиком небольших текстовых файлов:
cat [опции] <путь_к_файлу/имя_файла>
cat test1
На самом деле, при комбинировании некоторых свойств можно делать не совсем очевидные вещи.
Например, добавить текст из одного файла в другой:
cat test2 >> test3
или объединить несколько файлов в один:
cat test1 test2 > test4
tac работает точно также, но выводит файл в обратном порядке (неизвестно, зачем нужен, в отличие от cat ни разу не
использовал)

У любого объекта в Linux существует набор прав, который обозначает, кому и что можно с этим файлом делать.
Также при установке системы всегда создаётся так называемый супер пользователь, для которого задаётся пароль.
Любую команду можно выполнить от имени суперпользователя, если вы знаете пароль, и эта команда проигнорирует все возможные разрешения.
Для того чтобы выполнить такую команду, нужно использовать перед командой специальное слово sudo.
Чтобы проверить права файлов в текущей директории, необходимо выполнить команду ls -l:
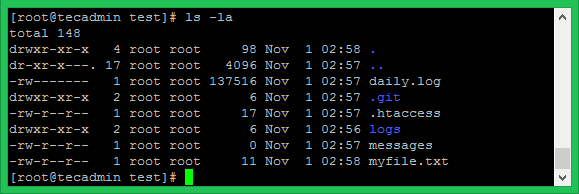
Вот эти страшные символы в начале и есть права доступа.
Если вы хотите посмотреть права для конкретного файла или папки, вы можете использовать:
ls -l имя_нужного_файла
ls -l имя_нужной_директории
Допустим, у нас есть такие права drwxrwxr-x.
Это символьная форма записи прав, состоит из 10 символов.
Первый символ обозначает тип данных.
Может быть:
\- обычный файл;d- директория;l- симлинк, разберём на следующем занятии.
Но бывают и более экзотические версии:
b- файл блочного устройства;c- файл символьного устройства;s- доменное гнездо (socket);p- именованный канал (pipe).
Последние 4 крайне редки, но socket мы будем использовать.
Следующие 9 символов обозначают права доступа.
rwxrwxr-x
На самом деле, состоит из 3 групп по 3 символа:
rwx rwx r-x
- Первая группа из трех символов обозначает права доступа владельца файла или директории (u - user).
- Вторая группа из трех символов обозначает права доступа на файл или директорию для системной группы (g - group).
- Третья группа из трех символов обозначает права доступа на файл или директорию для всех остальных (o - others).
У этих трёх групп одинаковая комбинация символов, то есть:
rwx
Что они обозначают:
r- этоread, то есть право доступа на чтение файла или директории.w- этоwrite, то есть право на изменение и удаление файла или директории.x- этоexecute, то есть право на запуск файла как программы или вход в директорию.
Всегда располагаются именно в таком порядке, и если одной (или больше) из этих букв нет, то этого права тоже нет.
Если взять наш пример:
drwxrwxr-x
это сообщение обозначает, что является директорией, у владельца и у группы есть полные права доступа - на чтение, изменение, удаление, запуск (вход внутрь каталога), у всех остальных есть только права на чтение и запуск (вход внутрь каталога).
Если мы посмотрим внимательнее на скрин из команды ls -l, то увидим всю нужную информацию:
Как видно на скриншоте:
- в третьей колонке идет имя владельца файла;
- в четвертой колонке идет название группы.
Для изменения прав в текстовом режиме (бывает еще числовой, рассмотрим ниже, и он используется чаще)
Нужно выполнить команду chmodЖ
chmod personsOperatorRights имя_файла_или_имя_директории
Вместо persons нужно использовать совокупность символов или один из:
u(user) - пользователь, владелец файла или директории.g(group) - группа файла или директории.o(others) - все остальные.a(all), то есть все вместе взятые - владелец, группа и все остальные.
Этот символ обозначает субъект, которому будут назначены, удалены или изменены права.
Вместо Operator может быть один из следующих символов:
+"плюс", добавляем нужные права.-"минус", удаляем нужные права.="равно", устанавливаем нужные права.
Этот символ обозначает оператор, от которого зависит, будут ли добавлены, удалены или установлены нужные права, которые последуют за оператором.
Вместо Rights перечисляем символы прав доступа:
r(read) - чтение.w(write) - запись.x(execute) - выполнение.
Здесь идёт цепочка из трёх перечисленных символов, но в определённом порядке rwx. Но при этом не нужно указывать тире
для пропуска. Примеры: rwx, rw, wx, rx, r, w, x.
Если Вы не являетесь владельцем файла или директории или у вас нет прав на изменение файла, то нужно будет использовать права суперпользователя:
sudo chmod personsOperatorRights имя_файла_или_имя_директории
Убираем права для группы на изменение файла:
chmod g-w file1
Убираем права на чтение у группы и всех остальных:
chmod go-r file1
Добавим для группы права на чтение и изменение:
chmod g+rw file1
Изменим рекурсивно права на файлы и директории внутри нужной директории. Отменим, к примеру, все права у остальных пользователей и групп:
chmod -R o-rwx ~/my_images/
-R в данном случае значит рекурсивно (все вложенные в папку объекты тоже изменятся)
Можно не указывать объект, если вы хотите заменить определённое право для всех, например, всем разрешить исполнять файл.
chmod +x имя_файла.sh
Я лично чаще встречал изменения прав доступа в числовом виде, поэтому рекомендую в нём разобраться тоже.
Итак, допустим, у нас всё еще есть вот такие права, которые мы хотим назначить:
rwxrwxr-x
Чтобы преобразовать их в число, нужно разбить их на 3 группы:
rwx rwx r-x
Теперь, если символ есть заменить его на 1, если прочерк, то заменить его на 0:
111 111 101
А теперь перевести это число из двоичной системы в восьмеричную:
7 7 5
Вот мы и получили числовую запись прав доступа
Например:
chmod 775 имя_файла
Или
chmod 700 имя_файла - предоставить права на всё, но только владельцу файла.
Для этого есть специальная команда chown (change owner).
Использовать так:
sudo chown имя_нового_владельца:имя_новой_группы имя_файла_или_директории
Необязательно указывать и владельца, и группу, можно изменить только что-то одно, и так же принимает параметр рекурсивно:
sudo chown :имя_новой_группы имя_файла_или_директории
sudo chown имя_нового_владельца имя_файла_или_директории
sudo chown -R имя_нового_владельца:имя_новой_группы имя_директории
Чтобы узнать текущего пользователя, используйте команду whoami.
Чтобы узнать группы текущих пользователей, используйте команду groups.
Чтобы получить список пользователей, используйте команду users.
Чтобы получить группы конкретного пользователя, используйте команду groups user_name.
Если нам необходимо, чтобы доступ к файлу имел только суперпользователь, можно указать в качестве владельца
файла root.
sudo chown root file1
Изменится сразу и владелец группы.
Естественно, как и в любой другой операционной системе, мы можем устанавливать различные приложения, допустим, тот же
postgres или даже Python.
Для управления установленными пакетами в семействе дистрибутивов Ubuntu/Mint мы можем использовать менеджер APT (Advanced Package Tool).
Для более ранних версий чем, например, Ubuntu 16.04, можно было бы использовать apt-get.
Для обновления списка доступных приложений используется команда update. Обратите внимание, что такая операция будет
требовать sudo.
sudo apt update
Вывод этой команды на экран включает данные о доступных пакетах, полученные от различных серверов.
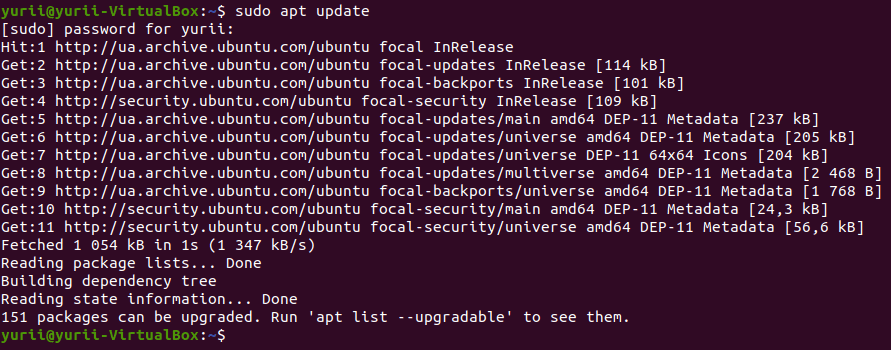
Каждая строка вывода начинается с одного из трёх идентификаторов: Hit, Ign и Get, имеющих следующие трактовки
значений:
Hit— доступных обновлений для данного пакета сейчас нет.Ign— данный пакет игнорируется, так как его нельзя проверить или при проверке обновлений возник тривиальный сбой (не беспокойтесь, это не ошибка)Get— доступна для скачивания более новая версия пакета.
Обратите внимание, мы ничего не обновляли, а только проверили наличие обновлений в системе. Для скачивания всех доступных обновлений используется следующая команда:
sudo apt upgrade
Для установки нового пакета используется команда:
sudo apt install package_name
При установке пакетов тоже будет работать TAB, например, если вы начнёте писать net-t и нажмете TAB, вам выпадет
список из доступных приложений, там как минимум будет net-tools и net-telnet-cisco.
Можно установить несколько пакетов одновременно:
sudo apt install package_1 package_2 package_3
Если вы попытаетесь установить уже установленный пакет, система просто проверит наличие обновлений, и если обнаружит, то установит их.
Можно установить конкретную версию пакета, для этого её необходимо указать явно:
sudo apt install package_name=version_number
Для удаления пакета используется две разные команды:
sudo apt remove package_name
или
sudo apt purge package_name
remove— удаляет все двоичные файлы пакета, но не трогает его файлы конфигурации;purge— удаляет и пакет, и его файлы конфигурации.
То есть, если вы удалите что-то через remove и потом переустановите, у вас будут сохранены прошлые настройки, а если
через purge, то абсолютно заново установленная программа.
У команды также есть возможность удалить не используемые приложения через команду sudo apt autoremove.
Очень часто для различных программ или задач необходимо сохранить какую-либо переменную, причём сделать это прямо в операционной системе. (Мы будем использовать их, например, для хранения паролей от базы или SECRET_KEY из Django)
Какие варианты нам предлагает Linux? Давайте посмотрим.
Если смотреть более широко, переменная окружения может быть трех типов.
Эти переменные определены только для текущей сессии. Они будут безвозвратно стерты после завершения сессии, будь то удаленный доступ или эмулятор терминала. Они не хранятся ни в каких файлах, а создаются и удаляются с помощью специальных команд.
Эти переменные оболочки в Linux определяются для конкретного пользователя и загружаются каждый раз, когда он входит в
систему при помощи локального терминала или же подключается удаленно. Такие переменные, как правило, хранятся в файлах
конфигурации: .bashrc, .bash_profile, .bash_login, .profile или в других файлах, размещенных в директории
пользователя.
Эти переменные доступны во всей системе для всех пользователей. Они загружаются при старте системы из системных файлов
конфигурации: /etc/environment, /etc/profile, /etc/profile.d/, /etc/bash.bashrc.
Это файл переменных конкретного пользователя. Загружается каждый раз, когда пользователь создает терминальный сеанс, то есть, проще говоря, открывает новый терминал. Все переменные окружения, созданные в этом файле, вступают в силу каждый раз, когда началась новая терминальная сессия.
Эти переменные вступают в силу каждый раз, когда пользователь подключается удаленно по SSH (рассмотрим в следующей
лекции). Если этот файл отсутствует, система будет искать .bash_login или .profile.
Этот файл для создания, редактирования и удаления каких-либо переменных окружения на системном уровне. Переменные окружения, созданные в этом файле, доступны для всей системы, для каждого пользователя и даже при удаленном подключении.
Системный bashrc. Этот файл выполняется для каждого пользователя каждый раз, когда он создает новую
терминальную сессию. Это работает только для локальных пользователей, при подключении через интернет такие переменные
не будут видны.
Системный файл profile. Все переменные из этого файла, доступны любому пользователю в системе, только если
он вошел удаленно. Но они не будут доступны при создании локальной терминальной сессии, то есть, если вы просто откроете
терминал.
Все переменные окружения Linux, созданные с помощью этих файлов, могут быть удалены простым удалением их оттуда. Только после каждого изменения нужно либо выйти и зайти в систему, либо выполнить эту команду:
source имя_файла
Локальные переменные окружения в Linux можно создавать следующими командами:
var=значение
export var=значение
Эти переменные будут доступны только для текущей терминальной сессии.
unset имя_переменной
Для создания пользовательских переменных откройте файл .bashrc и измените его.
Например, через nano:
nano ~/.bashrc
И добавьте там, например, такую строчку:
export CD='This is Losst Home'
Чтобы изменения вступили в силу, нужно явно указать, что мы изменили этот файл, через команду source:
source ~/.bashrc
Для проверки можем вызвать команду echo, которая просто печатает переменные:
echo $CD
Для создания системных переменных нужно выполнить такие же действия как и с пользовательскими, но на системном
уровне, для этого изменим файл /etc/bash.profile.
В остальном это будет работать точно так же.

