- 通过ansible脚本, 降低安装部署一套k8s集群的工作难度
- 熟悉linux的基本操作命令
- 熟悉Ansible的基本操作
- 熟悉Docker的基本操作
- 基本阅读完成k8s的官方文档,对k8s有一个基本的认识,了解其术语和基本概念.能够根据关键字,迅速在官网上找到对应的文档进行查阅.
- 脚本使用 kubeadm 来创建k8s集群, 请读者熟读文档
- 了解负载均衡的技术概念, HAProxy 的基本工作原理
- 了解高可用的技术概念, Keepalived的基本工作原理
- 准备阶段
- 网络规划
- 获取安装脚本
- 根据目标主机和网络规划修改配置文件
- 分阶段执行脚本
- 操作系统: ubuntu 18.04
- 配置主机能够使用 root 用户进行 ssh证书登录
- 目标主机硬件配置符合安装k8s的最低要求, 参考
- 若干台主机
- 单 master 模式的集群, 需要 1 台master主机, 和至少1台的worker主机(用于跑pod负载)
- 3 master 模式的 负载均衡 + 高可用 模式的集群, 需要 3 台 master 主机, 和至少1台的worker主机(用于跑pod负载)
- 所有的目标主机配置好静态IP, 同一个集群的主机, 尽量在同一个子网内
- 我们通过控制端主机进行操作, 完成整个k8s集群的创建过程
- 控制端主机上要求安装 Python3 环境
- 安装了 Ansible, 我们通过 Ansible 进行整个集群的创建操作
-
目标主机配置了静态IP
-
目标主机之间能够网络互通
-
控制端主机能够与目标主机网络互通, 控制端主机能够通过SSH证书方式,对目标主机进行ssh操作 参考:ssh-copy-id
-
目标主机能够访问公网, 以便目标主机能够下载依赖软件包和docker镜像 (离线方式的解决方案另外开篇叙述)
-
k8s网络插件,采用 Calico
问: 为什么采用 Calico ?
答: 参考这篇文章的描述和评测,认为 Calico 是一个比较成熟的方案.
在进行创建集群的工作之前,我们需要先集群的ip地址进行统一规划:
- 明确每一台主机的静态ip地址
- 确定每一台主机在集群里担任的角色: master, worker
- 根据主机数量(资源,成本)选择采用:
- 单 master 集群模式
- 多 master 集群模式 (多个 master 组成 负载均衡 + 高可用)
- 确定 控制平面 的域名, IP地址, 端口
- 控制平面的IP地址, 在高可用的模式下, 为高可用服务的 虚IP. 在单master节点的模式下, 为 master 的IP地址
- 多 master 集群模式下, 如果控制平面使用的端口与 kube-apiserverer 使用的端口相同(默认:6443), 则负载均衡服务不能够与master运行在同一台主机上, 否则会出现端口冲突. 在此情况下, 可以选择另外的worker主机运行负载均衡服务. 或者更改控制平面的端口为其他值,例如:7443. 但是, 这种方式下, 需要在开始创建集群之前, 先在3台master上搭建好 负载均衡+高可用 服务.
- 在所有的目标主机上 /etc/hosts 文件里添加一条 控制平面域名 到IP的解析记录
- 确定k8s集群中, pod 使用的网段, 一般来说,只要和目标主机不在同一个网段即可.
