Assignment 1 for IT3105 Artificial intelligence programming at NTNU
There are two tasks (Contents).
- Solve the rush hour problem with best-first search.
- Solve the nonogram problem with constraint-satisfation-problem + best-first-search.
The following is the reports written for the assignment. I've only written about what was needed, since there was a restriction on number of pages per report.
The reports are written in Norwegian.
- De forskjellige heuristiske funksjonene
- Hvordan man finner nye noder
- Sammenlikningstabell av ytelsen til de tre typene søk.
For denne oppgaven har jeg laget tre forskjelige heuristiske funksjoner. Jeg begynte med de to åpenbare, manhatten og euclidiean distanse til mål. Disse vil alltid gi samme resultat for Rush Hour problemet, men jeg valgte å legge inn begge for å sjekke tidsforskjellene. Resultatene viste ca den samme tiden for begge. Manhatten var såvidt raskere i alle tilfeller, og dette var forventet.
Manhatten distansen ble veldig enkel for Rush Hour problemet, man har alltid samme Y-koordinat for bilden som er interessant. Der bilens X-koordinat er betegnet som “x” blir regnestykket som følger:

Denne distansen er også veldig enkel for Rush Hour probelmet. Dette blir pythagoras læresetning. Igjen, siden det ikke er noe Y-koordinat vil dette regnestykket alltid gi tilbake et heltall og da akkurat det samme heltallet som Manhatten gir. Der bilens X-koordinat er betegnet som x og Y-koordinaten er y:

Vektet sti er en egendefinert algoritme som gjør en enkel beregning av alt som er direkte foran hovedbilen. Dette er da alle koordinater som er større enn bilens X-koordinat og har samme Y koordinat (2). For hver av disse posisjonene gir den poeng etter rutens innhold.
Tom rute = 1 Bil i rute = 2
Dette gir formelen:

Der poeng(x,y) er formelen for poeng gitt en koordinat.
Alt-foran er basert på vektet sti i sin funksjon. Istedenfor å hente ut alle vediene direkte foran, der Y-koodinaten er satt til å alltid være 2 skal denne algoritmen se på alle (x,y) koordinatene foran bilen. Dette betyr at den gir poeng til alle cellene foran bilen. Denne algoritmen gir klart de beste resultatene, men den er ikke “admissable”. Om man endrer på poengene gitt for forskjellige ruter vil den finne løsninger dårligere enn den beste.
Formelen for all-in-front algoritmen, med den samme poeng(x,y) funksjonen som Vektet sti:

Om poeng(x,y): Poenggivningen er satt til å være som nevnt over:
Tom rute = 1 Bil i rute = 2
Om disse endres vil algoritmen gi bedre resultater. Jeg har prøvd litt forskjellige poeng, en variant der tom rute gir 0 og bil i rute gir 1. Denne gir dårligere resutlater enn de over. Jeg har også prøvd å gange summen av alle poengene med 10 eller 100. Når man gjør dette gir algoritmen feil svar for alle H. Denne overestimerer veldig. Dette gjelder også hvis jeg ganger hver av poengene med 10. Dette betyr vel strengt talt at begge de heuristiske funksjonene som bruker poeng funksjonen ikke er brukbare.

Å lage nye noder med A* algoritmen og Rush Hour noder gjøres det en gjennomgang av alle bilene på kartet. For hver bil sjekker jeg om det er noen lovlige trekk for bilen, e.g. om det er en tom celle foran eller bak bilen. Hvor hvert av de gyldige trekkene som finnes blir det laget en ny node der en enkelt bil er flyttet. Når alle mulige noder er laget blir det gjort noen sjekker på hvordan noden ser ut.
Hvis noden er i “closed”:
Hvis noden har dårligere heuristisk verdi enn den som allerede var sett, kast noden. Om noden har bedre heuristisk verdi vil vi bytte ut den eksistenede noden med denne noden, slik at alle barn får stien fra den nye noden til sin posisjon. Dette medfører også at vi endrer den heuristiske verdien for alle barn.
Hvis noden er i “open”/agenda:
Hvis noden har dårligere heuristisk verdi enn den som allerede var sett, kast noden. Hvis noden har bedre heuristisk verdi blir noden lagt til i agenda. Her kunne jeg valgt å slette noden, men dette gjøres ikke.
Om ingen av de to over gjelder, legges noden til i agendaen.
Under er sammenlikning av dybde-først, bredde-først og A* søkene. Jeg har oppnådd de forskjellige typene søkene ved å endre på “agendaen” i A*. Dybde først er LIFO (Last in, first out) og er implementert ved å lage innsetting først i listen. Her har vi ikke sortering. Det er heller ikke sortering for bredde først. Bredde først er FIFO (First in, first out) er laget ved å fjerne sortering fra agendaen. Køen er fortsatt samme.