SSH (от англ. “Secure Shell”) — это протокол удаленного администрирования, разработанный для осуществления
удаленного управления операционными системами и туннелирования TCP-соединения. Использование этого протокола допускает
использование разных алгоритмов шифрования, что позволяет безопасно работать практически в любой незащищенной среде:
работать с ПК через командную оболочку, передавать по шифрованному каналу любой тип данных (например, видеофайлы и
аудиофайлы). Первый релиз протокола состоялся в 1995 г., а уже в 1996 году была представлена его усовершенствованная
версия, которая и стала основой для дальнейшего развития продукта. Сегодня для всех сетевых ОС доступны SSH сервер и
SSH клиент, а сам протокол SSH является одним из самых популярных решений для удаленного управления системами и
передачи важной информации.
а практике по SSH мы обычно будем подключаться к удалённым серверам и иногда передавать через этот протокол файлы (хотя чаще файлы всё-таки передаются через git, который в свою очередь использует SSH для аутентификации, если мы говорим о развёртывании серверов).
SSH - это протокол, использующий клиент-серверную модель для аутентификации удаленных систем и обеспечения шифрования данных, обмен которыми происходит в рамках удаленного доступа.
По умолчанию для работы протокола используется TCP-22 порт: на нем сервер (хост) ожидает входящее подключение и после получения команды и проведения аутентификации организует запуск клиента, открывая выбранную пользователем оболочку. При необходимости пользователь может менять используемый порт (на практике это очень часто делается). Для создания SSH подключения клиент должен инициировать соединение с сервером, обеспечив защищенное соединение и подтвердив свой идентификатор (проверяются соответствие идентификатора с предыдущими записями, хранящимися в RSA-файле, и личные данные пользователя, необходимые для аутентификации).
Использование SSH подключения имеет ряд преимуществ:
- безопасная работа на удаленном ПК с использованием командной оболочки; использование разных алгоритмов шифрования (симметричного, асимметричного и хеширования);
- возможность безопасного использования любого сетевого протокола, что позволяет передавать по защищенному каналу файлы любого размера.
Чтобы обеспечить SSH доступ, пользователю необходимы SSH-клиент и SSH-сервер. Каждая операционная система имеет свой
набор программ, обеспечивающих соединение. Так, для Linux - это lsh (server и client), openssh (server и client).
Для Mac OS зачастую используется NiftyTelnet SSH. А в ОС Windows для реализации соединения через SSH протокол чаще
всего используется приложение PuTTY.