- 确定k8s集群中, service 使用的网段, 不能和目标主机以及pod使用的网络在同一网段
-
安装脚本源代码托管在github上, 源码地址
-
获取代码到控制端主机
git clone https://github.com/LoveInShenZhen/k8s-ubuntu-ansible.git
-
hosts 文件描述了我们的 ansible 脚本要操作的目标主机
-
文件sample 如下, 文件中的配置以下文的 案例描述 为例:
# 主机清单文件参考: http://ansible.com.cn/docs/intro_inventory.html [nodes:children] master worker [master:children] first_master other_master # host_name 只能包含 英文字母,数字,中杠线 这3种字符, 我们使用 host_name 作为k8s 的node_name, 要保证唯一性 (注: 不允许有下划线) # 创建集群时的第一个 Master [first_master] 192.168.3.151 host_name=master-1 # 需要加入到现有集群的其他 Master [other_master] 192.168.3.152 host_name=master-2 192.168.3.153 host_name=master-3 [worker] 192.168.3.154 host_name=work-1 192.168.3.155 host_name=work-2 # vip_interface 为虚IP所绑定的网卡设备名称 [lb_and_ha] 192.168.3.151 vip_interface=eth1 192.168.3.152 vip_interface=eth1 192.168.3.153 vip_interface=eth1 [all:vars] ansible_ssh_user=root ansible_ssh_private_key_file=<请替换成你的root用户证书> ansible_python_interpreter=/usr/bin/python3 -
目标主机,按照用途和分工不同, 分成不同的组, 说明如下:
组名 说明 nodes k8s集群内所有的 master 主机和所有的 worker 主机 master k8s集群管理节点, 包含2个 子组, 分别是 first_master 和 other_master first_master 创建集群时的第一个 Master other_master 要加入到现有集群的其他 Master. 如果是 单master 模式下, 该组成员为空 worker k8s集群工作节点, 用于运行负载pod lb_and_ha 用于运行 k8s_kube-apiserverer负载均衡服务 + 高可用 的节点 -
请根据网络规划, 修改分组中的主机的 ip, host_name
-
host_name 应该是全局唯一, 只能包含 英文字母,数字,中杠线 这3种字符
为什么?
- 在 kubeadm init 初始化集群 和 kubeadm join 添加节点到集群的时候, 都是用了 --node-name 参数来指定节点的名称, 我们的脚本是使用主机名作为此参数的值, 因此需要为每个主机单独设置一个不重复的主机名.
-
在 lb_and_ha 组中, 每个主机需要单独设置 vip_interface 参数.
为什么?
- vip_interface 被用来指定虚IP所绑定的网卡设备名称
- 主机上可能有不止一块网卡, 所以需要进行明确指定
- 主机上的多块网卡可能设置成bond模式, 通过此参数来指定虚IP绑定到指定的 bond网卡上
-
请设置 ansible_ssh_private_key_file 为root用户ssh登录目标主机的证书
-
文件路径: roles/common/defaults/main.yml
-
文件sample 如下, 文件中的配置以下文的 案例描述 为例:
--- # defaults file for common k8s: # 控制平面的 主机域名和端口号 # ref: https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/high-availability/#%E4%BD%BF%E7%94%A8%E5%A0%86%E6%8E%A7%E5%88%B6%E5%B9%B3%E9%9D%A2%E5%92%8C-etcd-%E8%8A%82%E7%82%B9 # kubeadm init --control-plane-endpoint "control_plane_dns:control_plane_port" ...(略) control_plane_dns: k8s.cluster.local control_plane_port: 6443 # apiserver_advertise_address: 0.0.0.0 apiserver_bind_port: 6443 # ref: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/#pod-network pod_network_cidr: "192.168.0.0/16" service_cidr: "10.96.0.0/12" service_dns_domain: "cluster.local" # 可选值: registry.cn-hangzhou.aliyuncs.com/google_containers [官方文档](https://github.com/AliyunContainerService/sync-repo) # gcr.azk8s.cn/google_containers [官方文档](http://mirror.azure.cn/help/gcr-proxy-cache.html) image_repository: "registry.cn-hangzhou.aliyuncs.com/google_containers" apt: docker: apt_key_url: https://download.docker.com/linux/ubuntu/gpg apt_repository: https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu k8s: apt_key_url: https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg apt_repository: https://mirrors.aliyun.com/kubernetes/apt/ # master 节点个数 master_count: "{{ groups['master'] | length }}" # 是否是单master模式 single_master: "{{ (groups['master'] | length) == 1 }}" # first_master: "{{ groups['first_master'] | first }}" ntpdate_server: cn.ntp.org.cn docker: # daemon.json 配置, 参考: https://docs.docker.com/engine/reference/commandline/dockerd/#daemon-configuration-file daemon: # Docker Hub镜像服务器 registry-mirrors: - https://dockerhub.azk8s.cn - https://docker.mirrors.ustc.edu.cn - https://reg-mirror.qiniu.com # 参考: https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/install-kubeadm/#%E5%9C%A8%E6%8E%A7%E5%88%B6%E5%B9%B3%E9%9D%A2%E8%8A%82%E7%82%B9%E4%B8%8A%E9%85%8D%E7%BD%AE-kubelet-%E4%BD%BF%E7%94%A8%E7%9A%84-cgroup-%E9%A9%B1%E5%8A%A8%E7%A8%8B%E5%BA%8F exec-opts: - "native.cgroupdriver=systemd"
-
配置参数说明
- k8s.control_plane_dns
- 控制平面的域名
- k8s.control_plane_port
- 控制平面的端口.