For mitt CSP problem valgte jeg å gå for den aggregerte versjonen, gitt i oppgaveteksten. En variabel for meg er dermed en hel rad eller en hel kolonne. For hver av verdiene som er gitt på hver side av brettet (eller for hver linje i brett-filen) lager jeg alle mulige permutasjoner av verdiene.
Permutasjonene lagres i form av en streng. Denne strengen er oppgitt som feks. “00110100”. Dette er da en hel rad. Domenet består av kun slike verdier. Det kan være laget opp til ~25000 slike for et 25x25 brett. Jeg har dermed en variabel per rad og en variabel per kolonne.
- index (index for rad eller kolonne på brettet)
- domene (alle de forskjellige domene-verdiene)
- type (Rad eller kolonne)
State holder på alle variablene. Denne har en liste med rader og en liste med kolonner. State holder også på alle constraints. Det blir laget en constraint per celle i matrisen.
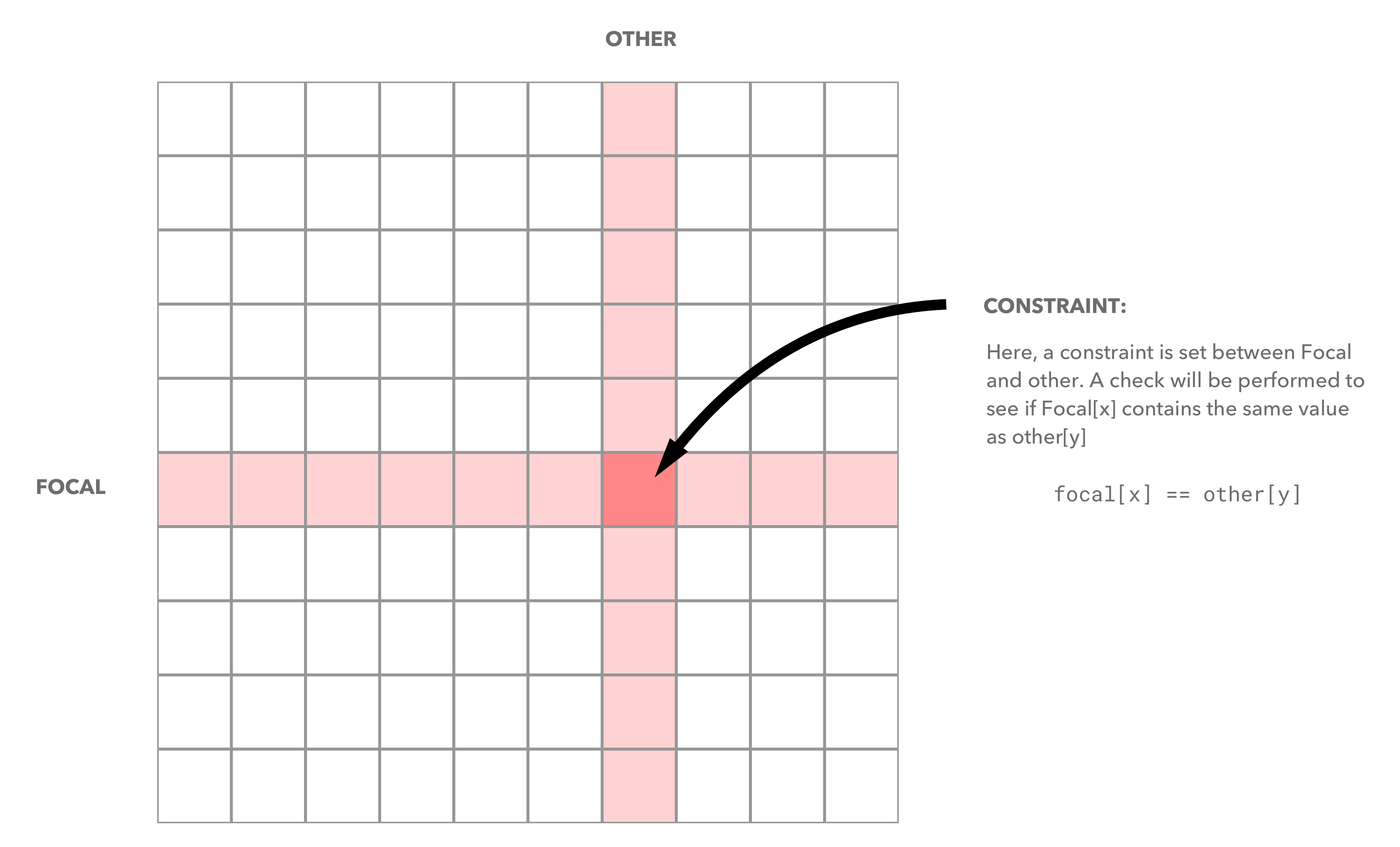
Constraints er bygd opp av en enkel sammenlikning. En hver constraints er en kontroll på om en celle har samme verdi for to forskjellige variabler. De to variablene må være en av kolonne og en rad. Sammenlikningen baserer seg på at en av variablene er hoved variabelen (Focal) sammenliknes med en annen variabel (other).
Hovedvariabelen får hver enkelt av verdiene i domenet sitt sjekket mot alle verdiene i domenet til other. Om ingen av verdiene er i hele domenet til other er lik verdien i den enkle verdien i focal blir verdien kastet fra domenet til focal. Slik skjer filtreringen.
Den heuristiske funksjonen for A* er veldig enkel. Denne funksjonen er summen av lengden til alle domenene til alle variabler -1. Denne gir ganske nøyaktig heuristisk funksjon.