Синтаксис команды для подключения из Linux к другому Linux выглядит следующим образом:
ssh [опции] имя пользователя@сервер [команда]
Я для такого подключения буду использовать терминал GIT для Windows, который я при установке настроил как консоль Linux. На самом деле версии Windows 10/11 содержат в себе урезанное ядро Linux, что и позволяет использовать некоторые базовые команды и синтаксис Linux.
На самом деле, все конфигурации ssh сервера находятся в папке /etc/ssh/, если хотите деталей, можете изучить их
самостоятельно.
Из интересного там есть возможность изменить стандартный порт с 22, ограничить пользователей или группы, которые могут подключаться и т. д.
Для подключения нужно использовать команду:
ssh user@host
Где user - это имя пользователя, от чьего имени мы хотим подключиться.
А host - это IP или URL адрес машины, к которой мы хотим подключиться. На практике этот параметр чаще всего будет
предоставлен компанией, у которой мы будем арендовать сервер (а чаще всего используется именно арендованные сервера),
либо, если вам необходим собственный сервер, он должен быть обеспечен статическим IP адресом для выхода в интернет.
После такого запроса команда затребует пароль от пользователя. И как чаще всего бывает при введении пароля в Linux, никакие введённые символы отображаться не будут, но всё работает.

Использовать вход по паролю можно, но чаще всего не нужно. :)
При использовании входа по паролю появляется одна проблема, такой пароль может перебрать злоумышленник, и на практике это вполне возможно. А мы же не хотим подарить кому-то и код, и пароли от базы данных и т.д.
Поэтому чаще всего используются ssh ключи. Это специально сгенерированные 2 (чаще всего два) файла, причём
сгенерированные так, что, имея один из ключей, можно при помощи специальных алгоритмов проверить, подходит ли он ко
второму. Один из них называется public (публичный или открытый), второй - private (приватный или закрытый).
Публичный ключ мы можем оставлять почти где угодно без особых переживаний, а вот приватный всегда должен оставаться в
тайне (как и пароль, так как используется для этих же целей).

Для этого в Linux существует специальная команда:
ssh-keygen -t rsa
Параметр -t отвечает за то, какой именно алгоритм шифрования нужно использовать; для нас обычно подходит два
алгоритма rsa или dsa, я чаще пользуюсь rsa.
После введения команды командная строка спросит нас о некоторых деталях. Куда именно сложить полученные файлы (по
умолчанию будет использована папка ~/.ssh/, рекомендую не менять), и так называемую кодовую фразу, она не является
обязательной, можно оставить пустую строку, по сути, эта фраза будет являться уже паролем от нашего закрытого ключа, на
практике обычно нет особого смысла задавать эту фразу.
После генерации в указанной папке сгенерируются два файла: закрытый ключ some_key_name и публичный ключ
some_key_name.pub.
Обычно эти ключи генерируются сразу на удалённом сервере, куда мы впоследствии собираемся подключаться. Чтобы
мы могли подключиться, публичный ключ нужно переместить в правильную папку с правильным названием файла
authorized_keys.
cat some_key_name.pub >> ~/.ssh/authorized_keys
Файл оригинала обычно удаляется, и больше публичный ключ не трогается:
rm some_key_name.pub
Теперь достаточно скопировать файл публичного ключа (любым доступным способом, хоть вручную переписать, обычно там будет храниться 3-5 строк символов) туда, откуда мы собираемся подключаться.
Для подключения по ssh через ключи необходимо указать параметр -i, в котором указать путь к открытому ключу. Если
мы скопировали такой файл в папку ~/.ssh/, как чаще всего и делается, то подключиться можно так:
ssh user@host -i ~/.ssh/some_key_name.pub

Обычно, когда мы арендуем машину у какой-либо компании, нам сразу при покупке предоставят юзернейм, хост и файл открытого ключа. Что позволяет нам сразу подключиться к такой машине, не заморачиваясь с настройкой подключения.

Симлинк - это сокращение от «символическая ссылка».
Символическая («мягкая») ссылка (также «симлинк», от англ. Symbolic link) — специальный файл в файловой системе, в котором вместо пользовательских данных содержится путь к файлу, открываемому при обращении к данной ссылке (файлу).
Целью ссылки может быть любой объект: например, другая ссылка, файл, каталог или даже несуществующий файл (в последнем случае при попытке открыть его должно выдаваться сообщение об отсутствии файла). Ссылка, указывающая на несуществующий файл, называется висячей или битой.
Символические ссылки используются для более удобной организации структуры файлов на компьютере, так как:
- позволяют для одного файла или каталога иметь несколько имён и различных атрибутов;
- свободны от некоторых ограничений, присущих жёстким ссылкам (последние действуют только в пределах одной файловой системы (одного раздела) и не могут ссылаться на каталоги).
Такие типы файлов существуют в различных операционных системах, включая Windows.
Для создания такой ссылки в Linux используется команда ln:
ln -s файл имя_ссылки
Такие ссылки мы будем использовать для передачи северам файлов конфигурации.
Что такое curl? curl — это сокращение от “Client URL”. Утилита доступна в большинстве систем на основе Unix и предназначена для проверки подключения к URL-адресам. Кроме того, команда curl — отличный инструмент передачи данных. Давайте же узнаем, как ею пользоваться.
По факту curl - это тот же самый Postman прямо из командной строки.
Команда curl поддерживает следующий список протоколов:
- HTTP и HTTPS
- FTP и FTPS
- IMAP и IMAPS
- POP3 и POP3S
- SMB и SMBS
- SFTP
- SCP
- TELNET
- GOPHER
- LDAP и LDAPS
- SMTP и SMTPS
Это наиболее важные поддерживаемые протоколы, но есть и другие. curl работает на libcurl, которая является бесплатной
библиотекой для передачи URL на стороне клиента.
Сначала давайте проверим её доступною версию с помощью следующей команды:
curl --version
В выводе вы должны увидеть версию и список поддерживаемых протоколов. Теперь мы можем взглянуть на некоторые примеры команд curl.