- 如果我们希望在 master 的主机上可以运行控制平面的负载均衡服务, 则需要将此端口设置成一个与k8s.apiserver_bind_port不同的值
- 如果是 单master 模式下的集群, 实际上就不需要控制平面的负载均衡服务, 可以设置的与k8s.apiserver_bind_port 一致.
- 在下文中的案例描述里, 我们演示的过程是从单master集群变化成3master集群, 控制平面服务的高可用和负载均衡, 我们不放在master的机器上部署,而是选择2台worker主机来做一主一备方式的HA+LB的方式, 所以控制平面的端口就一开始按照单master的方式, 设置成与k8s.apiserver_bind_port, 默认 6443
- k8s.apiserver_bind_port
- kube-apiserverer 服务的端口,一般不做修改,默认 6443, 请参考 kubeadm init 的 --apiserver-bind-port 参数
- k8s.pod_network_cidr
- 请参考 kubeadm init 命令的 --pod-network-cidr 参数
- k8s.service_cidr
- 请参考 kubeadm init 命令的 --service-cidr 参数
- k8s.service_dns_domain
- 请参考 kubeadm init 命令的 --service-dns-domain 参数
- k8s.image_repository
- 请参考 kubeadm init 命令的 --image-repository 参数
- 通过设置此参数, 安装过程就不会从默认的 k8s.gcr.io 仓库下载镜像了, 解决了 k8s.gcr.io 仓库被墙的问题.
- 我们的参数配置,使用了 Aliyun (Alibaba Cloud) Container Service 提供的镜像仓库
- --image-repository 参数使用请参考这篇文章
- apt.docker.apt_key_url
- Docker’s official GPG key.
- apt.docker.apt_repository
- Docker’s official repository 请参考官方文档:ununtu下安装docker-ce
- apt.k8s.apt_key_url
- Kubernetes 镜像源 GPG key
- apt.k8s.apt_repository
- Kubernetes 镜像源, 参考: 阿里巴巴Kubernetes 镜像源
- 使用镜像源, 是为了解决被墙的问题
- ntpdate_server
- 时间同步服务器域名
- k8s.control_plane_dns
进入到脚本源码中的 build_k8s 目录 (即hosts 文件所在的目录)
ansible-playbook prepare_all_host.yml-
检查全局配置文件 中的 k8s.control_plane_port, 我们使用默认值: 6443
-
更新所有节点的 /etc/hosts, 将控制平面的域名解析到 第一个master节点 的IP地址上
为什么?
- 在创建集群, 向集群添加节点的过程, 我们需要保证通过 控制平面域名+控制平面端口 的方式, 可以访问到master的kube-apiserverer服务. 所以在集群的创建的过程中, 先暂时将控制平面域名解析到第一个Master 节点
- 等待其余的2个master都加入到集群后, 再将3个master配置成高可用, 控制平面的虚IP生效后, 再更新所有节点的 /etc/hosts, 将控制平面的域名解析到虚IP.
-
执行以下命令进行更新控制平面域名解析操作, 注意下面示例中的传参方式
- 通过 -e "key1=value1 key2=value2 ..." 方式传参
- 需要指定 domain_name 和 domain_ip 2个参数
- domain_name 为控制平面域名, 请根据制定的网络规划进行赋值
- domain_ip 为控制域名解析的目标IP, 这里我们指定为第一个master的IP
ansible-playbook set_hosts.yml -e "domain_name=k8s.cluster.local domain_ip=192.168.3.151" -
执行脚本, 开始创建第一个master节点
ansible-playbook create_first_master_for_cluster.yml -
脚本执行完成后, 第一个master应该顺利启动了, ssh到 master-1 上执行以下命令, 查看集群节点信息:
kubectl get nodes
应该出现如下信息, 表明集群已经顺利创建了,尽管现在只有一个master-1节点
NAME STATUS ROLES AGE VERSION master-1 NotReady master 29s v1.18.0在master-1上执行以下命令查看集群信息
kubectl cluster-info
输出如下信息, 可以看到集群已经是 running 状态
Kubernetes master is running at https://k8s.cluster.local:7443 KubeDNS is running at https://k8s.cluster.local:7443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
执行脚本, 添加 其他的 master 节点和 worker节点到集群
注: 添加 --forks 1 以便一台一台的加. 因为测试中发现, 并行添加的时候, 有一定概率出现因ETCD发生重新选举而导致添加Master失败, 更多数量(超过4台)的主机的同时加入集群的情况, 因为硬件资源有限, 没有测试过.