Når A* GAC skal lage barn for en Node i A* algoritmen må den velge hvilken som variabel den skal lage barn ut av. Dette gjør den ved å søke gjennom alle nodene, først i rad-listen (den søker i kolonne-listen om alle rader har alle variablene side med domene på lengde 0). Den søker så igjennom alle i listen for å så velge den med minst domener i domenet sitt. Et kriterie som må oppfylles er at det minst må være to domener i domenet.
Det er viktig å velge den med det minste domenet fordi den har minst sannsynlighet for å velge feil. Dette er nyttig når søket går videre. A* vil velge den med minst F() verdi, og det blir ikke de nodene som har blitt laget tidlig i søket. Om en dårlig antakelse er gjort tidlig er dette veldig dårlig for ytelsen til søket.
Ingen endringer var nødvendig for selve A* kjernen. Jeg var nødt til å lage en arving av A* noden. Denne noden (GACNode) har spesialisert de samme metodene som måtte spesialiseres for RushHourNode. Det er de følgende metodene:
| Metode | Beskrivelse |
|---|---|
| is_solution() | Sjekker om den nåværende “state” er en løsning på problemet. Om søket er ferdig. |
| create_children() | Lager barnenoder som returneres tilbake til A* algoritmens agenda. |
| setH() | Heuristiske funksjonen, beskrevet over. |
For GAC er det lite av de tredelte funksjonene som må endres. Under er en tabell av endringer:
| Metode | Beskrivelse |
|---|---|
| Initialization / find neighbours | Denne er helt skreddersydd til Nonogram puslespillet og må skrives helt om. Algoritmen for å finne naboer er samme som initialiseringsmetoden med en liten spesialisering. Denne må også skrives helt om for å brukes med noen andre algoritmer. |
| Domain filtering | Denne er generell nok til at den burde takle et hvert CSP problem. |
| Revise | Revise er også laget generell og burde derfor takle et hvert CSP problem. |
Naboskapsmetoden i GAC var vanskelig å få til. Jeg hadde en feil som gjorde at GAC ikke klarte å løse alle Nonogram brettene den burde. Jeg gjorde et par forskjellige forsøk før jeg fikk et tips fra en medstudent.
Mitt forsøk: Lage en algoritme som henter inn alle constraints og tilhørende variabler som var knyttet til variabelen som endret seg gjennom revise. Dette vil da være alle enkelte celler med samme indeks som den endrede focal variabelen. Disse skal ha motsatt retning som focal. Dette vil si at jeg legger til en rekke med constraints inn i køen.
Med denne naboskaps algoritmen blir veldig få puslespill løst.
Etter samtale med medstudent: Legge til alle constraints for alle celler med hensyn på motsatt rad. Altså, samme antall constraints som det er celler i brettet. Dette virker, men er veldig tregt. Mange unødvendige constraints som blir laget.
Jeg fikk ikke tid til å finne en optimal løsning på problemet.