Итак, давайте узнаем, как пользоваться утилитой. Основной синтаксис curl выглядит следующим образом:
curl [OPTIONS] [URL]
Список доступных флагов для команды curl можно посмотреть ТУТ.
Самый простой пример использования curl — отображение содержимого страницы. Приведённая ниже команда отобразит домашнюю страницу testdomain.com.
curl testdomain.com
Эта команда отобразит полный исходный код домашней страницы домена. Если протокол не указан, curl интерпретирует его как HTTP.
Команды curl могут загружать файлы из удалённой локации. Есть два способа это сделать:
-O(--Output) сохранит файл в текущем рабочем каталоге с тем же именем, что и у удалённого;-o(--output) позволяет указать другое имя файла или местоположение.
Вот пример:
curl -O http://testdomain.com/testfile.tar.gz
Приведённая выше команда сохранит файл как testfile.tar.gz.
curl -o newtestfile.tar.gz http://testdomain.com/testfile.tar.gz
А эта команда сохранит его как newtestfile.tar.gz.
Если по какой-либо причине загрузка будет прервана, вы можете возобновить её с помощью следующей команды
(-C (--continue-at):
curl -C -O http://testdomain.com/testfile.tar.gz
curl также позволяет загрузить несколько файлов одновременно. Пример:
curl -O http://testdomain.com/testfile.tar.gz -O http://mydomain.com/myfile.tar.gz
Если вы хотите загрузить несколько файлов с нескольких URL, перечислите их все в файле. Команды Curl могут быть
объединены с xargs для загрузки различных URL-адресов.
Например, если у нас есть файл allUrls.txt, который содержит список всех URL-адресов для загрузки, то приведённый ниже пример выполнит загрузку всех файлов с этих URL.
xargs –n 1 curl -O < allUrls.txt
Типичный HTTP-запрос всегда содержит заголовок. Заголовок HTTP отправляет дополнительную информацию об удалённом веб-сервере вместе с фактическим запросом. С помощью инструментов разработчика в браузере вы можете посмотреть сведения о заголовке, а проверить их можно с помощью команды curl.
Пример ниже демонстрирует, как получить информацию о заголовке с веб-сайта.
curl -I www.testdomain.com
Используя curl, вы можете сделать запрос GET и POST. Запрос GET будет выглядеть следующим образом:
curl http://mydomain.com
А вот пример запроса POST:
curl –data “text=Hello” https://myDomain.com/firstPage.jsp
Здесь text=Hello — это параметр запроса POST. Такое поведение похоже на HTML-формы.
Вы также можете указать несколько методов HTTP в одной команде curl. Сделайте это, используя опцию –next, например:
curl –data “text=Hello” https://myDomain.com/firstPage.jsp --next https://myDomain.com/displayResult.jsp
Команда содержит запрос POST, за которым следует запрос GET.
Каждый HTTP-запрос содержит агент пользователя, который отправляется как часть запроса. Он указывает информацию о браузере клиента. По умолчанию запрос содержит curl и номер версии в качестве информации об агенте пользователя. Пример вывода показан ниже:
“GET / HTTP/1.1” 200 “_” ”curl/7/29/0”
Вы можете изменить дефолтную информацию об агенте пользователя, используя следующую команду:
curl -I http://mydomain.com –-user-agent “My new Browser”
Теперь вывод будет выглядеть так:
“GET / HTTP/1.1” 200 “_” ”My new Browser”
При помощи параметра -U (--user) можно указать параметры авторизации:
curl -U username:password -O http://testdomain.com/testfile.tar.gz
Утилиту можно использовать для проверки того, какие файлы cookie загружаются по URL. Допустим, вы зашли на https://www.samplewebsite.com, вы можете вывести и сохранить файлы cookie в файл, а затем получить к ним доступ, используя команду cat или редактор Vim.
Вот пример такой команды:
curl --cookie-jar Mycookies.txt https://www.samplewebsite.com /index.html -O
Точно также, если у вас есть файлы cookie в файле, вы можете отправить их на сайт. Вот, как это будет выглядеть:
curl --cookie Mycookies.txt https://www. samplewebsite.com

Если в двух словах, то Cron – это планировщик задач. Если подробнее, то это утилита, позволяющая выполнять скрипты на
сервере в назначенное время с заранее определенной периодичностью.
К примеру, у вас есть скрипт, который собирает какие-либо статистические данные каждый день в 6 часов вечера. Такие
скрипты называют «заданиями», а их логика описывается в специальных файлах под названием сrontab.
crontab – это таблица с расписанием запуска скриптов и программ, оформленная в специальном формате, который умеет
считывать компьютер. Для каждого пользователя системы создается отдельный crontab-файл со своим расписанием. Эта
встроенная в Linux утилита доступна на низком уровне в каждом дистрибутиве.
В Linux-дистрибутивах с поддержкой systemd (о нём дальше) Cron считается устаревшим решением, его заменили утилитой
systemd.timer. Ее предназначение и функциональность не отличаются, но фактически частота использования Cron все еще
выше.
Обычно Cron заставляют повторять вполне очевидные задачи в духе регулярного создания резервных копий данных. Но это не все.
-
Некоторые пользователи с помощью планировщика корректируют системное время. На многих компьютерах оно настраивается через Network Time Protocol. А так как этот протокол настраивает только время ОС, время, установленное для «железа», может отличаться. Cron позволяет регулярно корректировать время, установленное для аппаратного обеспечения, в соответствии со временем ОС.
-
Еще один популярный сценарий – создание оповещений, появляющихся каждое утро и рассказывающих о состоянии компьютера. В эти сообщения может входить любая полезная для пользователя информация.
-
Cron иногда работает даже без ведома пользователя. Эту утилиту используют такие сервисы, как Logwatch, logrotate и Rootkit Hunter. Повторяющиеся задачи они настраивают, как и пользователи, через Cron. С помощью Cron пользователи автоматизируют самые разные задачи, сокращая вмешательство системного администратора в работу сервера.
Планировать задачи через панель управления удобно, но не всегда возможно. Не все хостинг-провайдеры предлагают такие функциональные веб-интерфейсы. В этом случае придется воспользоваться командной строкой, подключившись к серверу по протоколу Secure Shell.
Для работы с планировщиком в системе есть ряд команд, помогающих решать основные задачи:
crontab -e– открывает конфигурационный файл (поговорим о нем чуть подробнее в разделе с первичной настройкой).crontab -l– показывает список задач из конфигурационного файла (все, что было запланировано).crontab -r– удаляет конфигурационный файл вместе со всеми запланированными задачами.сrontab -v– показывает, когда в последний раз открывался конфигурационный файл.
Чтобы запланировать задачи, используя командную строку, необходимо выполнить базовую настройку Cron, проверить, не
установлены ли ограничения, и заполнить расписание задач в соответствии с синтаксисом сrontab.
Как мы уже выяснили ранее, планировщик черпает параметры для выполнения своих задач из crontab-файлов (таблиц с расписанием). У каждого пользователя, включая root, должен быть свой crontab-файл. По умолчанию он не существуют, поэтому придется создать его вручную.
Для этого существует команда crontab -e. Она автоматически генерирует таблицу в директории /var/spool/cron.
Вновь созданный файл будет пустым текстовым полем. Необходимо добавлять в него все параметры самостоятельно с нуля,
опираясь на синтаксис сrontab (более подробно поговорим о нем ниже). После ввода параметров нужно сохранить параметры
редактора, нажав на клавишу F2, а затем покинуть конфигурационный файл, нажав на клавишу F10. При введении корректных
параметров в терминале отобразится строка crontab: installing new crontab.
Опытные разработчики и системные администраторы не рекомендуют использовать для редактирования расписания текстовые
редакторы в духе Nano, Emacs или Vi. Команды crontab позволяют не только внести изменения в таблицу запланированных
задач, но и перезапустить фоновый процесс crond, отвечающий за работу утилиты после сохранения настроек.
У Cron есть функция установки ограничений на использование, задаваемых через два специальных файла: cron.allow и
cron.deny.
Первый файл находится в директории /usr/lib/cron/cron.allow и содержит в себе список учетных записей (имен
пользователей), которые имеют право на планирование задач с помощью встроенных системных утилит.
Второй файл находится в директории /usr/lib/cron/cron.deny. В нем указываются имена пользователей, которые не могут
запускать встроенный в систему планировщик задач.
Если первого файла не существует, то любой пользователь может планировать задачи с помощью встроенного в систему планировщика, но только при условии, что его имени нет во втором файле. Если удалить оба файла, то каждый пользователь сможет планировать задачи без ограничений.