ansible-playbook --forks 1 add_other_node_to_cluster.yml检查集群节点信息, 在一台 master 节点上执行命令:
root@master-2:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master-1 Ready master 9m13s v1.18.0
master-2 NotReady master 4m5s v1.18.0
master-3 NotReady master 2m21s v1.18.0
work-1 NotReady <none> 110s v1.18.0
work-2 NotReady <none> 107s v1.18.0注: 单master节点模式不需要执行此步骤
完成了 第三步 之后, 集群已经运行起来了. 只不过, 由于 控制平面的域名 是解析到 第一个 master 的IP 上的, 所以现在虽然有3台master在集群, 但是只有第一个master才能够通过控制平面的域名提供k8s集群的 kube-apiserverer 服务.
下面, 我们选择2台除master节点之外的主机(可以是 worker 主机, 也可以是额外的2台主机), 创建一套一主一备形式的 负载均衡 + 高可用
-
检查主机清单文件: hosts 中的 [lb_and_ha] 的2台主机的 IP地址 与 需要绑定虚IP的网卡设备名称 是否设置正确
# vip_interface 为虚IP所绑定的网卡设备名称 [lb_and_ha] 192.168.3.154 vip_interface=eth0 192.168.3.155 vip_interface=eth0
-
检查 create_haproxy.yml 配置, 文件sample 如下, 文件中的配置以下文的 案例描述 为例:
--- - name: Create a load blance using HAproxy hosts: lb_and_ha vars: # 负载均衡对外提供服务的端口 service_bind_port: "{{ k8s.control_plane_port }}" # 后端服务器使用的端口, 是给下面转换的过滤器使用的, haproxy.cfg.j2 模板没有使用该变量 backend_server_port: "{{ k8s.apiserver_bind_port }}" # 转换成形如: ['192.168.3.154:6443', '192.168.3.155:6443'] 的列表 backend_servers: "{{ ansible_play_hosts_all | map('regex_replace', '^(.*)$', '\\1:' + backend_server_port) | list }}" # 或者采用如下的方式, 手动设置, 这样 backend_servers 可以由集群外的主机来担任 # backend_servers: # # - "<ip>:<port>" # - "192.168.3.154:6443" # - "192.168.3.155:6443" # 是否开启 haproxy stats 页面 ha_stats_enable: True # haproxy stats 页面的服务端口 ha_stats_port: 1936 # haproxy stats 页面的 url ha_stats_url: /haproxy_stats # haproxy stats 页面的访问的用户名 ha_stats_user: admin # haproxy stats 页面的访问的密码 ha_stats_pwd: showmethemoney container_name: k8s_kube-apiserverers_haproxy tasks: - name: check parameters fail: msg: "Please setup backend_servers parameter" when: backend_servers == None or (backend_servers|count) == 0 or backend_servers[0] == '' or backend_servers[0] == '<ip>:<port>' # 进行主机的基础设置 - import_role: name: basic_setup - name: pip install docker (python package) pip: executable: /usr/bin/pip3 name: docker state: present - name: mkdir -p /opt/haproxy file: path: /opt/haproxy state: directory - name: get container info docker_container_info: name: "{{ container_name }}" register: ha_container - name: setup HAproxy configuration template: backup: True src: haproxy.cfg.j2 dest: /opt/haproxy/haproxy.cfg mode: u=rw,g=r,o=r notify: restart HAproxy container - name: create HAproxy container docker_container: detach: yes image: haproxy:alpine name: "{{ container_name }}" volumes: - "/opt/haproxy/haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg" network_mode: bridge ports: - "{{ service_bind_port }}:{{ service_bind_port }}" - "{{ ha_stats_port }}:{{ ha_stats_port }}" restart_policy: always state: started handlers: - name: restart HAproxy container docker_container: name: "{{ container_name }}" state: started restart: yes when: ha_container.exists
-
在分配的2台worker上创建负载均衡服务
ansible-playbook create_haproxy.yml-
脚本运行完毕后, 我们可以在其中一台机器上, 查看 haproxy 的监控页面, 例如: 192.168.3.155 http://192.168.3.155:1936/haproxy_stats , 访问密码为 create_haproxy.yml 中 ha_stats_pwd 的值
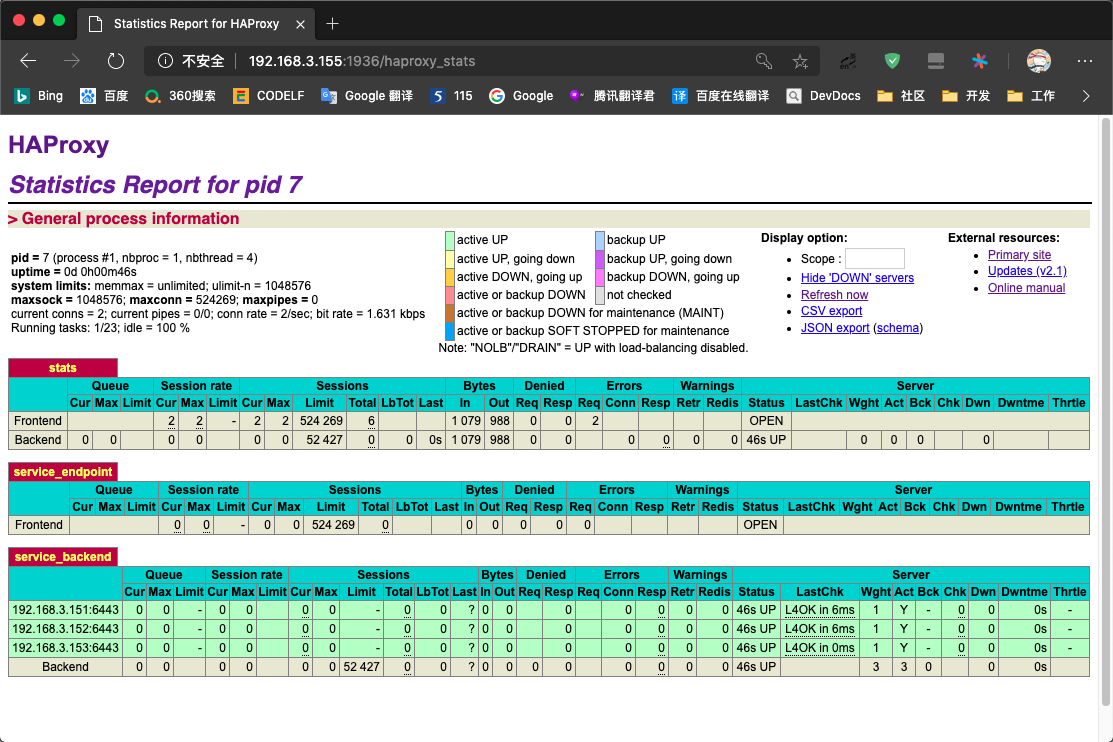
现在我们有2台提供相同服务的负载均衡, 接下来我们将这2台负载均衡配置成一主一备的方式, 并让 虚IP 生效
-
检查 create_keepalived.yml 配置, 文件sample 如下, 文件中的配置以下文的 案例描述 为例:
--- - name: setup keepalived on target host hosts: lb_and_ha vars: # 虚IP virtual_ipaddress: 192.168.3.150/24 keepalived_router_id: 99 keepalived_password: FE3C5A94ACDC container_name: k8s_kube-apiserverers_keepalived tasks: # 进行主机的基础设置 - import_role: name: basic_setup - import_role: name: install_docker - name: pip install docker (python package) pip: executable: /usr/bin/pip3 name: docker state: present - name: mkdir -p /opt/keepalived file: path: /opt/keepalived state: directory - name: get container info docker_container_info: name: "{{ container_name }}" register: the_container - name: copy Dockerfile to target host copy: src: keepalived.dockerfile dest: /opt/keepalived/Dockerfile - name: build keepalived image docker_image: name: keepalived:latest source: build build: path: /opt/keepalived pull: yes - name: setup keepalived configuration template: src: keepalived.conf.j2 dest: /opt/keepalived/keepalived.conf mode: u=rw,g=r,o=r notify: restart keepalived container - name: create keepalived container docker_container: capabilities: - NET_ADMIN - NET_BROADCAST - NET_RAW network_mode: host detach: yes image: keepalived:latest name: "{{ container_name }}" volumes: - "/opt/keepalived/keepalived.conf:/etc/keepalived/keepalived.conf" restart_policy: always state: started handlers: - name: restart keepalived container docker_container: name: "{{ container_name }}" state: started restart: yes when: the_container.exists
-
确定 虚IP 配置项 virtual_ipaddress 与规划的一致
注意: 这里的虚ip配置, ip地址需要加上子网掩码位数的标识, 例如: /24
-
执行脚本, 在 3 个master上配置高可用(keepalived方式)
ansible-playbook create_keepalived.yml
-
执行完毕后, 检查是否能够 ping 通虚IP. 能ping通, 说明主备模式下的虚IP已经生效
目前为止, 控制平面的域名 还是指向 master-1. 接着我们需要将 控制平面的域名 解析到 虚IP上, 这样就可以通过 控制平面的域名 来访问到上一步创建的 负载均衡 服务了.