# crontab -e
SHELL=/bin/bash
MAILTO=mymail@someprovider.com
PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin
# Детали смотрите в следующих разделах
# Примеры оформления задач в планировщике (формат данных):
# .---------------- минуты (0 - 59)
# | .------------- часы (0 - 23)
# | | .---------- дни месяца (1 - 31)
# | | | .------- сами месяцы (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- дни недели (0 - 6) (0 или 7 это воскресенье в зависимости от настроек системы) можно использовать сокращения типа mon,tue,wed,thu,fri,sat,sun
# | | | | |
# * * * * * имя пользователя команда, которую нужно запустить
# создание копии всей операционной системы с помощью кастомного скрипта
01 01 * * * /usr/local/bin/bckp -vbd1 ; /usr/local/bin/bckp -vbd2
# установка соответствия между временем операционной системы и "железа"
03 05 * * * /sbin/hwclock --systohc
# проведение обновления операционной системы в заданный период времени
25 04 1 * * /usr/bin/apt-get update
Первые три линии кода в таблице отвечают за первичную настройку. Сначала указывается оболочка, в которой будет работать Cron. У утилиты нет каких-либо предпочтений, поэтому можно указать любую на собственное усмотрение (в нашем примере это bash). Затем указывается адрес электронной почты, на который будут отправляться отчеты о работе планировщика. И напоследок указывается путь к окружению.
Ниже находятся параметры, используемые для запуска процессов в определенный период времени. В комментариях описан базовый синтаксис, включающий в себя формат времени, имя пользователя и команду, которая должна быть запущена.
В нашем случае указаны команды:
02 04 5 * * /usr/local/bin/bckp -vbd1 ; /usr/local/bin/bckp -vbd2
04 06 * * * /sbin/hwclock –systohc
10 05 5 * * /usr/bin/apt-get update
05 * * * * rm /home/myusername/tmp/*
Команда
02 04 5 * * /usr/local/bin/bckp -vbd1 ; /usr/local/bin/bckp -vbd2
создает в таблице расписания задачу на запуск скрипта под названием bckp (представим, что такой существует), который
создает резервную копию всей системы на стороннем накопителе. Он выполняется 5 числа каждого месяца в 4 часа 2 минуты
утра. Это видно по числовым значениям. Звездочки же указывают на отсутствие конкретного значения. Cron воспринимает их
как «выполнять каждый раз», то есть каждый месяц, день или неделю.
Команда
04 06 * * * /sbin/hwclock –systohc
меняет время аппаратного обеспечения на то, что используется в системе. Делает это каждый день, каждую неделю и каждый месяц в 6 часов 4 минуты утра. Как видите, здесь пропущено третье значение. Поэтому команда и запускается ежедневно, так как нет более конкретных правил.
Команда
10 05 5 * * /usr/bin/apt-get update
запускает обновление пакетов с помощью пакетного менеджера apt каждый месяц 5 числа в 05:10.
Команда
05 * * * * rm /home/myusername/tmp/*
удаляет содержимое папки с временными файлами для конкретного пользователя (меня) на пятой минуте (первый пункт) каждого часа. Так как определенные значения отсутствуют для всех остальных пунктов, получается, что скрипт готов выполняться каждый день, каждый месяц и каждый час. Но первое значение указано, поэтому он будет дожидаться пятой минуты и запускаться в этот момент. То есть в 12:05, 13:05, 14:05 и т. п.
Как видите, разобраться с базовыми командами несложно.
Apache и Nginx — два самых широко распространенных веб-сервера с открытым исходным кодом в мире. Вместе они обслуживают более 60% трафика во всем интернете. Оба решения способны работать с разнообразными рабочими нагрузками и взаимодействовать с другими приложениями для реализации полного веб-стека.
Несмотря на то, что у Apache и Nginx много схожих качеств, их нельзя рассматривать как полностью взаимозаменяемые решения. Каждый из них имеет собственные преимущества и важно понимать, какой веб-сервер выбрать в какой ситуации. В этой статье описано то, как каждый из этих веб-серверов ведет себя при различных условиях.
Прежде чем погрузиться в различия между Apache и Nginx, давайте бегло взглянем на предысторию каждого из этих проектов.
Apache был разработан для доставки веб-контента, доступ к которому осуществляется через Интернет. Он известен тем, что играл ключевую роль в начальном росте интернета. Apache - это программное обеспечение с открытым исходным кодом, разработанное и поддерживаемое открытым сообществом разработчиков и работающее в самых разных операционных системах. Архитектура включает в себя ядро Apache и модули. Основной компонент предоставляет базовую серверную функцию, поэтому он принимает соединения и управляет параллелизмом. Различные модули соответствуют различным функциям, которые выполняются по каждому запросу. Конкретное развертывание Apache может быть сконфигурировано для включения различных модулей, таких как функции безопасности, управление динамическим контентом или для базовой обработки HTTP-запросов.
Модель «один сервер делает все» стала ключом к раннему успеху Apache. Однако по мере увеличения уровня трафика и увеличения количества веб-страниц и ограничения производительности настройка Apache на работу с реальным трафиком усложнялась.

Nginx был разработан специально для устранения ограничений производительности веб-серверов Apache. Производительность и масштабируемость Nginx обусловлены архитектурой, управляемой событиями. Он значительно отличается от подхода Apache. В Nginx каждый рабочий процесс может одновременно обрабатывать тысячи HTTP-соединений. Следовательно, Nginx - это легковесная, масштабируемая и высокопроизводительная реализация. Эта архитектура делает обработку больших и флуктуирующих нагрузок на данные гораздо более предсказуемой с точки зрения использования ОЗУ, использования ЦП и задержки.
Nginx также имеет богатый набор функций и может выполнять различные роли сервера:
- Обратный прокси-сервер для протоколов HTTP, HTTPS, SMTP, POP3 и IMAP
- Балансировщик нагрузки и HTTP-кеш
- Интерфейсный прокси для Apache и других веб-серверов, сочетающий гибкость Apache с хорошей производительностью статического контента Nginx
Разрабатывать и обновлять приложения на Apache очень просто. Модель «одно соединение на процесс» позволяет очень легко вставлять модули в любой точке логики веб-обслуживания. Разработчики могут добавлять код таким образом, что в случае сбоев будет затронут только рабочий процесс, выполняющий код. Обработка всех других соединений будет продолжаться без помех.
Nginx, с другой стороны, имеет сложную архитектуру, поэтому разработка модулей не легка. Разработчики модулей Nginx должны быть очень осторожны, чтобы создавать эффективный и точный код, без сбоев, и соответствующим образом взаимодействовать со сложным ядром, управляемым событиями, чтобы избежать блокирования операций.
Производительность измеряется тем, как сервер доставляет большие объемы контента в браузер клиента, и это важный фактор. Контент может быть статическим или динамическим. Давайте посмотрим статистику по этому вопросу.
Nginx работает в 2,5 раза быстрее, чем Apache, согласно тесту производительности, выполняемому до 1000 одновременных подключений. Другой тест с 512 одновременными подключениями показал, что Nginx примерно в два раза быстрее и потребляет меньше памяти. Несомненно, Nginx имеет преимущество перед Apache со статическим контентом. Поэтому, если вам нужно обслуживать одновременный статический контент, Nginx является предпочтительным выбором.
Результаты тестов Speedemy показали, что для динамического контента производительность серверов Apache и Nginx была одинаковой. Вероятная причина этого заключается в том, что почти все время обработки запросов расходуется в среде выполнения PHP, а не в основной части веб-сервера. Среда выполнения PHP довольно похожа для обоих веб-серверов.
Apache также может обрабатывать динамический контент, встраивая процессор языка, подобного PHP, в каждый из его рабочих экземпляров. Это позволяет ему выполнять динамический контент на самом веб-сервере, не полагаясь на внешние компоненты. Эти динамические процессоры могут быть включены с помощью динамически загружаемых модулей.
Nginx не имеет возможности обрабатывать динамический контент изначально. Чтобы обрабатывать PHP и другие запросы на динамический контент, Nginx должен перейти на внешний процессор для выполнения и дождаться отправки визуализированного контента. Однако этот метод также имеет некоторые преимущества. Поскольку динамический интерпретатор не встроен в рабочий процесс, его издержки будут присутствовать только для динамического содержимого.
Apache работает во всех операционных системах, таких как UNIX, Linux или BSD, и полностью поддерживает Microsoft Windows. Nginx также работает на нескольких современных Unix-подобных системах и поддерживает Windows, но его производительность в Windows не так стабильна, как на платформах UNIX.

И Apache, и Nginx являются безопасными веб-серверами. Apache Security Team существует, чтобы предоставить помощь и советы проектам Apache по вопросам безопасности и координировать обработку уязвимостей безопасности. Важно правильно настроить серверы и знать, что делает каждый параметр в настройках.
Веб-серверы могут быть настроены путем добавления модулей. Apache долго загружал динамические модули, поэтому все модули Apache поддерживают это.
Nginx Plus (Nginx Plus - это программный балансировщик нагрузки, веб-сервер и кэш контента, построенный на основе открытого исходного кода Nginx) также использует модульную архитектуру. Новые функции и возможности могут быть добавлены с программными модулями, которые могут быть подключены к работающему экземпляру Nginx Plus по требованию. Динамические модули добавляют в Nginx Plus такие функции, как геолокация пользователей по IP-адресу, изменение размеров изображений и встраивание сценариев Lua в модель обработки событий Nginx Plus. Модули создаются как Nginx, Inc., так и сторонними разработчиками.
Большинство необходимых функциональных возможностей основного модуля (например, прокси, кэширование, распределение нагрузки) поддерживаются обоими веб-серверами.
Важным моментом, который следует учитывать, является доступная справка и поддержка веб-серверов среди прочего программного обеспечения. Поскольку Apache был популярен так долго, поддержка сервера довольно распространена повсеместно. Для главного сервера и для основанных на задачах сценариев, связанных с подключением Apache к другому программному обеспечению, имеется большая библиотека документации первого и стороннего производителя.
Наряду с документацией многие инструменты и веб-проекты содержат инструменты для начальной загрузки в среде Apache. Это может быть включено в сами проекты или в пакеты, поддерживаемые отделом упаковки вашего дистрибутива.
Apache, как правило, получает большую поддержку от сторонних проектов просто из-за своей доли рынка и продолжительности времени, в течение которого он был доступен.
В прошлом для Nginx было трудно найти исчерпывающую англоязычную документацию из-за того, что большая часть ранней разработки и документации была на русском языке. Однако на сегодняшний день документация заполнена, и на сайте Nginx имеется множество ресурсов для администрирования и доступной документации от третьих лиц.

Для многих приложений Nginx и Apache хорошо дополняют друг друга. Очень распространенным начальным шаблоном является развертывание программного обеспечения Nginx с открытым исходным кодом в качестве прокси-сервера (или Nginx Plus в качестве платформы доставки приложений) перед веб-приложением на основе Apache. Nginx выполняет тяжелую работу, связанную с HTTP - обслуживает статические файлы, кэширует содержимое и разряжает медленные HTTP-соединения - так что сервер Apache может выполнять код приложения в безопасной и защищенной среде.
В случае с разворачиванием проектов на Python, мы будем использовать Nginx как прокси сервер, а вот в случае с обработкой данных, мы будем использовать совсем другие технологии, о них на следующем занятии.
Что или кто такие демоны с точки зрения линукса?