我们需要更新所有节点的 /etc/hosts, 将控制平面的域名解析到虚IP上
执行脚本命令:
在此例中, 虚IP地址为: 192.168.3.150
ansible-playbook set_hosts.yml -e "domain_name=k8s.cluster.local domain_ip=192.168.3.150"在节点主机对控制平面域名进行 ping 测试, 验证域名已正确解析到虚IP上.
在master节点主机上, 执行命令, 检查是否能正常查看节点信息 (kubectl 命令会通过控制平面域名和端口来访问控制平面的 kube-apiserverer):
kubectl get nodes- 采用多 master 集群模式
- 在 3 台 master 主机上, 部署负载均衡和高可用
- 2 台 worker
-
假设目标主机处于 192.168.3.0/24 网段,分配地址如下表所示:
用于 IP地址 --control-plane-endpoint (控制平面在本地集群的域名:端口),域名解析到右边所分配的IP地址 192.168.3.150 master-1 192.168.3.151 master-2 192.168.3.152 master-3 192.168.3.153 worker-1 192.168.3.154 worker-2 192.168.3.155 -
控制平面网络配置规划
控制平面 设置 备注 控制平面域名 k8s.cluster.local 可按照自己的要求自定义 IP (高可用的虚IP) 192.168.3.150 控制平面端口 7443 -
k8s集群内部网段规划
用于 网段 备注 --pod-network-cidr 172.19.0.0/16 采用Calico网络插件时, 该设置的值要与calico.yaml中的值一致.
一致性由提供的Ansible脚本保证--service-cidr 10.96.0.0/12
所有的目标主机, 在执行安装脚本前, 都要先经过初始化设置, 已达到作为 k8s 集群主机的基本要求.
-
为每个主机设置主机名, 加入集群时, 主机名会作为节点的 node_name 使用
-
host_name 变量, 是在 [hosts](###Ansible 的 hosts 文件) 文件中, 为每个主机单独设置的, 主机名请问重复
- name: setup hostname hostname: name: "{{ host_name }}"
-
因为需要访问外网下载镜像, 所以添加额外的dns服务器配置
-
因为ubuntu采用了 systemd-resolved 作为dns服务, 修改方法请参考这篇文章
- name: add dns blockinfile: path: /etc/systemd/resolved.conf backup: yes insertafter: "\\[Resolve\\]" block: | DNS=8.8.8.8 state: present notify: restart systemd-resolved service
-
ubuntu 采用的是 Uncomplicated Firewall 防火墙
- name: "disable ufw [Uncomplicated Firewall]" service: name: ufw enabled: no state: stopped
-
kube-proxy 支持使用 ip_vs, 所以我们预先是所有主机都自动加载 ip_vs 模块
- 参考这边文章 [IPVS-Based In-Cluster Load Balancing Deep Dive]
- 技术细节请参考官方源码文档
- 但是参考这篇文章 kube-proxy 模式对比:iptables 还是 IPVS? 的末尾的 补充:Calico 和 kube-proxy 的 iptables 比较 这段话末尾的结论: 即使是使用 10,000 个服务和 100,000 个 Pod 的情况下,Calico 每连接执行的 iptables 规则也只是和 kube-proxy 在 20 服务 200 个 Pod 的情况基本一致 . 所以我们现在只是让所有的主机自动加载需要的ip_vs模块, 但是并没有在集群里让 kube-proxy 真正使用ip_vs mode
- name: enable ip_vs kernel module auto loading when reboot blockinfile: path: /etc/modules backup: yes block: | ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack_ipv4 state: present - name: Load ip_vs kernel module modprobe: name: ip_vs state: present - name: Load ip_vs_rr kernel module modprobe: name: ip_vs_rr state: present - name: Load ip_vs_wrr kernel module modprobe: name: ip_vs_wrr state: present - name: Load ip_vs_sh kernel module modprobe: name: ip_vs_sh state: present - name: Load nf_conntrack_ipv4 kernel module modprobe: name: nf_conntrack_ipv4 state: present
-