Демоны много работают для того, чтобы вы могли сосредоточиться на своем деле. Представьте, что вы пишете статью или книгу. Вы заинтересованы в том, чтобы писать. Удобно, что вам не нужно вручную запускать принтер и сетевые службы, а потом следить за ними весь день для того, чтобы убедиться, что всё работает нормально.
Демон Linux - это программа, у которой есть определённая уникальная цель. Обычно, это служебные программы, которые незаметно работают в фоновом режиме для того, чтобы отслеживать состояние и обслуживать определённые подсистемы и гарантировать правильную работу всей операционной системы в целом. Например, демон принтера отслеживает состояние служб печати, а сетевой демон управляет сетевыми подключениями и следит за их состоянием.
Многие люди, перешедшие в Linux из Windows, знают демонов как службы или сервисы. В MacOS термин "Служба" имеет другое значение. Так как MacOS - это тоже Unix, в ней испольуpются демоны. А службами называются программы, которые находятся в меню "Службы".
Демоны выполняют определённые действия в запланированное время или в зависимости от определённых событий. В системе Linux работает множество демонов, и каждый из них предназначен для того, чтобы следить за своей небольшой частью операционной системы. Поскольку они не находятся под непосредственным контролем пользователя, они фактически невидимы, но, тем не менее, необходимы. Поскольку демоны выполняют большую часть своей работы в фоновом режиме, они могут казаться загадочными.
Обычно имена процессов демонов заканчиваются на букву d. В Linux принято называть демоны именно так. Есть много
способов увидеть работающих демонов. Они попадаются в списке процессов, выводимом утилитами ps, top или htop. Но
больше всего для поиска демонов подходит утилита pstree. Эта утилита показывает все процессы, запущенные в вашей
системе в виде дерева. Откройте терминал и выполните такую команду:
pstree
Вы увидите полный список всех запущенных процессов. Вы можете не знать, за что отвечают эти процессы, но они все будут
здесь перечислены. Вывод pstree - отличная иллюстрация того, что происходит с вашей машиной. Здесь удобно найти
запущенные демоны Linux.
Давайте разберемся, как запустить демона Linux. Ещё раз, демон - это процесс, работающий в фоновом режиме и находящийся вне контроля пользователя. Это значит, что демон не связан с терминалом, с помощью которого можно было бы им управлять. Процесс - это запущенная программа. В каждый момент времени он может быть запущенным, спящим или зомби (процесс выполнивший свою задачу, но ожидающий, пока родительский процесс примет результат).
В Linux существует три типа процессов: интерактивные, пакетные и демоны. Интерактивные процессы пользователь запускает из командной строки. Пакетные процессы обычно тоже не связаны с терминалом. Как правило, они запускаются в момент минимальной нагрузки на систему и делают свою работу. Это могут быть, например, скрипты резервного копирования или другие подобные обслуживающие сценарии.
Интерактивные и пакетные процессы нельзя считать демонами, хотя их можно запускать в фоновом режиме, и они делают определённую работу. Ключевое отличие в том, что оба вида процессов требуют участия человека. Демонам не нужен человек для того, чтобы их запускать.
Когда загрузка системы завершается, система инициализации, например, systemd, начинает создавать демонов. Этот процесс
называется forking (разветвление). Программа запускается как обычный интерактивный процесс с привязкой к терминалу,
но в определённый момент она делится на два идентичных потока. Первый процесс, привязанный к терминалу может выполняться
дальше или завершиться, а второй, уже ни к чему не привязанный, продолжает работать в фоновом режиме.
Существуют и другие способы ветвления программ в Linux, но традиционно для создания дочерних процессов создается копия
текущего. Термин forking появился не из ниоткуда. Его название походит от функции языка программирования C.
Стандартная библиотека C содержит методы для управления службами, и один из них называется fork. Используется он для
создания новых процессов. После создания процесса, процесс, на основе которого был создан демон, считается для него
родительским процессом.
Когда система инициализации запускает демонов, она просто разделяется на две части. В таком случае система инициализации будет считаться родительским процессом. Однако в Linux есть ещё один метод запуска демонов. Когда процесс создает дочерний процесс демона, а затем завершается. Тогда демон остается без родителя, и его родителем становится система инициализации. Важно не путать такие процессы с зомби. Зомби - это процессы, завершившие свою работу и ожидающие пока родительский процесс примет их код выхода.
Самый простой способ определить демона - это буква d в конце его названия. Вот небольшой список демонов, которые
работают в вашей системе. Каждый демон создан для выполнения определённой задачи.
systemd- основная задача этого демона унифицировать конфигурацию и поведение других демонов в разных дистрибутивах Linux.udisksd- обрабатывает такие операции как: монтирование, размонтирование, форматирование, подключение и отключение устройств хранения данных, таких как жесткие диски, USB флешки и т.д.logind- небольшой демон, управляющий авторизацией пользователей.httpd- демон веб-сервера позволяет размешать на компьютере или сервере веб-сайты.sshd- позволяет подключаться к серверу или компьютеру удалённо, по протоколу SSH.ftpd- организует доступ к компьютеру по протоколу FTP для передачи файлов.crond- демон планировщика, позволяющий выполнять нужные задачи в определённое время. (Да, cron работает не на чёрной магии)
systemd — это система инициализации и системный диспетчер, который стал новым стандартом для дистрибутивов Linux.
Из-за сложной адаптивности знакомство с системой systemd оправдано, поскольку это существенно упростит
администрирование серверов. Изучение и использование инструментов и демонов, которые включают systemd, поможет вам
лучше оценить предоставляемые возможности и гибкость или, по крайней мере, работать с минимальным количеством проблем.
В этом руководстве мы обсудим команду systemctl, которая является инструментом центрального управления для контроля
системы инициализации. Поговорим о том, как управлять службами, проверять статус, изменять состояние системы и работать
с файлами конфигурации.
Обратите внимание, что хотя система systemd стала системой инициализации по умолчанию для многих дистрибутивов Linux,
она не используется повсеместно во всех дистрибутивах.

Основополагающая цель системы инициализации заключается в инициализации компонентов, которые должны запускаться после загрузки ядра Linux (традиционно называются компоненты пользовательского пространства). Система инициализации также используется для управления службами и демонами для сервера и в любой момент времени работы системы. С учетом этого мы начнем с нескольких базовых операций по управлению службами.
В systemd целью большинства действий являются «модули», являющиеся ресурсами, которыми systemd знает, как управлять.
Модули распределяются по категориям по типу ресурса, который они представляют, и определяются файлами, известными как
файлы модулей. Тип каждого модуля можно вывести из суффикса в конце файла.
Для задач по управлению службами целевым модулем будут модули службы, которые имеют файлы модулей с суффиксом
.service. Однако для большинства команд по управлению службами вы можете не использовать суффикс .service,
поскольку systemd достаточно умна, чтобы знать, что вы, возможно, хотите работать со службой при использовании команд
по управлению службами.
Чтобы запустить службу systemd, используя инструкции в файле модуля службы, используйте команду start. Если вы
работаете как пользователь без прав root, вам потребуется использовать sudo, поскольку это влияет на состояние
операционной системы:
sudo systemctl start application.service
Как мы уже упомянули выше, systemd будет искать файлы *.service для команд управления службами, так что команду
можно легко ввести следующим образом:
sudo systemctl start application
Хотя вы можете использовать вышеуказанный формат для общего администрирования, для ясности мы будем использовать суффикс
.service для остальных команд, чтобы предельно четко выражать цель, над которой мы работаем.
Чтобы остановить работающую в данный момент службу, можно использовать команду stop:
sudo systemctl stop application.service

Чтобы перезапустить работающую службу, можно использовать команду restart:
sudo systemctl restart application.service
Если данное приложение может перезагрузить файлы конфигурации (без перезапуска), вы можете выдать команду reload для
инициализации этого процесса:
sudo systemctl reload application.service
Если вы не уверены, есть ли у службы функция перезагрузки своей конфигурации, можно использовать команду
reload-or-restart. Это перезагрузит необходимую конфигурацию при наличии. В противном случае будет перезагружена
служба для выбора новой конфигурации:
sudo systemctl reload-or-restart application.service
Указанные выше команды полезны для запуска или остановки служб во время текущего сеанса. Чтобы дать команду systemd
автоматически запускать службы при загрузке, их необходимо включить.
Для запуска службы во время загрузки используйте команду enable:
sudo systemctl enable application.service
При этом будет создана символическая ссылка из системной копии служебного файла (обычно в /lib/systemd/system или
/etc/systemd/system) в месте на диске, где systemd ищет файлы для автозапуска (обычно
/etc/systemd/system/some_target.target.wants; что такое цель, мы рассмотрим далее в этом руководстве).
Чтобы отключить автоматический запуск службы, можно ввести следующее:
sudo systemctl disable application.service
При этом будет удалена символическая ссылка, что укажет на то, что служба не должна запускаться автоматически.
Помните, что включение службы не запустит ее в текущем сеансе. Если вы хотите запустить службу и включить ее при
загрузке, необходимо дать обе команды, start и enable.
Чтобы проверить статус службы в вашей системе, можно использовать команду status:
systemctl status application.service
При этом вы получите статус службы, иерархию контрольных групп и первые несколько строк журнала.
Например, при проверке статуса сервера Nginx вы можете видеть следующий вывод:
Output
● nginx.service - A high performance web server and a reverse proxy server
Loaded: loaded (/usr/lib/systemd/system/nginx.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2015-01-27 19:41:23 EST; 22h ago
Main PID: 495 (nginx)
CGroup: /system.slice/nginx.service
├─495 nginx: master process /usr/bin/nginx -g pid /run/nginx.pid; error_log stderr;
└─496 nginx: worker process
Jan 27 19:41:23 desktop systemd[1]: Starting A high performance web server and a reverse proxy server...
Jan 27 19:41:23 desktop systemd[1]: Started A high performance web server and a reverse proxy server.
Это дает вам хороший обзор текущего статуса приложения и уведомляет о наличии каких-либо проблем или необходимости выполнения каких-либо действий.
Также есть методы для проверки определенных статусов. Например, чтобы проверить, активен ли (работает ли) модуль в
данный момент, можно использовать команду is-active:
systemctl is-active application.service
Это вернет текущий статус модуля, который обычно active или inactive. Код выхода будет «0», если он активен, и результат будет проще парсить в скрипты оболочки.
Чтобы увидеть, включен ли модуль, можно использовать команду is-enabled:
systemctl is-enabled application.service
Это выведет информацию о том, что служба enabled или disabled, и снова установит код выхода на «0» или «1» в зависимости от вопроса команды.
Третья проверка заключается в проверке того, находится ли модуль в состоянии сбоя. Это означает, что была проблема, которая запустила данный модуль:
systemctl is-failed application.service
Это вернет active, если он работает должным образом, или failed, если возникла ошибка. Если модуль был намеренно остановлен, может вернуться unknown или inactive. Статус выхода «0» означает, что произошел сбой, а статус выхода «1» указывает на какой-либо другой статус.
На самом деле, тема этого модуля гораздо шире, но пока нам этого достаточно.
А что делать, если нужно запустить какой-то скрипт, чтобы он работал постоянно (например, веб-сервер пусть работает, но не блокирует нам консоль), конечно же создавать свои юниты.
Systemd запускает сервисы, описанные в его конфигурации. Конфигурация состоит из множества файлов, которые по-модному
называют юнитами.
Все эти юниты разложены в трех каталогах:
/usr/lib/systemd/system/– юниты из установленных пакетов RPM — всякие nginx, apache, mysql и прочее/run/systemd/system/— юниты, созданные в runtime — тоже, наверное, нужная штука/etc/systemd/system/— юниты, созданные системным администратором — а вот сюда мы и положим свой юнит.
Юнит, представляет собой текстовый файл с форматом, похожим на файлы .ini Microsoft Windows.
[Название секции в квадратных скобках]
имя_переменной = значение
Для создания простейшего юнита надо описать три секции: [Unit], [Service], [Install]
В секции [Unit] описываем, что это за юнит. Добавляем описание юнита:
Description=MyUnit
Далее следует блок переменных, которые влияют на порядок загрузки сервисов.
Запускать юнит после какого-либо сервиса или группы сервисов (например, network.target):
After=syslog.target //запустить после того, как запустится syslog
After=network.target //запустить после того, как появится доступ к интернету
After=nginx.service //зустить после того, как запустится nginx
After=mysql.service //зустить после того, как запустится mysql
Для запуска сервиса необходим запущенный сервис mysql:
Requires=mysql.service
Для запуска сервиса желателен запущенный сервис redis:
Wants=redis.service
В итоге переменная Wants получается чисто описательной. Если сервис есть в Requires, но нет в After, то наш сервис
будет запущен параллельно с требуемым сервисом, а не после успешной загрузки требуемого сервиса.
В секции Service указываем, какими командами и под каким пользователем надо запускать сервис:
Тип сервиса:
Type=simple
(по умолчанию): systemd предполагает, что служба будет запущена незамедлительно. Процесс при этом не должен
разветвляться. Не используйте этот тип, если другие службы зависят от очередности при запуске данной службы.
Type=forking
systemd предполагает, что служба запускается однократно и процесс разветвляется с завершением родительского процесса.
Данный тип используется для запуска классических демонов. Также следует определить PIDFile=, чтобы systemd могла
отслеживать основной процесс:
PIDFile=/work/www/myunit/shared/tmp/pids/service.pid
Рабочий каталог, он делается текущим перед запуском стартап команд:
WorkingDirectory=/work/www/myunit/current
Пользователь и группа, под которым надо стартовать сервис:
User=myunit
Group=myunit
Переменные окружения:
Environment=RACK_ENV=production
Команды на старт/стоп и перезапуск сервиса:
ExecStart=/usr/local/bin/bundle exec service -C /work/www/myunit/shared/config/service.rb --daemon
ExecStop=/usr/local/bin/bundle exec service -S /work/www/myunit/shared/tmp/pids/service.state stop
ExecReload=/usr/local/bin/bundle exec service -S /work/www/myunit/shared/tmp/pids/service.state restart
Тут есть тонкость — systemd настаивает, чтобы команда указывала на конкретный исполняемый файл. Надо указывать полный
путь.
Таймаут в секундах, сколько ждать system отработки старт/стоп команд.
TimeoutSec=300
Попросим systemd автоматически рестартовать наш сервис, если он вдруг перестанет работать. Контроль ведется по наличию
процесса из PID файла
Restart=always
В секции [Install] опишем, в каком уровне запуска должен стартовать сервис.
Уровень запуска:
WantedBy=multi-user.target
multi-user.target или runlevel3.target соответствует нашему привычному runlevel=3 «Многопользовательский режим
без графики. Пользователи, как правило, входят в систему при помощи множества консолей или через сеть»
Вот и готов простейший стартап скрипт, он же unit для systemd:
myunit.service
[Unit]
Description=MyUnit
After=syslog.target
After=network.target
After=nginx.service
After=mysql.service
Requires=mysql.service
Wants=redis.service
[Service]
Type=forking
PIDFile=/work/www/myunit/shared/tmp/pids/service.pid
WorkingDirectory=/work/www/myunit/current
User=myunit
Group=myunit
Environment=RACK_ENV=production
ExecStart=/usr/local/bin/bundle exec service -C /work/www/myunit/shared/config/service.rb --daemon
ExecStop=/usr/local/bin/bundle exec service -S /work/www/myunit/shared/tmp/pids/service.state stop
ExecReload=/usr/local/bin/bundle exec service -S /work/www/myunit/shared/tmp/pids/service.state restart
TimeoutSec=300
[Install]
WantedBy=multi-user.target
Кладем этот файл в каталог /etc/systemd/system/
Смотрим его статус командой systemctl status myunit:
myunit.service - MyUnit
Loaded: loaded (/etc/systemd/system/myunit.service; disabled)
Active: inactive (dead)
Видим, что он disabled — разрешаем его
systemctl enable myunit
systemctl -l status myunit
Если нет никаких ошибок в юните, то вывод будет вот такой:
myunit.service - MyUnit
Loaded: loaded (/etc/systemd/system/myunit.service; enabled)
Active: inactive (dead)
Запускаем сервис
systemctl start myunit
Смотрим красивый статус:
systemctl -l status myunit
Если есть ошибки, читаем вывод в статусе, исправляем, не забываем после исправлений в юните перегружать демон systemd
systemctl daemon-reload