为了加快下载依赖软件包的速度, 改成使用阿里云的ubuntu源
- name: change to aliyun source copy: src: aliyun.ubuntu.1804.source.list dest: /etc/apt/sources.list mode: u=rw,g=r,o=r
- nftables 与当前的 kubeadm 软件包不兼容:它会导致重复防火墙规则并破坏
kube-proxy - 具体请参考: 官网文档
-
确保如下的软件包安装在目标主机上
- name: install dependence pkgs apt: update_cache: yes pkg: - apt-transport-https - ca-certificates - software-properties-common - curl - gnupg-agent - python3-pip - iptables - ntpdate - rsync - ipvsadm - ipset state: present
-
集群内的所有主机的时区应该一致
-
集群内的所有主机的时间应该一致(误差范围内)
-
时区统一设置成 Asia/Shanghai
-
每天凌晨03:00开始时间同步
- name: setup timezone timezone: hwclock: UTC name: Asia/Shanghai - name: setup ntpdate cron task cron: name: ntpdate sync time daily job: "ntpdate {{ ntpdate_server }}" day: "*" hour: "3" minute: "0" notify: ntpdate sync time now
-
k8s需要主机关闭交换分区.
-
参考官方文档说明 You MUST disable swap in order for the kubelet to work properly.
- name: gathering swap state swap_state: - name: disable swapoff now shell: swapoff -a when: host_swap_on == True - name: disable swapoff permanently replace: path: /etc/fstab regexp: '^(\s*)([^#\n]+\s+)(\w+\s+)swap(\s+.*)$' replace: '#\1\2\3swap\4' backup: yes
-
需要安装 docker-ce
- name: add docker-ce GPG key apt_key: url: "{{ apt.docker.apt_key_url }}" state: present - name: add docker-ce APT repository apt_repository: repo: "deb [arch=amd64] {{ apt.docker.apt_repository }} {{ ansible_lsb.codename }} stable" - name: install docker-ce pkg apt: pkg: - docker-ce - docker-ce-cli - containerd.io
-
设置 docker 官方image仓库的镜像站点
-
设置 native.cgroupdriver=systemd 参考官方文档:在控制平面节点上配置 kubelet 使用的 cgroup 驱动程序
- name: setup /etc/docker/daemon.json template: src: daemon.json.j2 dest: /etc/docker/daemon.json mode: u=rw,g=r,o=r notify: restart docker service
默认配置生成的 /etc/docker/daemon.json 如下:
{ "exec-opts": [ "native.cgroupdriver=systemd" ], "registry-mirrors": [ "https://dockerhub.azk8s.cn", "https://docker.mirrors.ustc.edu.cn", "https://reg-mirror.qiniu.com" ] }
- name: add k8s GPG key
apt_key:
url: "{{ apt.k8s.apt_key_url }}"
state: present
- name: add k8s APT repository
apt_repository:
repo: "deb {{ apt.k8s.apt_repository }} kubernetes-xenial main"
- name: install docker-ce pkg
apt:
pkg:
- docker-ce
- docker-ce-cli
- containerd.io- Kubernetes Dashboard 是 Kubernetes 的官方 Web UI. 使用 Kubernetes Dashboard,您可以:
- 向 Kubernetes 集群部署容器化应用
- 诊断容器化应用的问题
- 管理集群的资源
- 查看集群上所运行的应用程序
- 创建、修改Kubernetes 上的资源(例如 Deployment、Job、DaemonSet等)
- 展示集群上发生的错误
- 安装过程请参考 官方文档
- Kubernetes Dashboard github